
With PHP you can enable the web server to interface with any other program. One of the most commonly used applications for interfacing with a web server is a database server. With a database connection to the web server, your site can search the data of the database system and thus offer dynamic content. There is a large list of database systems to choose from. In this chapter, you will download and start using one of the most common ones, MySQL, which is a relational database that utilizes the Structured Query Language (SQL). SQL is the most widespread set of instructions used to set up and query a database system.
In this chapter, you will use some basic SQL commands to create and manage a MySQL database and to create a shell script to automatically feed a MySQL database with data collected from a web site, a process that is often called web scraping .
Installing and Testing MySQL

The first dialog of the MySQL installation process prompts you for a password
A second window appears for the password confirmation. If you did not enter a password previously, leave the field in this window empty and press Enter again.
The installation process continues, with information displayed in the terminal until completion.
Press Q (quit) on the keyboard to exit the command and release the terminal.
The terminal clears with the mysql prompt ready to accept the next command.
With these commands, you can start and exit the MySQL client and also view and run the set of the available commands that mysql interprets. Next, you will learn about the SQL statements that mysql issues to the MySQL server to create and manage a database.
Creating Your First MySQL Database
Start the mysql client to connect to the server so you can create and use your first database. In this section, you will design the tables included in this database, you will define the relationships between the tables, and then you will use the tables to enter your data. You will then be able to issue database queries on the table data and generate results.
Hint!
Each MySQL command requires a semicolon (;) to indicate the ending. Some SQL databases require the commands to be inserted in uppercase characters (e.g., CREATE DATABASE library;). The MySQL syntax used here does not require uppercase.
If you test drop at this time, make sure to repeat the previous create command to re-create the database.
Creating and Deleting Tables of Your Database
The first column, called name, is of type VARCHAR, which means it’s a string of characters with a variable length. You allocate the maximum number of characters for the value in parentheses. In this example, the author’s name can be up to 30 characters. The second column is of type CHAR, also a string of characters but with a fixed length. The length in this example is specified in the parentheses as 2, which means the author’s country will always be inserted as two characters. This is sufficient because the country column value will be provided as the ISO 3166-1 alpha two-character code, e.g., uk.
Because it’s a relational database, MySQL allows you to connect two or more tables by relating their entries. This allows you to store data in multiple tables, instead of just a big one. This approach makes data more manageable and less error prone.
The queries you’ll execute next will combine columns from both tables. In this example, details of the books written by the authors in the author’s table will make up a second table called book. To connect the two tables and allow their data to be combined, a common column must be used from both tables. This column is defined as the primary key for the first table and the foreign key for the second. A primary key (and therefore a foreign key) must have a unique value in each table’s record so that it discriminates this record from the others.
Notice that the author_id field is identified by the PRI value in the Key column as the primary key. In addition, as indicated by the NO value in the Null column field, author_id should not be empty for any record. Also, the auto_increment keyword for the primary key is shown in the Extra column.
This time, two columns have a NO value in the Null column: book_id, which is the primary key, and author_id, the foreign key, which was explicitly set to not null. The MUL (multiple) key indicates that multiple rows may have the same value as the author_id column.
Inserting, Displaying, and Deleting Records
Altering the Table’s Structure
Even when a table is filled with data, it is not too late to modify the table’s characteristics. In this section, you will make three alterations in a table’s structure. The first one solves the problem of the duplicated entry shown in the previous section. The second modification will be to the data type, and the third will be to add a column.
Testing the Table Connection
By using a foreign key, the two database tables are connected with a parent-child relationship. In this example, the parent table is author, which provides its primary key as a foreign key to the book table. You can’t delete the author table if you have not already deleted the book table. Also, you can’t insert a book entry with a foreign key value that does not exist.
In the previous commands, since book_id is the primary key for book, the book_id values must be unique. For the values of the book_id column, the ISBN-13 of each book was chosen because it’s unique to each book.
The two tables, connected now with a parent-child relationship and filled with records, are used in the following section for extracting information from the database. In other words, you’ll next query the database.
Performing SQL Queries with the MySQL Server
The inner join includes records of the two tables that have the same value in their author_id columns. The columns for the records included are the title (from book), the name (from author), and the publication date (from author) where the language column in the book table is English.
In the previous table, the output is grouped from right to left, first by publication date (two records have the value 2012) and then by author’s name.
Modifying Records with the update Command
Using the SQL like Operator
The percentage (%) wildcard matches any string of zero or more characters.
The underscore (_) wildcard matches a single character.
Web Scraping with MySQL and the Linux Shell
In the previous examples, you manually inserted records into your database. Filling your database one record at a time is certainly tedious. For more realistic examples, you can use automated methods to transfer your data to one or more tables.
In this section, you will implement what is commonly called web scraping . This is the detection and collection of data from various web pages and inserting it into a file (e.g., a spreadsheet) or more appropriately into a database. The Bash shell scripting language and MySQL will be used for this project. Writing a Linux shell script that applies only to a certain web site may seem like overkill; however, this may help you process thousands of data records in some cases.
