
13. SQL Server 2005 and Clients
WITH THE ADVENT OF CLR user-defined types, as well as improved large value type data support, XML support, and other SQL Server engine features, comes enhancement of the client APIs. This chapter looks at the enhancements to the ADO.NET client libraries as well as the classic data access APIs—OLE DB, ADO, and ODBC—to support new SQL Server 2005 features.
SQL Native Client
SQL Server ships with support for four main data access APIs currently used in client-side programming:
• ADO.NET
• OLE DB and ADO
• ODBC
• JDBC
ADO.NET is the managed data access layer for the .NET Framework. If you’re using the .NET Framework in your client-side code, the ADO.NET data provider, System.Data.SqlClient, is your best choice. It is more powerful and has better performance than using either the ADO.NET OleDb or Odbc bridge data providers with SQL Server. The OleDb and Odbc bridges were provided mostly for compatibility with those data sources for which a managed ADO.NET data provider doesn’t exist. OLE DB is a data access API based on the Component Object Model (COM), and ODBC is a vendor-neutral set of APIs based on C-style calls. If you are not using the .NET Framework or Java for your client application, you’re most likely using OLE DB or ODBC for data access. OLE DB and ODBC are still very much used inside the SQL Server 2005 database as well. SQL Server–linked servers are still configured using OLE DB providers, for example. Microsoft ships a JDBC driver for SQL Server 2005, but coverage of this driver is beyond the scope of this book.
If you are using ADO.NET, you must use the latest version of the .NET Framework, version 2.0, to use the cornucopia of new SQL Server 2005 features. That means you must deploy the .NET Framework 2.0 runtime to every Web server or client workstation that talks to SQL Server 2005. If you are using OLE DB or ODBC, you must use SQL Native Client to get at the new features. Older versions of all the APIs (ADO.NET 1.0 and 1.1, and the OLE DB provider and ODBC driver in MDAC) are still supported at the SQL Server 2000 level of functionality.
Support for the new features in SQL Server 2005 involved a refactoring of the client-side functionality for the traditional data access APIs and in removal of the dependency between ADO.NET and Microsoft Data Access Components (MDAC). In the OLE DB and ODBC data access arena, there is a new, separate client-side OLE DB provider and ODBC driver: SQL Native Client. If you want to use the new features of SQL Server 2005, such as multiple active resultsets or Query Notifications from OLE DB, ADO, or ODBC, you’re going to need this new client stack.
SQL Native Client is meant to separate SQL Server’s OLE DB provider, ODBC driver, and network library calls from the MDAC stack. Currently, the SQL Server OLE DB provider (SQLOLEDB) and ODBC driver (listed as SQL Server in the driver list) ship as part of MDAC. This provider and driver will continue to be supported at a pre–SQL Server 2005 level of functionality, but their functionality will not be upgraded. A new version of MDAC (called MDAC 9.0) was originally planned to support the new SQL Server 2005 functionality, but this didn’t happen. Instead, the current components of MDAC have become part of the Windows family of operating systems, most likely along with the next operating system Service Pack. MDAC will change infrequently, and changes will not be tied to new SQL Server functionality. SQL Native Client will be versioned with new versions of SQL Server (starting at SQL Server 2005), will ship with SQL Server, and can keep current with server improvements. If you’ve installed SQL Server 2005, you can see SQL Native Client in the Install and Remove Programs Control Panel applet.
When you’ve installed SQL Native Client, you should see a new OLE DB provider (SQLNCLI, listed as “SQL Native Client”) and a new ODBC driver (listed as “SQL Native Client”). You need to use them instead of the older versions to get the SQL Server 2005–specific functionality. Note that they need to be coded into the connection string (OLE DB, ADO, or ODBC) or ODBC DSN. SQL Native Client does have a limitation—it does not run on Windows 9x (Windows 95 and 98) operating systems—so keep this in mind as you plan your upgrade.
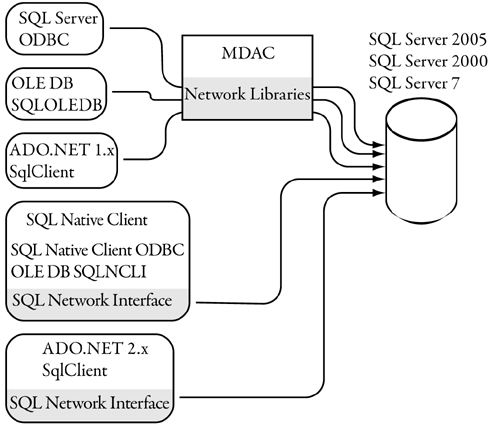
If you’re using ADO.NET’s SqlClient data provider, it has been rearchitected so it doesn’t rely on MDAC or SQL Native Client. The calls it makes to SQL Server over the network, which used to be supported through separate network libraries, use a facility known as SNI (SQL Server Network Interface), and this facility is separate from analogous SNI calls made in the SQL Native Client. That’s good news, because you have to be concerned with only one data access piece instead of two, as Figure 13-1 shows.
Figure 13-1. Network library functionality in ADO.NET 2.0 SqlClient and in SQL Native Client
Now that you are wondering what specific feature support you get by using SQL Native Client or ADO.NET 2.0, we’ll just say these are the features covered in this chapter, namely:
• Support of the SQL Server 2005 data types
• Query Notifications
• Multiple active resultsets
• Password change for SQL logins
• Promotable transactions (ADO.NET only)
• Automatic client failover
• Support for the self-signed certificates generated by SQL Server 2005
As we discuss each feature, we’ll begin with an exposition of the functionality in ADO.NET and conclude with a short description of where the functionality resides in the SQL Server Client APIs. ADO.NET does have better support and extended support in the API for certain new features.
For those of you who currently use ADO (classic ADO rather than ADO.NET), you may be worried because ADO itself (msado15.dll and friends) are part of MDAC, and we’ve just said that MDAC won’t change for SQL Server 2005. ADO users can use the new features through the new OLE DB provider (SQLNCLI), because the new features have been exposed on this provider using special connection-string parameters or extended properties on the ADO Connection and Command object.
When you are converting an application to use the new provider or driver, you’ll notice very few changes. SQL Native Client has been designed with backward compatibility in mind. As with any conversion, of course, you should retest your applications. One small difference in existing functionality that we noticed was that if you are using named parameters in OLE DB, the parameter names must be valid (must begin with an at sign). Using named parameters and incorrect SQL parameter names with SQLNCLI will cause an error; with SQLOLEDB, this is OK. You can also choose to use positional parameters and leave the names out, but if you do specify parameter names in SQLNCLI, they must be correct names. Another difference is that the SQLNCLI provider does not support all the client-side provider-specific functionality in SQLOLEDB—namely, support for the ICommandStream interface used with a small subset of the SQL Server 2000 XML functionality. This functionality has largely been superseded by the XML data type functionality in SQL Server 2005.
The new OLE DB provider does have two new features that are not in the SQLOLEDB provider. The first is that SQLNCLI implements support for asynchronous connections and asynchronous commands directly. This is accomplished by implementing the IDBAsyncStatus interface on the OLE DB Session and Command objects. SQL Server’s OLE DB provider actually goes one step further and implements a provider-specific interface, ISSAsyncStatus, to provide more functionality in this area. For more information on using asynchronous connections and commands with OLE DB, consult “OLE DB Programmer’s Reference” in the MSDN documentation, and SQL Server Books Online for SQL Server specifics. Note that this built-in asynchrony is not consumed by ADO; this library has its own way to implement asynchronous operations. It uses additional library threads instead of implementing the functionality in the network protocol. The SQL Native Client OLE DB provider also exposes an interface for programming bulk copy, IBCPSession, in addition to IRowset-FastLoad for memory-based bulk loading. In previous versions, programmatic bulk copy (BCP) functionality was available only through ODBC. There also are new implementations of ISQLServerErrorInfo to provide more comprehensive error information and ISSAbort to cancel executing SQL commands and batches.
New Data Types and Data Type Compatibility Mode
The change in SQL Server 2005 that has the most pervasive impact on the new provider and driver is the new data types—namely, the XML data type, CLR user-defined types, and large value types. If you simply convert existing programs by switching to the new SQL Native Client providers or ADO.NET 2.0 SqlClient data provider, and then use the new types in your SQL Server 2005 database, it’s quite possible that parts of the program that inspect a rowset’s column information, parameter information, or schema metadata may fail. To ease conversion, you can set the connection-string parameter setting DataTypeCompatibility=80 in OLE DB or Type System Version=SQL Server 2000 in ADO.NET. It’s not yet supported for ODBC but due to be supported in the next SQL Server release. In this case, the new data types will be represented as their closest possible SQL Server 2000 data type. VARCHAR(MAX) may show up in metadata as NTEXT, for example. We’ll have more to say on this in the discussion of new data type support for each of the types in question.
User-Defined Types and Relational Data Access APIs
SQL Server 2005 offers inside-the-database support for some new data types. Although basic support of the new VARCHAR(MAX) data types is straightforward, the user-defined types and the XML data type are complex types. Because we’d like to deal with the user-defined types and XML in its native form on the client as well as on the server, the client APIs need to be enhanced as well. In the book Essential ADO.NET, by Bob Beauchemin (Addison-Wesley, 2002), Bob speculated on the challenges of adding UDT support to the .NET Framework DataSet. We’ll also discuss how this is supported with SQL Server 2005 UDTs.
Most client application programming interfaces designed for use with relational databases were not designed with complex-type features built in. The original database-independent library, ODBC, was tailored specifically around SQL:1992–style database operations. It was not updated when extended types were introduced into the SQL standard in SQL:1999. Each ODBC column binding was supposed to refer to an ODBC-defined data type; user-defined types were not recognized as ODBC types. The COMbased data access APIs, OLE DB and ADO, were designed with some thought given to UDTs; there is an OLE DB DBTYPE_UDT, and ADO maps this data type to its adUserDefined data type. DBTYPE_UDT, however, was meant to be used to bind to data as COM objects, binding the data by using the COM interface IUnknown or IDispatch.
Though ADO.NET was not designed with user-defined types in mind either, this is the client-side library that programmers using SQL Server 2005 are most likely to use. ADO.NET does contain rich support for mixing relational and XML data, however. Combined with the fact that userdefined types are actually .NET Framework types (classes and structures), this gives ADO.NET the tightest and richest integration with the new extended SQL Server type model.
Using .NET Framework UDTs in ADO.NET
When we deal with UDTs from clients in ADO.NET, we’ll usually be storing them in tables or retrieving them from tables. The “instance” of the UDT is actually stored in the database, and we manipulate it in place. We can do this all from the client by using conversion from strings or through carefully thought-out mutator functions, regardless of the API. Listing 13-1 shows a simple example in ADO.NET.
Listing 13-1. Manipulating a UDT inside the server
/*
assuming a UDT called LDim that has an "Inches" property
and a table dbo.Tiles defined like this:
CREATE TABLE dbo.Tiles(
id INTEGER,
length LDim,
width LDim)
*/
string connect_string = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(connect_string);
SqlCommand cmd = new SqlCommand();
cmd.Connection = conn;
conn.Open();
cmd.CommandText =
"INSERT INTO dbo.Tiles VALUES(1, '10 ft, 8 in')";
int i;
i = cmd.ExecuteNonQuery();
cmd.CommandText =
@"UPDATE dbo.Tiles
SET Length.ToIn()
WHERE id = 1";
i = cmd.ExecuteNonQuery();
cmd.Dispose(); conn.Dispose();
Note
Everywhere we use a connection string in an example program, we obtain it through a pseudocode method named GetConnectStringFromConfigFile. It’s not a good idea to hard-code connection strings in program code. You can either get them from your own location in a configuration file or, in ADO.NET 2.0, use the ConfigurationManager.ConnectionStrings collection that’s provided in System.Configuration.dll.)
Note that in this example, we’re using the LDim type only on the server, passing in string values to INSERT and integer values to UPDATE through the mutator. We don’t have to have access to the LDim type code on the client at all.
It is possible to manipulate user-defined types from client code by using only SQL statements, stored procedures, and user-defined functions. Instances of user-defined types will not ordinarily be held in the database past the end of a SQL batch, however. If we want to manipulate the same instance of the UDT over multiple batches, we could store it in a SQL Server temporary table, but this would incur the overhead of serializing and deserializing the instance (from the temporary table) each time we access it.
New functionality in ADO.NET permits the use of UDT code in client programs as well as server programs. You can deploy the UDT code to each client as part of a program’s installation process. You can early-bind to UDT code if you reference it in an application or use .NET Framework reflection to use late binding. You can also use UDTs as stored procedures or userdefined function parameters. Let’s see how this would look in code.
