
16
Practical Considerations
There are a bunch of algorithms presented in this book that can be used to solve real-world problems. In this chapter, we’ll examine the practicality of the algorithms presented in this book. Our focus will be on their real-world applicability, potential challenges, and overarching themes, including utility and ethical implications.
This chapter is organized as follows. We will start with an introduction. Then, we will present the issues around the explainability of an algorithm, which is the degree to which the internal mechanics of an algorithm can be explained in understandable terms. Then, we will present the ethics of using an algorithm and the possibility of creating biases when implementing them. Next, the techniques for handling NP-hard problems will be discussed. Finally, we will investigate factors that should be considered before choosing an algorithm.
By the end of this chapter, you will have learned about the practical considerations that are important to keep in mind when using algorithms to solve real-world problems.
In this chapter, we will cover the following topics:
- Introducing practical considerations
- The explainability of an algorithm
- Understanding ethics and algorithms
- Reducing bias in models
- When to use algorithms
Let’s start with some of the challenges facing algorithmic solutions.
Challenges facing algorithmic solutions
In addition to designing, developing, and testing an algorithm, in many cases, it is important to consider certain practical aspects of starting to rely on a machine to solve a real-world problem. For certain algorithms, we may need to consider ways to reliably incorporate new, important information that is expected to keep changing even after we have deployed our algorithm. For example, the unexpected disruption of global supply chains may negate some of the assumptions we used to train a model predicting the profit margins for a product. We need to carefully consider whether incorporating this new information will change the quality of our well-tested algorithm in any way. If so, how is our design going to handle it?
Expecting the unexpected
Most solutions to real-world problems developed using algorithms are based on some assumptions. These assumptions may unexpectedly change after the model has been deployed. Some algorithms use assumptions that may be affected by changing global geo-political situations. For example, consider a trained model that predicts the financial profit for an international company with offices all over the world. An unexpected disruptive event like a war or the spread of a sudden deadly virus may result in fundamentally changing the assumptions for this model and the quality of predictions. For such use cases, the advice is to “expect the unexpected” and strategize for surprises. For certain data-driven models, the surprise may come from changes in the regulatory policies after the solution has been deployed.
When we are using algorithms to solve a real-world problem, we are, in a way, relying on machines for problem-solving. Even the most sophisticated algorithms are based on simplification and assumptions and cannot handle surprises. We are still not even close to fully handing over critical decision-making to algorithms we’ve designed ourselves.
For example, Google’s recommendation engine algorithms have recently faced the European Union’s regulatory restrictions due to privacy concerns. These algorithms may be some of the most advanced in their field but if banned, these algorithms may turn out to be useless as they won’t be used to solve the problems they were supposed to tackle.
But, the truth of the matter is that, unfortunately, the practical considerations of an algorithm are still after-thoughts that are not usually considered at the initial design phase.
For many use cases, once an algorithm is deployed and the short-term excitement of providing the solution is over, the practical aspects and implications of using an algorithm will be discovered over time and will define the success or failure of the project.
Let’s look into a practical example where not paying attention to the practical considerations failed a high-profile project designed by one of the best IT companies in the world.
Failure of Tay, the Twitter AI bot
Let’s present the classical example of Tay, which was presented as the first-ever AI Twitter bot created by Microsoft in 2016. Using an AI algorithm, Tay was trained as an automated Twitter bot capable of responding to tweets about a particular topic. To achieve that, it had the capability of constructing simple messages using its existing vocabulary by sensing the context of the conversation. Once deployed, it was supposed to keep learning from real-time online conversations and by augmenting its vocabulary of the words used often in important conversations. After living in cyberspace for a couple of days, Tay started learning new words. In addition to some new words, unfortunately, Tay picked up some words from the racism and rudeness of ongoing tweets. It soon started using newly learned words to generate tweets of its own. A tiny minority of these tweets were offensive enough to raise a red flag. Although it exhibited intelligence and quickly learned how to create customized tweets based on real-time events, as designed, at the same time, it seriously offended people. Microsoft took it offline and tried to re-tool it, but that did not work. Microsoft had to eventually kill the project. That was the sad end of an ambitious project.
