
14. ADO.NET 2.0 and SqlClient
IN THIS CHAPTER, we round out the functionality enhancements for SQL Server clients and go into some general ADO.NET provider-model enhancements. All these enhancements are backward compatible—that is, they work with SQL Server 2000 and SQL Server 7 as well. We'll look at these enhancements using the ADO.NET SqlClient provider, though we'll point out where equivalent new functionality is available to other ADO.NET data providers or through other APIs.
Generic Coding with the ADO.NET 2.0 Base Classes and Factories
ADO.NET is a database-agnostic API. It is an API in which database vendors write plug-in data providers for their database … la OLE DB/ADO (providers), ODBC (drivers), or JDBC (drivers), rather than a database-specific set of functions like dbLib or a database-specific object model like OO4O (Oracle Objects for OLE). Predecessors of ADO.NET factored their providers into sets of interfaces, defined by a strict specification. Each OLE DB provider writer implemented a standard set of interfaces, although this could include required and optional interfaces. Required interfaces specified the lowest common denominator; optional interfaces were defined for advanced database/provider features. Although the OLE DB specification permitted providers to add new interfaces to encapsulate database-specific functionality, the library that programmers used with OLE DB providers, ADO, generally did not use those interfaces.
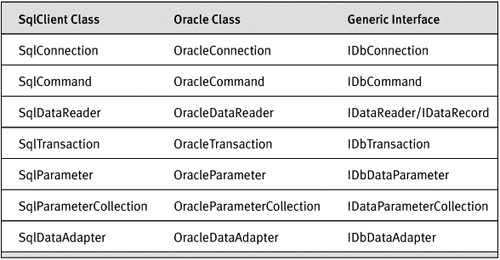
ADO.NET was designed from the beginning to allow the provider writer space to support database-specific features. Provider writers implemented a set of classes, such as a Connection class, Command class, and DataReader class. Because classes as well as interfaces are visible in the .NET Framework (in COM, in general only interfaces were visible to the programmer), ADO.NET provider writers implement a set of provider-specific classes, exposing generic functionality via interfaces and database-specific functions as class methods. Each provider writer implemented his own parallel hierarchy of classes. Table 14-1 shows the parallel class hierarchies for the SqlClient and the OracleClient data providers, as well as the interface implemented by both data providers. These interfaces are defined in the System.Data namespace.
Table 14-1. Provider-Specific Classes and Generic Interfaces in ADO.NET 1.0/1.1
In ADO.NET 1.0 and 1.1, programmers had two choices: They could code to the provider-specific classes, or they could code to the generic interfaces. If there was the possibility that the company database could change during the projected lifetime of the software, or if the product was a commercial package intended to support customers with different databases, they had to program with the generic interfaces. You can’t “new” an interface, so most generic programs included code that accomplished the task of obtaining the original IDbConnection by calling “new” on the appropriate provider-specific class, as shown in Listing 14-1.
Listing 14-1. Generic code using interfaces in ADO.NET 1.0 and 1.1
enum provider {sqlserver, oracle, oledb, odbc};
public IDbConnection GetConnectionInterface()
{
// determine provider from configuration
provider prov = GetProviderFromConfigFile();
IDbConnection conn = null;
switch (prov) {
case provider.sqlserver:
conn = new SqlConnection(); break;
case provider.oracle:
conn = new OracleConnection(); break;
// add new providers as the application supports them
}
return conn;
}
The GetProviderFromConfigFile method referred to above was handcoded by each company, as was the mechanism for storing the provider information in the configuration file. In addition, vendors that supported multiple databases had to write vendor-specific code to allow the user or software programmer to choose which database to use at installation time.
ADO.NET 2.0 codifies configuration, setup, and generic coding with a prescribed set of base classes for providers to implement, connection-string setup and handling, and factory classes to standardize obtaining a provider-specific Connection, Command, and so on. These features make it easier for software companies that support running on the user’s choice of database, as well as for programmers who think that the database might change (from Access to SQL Server, for example) during the lifetime of the project.
ADO.NET adds new features to the “base provider profile” with each release. Version 1.1 added a property to the DataReader to allow the programmer to determine whether the DataReader contained a nonzero number of rows (the HasRows property) without calling IDataReader.Read. Because interfaces are immutable, this property could not just be added to the IDataReader interface; this new property had to be added to each provider-specific class (SqlDataReader, OleDbDataReader, and so on). The usual way to use versioning with interfaces is to define a new interface. This new interface could either extend the original interface (IDataReader2 inherits from IDataReader and adds HasRows) or includes only the new functionality (IDataReaderNewStuff contains only HasRows).
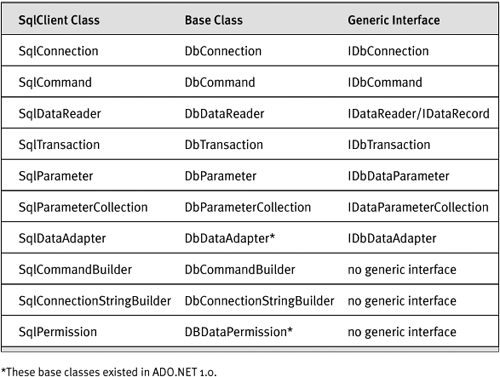
Another way to version functionality is to use base classes. Although using base classes restricts the class inheritance model (each class can inherit from only a single base class in the .NET Framework), this is the preferred mechanism if you expect changes to your set of functionality in the future. Lots of new functionality is exposed in ADO.NET 2.0, and more changes are expected going forward, and so the model now uses base classes instead of interfaces. The ADO.NET 1.0/1.1 interfaces are retained for backward compatibility, however. To use our original example, ADO.NET 2.0 contains a DbDataReader class that includes a HasRows property. More properties, methods, and events can be added in the future. The only ADO.NET 1.0/1.1 provider class to be based on the base class concept was the DataAdapter; all provider-specific base classes, such as SqlDataAdapter, derived from DbDataAdapter, which derived from DataAdapter. The new ADO.NET provider base classes are listed in Table 14-2. These classes are defined in System.Data.Common. All new generic functionality is included in the base classes (but not the interfaces) in ADO.NET.
Table 14-2. Generic Base Classes and Generic Interfaces in ADO.NET 2.0
In addition to these “main” base classes, many new base classes were added in ADO.NET 2.0, including some that we’ll be talking about later in this chapter. The provider base classes in ADO.NET are abstract, however, meaning that they can’t be instantiated directly, either. Our interface-based code would change to the code shown in Listing 14-2.
Listing 14-2. Adding new providers means changing code
enum provider {sqlserver, oracle, oledb, odbc};
public DbConnection GetConnectionBaseClass()
{
// determine provider from configuration
provider prov = GetProviderFromConfigFile();
DbConnection conn = null;
switch (prov) {
case provider.sqlserver:
conn = new SqlConnection(); break;
case provider.oracle:
conn = new OracleConnection(); break;
// add new providers as the application supports them
}
return conn;
}
That wouldn’t be much of an improvement from a programmer-usability standpoint. Enter provider factories.
Provider Factories
Rather than rely on the case statements above, it would be nice to have a class that gave out a DbConnection, for example, based on instantiating the “correct” provider-specific connection. But how do you know whether to instantiate SqlConnection or OracleConnection? The solution is to use a Provider Factory class to give out the right type of concrete class. Each provider implements a provider factory class—for example, SqlProvider Factory, OracleProviderFactory, or OleDbProviderFactory. These classes all derive from DbProviderFactory and contain static (shared in Visual Basic .NET) methods to dole out creatable classes. Here’s the list of DbProviderFactory’s methods:
• CreateCommand
• CreateCommandBuilder
• CreateConnectionStringBuilder
• CreateDataAdapter
• CreateDataSourceEnumerator
• CreateParameter
• CreatePermission
• CanCreateDataSourceEnumerator (read-only property)
Note that we don’t need a CreateDbDataReader class, for example, because DbDataReader isn’t creatable directly with the “new” operator; it’s always created via DbCommand.ExecuteReader().
Each data provider that exposes a DbProviderFactory-based class registers configuration information in machine.config. This information can also be added to program-specific configuration files like web.config. A typical entry in machine.config for the SqlClient data provider looks like this:
<system.data>
<DbProviderFactories>
<add name="SqlClient Data Provider"
invariant="System.Data.SqlClient"
description=".Net Framework Data Provider for SqlServer"
type="System.Data.SqlClient.SqlClientFactory, System.Data,
Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" />
<!--other provider entries elided —>
</DbProviderFactories>
</system.data>
Some of these attributes can be used for displaying a list of available data providers. One important attribute, from a programming point of view, is invariant—the provider-invariant name that can be passed as a string to the DbProviderFactories class, mentioned in the next paragraph.
The DbProviderFactories class, which you could think of as “a factory for factories,” has static methods to accommodate choosing a provider and instantiating its DbProviderFactory. These methods are listed in Table 14-3.
Table 14-3. DbProviderFactories Methods
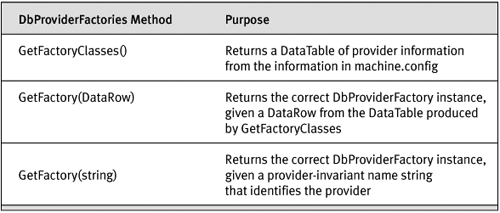
The methods of DbProviderFactories could be used to produce a drop-down list box with a list of .NET Framework data providers (via GetFactoryClasses), let the user choose one, and instantiate the correct DbProviderFactory via GetFactory(DataRow), or just get the correct DbProviderFactory with a string. So now, if we choose to prompt the user for a provider to use, our code to select a provider and instantiate a DbConnection looks like Listing 14-3.
Listing 14-3. Using the ProviderFactories class to obtain a ProviderFactory
public DbConnection GetConnectionBaseClass2()
{
DbProviderFactory f = GetProviderFactoryFromUserInput();
// call provider factory-specific CreateConnection
return f.CreateConnection();
}
public DbProviderFactory GetProviderFactoryFromUserInput()
{
DataTable t = DbProviderFactories.GetFactoryClasses();
int selected_row;
DataRow r;
// code elided,
// user selects a DataRow selected_row from DataTable t
r = t.Rows[selected_row];
return DbProviderFactories.GetFactory(r);
}
When we have the appropriate DbProviderFactory, we can instantiate any of the creatable classes that the provider supports; the DbConnection is just the most common example.
This takes care of allowing the user to configure a provider, but this is usually done once, during setup of a particular application. After setting up the database and choosing a database instance, this information should be stored in a user’s config file, and it should be changed only if the company changes database products or if the location of the database instance changes (for example, the application moves from a test server to a production server). ADO.NET 2.0 accommodates both of these cases with built-in functionality; you don’t have to roll your own.