Fetching UDT Data from a DataReader
In the preceding simple example, we did all the UDT manipulations in code on the server side. We didn’t need the UDT on the client at all. But we could also change the statement to fetch the entire UDT over to the client via a SqlDataReader. The code would start by looking like Listing 13-2.
Listing 13-2. Fetching a UDT through SqlDataReader; no compile-time reference
// Use the same Tiles table as in the first example.
string connect_string = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(connect_string);
SqlCommand cmd = new SqlCommand();
cmd.Connection = conn;
conn.Open();
// get the entire LDim column
cmd.CommandText = "SELECT id, length FROM dbo.Tiles";
SqlDataReader rdr = cmd.ExecuteReader();
while (rdr.Read())
{
// rdr["Length"] contains an instance of a LDim class
// easiest access, WriteLine calls ToString() implicitl
Console.WriteLine("column 1 is {0}", rdr["Length"]);
}
rdr.Close();
cmd.Dispose();
conn.Dispose();
The LDim class inside the DataReader can be used in a few different ways, but the bottom line is always the same. To manipulate the LDim—including the simplest method, which consists of returning a string representation of it—the code for the LDim class has to exist on the client. If you’ve not deployed it, the code exists only inside the SQL Server instance. When the attempt to load the LDim class using normal assembly loader mechanisms fails, the ADO.NET client code will throw an exception. Although the information in the TDS data stream is sufficient to “fill in” an instance of the LDim class that exists on the client, it is not sufficient to instantiate a LDim if the assembly does not exist on the client. It’s more like an opaque binary blob. There is additional information in the TDS stream to identify the class name and the assembly version, however. The UDT assembly must be deployed into the global assembly cache (GAC) or available in the caller’s assembly probing path, or instantiating it on the client will fail.
In addition to retrieving the information from the LDim class, you can create an instance of LDim directly for every row read through the DataReader by getting the value of the column and casting it to the correct type, as shown in Listing 13-3.
Listing 13-3. Fetching a UDT through SqlDataReader; compile-time reference required
while (rdr.Read())
{
// rdr["length"] contains an instance of a LDim class
// get a strongly typed instance
LDim ld = (LDim)rdr["length"];
}
Note that the big difference between using ToString and using the code in Listing 13-2 is that you must have an assembly containing the LDim class available at compile time as a reference. This method probably will be used most often because it lets you deal with the SQL Server CLR classes as though they were “normal” client classes, with special data access methods based on the fact that they can be persisted.
There are a few slight performance optimizations based on either dealing with the instance as a stream of bytes or using your own object serialization code. If you just want to pass the stream of bytes around without deserializing it—for example, to perform a kind of manual object replication—you can use GetBytes or GetSqlBytes to read the bytes as a binary stream. If you have implemented your own serialization using IBinarySerialize or want to hook the serialized form into a .NET Framework technology like remoting, you can pass the bytes around and deserialize them manually. Except in applications that need a very high degree of optimization, the small performance gain is not worth the increase in code complexity.
When you get an instance of a UDT through a DataReader using any of the methods shown earlier, it is not a reference to the data in the DataReader directly; you are making a copy. The instance data in the DataReader itself is read-only, but the data in the copy can be updated. When you update the data, accessing the data again from the DataReader will return the original data, not the changed data. Listing 13-4 shows an illustrative example.
Listing 13-4. UDT retrieved is a copy of the UDT in the SqlDataReader
// SqlDataReader obtained from the previous code
LDim p1, p2;
rdr = cmd.ExecuteReader();
while (rdr.Read())
{
// rdr[1] contains an instance of a LDim class
// p1 is a copy of rdr[1]
p1 = (LDim)rdr[1];
// attempting to update this will work
p1.Inches = 1000;
// retrieve the value in the DataReader again
p2 = (LDim)rdr[1];
// now p1 != p2
}
This covers almost every case in which we’d want to access a UDT from a DataReader. But what if we were writing a generic access layer, had a library of types loaded, and wanted to know the type so that we could instantiate the correct strongly typed class at runtime? Or what if we wanted to be able to specify a UDT as a parameter in a parameterized query, stored procedure, or user-defined function?
The way to get information about a DataReader’s columns at runtime in ADO.NET is to use the method SqlDataReader.GetSchemaTable. This method has been extended to provide two UDT-specific pieces of information in ADO.NET 2.0: the .NET Framework class name and the name of the UDT in SQL Server. Note that the CREATE TYPE DDL statement does not mandate that the SQL Server type object name be the same as the .NET Framework class name. The “database name” of a UDT is the SQL Server object name (for example, demo.dbo.LDim), and the .NET Framework name is a string containing a four-part CLR type name, including assembly (for example, LDim, Dimension.dll, Version=1.0.0.0, Culture=neutral, PublicKeyToken=bac3c561934e089). GetSchemaTable returns a DataTable containing one row of information about each column in the resultset, and using it in our code would look like Listing 13-5.
Listing 13-5. Getting metadata about a UDT on the client
SqlDataReader rdr = cmd.ExecuteReader();
DataTable t = rdr.GetSchemaTable();
// either of these print Dimensions.LDim,
// the .NET Framework class name
// prints byte[] if "Type System Version=SQL Server 2000"
Console.WriteLine(t.Rows[1]["DataType"]);
// prints SqlBinary if "Type System Version=SQL Server 2000"
Console.WriteLine(t.Rows[1]["ProviderSpecificDataType"]);
// this prints demo.dbo.LDim, SQL Server name for UDT
// prints varbinary if "Type System Version=SQL Server 2000"
Console.WriteLine(t.Rows[1]["DataTypeName"]);
// this prints 4-part assembly name,
// blank if "Type System Version=SQL Server 2000"
Console.WriteLine(t.Rows[1]["UdtAssemblyQualifiedName"]);
// Prints 21 (varbinary) if "Type System Version=SQL Server 2000"
// else prints 29
Console.WriteLine(t.Rows[1]["ProviderType"]);
// Always prints 29 (SQLCLR UDT)
Console.WriteLine(t.Rows[1]["NonVersionedProviderType"]);
A typical row in the DataTable of schema information would contain columns of information about the data. In other rowset metadata, although the SqlDbType is present, this does not completely describe the UDT, and the SqlDbType would be SqlDbType.SqlUdt. Using GetSchemaTable is the only API that permits getting rich UDT information. Note that the provider type and other information change when SQL Server 2000 client compatibility mode is used; in this case, the UDT appears as a byte array (varbinary in SQL Server).
We have a similar issue when we go to set the data type of a SqlParameter. Only SqlDbType is actually specified using the current implementation of DbParameter or IDbParameter. In addition to using SqlDbType for a UDT parameter, you need to specify the SqlParameter.UdtTypeName when using UDT parameters in a parameterized query.
Let’s look at calling a user-defined function that adds two LDim instances together, returning another LDim instance as the result. Such a user-defined function, LDimAdd, is part of the LDim class itself. Refer to Chapter 5 for details.
Alternatively, the UDF could be defined in Transact-SQL (T-SQL) using the T-SQL definition of the type and the .NET Framework implementation of the LDim class, as shown in Listing 13-6.
Listing 13-6. TSQL implementation of user-defined function that uses a UDT
--
-- T-SQL implementation of AddLDim
--
CREATE FUNCTION AddLDim2 (@a LDim, @b LDim)
RETURNS LDim
AS
BEGIN
DECLARE @c LDim
SET @c = '0 in' – set the units
SET @c.Inches = @a.Inches + @b.Inches
RETURN @c
END
GO
Because no data access is done in adding two LDims together, it might be best to implement this operation either completely on the server side (call the LDim UDF from another UDF or a SQL statement) or all on the client side (instantiate two LDim objects and add them on the client) rather than calling from client to server, but we’ll use this example to demonstrate calling a parameterized function from the client.
To invoke the UDF from the client, we’ll need to instantiate a SqlCommand and add the parameters to its ParametersCollection, the Parameters property of the SqlCommand. The code would look like Listing 13-7.
Listing 13-7. Using UDTs as parameters (naïve implementation)
string connect_string = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(connect_string);
SqlCommand cmd = new SqlCommand("dbo.AddLDim", conn);
cmd.CommandType = CommandType.StoredProcedure;
// define two LDims to add
LDim p1 = LDim.Parse("2 ft");
LDim p2 = LDim.Parse("10 in");
// now, define the Parameters
// use the overload that takes a parameter name
// and type for the input parameters
cmd.Parameters.Add("@a", SqlDbType.Udt);
cmd.Parameters[0].Value = p1;
cmd.Parameters.Add("@b", SqlDbType.Udt);
cmd.Parameters[1].Value = p2;
// define the output parameters. This parameter need not be initialized
cmd.Parameters.Add("@c", SqlDbType.Udt);
cmd.Parameters[2].Direction = ParameterDirection.ReturnValue;
This code is incomplete because although the client is telling SQL Server that the Parameter contains a user-defined type, there is no indication of which user-defined type we’re passing in! We need to specify the correct metadata to SQL Server. This consists of the UdtTypeName—that is, the name that SQLServer uses to identify the type. This name need not be fully qualified, but we’re doing this to make it clear which name is required. When SQL Server has the correct name, it can check to see that we’re passing in the correct parameter type and then invoke the UDF. We specify the type name using the SqlParameter class. Our finished code would look like Listing 13-8.
Listing 13-8. SQL Server data type must be used when using UDTs as parameters
// now, define the Parameters
// use the overload that takes a parameter name
// and type for the input parameters
cmd.Parameters.Add("@a", SqlDbType.Udt);
cmd.Parameters[0].UdtTypeName = "demo.dbo.LDim";
cmd.Parameters[0].Value = p1;
cmd.Parameters.Add("@b", SqlDbType.Udt);
cmd.Parameters[1].Value = p2;
cmd.Parameters[1].UdtTypeName = "demo.dbo.LDim ";
// define the output parameters. This parameter need not be initialized
cmd.Parameters.Add("@c", SqlDbType.Udt);
cmd.Parameters[2].UdtTypeName = "demo.dbo.LDim";
cmd.Parameters[2].Direction = ParameterDirection.ReturnValue;
Using .NET Framework UDTs in ODBC, OLE DB, and ADO Clients
The SQL Native Client OLE DB provider and ODBC driver have some special functionality with respect to the new UDT types, although none of these APIs can get .NET Framework–based UDTs as though they were COM objects. Even though there are facilities to build a COM-callable wrapper around any .NET Framework object, fetching these as COM objects is specifically unsupported by the SQLNCLI data provider. The metadata in the new providers and drivers can report on and consume rich data about these types, however.
Any database API will be able to get a string representation of these types. You’d do this by using ToString in the SQL SELECT statement and retrieving the data as a SQL_WVARCHAR or SQL_WLONGVARCHAR(ODBC) or DBTYPE_WSTR(OLE DB) data type. Alternatively, you can select the entire UDT column and get the binary representation as a SQL_VARBINARY or SQL_LONGVARBINARY type (ODBC) or DBTYPE_BYTES (OLE DB). Note that this could also return the XML representation if the UDT were converted to XML format on the server. The SQL statements to accomplish this are pretty straightforward and are shown in Listing 13-9.
Listing 13-9. T-SQL code to access UDT; results obtained in ODBC
--
-- SQL statements to enable getting LDim
-- as a SQL_WVARCHAR/SQL_WLONGVARCHAR
--
SELECT id, length.ToString() AS dim_str
FROM dbo.Tiles
GO
--
-- SQL statements to enable getting LDim
-- as a SQL_VARBINARY/SQL_LONGVARBINARY
--
SELECT id, length FROM dbo.Tiles
In all cases, you are required to reformat and use the string or binary form manually or find some way to reconstitute the data in the objects manually.
If the UDT supports public fields that are data types that SQL Server APIs support, you can use SQL statements or UDT accessor methods on the server to pull out the individual field values in a form that non–.NET Framework APIs can understand, and use SQL statements containing mutator methods on the UDT to update the values on the server. This works, as in the first ADO.NET example, because you are fetching and updating ordinary SQL types such as INTEGER or NVARCHAR, not using the UDT directly. In the case of the LDim data type mentioned earlier in this chapter, you can get the property representing dimension in inches as integers and update the fields directly or by using mutator methods on the UDT.
When you use the SQL Native Client driver or provider, you are able to see that the data type of a column or parameter is a UDT when the T-SQL statement specifies a UDT column or parameter. These APIs also provide additional metadata information for UDTs when using IDBSchemaRowset::GetSchemaRowset in OLE DB.
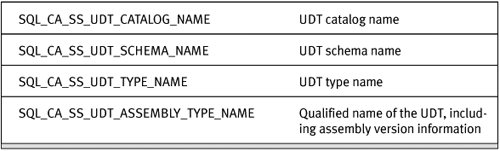
When using the SQL Native Client ODBC driver, you’ll get the UDT as a new SQL Server–specific data type, SQL_SS_UDT. You can get four additional properties of the UDT using SQLDescribeCol. These are shown in Table 13-1.
