
Chapter 13. IT Operations
Intent-Based Networking (IBN) describes how to manage and operate a network infrastructure. Traditionally, IT operations teams are organized around IT operations frameworks based on best practices. These kinds of changes would have to follow (strict) change procedures including approvals from the change advisory boards.
This often results in the fact that a relatively simple change (for example, in some organizations even a reload of a switch) will take much more time and require significant resources to write a change procedure, request the change to the advisory board, wait for approval, have a discussion about the denial, and then after a long period of time, be able to reload that switch in the evening.
Change procedures and change advisory boards are in general a good thing to reduce the risk of major disruptions and prevent two changes from different domains at the same time; however, organizations often overdo the implementation with a drastic reduction in flexibility and change agility as a consequence.
With a full implementation of IBN, applications leverage APIs to change behavior in the network automatically, without any human intervention at all. The organization of IT operations will need to change to keep the processes (and thus compliancy) in line with IBN and to achieve the maximum potential of digitalization and IBN.
This chapter provides background information on some common frameworks found within IT operations and their principles and how IBN has an impact on these frameworks. The second part of this chapter provides some recommended changes to IT operations to truly enable IBN:
Common Frameworks Within IT Operations
Many enterprises organize their IT processes around a set of common IT operations frameworks. This section describes (briefly) the most common operations frameworks that are used throughout enterprises. Within each framework, the challenge with IBN is described as well.
ITIL
Perhaps the best known and widely used IT operation framework is Information Technology Infrastructure Library (ITIL). ITIL is actually not a framework (containing a model, design principles, and so on) but a collection of concepts and best practices from the industry for delivering IT services to the enterprise.
The most recent version of ITIL is ITIL v4, which was published in early 2019. It is an update of the previous version, ITIL v3 from 2011. ITIL v4 uses new techniques to increase efficiency within IT while also being more aligned with other existing methods, such as Agile, DevOps, and Lean. ITIL v4 encourages, in contrast to ITIL v3, fewer silos, increased collaboration, and the integration of Agile and DevOps into IT Service Management (ITSM) strategies. ITIL v4 is more flexible and customizable compared to ITIL v3. Also, ITIL v4 and ITIL v3 are not mutually exclusive, and many parts of ITIL v3 can be used within ITIL v4 too, which is great because many organizations have based their IT operations on ITIL v3. This section is not intended to fully describe the ITIL v3 framework, but rather provide a conceptual overview to provide context where the ITIL v3 framework has a relationship with IBN.
Use Case: Overusing an IT Operation Framework
SharedService Group provides several IT services to its internal businesses. Some of these systems are Electronic Data Interchange (EDI) systems used by partners to submit data electronically to specific business processes within the enterprise.
EDI systems are used to automatically exchange information electronically (based on agreed and standard document formats) between systems at each communication partner without human intervention. A clear example would be the automatic generation and sending of an electronic invoice to a customer, which would automatically be received and processed in the financial system.
To gain more control of IT in general, SharedService Group decided to implement the ITIL framework. A project was defined, and after executing a number of changes, including significant restructuring of the organization to represent and divide several responsibilities, the project was a success. In general, IT services were described, and procedures could be followed to have applications or services changed within the enterprise.
However, part of the systems that SharedService Group was managing also included specific EDI applications that were critical to the business. These applications were used by partners of the enterprise to submit data electronically.
Part of that data were structured physical locations that were used within the logistics department for receiving and sending shipments. These physical locations were using a coding scheme that made each location unique; and the unique codes were shared throughout the different EDI applications, and were also used by the partners.
As ITIL was fully implemented, the addition of a new physical location would now require a full change procedure, including approval from the change advisory board, and several persons would need to validate whether the additional record was allowed as change to be executed in a change service window.
As long as the change was not approved, no shipment could be sent or received to that new location. This resulted in considerable business loss and business standstills.
Unfortunately, this use case example is not a story on its own. Often organizations perform a full implementation of ITIL, and because it is a collection of best practices in the IT, it is assumed best to incorporate it fully. Consequently, it essentially negates one of the key aspects of any best practice: only adopt them if the context and best practices are applicable for the situation.
Often ITIL is initialized as an attempt to improve service, but it also often ends in a paper tiger containing a lot of procedures and processes that do not directly improve the service experience for customers. It is always important to be very careful and balance between processes and actual operations when implementing a framework.
ITILv3 defines five stages that each define a number of subprocesses for that specific phase.
Figure 13-1 provides a conceptual representation of the different stages an IT service can follow throughout its lifecycle. The image represents a continuous process of (re-)defining and managing services.