Specifying Configuration Information
In addition to the DbProviderFactories section of configuration files, there are a standard config file location and APIs for manipulating connectionstring information. This requires a little more handling than name–value pairs that you might expect. OLE DB/ADO, ODBC, and JDBC connection strings contain two discrete types of information: information identifying the provider/driver and name–value pairs of information describing how to connect to the provider. Here’s a typical ADO (classic) connection string:
"provider=sqloledb;data source=mysvr;integrated security=sspi;initial
catalog=pubs"
When the Visual Basic 6.0 programmer codes the statement
Dim conn as New Connection
conn.Open connstr 'use the connection string defined above
the connection-string information is used by the OLE DB service components to:
• Search the Registry and load the correct provider (CoCreateInstance on the OLE DB data source class for the provider name specified)
• Create an ADO Connection instance that encapsulates the OLE DB Data Source (and Session) objects
• Return the correct ADO interface pointer (_Connection, in this case) to the program
• Call Open() on the ADO _Connection interface, which calls the underlying OLE DB provider code using OLE DB interfaces
ADO.NET database-specific connection strings do not contain provider information.1 Programmers must decide which provider to use at program coding time or invent a mechanism to store that information. ADO.NET 2.0 connection configuration information takes care of this. A typical ADO. NET 2.0 connection string in an application configuration file looks like this
<configuration>
<connectionStrings>
<add name="Publications" providerName="System.Data.SqlClient"
connectionString="Data Source=MyServer;Initial Catalog=pubs;
integrated security=SSPI" />
</connectionStrings>
</configuration>
and contains a connection-string name and provider name, as well as the connection string itself.
This information is exposed through the ConnectionStringsSettings Collection collection class of ConnectionStringSettings. You can fetch a connection string by name and retrieve all the needed information with very little code. Using the connection-string information above, the generic DbConnection fetching program becomes the code shown in Listing 14-4.
Listing 14-4. Getting a generic DbConnection
public DbConnection GetInitializedConnectionBaseClass()
{
DbConnection conn = null;
ConnectionStringSettings s =
ConfigurationManager.ConnectionStrings["Publications"];
DbProviderFactory f = DbProviderFactories.GetFactory(
s.ProviderName);
conn = f.CreateConnection();
conn.ConnectionString = s.ConnectionString;
return conn;
}
Storing named connection-string information is just as easy using the ConnectionStringSettingsCollection class, as we’ll see later in this chapter.
Enumerating Data Sources and Building Connection Strings
So now, we can configure and load connection strings, and get a connection to the database using ADO.NET 2.0 in a completely provider-independent manner. But what if the database that you’re connecting to changes? The DBAs have moved the data you’re using from the “Publications” instance of SQL Server to the “Bookstore” instance, and you’ve received e-mail that your configuration should be changed. Although Microsoft System Management Server (SMS) or other automatic deployment could be used to automate the process of pushing the new configuration, a program could be written to list all the SQL Server databases on the network and allow you to reconfigure it yourself. ADO.NET 2.0 introduces Data Source Enumerator classes just for that purpose.
The ADO.NET data source enumerators derive from a common base class (of course): DbDataSourceEnumerator. You can retrieve the appropriate DbDataSourceEnumerator through the DbProviderFactory using the pattern described above. In addition, you can use SqlDataSource Enumerator’s static property, named “Instance,” to get an instance, like this: SqlDataSourceEnumerator en = SqlDataSourceEnumerator.Instance.
DbDataSourceEnumerator classes expose a single instance method, GetDataSources. If my database or data source changes, the code to change it would look like Listing 14-5.
Listing 14-5. Using ADO.NET to change the data source in a connection string
public void ChangeDataSourceOrProvider()
{
// see this method in the example above
DbProviderFactory f = GetProviderFactoryFromUserInput();
// if our factory supports creating a DbConnection, return it.
if (f.CanCreateDataSourceEnumerator)
{
DbDataSourceEnumerator e = f.CreateDataSourceEnumerator();
DataTable t = e.GetDataSources();
// code elided, user chooses a Data Row selected_row
int selected_row = 0;
DataRow r = t.Rows["selected_row"];
string dataSource = (string)r["ServerName"];
if (r[InstanceName] != null)
dataSource += ("\" + r["InstanceName"]);
// change "Pubs" connection string, this method is defined below
RewriteConnectionStringAndUpdateConfigFile(f, dataSource, "Pubs");
}
else
Console.WriteLine("Source must be changed manually");
}
Note that this was fairly simple generic code, with the exception of the last RewriteConnectionStringAndUpdateConfigFile method. Because connection strings are name–value pairs, we’ll have to do some string manipulation to ensure that we’re replacing the right value. And what if not only the instance of the database changes, but also other connection-string parameters, such as the User ID or Initial Catalog (Database)? It would be nice to have a built-in class to help with this task. ADO.NET 2.0 provides just such a class: the generic base class DbConnectionStringBuilder.
In ADO.NET, connection strings are name–value pairs, as with other generic APIs. Unlike OLE DB and ODBC, ADO.NET does not mandate what those name keywords should be, though it is suggested that they follow the OLE DB conventions. The OleDb and Odbc bridge data providers each follow their own convention. Microsoft’s OracleClient follows OLE DB convention, and SqlClient supports either keyword when the OLE DB and ODBC keywords differ. Table 14-4 contains some examples.
Table 14-4. Example Connection-String Parameters in SQL Server APIs

The DbConnectionStringBuilder is a base class for provider-specific connection-string builders. Because it cannot be guaranteed that an ADO. NET data provider supports a specific connection-string parameter, the Db ConnectionStringBuilder just keeps a dictionary of name–value pairs. All the ordinary collection methods are available, including a GetKeys and GetValues method to get the entire list from the dictionary. DbConnectionStringBuilder does support some specific properties to do with connection-string parameters, such as ShouldSerialize (the user may not want the password value serialized into a file, for example). You can get an instance of the generic DbConnectionStringBuilder through the DbProviderFactory class. Specific ConnectionStringBuilder classes have convenience properties, such as a Data Source property that refers to the database server to connect to. In general, the properties are data provider–specific, as the keywords are.
To implement the RewriteConnectionStringAndUpdateConfigFile method mentioned earlier in this chapter, using the DbConnection-StringBuilder would look like Listing 14-6.
Listing 14-6. Rewriting the connection string
public void RewriteConnectionStringAndUpdateConfigFile(
DbProviderFactory f, string dataSource, string name)
{
Configuration config =
ConfigurationManager.OpenExeConfiguration(ConfigurationUserLevel.None);
DbConnectionStringBuilder b = f.CreateConnectionStringBuilder();
b.ConnectionString =
config.ConnectionStrings.ConnectionStrings[name].ConnectionString;
if (b.ContainsKey("Data Source"))
{
b.Remove("Data Source");
b.Add("Data Source", dataSource);
// Update ConfigurationSettings connection string
config.ConnectionStrings.ConnectionStrings[name].ConnectionString =
b.ConnectionString;
config.Save(ConfigurationSaveMode.Modified);
}
One last thing to mention about building connection strings: Both ODBC and OLE DB provide graphic editors for configuring connection information. The ODBC editor is contained in a Control Panel applet (Configure ODBC Data Sources). The OLE DB editor is invoked whenever a file with the extension .udl is double-clicked. In Visual Studio 2003, the OLE DB UDL editor is used to configure .NET Framework data providers; the connection strings for SqlClient must be postprocessed by Visual Studio itself. Visual Studio 2005 contains a graphic editor that uses the DbConnectionStringBuilder and ProviderFactories classes. To have a look at it, configure a new data source in Visual Studio .NET, using the Server Explorer window. It lists the .NET Framework data providers, not the OLE DB providers anymore! This component is not usable directly, but the DbConnectionStringBuilder class can easily be bound to the PropertyGrid control as a data source. There are also provider-specific subclasses of DbConnectionStringBuilder that expose provider-specific connectionstring parameters.
Other Generic Coding Considerations
So now, using ADO.NET 2.0, common base classes, and factories, we can write almost completely generic code. Databases, however, by their very nature aren’t completely generic. Programmers never have been able to write one program that will work on every database and have it perform the same on each one. One big example of this is that strategies that work well on client-server databases (like SQL Server and Oracle) wouldn’t work as well on file-based data stores (like Access and FoxPro). As we programmers found out in the ADO era, porting between file-based and clientserver (network-based) involves a little more than changing the provider and connection string.
Each data provider may support some properties, methods, and events that are not supported by other data providers. The premise behind the base classes is that they expose generic functionality; providerspecific functionality is exposed on the provider-specific classes. These extras are always available through casting using the cast syntax, "as" or "is" in C#, or the CType method in Visual Basic .NET. Here’s an example of using the SqlConnection-specific method RetrieveStatistics from C# code:
public void GetStatsIfPossible(DbConnection conn)
{
if (conn is SqlConnection)
Hashtable h = ((SqlConnection)conn).RetrieveStatistics();
}
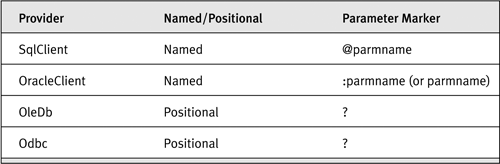
Another place where providers differ is in their usage of parameters in parameterized queries or stored procedures. In ADO.NET, data providers can support named parameters (the parameter name is significant; the order in which parameters are specified is irrelevant), positional parameters (the parameter order is significant; the name is irrelevant), or both. Sql-Client and Microsoft’s OracleClient provider insist on named parameters; OleDb and Odbc use positional parameters. Another difference is parameter markers, if you are using parameterized queries. Each provider has its own idea of what the parameter marker should be. Table 14-5 contains a short list of differences, using the providers that ship with ADO.NET as an example. If you obtain providers from DataDirect Technologies or Oracle Corporation, these can differ.
Table 14-5. Parameter Styles and Parameter Markers in ADO.NET 2.0 Data Providers
Other differences are based on how the database’s network protocol works. The network protocol defines the way that result packets are returned from database to client. SQL Server uses TDS (Tabular Data Stream) protocol, for example; Oracle uses TNS (transparent network substrate). Because of how the database and protocol work, versions of SQL Server prior to SQL Server 2005 can have only one active resultset (DataReader, in ADO.NET terms) at a time. SQL Server 2005 does not have this limitation; the feature that permits multiple active resultsets on a single connection is known as MARS. In SQL Server, output parameters are available only after resultsets are returned and the DataReader is closed. Oracle, on the other hand, returns resultsets from stored procedures as a special type of output parameter, REFCURSOR, and has different behaviors with respect to DataReaders and output parameters. Nothing is completely generic, although ADO.NET 2.0 provides a way to find out such provider-specific data through generic metadata information.
Schemas in ADO.NET 2.0
As we’ve mentioned, Visual Studio 2005 Server Explorer now uses a dialog box containing a list of .NET Framework data providers (rather than OLE DB providers) to prompt for connection information. When you decide on a connection string and add a Data Connection, each Data Connection also displays a tree of information about the database objects (such as tables, views, and stored procedures) visible directly through the connection. But where does this information come from? Is Visual Studio 2005 hard-coded to produce this information only for certain data providers, leaving you with an empty node if you write your own data provider or buy one from a third party? Not in Visual Studio 2005. All this good information is brought to you courtesy of the new Schema API in ADO.NET 2.0. We don’t know whether this is exactly the way that Visual Studio 2005 does it, but Listing 14-7 shows code to get a list of tables in a database using the new APIs.