Note that although the intelligence built into it by Microsoft was impressive, the company ignored the practical implications of deploying a self-learning Twitter bot. The NLP and machine learning algorithms may have been best in class, but due to the obvious shortcomings, it was practically a useless project. Today, Tay has become a textbook example of a failure due to ignoring the practical implications of allowing algorithms to learn on the fly. The lessons learned by the failure of Tay definitely influenced the AI projects of later years. Data scientists also started paying more attention to the transparency of algorithms.
To delve deeper, here’s a comprehensive study on Tay: https://spectrum.ieee.org/in-2016-microsofts-racist-chatbot-revealed-the-dangers-of -online-conversation.
That brings us to the next topic, which explores the need for and ways to make algorithms transparent.
The explainability of an algorithm
First, let us differentiate between a black box and a white box algorithm:
- A black box algorithm is one whose logic is not interpretable by humans either due to its complexity or due to its logic being represented in a convoluted manner.
- A white box algorithm is one whose logic is visible and understandable to a human.
Explainability in the context of machine learning refers to our capacity to grasp and articulate the reasons behind an algorithm’s specific outputs. In essence, it gauges how comprehensible an algorithm’s inner workings and decision pathways are to human cognition.
Many algorithms, especially within the machine learning sphere, are often termed “black box” due to their opaque nature. For instance, consider neural networks, which we delve into in Chapter 8, Neural Network Algorithms. These algorithms, which underpin many deep learning applications, are quintessential examples of black box models. Their complexity and multi-layered structures make them inherently non-intuitive, rendering their inner decision-making processes enigmatic to human understanding.
However, it’s crucial to note that the terms “black box” and “white box” are definitive categorizations, indicating either complete opacity or transparency, respectively. It’s not a gradient or spectrum where an algorithm can be somewhat black or somewhat white. Current research is fervently aimed at rendering these black box algorithms, like neural networks, more transparent and explainable. Yet, due to their intricate architecture, they remain predominantly in the black box category.
If algorithms are used for critical decision-making, it may be important to understand the reasons behind the results generated by the algorithm. Avoiding black box algorithms and using white box ones instead also provides better insights into the inner workings of the model. The decision tree algorithm discussed in Chapter 7, Traditional Supervised Learning Algorithms, is an example of such white box algorithms. For example, an explainable algorithm will guide doctors as to which features were actually used to classify patients as sick or not. If the doctor has any doubts about the results, they can go back and double-check those particular features for accuracy.
Machine learning algorithms and explainability
In the realm of machine learning, the concept of explainability is paramount. But what exactly do we mean by explainability? At its core, explainability refers to the clarity with which we can understand and interpret a machine learning model’s decisions.
It’s about pulling back the curtain on a model’s predictions and understanding the “why” behind them.
When leveraging machine learning, especially in decision-making scenarios, individuals often need to place trust in a model’s output. This trust can be significantly amplified if the model’s processes and decisions are transparent and justifiable. To illustrate the significance of explainability, let’s consider a real-world scenario.
Let’s assume that we want to use machine learning to predict the prices of houses in the Boston area based on their characteristics. Let’s also assume that local city regulations will allow us to use machine learning algorithms only if we can provide detailed information for the justification of any predictions whenever needed. This information is needed for audit purposes to make sure that certain segments of the housing market are not artificially manipulated. Making our trained model explainable will provide this additional information.
Let’s look into different options that are available for implementing the explainability of our trained model.
Presenting strategies for explainability
For machine learning, there are fundamentally two strategies to provide explainability to algorithms:
- A global explainability strategy: This is to provide the details of the formulation of a model as a whole. For example, let us consider the case of a machine learning model used to approve or refuse loans for individuals for a major bank. A global explainability strategy can be used to quantify the transparency of the decisions of this model. The global explainability strategy is not about the transparency of individual decisions but about the transparency of aggregated trends. Let us say that if there is speculation in the press about gender bias in this model, a global explainability strategy will provide the necessary information to validate or negate the speculation.