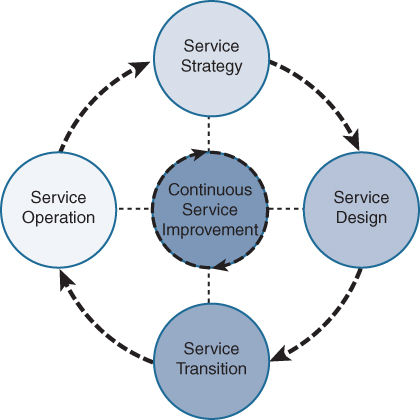
Figure 13-1 ITILv3 Overview of Stages
As you can see, the ITILv3 framework has a significant number of descriptive management processes and corresponding key performance indicators (KPIs). This section does not go into detail for each management process, but quite a few processes from the different stages, such as incident management, change management, problem management, and asset management, are familiar within IT operations teams.
Stage 1: Service Strategy
This stage determines which types of services should be offered to customers (or internally within an enterprise). Five rather generic processes are defined to describe this service strategy:
Strategy management
Service portfolio management
Financial management
Demand management
Business relationship management
Stage 2: Service Design
The service design stage is used to identify requirements for the service to be provided and can also be used to define new service offerings as well as improving existing services. The following processes are part of stage two:
Design coordination
Service catalog management
Service level management
Risk management
Capacity management
Availability management
IT service continuity management
Information security management
Compliancy management
Architecture management
Supplier management
Stage 3: Service Transition
The service transition stage is used to build and deploy IT services. Traditionally project management and improvements are part of this stage. The following processes are identified with this stage:
Change management
Change evaluation
Project management (transition planning and support)
Application development
Release and deployment management
Service validation and testing
Service asset and configuration management
Knowledge management
Stage 4: Service Operation
The objective of this stage is to make sure IT services are delivered effectively and efficiently. This would include fulfilling user requests, resolving incidents, and fixing problems, as well as executing routine maintenance tasks.
The following processes are defined within this stage:
Event management
Incident management
Request fulfillment
Access management
Problem management
IT operations control
Facilities management
Application management
Technical management
Stage 5: Continual Service Improvement (CSI)
The last stage for an IT service is the concept of continual service improvement (CSI). The purpose of this stage is to identify repeating incidents or problems that can be solved by improving or changing the service (implementation). The following processes are part of this stage:
Service review
Process evaluation
Definition of CSI initiatives
Monitoring of CSI initiatives
Often the ITIL management processes used within operations are defined and documentbased procedures. In other words, there are written steps to take when a specific action (within a process) needs to be executed. Usually these steps also include control points that require a human decision or validation by another team or group of persons.
Intent-Based Networking has some (interesting) cross-sections with different ITIL management processes. For example, the design of network Intent itself can have a strong relationship with the ITIL service definition stage as a whole; however, once a network Intent (service) has been defined, APIs and automation can be leveraged to deliver that service to the customer automatically. There is no written or documented process necessary; once the service is designed and defined, and applications are allowed to request that service and be deployed on the network.
A similar major difference (and strong relationship) can be seen with event and incident management.
Once a service is deployed, the IBN-enabled network uses analytics to detect and possibly autocorrect incidents based on triggered events.
ITIL and IBN are not mutually exclusive strategies; they can support and complement each other. Cisco DNA Center, for example, provides a number of APIs to tightly integrate Cisco DNA Center with IT Service Management (ITSM) tools that are based on ITIL process definitions. A good example of this is the software upgrade workflow within Cisco DNA Center. Once a (new) golden image is selected for a site within Cisco DNA Center, a change request can automatically be created in the ITSM tool. If the ITSM tool replies (via APIs) back to Cisco DNA Center with an approved service window, Cisco DNA Center can automatically deploy, update, and validate the software upgrade in that time window without human intervention, except when an incident is found while upgrading.
In conclusion, the ITIL framework itself is based on a set of best practices and is set around the definition and delivery of IT services. This is a common approach within any IT organization (or IT department within an enterprise). Intent-Based Networking will enforce that certain procedures will be optimized (or removed) and service delivery will improve.
However, with digitization and Intent-Based Networking as an enabler, the clear distinction between IT providing services and business applications/processes consuming an IT service will be removed. This process will in time result in a required revisitation of the ITIL processes as a whole. IBN can be an accelerator to this revisitation.