Listing 14-7. Using GetSchema to get a list of tables
// uses a ADO.NET 2.0 named connection string in config file
// uses ADO.NET 2.0 ProviderFactory and base classes
public static void GetListOfTables(string connectstring_name)
{
ConnectionStringSettings s =
ConfigurationManager.ConnectionStrings[connectstring_name];
DbProviderFactory f = DbProviderFactories.GetFactory(s.ProviderName);
using (DbConnection conn = f.CreateConnection())
{
conn.ConnectionString = s.ConnectionString;
conn.Open();
DataTable t = conn.GetSchema("Tables");
t.WriteXml("tables.xml");
}
}
Who Needs Metadata, Anyway?
Metadata is part of every data access API. Although the primary consumers of metadata are tools like Visual Studio 2005 or code generators like DeKlarit, they’re not the only users. Application package designers may allow end users to customize an application by adding new tables or new columns to existing tables. When end users change the database schema like this, a general-purpose query and modification tool can use metadata to include the users’ new tables in maintenance, backup, and other application functions just as though they were built-in tables that shipped with the application. Programmers can use metadata to write their own custom classes that derive from System.Data.Common.DbCommandBuilder and build insert, update, and delete commands for use with the DataSet. Builders of multidatabase applications (that is, applications designed to run on the user’s choice of database) can use metadata to maintain a common codebase as much as possible, optimizing the data access code when needed.
It’s better to expose the metadata through a generic metadata API than to have each consumer use the database-specific API. That way, tool writers can maintain a more manageable codebase. Such an API must be very flexible as well, because there are three obstacles to consider when writing a generic API to expose metadata.
The metadata collections and information differ among databases. Users of SQL Server might want to expose a collection of linked servers, for example; Oracle users might be interested in information about Oracle SEQUENCEs.
The underlying system tables in which common database metadata is stored is different, not only in different database products, but also in different versions of the same database. SQL Server 2005, for example, exposes its metadata using new metadata views under a sys schema, sys.tables, whereas previous versions of SQL Server use metadata tables such as sysobjects to store the same data.
Different programs may want to expose different views of metadata. As an example, many programmers complain about long lists of tables in an Oracle database because most metadata APIs mix “system” tables with user tables. They’d like to have a short list that consists only of tables they defined.
Most database APIs approach this by providing a standard set of metadata that all providers must support and allowing provider writers to add new metadata tables. This is consistent with the approach taken by the ANSI SQL standard. The part of the standard that addresses this is the Schema Schemata (INFORMATION_SCHEMAand DEFINITION_SCHEMA), part 11. The ANSI SQL INFORMATION_SCHEMA defines a standard set of metadata views to be supported by a compliant database. But even the spec needs to have a way to address the points above. It states that “implementers are free to add additional tables to the INFORMATION_SCHEMA or additional columns to the predefined INFORMATION_SCHEMA tables.”
As an example of a data access API consistent in concept with the ANSI SQL standard, OLE DB defined a series of metadata that it called “Schema Rowsets.” It started with a predefined set that roughly followed the INFORMATION_SCHEMA and added OLE DB–specific columns to each one. ADO.NET 2.0 provides an even more powerful and flexible mechanism to expose metadata.
What Metadata Is Available?
ADO.NET 2.0 permits a provider writer to expose five different types of metadata. These main metadata meta-collections or categories are enumerated in the class System.Data.Common.DbMetaDataCollectionNames:
• MetaDataCollections—A list of metadata collections available.
• Restrictions—For each metadata collection, an array of qualifiers that can be used to restrict the scope of the schema information requested.
• DataSourceInformation—Information about the instance of the database the data provider references.
• DataTypes—A set of information about each data type the database supports.
• ReservedWords—Reserved words for that database’s query language. Usually, query language equates to a SQL dialect.
Using DbConnection.GetSchema, however, these metadata categories are also considered to be metadata. What this means in terms of code is that these collections can be obtained like ordinary metadata, as shown in Listing 14-8.
Listing 14-8. Getting the restrictions on metadata for VIEWs
// gets information about database Views
Table t1 = conn.GetSchema("Views");
// gets information about collections exposed by this provider
// this includes the five "meta-collections" described above
Table t2 = conn.GetSchema(DbMetaDataCollectionNames.MetaDataCollections);
// gets information about the Restrictions meta-collection
Table t3 = conn.GetSchema(DbMetaDataCollectionNames.Restrictions);
// No argument overload is same as asking for MetaDataCollections
Table t4 = conn.GetSchema();
Some of the five metacollections deserve further explanation.
Restrictions can be used to limit the amount of metadata returned. If you are familiar with OLE DB or ADO, the term restriction means the same thing in those APIs. As an example, let’s use the MetaDataCollection "Columns"—that is, the set of column names in tables. This collection can be used to get all the columns in all tables. The set of columns requested, however, can be restricted by database name, by owner/schema, or by table. Each metadata collection can have a different number of possible restrictions, and each restriction can have a default. Following along with our example, Listing 14-9 shows an XML representation of the restrictions for the Columns metadata.
Listing 14-9. Restrictions on the columns collection (XML format)
<Restrictions>
<CollectionName>Columns</CollectionName>
<RestrictionName>Catalog</RestrictionName>
<RestrictionDefault>table_catalog</RestrictionDefault>
<RestrictionNumber>1</RestrictionNumber>
</Restrictions>
<Restrictions>
<CollectionName>Columns</CollectionName>
<RestrictionName>Owner</RestrictionName>
<RestrictionDefault>table_schema</RestrictionDefault>
<RestrictionNumber>2</RestrictionNumber>
</Restrictions>
<Restrictions>
<CollectionName>Columns</CollectionName>
<RestrictionName>Table</RestrictionName>
<RestrictionDefault>table_name</RestrictionDefault>
<RestrictionNumber>3</RestrictionNumber>
</Restrictions>
<Restrictions>
<CollectionName>Columns</CollectionName>
<RestrictionName>Column</RestrictionName>
<RestrictionDefault>column_name</RestrictionDefault>
<RestrictionNumber>4</RestrictionNumber>
</Restrictions>
Restrictions are specified using an overload of DbConnection. GetSchema. The restrictions are specified as an array. You can specify an array as large as the entire restrictions collections or a subset array, because RestrictionNumbers usually progress from least restrictive to most restrictive. Use a null value (not database NULL, but .NET Framework null; Nothing in Visual Basic .NET) for restriction values you want to leave out. Listing 14-10 shows an example of using restrictions.
Listing 14-10. Using restrictions with GetSchema
// restriction string array
string[] res = new string[4];
// all columns, all tables owned by dbo
res[1] = "dbo";
DataTable t1 = conn.GetSchema("Columns", res);
// clear collection
for (int i = 0; i < 4; i++) res[i] = null;
// all columns, all tables named "authors", any owner/schema
res[2] = "authors";
DataTable t2 = conn.GetSchema("Columns", res);
// clear collection
for (int i = 0; i < 4; i++) res[i] = null;
// columns named au_lname
// all tables named "authors", any owner/schema
res[2] = "authors"; res[3] = "au_lname";
DataTable t3 = conn.GetSchema("Columns", res);
// clear collection
for (int i = 0; i < 4; i++) res[i] = null;
// columns named au_lname
// any tables, any owner/schema
res[3] = "name";
DataTable t4 = conn.GetSchema("Columns", res);
You need not specify the entire array of restrictions. In the case above, where you’d like to see only columns in tables owned by “dbo,” you can specify an array with only two members instead of all four. Note also that specifying an empty string as a restriction is different from specifying a null (Nothing in Visual Basic .NET) value. You do not need to memorize the restrictions; you can always query for them, just as you can with any other collection. The Restrictions collection itself does not allow restrictions, but because the information is fetched into a Data Table, you can use a DataView to provide similar functionality, as shown in Listing 14-11.
Listing 14-11. Fetching restriction metadata using GetSchema
DataTable tv = conn.GetSchema(DbMetaDataCollectionNames.Restrictions);
DataView v = tv.DefaultView;
// show restrictions on the "Columns" collection, sorted by number
v.RowFilter = "CollectionName = 'Columns'";
v.Sort = "RestrictionNumber";
for (int i = 0; i < tv.Count; i++)
Console.WriteLine("{0} (default){1}",
tv.Rows[i]["RestrictionName"],
tv.Rows[i]["RestrictionDefault"]);
The DataSourceInformation collection provides information about the current instance of the database (data source) for query builders. Although this collection can contain anything the provider desires, in the Microsoft providers (SqlClient, OracleClient, OleDb, and Odbc), this collection contains similar information. Table 14-6 lists the information you get by default.
Table 14-6. DataSourceInformation in Microsoft Providers
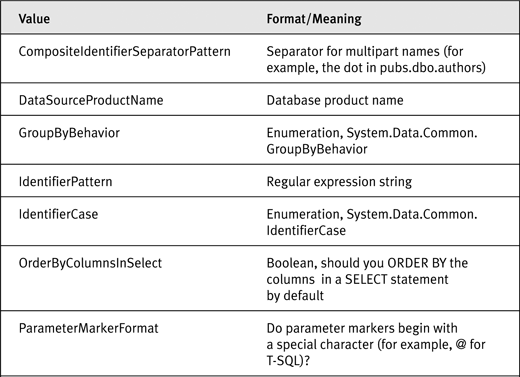
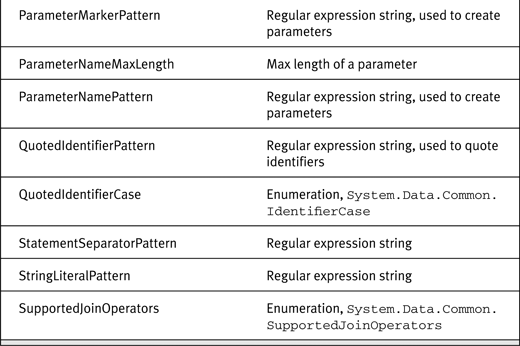
More than enough information to produce SQL for a particular database dialect, don’t you think? There is just one more piece of information we’d like, and that’s whether the provider uses named parameters or positional parameters in parameterized queries. We mentioned named and positional parameters earlier in this chapter as two ways to write parameterized commands.
Customizing and Extending the Metadata
Now that we’ve seen the base metadata that is provided and can find our way around DbConnection.GetSchema, let’s look at the ways that provider writers can customize metadata using a simple declarative format and how programmers can hook into that format. This discussion ties back to our original metadata complications: how to provide database-versionindependent metadata and how to deal with the fact that different customers may want different views of the same metadata.
