
CHAPTER 5. Protecting the Network: Preventative Maintenance Techniques
SOME OF THE MAIN TOPICS IN THIS CHAPTER ARE
Power Conditioning and Uninterruptible Power Supplies (UPSs) 58
Server and Workstation Backups 62
Building Redundancy into the Network 68
Justifying Preventative Maintenance 69
This chapter looks at some important preventive maintenance ideas to consider employing in your network. The size and composition of your network will determine which of the ideas in this chapter you should use. Not all are appropriate for every network. Some are prohibitively expensive for smaller networks. Yet it is important to be aware of the possibilities so that as your network grows and you plan for upgrades, you also can make plans for additional procedures and devices that can protect the growing network from downtime and preserve your valuable data.
Power Conditioning and Uninterruptible Power Supplies (UPSs)
Without electricity, you have no network at all, and computers require a well-conditioned electrical source to function properly. The power supply in a computer can’t handle an incoming spike of electricity caused by a lightning strike, for example. Similarly, a brownout, in which the voltage level drops for a short period, can cause a computer to crash.
Large-scale computer systems used in corporate environments, such as minicomputers or mainframes, also need a good source of power. To ensure this, most large computer rooms use a heavy-duty UPS to interface between the outside source of electricity and the computers and other devices in a computer room.
In most large computer rooms, for example, you’ll find that computers—whether they’re PC servers or larger systems—are rack-mounted in cabinets, along with tape drives, disk drives, and other peripheral equipment. The cabinet usually contains one or more power distribution units (also known as PDUs) that are used to supply power to components mounted in the cabinet (see Figure 5.1).
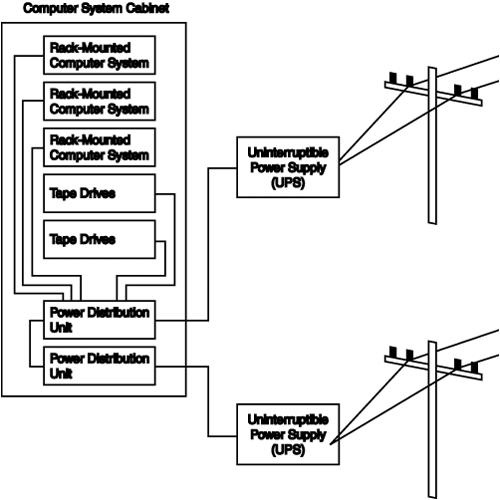
Figure 5.1. Several points in the power supply can be constructed to prevent a single point of failure for powering the network.
As you can see from this figure, several computer systems and the tape drives they use are housed in a single cabinet. Two power distribution units located at the bottom of the cabinet supply power to all devices in the cabinet. These two power distribution units are configured in a dual-redundant manner so that if one fails the other continues to supply power to the cabinet. Each of these power distribution units is connected to a separate UPS in the computer room. This is important for several reasons. First, not all power failures are due to outside problems, such as a downed power line. Sometimes, UPSs themselves fail. An electrician might disconnect the wrong cable during routine maintenance or installation tasks. A mouse could chew into the wires, causing a short. Sometimes, things just happen. You need to prepare for the unexpected.
To carry the concept further, each UPS in the computer room that the system uses is connected to a separate outside source of power. Thus, if a tree falls and knocks down a power line, an alternative power line is still feeding electricity into the computer room to redundant UPS systems. Because of this second source of power, computers and other devices on the network stay up and running.
Power Is Money
There is an old saying that “money is power.” The opposite also is true.
The setup described in the preceding section might seem extreme to a network administrator running a small network of PCs in which some downtime can be tolerated. However, in a high-availability computer environment—such as in a large corporation—the cost of downtime can be prohibitively expensive for several reasons:
![]() Hundreds or maybe thousands of employees remain idle while the computers they use are down. Employees are still being paid even though they can’t work. Add up the dollars and you’ll see that each minute of downtime is expensive.
Hundreds or maybe thousands of employees remain idle while the computers they use are down. Employees are still being paid even though they can’t work. Add up the dollars and you’ll see that each minute of downtime is expensive.
![]() Customers might be unable to place orders or check on the status of existing orders. Fickle customers might just call someone else. No one likes to hear, “Our computer is down right now; please call back later.” After your customer talks to another supplier, you might never hear from that customer again. So you lose the current order, and possibly future business.
Customers might be unable to place orders or check on the status of existing orders. Fickle customers might just call someone else. No one likes to hear, “Our computer is down right now; please call back later.” After your customer talks to another supplier, you might never hear from that customer again. So you lose the current order, and possibly future business.