Table 13-1. ODBC Metadata Columns for UDTs
In OLE DB and ADO, support is a bit richer. Using the SQLNCLI provider, the UDT is returned as DBTYPE_UDT. There is no additional metadata for columns in OLE DB by using IColumnInfo::GetColumnInfo, but analogous information to the ODBC information above is returned when you use IColumnsRowset::GetColumnsRowset. The four additional columns are shown in Table 13-2.
Table 13-2. OLE DB Metadata Columns for UDTs

This data also appears as extended properties in ADO’s Field Object Properties collection. In OLE DB and ADO, there is additional support for UDT parameters as well. This is exposed through a special interface, ISSCommandWithParameters, that extends IDBCommandWithParameters. The two methods, GetParameterProperties and SetParameterProperties, permit using a new OLE DB property set, DBPROPSET_SQLSERVER PARAMETERS, that exposes UDT catalog name, schema name, and name. These are also exposed in the extended properties collection of ADO’s Parameter Object. In OLE DB and ADO, there is support in the DBSCHEMA_COLUMNS and DBSCHEMA_PROCEDURE_PARAMETERS for UDTs. There is also a special DBSCHEMA_SQL_USER_TYPES schema rowset that enumerates the UDTs that exist in a database, as well as DBSCHEMA_SQL_ASSEMBLIES and DBSCHEMA_SQL_ASSEMBLY_DEPENDENCIES to obtain .NET Framework assembly information.
To summarize this, you can get information and set information about UDTs in ODBC, OLE DB, and ADO. There is even additional metadata in OLE DB. But you cannot manipulate and store UDTs directly without mixing .NET Framework code with your C++ code.
Supporting the XML Data Type on the Client
SQL Server 2005 includes a new native XML data type, described in Chapter 9. Although this type can be manipulated on the server, we’d like to manipulate it using the client-side data access APIs as well.
One method for using XML is to serialize it into a string of characters. The original specification for XML (Extensible Markup Language 1.0) is a description of “a class of data objects called XML documents” and is couched entirely in terms of this serialized form. In addition to being able to work with the serialized form as a string, you can simply consume XML by using XML APIs such as DOM (Document Object Model), SAX (Simple API for XML), or the .NET Framework’s XmlReader. Both ADO (used in conjunction with MSXML) and ADO.NET provide a way to consume the XML database and use it in parameterized queries using both strings and XML APIs.
Using the XML Data Type in ADO.NET
There are two types of XML output that SQL Server 2005 can produce. The statement SELECT * FROM AUTHORS FOR XML AUTO produces a stream of XML, not a one-column, one-row rowset. This type of output is unchanged from SQL Server 2000. The XML stream output appears in SQL Server Query Analyzer as a one-column, one-row rowset only because of the limitations of the Query Analyzer tool. You can distinguish this stream from a “normal” column by its special unique identifier name, “XML_F52E2B61-18A1-11d1- B105-000805F49916B”. This name is actually an indicator to the underlying TDS (that’s Tabular Data Stream, SQL Server’s network format) parser that the column should be streamed to the client rather than sent as an ordinary rowset would be. There is a special method, SqlCommand.ExecuteXml-Reader, to retrieve this special stream on the client. In SQL Server 2005, the SELECT . . . FOR XML dialect has been enhanced in many ways, discussed in detail in Chapter 9. To mention a few of them:
• SELECT . . . FOR XML can produce XML documents as well as XML fragments.
• You can prepend a standard XSD schema to the stream.
• You can produce an XML data type column in addition to the stream.
You get your first indication that XML is now a first-class relational database type by referencing the relational data type enumerations in ADO.NET 2.0. System.Data.DbType and System.Data.SqlDbType contain additional values for DbType.Xml and SqlDbType.Xml, respectively. There is also a new class in the System.Data.SqlTypes namespace, SqlXml. This class encapsulates an XmlReader class. We’ll demonstrate by means of some simple code. Suppose that we have a SQL Server table that looks like this:
CREATE TABLE xmltest (
id INT IDENTITY PRIMARY KEY,
xmlcol XML)
You can access this table on the client using the ADO.NET 2.0 code in Listing 13-10.
Listing 13-10. Accessing an XML data type column in ADO.NET
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Xml;
void GetXMLColumn() {
string connect_string = GetConnectStringFromConfigFile();
using (SqlConnection conn = new SqlConnection(connect_string))
using (SqlCommand cmd = new SqlCommand(
"select * from xmltab", conn))
{
conn.Open();
SqlDataReader rdr = cmd.ExecuteReader();
DataTable t = rdr.GetSchemaTable();
while (rdr.Read())
{
SqlXml sx = rdr.GetSqlXml(1);
XmlReader xr = sx.CreateReader();
xr.Read();
Console.WriteLine(xr.ReadOuterXml());
}
}
}
The column metadata that is returned when we browse through the DataTable produced by GetSchemaTable correctly identifies the column:
ProviderType: 25 (25 = XML)
ProviderSpecificDataType: System.Data.SqlTypes.SqlXml
DataType: System.Xml.XmlReader
DataTypeName: [blank]
It looks like any other type that’s built in to SQL Server. Note that the “.NET Framework type” of this column is XmlReader, and to the .NET Framework, it looks just like any XML that is loaded from a file or produced with the XmlDocument class. Using the XML data type column as a parameter in a stored procedure or parameterized statement in ADO.NET 2.0 is just as straightforward, as shown in Listing 13-11.
Listing 13-11. Using an XML data type as a parameter in ADO.NET
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Xml;
void AddARow() {
string connect_string = GetConnectStringFromConfigFile();
using (SqlConnection conn = new SqlConnection(connect_string))
using (SqlCommand cmd = new SqlCommand(
"INSERT xmltest(xmlcol) VALUES(@x)", conn))
{
conn.Open();
cmd.Parameters.Add("@x", SqlDbType.Xml);
// connect the parameter value to a file
XmlReader xr = XmlReader.Create("somexml.xml");
cmd.Parameters[0].Value = new SqlXml(xr);
int i = cmd.ExecuteNonQuery();
}
}
Getting the XML As XML or a String
Both of the methods in the preceding code use the SQL Server–specific data type in SqlTypes. When we use the more generic accessor method of SqlDataReader, GetValue(), the value is quite different. The column does not appear as an XmlReader but as a .NET Framework String class. Note that even though the metadata identifies the column’s .NET Framework data type as XmlReader, you can’t just cast the column to an XmlReader. Using any accessor but GetSqlXml() returns a string, as shown in Listing 13-12.
Listing 13-12. The generic ADO.NET methods return XML column as a string
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Xml;
void GetXMLColumn2() {
string connect_string = GetConnectStringFromConfigFile();
using (SqlConnection conn = new SqlConnection(connect_string))
using (SqlCommand cmd = new SqlCommand(
"select * from xmltest", conn))
{
conn.Open();
SqlDataReader rdr = cmd.ExecuteReader();
// prints "System.String"
Console.WriteLine(rdr[1].GetType());
// fails, invalid cast
XmlReader xr = (XmlReader)rdr[1];
// this works
string s = (string)rdr[1];
}
}
You can get the provider-specific field type information by using GetProviderSpecificFieldType or return an instance of the providerspecific value using GetProviderSpecificValue. In this case, you’ll get the System.Sql.Types.SqlXml type, as shown in Listing 13-13.
Listing 13-13. Getting the provider-specific data type, SqlXml
// System.Data.SqlTypes.SqlXml
Console.WriteLine(rdr.GetProviderSpecificFieldType(1));
// System.Data.SqlTypes.SqlXml
Object o = rdr.GetProviderSpecificValue(1);
Console.WriteLine(o.GetType());
SqlClient provides symmetric functionality for XML parameters; you can also use the String data type with these. Being able to pass in a string (NVARCHAR) where an XML type is expected relies on the fact that SQL Server provides automatic conversion of VARCHAR or NVARCHAR to the XML data type. Note that this conversion can also happen on the client side, as shown in the following example. Passing either type to the stored procedure insert_xml will work. This is illustrated in Listing 13-14.
Listing 13-14. Conversion of string to XML can occur client-side or server-side
-- T-SQL stored procedure definition
CREATE PROCEDURE insert_xml(@x XML)
AS
INSERT xmltest(xmlcol) VALUES(@x)
using System;
using System.Data;
using System.Data.SqlClient;
void InsertXMLFromClient() {
string connect_string = GetConnectStringFromConfigFile();
using (SqlConnection conn = new SqlConnection(connect_string))
using (SqlCommand cmd1 = new SqlCommand(
"INSERT xmltab (xmlcol) VALUES(@x)", conn))
using (SqlCommand cmd2 = new SqlCommand(
" insert_xml", conn))
{
string s = "<somedoc/>";
conn.Open();
// server-side conversion
cmd1.Parameters.Add("@x", SqlDbType.NVarChar);
cmd1.Parameters[0].Value = s;
cmd1.ExecuteNonQuery();
// client-side conversion works too
cmd2.CommandType = CommandType.StoredProcedure;
cmd2.Parameters.Add("@x", SqlDbType.Xml);
cmd2.Parameters[0].Value = s;
cmd2.ExecuteNonQuery();
}
}
Documents, Fragments, and FOR XML Support
The XML data type in SQL Server 2005 supports both XML documents and XML document fragments. A fragment differs from a document in that fragments can contain multiple root elements and bare root elements. The T-SQL code in Listing 13-15 illustrates support for fragments.
Listing 13-15. Storing an XML fragment into an XML data type column
CREATE TABLE xmltab (
id INT IDENTITY PRIMARY KEY,
xmlcol XML)
GO
-- insert a document
INSERT xmltab VALUES('<doc/>')
-- fragment, multiple root elements
INSERT xmltab VALUES('<doc/><doc/>')
-- fragment, bare text element
INSERT xmltab VALUES('Hello World')
-- even this fragment works
INSERT xmltab VALUES('<doc/>sometext')
XML fragments are also produced by SELECT ... FOR XML. The statement "SELECT job_id, min_lvl, max_lvl FROM jobs FOR XML AUTO" produces the following output. Note that there are multiple root elements:
<jobs job_id="1" min_lvl="10" max_lvl="10" />
<jobs job_id="2" min_lvl="200" max_lvl="250" />
<jobs job_id="3" min_lvl="175" max_lvl="225" />
<jobs job_id="4" min_lvl="175" max_lvl="250" />
<!— some jobs elements deleted for compactness —>
Both documents and fragments are supported using SqlXml. SqlXml’s CreateReader method always creates an XmlReader that supports fragments by using the new XmlReaderSettings class, like this:
// pseudocode from SqlXml.CreateReader
Stream stm = stm; // stream filled from column (code elided)
XmlReaderSettings settings = new XmlReaderSettings();
settings.ConformanceLevel = ConformanceLevel.Fragment;
XmlReader xr = XmlReader.Create(
stm, String.Empty, null, null, settings);
You can use XML fragments in input parameters if you construct your XmlReader the same way. Although fragment support is built in when using the SqlXml type, you need to be careful about handling an XmlReader that contains fragments. Be aware that calling XmlReader.GetOuterXml will provide only the first fragment; to position the XmlReader to get succeeding fragments, you must call XmlReader’s Read method again. We’ll demonstrate this later in this chapter.
T-SQL’s "SELECT...FOR XML" produces a stream of XML by default rather than a one-column, one-row rowset. It also provided the XML in a binary format rather than XML’s standard serialization. Because of the format differences, and also because "SELECT...FOR XML" always produced fragments, a special method was needed to consume it. The SqlClient data provider implements a provider-specific method, SqlCommand.ExecuteXmlReader, for this purpose. Using SQL Server 2000 and ADO 1.0/1.1, it’s required to use ExecuteXmlReader to get the results of a FOR XML query unless you want to use some fairly ugly workarounds that require string concatenation. With SQL Server 2005’s FOR XML enhancements and the support of XML as a data type, it’s almost never necessary to use ExecuteXmlReader, but because a lot of legacy code used it, this method is supported and enhanced in ADO.NET 2.0. ExecuteXmlReader is the only way to guarantee full end-to-end streaming without buffering the result, however.
You can use ExecuteXmlReader to retrieve any stream from a FOR XML query, as in previous versions. In addition, this method supports retrieving an XML data type column produced by an ordinary SELECT statement. The only caveat is that when an ordinary SELECT statement returns more than one row, ExecuteXmlReader returns only the content of the first row. Listing 13-16 shows an example that illustrates this using the same table as in previous examples.