The URLs Describing the Resources
To start with web scraping, you have to identify the format in which the data is encoded for a specific portal. To search for data in specific web pages, you first have to describe their URLs in a systematic way. Consider, for instance, amazon.com. By visiting any product page, you can find that what uniquely identifies a product for Amazon is the Amazon Standard Identification Number (ASIN) code. This is a 10-charcter alphanumeric unique identifier.
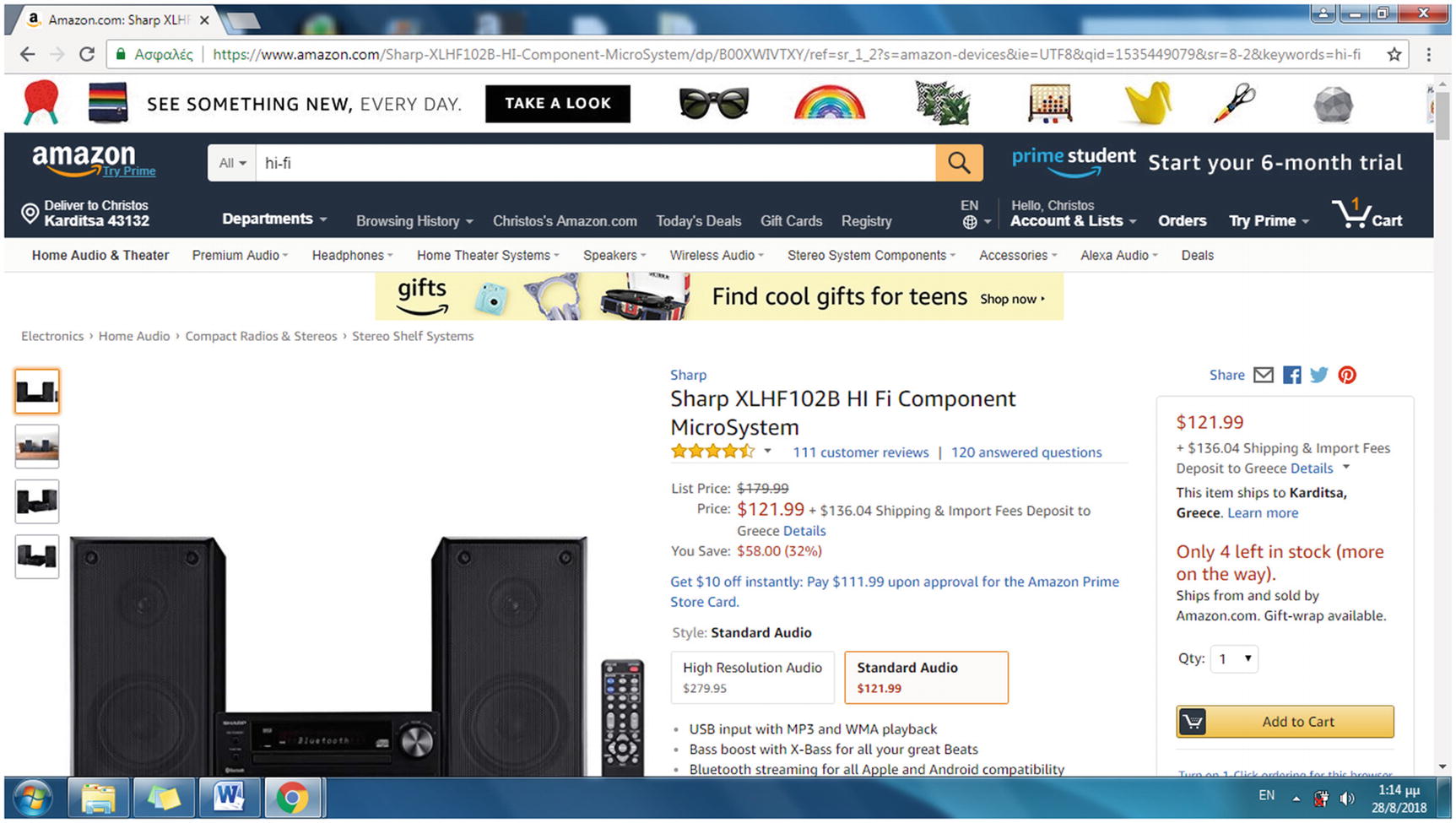
The ASIN is included in the product’s URL
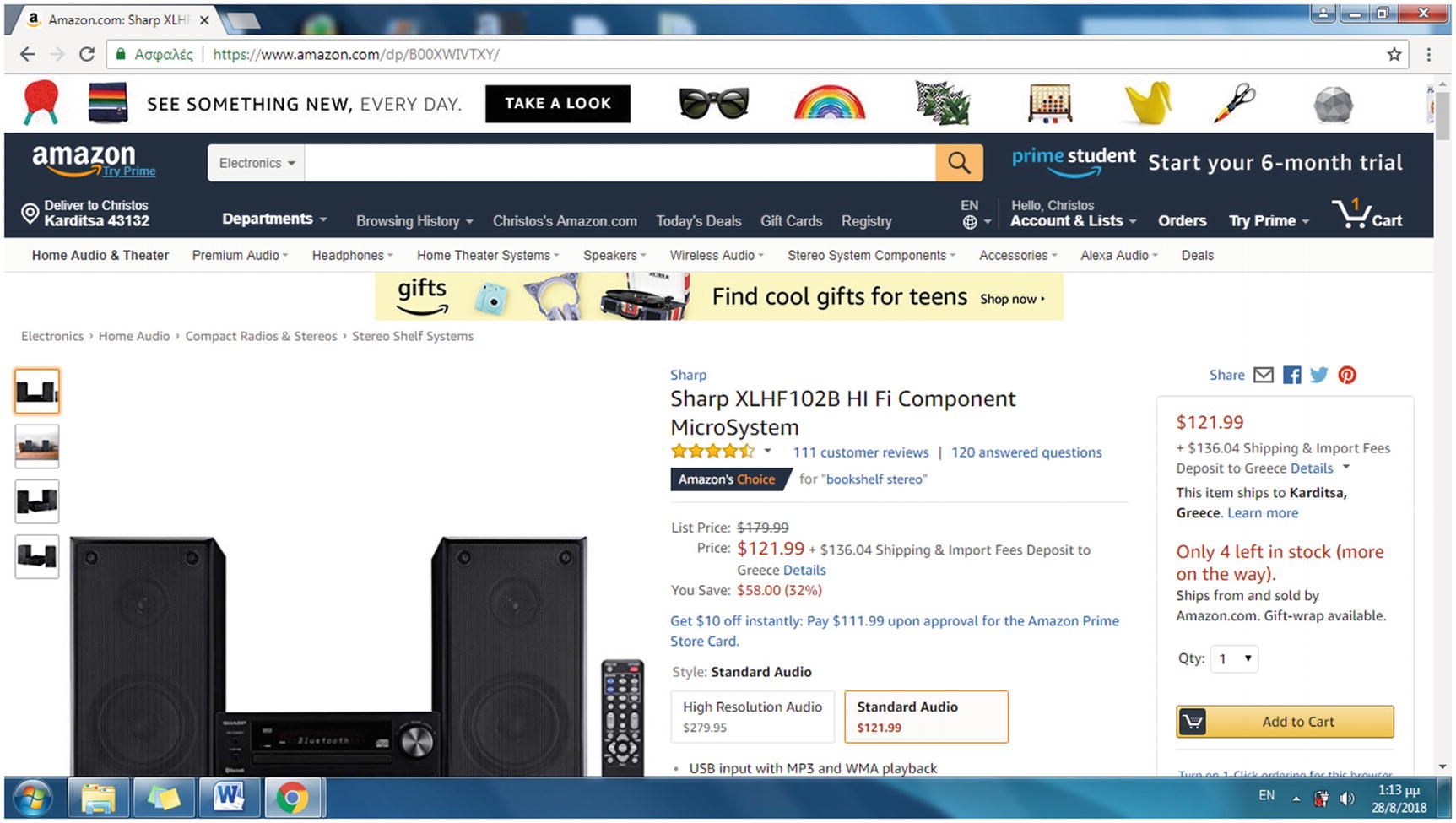
The ASIN included in the simplified URL format of a product
A 13-digit ISBN, used for books released after the January 1, 2007
A 10-digit ISBN, used for books released before January 1, 2007

The Apress home page
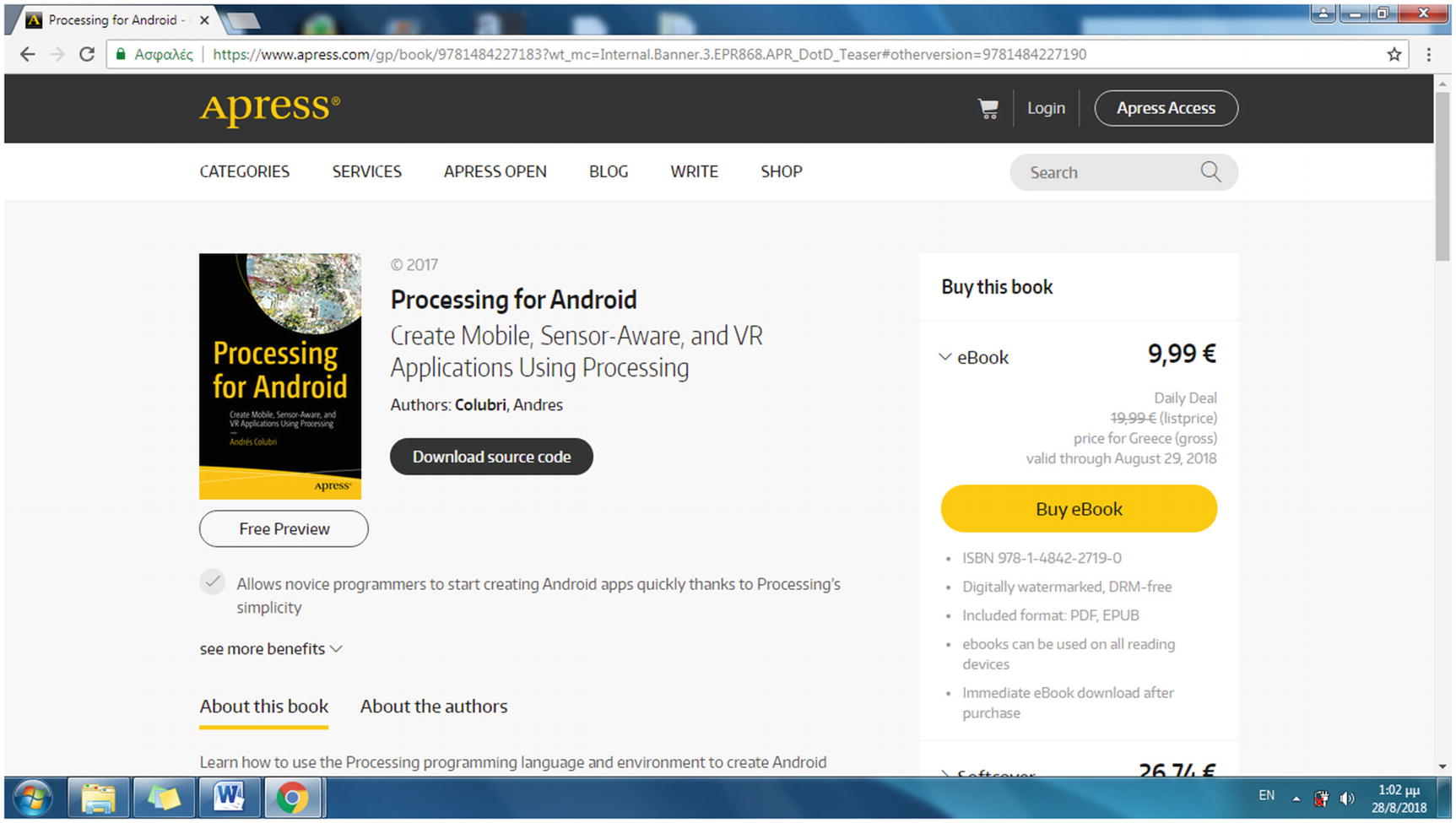
A product page on the Apress site identifies a book with the ISBN in the URL