![]() An unexpected system crash due to a power failure can cause corruption to data. After the power is restored, it can sometimes take hours (or even days) to determine which files are corrupted and then restore them to a known state from backup tapes. Many large networks, such as those operated by Internet Service Providers, now measure data in terabytes. Restoring an entire database can be very expensive and time-consuming. This additional downtime can potentially be more costly than the original power outage that caused it.
An unexpected system crash due to a power failure can cause corruption to data. After the power is restored, it can sometimes take hours (or even days) to determine which files are corrupted and then restore them to a known state from backup tapes. Many large networks, such as those operated by Internet Service Providers, now measure data in terabytes. Restoring an entire database can be very expensive and time-consuming. This additional downtime can potentially be more costly than the original power outage that caused it.
If you operate in a large-scale environment like this, you are probably already aware of how important it is to keep computer systems up and running. If you don’t provide a steady, secure source of power up front, all your other preventive maintenance measures might prove of little value the next time the power goes out.
A UPS is not an eternal source of power. It is a conduit through which your external power source is routed before it gets to your computer systems. UPSs operate by storing electricity in one or more batteries so that when the outside source of electricity is unexpectedly lost, the batteries can be switched into use in a few milliseconds. However, batteries can be used only for a limited amount of time. If you are using only a single UPS connected to a single power source, the UPS buys you the time needed to notify users to log off the systems affected and gracefully shut down the computers so that no data is compromised. Although you’ll still have idle employees, you won’t have to recover data after power has been restored.
For a large network consider planning for power outages one step further: Diesel generators. Although these would be too expensive to keep a large number of desktop users working, they can be used to keep servers up so that you can relocate users to a disaster recovery site that has been set up in advance to give users a temporary workplace. For example, in most situations not all network applications are critical and require 24/7 uptime. Thus, you should provide backup power systems for servers that are critical. If your operation is a retail one, for example, you would want to keep servers running that interface with your customers—such as your Web site. Other applications, such as word processing for the legal department, and other job functions that can wait can be recovered later.
Advanced Configuration and Power Interface (ACPI) and Standalone UPS Systems
For PCs and small servers, you can buy inexpensive UPS systems for a few hundred dollars that can be used in an environment in which downtime can be tolerated but data corruption cannot. A typical UPS, such as one from American Power Conversion Corp. (APC), can be installed in just a few minutes. Depending on the model, it can provide both a battery backup and some power conditioning.
Be aware that surge protectors, even those that claim to be able to prevent power spikes from getting through, don’t always work as the manufacturer claims. The inexpensive models you buy at local discount stores are notorious for not providing the protection they claim to provide. If you depend on the simple mechanics of a fuse or breaker in a cheap surge protector to protect your computer, also plan on buying a new computer the next time lightning strikes. If you don’t use a large-scale UPS, then for true protection, you need to spend the extra hundred dollars to get a small UPS for your server or other network devices.
Tip
Keep in mind that all hardware connected to your computer must be protected against surges and such. If your computer is connected to a surge-protecting UPS, but your monitor and cable modem are plugged directly into the wall, and then into your computer, a surge could still travel from the wall to the monitor to the computer. In a SOHO environment with cable Internet, if lightning hits your outside cable TV/Internet box, the power surge could get through the cable from the wall to the cable modem to the computer. In other words, if any hardware component is connected in any way to your computer, use UPS or surge-protected connections for each and every device.
To allow you to gracefully shut down the operating system when the power goes out and the batteries take over, an industry initiative (involving major players such as Intel, Microsoft, and others) developed the Advanced Configuration and Power Interface (ACPI). ACPI covers a lot of territory, including power management for laptops and other computers. However, ACPI also allows a standard way for a standalone UPS to communicate with a computer and instruct it to shut down when the UPS battery supply takes over from the outside source of electricity.
Note
You can visit the ACPI Web site using the URL http://acpi.info to get more information about specifications and other information about how ACPI interacts with the BIOS code for computers. You will also find here a selection of tools, including tools (such as compilers) that use the ACPI Source Language, which is used to create the firmware code used on your computer’s motherboard. This is not light reading but is suggested for those who like to dig into the details to “find out how things work.” There is also a disassembler you can use to turn the firmware’s machine language code back to ASL to make existing code easier to read. ACPI is also being adopted into Linux-based computers. Learn more at http://acpi.sourceforge.net/.
ACPI is not limited to just external UPS devices. The specification also includes other power-management capabilities that are standard for the major operating systems today. For example, if you open the Power Options icon in the Windows 2000/XP/2003 Control Panel, the settings that can be enabled or disabled there interact with ACPI. Another interesting feature of ACPI is the capability to restart your computer by simply pressing a key.