Listing 13-16. Consuming XML documents and XML fragments on the client
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Xml;
void UseExecXmlReader() {
string connect_string = GetConnectStringFromConfigFile();
using (SqlConnection conn = new SqlConnection(connect_string))
using (SqlCommand cmd1 = new SqlCommand(
"SELECT * FROM pubs..authors FOR XML AUTO,ROOT('root')", conn))
using (SqlCommand cmd2 = new SqlCommand(
"SELECT * FROM pubs..authors FOR XML AUTO", conn))
using (SqlCommand cmd3 = new SqlCommand(
"SELECT * FROM xmltab", conn))
{
conn.Open();
// contains fragment
XmlReader xr1 = cmd1.ExecuteXmlReader();
// contains document
XmlReader xr2 = cmd2.ExecuteXmlReader();
// contains contents of first row in xmltab only
XmlReader xr3 = cmd3.ExecuteXmlReader();
// use XmlReaders, then
xr1.Close(); xr2.Close(); xr3.Close();
}
}
To finish the discussion of getting XML in ADO.NET 2.0, it’s helpful to mention the lifetime of the XmlReader content in various usage scenarios. Investigating the lifetime of the XmlReader also helps you understand the buffering done by SqlClient and how to use this data for maximum performance. The XmlReader uses resources, and to free those resources, the Close or Dispose method should be called, just like with SqlConnection, SqlCommand, and SqlDataReader. In the case of reading XML columns through a SqlDataReader, there can be an XmlReader allocated for each row. Remember that the XmlReader is good only as long as that row is being read; the next call to SqlDataReader.Read() will invalidate the XmlReader’s contents. In addition, to support moving backward through columns in the same row, the XmlReader’s contents will be buffered in memory. You can use SqlCommand’s CommandBehavior.SequentialAccess to optimize reading large data, but you must be more careful when using this access method. The XmlReader associated with a column must be completely consumed before moving to the next column in the rowset when using CommandBehavior.SequentialAccess; after moving to the next column, the XmlReader appears to be valid, but calling its Read method produces no data. When you are using ExecuteXmlReader or ExecuteScalar instead of ExecuteReader, you don’t need to be aware of this behavior as much, but don’t forget to Close/Dispose the XmlReader here, too.
Using the XML Data Type in ADO Classic
The only way to consume XML in ADO is to treat it as a string. This string can be used as input to either the DOM or the SAX APIs. When we bind an XML column in a Recordset as a string in ADO, we bind it using adBindVariant. Assuming that we have a table that contains an XML type column named xml_col, binding as a string looks like Listing 13-17.
Listing 13-17. Using the XML data type in ADO, Visual Basic 6.0
Dim rs As New ADODB.Recordset
Dim connect_string as String
connect_string = GetConnectStringFromConfiguration
rs.Open "SELECT xml_col FROM xml_tab1", connect_string
' Prints 141 - XML
Debug.Print rs(0).Type
' adBindVariant is the default
' Deserializes as a String
Debug.Print rs(0)
' Load it into a DOM
Dim dom As MSXML2.DOMDocument40
dom.loadXML rs(0)
We can also use a string as input to a SAX Reader. Assuming that we define a SAX ContentHandler and ErrorHandler elsewhere, the same Recordset could be used as in Listing 13-18.
Listing 13-18. Consuming XML in Visual Basic 6.0 through the SAX API
Dim rs As New ADODB.Recordset
Dim saxXMLReader As New SAXXMLReader40
Dim saxContentHandler As New clsSAXHandler
Dim saxErrorHandler As New clsSAXError
Dim connect_string as String
connect_string = GetConnectStringFromConfiguration
rs.Open "SELECT xml_col FROM xml_tab1", connect_string
' default binding as string
rs.Fields("xml_col").BindType = adBindVariant
' Load SAX Reader, hook up handlers, parse
Set saxXMLReader.contentHandler = saxContentHandler
Set saxXMLReader.errorHandler = saxErrorHandler
saxXMLReader.parse (rs.Fields("xml_col").Value)
You can use direct updating or parameterized updating through either strings or SAXXMLReader40. The code for updating through a Recordset and a SAXXMLReader40 would look like Listing 13-19.
Listing 13-19. Updating an XML data type column using ADO and MSXML SAXXMLReader
Dim xmlStream as Stream
Dim saxXMLReader As New SAXXMLReader40
' populate the stream
Set saxXMLReader.InputStream = xmlStream
' Update the Recordset through the SAX Reader
Set rs.Fields("xml_col").Value = saxXMLReader
rs.Update
Both OLE DB and ODBC return the correct data type for XML (141) when you fetch or use an instance of it with the SQL Native Client provider or driver. When you fetch XML in any of the older APIs, it is fetched as a Unicode string type (SQL_WVARCHAR or DBTYPE_WSTR). In addition, you can stream XML input and output (which includes the byte-order marker) in OLE DB by using the OLE DB IStream interfaces. This would use XML as data type DBTYPE_UNKNOWN, which uses data accessed through a COM interface pointer (any pointer that derives from IUnknown—in this case, IStream). The latest provider and driver also return additional metadata about the XML data type, indicating the database, schema, and name of the associated XML Schema Collection if one is associated with the XML instance.
The additional XML Schema Collection metadata is analogous to the additional UDT information in these APIs. Table 13-3 and Table 13-4 list the ODBC and OLE DB metadata constants, respectively.
Table 13-3. ODBC Metadata for XML Data Type Column with an XML Schema Collection
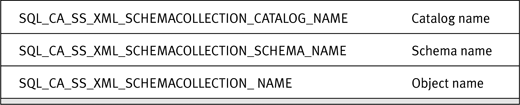
Table 13-4. OLE DB Metadata for XML Data Type Column with an XML Schema Collection

OLE DB’s schema rowsets also contain a special schema rowset for XML SCHEMA COLLECTION metadata information with the symbolic name DBSCHEMA_XML_COLLECTIONS.
Supporting the Large Value Data Types on the Client
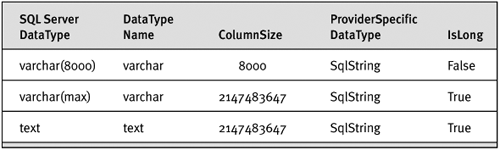
SQL Server 2005 introduces large value types: VARCHAR(MAX), NVARCHAR (MAX), and VARBINARY(MAX). These are new, distinct types that act somewhat like an ordinary VARCHAR/VARBINARY and somewhat like TEXT/IMAGE data type. As far as ADO.NET is concerned, the new large value types are more like long versions of the vanilla data type VARCHAR than they are like the old TEXT data type. This is evident in the metadata returned by the SqlDataReader’s GetSchemaTable method. Table 13-5 lists a subset of the columns that GetSchemaTable returns.
Table 13-5. Metadata Columns Returned from ADO.NET for Large Value Types
When it comes to fetching the data through a SqlDataReader, you can use a variety of methods to use the large value types:
• GetChars/GetBytes—These methods get the value as a stream of Unicode characters or bytes.
• GetSqlChars/GetSqlBytes—These methods get the value as a stream of Unicode characters or bytes.
• GetSqlString/GetSqlBinary—These methods work like Get- SqlChars and GetSqlBytes, respectively, but they work by copying the contents rather than by providing a reference to it. Because of this behavior, it’s not recommended to use these when memory is at a premium—for example, in a SQLCLR procedure.
• GetValue—This method gets the entire type into memory.
The SqlChars and SqlBytes data types have some additional properties—namely, IsNull and Buffer. SqlBytes have a Stream property that can be used like any other of the .NET Framework Stream classes. SqlChars is particularly useful when setting character-related properties such as Sort Options in a SQLCLR procedure.
Using any of the Get methods mentioned so far can fetch the large value type in user-defined chunks. This keeps from having to have enough memory on the client workstation to be able to hold the entire large value in memory at one time. For this buffering to work, you must use CommandBehavior. SequentialAccess with your SqlCommand. If you do not use this method, when you invoke SqlDataReader.Read, the entire row (including the entire large value type) is fetched into memory. Using GetValue will read the entire type into memory regardless of the setting of the Command- Behavior parameter. Using CommandBehavior.SequentialAccess also means that you must fetch the SqlDataReader’s columns in ordinal order.
Listing 13-20 shows examples of ways to access a large value type column.
Listing 13-20. Three ways to consume a large binary value type in ADO.NET
string s = GetConnectionStringFromConfigFile();
using (SqlConnection conn = new SqlConnection(s))
using (SqlCommand cmd1 = new SqlCommand(
"select top(1) LargePhoto from Production.ProductPhoto", conn))
{
conn.Open();
SqlDataReader rdr1 =
cmd1.ExecuteReader(CommandBehavior.SequentialAccess);
rdr1.Read();
int buffer_size = 1000;
// gets reference to internal buffer (SQLCLR)
SqlBytes sb = rdr1.GetSqlBytes(1);
if (!sb.IsNull) {
BinaryReader br = new BinaryReader(sb.Stream);
byte[] buffer = new byte[buffer_size];
int bytes_read;
do {
bytes_read = br.Read(buffer, 0, buffer_size);
// do something with the buffer
}
while (bytes_read == buffer_size);
}
// makes a buffer-size copy into address space
if (rdr1[1] != DBNull.Value)
{
byte[] buffer2 = new byte[buffer_size];
long long_bytes_read; long dataIndex = 0;
do {
long_bytes_read = rdr1.GetBytes(
1, dataIndex, buffer2, 0, buffer_size);
dataIndex += long_bytes_read;
// do something with the buffer
}
while (long_bytes_read == buffer_size);
}
// copy the whole thing into memory
SqlBinary sbin = rdr1.GetSqlBinary(1);
if (!sbin.IsNull) {
byte[] bigbuffer = new byte[sbin.Length];
bigbuffer = sbin.Value;
}
}
Using the new data types with SqlParameter has some interesting twists. When you use the new large value types with ADO.NET 2.0, the parameter’s data type DbType or SqlDbType should be set to SqlDbType. Var Char, SqlDbType.NVarChar, or SqlDbType.VarBinary, respectively, rather than SqlDbType.Text, SqlDbType.NText, and SqlDbType.Image. When you use the SqlDbType.VarChar and friends with data longer than 8,000 bytes in previous releases, ADO.NET throws an error, because it cannot infer the data type. You must specify the exact size of the data. In ADO.NET 2.0, you still need to specify a size, but the size can be–1. The SqlClient data provider will read as much data is in the stream (input parameter) or in the database (output parameter).
Even in ADO.NET 2.0, there is no way to stream in a long input parameter. Regardless of the method you use to push the data into the parameter, at some time in the statement execution, the entire value of the data will exist in memory on the client. This is also the case if System.Data.SqlClient is being used in process with .NET Framework procedural code. When you consume the large data types in SqlDataReader or as output parameters, using either of the bytewise/characterwise APIs can buffer the value in memory. If you are using SqlDataReader, you need to set Command Behavior.SequentialAccess in the SqlCommand instance. Setting this behavior requires you to consume each column in ordinal order. If you use GetValue or GetValues, the entire row (including the entire large value) is fetched into memory.
When you use ADO.NET 1.1, the “old” OLE DB provider or ODBC driver, or specify Data Type Version = SQL Server 2000” in the ADO.NET connection string, the large values look like and have the same behavior as the TEXT/NTEXT and IMAGE data types. This mostly affects the reported maximum size of the column in the metadata. Be careful, though, because the method T-SQL statements for fetching and updating large value types are different from the methods in T-SQL for dealing with TEXT/NTEXT/ VARBINARY. Large value types are updated by using the WRITE mutator method rather than by using the READTEXT, WRITETEXT, and UPDATETEXT methods, as the large object types do.
When you use the new providers without the DataTypeCompatibility connection string parameter (that is, using the SQL Server 2005 behavior), the size of the large value types is reported as -1. In OLE DB, they appear as character or binary data types with the ISLONG flag set to true. In ODBC, they appear as LONGVARCHAR, LONGWVARCHAR, and LONGVARBINARY, as the TEXT and IMAGE data types do.
Query Notification Support
Any nontrivial relational database application is bound to have a lot of lookup tables. If you code graphic user interfaces as a specialty, you know these as the lists that populate the drop-down list boxes. We categorize lookup tables into two types: read-only tables and read-mostly tables. The difference is what can cause those tables to change. You can think of a table as read-only if it takes a staff meeting or user meeting to change them. A good example is a table that contains categories of the company’s products. That one’s not about to change until the company launches a new product or a company reorganization occurs. Read-mostly tables are lists that are relatively constant but can be changed by end users. These usually are presented in combo boxes rather than drop-down lists. An example of a read-mostly table would be a term-of-greeting table. Your application designers can always think of the most common ones, such as Ms., Mr., Mrs., and Dr., but there’s always the user who has a title you’ve never thought of and wants to add it. As an example of how common this is, the last medium-size product we worked on had a nice third normal form relational database that contained 350 to 400 tables. We’d estimate that about 250 were readonly or read-mostly tables.