The next step is to locate and extract the data format used in the HTML source code of each product web page. For e-commerce sites, the data format is stored in a consistent way by implementing a data layer. The structure that defines the data layer for this example, the appDataLayer struct, is discussed in the following section.
Designing the Web Scraping Project
The following is the plan for creating the scrapping project: The web scraping shell script receives as an argument the URL of an Apress web page, which includes books of a certain category. It downloads this web page and then searches in the HTML source code of this web page for URLs of web pages that represent certain books. For each URL, the Bash shell script will perform an HTTPS connection to download the corresponding web page. The shell script will examine the web page’s data layer, found behind the scenes, in the HTML source code for values of specific book attributes such as for the title, ISBN, and price. These values will be stored in a MySQL database table that will be created for gathering the data acquired with the previous web scraping technique.
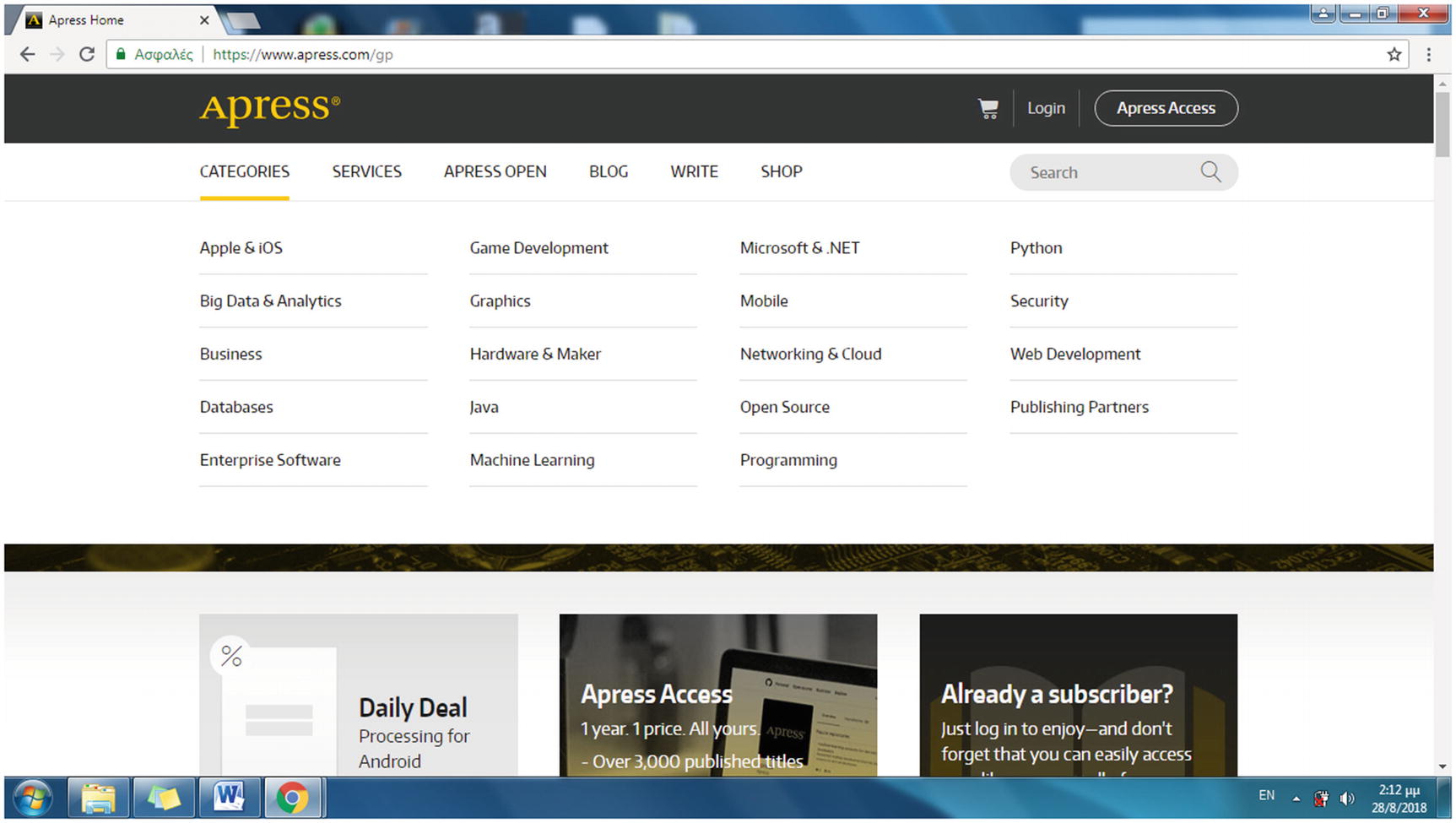
The Categories menu on the Apress home page
The books included in the Web Development category of Apress
On this web page, a number of images representing the books appear. Those images are links to web pages that provide descriptions to the corresponding books.
Hint!
Each option in the Categories menu leads to a web page that includes only a portion of the category’s books. It is, however, sufficient for examining the web scraping method here. To view all the books in each category, follow the “Browse all titles” link in each category.
It uses the category name, in lowercase, with the space between the words substituted by a hyphen (-).
shell.sh is the name of the shell script that performs the web scraping.
https://www.apress.com/gp/web-development is the URL of the category web page, used to provide the URLs of the books included in the category web page, which finally will be downloaded and searched for the pPriceGross, fn, and isbn values of each book.
apress is the database name that will be used to store the information.
book is the apress database’s table that includes the pPriceGross, fn, and isbn fields.
pPriceGross, fn, and isbn are three fields found in the data layer of each page that provide values for the price, the name, and the ISBN, respectively. The number of fields this script supports is variable, which means that the same script can also run for two or five fields without changing any part of the source code.
The web page of the URL provided to the shell script command is the category page that includes a number of URLs leading to product web pages, each one dedicated to a single book. The product URLs have to be retrieved by the script and to be visited to extract the values of the pPriceGross, fn, and isbn fields of the data layer struct.