- A local explainability strategy: This is to provide the rationale for a single individual prediction made by our trained model. The aim is to provide transparency for each individual decision. For instance, consider our earlier example of predicting house prices in the Boston area. If a homeowner questions why their house was valued at a specific price by the model, a local explainability strategy would provide the detailed reasoning behind that specific valuation, offering clarity on the various factors and weights that contributed to the estimate.
For global explainability, we have techniques such as Testing with Concept Activation Vectors (TCAV), which is used to provide explainability for image classification models. TCAV depends on calculating directional derivatives to quantify the degree of the relationship between a user-defined concept and the classification of pictures. For example, it will quantify how sensitive a prediction of classifying a person as male is to the presence of facial hair in the picture. There are other global explainability strategies, such as partial dependence plots and calculating the permutation importance, which can help explain the formulations in our trained model. Both global and local explainability strategies can either be model-specific or model-agnostic. Model-specific strategies apply to certain types of models, whereas model-agnostic strategies can be applied to a wide variety of models.
The following diagram summarizes the different strategies available for machine learning explainability:
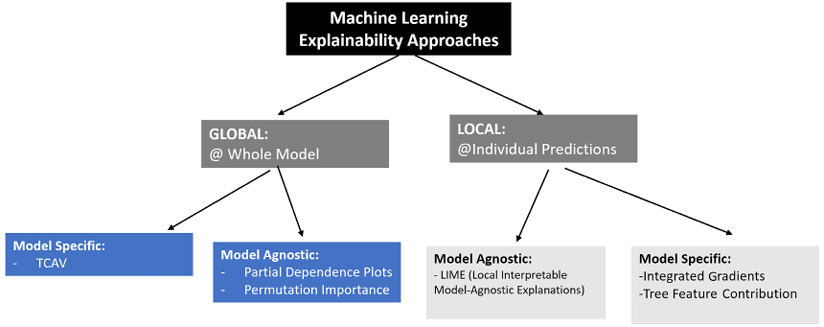
Figure 16.1: Machine learning explainability approaches
Now, let’s look at how we can implement explainability using one of these strategies.
Implementing explainability
Local Interpretable Model-Agnostic Explanations (LIME) is a model-agnostic approach that can explain individual predictions made by a trained model. Being model-agnostic, it can explain the predictions of most types of trained machine learning models.
LIME explains decisions by inducing small changes to the input for each instance. It can gather the effects on the local decision boundary for that instance. It iterates over the loop to provide details for each variable. Looking at the output, we can see which variable has the most influence on that instance.
Let’s see how we can use LIME to make the individual predictions of our house price model explainable:
- If you have never used
LIMEbefore, you need to install the package usingpip:!pip install lime - Then, let’s import the Python packages that we need:
import sklearn import requests import pickle import numpy as np from lime.lime_tabular import LimeTabularExplainer as ex - We will train a model that can predict housing prices in a particular city. For that, we will first import the dataset that is stored in the
housing.pklfile. Then, we will explore the features it has:# Define the URL url = "https://storage.googleapis.com/neurals/data/data/housing.pkl" # Fetch the data from the URL response = requests.get(url) data = response.content # Load the data using pickle housing = pickle.loads(data) housing['feature_names']array(['crime_per_capita', 'zoning_prop', 'industrial_prop', 'nitrogen oxide', 'number_of_rooms', 'old_home_prop', 'distance_from_city_center', 'high_way_access', 'property_tax_rate', 'pupil_teacher_ratio', 'low_income_prop', 'lower_status_prop', 'median_price_in_area'], dtype='<U25')Based on these features, we need to predict the price of a home.