In the traditional Web application (which is the quintessential example of a three-tier application), you’d like to cache these types of tables as much as possible. This not only decreases the number of round trips to the database, but also decreases the query load on the database, making it more responsive for use cases like new orders. Read-only tables are easy to cache; you always keep the table in the cache and give a DBA a way to reload the cache on the rare occasion where she has to reload the table. Ideally, meetings that change the basic database structure and content are rare occurrences in your organization. Refreshing read-mostly lookup tables in a middle-tier cache is a bit more problematic. Refreshing the cache infrequently on a schedule doesn’t produce the behavior you want; users don’t see one another’s changes immediately. A support person could add a new item using a different application or send an instant-messenger message to a friend who tries to use it, but the friend’s list of choices doesn’t include the new entry. Worse, if the second user tries to re-add the “missing list entry,” he receives a database error indicating that the item already exists. Caching read-mostly tables usually isn’t done if they have more than one “point of update” because of problems like this.
In the past, programmers have resorted to hand-crafted solutions using message queuing, triggers that write to files, or out-of-band protocols to notify the cache when someone outside the application has updated a read-mostly table. These “signaling” solutions merely notify the cache that a row has been added or changed, indicating that the cache must be refreshed. Notifying the cache about which specific row has changed or been added is a different problem; it’s the province of distributed database and transactional or merge replication. In the low-overhead signaling solution, when the program gets a “cache invalid” message, it just refreshes the entire cache.
If you’re using SQL Server 2005 and ADO.NET 2.0, there is now a signaling solution built into the SqlClient data provider and the database: Query Notifications. At last, there’s a built-in, easy-to-use solution to this common problem! Query Notifications are also directly supported with a built-in feature in ASP.NET 2.0. The ASP.NET Cache class can be used to register for notifications, and the notifications can even be used in conjunction with the page and page-fragment caching that ASP.NET uses.
The infrastructure that accomplishes this useful function is split among SQLServer 2005’s Query Engine, Service Broker, an internal ADO.NET notification listener mechanism, ADO.NET’s SqlNotification and SqlDependency classes, and ASP.NET’s Cache class. In brief, it works like this:
- You can add a
SqlNotificationproperty to a new ASP.NETCacheentry or as a parameter on theOutputCachedirective. - Each ADO.NET
SqlCommandcontains a property that represents a request for notification. - When the
SqlCommandis executed, the presence of aNotificationproperty causes a TDS packet that indicates a request for notification to be appended to the request. - SQL Server registers a subscription for the requested notification with its Service Broker and executes the command.
- SQL Server watches the query results for anything that could cause the originally returned rowset to change. When a change occurs, a message is sent to a Service Broker service.
- The Query Notification message sits in a Service Broker’s service queue, available for processing.
- You can use either a built-in listener or custom processing to process the message.
The ASP.NET SqlCacheDependency class and OutputCache directive use SqlDependency to use the automatic message-processing capability. ADO.NET clients that require more control can use SqlNotificationRequest and process the Service Broker queue manually, implementing whatever custom semantics they like.
Before proceeding, it’s important to clarify that each SqlNotificationRequest or SqlDependency gets a single notification message when the rowset changes. The message is identical whether the change is caused to a database INSERT, a DELETE statement that deletes one or more rows, or an UPDATE that updates one or more rows. The notification does not contain any information about which rows have changed or how many have changed. When the cache or user application receives the single change message, it has one choice: Refresh the entire rowset, and reregister for notification. You don’t get multiple messages, and after the single message fires, the user’s subscription in the database is gone. The Query Notification framework also works on the premise that it’s better to be notified of more events than not to be notified at all. Notifications are sent not only when the rowset is changed, but also when a table that participates in the rowset is dropped or altered, when the database is recycled, or for other reasons. The cache or program’s response is usually the same regardless: Refresh the cached data and reregister for notification.
Now that you’ve got the general semantics involved, we’ll look at how this works in detail from three perspectives:
• How Query Notifications are implemented in SQL Server and how the optional listener works
• How SqlClient’s SqlDependency and SqlNotificationRequest work on the client/middle tier
• How ASP.NET 2.0 supports SqlDependency
Query Notifications in SQL Server 2005
At the server level, SQL Server handles queries from clients in batches. Each query (think of the query as the SqlCommand.CommandText property) can contain only one batch, although a batch can contain multiple T-SQL statements. A SqlCommand can also be used to execute a stored procedure or user-defined function, which can contain multiple T-SQL statements. In SQL Server 2005, a query from a client can also contain three additional pieces of information: the name of a Service Broker service to deliver notifications to, a notification identifier (which is a string), and a notification timeout. If these three pieces of information are present in the query request, and the request contains SELECT or EXECUTE statements, SQL Server will watch any rowsets produced by the query for changes made by other SQL Server sessions. If there are multiple rowsets produced—for example, in a stored procedure execution—SQL Server will watch all of the rowsets.
So what do we mean by watching rowsets, and how does SQL Server accomplish this? Detecting changes to a rowset is part of the SQL Server engine and uses a mechanism that has been around since SQL Server 2000: change detection for indexed VIEW synchronization. Query Notifications use a variation of this mechanism. In SQL Server 2000, Microsoft introduced the concept of indexed views. A view in SQL Server consists of a query against columns in one or more tables. A view has a name that can be used like a table name. For example:
CREATE VIEW WestCoastAuthors
AS
SELECT * FROM authors
WHERE state IN ('CA', 'WA', 'OR')
Now you can use the view as though it were a table in a query:
SELECT au_id, au_lname FROM WestCoastAuthors
WHERE au_lname LIKE 'S%'
Most programmers are familiar with views but may not be familiar with indexed views. In a nonindexed VIEW, the VIEW data is not stored in the database as a separate copy; each time the VIEW is used, the underlying query is executed. So in the example above, the query to get the WestCoast Authors rowset will be executed, and it will include a predicate to pull out the particular WestCoastAuthors that we want. An indexed view stores a copy of the data, so if we make WestCoastAuthors an indexed view, we have two copies of these authors’ data. Now you can update the data through two paths, either through the indexed VIEW or through the original table. Therefore, SQL Server has to detect changes in both physical data stores to apply the changes to the other one. This change-detection mechanism is similar to the one that the engine uses when Query Notifications are used.
Because of the way change detection is implemented, not all VIEWs can be indexed. The limitations that apply to indexed views also apply to queries that can be used for Query Notifications. The WestCoastAuthors VIEW, for example, is not indexable the way it is written. To be indexable, the VIEW definition must use two-part names, name all the rowset columns explicitly, and use the "WITH SCHEMABINDING" option of CREATE VIEW to ensure that the underlying metadata that the view uses cannot be changed. So let’s change the VIEW to be indexable:
CREATE VIEW WestCoastAuthors
WITH SCHEMABINDING
AS
SELECT au_id, au_lname, au_fname, address, city, state, zip, phone
FROM dbo.authors
WHERE state in ('CA', 'WA', 'OR')
Only queries that go by the indexed VIEW rules can be used with notifications. Note that although the same mechanism is used for determining whether the results of a query have changed, Query Notifications do not cause SQL Server to make a copy of the data, as indexed views do. There is a list of the rules for indexable views that is quite extensive; you can find it in SQL Server 2005 Books Online. If a query is submitted with a notification request, and it does not go by the rules, SQL Server immediately posts a notification with a reason “Invalid Query.” But where does it post the notification?
SQL Server 2005 uses the Service Broker feature to post notifications. We discuss how Service Broker works in Chapter 11; the only special consideration for Query Notifications is that your SERVICE must use the built-in CONTRACT for Query Notifications. Its name is http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification. The SQL DDL to define such a service would look like this:
CREATE QUEUE mynotificationqueue
CREATE SERVICE myservice ON QUEUE mynotificationqueue
([http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification]
)
GO
Now you could use the myservice SERVICE as a destination in a Query Notification request. SQL Server sends a notification by sending a message to the SERVICE. You can use your own SERVICE or have ADO.NET create one for you on the fly. If you use your own SERVICE, you must write code to read the messages and process them. If you use the built-in listener facility, there is prewritten code that looks for the message. We’ll come back to this later.
Because Query Notifications use Service Broker, there are some additional requirements. Service Broker must be enabled in the database where the notification query runs. If Service Broker is not enabled in the database you’re using, you can enable it with DDL, like the following:
ALTER DATABASE pubs SET BROKER ENABLED
If you use ADO.NET’s built-in listener, the user submitting the query must have the permission to subscribe to Query Notifications. This is done on a per-database basis. The following DDL would give the user bob permission to subscribe in the current database:
GRANT SUBSCRIBE QUERY NOTIFICATIONS TO bob
Using Query Notifications in OLE DB and ODBC
Query Notifications are supported when using SQL Native Client in OLE DB, ADO, and ODBC at the level of ADO.NET’s SqlNotificationRequest—that is, there is no built-in listener in these APIs … la SqlDependency in ADO.NET. You set three properties, shown in Table 13-6, on the ODBC statement to enable Query Notifications in ODBC. In OLE DB, there are analogous properties that you set by using the DBPROPSET_SS_ROWSET property set of the OLE DB Command object. These properties, shown in Table 13-7, are exposed as extended properties in ADO.
Table 13-6. Notification Request Properties in ODBC

Table 13-7. Notification Request Properties in OLE DB and ADO

Dispatching a Notification to an End User or Cache
So at this point, we’ve submitted the correct kind of query batch with a notification request to SQL Server. SQL Server has put a watch on the rowset, and when anyone changes the rowset, a message will be sent to the SERVICE of our choice. What now? You can write custom code that takes care of reading the messages and performing whatever logic you like when the notifications occur, or you can have the built-in listener take care of it for you. So let’s look at the built-in listener. It’s part of the SqlDependency class.
You must start the listener using a static Start method of the SqlDependency class. You specify a connection string and an optional Service Broker QUEUE. The listener opens a connection to the instance of SQL Server you specify. If you do not specify a QUEUE, the listener will create a SERVICE and a QUEUE for you. The SERVICE’s name is SqlQueryNotificationService-[GUID]. Then the listener begins a Service Broker DIALOG to listen on that SERVICE using a WAIT FOR...RECEIVE statement. The SQL code executed by SqlDependency.Start using a default QUEUE is illustrated in Listing 13-21.1
Listing 13-21. Code issued in SQL server during SqlDependency.Start
{GUID} = 5e15087f-7039-4f03-aeab-15063d38b004
{GUID2}= C0588F48-C503-DA11-AC11-0003FFAA155A
CREATE PROCEDURE [SqlQueryNotificationStoredProcedure-{GUID}]
AS
BEGIN
IF (SELECT COUNT(*) AS numRows FROM sys.sysprocesses
WHERE program_name='SqlQueryNotificationService-{GUID}') <= 0
BEGIN
BEGIN TRANSACTION;
DROP SERVICE [SqlQueryNotificationService-{GUID}];
DROP QUEUE [SqlQueryNotificationService-{GUID}];
DROP PROCEDURE [SqlQueryNotificationStoredProcedure-{GUID}];
COMMIT TRANSACTION;
END
END
declare @p3 uniqueidentifier
set @p3='{GUID2}'
exec sp_executesql
N'IF OBJECT_ID(''[SqlQueryNotificationService-{GUID}]'') IS NULL
BEGIN
CREATE QUEUE
[SqlQueryNotificationService-{GUID}]
WITH ACTIVATION
(PROCEDURE_NAME=[SqlQueryNotificationStoredProcedure-{GUID}],
MAX_QUEUE_READERS=1,
EXECUTE AS OWNER);
END;
IF
(SELECT COUNT(*) FROM SYS.SERVICES
WHERE NAME=''[SqlQueryNotificationService-{GUID}]'') = 0
BEGIN
CREATE SERVICE [SqlQueryNotificationService-{GUID}]
ON QUEUE [SqlQueryNotificationService-{GUID}]
([http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification]
);
END;
BEGIN DIALOG @dialog_handle
FROM SERVICE [SqlQueryNotificationService-{GUID}]
TO SERVICE ''SqlQueryNotificationService-{GUID}''',
N'@dialog_handle uniqueidentifier output',
@dialog_handle=@p3 output
select @p3
exec sp_executesql
N'BEGIN CONVERSATION TIMER (''{GUID2}'')
TIMEOUT = 120;
WAITFOR(RECEIVE TOP (1)
message_type_name, conversation_handle,
cast(message_body AS XML) as message_body from
[SqlQueryNotificationService-{GUID}]),
TIMEOUT @p2;',N'@p2 int',@p2=0
exec sp_executesql
N'WAITFOR(RECEIVE TOP (1)
message_type_name,
conversation_handle,
cast(message_body AS XML) as message_body from
[SqlQueryNotificationService-{GUID}]),
TIMEOUT @p2;',N'@p2 int',@p2=60000
Calling SqlDependency.Stop shuts down the listener and deletes the SERVICE and QUEUE if they were created by the call to SqlDependency.Start. Each client that uses Query Notifications will have an open connection (and use a thread on SQL Server). One nice feature about being able to specify your own queue as well as your own connection string is that in a situation where every Web server in a large Web farm is listening on the same Query Notification, the queue can be on different physical machines. When configured this way, it limits the number of listener connections on any of the instances of SQL Server. The feature that enables this is Service Broker delivery. If you spread the listeners out like this, you are responsible for defining your own queue and also your own Service Broker routes. See Chapter 11 for more information on Service Broker and routing.