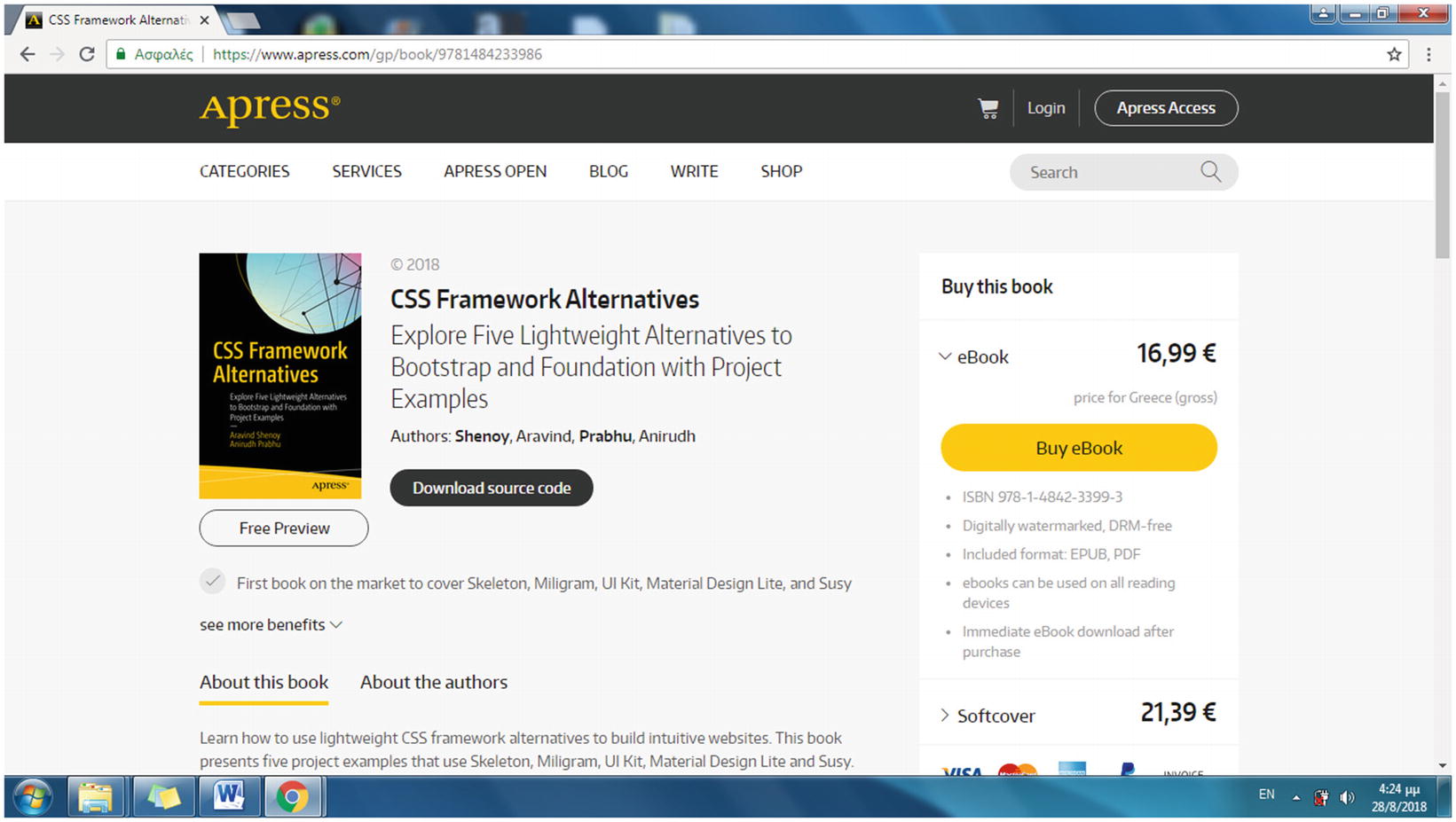
Visiting an Apress book web page to view the HTML source code and locate the fields required for the shell script
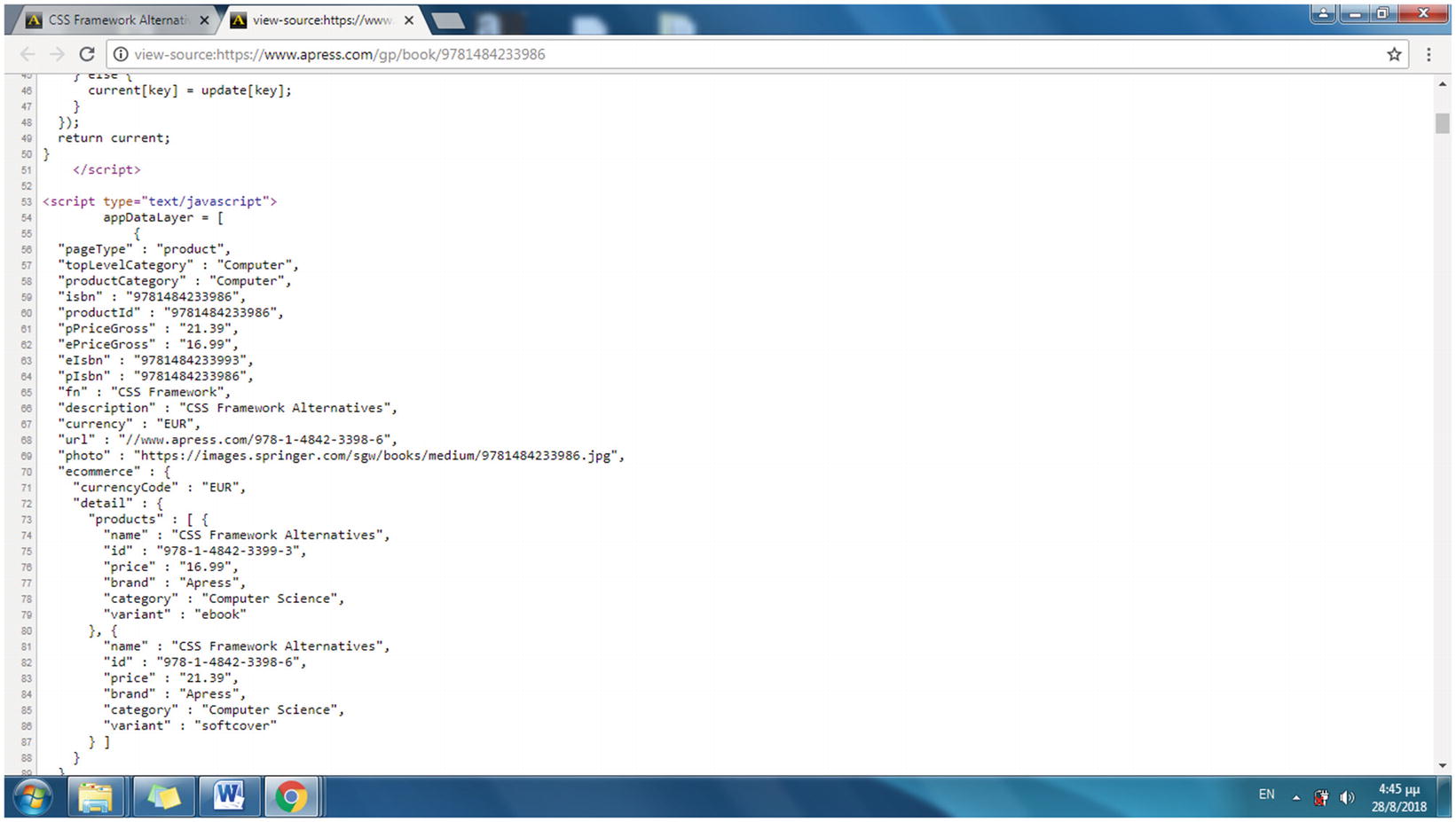
The HTML source code of an Apress web page for a specific book
The data layer is a collection of information required to pass data to other systems or software. The data layer is included in the source code of the web page, and more specifically to the JavaScript source code, usually as an object or a variable and therefore is hidden from the user. The format of the data layer can be considered as variable-value pairs (for instance, variable description and value CSS Framework Alternatives).
This data layer struct, found in each product page, is the resource for the information that the web scraping script will gather. In the current example, the values of the three fields retrieved (pPriceGross, fn, and isbn) will be stored in a database table, which is created in the following section.
Creating the MySQL Database Used for the Web Scraping Project
isbn, which is of type CHAR with a length of 13 characters
fn, which is of type VARCHAR with a length up to 40 characters
pPriceGross, of type DECIMAL, with four digits and two decimal places
In the following section, you will create a Bash shell script that runs the web scraping project to download the web content, search for the specified fields, and fill the database.
Implementing the Web Scraping Project
All URLs are then visited, and the appDataLayer array in each web page is used to provide the values for the isbn, fn, and pPriceGross fields. Finally, the fields are stored in a database table.
awk takes its name from the initials of its developers Aho, Weinberger, and Kernighan. It is a utility language used for data extraction from text. awk is often combined with sed, and the most common usage is to extract a column from text.
sed stands for Stream Editor and is capable of receiving text and performing operations such as appending, inserting, deleting, or substituting text. The latter is one of the most commonly used operations of sed and is the one applied in the current example.
grep is a command-line utility for searching text for lines that match a regular expression (or just a piece of text). Its name comes from the text editor command g/re/p that means to globally (g) search a regular expression (re) and print (p).