DevOps
DevOps, the concatenation of Development and Operations, is a methodology that has been driven by software development to be able to deliver new features and functions of an application or service faster to the customer. Within software development, the Agile software development methodology has proven to be very successful in delivering large IT software projects more efficiently and with increased customer satisfaction.
Being able to provide a new version of a software service every two weeks but needing to wait an extra week for operations to deploy that new version into production is counterproductive. As both worlds (development and operations) were increasingly using automation to release software and provision new services, the merger of the two into a single methodology was only logical. (Net)DevOps is in that regard the next logical step for Agile-based organizations, where network operations will be run based on the same Agile methodology.
But the Agile methodology itself (the basis for DevOps) can be applied to operations teams very successfully. The concept of having multidisciplinary teams that execute the work improves the efficiency as the accountability and responsibility are shared by the team. And although an operations team’s primary responsibility is in operating and managing the network, the required work can be categorized into system management work (such as upgrades and changes), responding to incidents, and possibly project work.
One of the characteristics of project work and system management is that the required time can be estimated, in contrast to responding to incidents and problems. And because the work can be estimated and planned, it fits perfectly in the sprint capability within Scrum/Agile. (Sprints were explained in Chapter 2, “Why Change Current Networks? A Need for Change.”)
Responding to incidents and problems is a completely different world with its own dynamics. Incidents and problems happen; they cannot be planned. So resources need to be allocated and made available beforehand to respond to the incidents. Kanban is a methodology (from Lean) that can follow Agile and is perfectly suited for incident response. Incidents are entered into the Kanban queue, and resources will work on the different items and effectively resolve incidents and problems.
To successfully implement Agile (and thus DevOps) into an operations team, it is required that the team be divided into two teams, where the teams alternate between sprints and Kanban work. Basically team one is working on system management tasks, such as regular updates and changes, using the sprints from Scrum/Agile, whereas team two is responding to incidents (if they occur) and assisting team one when required.
By allowing the teams to alternate between sprints and Kanban, there is always one team on incident response while the other team performs planned work. This method is very successful and helps employees keep focus. How often is a planned task delayed because a priority-1 incident occurred? In this method of operation, those types of delays are essentially removed.
This method of operation is very successful, and it is only a matter of time before more network operations teams will work on a similar basis, as DevOps is slowly but surely trickling to network operations as well.
However, DevOps is also based on the “fail fast” concept. In other words, deliver a new feature or function fast, and if it does not work, learn from it and fix it fast (in a next release). This concept provides some significant benefits as customers can see new features, test them, and provide feedback so that the solution can be improved. This is in contrast to more traditional software engineering methodologies such as waterfall.
But this concept is not very applicable to the network infrastructure, as a failure in a network configuration or service can have a dramatic impact on the business (even resulting in a business standstill). So fail fast is not really a success factor for network operations, but rather a risk.
Intent-Based Networking can be used to reduce that risk and still work within the Agile methodology.
In an Intent-enabled network, it is easy to quickly deploy network Intents on the infrastructure. To do so successfully, it is important to have those available Intents thoroughly designed and tested before release.
In that sense, the network Intents have a very large parallel to features within a software application; the Intents are features of the network available to be used.
And with that parallel, the tasks required for designing, developing, and testing network Intents are perfect for a Scrum/Agile methodology leveraging sprint items.
And once the network Intent (feature) is tested and approved, it can be released as a new available Intent and can then be used by applications and operations on the network. Because the Intent is tested, the risk of failure and a big impact to the enterprise is reduced.
In conclusion, the Intent-Based Networking concept fits very well within an Agile-based enterprise and operations team.
Lean
Lean IT is an extension of the Lean manufacturing and Lean service principles. It is focused on the development and management of IT products and services. Lean manufacturing, or simply Lean, was originally created by Toyota to eliminate waste and inefficiency in the manufacturing of cars. Because the principles were successful, many other manufacturers adopted the same principles, and Lean became the de facto standard for manufacturing. For many manufacturers, the adoption of Lean is critical in the competition against low-cost countries.
The ultimate goal of Lean is to eliminate waste, where waste is defined as the non-valueadded components in any process, to maximize customer value. With every iteration of Lean in a process, the waste is reduced by bits and can be eliminated after a number of iterations. The iteration through Lean is defined with five key principles, which need to be executed sequentially.
Five Key Principles
The Lean Enterprise Institute (LEI), founded by James P Womack and Daniel T Jones in 1997, is considered the central location for Lean knowledge, training, and seminars. According to LEI, there are five key principles: value, value stream, flow, pull, and perfection. Figure 13-2 illustrates the flow of these five key principles.