Using Query Notifications from a Database Client
Now that we know all the internal plumbing, let’s write an ADO.NET client that uses it. Why all this explanation before we write some relatively simple client-side code? Although the code is relatively simple to write, you have to remember to go by the rules. The most common problems are submitting an invalid query for notifications and forgetting to set up the Service Broker and user permissions. This has caused frustration with this powerful feature, even giving some beta testers the impression that it wasn’t working. A little prep work and research go a long way. Finally, it was good to do internals first, because we’re going to specify properties like Service Broker SERVICEs or QUEUEs, and by now, you know what these terms refer to.
You can write a Query Notification client in ADO.NET as we’ll be doing, use OLE DB, or even use the new HTTP Web Service client, but a point to remember is that Query Notifications are available only through client-side code. You cannot use this feature with T-SQL directly or with SQLCLR procedural code that uses the SqlClient data provider to talk to SQL Server.
The SqlClient data provider contains two classes that you can use: SqlDependency and SqlNotificationRequest. You use SqlDependency when you want automatic notification using the dispatcher. You use SqlNotificationRequest when you want to process the notification messages yourself. We’ll look at an example of each one.
Using SqlDependency
The steps to use SqlDependency are simple. First, call the Start method to initialize the listener. Then create a SqlCommand that contains the SQL statements that you want Query Notifications for. Associate the SqlCommand with a SqlDependency. Register an event handler for the SqlDependency’s OnChange event. Then execute the SqlCommand. You can process the DataReader, close the DataReader, and even close the associated SqlConnection; you’ll be notified by the listener when there is a change in your rowset. Listing 13-22 shows the code.
Listing 13-22. Using SqlDependency in ADO.NET
static void Main(string[] args)
{
string connstring = GetConnectStringFromConfigFile();
SqlDependency.Start(connstring);
using (SqlConnection conn = new SqlConnection(connstring))
using (SqlCommand cmd =
// 2-part table names, no "SELECT * FROM ..."
new SqlCommand("SELECT au_id, au_lname FROM dbo.authors", conn))
{
try
{
// create dependency associated with cmd
SqlDependency depend = new SqlDependency(cmd);
// register handler
depend.OnChange += new OnChangeEventHandler(MyOnChange);
conn.Open();
SqlDataReader rdr = cmd.ExecuteReader();
// process DataReader
while (rdr.Read())
Console.WriteLine(rdr[0]);
rdr.Close();
// Wait for invalidation to come through
Console.WriteLine("Press Enter to continue");
Console.ReadLine();
SqlDependency.Stop(connstring);
}
catch (Exception e)
{ Console.WriteLine(e.Message); }
}
}
static void MyOnChange(object caller, SqlNotificationEventArgs e)
{
Console.WriteLine("result has changed");
Console.WriteLine("Source " + e.Source);
Console.WriteLine("Type " + e.Type);
Console.WriteLine("Info " + e.Info);
}
You can write the same code in Visual Basic .NET, using the familiar WithEvents keyword along with the SqlDependency. Note that this program will get and process only a single OnChange event, no matter how many times the underlying results change. For any nontrivial usage, what we really want to do when we’re notified is invalidate our cache. When the next user needs the result, we resubmit the command with a fresh notification and use its results to refresh the cache with the new data. If we take our code in Main() in the example above and move it to a routine named GetAndProcessData, our code might look something like Listing 13-23.
Listing 13-23. Responding to the query notification
static void Main(string[] args)
{
string connstring = GetConnectStringFromConfigFile();
SqlDependency.Start(connstring);
GetAndProcessData();
UpdateCache();
// wait for user to end program
Console.WriteLine("Press Enter to continue");
Console.ReadLine();
SqlDependency.Stop(connstring);
}
static void MyOnChange(object caller, SqlNotificationEventArgs e)
{
GetAndProcessData();
UpdateCache();
}
We’ll see in a few paragraphs that this is exactly what you can do in ASP.NET 2.0, using the ASP.NET Cache class as your data cache.
When you use SqlDependency, you can customize how the listener works and where the SERVICE that the listener is listening on resides, as mentioned earlier in the chapter. With the SqlNotificationRequest, we have even more control.
Using SqlNotificationRequest
Using SqlNotificationRequest is only a little bit more complex than SqlDependency on the setup side, but it’s up to your program to process the messages. When you use SqlDependency, the notifications on the server will be sent to the SqlQueryNotificationService or SERVICE of your choice, and the listener will process the messages for you. With SqlNotificationRequest, you must process the messages yourself. Listing 13-24 shows a simple example of using SqlNotificationRequest and the SERVICE that we defined earlier.
Listing 13-24. Using SqlNotificationRequest in ADO.NET code
class Class1
{
static string connstring = null;
static SqlConnection conn = null;
SqlDataReader rdr = null;
static void Main(string[] args)
{
connstring = GetConnectStringFromConfigFile();
conn = new SqlConnection(connstring);
Class1 c = new Class1();
c.DoWork();
}
void DoWork()
{
conn.Open();
rdr = GetJobs(2);
if (rdr != null)
{
rdr.Close();
WaitForChanges();
}
conn.Dispose();
}
public SqlDataReader GetJobs(int JobId)
{
using (SqlCommand cmd = new SqlCommand(
"SELECT job_id, job_desc FROM dbo.jobs WHERE job_id = @id",
conn))
{
try
{
cmd.Parameters.AddWithValue("@id", JobId);
SqlNotificationRequest not = new SqlNotificationRequest();
not.UserData = (new Guid()).ToString();
// this must be a service named myservice in the pubs database
// associated with a queue called notificationqueue (see below)
// service must go by QueryNotifications contract
not.Options = "service=myservice;local database=pubs";
not.Timeout = 0;
// hook up the notification request
cmd.Notification = not;
rdr = cmd.ExecuteReader();
while (rdr.Read())
Console.WriteLine(rdr[0]);
rdr.Close();
}
catch (Exception ex)
{ Console.WriteLine(ex.Message); }
return rdr;
}
}
public void WaitForChanges()
{
// wait for notification to appear on the queue
// then read it yourself
using (SqlCommand cmd = new SqlCommand(
"WAITFOR (RECEIVE CONVERT(xml,message_body) FROM myqueue)",
conn))
{
object o = cmd.ExecuteScalar();
// process the notification message however you like
Console.WriteLine(o);
}
}
The power (as well as the extra work) in using SqlNotificationRequest is that you have to wait for and process the notification yourself, as shown in Figure 13-2.
Figure 13-2. Using SqlNotification request
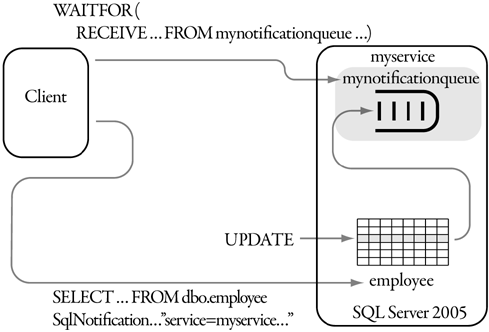
When you use the SqlNotificationRequest, you need not ever connect to the database again until you receive the notification. You don’t really need to wait around for the SqlNotificationRequest’s notification, either; you can poll the queue every once in a while. Another use of SqlNotificationRequest might be to write a specialized application that may not even be running when the notification is fired. When the application starts up, it can connect to the queue and determine which results in its persistent cache (from a previous application run) are now invalid.
Discussing applications that can wait around hours or days for a notification brings up the question “If there are no changes in the data, when does the notification go away?” The only things that cause a notification to go away (that is, be purged from the database’s subscription tables) is when the notification is fired or when it expires. Database administrators who might be annoyed at having notification subscriptions hanging around (because they use SQL resources and add overhead to queries and updates) have a way to dispose of a notification manually in SQL Server. First, you query one of SQL Server 2005’s dynamic views and find the offending notification subscription; then you issue the command to get rid of it:
-- look at all subscriptions
SELECT * FROM sys.dm_qn_subscriptions
-- pick the ID of the subscription that you want, then
-- say it's ID = 42
KILL QUERY NOTIFICATION SUBSCRIPTION 42
We’ve seen how the internals of Query Notifications work; looked at the low-level implementation in OLE DB, ODBC, and ADO.NET’s SqlNotificationRequest’ and shown how ADO.NET provides a built-in listener and client-notification mechanism through SqlDependency. ASP.NET 2.0 uses a level of abstraction above the SqlDependency to direct tie Query Notifications into the ASP.NET Cache class and its built-in page caching functionality. Let’s look at this now.
Using SqlCacheDependency in ASP.NET
Query Notifications are also hooked up to the ASP.NET Cache class. In ASP.NET 2.0, the CacheDependency class can be subclassed, and SqlCache Dependency encapsulates the SqlDependency and behaves just like any other ASP.NET CacheDependency. SqlCacheDependency goes beyond SqlDependency in that it works whether you are using SQL Server 2005 or earlier versions of SQL Server. It’s implemented completely differently for pre–SQL Server 2005 versions, of course.
When you use earlier versions of SQL Server, the SqlCacheDependency works by means of triggers on TABLEs that you want to watch. These triggers write rows to a different SQL Server table. Then this TABLE is polled. Which TABLEs are enabled for dependencies and the value of the polling interval are configurable. The details of the pre–SQL Server 2005 implementation are beyond the scope of this book; for more information, see the MSDN online article “Improved Caching in ASP.NET 2.0.”
When you use SQL Server 2005, the SqlCacheDependency just encapsulates a SqlDependency instance similarly to the ADO.NET example shown above. Listing 13-25 shows a short code example that illustrates using SqlCacheDependency.
Listing 13-25. Using SqlCacheDependency manually with the ASP.NET cache
// called from Page.Load
CreateSqlCacheDependency(SqlCommand cmd)
{
SqlCacheDependency dep = new SqlCacheDepedency(cmd);
Response.Cache.SetExpires(DateTime.Now.AddSeconds(60));
Response.Cache.SetCacheability(HttpCacheability.Public);
Response.Cache.SetValidUntilExpires(true);
Response.AddCacheDependency(dep);
}
A nice ease-of-use feature is that SqlCacheDependency is even hooked into page or page-fragment caching. You can declaratively enable all the SqlCommands in a particular ASP.NET OutputCache directive. This uses the same SqlDependency for all the SqlCommands in the page and looks like this for a SQL Server 2005 database:
<%OutputCache SqlDependency="CommandNotification" ... %>
The general concept behind this, and how it affects the underlying database, is shown in Figure 13-3.
Figure 13-3. Using query notifications with the ASP.NET OutputCache directive

Note that CommandNotification is a keyword value that means “Use SQL Server 2005 and SqlDependency”; the syntax for this directive parameter is completely different when earlier versions of SQL Server are used. Also, the CommandNotification keyword value is enabled only when you are running ASP.NET 2.0 on specific operating system versions.
Eager Notifications
A design policy of SQL Server Query Notifications is that it is better to notify a client too often than to miss a notification. Although it’s most often the case that you’ll be notified when someone else has changed a row that invalidates your cache, that’s not always the case. If the database is recycled by the DBA, for example, you’ll get a notification. If any of the TABLEs in your query is ALTERed, DELETEd, or TRUNCATEd, you’ll be notified. Because Query Notifications take up SQL Server resources, it is possible that if SQL Server is under severe-enough resource stress, it will start to remove Query Notifications from its internal tables; you’ll get a notification on the client in this case as well. And because each notification request includes a timeout value, you’ll be notified when your subscription times out.
If you are using SqlDependency, the dispatcher will wrap this information up in a SqlNotificationEventArgs instance. This class contains three properties—Info, Source, and Type—that will allow you to pinpoint what caused the notification. If you are using SqlNotificationRequest, the message_body field in the queued message contains an XML document that contains the same information, but you’ll have to parse it out yourself with XPath or XQuery. Listing 13-26 shows an example of the XML document that was produced from the earlier ADO.NET SqlNotificationRequest example.