cat is used to read content of files or concatenate (hence the command’s name) files.
wget (web get) is used to fetch content of the web servers it connects to from the command line.
The Script’s First Part
In the next section, you will enable shell.sh to run from any directory at the terminal with only its name provided.
This also could be indicated as ELEMENTS=${#args[@]}.
In the first command, wget runs in quiet (flag -q) mode, outputs the content retrieved to stdout (flag -O), and connects to the URL indicated with the first argument ($1) of the shell program (the URL of the category web page).
The source code of the web page downloaded with wget is passed therefore to the grep command to extract the line including the string <h3><a href="/gp/book/, the fixed part of the hyperlink inserted in the <h3> header, which is the format of the links for products included in this web page.
Therefore, when the script runs, file.txt includes a number of ISBNs, with each one placed on its own line.
The Script’s Second Part
In the for loop, each ISBN value is concatenated to the fixed string https://www.apress.com/gp/book/ to form the simplified URL of the products pages. Here’s an example:
https://www.apress.com/gp/book/9781484233986
Notice that the value of b is output to the terminal with the echo Bash command. The echo commands in the program are used to display the connections performed by the shell script while the script runs.
Therefore, if args[4] currently has the value fn, args2[4] has the value of the field fn, in this example CSS Framework.
For each line of file.txt, the args2[3], args2[4], and args2[5] elements are filled.
shell.sh was used here with three fields, but it works equally for any number of fields. For example, if four fields were used, the previous code snippet would concatenate the elements args[3], args[4], args[5], and args[6] (the new field) using commas.
The code runs recursively and assigns the first field name to variable mysql, finds the next and concatenates the two fields with commas as mysql again, and repeats until all fields are included.
In the previous source code, mysql2 forms the string of all field values separated by commas with a recursive process. The reason the spaces need to be removed from the mysql2 and sql2 variables is that Bash currently prepends a space character to elements, which are read using a for loop from an array.