- Now, let’s train the model. We will be using a random forest regressor to train the model. First, we divide the data into testing and training partitions and then we use it to train the model:
from sklearn.ensemble import RandomForestRegressor X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(housing.data, housing.target) regressor = RandomForestRegressor() regressor.fit(X_train, y_train)RandomForestRegressor() - Next, let us identify the category columns:
cat_col = [i for i, col in enumerate(housing.data.T) if np.unique(col).size < 10] - Now, let’s instantiate the LIME explainer with the required configuration parameters. Note that we are specifying that our label is
'price', representing the prices of houses in Boston:myexplainer = ex(X_train, feature_names=housing.feature_names, class_names=['price'], categorical_features=cat_col, mode='regression') - Let us try to look into the details of predictions. For that, first, let us import
pyplotas the plotter frommatplotlib:exp = myexplainer.explain_instance(X_test[25], regressor.predict, num_features=10) exp.as_pyplot_figure() from matplotlib import pyplot as plt plt.tight_layout()

Figure 16.2: Feature-wise explanation of a Housing Price Prediction
- As the LIME explainer works on individual predictions, we need to choose the predictions we want to analyze. We have asked the explainer for its justification of the predictions indexed as
1and35:for i in [1, 35]: exp = myexplainer.explain_instance(X_test[i], regressor.predict, num_features=10) exp.as_pyplot_figure() plt.tight_layout()
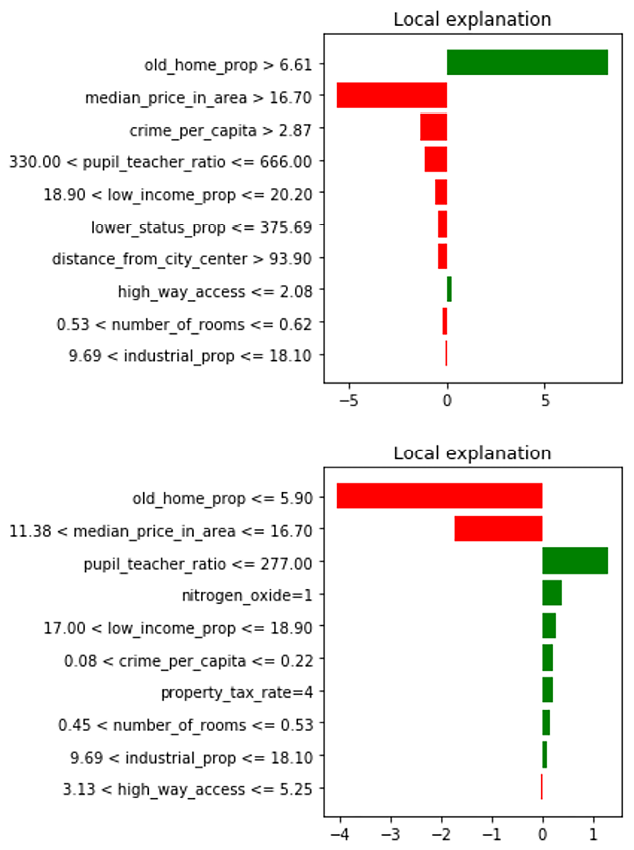
Figure 16.3: Highlighting key features: Dissecting predictions for test instances 1 and 35
Let’s try to analyze the preceding explanation by LIME, which tells us the following:
- The list of features used in the individual predictions: They are indicated on the y-axis in the preceding screenshot.
- The relative importance of the features in determining the decision: The larger the bar line, the greater the importance is. The value of the number is on the x-axis.
- The positive or negative influence of each of the input features on the label: Red bars show a negative influence and green bars show the positive influence of a particular feature.
Understanding ethics and algorithms
Algorithmic ethics, also known as computational ethics, delves into the moral dimensions of algorithms. This crucial domain aims to ensure that machines operating on these algorithms uphold ethical standards. The development and deployment of algorithms may inadvertently foster unethical outcomes or biases. Crafting algorithms poses a challenge in anticipating their full range of ethical repercussions. When we discuss large-scale algorithms in this context, we refer to those processing vast volumes of data. However, the complexity is magnified when multiple users or designers contribute to an algorithm, introducing varied human biases. The overarching goal of algorithmic ethics is to spotlight and address concerns arising in these areas:
- Bias and discrimination: There are many factors that can affect the quality of the solutions created by algorithms. One of the major concerns is unintentional and algorithmic bias. The reason may be the design of the algorithm resulting in giving some data more importance than other data. Or, the reason may be in the data collection and selection of data. It may result in data points that should be computed by the algorithm being omitted, or data that shouldn’t be involved being included. An example is the use of an algorithm by an insurance company to calculate risk. It may be using data about car accidents that includes the gender of drivers involved. Based on the data available, the algorithm might decide that women are involved in more crashes and therefore women drivers automatically receive higher-cost insurance quotes.