Provider writers can hard-code metadata logic directly into their providers, each provider-writer using a potentially different internal algorithm for obtaining similar metadata. This is the way it’s been done in the past—for example, in implementing OLE DB’s ISchemaRowset method. In ADO.NET 2.0, however, Microsoft’s four shipping providers all use base classes in the System.Data.ProviderBase namespace, so they all implement schemas similarly. We’ll use this implementation for exposition, hoping that major provider-writing players like DataDirect Technologies and other provider writers will use it too.
The base class for exposing metadata is DbMetaDataFactory. Each provider that implements a subclass of it uses an XML file to define its metadata fetching behavior. These files are embedded resources in System.Data.dll and System.Data.OracleClient.dll. You can look at the raw XML files by running ildasm.exe (the.NET Framework intermediate language utility) from the command line:
>ildasm.exe System.Data.dll /out:dummy.il
This produces the XML resource files as a side effect. The files we’re looking for have names like System.Data.SqlClient.SqlMetaData.xml. You can safely throw away dummy.il.
Looking at the XML resource files produced from ildasm peels another layer off the onion. The file enumerates the collections that are supported and the information contained in each metacollection (through the schema), and appears to be the output of the DataSet.WriteXml method using the DataSet.WriteXml(XmlWriteMode.WriteSchema) overload. The most interesting bits are the MinimumVersion/MaximumVersion elements in all the metacollections except DataSourceInformation and the Population Mechanism/PopulationString subelements in the MetaDataCollections elements.
Using MinimumVersion/MaximumVersion allows the provider writer to specify which metadata queries to execute for different versions of the database. By using multiple elements for a single MetaDataCollection, you can make GetSchema act differently for different versions of the database. As an obvious example, you could use different versions for SQL Server 2005 than for previous versions of SQL Server. Listing 14-12 shows an example of using MinimumVersion from the SQL Server metadata resource System.Data.SqlClient.SqlMetaData.
Listing 14-12. Metadata entry for data type XML in data types collection
<DataTypes>
<TypeName>xml</TypeName>
<ProviderDbType>25</ProviderDbType>
<ColumnSize>2147483647</ColumnSize>
<DataType>System.String</DataType>
<IsAutoIncrementable>false</IsAutoIncrementable>
<IsCaseSensitive>false</IsCaseSensitive>
<IsFixedLength>false</IsFixedLength>
<IsFixedPrecisionScale>false</IsFixedPrecisionScale>
<IsLong>true</IsLong>
<IsNullable>true</IsNullable>
<IsSearchable>true</IsSearchable>
<IsSearchableWithLike>false</IsSearchableWithLike>
<MinimumVersion>09.00.000.0</MinimumVersion>
<IsLiteralSupported>false</IsLiteralSupported>
</DataTypes>
This defines information about the SQL Server data type XML. The MinimumVersion indicates that this data type is available only when using SQL Server 2005. If you ask SqlConnection.GetSchema for a list of data types that the database supports, only SQL Server 2005 databases (SQL Server 2005 is actually version 9) will report that they support the XML data type.
For collections usually exposed by the INFORMATION_SCHEMA (such as Tables, Views, and Stored Procedures), PopulationMechanism and PopulationString cause the wheels to spin. There are three PopulationMechanisms used in this implementation: DataTable, SQLCommand, and PrepareCollection. DataTable is used to populate the metacollections. Using DataTable means that the information used to populate the collection is in the XML resource file itself. In each case, the PopulationString is the name of the DataTable produced when the XML resource file is loaded into a .NET Framework DataSet. SQLCommand means that the provider will use a DbCommand instance to issue the command against the database. If you look at one of the Population-Strings of a collection produced by a SQLCommand, shown in Listing 14-13,
Listing 14-13. Entry for databases (catalogs) in SQL Server MetaDataCollection
<MetaDataCollections>
<CollectionName>Databases</CollectionName>
<NumberOfRestrictions>1</NumberOfRestrictions>
<NumberOfIdentifierParts>1</NumberOfIdentifierParts>
<PopulationMechanism>SQLCommand</PopulationMechanism>
<PopulationString>select name as database_name, dbid, crdate as
create_date from master..sysdatabases where name = {0}</PopulationString>
</MetaDataCollections>
it’s fairly easy to deduce that string substitution will be applied to the base query when restrictions are used in DbConnection.GetSchema. If no restrictions are specified, that predicate will effectively be stripped out of the query.
The provider writer can use a custom mechanism when the value of PopulationMechanism is PrepareCommand. There is a PrepareCommand method of DbMetaDataFactory that, if overridden by the provider writer, can be coded to use whatever custom semantics the provider chooses. This mechanism is used in SqlClient is to produce the DataTypes metacollection. The SqlMetaDataFactory subclass’s implementation of Prepare Command first reads the built-in data types supported by SQL Server from the DataTable, as with other metacollections, and then uses custom logic to add user-defined types to the collection if the database is SQL Server 2005. (See chapter 5 for information on UDTs.)
User Customization
In addition to the provider customization mechanism, there is a hook that allows programmers to customize schema information on a per-application basis! Before loading the embedded resource, DbMetaDataFactory will consult the application configuration file. Each Microsoft provider will look for an application configuration setting named after the provider itself (for example, system.data.sqlclient). In this setting element, you can add or remove name–value pairs. DbMetaDataFactory looks for a name "MetaDataXml". The value corresponding to the special name is the name of a file. This is a simple filename; the file must exist in the config subdirectory of the location where .NET Framework is installed. This is the directory where machine.config and the security configuration settings files live. This file must contain the entire set of schema configuration information, not just the changes.
You can use this mechanism, for providers that support it, for many reasons. You could change the schema queries in the OracleClient provider to use the USER catalog views rather than the ALL catalog views, for example. Because the USER views don’t contain information about internal database tables, the list of Tables, for example, will be much shorter and easier to work with. Another example might consist of coding out metadata XML files for all .NET Framework data providers that give you a consistent standard set of metadata—possibly one that corresponds exactly to the SQL-99 INFORMATION_SCHEMA views. This might be just right for your application.
As an example, suppose that we want to expose information about SQL Server Service Broker metadata collections in SQL Server 2005. These collections might include QUEUEs, SERVICEs, CONTRACTs, and MessageTypes. We would start with the embedded XML resource file and embellish it with information on our new collections. If the filename were SQLBroker-Aware.xml, we would install the file, and our application configuration file would look like this:
<?xml version="1.0" encoding="utf-8” ?>
<configuration>
<system.data.sqlclient>
<settings>
<add name="MetaDataXml" value="SQLBrokerAware.xml"></add>
</settings>
</system.data.sqlclient>
</configuration>
That’s all there is to it. Using that setup, we could write code in which Service Broker metadata is part of the built-in metadata available to the client. The code might look for all the QUEUEs, as shown in Listing 14-14.
Listing 14-14. Using customized metadata with GetSchema
using (SqlConnection conn = new SqlConnection(connstring))
{
conn.Open();
// this includes Service Broker metadata collections
Table t =
conn.GetSchema(DbMetaDataCollectionNames.MetaDataCollections);
// get all the queues in my database
Table queues = conn.GetSchema("Queues");
}
Although this is a very powerful feature, it does have the capability to be abused. Remember that you’ll need to distribute the metadata XML file with every application that uses it and persuade the System Administrator to install it in the config directory for you. Also remember that you’ll need to maintain it with each new version of the provider that ships. Because one of the reasons for generic metadata APIs is to have consistent metadata across databases and applications, this feature should not be used gratuitously. Note that you cannot provide a custom implementation of Prepare Command at this time.
As a final remark on customization, you might have guessed that customization and resources would work differently with the bridge providers for OLE DB and ODBC. When you use these providers, a separate XML resource is provided for each OLE DB provider or ODBC driver you want to support. Microsoft built-in support includes its providers and drivers for SQL Server, Oracle, and Jet databases. If you want to specify your own providers or drivers, the name attribute used in adding/removing settings subelements would not be MetaDataXml, but instead would be [providershortname]:MetaDataXml. If you want your file to be the default for the OleDb or Odbc data provider, you can even specify a name of defaultMetaDataXml.
We’d also like to mention two other metadata extensions that are not exposed through DbConnection.GetSchema. The DbCommandBuilder includes two properties, QuoteIdentifier and UnquoteIdentifier, that permit you to customize identifiers in commands that the CommandBuilder builds. As an example, in SQL Server you can use double quotes ('') or brackets ('[' and ']') to quote identifiers, depending on your session settings. Finally, the DbDataReader’s GetSchemaTable method is used to expose metadata about columns contained in a DbDataReader returned through the SQL SELECT statement. This metadata is similar in concept to, though not nearly as detailed as, the metadata exposed in the DataTypes metacollection.
Tracing Data Access
We’ve been missing a good generalized built-in trace facility for data access since ODBC Trace. OLE DB had many types of tracing; two that come to mind are the Visual Studio Analyzer–compatible instrumentation and ATLTRACE (a trace macro for ATL OLE DB templates). The issue in OLE DB and MDAC was not that there was no trace, but that there were too many separate kinds of tracing, each tied to a different evaluation mechanism. It was difficult, if not impossible, to trace down into various layers of the data access stack and get one trace output.
ADO.NET 2.0 and SQL Native Client (a new OLE DB/ODBC/network library feature) contain a flexible, rich, built-in data trace facility. Microsoft has instrumented all four of its .NET Framework data providers (SqlClient, OracleClient, OleDb bridge, and Odbc bridge); the ADO.NET DataSet and friends; SQL Native Client OLE DB and ODBC provider/driver; and, to top it off, the SQL Server 2005 network libraries.
Tracepoints are already programmed into the .NET Framework and SNAC libraries. Using an IL disassembler like Reflector, you may already have noticed them. The first step is configuring things to allow you to get basic output. The basic steps for using tracing are:
- Set up the data tracing DLL Registry entry, ETW providers, and WMI schemas.
- Configure and run the trace itself.
- Harvest the trace results as a comma-separated value file.
Don’t worry if some of the acronyms, like ETW (Event Tracing for Windows) and WMI (Windows Management Instrumentation), are unfamiliar to you for now; we’ll explain them later. Let’s go over the steps one by one and then go back to a discussion of how they work.
Setting Up Data Tracing
First, you need to set up the trace DLL Registry entry. This step consists of running a Registry script or manually editing the Registry to hook up data tracing to its Event Tracing for Windows (ETW) provider. Currently, editing the Registry is the only way to accomplish this; in the future, there may be a Control Panel application or a configuration file mechanism. We’ll have more to say about using this Registry key later; for now, let’s just enable tracing for every data-related process on the machine:
- Locate the Registry key HKLMSoftwareMicrosoftBidInterface.
- Add a subkey named Loader.
- Add a new string value (under the Loader key): Name=":Path"Value="[Path to AdoNetDiag.dll]".
On my machine, the “Path to AdoNetDiag.dll” is c:Windows Microsoft.NETFrameworkv2.0.50727. Also, note that the colon before Path in a Name key is significant. You can also customize this into a .reg file for future use.