This communication is accomplished by connecting the power cable from the computer to the power UPS, and also attaching a specially-designed serial or standard USB cable to the UPS and the computer system, and then enabling the UPS service in the operating system. Windows 2000 and Windows 2003 servers have a UPS service you can run in conjunction with an attached UPS that supports ACPI. You’ll even find this service in Windows 2000 Professional as well as Windows XP, and some Linux/Unix systems. The UPS communicates with the service and instructs the system to perform an orderly shutdown when the loss of power is detected and the batteries take over. Things to look for in a small UPS include the following:
![]() Audible alarms—I remember waking up to an alarm from my UPS several years ago to find out I was sleeping through a hurricane. Glad I had that UPS hooked up. Saved the computer; saved me.
Audible alarms—I remember waking up to an alarm from my UPS several years ago to find out I was sleeping through a hurricane. Glad I had that UPS hooked up. Saved the computer; saved me.
![]() Multiple outlets—Most small UPSs allow you to connect two to four devices to the unit so that you don’t have to buy one for your computer, one for your printer, one for your router, and so on. This feature can be useful in a Small Office/Home Office (SOHO) environment where the devices that need protection are in close proximity. In addition, look for a UPS that offers connections for other important devices, such as your broadband connection or other network interface, and a phone line, among other items that are connected to your computer. Keep in mind that some UPS outlets provide surge protection only. The printer and other non-essential devices should be connected to surge-only outlets on the UPS.
Multiple outlets—Most small UPSs allow you to connect two to four devices to the unit so that you don’t have to buy one for your computer, one for your printer, one for your router, and so on. This feature can be useful in a Small Office/Home Office (SOHO) environment where the devices that need protection are in close proximity. In addition, look for a UPS that offers connections for other important devices, such as your broadband connection or other network interface, and a phone line, among other items that are connected to your computer. Keep in mind that some UPS outlets provide surge protection only. The printer and other non-essential devices should be connected to surge-only outlets on the UPS.
![]() Battery indicators—Be sure the UPS provides some mechanism (usually an indicator light) for notifying you when the battery is fully charged or is charging. Batteries (and UPSs) don’t last forever. Additionally, an indicator light should let you know whether the unit is powering your system by battery power or the outside source.
Battery indicators—Be sure the UPS provides some mechanism (usually an indicator light) for notifying you when the battery is fully charged or is charging. Batteries (and UPSs) don’t last forever. Additionally, an indicator light should let you know whether the unit is powering your system by battery power or the outside source.
![]() Overload indicator—Even though multiple outlets are available on a UPS, it might not be capable of supplying sufficient power to the devices you plug into it. A good UPS will indicate (again, usually with a light) that you are straining the UPS to its limit. In such a case, you’ll need more than one UPS. The documentation that accompanies the UPS should indicate the amount of current it can supply. Documentation for computers and peripheral devices likewise should contain information about the power they consume. Do the calculations to ensure that the UPS is sufficient for your needs.
Overload indicator—Even though multiple outlets are available on a UPS, it might not be capable of supplying sufficient power to the devices you plug into it. A good UPS will indicate (again, usually with a light) that you are straining the UPS to its limit. In such a case, you’ll need more than one UPS. The documentation that accompanies the UPS should indicate the amount of current it can supply. Documentation for computers and peripheral devices likewise should contain information about the power they consume. Do the calculations to ensure that the UPS is sufficient for your needs.
![]() Circuit breaker—If you choose to ignore an overload indicator, the UPS should be equipped with a circuit breaker, usually a small button that can be reset, to disconnect itself from the outside power source if you continue to attempt to pull more power through the unit than it can tolerate. When the UPS finds itself at risk, it can trip the breaker, use the battery for a power source, and then instruct your computer to shut down.
Circuit breaker—If you choose to ignore an overload indicator, the UPS should be equipped with a circuit breaker, usually a small button that can be reset, to disconnect itself from the outside power source if you continue to attempt to pull more power through the unit than it can tolerate. When the UPS finds itself at risk, it can trip the breaker, use the battery for a power source, and then instruct your computer to shut down.
Although a large number of vendors manufacture and sell small UPS systems of this type, the Web site for American Power Conversion Corp. (www.apcc.com) has information (including documentation) for products that scale from the desktop to full-fledged computer-room UPS systems.
As with surge suppression, when making a purchasing decision about a UPS system, you generally get what you pay for. Balance the cost of the unit with what it would cost you to replace the devices you are going to use it to protect, as well as the cost of downtime, data corruption, and so on.