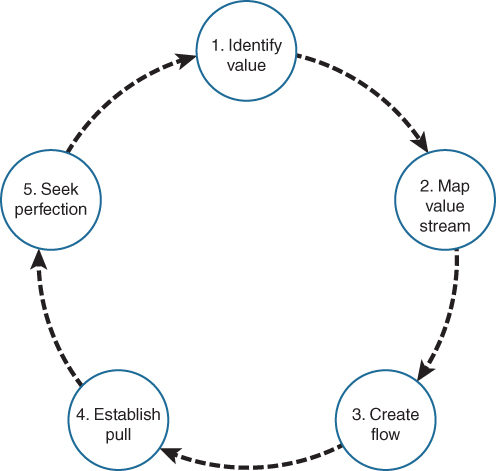
Figure 13-2 Five Key Principles of Lean
The sections that follow describe the five key principles of Lean in more detail.
1. Identify Value
Value is always defined as the customer’s need for a specific product (or in the case of an IT service organization, an IT service). The value itself is not only monetary but also the timeliness of delivery and the quality of the product. What other requirements or expectations does the customer have for a specific product? These types of questions are used to define the value of a product or service. Once value is defined, it is effectively the end goal for the product or service.
2. Map Value Stream
Once the value (and the corresponding end goal) has been defined, the next step is to map the so-called value stream for all the steps and processes that are required and involved to actually define and make the product for the customer.
Value-stream mapping is a simple but often revealing experience that identifies which actions need to be taken to deliver the product. All processes required should be identified, including processes such as procurement, production, administration, HR, and delivery. The concept is to create a one-page map that contains the identified processes and maps out the flow of material/products throughout the process.
The goal is to identify all steps on that map that do not add value to the product and find ways to eliminate those wasteful steps.
3. Create Flow
Once the waste has been removed from the value stream, the next step is to validate whether the product flows through the remaining processes without any delay, interruption, or other bottlenecks. This step might require breaking down silos and making an effort to become cross-functional across all departments to optimize the value and keep the waste out of the process of creating value. This aspect of working across multiple domains and functional levels is one of the most difficult and challenging aspects in any organization, as it touches accountability and responsibility and requires change (of thinking).
However, studies show that overcoming a silo mentality can increase efficiency with double-digit improvement values.
4. Establish Pull
With the improved and optimized workflow to create the product, the time to market (or to consumer) for the mentioned product can also be optimized. This makes it easier to optimize the organization to deliver “just-in-time.” It could literally mean that the customer can “pull” the product from the enterprise as needed, which results in shorter service delivery times (moving these delivery times from months to weeks). As a result of just-in-time delivery, the stock of materials required for the product can then be optimized to reduce the (often) expensive cost of inventory. This results in saving money for both the customer and the manufacturer.
5. Seek Perfection
Steps 1 through 4 already provide a good start and improvement to any production process, but the fifth step is perhaps the most important one: making Lean an integral part of the enterprise and corporate culture. Only when that strive to perfection (removing any waste in providing value) is an integral part of the culture and every employee thinks Lean can the waste be kept to an absolute minimum or ultimately no waste.
Lean can provide very big effects and increase customer satisfaction. Those effects will also fan out to suppliers and partners as they want to generate their own improvements, which will result in improvements for the enterprise too. But bureaucracy and unnecessary actions always lie around the corner, so these five key principles should be iterated frequently so that newly created waste can be removed, and the ultimate goal of providing maximal customer value with minimal waste can be achieved and maintained.
Lean for IT
Lean is originally focused on removing waste in the manufacturing of products and improving the value for customers. But in a sense the IT department within an enterprise, or an IT service company, also provides products, except these products are less tangible as they are focused on services.
Lean IT is an extension to Lean thinking and aims to adopt the framework to IT services. The five key principles are now applied to IT departments (or businesses) and how they provide the IT services to their customer, whether an internal or an external customer.
One of the differences is that the Lean IT extension predefines a set of identified wastes that affect customer satisfaction and service in general (and thus affect the value). Most of these waste types are recognizable within any IT operations team. The following waste types are part of that list and are (very) common within IT. These should be addressed with Lean IT thinking.
Defects: Defects could be unauthorized system and application changes or substandard project execution. This would lead up to poor customer service (and satisfaction) and will increase cost of the service as more time and resources are required to provide the service.
Overproduction: This occurs when IT services are deployed on oversized resources. For example, a branch office for ten Citrix users is provisioned with a 1 Gb WAN link as that is the predefined standard bandwidth for any location. This results in increased business and IT costs.