Next, you must register data tracing’s schema. The AdoNetDiag.dll you have just registered is a component that contains multiple ETW providers. You now need to register the ETW providers and their WMI schemas for the events that AdoNetDiag.dll exposes. You do this with a special-format schema file called a Managed Object Format (MOF) file and a utility named mofcomp. ADO.NET 2.0 provides a MOF file in the .NET Framework directory. At this writing, there is no SQL Native Client MOF file as part of the SQL Server installation. We provide one as part of the ancillary materials on the book’s Web site. If you issue the command manually from the command line, it would look like this:
1>mofcomp adonetdiag.mof
1>mofcomp snac.mof
You can check that the providers are registered correctly by listing the ETW providers using the command
1> logman query providers
You should see the providers that you have registered, as well as other providers that come with the OS or other products. Note that each provider is identified by a GUID. Your provider list should look something like this:
Provider GUID
-------------------------------------------------------------------------
*System.Data.1 {914ABDE2-171E-C600-3348-C514171DE148}
ACPI Driver Trace Provider {dab01d4d-2d48-477d-b1c3-daad0ce6f06b}
Active Directory: Kerberos {bba3add2-c229-4cdb-ae2b-57eb6966b0c4}
IIS: SSL Filter {1fbecc45-c060-4e7c-8a0e-0dbd6116181b}
IIS: WWW Server {3a2a4e84-4c21-4981-ae10-3fda0d9b0f83}
IIS: Active Server Pages (ASP) {06b94d9a-b15e-456e-a4ef-37c984a2cb4b}
MSSQLSERVER Trace {2373A92B-1C1C-4E71-B494-5CA97F96AA19}
*MSDADIAG.ETW {8B98D3F2-3CC6-0B9C-6651-9649CCE5C752}
Local Security Authority (LSA) {cc85922f-db41-11d2-9244-006008269001}
*System.Data.SNI.1 {C9996FA5-C06F-F20C-8A20-69B3BA392315}
*SQLNCLI.1 {BA798F36-2325-EC5B-ECF8-76958A2AF9B5}
Windows Kernel Trace {9e814aad-3204-11d2-9a82-006008a86939}
*System.Data.OracleClient.1 {DCD90923-4953-20C2-8708-01976FB15287}
*ADONETDIAG.ETW {8B98D3F2-3CC6-0B9C-6651-9649CCE5C752}
ASP.NET Events {AFF081FE-0247-4275-9C4E-021F3DC1DA35}
NTLM Security Protocol {C92CF544-91B3-4dc0-8E11-C580339A0BF8}
IIS: WWW Isapi Extension {a1c2040e-8840-4c31-ba11-9871031a19ea}
HTTP Service Trace {dd5ef90a-6398-47a4-ad34-4dcecdef795f}
Spooler Trace Control {94a984ef-f525-4bf1-be3c-ef374056a592}
We’ve changed the output a bit, adding an asterisk next to the providers that we care about. You can also check out the WMI schemas that were registered by using the WMI CIM Studio tool. You can find this tool on the MSDN Online Web site. The WMI schemas for data tracing are fairly simple; we’ll talk about them later in the chapter.
Running the Trace
Running the trace consists of defining named traces and issuing ETW commands to use them using a utility named logman (log manager). The logman command looks like this:
@Logman start MyTrace -pf provfile -ct perf -o Out.etl -ets
This command file defines a single named trace instance (MyTrace) specifying all the providers that we just registered. The file provfile would contain a list of the providers that you want to trace in a special format. The contents of this file are
{7ACDCAC8-8947-F88A-E51A-24018F5129EF} 0x00000000 0 ADONETDIAG.ETW
{914ABDE2-171E-C600-3348-C514171DE148} 0x00000000 0 System.Data.1
{C9996FA5-C06F-F20C-8A20-69B3BA392315} 0x00000000 0 System.Data.SNI.1
{DCD90923-4953-20C2-8708-01976FB15287} 0x00000000 0
System.Data.OracleClient.1
{BA798F36-2325-EC5B-ECF8-76958A2AF9B5} 0x00000000 0 SQLNCLI.1
The lines include a GUID for each provider, provider options, and the provider’s name (watch for line wrap). We’ll say more about the provider options later.
Invoking logman in this manner writes all the events in a concise binary format to an event trace log file. These files have the extension .etl by convention. When you’ve turned it on, run the program that you want to trace. Turn off the trace by running the following command from the command line:
@Logman stop MyTrace -ets
You should see a file, about 150KB, named out.etl in the directory where you issued the command from. Because we’ve turned the trace providers on at each level of detail (ADO.NET providers, network calls, and responses from SQL Server, if it’s running on the same machine), there will be a large amount of output. We’ll look at ways to filter the output later. Note that bringing up Visual Studio 2005 to run the test program may generate extra trace events when, for example, Server Explorer runs data access code.
Harvest the Results As a CSV File
The out.etl file is not in a human-readable format unless you’re one of those rare humans who like to read binary. ETW utilities include a basic formatter named tracerpt.exe to convert it to a comma-separated-value (CSV) file. To get the CSV file, run report.cmd, which issues the following command:
@TraceRPT /y Out.etl
This utility produces two files: summary.txt, a summary of the trace events captured in the session, and dumpfile.csv. These are the default filenames output by tracerpt; you can change them through commandline options. dumpfile.csv is the file containing the information you want. You can browse this file with Excel for now; later, you can do some further postprocessing, such as loading the data into SQL Server and querying it with SQL. Now you have your first trace. Let’s have a look at the output.
Reading the Trace Output
The data tracing providers expose three major types of information: tracepoint information and provider identity, event type, and thread and timing information. Specifically, the columns of information consist of:
• Event Name—The name of the data tracing event provider
• Event Type—TextW or TextA
• TID—Thread ID
• Clock-Time—Timestamp of the event
• Kernel (ms)—Number of milliseconds in kernel mode (CPU time)
• User (ms)—Number of milliseconds in user mode (CPU time)
• User Data—Detailed information about the tracepoint
Although WMI providers are permitted to expose complex schema, the data tracing providers expose only two simple event types: TextW and TextA. Many of the data tracing events are bracketing “begin” and “end” pairs, which make it easy to follow the nested API calls. TextW and TextA are used to achieve that bracketing. In the following trace, for example, the User Data field looks somewhat like this:
"enter_01 <comm.DbDataAdapter.Fill|API> 1# dataSet"
"enter_02 <comm.DbDataAdapter.Fill|API> 1# dataSet startRecord
maxRecords srcTable command behavior=16{ds.CommandBehavior}"
"<sc.SqlCommand.get_Connection|API> 1#"
"<sc.SqlCommand.get_Connection|API> 1#"
"enter_03 <sc.SqlConnection.Open|API> 1#"
"enter_04 <prov.DbConnectionBase.Open|API> 1#"
"enter_05 <SNIInitialize|API|SNI> pmo: 00000000{void}"
... many events deleted
"leave_05"
"<sc.TdsParser.CreateSession|ADV> 1# created session 2"
"<prov.DbConnectionFactory.CreatePooledConnection|RES|CPOOL> 1# Pooled
database connection created."
"leave_04"
"leave_03"
It’s fairly straightforward to see that the user program called Data Adapter.Fill(DataSet) itself called in a different overload of Data Adapter.Fill, which called into SqlConnection.Open, and so on. Each enter_nn event has a corresponding leave_nn event. In this example, you’re even tracing the call into the underlying SNI (SQL Server networking interface) low-level protocol events. But what is that funny bracket format of the user data put out by the “mainstream” tracer, System.Data.1?
User Data and ADO.NET Tracing
As the name implies, the content and format of the user data field are entirely at the user’s (in this case, trace provider’s) discretion. Calls to System. Data.dll and System.OracleClient.dll go by a special format that can be easily decoded. Take the entry from the previous trace record sequence:
"enter_04 <prov.DbConnectionBase.Open|API> 1#"
This can be decoded to:
<namespace abbreviation.classname.methodname|type of call> parms
So the example above means that there is an API call to the System. Data.ProviderBase,DbConnectionBase’s Open method with a single parameter. The reason for using abbreviated namespaces is to keep the output smaller. The pound sign (#) after the parameter number indicates that this parameter is an object reference, with simple values or value types in the .NET Framework; the actual parameter value is shown.
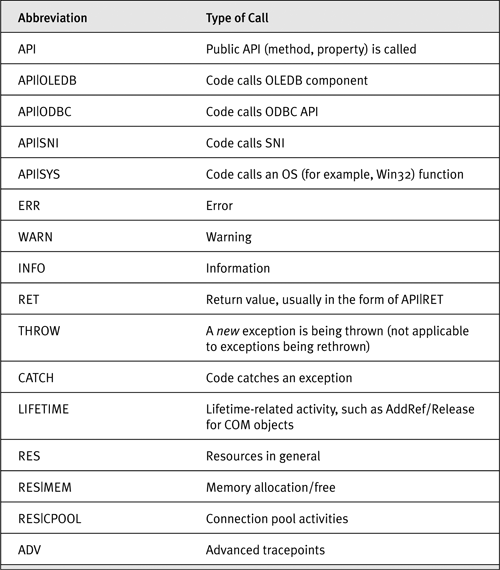
Table 14-7 and Table 14-8 will help you decode the user data.
Table 14-7. Namespace Abbreviations Used in .NET Framework Tracepoints
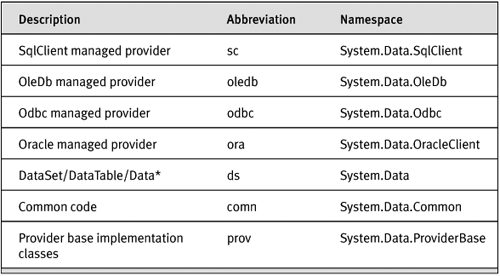
Table 14-8. Call Types Used in .NET Framework Tracepoints
Configuring Which Applications Are Traced
Earlier, we mentioned configuring the :Path string value of the Loader Registry key. Manual configuration is needed only because data access tracing is in its infancy. Specifically, vendors that ship products built around data tracing should not depend on this key to be manually configurable in future releases; it will most likely be protected by an ACL (security access control list).
With that warning out of the way, configuring only the :Path value makes tracing available on all applications running on a given machine. If a programmer is running a SQL Server 2005 instance and a data access client on her machine, for example, turning on SNI tracing will trace SNI calls from both sides. That can generate some large output, although in certain use cases, this can be exactly the type of output you want. You can configure applications to be traced if there is no :Path value or to be excluded from tracing if there is a :Path value.
If there is no :Path value, only applications that are specifically configured will be traced. You can configure applications to be traceable by specifying a REG_SZ or REG_MULTISZ entry with the program name as the value name and the full path to AdoNetDiag.dll as the value. You can also configure an entire directory to be traceable by using the pathname and the * wildcard.