Network Devices
UPS systems aren’t just for computers. After all, this book is about networking. Don’t forget the routers, switches, and other devices in your network. Although it might be acceptable to let a printer be offline for a while during a power problem, it won’t matter whether your computers are up and running if users can’t access them through the network. In a large computer room, routers and other such devices should be connected to outlets in the UPS that provide battery backup. In a small office or home-office environment, don’t forget to connect your broadband switch/router and your cable, DSL, or satellite modem to the UPS just as you do your computer.
Network Monitoring
The Simple Network Management Protocol (SNMP) and Remote Monitoring (RMON) protocol are powerful tools that can be used to manage a medium to large network. In a small LAN, such as in a home office, these capabilities are not needed. If a device such as a cable/DSL modem or router is not working, you will probably be able to determine that quickly. This applies also to your printer (it has run out of toner or ink), and your computer(s) (it hangs or crashes). However, when a network is spread out over a large geographical area, or when a large number of network devices and computers are on the network, these two protocols can be used with management consoles to help you diagnose problems remotely and gather statistical information about your network. SNMP and RMON also can help you spot trouble before it becomes a real problem.
SNMP basically collects data about computers and other devices on the network, and is used with a management console application to provide a central reporting station. RMON is similar to SNMP but supports additional features, especially on the remote devices. By choosing a good management station application, you can set up thresholds for certain events (such as network traffic, errors, and other statistical information) so that automatic alerts are issued to warn you when something is amiss.
![]() SNMP and RMON are covered in greater detail in Chapter 49, “Network Testing and Analysis Tools.” If you manage a large network, the central network management application that you use (such as HP OpenView or IBM’s Tivoli suite of products) uses these protocols to obtain information from networked devices or, in the case of RMON, to set variables in the Management Information Base (MIB) of these devices.
SNMP and RMON are covered in greater detail in Chapter 49, “Network Testing and Analysis Tools.” If you manage a large network, the central network management application that you use (such as HP OpenView or IBM’s Tivoli suite of products) uses these protocols to obtain information from networked devices or, in the case of RMON, to set variables in the Management Information Base (MIB) of these devices.
Server and Workstation Backups
Did you ever lose your address book? Did you have another copy? If you use a PDA or a laptop instead, let’s rephrase the question: Did you ever lose the data on your PC? Did you have a backup? Trivial as it might seem, this is about the most important point to be made in this chapter.
Nothing will save your neck more often than a good backup of all computer systems in your network. It doesn’t matter whether you’ve spent hundreds of thousands of dollars (or even millions) getting state-of-the art RAID (Redundant Array of Independent Disk) disk arrays that have multiple copies of data stored on separate disks. Many financial institutions even have online mirroring of data between distant geographical sites to prevent a natural disaster from causing loss of data. However, no matter how well you prepare your online storage to be fully redundant, there are other reasons you should establish a good schedule of regular backups of all important data on the computer systems in your network.
For example, even if you use disk mirroring and other RAID techniques, what are you going to do if a meteor falls out of the sky and lands on your computer room? Boom! There go all your computers, your data, and, of course, a few operators. You can replace the computers and the operators (with a little training, of course), but can you replace the data?
![]() There is one other technology that can help you out when entire storage systems fail at your local site. Storage Area Networks (SANs) can be used to replicate data between sites that are located several miles away. You can also connect SANs over much longer geographical distances (from coast to coast) by channeling the SAN traffic through standard long-haul protocols such as ATM or Frame Relay. For more information about SANs, see Chapter 11.
There is one other technology that can help you out when entire storage systems fail at your local site. Storage Area Networks (SANs) can be used to replicate data between sites that are located several miles away. You can also connect SANs over much longer geographical distances (from coast to coast) by channeling the SAN traffic through standard long-haul protocols such as ATM or Frame Relay. For more information about SANs, see Chapter 11.
For a more practical reason to perform frequent, regular backups, just think of your users. When was the last time a user deleted a file (or worse yet, a directory of files) and asked you to restore it? Backups can protect you from more than just computer failures and natural or unnatural disasters—do you really trust all of your employees? Bad mistake. As the old saying goes, trust everyone but cut the cards first. In a large organization it’s difficult to keep all employees happy. Some studies have shown that most of the damage inflicted on individual computers or networks is an “inside job.” You need to protect your network from both internal and external problem sources.
Nothing can substitute for a good backup, short of a new job (job security tends to drop some if you lose months of corporate data or even a single day’s worth, depending on your industry).
Backup Media—Tape, Optical Storage, and Hard Disk
The standard mechanism used by most sites to create backups of computer data is magnetic tape. You’ll find all sorts of tape backup devices, ranging from Travan cartridges to the more modern high-capacity Digital Linear Tape (DLT) cartridges. You might even still see the old-fashioned, reel-to-reel nine-track tape in some installation. However, you should choose the backup media based on several things:
![]() Is the backup needed for the short or long term?