Waiting: If an application or service provides slow response times, the customer is losing money (because of wait), and the customer satisfaction will be low as the product is not providing the value the customer requires.
Motion (excess): IT operations respond to incidents as firefighters. They respond to an incident and repetitively fix the incident the same way and do not resolve the underlying problem that causes the incidents. This behavior results in reduced customer satisfaction and lost productivity.
Employee knowledge: Perhaps one of the underestimated wastes in any organization is the waste of knowledge. It is quite common that employees on the work floor know where parts of the service or product are not optimized. But ideas and concepts to improve are lost when the information is sent up the hierarchy. And thus the waste remains. Another type of employee knowledge waste occurs when qualified staff executes non-service-related work or when they spend time on mundane and time-consuming repetitive tasks. This results in talent leakage (knowledge is lost) and low job satisfaction, as well as an increase in support and maintenance costs.
The same iteration of the five Lean key principles is executed to identify and remove waste in a service provided by the IT department. The previously mentioned waste types can be used as initiators to optimize request procedures and provide a better experience and service to the customer.
Transforming an IT organization to Lean can be difficult. Many IT organizations are cost focused, have service-level agreements (SLAs) with their customers, and have an internal “production quota” for billable hours. If a problem is found in a service, the primary focus is to restore service as quickly as possible. There is a slim to no chance that the service will be redesigned to prevent the incident from reoccurring.
When Toyota introduced this paradigm in the 1980s, when employees found a quality problem on the production line, they were required to stop the line and fix the problem but also take the time to prevent that quality problem from happening again. That principle is the road to increased quality and perfection.
Within IT service organizations, there is most probably a fear to report these types of quality issues and take a step back to improve the service and quality to the customer as that stop will affect SLAs, affect production quotas, and possibly result in lost revenue. That fear will have a negative impact on customer value and will greatly reduce the chance for maximizing Lean IT thinking potential.
Changing that mindset is difficult as it is also related to how well a business operates in the short term, and (upper) management needs to be aware that Lean IT thinking will have an impact on productivity in the short term to gain in the long term.
In conclusion, Lean itself is not an IT operations framework but more an organizationwide methodology that aims to create the best value for customers. For a network or IT operations department, the best value would be to provide the best IT service with a highly effective and efficient balance between customer needs and available IT resources with a minimum overhead on the service.
Intent-Based Networking is a methodology that fits very well inside the Lean IT thinking methodology. One of the drivers of IBN is that the number of connected devices and services (intents) on a network will increase exponentially, while the operations staff will not be able to follow that same growth pattern. In other words, IBN will result in an increase in efficiency and thus support Lean thinking in the enterprise.
Also, IBN allows business applications to request and consume network Intents automatically, removing waste from the services provided. IBN also allows the operations team to leverage the data gained from operating the network to fix incidents faster and more efficiently, as well as a continuous validation of Intents on the network. That is effectively also a reduction of waste.
For organizations that are fully Lean, IBN is a very good solution to remove waste from the IT services provided within the organization.
Summary of Common Frameworks Within IT Operations
In summary, ITIL and DevOps are probably the most commonly found and applied frameworks within IT operations. And although Lean IT might not be that common within IT operations, it is a method of thinking that has a lot of traction within enterprises.
There are, of course, many other frameworks available that can be used to describe how to manage and organize the IT operations team. Other common frameworks within IT are the ISO standards (ISO 20000 describes the standard for IT Service Management, and ISO 19770 describes asset management), whereas the Six Sigma for process improvement and PRINCE2 for project management with the goal to deliver projects with minimal risk, and too many other frameworks to mention as well.
All these frameworks have in common that they describe a model or abstract of the enterprise using processes and sequential steps; they are process-oriented. The identification of processes is used to abstract complexity as well as to introduce the demarcation of responsibility. Also, in these frameworks, the processes are defined and executed sequentially to keep focus and clarity.
However, the implementation of an Intent-Based Network will over time have an impact on those frameworks as the operation of the network is changed and will not adhere to those frameworks.
The biggest example is how changes occur on the network. Traditionally, changes require the submission of a change request that follows a (strict) change procedure. That change procedure attempts to assess the risk and impact and provides an approval or denial for that change. Often that decision is made by a change advisory board that meets once or twice a week.
But with an Intent-enabled network, an application can request a new network Intent via an API and get that Intent automatically deployed on the network. In essence, the application is performing a change on the network without following the paper-based change procedure.