For this example, statement INSERT INTO inserts a record into the book table by entering value 35.3 in the pPriceGross field, value Mastering Zoho Creator in the fn field, and value 9781484229064 in the isbn field.
The previous command runs a number of times equal to the number of books included in the web page source of the URL provided as the first argument of the shell ($1).
Testing the Web Scraping Shell Program
Hint!
To run the shell script from any working directory, copy the shell.sh file to /usr/local/bin.
$ sudo cp ~/shell.sh /usr/local/sbin
Execute it then from any working directory as follows:
$ sudo shell.sh https://www.apress.com/gp/web-development apress book pPriceGross fn isbn
The MySQL server connects, and the mysql> prompt appears.
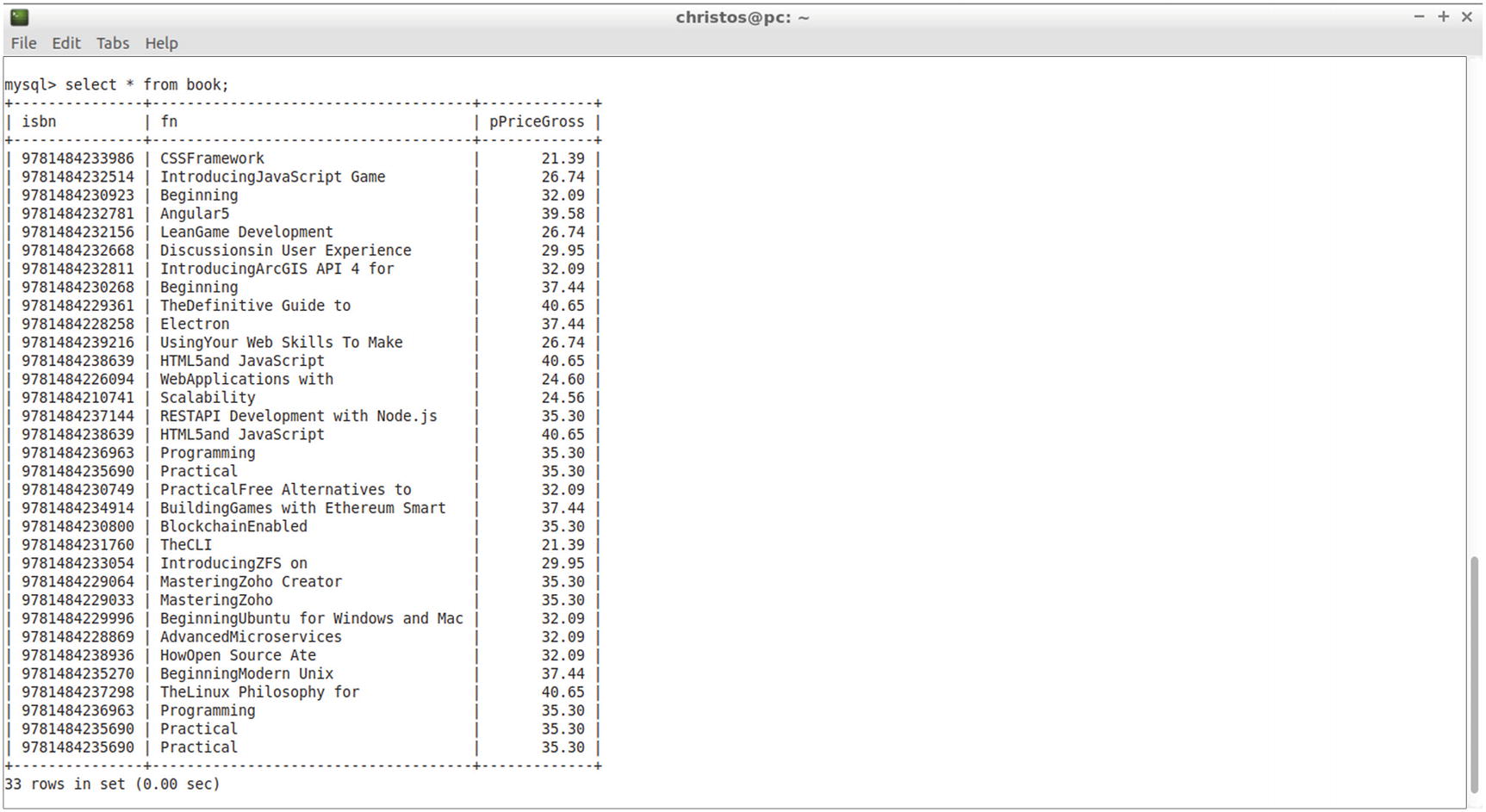
The output
You can add even more records by using the rest of the Categories menu links.
Summary
In this chapter, you used the MySQL server to create, manage, and query databases using SQL commands. You inserted records into the database tables manually and also used the web scraping technique to fill the database automatically by collecting data provided by a site.
In the following chapter, you will run PHP programs that connect to the MySQL server, enabling the web server to provide a search capability and therefore offer dynamic web content to its sites.