Is the backup needed for the short or long term?
![]() If a restore is necessary, can the backup media perform up to your expectations?
If a restore is necessary, can the backup media perform up to your expectations?
![]() How expensive is the backup media?
How expensive is the backup media?
![]() Do you need to exchange data with other sites, such as companies that provide a disaster recovery hot site?
Do you need to exchange data with other sites, such as companies that provide a disaster recovery hot site?
If you have data that is transient and you only need to recover your systems to a known state that doesn’t go far back in time, you can use many kinds of backup media. Most likely, your choice will depend on the speed at which you want to create backups and the speed at which the data can be restored. In this case, tape is probably your best choice. High-speed magnetic tape solutions are available that can back up and restore many gigabytes per hour. Magnetic tape also is good for short-term to long-term storage, provided it is cared for properly as specified by its manufacturer. However, for long-term storage, be sure to pick media that can be used in standard devices. For example, nine-track tapes were used for a long time as the standard in the industry for computer backups. However, if you are required to keep backups for several years due to regulatory requirements, for example, be sure to also keep around tape drives that can be used to read back the data stored on those tapes.
Note
At one of my jobs, I once watched the company spend a large sum of money to transfer a large stock of old nine-track tapes to more modern DLT media. Occasionally, a tape was found that was unreadable; however, most of the data was recovered and is now sitting in storage awaiting the next expensive conversion. Government regulations!
For long-term storage, you really don’t have much choice because technology is changing so fast. However, be sure to look for a backup technology that is from a reliable manufacturer, whom you expect to be in business for a few years to come.
In an emergency, the amount of time required to restore data from a backup can be more important than the amount of time it takes to create the backup in the first place.
For example, it might be possible to break a mirror set cleanly, use one of the mirrored disks to create a backup, and then re-create the mirror set using the software provided by your RAID subsystem. This allows your users to continue using the system with minimal interference from the backup process. If you use a disk-mirroring setup that uses three or more mirrored disks for each mirror set, you can still provide for fault-tolerance while the backup is being produced because multiple disks in the system contain copies of the current data.
Restoring data to a RAID subsystem might take longer than the backup, or it might proceed along at the same rapid pace, depending on the disk controllers, device firmware, and other factors. When choosing a backup solution, don’t forget that you need to consider the opposite of the backup: the restore. You might purchase a high-tech, whiz-bang disk subsystem that supports many different levels of RAID techniques, including online backup. However, if restoring data to multiple disks takes significantly longer than restoring to a single disk, you might want to consider an alternative solution.
In case the absolute worst thing that can happen happens—your site is down, not just the computers, due to some disaster such as a fire—you must be sure that the backup media you have is compatible with the equipment you will use in a disaster-recovery scenario. This is easy to overlook when shopping around for an off-site, hot-site provider. In this kind of situation, don’t take the vendor’s word for it. Test it. Take your backup tapes to the hot site and perform a restore. Time the restore. Be sure the media you are using is compatible with the hot site, and be sure the tape drives (or other media drives) are fast enough to get you back up and running in a short time.
Magnetic tape is not the only backup method available today. You’ll find a wide assortment of media, from magneto-optical discs to recordable CDs and DVDs. The problem with recordable (and rewritable) CDs and DVDs is that they are still extremely slow (even if you have one of the faster drives) when compared to the speed at which magnetic tape can be used, for both the backup and the restore process. That said, recordable CD and DVD technology offers a rather inexpensive method for backing up a small computer system used in a SOHO environment. Because hard disk drives are measured in units of gigabytes, and CD-R discs in megabytes, you should consider recordable CD technology only for situations such as a small office or home office in which you just need to put a small amount of data in offline storage for backup purposes. Recordable DVDs, however, offer 4.7 gigabytes (single-layer) or 8.5 gigabytes (double-layer) per disc, which makes them very suitable for larger backup jobs (though not for full hard-disk backups, for which tape drives remain the most ideal solution).
When using rewritable (RW) discs for backup purposes, you’re utilizing a medium that can be added to, erased, and reused. You can do this with many of the popular CD and DVD-burner software packages on the market today (Nero Ultra Edition, Easy Media Creator, and so on). Microsoft Windows XP and Vista also include CD-burning technology built into the operating system. Note, however, that the software incorporated into Windows XP is not as easy to use as some third-party applications and, more significantly, does not support DVD media (DVD drives are handled as if they were CD-RW drives). With dual-layer (DL) rewritable DVD drives now available for under $100, it’s easy and inexpensive to upgrade systems with CD-RW or single-layer rewritable DVD drives to the latest technology. Keep in mind that rewritable DVD drives also work with CD-R and CD-RW media and some rewritable DVD drives include backup software.