There are other differences between IBN and these frameworks, such as the design of a network infrastructure. If IT operations are strictly organized around these frameworks, they will effectively block a successful implementation of IBN. Some parts of IT operations need to be changed to fully enable IBN.
Potential Conflicts and Recommendations
For those enterprises that have organized and implemented their IT operations around these common frameworks, the implementation of IBN will create potential conflicts within the IT department and the network operations team. As each enterprise is different, the impact of that conflict will vary as well. A complete list of conflicts between IBN and all frameworks is impossible to provide; however, a number of recommended changes in IT operations can be described and motivated. The section that follows describes the causes of potential conflicts and provides some recommendations to overcome these.
Common Design Patterns Change
One of the most common approaches to IT operations in general is a sequential approach. A problem is identified, the requirements are identified, a solution is designed, and then the solution is implemented and managed. This approach is so common that many frameworks and project steps take a similar approach.
Thus the organization (and operation) is defined in a similar approach, where designers and architects listen to the business. They identify the problem, determine the requirements, and design a solution. Network engineering will then implement the solution, and operations will in turn operate that solution. Often new networks are designed and implemented in this manner to solve new functional requirements as the existing network cannot be matched to these new requirements.
The approach in IBN is quite different. With an Intent-enabled network, there is a common existing underlying network infrastructure upon which Intents need to be designed and implemented. So instead of designing a new network, the designer needs to define the solution as part of the existing network, but it needs to be designed in such a way that it is easy to deploy and remove the Intent from the network. Designers need to change their design patterns and consider not only the deployment of the Intent, but also the removal. All network Intents must be designed as service blocks that can easily be reused.
There will, of course, be times when the organization wants to have an Intent-enabled network in a greenfield situation. In that case, the network architect or designer should focus on creating a minimalistic underlay network upon which a diverse variety of Intents are possible. The traditional limitations of designing a network for a single purpose or focusing on a single problem are not applicable; instead, the basic underlay network must be designed in such a way that it can facilitate for that single problem and for other Intents that are to be deployed on the network. In this situation (where a new Intent-Based Network needs to be designed), the network architect should not only look at the new required network infrastructure but also services and applications running on the network.
Management by Exception
The IT operations team (specifically the network operations team) is responsible for the proper operation and management of the network infrastructure. Traditionally, the network operations team is in control of the network and its configuration. Best practices and validated designs are used to guarantee that the configuration and operation of the network are as optimal as possible. Often the operations team will state that it can only be responsible (and accountable) for the network if it has full control and operation of the network. Every change on the network must be under the auspices and approval of the operations team.
In principle, the operations team is somewhat correct. To take responsibility, there needs to be control; however, with IBN, the control of the network configuration is split between the operations team and any application or business process that is allowed to request and remove Intents on the network. When this functionality is enabled (key component of IBN), the absolute control of the network is effectively given out of hand. That aspect will be a driver for fear and resistance from the operations team to share control with an external entity, as the operations team remains responsible and accountable.
This fear and risk of losing control is mitigated by leveraging two paradigms and changing the way responsibility is organized and documented.
To restrict the number of allowed changes on the network and prevent chaos on the Intents, only approved and tested Intents are allowed on the network (quite possibly with a limitation). In other words, the network operations team will define, in collaboration with network designers and architects, which Intents can be requested and deployed. These Intents must, of course, be well defined, well designed, and properly tested in a lab environment. Part of the requirements will be that a single Intent cannot interfere with other Intents.
This process will initially limit the number of available Intents, but it will also provide control back to the operations team because it controls which Intents can be provided as a service.
The other paradigm is called management by exception. Management by exception has both a general business application and a business intelligence application. Its principle is common in industries where the flow of information or the flow of goods is so complex that managing them individually is impossible. The basic principle of management by exception is the assumption that the generic process itself is well-defined and that 99% of the flow is going according to the process and plan. Specific tools, metrics, and procedures are defined that are activated in case something goes wrong. The performance of the actual operation would continuously be validated against the expected metrics, and if a deviation is found, the focus will be on that deviation.
Another example of management by exception is within logistics, where the amount of goods being transported is so high that it is impossible for public safety organizations to inspect every item being transported. Instead, they rely on profiling and smart usage of data to identify potentially interesting transports and will inspect them.
Sales organizations could rely on that same principle where the metrics are based on the number of units sold and the average selling price. If a single product underperforms in a quarter, management is informed and appropriate action can be determined and executed.
This approach is also common within IT for service monitoring in combination with SLAs. A probe periodically validates the performance of an application; if the performance is outside the allowed bandwidth, it will be reported and acted on.