- Privacy: The data used by algorithms may have personal information and may be used in ways that could intrude on the privacy of individuals. For example, the algorithms that enable facial recognition are one example of the privacy issues that are caused by the use of algorithms. Currently, many cities and airports are using facial recognition systems around the world. The challenge is to use these algorithms in a way that protects individuals against any privacy breaches.
More and more companies are making the ethical analysis of an algorithm part of its design. But the truth is that problems may not become apparent until we find a problematic use case.
Problems with learning algorithms
Algorithms capable of fine-tuning themselves according to changing data patterns are called learning algorithms. They are in learning mode in real time, but this real-time learning capability may have ethical implications. This creates the possibility that their learning could result in decisions that may have problems from an ethical point of view. As they are created to be in a continuous evolutionary phase, it is almost impossible to continuously perform an ethical analysis of them.
For example, let us study the problem that Amazon discovered in the learning algorithm they designed to hire people. Amazon started using an AI algorithm for hiring employees in 2015. Before it was deployed, it went through stringent testing to make sure that it met both functional and non-functional requirements and had no bias or any other ethical issue. As it was designed as a learning algorithm, it was constantly fine-tuning itself with new data as it became available. A couple of weeks after it was deployed, Amazon discovered that the AI algorithm had surprisingly developed a gender bias. Amazon took the algorithm offline and investigated. It was found that gender bias was introduced due to some specific patterns in the new data. Specifically, in recent data, there were far more men than women. And the men in the recent data happened to have a more relevant background for the job posted. The real-time fine-tuning learning had some unintentional consequences and resulted in the algorithm starting to favor men over women, thus introducing bias. The algorithm started using gender as one of the deciding factors for hiring. The model was re-trained and necessary safety guardrails were added to make sure that gender bias was not re-introduced.
As the complexity of algorithms grows, it is becoming more and more difficult to fully understand their long-term implications for individuals and groups within society.
Understanding ethical considerations
Algorithmic solutions are mathematical formulations. It is the responsibility of the people responsible for developing algorithms to ensure that they conform to ethical sensitivities around the problem we are trying to solve. Once the solutions are deployed, they may need to be periodically monitored to make sure that they do not start creating ethical issues as new data becomes available and underlying assumptions shift.
These ethical considerations of algorithms depend on the type of the algorithm. For example, let’s look into the following algorithms and their ethical considerations. Some examples of powerful algorithms for which careful ethical considerations are needed are as follows:
- Both classification and regression algorithms serve distinct purposes in machine learning. Classification algorithms categorize data into predefined classes and can be directly instrumental in decision-making processes. For instance, they might determine visa approvals or identify specific demographics in a city. On the other hand, regression algorithms predict numerical values based on input data, and these predictions can indeed be utilized in decision-making. For example, a regression model might predict the optimal price for listing a house on the market. In essence, while classification offers categorical outcomes, regression provides quantitative predictions; both are valuable for informed decision-making in varied scenarios.
- Algorithms, when used in recommendation engines, can match resumes to job seekers, both for individuals and groups. For such use cases, the algorithms should implement the explainability at both a local and global level. Local-level explainability will provide traceability for a particular individual resume when matched to available jobs. Global-level explainability will provide transparency of the overall logic being used to match resumes to jobs.
- Data mining algorithms can be used to mine information about individuals from various data sources that may be used by governments for decision-making. For example, the Chicago police department uses data mining algorithms to identify criminal hotspots and high-risk individuals in the city. Making sure these data mining algorithms are designed and used in a way that satisfies all requirements related to ethics is done through careful design and constant monitoring.