One of the fastest growing means of backing up data is the external hard disk. Many vendors make external hard disk drives that connect to a system via USB 2.0 or IEEE-1394a ports (some drives offer both interfaces). The newest external drives offer capacities up to 500GB, and most include backup software. Some even feature a one-touch system that automatically runs a backup at the touch of a button on the backup drive. By making backups with an external hard disk and then transferring older backups to DL DVD media, you have a solution for fast frequent backups and long-term storage of older data.
Backup Rotation Schedules
When you create backups, first determine what data needs to be backed up and how long it must be accessible for restore purposes. If you have a volatile environment in which data older than a few weeks or months is no longer of use, you won’t need to keep tapes or other media in long-term storage. However, for most companies, it’s important to be able to produce data from months if not years ago to meet financial or regulatory requirements. In this case, you should create a backup rotation schedule appropriate for your needs.
For example, you might perform a full backup of all the data on your systems each night. Or you might want to produce a full backup once a week, and then produce incremental backups during the week—that is, back up only the files that have changed since the full backup. Using the combination of the full backup and the incremental backup media, you can restore the system to the state it was in at any of the backup points.
In this kind of situation, when the next full backup is performed, the incremental backups might no longer be needed. If that is the case, you can reuse the tapes. The rate at which tapes or other media can be reused is called the rotation schedule. A good generic policy (depending on your environment, of course) is to create a weekly backup of all data and perform incremental backups during the week. This allows you to schedule the full backup for a time (such as the weekend) when it won’t impact your users. The weekly incremental backup media can be reused during the next week if the next full backup is successful.
The full backups done on a weekly basis can be stored for a month and then reused. Additionally, you might want to keep one of the end-of-month full backups for long-term storage, depending on the nature of your applications.
The full/incremental backup method has been developed to help reduce the backup window. This term is used to refer to the time that is available to the backup program when users do not need to have access to the system. However, as storage requirements continue to increase, and because data access in many industries is now a round-the-clock requirement, there is another technology that can be useful in these situations. As mentioned earlier in this chapter, Storage Area Networks can be used to offload storage devices from servers. SANs solve many problems associated with the standard SCSI devices. First, SCSI is limited in the number of devices that can be attached to a SCSI bus, as well as the short distances that SCSI hardware can be used over. SANs allow you to connect storage devices, both disk and tape, over much longer distances without any reduction in the access time. SANs also can be used to offload the backup process from a server’s CPU. The SAN can instead be used to back up disk drives to tape drives, with no intervention by the server(s) that use the SAN.
Whatever rotation schedule you decide to use for your backup media, be sure that it meets the needs of your users and the applications they use. In addition, you should implement some type of mechanism—such as a database storing information about each tape—so that you can discard the tape after it has been reused a certain number of times. Magnetic tape does degrade with each usage, and can even deteriorate when stored in a place where such things as temperature and humidity exceed the limits recommended by the manufacturer.
Using barcodes, or simply labeling tapes using a serial numbering method, can enable you to identify each tape in the database, and you can update the database each time a tape is used. Barcoding is used as part of the tape-identification system used with autoloaders or tape libraries, but it’s a good idea even if you manually insert tapes into your backup drive. When a tape has passed its recommended useful lifetime, zap it with some utility to make the data unreadable, and toss the tape into the trash. It is a good idea to have a company policy on the disposal of all materials (including printouts as well as tapes, among other things) for security purposes. Who is looking in your trash dumpster? Better to be safe than to give someone else valuable information about your company’s data.
Off-Site Storage
The backup media is helpful only if it’s safely stored as well. If you need to restore only a single file because a user has made a mistake and deleted it, having a tape stored in the computer room makes this a quick and easy job. Pop the tape in the tape drive, restore the file, and then call the user. However, storing backup tapes in the same place that you house your computers is not always such a good idea. For example, this might not help you in the event of some kind of disaster, such as a fire. Not only are your computers lost, but your backups are gone as well.
For important data, the backup media should be sent to an off-site storage location as soon as practical after the backup has finished. In this scenario, if a disaster strikes your site, your tapes are safely stored away at another site and you can use them to recover when you move to a hot site or when you replace the destroyed equipment.