This management by exception principle is actually an integral part of an Intent-Based Network. The tooling within an Intent-Based Network continually validates the successful operation of the requested Intents, and if an Intent is not performing as expected, the operations team is informed. In other words, an IBN has, by design, implemented the management by exception paradigm. It is important that the operations team is made aware of this concept and embraces that principle because the exponential growth of devices connecting to the network will make classical full control management impossible to maintain.
Work Cross-Domain
In a digitalized enterprise, business and IT are becoming aligned, and technology will support and drive business process changes. Part of that aspect is that business and IT need to understand each other. IBN is an enabler for the digitalization. IBN allows network Intents to be deployed onto the network, but IT is not only the network. It also comprises compute, storage, cloud, security, and application development.
It is common for organizations to organize their departments and processes around these different domains and fields of expertise. In other words, a dedicated team is responsible for server management, whereas a different team is responsible for workspace management. Although this is good for the organization of responsibility, it is bad for customer experience and innovation as they are essentially silos. One of the things that DevOps/Scrum Agile has shown is that with multidisciplinary teams, a much better valued software program is created, as the different experts work together to implement a specific feature.
Intent-Based Networking dictates a similar approach. The network enables connectivity for the applications and services of the enterprise, but the intents need to be defined and designed based upon the requirements of the business, and they need to be aligned with the other IT expertise fields.
It is therefore recommended to open up as a network infrastructure team, and when defining intents, work across domain with all expertise areas, including the customer (business process) to define a network intent that truly creates value for the business.
Organizational Change
In conclusion, the existing (control) frameworks used within businesses to organize IT services and operations will generate conflicts of interest with Intent-Based Networking and the digitization process in general. To solve these conflicts, deviations fromwell-known and familiar processes and responsibilities need to be defined. These deviations will in turn force a change in how IT operations manages their responsibility and provides services.
It also means that the organization is consciously deviating from the existing frameworks, which will have consequences for businesses that are being audited. Therefore, these deviations need to be validated and documented.
It is only logical that as IBN changes the way a network is designed and operated, IT operations needs to follow, and over time the frameworks will follow suit. But changing operational processes is challenging and complex. However, these changes are required for IBN; therefore, it is important to have commitment from management.
Summary
IBN is the next evolution of networking. It describes a way to operate and manage the network to be able to cope with the external changes, such as the exponential growth of connecting devices and the digitization of businesses.
Traditionally, IT operations teams are organized around a number of well-known common frameworks. These frameworks typically take a process-oriented and sequential approach on how to manage, operate, and improve IT services.
As IBN takes a new approach on how the network is operated, it is very well possible that IBN will conflict with some of these common frameworks.
A good example of such a conflict is the change request procedure. In traditional environments, a change request is registered in an IT Service Management (ITSM) tool and follows a (strict) change procedure where the impact and scope of change are determined, and a change advisory board decides whether the change is approved or denied.
These procedures usually take time from both the IT operations team as well as employees who have a seat on the change advisory board (which probably only meets once or twice a week). And although the principle behind it is to prevent major incidents, the change itself takes time.
With IBN, an application can use an API call to the network controller to remove an existing intent from the network, which results in changes in the network configuration. The application bypasses the change procedure to get its intent enabled or removed.
So although these frameworks aim to provide better service quality, improve customer experience, and provide a faster delivery time, parts of processes around the design and operation of the network will need to be changed and accepted. With the preceding example, if the API call were placed on hold until the change advisory board approved it, then where would the gain of faster deployment be? As with every change, small steps provide the best chance of success.
If the organization has a strong ITIL-based process organization and the business adheres strongly to those processes, there will be no room for change, and the chance of a successful IBN implementation would be reduced. But if the organization is open to improvement (for example, via the Lean thinking principles or the introduction of Agile), then the chance of successfully changing the processes that involve IBN is much higher.
In conclusion, IBN will also force and drive change in the organization’s processes and responsibilities. This need for change will create conflicting interests within frameworks commonly used by organizations to define and manage their IT environment. Conflicts of interest could arise, and you need to be aware of these.
Common Design Pattern Change
Traditionally, enterprises follow a sequential pattern to solve a problem or define a new service. The problem is defined, its requirements and limitations are documented, and a designer creates a solution to that problem. Once the solution is designed, engineering implements the solution, and operations manages it.
In the case of a network, it is relatively common that a complete new network design is created because the old network design does not fit all the requirements, or possibly the engineering heart plays up, and new technology is required.