Listing 13-26. Query notification message format
<qn:QueryNotification
xmlns:qn="http://schemas.microsoft.com/SQL/Notifications/QueryNotification"
id="2" type="change" source="data" info="update"
database_id="6" user_id="1">
<qn:Message>{CFD53DDB-A633-4490-95A8-8E837D771707}</qn:Message>
</qn:QueryNotification>
Note that although we produced this notification by changing the value of the job_desc column to "new job" in the row with job_id = 5, you’ll never see this information in the message_body itself. This brings up a few final nuances of the notification process. The notification is only smart enough to know that a SQL statement altered something that could change your rowset. It is not smart enough to know that your UPDATE statement doesn’t change the actual value in a row. Changing a row from job_desc = "new job" to job_desc = "new job" would cause a notification, for example. Also, because Query Notifications are asynchronous and are registered at the moment you execute the command or batch, it is possible to receive a notification before you finish reading the rowset. You can also get an immediate notification if you submit a query that does not conform to the rules; these are the rules for indexed views that we mentioned earlier.
When Not to Use Notifications
Because you now know how Query Notifications work, it’s fairly straightforward to figure out where to use them: read-mostly lookup tables. Each notification rowset takes up resources in SQL Server; using them for read-only tables would be wasteful. In addition, you don’t want to use them for ad hoc queries; there would be too many different rowsets being watched at the same time. A useful internal detail to know is that SQL Server folds together notification resources for parameterized queries that use different sets of parameters. Always using parameterized queries (as shown in the SqlNotificationRequest example above) will return more bang for your notifiable query buck. If you are worried after hearing this, bear in mind that this performance feature does not mean that you won’t get the appropriate notifications. If user1 watches authors with au_lname from A-M, and user2 watches au_lname from N-Z, using the au_lname values as parameters, each user will get only the “right” notifications for his subset.
One last caution: When some folks think of notification applications, they envision a roomful of stockbrokers with changing market prices, each screen changing continuously. This is absolutely the wrong use of this feature, for two reasons:
• The rowsets are changing continuously, so the network may be flooded with Query Notifications and query refresh requests.
• If there are more than a trivial number of users, and they all watch the same data, each notification will cause many users to requery for the same results at the same time. This could flood SQL Server with many requests for the same data!
If you think you have programmers who might abuse this feature, you’ll be happy to know that SQL Server provides information to allow DBAs to monitor this feature through dynamic management views (DMVs). In addition to the Service Broker–related system views and DMVs, there is a special DMV, sys.dm_qn_subscriptions, that lists information about the current subscriptions. Remember, it’s always possible for SQL Server 2005 to decide that notifications are taking too many resources and start purging them itself.
Multiple Active Resultsets
SQL Server clients can fetch data from the server using two different semantics: server-side cursors; and forward-only, read-only, cursorless mode, also referred to as firehose mode. Although a single client connection can open multiple database cursors at the same time and fetch data from any of them, in SQL Server 2000 and earlier, only one cursorless-mode resultset could be active at a time. In addition, no other commands (such as a SQL UPDATE statement) could be issued while the cursorless rowset was active. Cursorless mode is the default behavior of all SQL Server database APIs when using resultsets, from DBLib to ADO.NET. Cursorless mode consumes fewer resources on the server, is the fastest mode for fetching data, and is the only mode to support processing multiple resultsets produced by a single batch of SQL statements. This mode reads rows in a forward-only, read-only fashion, however. Although multiple resultsets can be processed, the results must be read sequentially; you cannot interleave reads from the first and second resultset. This was due to the inner workings of the TDS protocol—the network protocol that SQL Server clients use.
In the SQL Server 2005 release, the SQL Server engine has been changed to permit multiple batches to be active simultaneously on a single connection. Because SQL Server batches can produce resultsets, this means that more than one cursorless-mode resultset can be read at the same time using the same connection. This feature was nicknamed MARS (multiple active resultsets). Although this feature is enabled on the server, the TDS protocol and client libraries had to be updated to permit clients to access this functionality. Figure 13-4 illustrates one way the functionality can be used.
Figure 13-4. MARS multiplexes resultsets over the same connection.

In the past, database APIs dealt with the single-batch limitation in different ways. In ADO (classic), for example, the API made it appear that you could execute multiple simultaneous batches, as shown in Listing 13-27.
Listing 13-27. ADO will silently open a new connection for each new result
Dim conn as New ADODB.Connection
Dim rs1 as New ADODB.Recordset
Dim rs2 as New ADODB.Recordset
rs1.Open "SELECT * FROM authors", conn
rs2.Open "SELECT * FROM jobs", conn
' Note: This only reads as many rows
' as are in the shortest resultset
' rows from the longest resultset are dropped
While not rs1.EOF and not rs2.EOF
Debug.Print rs1(0)
Debug.Print rs2(0)
rs1.MoveNext
rs2.MoveNext
Wend
conn.Close
Although this gave the appearance of multiple active batches, it was accomplished by a little library sleight of hand. The OLE DB provider simply opened additional connections under the covers to service the additional request. Although this prevented runtime errors, a well-meaning programmer could accidentally use up connections if he wasn’t aware of the way things worked. The code in Listing 13-28 will open a separate connection for every row in the loop that processes Recordset rs1.
Listing 13-28. The hazard of automatically opening new connections
Dim conn as New ADODB.Connection
Dim rs1 as New ADODB.Recordset
Dim rs2 as New ADODB.Recordset
rs1.Open "SELECT * FROM authors", conn
While not rs1.EOF
rs2.Open "SELECT * FROM titleauthor WHERE au_id = " & _
rs1("au_id"), conn
rs1.MoveNext
Wend
This behavior is controllable through a property on the OLE DB Data Source object, "Multiple Connections=false". This property is also available through ADO as an extended property on the Connection object.
Although it annoyed programmers who weren’t aware of how the protocol worked, ADO.NET’s way of dealing with the pre–SQL Server 2005 limitation was an improvement over ADO. When you attempted to open multiple batches containing results using SqlCommand.ExecuteReader, a runtime error occurred. The error message was verbose but exactly described the situation: “There is already an open DataReader associated with this Command, which must be closed first.” Programmers had to be careful to play by the rules.
Using MARS in ADO.NET 2.0
ADO.NET and other SQL Server APIs can use updated network library call to SNI—the SQL Server Networking Interface—to achieve true multiplexing of result batches on a single connection. Because this functionality is actually implemented on the server, it works only with a SQL Server 2005–release database, though OLE DB, ADO, and ODBC can take advantage of it, as well as ADO.NET. We’ll look at the implementation in ADO.NET first, although this is the API where you’d be least likely to use it.
MARS is enabled by connection-string parameters when you are using the ADO.NET data provider in .NET Framework 2.0 and a SQL Server 2005 client. You must use the connection-string parameter MultipleActiveResultSets=true to enable MARS support; the default value of this parameter is false.
Although you use the same SqlConnection instance with multiple resultsets, you must use different SqlCommand instances for each simultaneous resultset. The resultset is encapsulated by the SqlDataReader class, so you will have two SqlDataReaders as well. You can read from either SqlDataReader, although the behavior of SqlDataReader is still forward-only and read-only. Listing 13-29 shows a simple example.
Listing 13-29. Using multiple active resultsets in ADO.NET
string connect_string = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(
connect_string += ";multipleactiveresultsets=true");
conn.Open();
SqlCommand cmd1 = new SqlCommand(
"SELECT * FROM authors", conn);
SqlCommand cmd2 = new SqlCommand(
"SELECT * FROM jobs", conn);
SqlDataReader rdr1 = cmd1.ExecuteReader ();
// second resultset, same connection
SqlDataReader rdr2 = cmd2.ExecuteReader ();
while
((rdr1.Read() == true && rdr2.Read() == true))
{
// write first column of each resultset
Console.WriteLine (rdr1[0]);
Console.WriteLine (rdr2[0]);
}
// clean everything up
rdr1.Close(); rdr2.Close();
cmd1.Dispose(); cmd2.Dispose();
conn.Dispose();
Note also that each command can contain an entire batch of statements and return more than one resultset. The basic functionality of the cursorless-mode resultset has not changed, however, so these resultsets must be read in order. If, in the preceding example, the CommandText for cmd1 was SELECT * FROM authors;SELECT * FROM titles, we would read all the authors rows first, followed by the titles rows. This also does not change the fact that the stored-procedure output parameters are returned after all the resultsets, and the SqlDataReader must still be closed before the output parameters are available. See Chapter 3 of Essential ADO.NET, by Bob Beauchemin (Addison-Wesley, 2002), for details.
Although you can execute multiple batches in parallel over the same connection, parallel transactions over the same connection are not supported. The example in Listing 13-30 shows that the transaction is still scoped to the connection.
Listing 13-30. Even with MARS, transactions are scoped to the connection, not the command
string connect_string = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(connect_string);
conn.Open();
// one transaction
SqlTransaction tx1 = conn.BeginTransaction();
// this would fail
//SqlTransaction tx2 = conn.BeginTransaction();
SqlCommand cmd1 = new SqlCommand
("update_authors_and_getresults", conn, tx1);
// both SqlCommands must be enlisted
SqlCommand cmd2 = new SqlCommand(
"update_authors_and_getresults", conn, tx1);
cmd1.CommandType = CommandType.StoredProcedure;
cmd2.CommandType = CommandType.StoredProcedure;
SqlDataReader rdr1 = cmd1.ExecuteReader();
// second resultset, same connection
SqlDataReader rdr2 = cmd2.ExecuteReader();
while
((rdr1.Read() == true && rdr2.Read() == true))
{
// write first column of each resultset
Console.WriteLine (rdr1[0]);
Console.WriteLine (rdr2[0]);
}
// commit one transaction (both authors & jobs)
tx1.Commit();
// but you cannot roll back just one or the other,
// attempt to build second transaction failed
// tx2.Rollback();
// clean everything up
rdr1.Close(); rdr2.Close();
cmd1.Dispose(); cmd2.Dispose();
conn.Dispose();
Besides making things easier for the programmer, if multiple simultaneous operations need to be performed on the same connection, the MARS feature can be used in conjunction with the asynchronous execution feature, covered in Chapter 14, though this does not provide an overall performance improvement. MARS sessions do not execute in parallel but execute interleaved.
You should be careful using MARS, because if you execute two commands, the execution of the commands is not guaranteed to be in order. Also, do not use SQL statements that change the connection environment, such as the SQL "USE database" command. Because command execution in order of execution in the client is not guaranteed, there is the possibility that you could be changing database context at the “wrong” time. This could cause later commands to fail, as shown in Figure 13-5.
Figure 13-5. Command execution between sessions is not guaranteed to be serialized.

Because of the fact that the commands in multiple MARS sessions on the same connection are not guaranteed to be serialized, transaction Savepoints are not available when using MARS. In addition, transactions are scoped to the stored procedure or to the SQL batch when using MARS. If a transaction in a MARS session is not committed by the end of the stored procedure or SQL batch, the transaction will be rolled back automatically.
MARS in SQL Native Client
MARS support is also provided in the SQL Native Client driver and provider. You indicate that you want MARS support by using the connection-string name–value pair "MARS Connection=True". You can also use an OLE DB property SSPROP_INIT_MARSCONNECTION or an ODBC connection option SQL_COPT_SS_MARS_ENABLED, but the connection-string method will most likely be more popular, as it can also be used in ADO.
New Transaction and Isolation Features in ADO.NET
Using the New Isolation Levels
In Chapter 7, we discuss one of the biggest enhancements to the SQL Server engine in SQL Server 2005: the ability to use versioning rather than locking to achieve user isolation inside a SQL Server transaction. This capability is also exposed in the client in a way analogous to that on the server, as a database capability and a new transaction isolation level. The code to accomplish this using SqlClient is straightforward, as shown in Listing 13-31.
Listing 13-31. Using snapshot isolation level in ADO.NET
public void DoSnapshot()
{
string connstr = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(connstr);
conn.Open();
SqlCommand myCommand = conn.CreateCommand();
SqlTransaction tx = null;
// Start a local transaction.
tx = conn.BeginTransaction(IsolationLevel.Snapshot);
// Associate Command with Transaction
SqlCommand cmd = new SqlCommand(
"INSERT INTO jobs VALUES('new job', 100, 100)",
conn, tx);
try
{
// first insert
cmd.ExecuteNonQuery();
// second insert
cmd.CommandText =
"INSERT INTO jobs VALUES('Grand Poobah', 200, 200)", cmd.Exe-
cuteNonQuery();
tx.Commit();
}
catch(Exception e) {
try {
tx.Rollback();
}
catch (SqlException ex) {
// no-op catch, tx already rolled back
}
}
finally {
cmd.Dispose();
conn.Dispose();
}
}
This is normal client-side local transaction code; the only thing that may look a little odd is that when you roll back a transaction from the client, you do so in a try/catch block and ignore the error that you catch. This is because the transaction may already have been rolled back inside the database; attempting to roll back a nonexistent transaction will cause an exception. You can safely catch and ignore the exception.