That said, what constitutes off-site storage? You can use several different places for off-site storage, depending on your needs. Consider first how safe the storage site is. Second, consider the amount of time it takes to retrieve the backup media. Third, consider the expense involved. Some sites to consider:
![]() Use a company whose business is to pick up, store, and deliver backup media. There are many companies in this business. You’ll want to visit their storage site to be sure that the storage conditions are conducive to long-term storage of sensitive backup media. Test the promised restore-time window by requesting the retrieval of tapes now and then. Be sure that the site offers 24-hour access to your data.
Use a company whose business is to pick up, store, and deliver backup media. There are many companies in this business. You’ll want to visit their storage site to be sure that the storage conditions are conducive to long-term storage of sensitive backup media. Test the promised restore-time window by requesting the retrieval of tapes now and then. Be sure that the site offers 24-hour access to your data.
![]() If you employ the service of a hot site that can be used to re-create your computer system or network during a disaster, the hot-site vendor often can provide services for off-site storage of backup media. In this case, you can save time during an emergency because you won’t have to retrieve the tapes from a third party when you activate the hot site.
If you employ the service of a hot site that can be used to re-create your computer system or network during a disaster, the hot-site vendor often can provide services for off-site storage of backup media. In this case, you can save time during an emergency because you won’t have to retrieve the tapes from a third party when you activate the hot site.
![]() If you are a large company, it might be practical to store your backup media at another company site. The odds of a disaster striking multiple sites at the same time should be taken into consideration, as well as the storage conditions at the other site. For example, if the sites are within close proximity, this might not be a good idea. A natural disaster such as a hurricane or flood might cause a disaster at both places. Consider also the expense in having to regularly send tapes to your other company site. It might be less expensive to pay a professional service to store your tapes than to have employees transferring tapes from one site to another.
If you are a large company, it might be practical to store your backup media at another company site. The odds of a disaster striking multiple sites at the same time should be taken into consideration, as well as the storage conditions at the other site. For example, if the sites are within close proximity, this might not be a good idea. A natural disaster such as a hurricane or flood might cause a disaster at both places. Consider also the expense in having to regularly send tapes to your other company site. It might be less expensive to pay a professional service to store your tapes than to have employees transferring tapes from one site to another.
![]() Take the media or the external hard disk drive home and stick the backups under your bed. This is no joke. I once worked at a small company in which the system manager would take the monthly backup home and store it under her bed until the next month. Along the same lines, if you operate a small office at home, you might consider taking your weekly or monthly backup tape to a safety deposit box at your local bank for off-site storage. The point is to make sure that the data is stored away from the computer system so that you can reduce the odds of a disaster destroying both your systems and your backups.
Take the media or the external hard disk drive home and stick the backups under your bed. This is no joke. I once worked at a small company in which the system manager would take the monthly backup home and store it under her bed until the next month. Along the same lines, if you operate a small office at home, you might consider taking your weekly or monthly backup tape to a safety deposit box at your local bank for off-site storage. The point is to make sure that the data is stored away from the computer system so that you can reduce the odds of a disaster destroying both your systems and your backups.
Routine Maintenance
Although the focus of this chapter is preventive maintenance, routine maintenance for computers and network devices needs to be performed on a regular basis. Routine maintenance helps prevent hardware failures due to fatigued or old equipment that breaks down. For example, although all computers, from the small desktop to the large rack-mounted systems, use fans to ensure the smooth flow of air through the system to keep components from overheating, you should periodically make sure that dust and other contaminants are not being sucked into the system, where electrical charges can cause them to adhere to system components.
Opening the system box and using canned compressed air to get rid of this kind of contamination can be a good preventive technique to use once or twice a year. If you have a home office, this is easily overlooked. If you have a smoker at home, for example, you’ll find that cigarette smoke can produce a fine layer of dust on computer components over time. This can also happen, as I know from experience, with cat hair. Don’t leave the box closed forever. Open it up and look inside now and then to clean things up. Even the larger servers that are stored away in a locked computer room can use cleaning now and then. No matter how “clean” you think your computer room is, just take a look at the dust that accumulates over time inside your servers. You might be surprised. This is one of the problems associated with the “lights out” computer-room scenario. If you don’t look into the computer room now and then, you may have a problem slowly accumulating. It’s always best to find a problem before it seriously impacts your hardware.
Tape drives need to be cleaned periodically because the magnetic tape comes in contact with the tape heads inside the unit. A cleaning tape should be run on a schedule recommended by the manufacturer. DLT tape drives usually have an indicator light that comes on when a sufficient amount of contamination has accumulated on the tape head such that parity errors are occurring. If the cleaning tape light comes on more frequently than the cleaning schedule recommended by the manufacturer, you might want to consider looking at which backup tapes were used just before this happened. You might have an old tape that needs to be discarded, or even a tape drive that needs to be recalibrated or replaced.