But with IBN, newly requested network intents are dynamically deployed on the network; in other words, there is a common network infrastructure that carries the required intents. The consequence is that the design of new network functions needs to take into account the existing Intent-Based Network, and the solution must be based on a small service that can easily be deployed and removed on that Intent-Enabled Network.
In other words, designers need to start designing in small microservices on the network instead of a (large) new network where the key design principles of DNA and concepts of IBN are leveraged.
Another design pattern change is when a complete new network, such as for a new plant or warehouse, needs to be designed. In that case, the network designer should design a minimal baseline network infrastructure with the microservices on top that will match with the requirements set for that new network. The designer needs to be aware that other services, possibly unknown to him, can be added and removed dynamically.
Management by Exception
A business is organized around the aspect of responsibility and accountability. As a business grows, departments are created to delegate and split responsibility and accountability among these departments. Most IT frameworks take the same approach. It is common that accountability and responsibility can only be provided if the team has full control of the process. In other words, many network operations teams claim that they can only be held responsible for the network if they have full control over it.
But with IBN, part of that control is delegated to (business) applications and processes that can add and remove intents on that network. Some control is being lifted, so how can the operations team still remain in control?
Besides the fact that any allowed intent should have been thoroughly tested in a lab before being enabled on the network, a mental shift in thinking about responsibility is required. There should be a mental shift from management by control to management by exception. Management by exception has both a general business application and a business intelligence application. Its concept is common in industries and markets where the high volume of data or goods makes a control-based management concept impossible. This concept assumes that in general the process is working and operating as expected, and if something is out of order, an exception is generated and handled.
A good example is the Rotterdam harbor. They handled 8,635,782 containers in 2018,1 which averages to 23,660 containers per day. Because as it is common to have multiple types of goods and transports inside a single container, it is impossible for authorities to inspect every individual item. Instead, the assumption is that everybody follows the normal procedures and pays their import duties. Profiling is used to find exceptions to the process, and those containers will be inspected.
1 Source: https://www.portofrotterdam.com/sites/default/files/overslag-havenbedrijf-rotterdam-2018.pdf or https://www.portofrotterdam.com/en/our-port/facts-and-figures/facts-figures-about-the-port/throughput
Although the concept is not known as management by exception within networking, network monitoring systems actually take the same approach. They assume that the network is operating correctly, and probes are used to validate this assumption. If an error is found, an alert is generated so the operations team can take appropriate actions.
Management by exception is actually an integral part of IBN. The tools used for IBN continuously validate whether the intents are operating correctly on the network and actively report the event to the operations team. Machine intelligence assists to determine whether the exception needs to be aggregated to a site-wide problem.
This concept should also be applied to the way the network operations teams view the network and can still take responsibility by leveraging the assumption that all flows are working correctly, unless monitoring states otherwise.
Cross Domain
It is common for businesses to organize their teams and processes around specific knowledge (technology) domains; for example, a dedicated team is responsible for server management, a different team is responsible for network security, another for application management, and so on. Although this is good from a responsibility (and control) perspective, it is bad for customer experience, as these domains are essentially silos. Silos are proven not to provide the best customer experience or best service. One of the success factors of Scrum/Agile (and DevOps) is the power of multidisciplinary teams that jointly work on problems and incidents. It has proven to provide a more customer-focused solution and increases efficiency as well.
IBN dictates a similar approach. The network is the connecting factor between endpoints and application services. And the necessary intents on that network are defined and built upon business requirements and needs at that moment. As the connecting factor, that intent needs to be aligned with other IT expertise fields as well to provide a consistent experience and service to the business.
It is therefore recommended to open up as a network infrastructure team, and when defining intents, work across domains with all expertise areas, including the customer (business process) to define a network intent that truly creates value for the business.
Organizational Change
The organization will change because of IBN. That change is required to fully maximize the capabilities of IBN and prepare for the next steps in the evolution of technology.
This organizational change means that the organization will deviate from existing frameworks and suggested methods of operation to define new ways, just as with digitization. Most frameworks approve of that type of deviation, as long as its arguments are documented.
But many organizations that follow these frameworks often follow it by the letter instead of using the best practices specific for their organization (due to lack of understanding or lack of faith in their own organization’s capabilities). Consequently, auditors can have comments on those deviations. It is recommended to not only keep commitment from management for those changes but also document them and change the documented procedures, including arguments for why the change was made.
Without that type of documentation and commitment, there is a risk the change needs to be rolled back because of an auditor who is not aware of IBN.