Hence, the ethical consideration of algorithms will depend on the particular use case they are used in and the entities they directly or indirectly affect. Careful analysis is needed from an ethical point of view before starting to use an algorithm for critical decision-making. These ethical considerations should be part of the design process.
Factors affecting algorithmic solutions
The following are the factors that we should keep in mind while performing an analysis of how good algorithmic solutions are.
Considering inconclusive evidence
In machine learning, the quality and breadth of your dataset play crucial roles in the accuracy and reliability of your model’s outcomes. Often, data might appear limited or may lack the comprehensive depth required to provide a conclusive result.
For instance, let’s consider clinical trials: if a new drug is tested on a small group of people, the results might not comprehensively reflect its efficacy. Similarly, if we examine patterns of fraud in a particular postal code of a city, limited data might suggest a trend that isn’t necessarily accurate on a broader scale.
It’s essential to differentiate between “limited data” and “inconclusive evidence.” While most datasets are inherently limited (no dataset can capture every single possibility), the term ‘inconclusive evidence’ refers to data that doesn’t provide a clear or definitive trend or outcome. This distinction is vital as basing decisions on inconclusive patterns could lead to errors in judgment. Always approach decision-making with a critical eye, especially when working with algorithms trained on such data.
Decisions that are based on inconclusive evidence are prone to lead to unjustified actions.
Traceability
Machine learning algorithms typically have separate development and production environments. This can potentially create a disconnection between the training phase and the inference phase. It means that if there is some harm caused by an algorithm, it is very hard to trace and debug. Also, when a problem is found in an algorithm, it is difficult to actually determine the people who were affected by it.
Misguided evidence
Algorithms are data-driven formulations. The Garbage-in, Garbage-out (GIGO) principle means that results from algorithms can only be as reliable as the data on which they are based. If there are biases in the data, they will be reflected in the algorithms as well.
Unfair outcomes
The use of algorithms may result in harming vulnerable communities and groups that are already at a disadvantage.
Additionally, the use of algorithms to distribute research funding has been proven on more than one occasion to be biased toward the male population. Algorithms used for granting immigration are sometimes unintentionally biased toward vulnerable population groups.
Despite using high-quality data and complex mathematical formulations, if the result is an unfair outcome, the whole effort may bring more harm than benefit.
Let us look into how we can reduce the bias in models.
Reducing bias in models
As we have discussed, the bias in a model is about certain attributes of a particular algorithm that cause it to create unfair outcomes. In the current world, there are known, well-documented general biases based on gender, race, and sexual orientation. It means that the data we collect is expected to exhibit those biases unless we are dealing with an environment where an effort has been made to remove them before collecting the data.
Most of the time, bias in algorithms is directly or indirectly introduced by humans. Humans introduce bias either unintentionally through negligence or intentionally through subjectivity. One of the reasons for human bias is the fact that the human brain is vulnerable to cognitive bias, which reflects a person’s own subjectivity, beliefs, and ideology in both the data process and logic creation process of an algorithm. Human bias can be reflected either in data used by the algorithm or in the formulation of the algorithm itself. For a typical machine learning project following the CRISP-DM (short for Cross-Industry Standard Process) lifecycle, which was explained in Chapter 5, Graph Algorithms, the bias looks like the following:
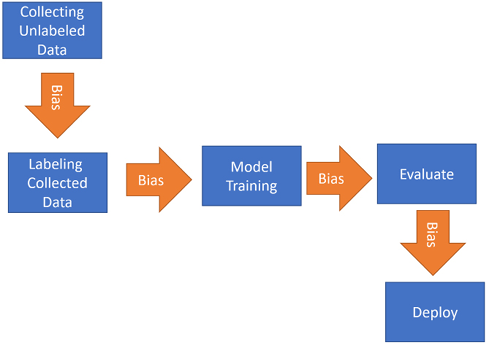
Figure 16.4: Bias can be introduced in different phases of the CRISP-DM lifecycle
The trickiest part of reducing bias is to first identify and locate unconscious bias.