Building Redundancy into the Network
It doesn’t matter what kind of support maintenance contract you have with your vendor if it takes the vendor hours or days to get the parts necessary to replace a failed system. For this reason, it’s a good idea to build redundant paths in your network from the design phase so that, for example, if a router goes down, another path through the network will allow users to keep accessing the data they need. Providing for fault-tolerant servers using clustering technology also can be used to ensure maximum uptime for critical systems.
![]() In Chapter 2, “Overview of Network Topologies,” you will find a good discussion of using partial-mesh topologies to build redundancy into your network. See “Mesh Topology” (p. 17) and as they pertain to redundancy, “Building and Campus Topologies” (p. 23) and “Multi-Tiered Network Topology” (p. 26).
In Chapter 2, “Overview of Network Topologies,” you will find a good discussion of using partial-mesh topologies to build redundancy into your network. See “Mesh Topology” (p. 17) and as they pertain to redundancy, “Building and Campus Topologies” (p. 23) and “Multi-Tiered Network Topology” (p. 26).
If the time needed to get replacements is excessive (when compared to the cost of paying idle users, the overhead involved in office space, and so on), it might be wise to keep a duplicate device on-site so that you can swap it into service to replace a failed device in an emergency. In the case of a router or switch, it’s easy to replace the failed device, follow a carefully written plan to reconfigure it, and put the network path back in service.
Recovery Planning
Nothing (other than a backup) is more helpful during an emergency than a well-thought-out recovery plan. Actually, this is an overall term because you should plan for network or server outages—from the loss of a single disk drive to the loss of a single computer system, and even to the loss of your entire network. Chapter 3, “Network Design Strategies,” stresses that you should always document the network and its components. Recovery procedures should be part of this documentation.
The problem with disasters is that you can’t schedule them. They don’t always occur during normal business hours when you are wide awake and functioning well. In the middle of the night after a long day at work, you might get called in to restore a system without having the advantage of a good night’s sleep. A good disaster-recovery plan can be helpful if only to keep you from making a mistake during the recovery process.
A good disaster recovery plan includes several items:
![]() Contact information for key personnel who need to be involved in the recovery effort, as well as personnel who need to be informed of the event, such as application client representatives. Don’t forget to keep this information up-to-date.
Contact information for key personnel who need to be involved in the recovery effort, as well as personnel who need to be informed of the event, such as application client representatives. Don’t forget to keep this information up-to-date.
![]() Contact information for vendors of both the hardware and the software components of the system or network. This should include both technical support telephone numbers and contact information for local field personnel who might need to come in and assist you with setting up or repairing the damage.
Contact information for vendors of both the hardware and the software components of the system or network. This should include both technical support telephone numbers and contact information for local field personnel who might need to come in and assist you with setting up or repairing the damage.
![]() Step-by-step procedures for remedying the situation. This can involve such things as how to completely rebuild a particular computer system from scratch by reinstalling the operating system and applying the backup tapes. Configuration information for routers and other devices should be documented in the recovery plan.
Step-by-step procedures for remedying the situation. This can involve such things as how to completely rebuild a particular computer system from scratch by reinstalling the operating system and applying the backup tapes. Configuration information for routers and other devices should be documented in the recovery plan.
![]() After the disaster has been remedied according to your plan, there needs to be a set of tests you can perform on the operating system, the hardware, and the applications to ensure that the recovery effort has been successful.
After the disaster has been remedied according to your plan, there needs to be a set of tests you can perform on the operating system, the hardware, and the applications to ensure that the recovery effort has been successful.
Justifying Preventative Maintenance
Some of the approaches that have been discussed in this chapter are expensive. Because of this, you might experience problems obtaining funding from upper management for these items. You can do several things to help yourself out in these situations.
Be sure to document all the downtime you experience for each system in the network, and try to associate a cost with it. Although you might not be able to get data that allows you to show the impact on your customers, you usually can determine the number of users who are impacted. Assuming that these users can perform only a certain percentage of their daily work without access to the computer or network, try to assign the number of hours lost due to the downtime and multiply it by an average hourly rate for the employees affected by the downtime. Most likely, you won’t have access to accurate pay rates for other employees. However, a way to get around this is to multiply the hours times the minimum hourly wage and show this to upper management if it results in a significant amount. Point out that you’ve based your costing on the minimum wage. Because those in upper management are more likely to know the average salaries of experienced computer users, this figure still gives them a good idea of what downtime costs. In other words, if you come up with a large figure during your calculations based on the minimum wage, they’ll quickly determine that the actual figure is magnitudes larger than that, and you just might get support for your preventative maintenance efforts.