If there is a :Path value, you can restrict applications or applications in a specific directory from being traced by adding a REG_SZ or REG_MULTISZ entry and the value of : (single colon). Wildcards in the directory name are allowed. The name field containing the directory name (C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLBinn*) along with a : value would keep all programs in SQL Server’s Binn directory (such as SQL Server, SQL Profiler, and so on) from showing up in a trace. If you’re running SQL Server on the same machine as your application, this is what you want most often. Remember that configuring the Registry entries just names the data tracing provider DLL (at this point, there is only AdoNetDiag.dll to choose); it does not turn on the trace.
You can also configure which provider information is traced to which files and control what is traced to a certain extent. You can trace the output from all five providers to a single file or separate them into one file per provider. You do this by making up named traces using the logman utility. Here’s an example that creates five traces:
logman create trace test1 -p System.Data.1
logman create trace test2 -p ADONETDIAG.ETW
logman create trace test3 -p System.Data.OracleClient.1
logman create trace test4 -p SQLNCLI.1
logman create trace test5 -p System.Data.SNI.1
In addition to using logman from the command line, you can use the graphic Microsoft Management Console snap-in, the “Snap-in for Performance Logs and Alerts,” to configure, run, and stop the trace. Describing how to use the MMC snap-in is beyond the scope of this book.
You have some control over what is traced by manipulating the bits in logman’s control.guid file. You need not even have a control.guid file if you use a single provider per trace and take defaults, as the previous examples show. To refresh your memory, here’s a single line from control.guid:
{914ABDE2-171E-C600-3348-C514171DE148} 0x00000000 0 System.Data.1
This information in this line consists of the following:
Provider Guid - which ETW provider
Control Bits - 0x00000000 in this case
Control Value - 0 in this case
Provider Name - Required by ETW, but ignored by the provider internally
By setting bits in the “Control Bits” and “Control Value” fields, you have a macro-level mechanism for prefiltering the events. The valid values are
0x0002 Regular tracepoints
0x0004 Execution flow (function enter/leave)
0x0080 Advanced Output
There is also a bit that has special meaning to System.Data.1 only:
0x1000 Connection Pooling specific trace
The bits can be or’d together, of course. If 0x00000000 is specified, 0x00000006 is assumed. There are two possible nondefault values that can be set in the control value:
128 - Convert Unicode text to ASCII text (reduces etl file size)
64 - Disable tracing in this component
Note that setting these control bits does not provide a granular mechanism for configuring individual components; it is meant to make it easy to filter types of events without postprocessing the CSV file yourself.
Using Tracing to Debug a Parameter Binding Problem
Now that we’ve gone through a quick overview of tracing, we’d like to present a simple use case. We’d often use ODBC trace to do problem determination when an application would “eat” a rich error message and produce a polite but fairly information-free message. Such application code would look like Listing 14-15.
Listing 14-15. Sample program that replaces the real error message with a polite message
string s = GetConnectionStringFromConfigFile();
using (SqlConnection conn = new SqlConnection(s);
using (SqlCommand cmd = new SqlCommand(
"select * from authors where au_id = @auid", conn))
{
// the error is hardcoded here but could have come from suboptimal
// editing in a graphic user interface
cmd.Parameters.Add("@auid", SqlDbType.Int);
cmd.Parameters[0].Value = 123456789;
SqlDataReader rdr = null;
try {
// some code that could fail goes here
conn.Open();
rdr = cmd.ExecuteReader();
while (rdr.Read())
Console.WriteLine(rdr[0]);
rdr.Close();
}
catch (Exception e) {
MessageBox.Show("polite error message");
}
}
In this case, the error was caused by a parameter type mismatch, and the person diagnosing the error might not have access to the source code of the program. Turning on the trace, we’ll see output like Listing 14-16.
Listing 14-16. Trace output used to diagnose the real error
"enter_01 <sc.SqlCommand.ExecuteReader|API> 1#"
"<sc.SqlCommand.get_Connection|API> 1#"
"<sc.SqlCommand.get_Connection|API> 1#"
"<sc.TdsParser.CreateSession|ADV> 1# created session 3"
"<sc.TdsParserSessionPool.CreateSession|ADV> 1# adding session 3 to
pool"
"<sc.TdsParserSessionPool.GetSession|ADV> 1# using session 3"
"<sc.TdsParser.GetSession|ADV> 1# getting session 3 from pool"
"<sc.SqlCommand.ExecuteReader|INFO> 1# Command executed as RPC."
"<sc.SqlCommand.get_Connection|API> 1#"
"leave_01"
"enter_01 <sc.SqlDataReader.Read|API> 1#"
"<sc.SqlError.SqlError|ERR> infoNumber=245 errorState=1
errorClass=16 errorMessage='Syntax error converting the varchar value
'123-45-6789' to a column of data type int.' procedure='' lineNumber=1"
"leave_01"
Although the value in the trace doesn’t match the value in our program (it comes from row 1 of the authors tables), this shows us directly that there is a parameter value mismatch. The sample and the trace file are provided in the code on the book’s Web site. Note that the trace file is much more compact in this case because we’re tracing only with the System.Data.1 provider, so no network traffic trace is provided.
We’ve barely scratched the surface of uses for this complex and powerful feature. Some other possible uses are
• Investigating connection pooling activity
• Debugging network connection problems
• Integrating tracing into unit testing
• Performing comparative analysis of DataSet and DataReader calls to determine where DataSet is spending its time
• Feeding the information into a monitoring facility like MOM (Microsoft Operations Manager)
• Using data tracing in conjunction with the ASP.NET and other ETW providers
• Doing a combined data trace and SQL Server trace using SQL Server’s ETW provider
Inside Data Tracing
You now have a cookbook way to set up, run, and interpret traces in the Microsoft data access stacks. But aside from issuing command-line scripts, what is going on?
Data tracing is based on a provider model itself. ADO.NET data providers and other data access code use standard APIs (which themselves use standard trace hooks) to feed trace information into the model, and in the future, multiple data trace providers may be built. Currently, only AdoNetDiag is available, but you could imagine data tracing consumers that would provide a prefiltering of events at a granular level or that use a different trace output system, such as Output-DebugString or output into SQL Server directly for ease in searching/ querying. You could even hook data tracing up to the .NET Framework’s System.Diagnostics.Trace.
Anyone can instrument his own code, but Microsoft has not yet released a data tracing provider specification to the public. Instead, ADO.NET 2.0 and SQL Native Client come with a prebuilt tracing provider using the ETW system. ETW is a high-performance tracing system that was introduced to implement kernel-level tracing for device driver writers. Following is a high-level explanation of ETW using data tracing as an example.
What Is ETW?
Event Tracing for Windows is meant to provide low-overhead tracing as compared with Windows Performance Monitor. ETW usually takes up no more than 5 percent of the CPU and can log up to 20,000 events per second. It’s fast enough to enable tracing in real time. ETW uses a provider-based model; in this case, a provider is a system or application component that sends events to the event system. Some examples of event providers are Active Directory, IIS, and ASP.NET. The ADO.NET and SQL Native Client data traces register five ETW event providers:
System.Data.1 - ADO.NET providers and classes in System.Data.dll
System.Data.OracleClient - OracleClient provider in
System.OracleClient.dll
System.Data.SNI.1 - SNI from System.Data
SQLNCLI.1 - SQL Native Client providers and SNI from SQL Native Client
ADONETDIAG.ETW - provides events from the trace providers themselves
ETW provider logs yield a timestamp with each event. When you start the trace, you can specify a high-resolution timestamp or a low-resolution timestamp. In our traceon.cmd file, we’ve chosen a high-resolution timestamp using the -ct perf option. In the single-file scripts above, we’ve chosen the default (low-resolution) timestamp. ETW chooses high performance over ease of use. Formatting ETW traces with tracerpt.exe produces a cursory decoding. The format of the ETL file is documented, and the schemas for individual trace providers are recorded in WMI, so programmers are welcome to build their own specialized formatters. A nice feature of using ETW is that the trace that you produce can be used in conjunction with an ASP.NET trace or, for that matter, with a low-level OS kernel trace. All the events can be logged on a per-provider basis to a single file for correlation or to separate files. Information on ETW is available in the “Performance Best Practices at a Glance” whitepaper on the MSDN Web site.2
ETW output can be consumed by a variety of tools, and if none of the tools suits your specific needs, you can build your own. One example of such a consumer tool is logparser, which can consume not only output from ETW, but also from other outputs, such as IIS log files and Windows Event Logs. Then logparser lets you query your events using a SQL-like syntax. It is available as part of the IIS Resource Kit on MSDN.3
Asynchronous Support
The OLE DB specification contains an interface that providers can implement to enable asynchronously executing a command. If these operations took a long time, your program could do other work in the meantime, such as responding to events in the graphical user interface or showing a progress bar. Implementing these interfaces was optional, and the SQLOLEDB provider did not implement them in the protocol. With the advent of the new client network libraries, asynchronous operation can be achieved not only with SQL Server 2005, but also with SQL Server 7 and 2000. This support has been added to OLE DB, ADO, and ADO.NET; for exposition, we’ll look at the ADO.NET implementation.
SqlClient uses the standard .NET Framework paradigm for asynchronous operations. In addition to the ordinary method for synchronous invocation—for example, SqlConnection.ExecuteReader—there is a pair of related methods, BeginExecuteReader and EndExecuteRead, for asynchronous invocation. BeginExecuteReader starts the operation and returns immediately to the caller. When the operation completes, you use EndExecute Reader to harvest the return code (or an error) and the results of the operation. As a reminder, every time you call any of the "Begin Execute" methods, the corresponding "EndExecute" method must be called; otherwise, memory may be leaked.
Asynchronous methods around SqlCommand.ExecuteReader, Execute XmlReader, and ExecuteNonQuery (but not ExecuteScalar) are provided. Listing 14-17 shows the equivalent code to execute a SQL UPDATE statement asynchronously and retrieve the number of rows affected by the UPDATE. To use the asynchronous methods, you must specify "Async=true" in the connection string. You should not specify this connection-string parameter if you do not use asynchronous methods, because the protocol change that implements asynchronous methods adds a little extra overhead when you use synchronous methods.
Listing 14-17. Using asynchronous command execution
string connect_string = GetConnectStringFromConfigFile();
connect_string += ";Async=true";
SqlConnection conn = new SqlConnection(connect_string);
SqlCommand cmd = new SqlCommand
("UPDATE authors SET state='OR' WHERE state='CA'", conn);
try
{
conn.Open();
// Asynch command execution
IAsyncResult ar = cmd.BeginExecuteNonQuery();
while (!ar.IsCompleted)
{
Console.Write(".");
Thread.Sleep(250);
}
// retrieve the results (or error) here
int i = cmd.EndExecuteNonQuery(ar);
Console.WriteLine("done, {0} rows affected", i);
}
catch (Exception e) {
Console.WriteLine(e.Message);
Console.WriteLine(e.StackTrace);
}
finally {
cmd.Dispose();
conn.Dispose();
}
Executing an asynchronous operation using Begin and End uses nonblocking overlapped I/O against the network. A thread from the .NET Framework AppDomain’s thread pool is used only when the I/O completion notification is dispatched to the process and only if the user specified a callback. I/O completion handling happens in a private thread in the provider; the thread pool is used only if the user provided a callback.
A more useful paradigm than just busy-waiting in the code (which just adds complexity and thread switching to the program, slowing overall execution) is registering an event handler to be called when the operation completes. Listing 14-18 shows a simple example that illustrates using an event handler with an asynchronous command execution.
Listing 14-18. Asynchronous execution with an event handler
public void UseEventHandler()
{
string connect_string = GetConnectStringFromConfigFile();
connect_string += ";Async=true";
SqlConnection conn = new SqlConnection(connect_string);
try
{
SqlCommand cmd = new SqlCommand
("SELECT * FROM authors", conn);
// Synchronous Open
conn.Open();
// Asynch command execution
cmd.BeginExecuteReader(
new AsyncCallback(GetResult,
null,
CommandBehavior.CloseConnection);
}
catch (Exception e) {
Console.WriteLine(e.Message);
Console.WriteLine(e.StackTrace);
}
finally {
cmd.Dispose();
conn.Dispose();
}
}
public void GetResult(IAsyncResult result)
{
// harvest results (or error) here
SqlDataReader rdr = result.EndExecuteReader(result);
// use results to populate page
}
Bear in mind that most of the time, you use asynchronous execution to perform two or more operations at the same time. This is useful in two major scenarios. In one scenario, you might be doing multiple data gathering operations in parallel over the same connection to fill up multiple sets of controls in a graphical user interface. The other scenario consists of doing multiple long-running operations against two databases, which may be in faraway locations. In each case, you want to synchronize at a point when all operations are complete and then continue. Multiple WaitHandles (a .NET Framework synchronization primitive) can come in handy here. You start a few operations and call WaitHandle.WaitAll to wait until they all complete. Listing 14-19 shows an example that uses MARS to wait for two different resultsets on the same connection, though the multiple database code would look similar.
Listing 14-19. Using multiple asynchronous commands and wait handles
public void UseWaitHandles()
{
string connect_string1 = GetConnectStringFromConfigFile("server1");
connect_string1 += ";Async=true";
string connect_string2 = GetConnectStringFromConfigFile("server2");
connect_string2 += ";Async=true";
SqlConnection conn1 = new SqlConnection(connect_string1);
SqlConnection conn2 = new SqlConnection(connect_string2);
// execute these simultaneously
SqlCommand cmd1 = new SqlCommand("SELECT * FROM authors", conn1);
SqlCommand cmd2 = new SqlCommand("SELECT * FROM titles", conn2);
WaitHandle[2] handles = new WaitHandle[2];
try
{
conn.Open();
handles[0] = (cmd1.BeginExecuteReader()).AsyncWaitHandle;
handles[1] = (cmd2.BeginExecuteReader()).AsyncWaitHandle;
// wait for both commands to complete
WaitHandle.WaitAll(handles);
SqlDataReader rdr1 = cmd1.EndExecuteReader();
SqlDataReader rdr2 = cmd2.EndExecuteReader();
// process both readers
// ...
rdr1.Close(); rdr2.Close();
}
catch (Exception e) {
Console.WriteLine(e.Message);
Console.WriteLine(e.StackTrace);
}
finally {
cmd1.Dispose(); cmd2.Dispose();
conn1.Dispose(); conn2.Dispose();
}
}
You can also process multiple results when any one of the commands completes by using WaitAny instead of WaitAll. You might use this to make a graphical user interface more responsive.
Using asynchronous execution with multiple commands on the same connection, using MARS to multiplex the commands, may sound like a good idea. It isn’t as nice as it sounds. The reason for this is that although you can return multiple rowsets using MARS and multiple asynchronous commands, only one command per connection is executing at the same time. So you don’t get the performance advantage that you might expect, and you add unnecessary complexity to your application.
Although executing each method call asynchronously may sound like a good idea at first mention, don’t use the asynchronous calls unless:
• You have an operation that you know will take a long time.
• You have something useful to do with that time.
In the first two examples, we were simply spinning and wasting processor time. As noted earlier, excessive thread switching will slow your application. In addition, be aware that when using the AppDomain’s thread pool, you are almost guaranteed to get the completion (the end request) on a different thread from the one on which you issued the original call. Some .NET Framework classes, such as GUI controls that wrap Window Handles, are usable only on the thread that the Window Handle is stuck to. Abetter way to accomplish this when you’re using Windows Forms is to use the BackgroundWorker class with a synchronous command. Information on the BackgroundWorker can be found in the .NET Framework 2.0 documentation.
One last scenario for asynchronous command execution is high-end ASP.NET applications, where it’s easy to run out of threads in the ASP.NET thread pool; a very common cause for that is that all threads are blocked for I/O on database execution requests. Away of freeing those threads is to use asynchronous execution so that you can unwind the thread when the database command is sent, allowing ASP.NET to reuse the thread. This requires either the creation of an asynchronous request handler (.ashx page) or the use of the new asynchronous pages in ASP.NET 2.0.
Finally, remember that when you read a resultset through a Data Reader, SQL Server queues (and locks) a buffer’s worth of data at a time on the server, waiting for you to fetch it. Waiting around before reading the results can cause excessive memory utilization and locking on the server, and can affect the throughput of your SQL Server instance. Use asynchronous operations wisely and correctly.
Bulk Import in SqlClient
There are several ways to import an array of rows into SQL Server. In SQL Server 2005, there is a .NET Framework API to SQL Server Integration Services (SSIS), the utility that replaced SQL Import/Export in SQL Server 7 and Data Transformation Services in SQL Server 2000; it provides a job scheduler and programmatic control over transformations, in addition to simple importing and exporting of data. The fastest way to import data, as long as the data to import is in a file, is to use the T-SQL BULK INSERT statement or the new BULK rowset provider, which we discuss in Chapter 7. This statement can be invoked from a .NET Framework program using the SqlCommand class and the BULK INSERT statement as command text.
Each data access API has exposed the bulk insert functionality as an extension to the base API. You can use the SQL Server BCP utility programmatically through ODBC or OLE DB. BCP is the command-line utility that has been around since the early days of SQL. It is a favorite of database administrators and programmers alike, consuming and producing text files in a variety of formats, including comma-separated values and fixed-length text. OLE DB exposed similar programmatic functionality by means of a custom interface and property set on SQLOLEDB’s Session cotype implementation. The custom interface, IRowsetFastLoad, has functionality reminiscent of SQL Server’s built-in BULK INSERT.
In ADO.NET 2.0, SqlClient follows ODBC, OLE DB, and DBLib, and exposes a programmatic API with IRowsetFastLoad-like functionality called SqlBulkCopy. The class can use rows from a DataTable in memory or be hooked up to a DataReader over the set of data to be inserted into the database. In the simplest case, you need only instantiate a SqlBulkCopy instance, set properties on it, and point the DataReader at it, using the WriteToServer method. Listing 14-20 shows a simple example that copies the jobs table in the SQL Server database to a nearly identically structured table named newjobs.
Listing 14-20. Using SqlBulkCopy with a DataReader as input
string connect_string = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(connect_string);
SqlCommand createcmd = new SqlCommand (
@"CREATE TABLE newjobs(
job_id SMALLINT PRIMARY KEY,
job_desc VARCHAR(30),
min_lvl TINYINT,
max_lvl TINYINT)",
conn);
SqlCommand cmd = new SqlCommand("SELECT * FROM jobs", conn);
conn.Open();
createcmd.ExecuteNonQuery();
SqlDataReader rdr = cmd.ExecuteReader();
// Copy the Data to SqlServer
string connect_string = GetConnectStringFromConfigFile();
SqlBulkCopy bcp = new SqlBulkCopy(connect_string);
bcp.DestinationTableName = "newjobs";
bcp.WriteToServer(rdr);
Importing rows is rarely that simple, however. You usually need to map fields in the source data to equivalent fields in the target table, perhaps doing some data type coercion along the way. SqlBulkCopyColumnMapping and its associated collection class, SqlBulkCopyColumnMappingCollection, are the classes you use to map source to target, as shown in Listing 14-21.
Listing 14-21. Using SqlBulkCopy with ColumnMappings
// Retrieve data from the source server.
string src_connect_string = GetConnectStringFromConfigFile("src");
SqlConnection src = new SqlConnection(src_connect_string);
src.Open();
SqlCommand cmd = new SqlCommand("SELECT * FROM orders", src);
IDataReader srcrdr = cmd.ExecuteReader();
// Connect to target server.
string dest_connect_string = GetConnectStringFromConfigFile("dest");
SqlConnection dest = new SqlConnection(dest_connect_string);
dest.Open();
// open a bulk copy using the destination connection
SqlBulkCopy bcp = new SqlBulkCopy(dest);
{
bcp.DestinationTableName = "order_history";
// map the columns
bcp.ColumnMappings.Add("orderid", "order_hist_id");
bcp.ColumnMappings.Add("description", "order_hist_desc");
bcp.ColumnMappings.Add("date", "order_hist_date");
bcp.WriteToServer(srcrdr);
}
bcp.Close();
dest.Dispose();
srcrdr.Close();
cmd.Dispose(); src.Dispose();
In addition to these simple examples that use IDataReader, SqlBulk-Copy can use a System.Data.DataTable or an array of DataRows as input. SqlBulkCopy exposes properties that will look familiar to anyone who has used the BCP utility. SqlBulkCopy actually uses direct TDS calls to write to the destination. This shows up in SQL Profiler as a command called "INSERT BULK" regardless of the version of SQL Server used. This is because Sql-BulkCopy is using the same TDS protocol commands that BCP uses. Nevertheless, it may be useful to compare its options with the options of SQL Server’s BULK INSERT command. A list of the properties and their equivalents in BULK INSERT is shown in Table 14-9. As an example of its usefulness, one high-performance way of importing a large number of rows is to implement a custom IDataReader and have SqlBulkCopy pull rows and push them into the server.
Table 14-9. SqlBulkCopy and BCP Equivalents
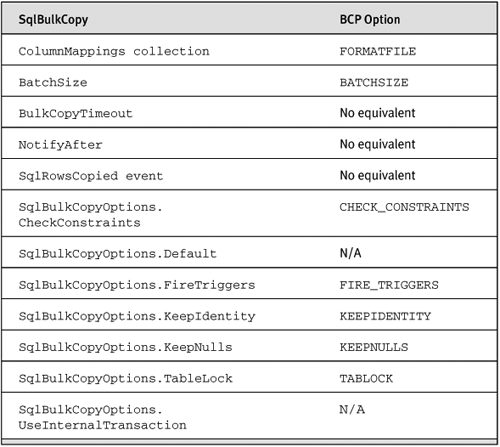
Client Statistics
The SQL Server ODBC driver enabled collection and reading of statistics on a per-connection basis via API calls. This has been added to the .NET Framework 2.0 version of SqlClient. This functionality exists mostly to enable client-side statistics display in SQL Server Management Studio, which is an ADO.NET application that, among other things, replaces Query Analyzer, an ODBC application. You can also use it in your own program to provide execution-time diagnostics.
Because collection of statistics adds overhead, statistics must be enabled on a per-connection basis. You enable statistics on a SqlConnection by setting its StatisticsEnabled property. In addition, the Sql-Connection exposes methods to retrieve and reset statistics. Listing 14-22 is a simple example of statistics gathering, followed by the output statistics that are gathered (shown in Listing 14-23). Using the client statistics API should make profiling client-side data access much simpler.
Listing 14-22. Statistics output from the previous program
static void Main(string[] args)
{
string connect_string = GetConnectStringFromConfigFile();
SqlConnection conn = new SqlConnection(connect_string);
conn.Open();
// Enable
conn.StatisticsEnabled = true;
// do some operations
//
SqlCommand cmd = new SqlCommand("select * from authors", conn);
SqlDataReader rdr = cmd.ExecuteReader();
Hashtable stats = (Hashtable)conn.RetrieveStatistics();
// process stats
IDictionaryEnumerator e = stats.GetEnumerator();
while (e.MoveNext())
Console.WriteLine("{0} : {1}", e.Key, e.Value);
conn.ResetStatistics();
}
Listing 14-23. Statistics output from the previous program
BytesReceived : 2207
SumResultSets : 0
ExecutionTime : 138
Transactions : 0
BuffersReceived : 1
CursorFetchTime : 0
IduRows : 0
CursorOpens : 0
PreparedExecs : 0
BytesSent : 72
SelectCount : 0
ServerRoundtrips : 1
CursorUsed : 0
CursorFetchCount : 0
ConnectionTime : 149
Prepares : 0
SelectRows : 0
UnpreparedExecs : 1
NetworkServerTime : 79
BuffersSent : 1
IduCount : 0
.NET Framework DataSet and SqlDataAdapter Enhancements
The easiest way to get a set of data from SQL Server back to the client that supports client-side updates and to flush updates back to the database is to use the ADO.NET DataSet. The SqlDataAdapter class consists of four SqlCommand instances: one each to SELECT, INSERT, UPDATE, and DELETE rows from SQL Server. SqlDataAdapter.Fill uses the SqlData Adapter’s Select Command to move rows from SQL Server to the DataSet. The data can be changed offline. The DataSet. SqlData Adapter. Update method uses the InsertCommand, UpdateCommand, and Delete Command SqlCommand instances to push updated data back to the database.
Insert/Update/ DeleteCommand can have a CommandText property that refers to textual parameterized update commands or stored procedures. Figure 14-1 shows a diagram of the SqlDataAdapter class. Listing 14-24 shows a short sample of code updating through a DataAdapter and a DataSet. For more information on the DataAdapter, see Chapter 5 of Essential ADO.NET, by Bob Beauchemin (Addison-Wesley, 2002).
Figure 14-1. Layout of the SqlDataAdapter
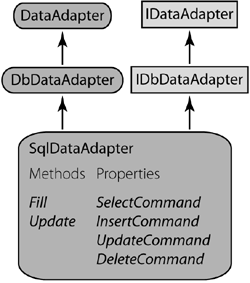
Listing 14-24. Updating through a SqlDataAdapter and DataSet
// Instantiate a SqlDataAdapter
string connect_string = GetConnectStringFromConfigFile();
SqlDataAdapter da = new SqlDataAdapter(
"select * from authors", connect_string);
// command builder for default update commands
SqlCommandBuilder bld = new SqlCommandBuilder(da);
DataSet ds = new DataSet();
da.Fill(ds, "authors");
// update the fifth row, third column
ds.Tables[0].Rows[4][2] = "Bob";
// use the default update commands
da.Update(ds, "authors");
This is an example of a generalized update pattern involving Sql-DataAdapter, DataSet, and SqlCommandBuilder. Note that in .NET Framework 2.0, SqlCommandBuilder does not support generating commands that involve UDT or XML data type columns. UDT data type columns are not supported by Visual Studio 2005’s strongly typed DataSet generation, either.
The DataSet is a disconnected cache. It consists of DataTables that contain DataRows and DataColumns, with semantics that mimic a relational database. DataTables, DataRows, and DataColumns are built over the .NET Framework ArrayList type; ArrayList is a .NET Framework collection class that implements a dynamic array. Rows can be selected in a DataTable using a SQL-like syntax known as data expression language. The DataSet can be marshaled as XML for use in Web Service scenarios. In ADO.NET 2.0, the DataSet can also be marshaled in a more compact binary format.
In ADO.NET 1.0 and 1.1, DataColumns in the DataSet were limited to a discreet set of .NET Framework types corresponding to the primitive types in a relational database. ADO.NET 2.0 extended this support to include the SqlTypes data types, including those added for SQL Server 2005. Figure 14-2 shows a list of the data types supported in version 2.0 of the DataSet.
Figure 14-2. Supported types in the ADO.NET DataSet
Moving data from a database to the DataSet generally meant mapping a database data type to the closest-fit .NET Framework data type, mostly in the case of mapping SQL Server’s DECIMAL type to .NET Framework’s System.Decimal. Although SQLServer’s DECIMAL type can contain up to 38 digits of precision, .NET Framework’s System.Decimal can hold only 28. In addition, supporting any other type (such as a SQL Server 2005 UDT) inside a DataSet did not throw an error and mostly worked but had some shortcomings:
• When the DataSet was serialized to XML, and the DataColumn’s type was not in the supported list, serialization was accomplished by calling ToString() on the type. Most types’ ToString() method did not render the object as XML.
• There was no obvious corollary to ToString() to deserialize the XML on the other side. The Parse method is not required, so the DataSet couldn’t rely on its being implemented by every class.
• Data expression language did not support column types other than the primitive, supported types.
These behaviors are described in detail in Chapters 6 and 7 of Essential ADO.NET.
In the SQL Server 2005 version of ADO.NET, this would present major problems for users of the DataSet. The data types that would cause problems would be UDTs and the XML data type.
The user-defined types would tend to be the most problematic, because a single DataColumn could contain multiple attributes (properties). Some new functionality in the DataSet takes care of this problem. The problem with the new non-UDT data types is resolved by support of new types in System.Data.SqlTypes and support of the SqlTypes family of classes in the DataSet. In addition, all the classes and structures that represent SQL Server data types in System.Data.SqlTypes are serializable. This means that they can be used in .NET Framework remoting scenarios or other places where System.Runtime.Serialization is used.
As mentioned earlier in this chapter, types other than the discrete set of types supported by the DataSet could always be pushed into a DataSet. There were a few problems with usability, however; most have been solved in ADO.NET 2.0. User-defined types are automatically serialized separately using System.Xml.Serialization rather than calling ToString. That obviates the necessity of implementing an XML-emitting ToString() method and a constructor that takes a single String as an argument. In addition, the interface System.Xml.Serialization.IXmlSerializable has been surfaced (in .NET Framework 1.1, it was documented as “internal use only”) as the way to implement custom serialization of an arbitrary class. System.Data.SqlTypes.SqlDateTime is one example of a class that implements IXmlSerializable. When the DataSet serializes itself into XML, if the classes contained in the underlying column implement IXmlSerializable, this implementation will be called.
One final piece of client-side disconnected model support needs to be mentioned. Although the DataSet supported (somewhat) SqlTypes as column values—and this would be helpful for the SQL DECIMAL value, for example—very few programmers used SqlTypes inside even a local DataSet, because there was no way to tell the SqlDataAdapter to use SqlTypes rather than .NET Framework basic types when Fill is called to fill the DataSet. In the new version of SqlDataAdapter, you can use the ReturnProviderSpecificTypes property to accomplish this. .NET Framework types inside the DataSet are still the default. In addition, a simplified but more ADO Recordset–like DataSet, the SqlDbTable class (this is not specific to SqlClient; all providers can implement a class that derives from System.Data.DbTable) can use strong types as well.
Finally, ADO.NET 2.0 contains changes to the DataSet’s updating semantics. In previous versions of ADO.NET, when the DataSet pushed a set of changed rows back to the database, it issued one update statement across the network at a time. In ADO.NET 2.0, SqlClient can batch multiple updates in a single network round trip by specifying UpdateBatchSize on the SqlDataAdapter. To support better a wide variety of optimistic concurrency scenarios, the SqlCommandBuilder now supports a variety of updated command generation options, and you specify them by using the ConflictOption property of the DbCommandBuilder. Your choices are now roughly equivalent to those in ADO classic. The conflict options are
• CompareAllSearchableValues—Generate a SQL UPDATE or DELETE statement with a WHERE clause that includes all columns in the query.
• OverwriteChanges—Generate a SQL UPDATE or DELETE statement with a WHERE clause that includes only the key.
• CompareRowVersion—Generate a SQL UPDATE or DELETE statement with a WHERE clause that includes only the TIMESTAMP column. The table must have a TIMESTAMP column if you choose this option.
See Chapter 5 of Essential ADO.NET for more information and a programmatic implementation for ADO.NET 1.0.
There are many more changes to the DataSet and related classes in ADO.NET 2.0, but a complete discussion of them is outside the scope of this book.
Where Are We?
In this chapter and in Chapter 13, we’ve covered many new features of the SQL Server client libraries. Some of the features are enabled by new server functionality and are available only when using SQL Server 2005 as the server. Table 14-10 shows where these features are available.
Table 14-10. SQL Server Version and Feature Availability
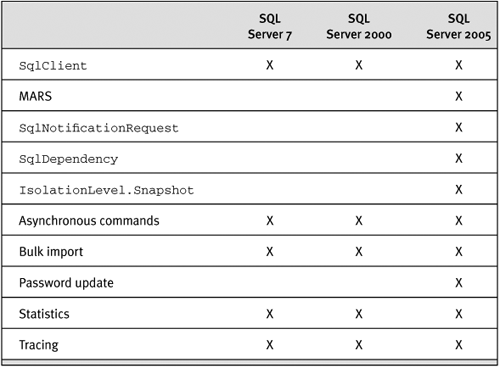
Support of the new data types, MARS, SqlNotifications, and SNAPSHOT isolation, depends on SQL Server 2005. Some features also depend on the new SQL client network library. Asynchronous invocation is an example of a network library–dependent feature that works against any version of SQL Server (7 and later). The network library enhancements are built into the .NET Framework 2.0 SqlClient provider, however. The rest of the features are enhancements to the ADO.NET API, including a tracing facility that is still in development at this writing. We covered the ones that are SQL Server–specific, including SqlNotificationRequest and SqlDependency, and the use of System.Data.SqlTypes inside the DataSet. Other data provider vendors, such as DataDirect Technologies, IBM, and Oracle Corporation, are also enhancing or have already enhanced their data providers to support the new features.