In OLE DB and ODBC, the code is just as simple, and there is an enumerated constant for the SNAPSHOT isolation level in the C++ include file sqlncli.h in addition to the standard transaction isolation levels in transaction. h. Because the ADO library itself has not been updated for SQL Server 2005, if you want to use the SNAPSHOT isolation level with ADO, you must use the hard-coded value for the transaction isolation level of SNAPSHOT, because there is no enumerated constant. You can also use SET TRANSACTION ISOLATION LEVEL SNAPSHOT as part of a command batch to achieve this isolation level in any version of any of the data access APIs.
The isolation level specifically named IsolationLevel.Snapshot is actually transaction-level snapshot. This is the only new named isolation level in SQL Server 2005. Using statement-level snapshot isolation is transparent from the client; you need only enable statement-level snapshot on the database and use IsolationLevel.ReadCommitted, which is the default. The behavior of IsolationLevel.ReadCommitted in SQL Server 2005 depends entirely on the setting in the database.
Promotable and Declarative Transactions
Microsoft Transaction Server (MTS) and its successors, COM+ and System. EnterpriseServices, popularized the concept of distributed transactions, for better or worse. These server- and object-based libraries permitted programmers to specify automatic transactions on a class or method level. Because the COM+ interceptor had no knowledge of which database the instance was going to use, or whether it was going to use a single database or multiple databases, COM+ always began a distributed transaction.
Distributed transactions are always slower than local transactions—sometimes, much slower. The network traffic that is generated when the distributed transaction coordinator (MSDTC) is involved is substantial. For an in-depth description of how distributed transactions work and how MTS/COM+ works, refer to Transactional COM+, by Tim Ewald (Addison-Wesley, 2001).
Promotable transactions is a feature that transparently promotes an existing local transaction to a distributed transaction automatically if you access any other transactional resource manager (including another connection to SQL Server) inside a transactional method. Promotion also works on a single SQL Server and any other transactional resource that supports it. This requires code both inside the SQL engine and in the client-side libraries but does not require the programmer to write additional program logic. It is designed for cases where the new System. Transaction library is used to manipulate transactions. Simply starting a transaction and using a command to access multiple instances of SQL Server will cause the transaction to be promoted automatically. Listing 13-32 shows a simple example that illustrates using the TransactionScope class.
Listing 13-32. Using TransactionScope to obtain promotable transactions in ADO.NET
using (TransactionScope ts = new TransactionScope())
{
SqlConnection conn1 = new SqlConnection(
"server=.;integrated security=sspi;database=pubs");
// start local tx if SQL 2005, distributed tx if not
conn1.Open();
SqlCommand cmd1 = new SqlCommand(
"INSERT jobs VALUES('job1', 10, 10", conn1);
cmd1.ExecuteNonQuery();
SqlConnection conn2 = new SqlConnection(
"server=other;integrated security=sspi;database=pubs");
// promote to distributed tx if SQL 2005
conn2.Open();
SqlCommand cmd2 = new SqlCommand(
"INSERT jobs VALUES('job2', 10, 10", conn2);
cmd2.ExecuteNonQuery();
ts.Complete();
// dispose SqlCommands and SqlConnections here
} // commits transaction when TransactionStream.Dispose is called here
If you have used MTS or COM+ declarative transactions in the past, the same transaction composition functionality exists using System.Transactions and the TransactionScope. You can nest TransactionScope, for example. Inside a nested TransactionScope, you have the ability to use a composition option, TransactionScopeOption, that has the familiar (to MTS programmers) values Requires, RequiresNew, and Suppress. Programmers who attempt to use TransactionScope and promotable transactions, with the familiar MTS object composition pattern, may be surprised that even opening a second connection with exactly the same connection string will start a distributed transaction, even when SQL Server 2005 is the database. Listing 13-33 shows an example of this behavior.
Listing 13-33. Two identical connections produce a distributed transaction
using (TransactionScope ts = new TransactionScope())
{
SqlConnection conn1 = new SqlConnection(
"server=.;integrated security=sspi;database=pubs"))
// start local tx if SQL 2005, distributed tx if not
conn1.Open();
SqlCommand cmd1 = new SqlCommand(
"INSERT jobs VALUES('job1', 10, 10", conn1);
cmd1.ExecuteNonQuery();
// EXACT same connection string as the first one
// second connection always causes promotion to distributed tx
SqlConnection conn2 = new SqlConnection(
"server=.;integrated security=sspi;database=pubs");
conn2.Open();
SqlCommand cmd2 = new SqlCommand(
"INSERT jobs VALUES('job2', 10, 10", conn2);
cmd2.ExecuteNonQuery();
ts.Complete();
} // dispose SqlCommands and SqlConnections here
The new System.Transactions library is used for more than transaction promotion with SQL Server 2005. Because it does not require entries in the MTS/COM+ component catalog or require that .NET Framework classes be registered as COM classes, it probably will replace System.EnterpriseServices eventually. In addition, the System.Transactions library will be used with the .NET Framework implementation of the Web Service standard WS-Transactions.
Changes Related to SQL Server 2005 Login
Password Change Support
SQLServer 2005 will expire passwords on SQLServer security accounts, just as the Windows 2003 security authority expires passwords on Windows accounts used by SQL Server. Because you use a SQL Server account only to log onto SQL Server, the SqlClient libraries provide a secure mechanism allowing a SQL Server account to change password during login.
When a SQL Server user with an expired password attempts to log in using ADO.NET, a SQL Server user with an expired password will receive an exception with a specific SQL Server state code. After catching the error, the program can prompt for a password (there is no standard “password expired” dialog box), and obtain a new password and the old password from the user. The program will use a static method on the SqlConnection class, ChangePassword, to change the password on SQL Server. The server validates the old password against the password in the connection string, and ensures that the new password is policy compliant, so you can’t just put in a random string for the old password. Using the ChangePassword method looks something like Listing 13-34.
Listing 13-34. Setting a password using ADO.NET ChangePassword
string connstring = GetConnectionString();
SqlConnection conn = new SqlConnection(connstring);
for(int i=0; i < 2; i++)
{
try
{
conn.Open();
break;
}
catch(SqlException ex)
{
// 18487 = password expired
// 18488 = must change password on first login
if ((ex.Number == 18487) || (ex.Number == 18488))
{
// prompt the user for the new password
string newpw = PromptPassword();
// change it on SQL Server
// note that the first parameter of ChangePassword
// is a connection string containing the old password
// not just the old password
SqlConnection.ChangePassword(connstring, newpw);
// fix connection string in config and SqlConnection instance
// to include the new password
// reattempt the login
}
}
}
Note that you must define your own PromptPassword method and write program-specific code to change both the configuration file and the connection string currently being used to use the new password. It was a programmer inconvenience to hard-code connection strings containing passwords in programs in the past, because the source code needed to be changed if the administrator changed the password. With the advent of SQL Server password-expiration policies, connection strings containing passwords must be stored outside the program. Not only should they be stored in a configuration file, but the connection string should be encrypted to guard against unauthorized access through the configuration file.
In OLE DB, ADO, and ODBC, there is a special connection-string parameter, NewPassword, to permit setting the new password. Clients can watch for the 18486 and 18487 error numbers in these APIs, as in ADO.NET. The ability to change the password when it expires has been incorporated into the login dialog boxes in these APIs, when you use DBPROP_INIT_PROMPT in OLE DB ("Prompt" extended property on the ADO Connection object) or SQLDriverConnect with fDriverCompletion in ODBC.
Failover Support
When running against a SQL Server 2005 database, your SqlClient, OLE DB, ADO, or ODBC code can support automatic failover. This requires that the server use database mirroring2 and that you know the network names of both the running server and the mirror. You enable this by specifying "Failover Partner=partner name" in the connection string. When the database fails over, any transaction in progress will be rolled back the next time you try to issue a command on the “failed” connection, but then the client will automatically connect to the failover partner server. Be aware of the fact that on failover, the transaction in progress will be rolled back, or the work in progress must be redone. In addition, the connection will be dropped and must be reopened. Listing 13-35 shows an example that uses this functionality.
Listing 13-35. Using client failover with ADO.NET
// Connection string in program to show special parameters
using (SqlConnection conn = new SqlConnection(
@"server=.SQLDev01;failover partner=.SQLDev02;
integrated security=sspi;database=pubs"))
using (SqlCommand cmd = new SqlCommand())
{
conn.Open();
SqlTransaction tx = null;
for (int i = 1; i < 101; i++)
{
try
{
// failover will close the connection, you have to reopen it
// or put the conn.Open here
// and remove it from before the tx = null line
if (conn.State == System.Data.ConnectionState.Closed)
conn.Open();
cmd.Connection = conn;
tx = conn.BeginTransaction();
cmd.Transaction = tx;
cmd.CommandText = "insert jobs values('row " + i + "',10,10)";
int numrows = cmd.ExecuteNonQuery();
// stop at this line
// then fail the master instance to test
Console.WriteLine("row {0} added", i);
tx.Commit();
Console.WriteLine("transaction {0} committed", i);
}
catch (Exception e)
{
Console.WriteLine(e.Message);
try
{
// this has to be in a try/catch block with no catch
// because losing the master will cause a transaction
// that cannot be committed on rolled back
tx.Rollback();
}
catch { }
}
}
} // SqlConnection and SqlCommand disposed here
Encryption Support
SQL Server 2005 does not have a distinct multiprotocol library to support encrypted data connections, as SQL Server 2000 does. Instead, it will rely on having a certificate available, because SQL Server 2005 can always generate certificates internally, even if there are no certificates currently installed. If SQL Server must generate a certificate to use to negotiate a session key for data encryption, it will generate a self-signed certificate, for which SQL Server itself is the root certificate authority. If a company does not want to provision client certificates, each SqlClient connection can choose to trust the SQL Server self-signed certificate. A client indicates this by using TrustServerCertificate=true along with Encrypt=true in the connection string. If certificates are provisioned to both the server and clients, the TrustServerCertificate parameter is not necessary. Note that using TrustServerCertificate=true is subject to man-in-the-middle attacks—a common security attack vector.
Comparing the Client and Server Model for Stored Procedures
With the advent of procedural code that can be written using System. Data.SqlClient either on the client or server, the question has arisen when to use a series of textual SQL commands and when to encapsulate these commands into a .NET Framework method that can be executed on the client or transparently moved to the server and declared as a .NET Framework stored procedure. In addition, SQL Server 2005 adds UDTs into the mix, and allows complex types with properties and methods to execute either on the server or on the client. With so much functionality at any tier, what are the best coding practices and deployment techniques? We’ll discuss this more in Chapter 17, but for now, let’s mention stored procedures invoked from the client versus procedural code invoked on the server.
The SQL Server engine works best fetching and operating on its own data, managing execution plans, memory buffers, and data buffers. If you could do the same on the client, you would have replicated the database functionality à la XBase databases. If, however, you are going to perform operations that SQL Server doesn’t support internally—say, processor-intensive operations—you could use the server to query and filter your data down to a small subset and then distribute processor-intensive operations to every client. These operations wouldn’t necessarily need to involve traditional data management unless you are working with UDTs that need to be sorted and grouped and that don’t support binary ordering. So in general, for data-intensive operations, stored procedures executed on the server with results returned to the client in a single round trip are still best.
Bear in mind that all the client functionality of the SqlClient data provider does not work inside SQLCLR stored procedures. Query Notifications and MARS are two examples; neither works when you are using SqlClient on the server. See Chapter 4 for a list of client-and server-specific SqlClient classes and methods.
Where Are We?
In this chapter, we’ve seen how the new SQL Server data types, especially UDTs and the XML type, affect the client libraries and cause us to rethink our coding models. Although ADO.NET has the richest support for the new nonrelational types, OLE DB and ADO (mostly because of COM interop and rich XML support) can take advantage of them as well. Because the authors of the SQL:1999 specification did not enhance SQL/CLI, the call language interface implemented by Microsoft and others as ODBC, this API has only cursory support for the new complex types.
In Chapter 14, we’ll look at the plethora of other new features exposed through the ADO.NET APIs in the client tier. Some of these enhancements are SQL Server–specific but work with older versions of SQL Server; others are enhancements to the ADO.NET framework itself.