Let us look into when to use algorithms.
When to use algorithms
Algorithms are like tools in a practitioner’s toolbox. First, we need to understand which tool is the best one to use under the given circumstances. Sometimes, we need to ask ourselves whether we even have a solution for the problem we are trying to solve and when the right time to deploy our solution is. We need to determine whether the use of an algorithm can provide a solution to a real problem that is actually useful, rather than the alternative. We need to analyze the effect of using the algorithm in terms of three aspects:
- Cost: Can use justify the cost related to the effort of implementing the algorithm?
- Time: Does our solution make the overall process more efficient than simpler alternatives?
- Accuracy: Does our solution produce more accurate results than simpler alternatives?
To choose the right algorithm, we need to find the answers to the following questions:
- Can we simplify the problem by making assumptions?
- How will we evaluate our algorithm?
- What are the key metrics?
- How will it be deployed and used?
- Does it need to be explainable?
- Do we understand the three important non-functional requirements—security, performance, and availability?
- Is there any expected deadline?
Upon selecting an algorithm based on the above-mentioned criteria, it’s worth considering that while most events or challenges can be anticipated and addressed, there are exceptions that defy our traditional understanding and predictive capabilities. Let us look into this in more detail.
Understanding black swan events and their implications on algorithms
In the realm of data science and algorithmic solutions, certain unpredictable and rare events can present unique challenges. Coined by Nassim Taleb in “Fooled by Randomness” (2001), the term “black swan event” metaphorically represents such rare and unpredictable occurrences.
To qualify as a black swan event, it must satisfy the following criteria:
- Unexpectedness: The event surprises most observers, like the atomic bomb drop on Hiroshima.
- Magnitude: The event is disruptive and significant, akin to the Spanish flu outbreak.
- Post-event predictability: After the event, it becomes apparent that if clues had been noted, the event could’ve been anticipated, like overlooked signs before the Spanish flu became a pandemic.
- Not a surprise to all: Some individuals might’ve anticipated the event, as the scientists involved in the Manhattan Project did with the atomic bomb.
Before black swans were first discovered in the wild, for centuries, they were used to represent something that could not happen. After their discovery, the term remained popular but there was a change in what it represented. It now represents something so rare that it cannot be predicted.
Challenges and opportunities for algorithms with black swan events:
- Forecasting dilemmas: While there are numerous forecasting algorithms, from ARIMA to deep learning methodologies, predicting a black swan event remains elusive. Using standard techniques might provide a false sense of security. Predicting the exact timing of another event, like COVID-19, for example, is fraught with challenges due to insufficient historical data.
- Predicting implications: Once a black swan event occurs, foreseeing its broad societal impacts is complex. We may lack both the relevant data for the algorithms and an understanding of societal interrelations affected by the event.
- Predictive potential: While black swan events appear random, they result from overlooked complex precursors. Herein lies an opportunity for algorithms: devising strategies to predict and detect these precursors might help anticipate a potential black swan event.
The relevance of a practical application:
Let’s consider the recent COVID-19 pandemic, a prime black swan event. A potential practical application might involve leveraging data on prior pandemics, global travel patterns, and local health metrics. An algorithm could then monitor for unusual spikes in illness or other potential early indicators, signaling a potential global health threat. However, the uniqueness of black swan events makes this challenging.
Summary
In this chapter, we learned about the practical aspects that should be considered while designing algorithms. We looked into the concept of algorithmic explainability and the various ways we can provide it at different levels. We also looked into the potential ethical issues in algorithms. Finally, we described which factors to consider while choosing an algorithm.
Algorithms are engines in the new automated world that we are witnessing today. It is important to learn about, experiment with, and understand the implications of using algorithms. Understanding their strengths and limitations and the ethical implications of using algorithms will go a long way in making this world a better place to live in, and this book is an effort to achieve this important goal in this ever-changing and evolving world.
Learn more on Discord
To join the Discord community for this book – where you can share feedback, ask questions to the author, and learn about new releases – follow the QR code below:
