
SnuCL
A unified OpenCL framework for heterogeneous clusters
J. Lee; G. Jo; W. Jung; H. Kim; J. Kim; Y.-J. Lee; J. Park Seoul National University, Seoul, Korea
Abstract
Open Computing Language (OpenCL) is a programming model for heterogeneous parallel computing systems. OpenCL provides a common abstraction layer across general-purpose CPUs and different types of accelerators. Programmers write an OpenCL application once and then can run it on any OpenCL-compliant system. However, to target a heterogeneous cluster, programmers must use OpenCL in combination with a communication library. This chapter introduces SnuCL, a freely available, open-source OpenCL framework for heterogeneous clusters. SnuCL provides the programmer with an illusion of a single, unified OpenCL platform image for the cluster. SnuCL allows the OpenCL application to utilize compute devices in a compute node as though they were in the host node. In addition, SnuCL integrates multiple OpenCL platforms from different vendors into a single platform. It enables an OpenCL application to share OpenCL objects between compute devices from different vendors. As a result, SnuCL achieves high performance and ease of programming for heterogeneous systems.
Keywords
OpenCL; Heterogeneous cluster; Installable client driver; Accelerator; GPU; SnuCL; Parallel programming model
Acknowledgments
This work was supported by Grant No. 2013R1A3A2003664 (Creative Research Initiatives: Center for Manycore Programming) from the National Research Foundation of Korea funded by the Korean Government (Ministry of Science, ICT, and Future Planning). ICT at Seoul National University provided research facilities for this study.
1 Introduction
A general-purpose computing on graphics processing units (GPGPU) system typically consists of a general-purpose CPU and one or more GPUs. The GPGPU system has been a great success so far and is continuously widening its user base. It is a typical example of heterogeneous computing systems. A heterogeneous computing system refers to a system that contains different types of computational units, such as multicore CPUs, GPUs, DSPs, FPGAs, and ASICs. The computational units in a heterogeneous system typically include a general-purpose processor that runs an operating system. Processors other than the general-purpose processor are called accelerators because they accelerate a specific type of computation by assisting the general-purpose processor. Each accelerator in the system is best suited to a different type of task. The program execution and data are distributed among these computational units. Introducing such additional, specialized computational resources in a single system enables users to gain extra performance and power efficiency. In addition, exploiting different capabilities of the wide range of accelerators enables users to solve difficult and complex problems efficiently and easily.
As of Nov. 2015, 21% of the supercomputers in TOP500 are heterogeneous systems [1], and it is expected that the number will increase continuously. To exploit heterogeneity in the system, new programming models, such as Compute Unified Device Architecture (CUDA) [2, 3] and Open Computing Language (OpenCL) [4] have been proposed and widely used. Although CUDA works only for NVIDIA GPUs, OpenCL is supported by many vendors, including Altera, AMD, Apple, ARM, IBM, Imagination, Intel, MediaTek, NVIDIA, Qualcomm, Samsung, TI, Xilinx, and so on. OpenCL works for any device that provides an OpenCL framework. OpenCL has code portability for different processors from different vendors. The processors include multicore CPUs, GPUs, and other accelerators, such as Intel Xeon Phi coprocessors and FPGAs.
OpenCL is a unified programming model for different types of processors. OpenCL provides a common hardware abstraction layer across them. Programmers can write OpenCL applications once and run them on any OpenCL-compliant hardware. This portability is one of the major advantages of OpenCL. It allows programmers to focus their efforts on the functionality of their application rather than the lower-level details of the underlying architecture. This makes OpenCL a standard for general-purpose and heterogeneous parallel programming models.
However, one of the limitations of OpenCL is that it is a programming model for a single operating system instance. That is, it is restricted to a single node in a cluster system. An OpenCL application does not work for a cluster of multiple nodes unless the application developer explicitly inserts communication libraries, such as MPI, into the application. The same thing is true for CUDA [2, 3].
For example, a GPU cluster contains multiple GPUs across its nodes to solve bigger problems within an acceptable timeframe. Application developers for the clusters are forced to turn to a mix of two programming models, OpenCL + MPI or CUDA + MPI. Thus the application becomes a mixture of a communication API and OpenCL/CUDA. This makes the application more complex, less portable, and harder to maintain.
The mixed programming model requires the hierarchical distribution of the workload and data across nodes and across accelerators in a node. MPI functions are used to communicate between the nodes in the cluster. Therefore the resulting application may not be executed in a single node.
Another limitation comes from OpenCL’s installable client driver (ICD). It enables different OpenCL platforms from different vendors to coexist under a single operating system instance. However, to use different processors from different vendors in the same application, programmers need to explicitly choose a vendor-specific OpenCL platform for each processor in the application. Moreover, OpenCL objects (buffers, events, and so on) cannot be shared across different vendor platforms without explicit data copying through the host main memory.
In this chapter, we present an OpenCL framework called SnuCL. SnuCL overcomes aforementioned limitations of OpenCL and is a unified programming model for heterogeneous clusters. The target cluster architecture is shown in Fig. 1. Each node in the cluster contains one or more multicore CPUs and accelerators, such as GPUs. The nodes are connected by an interconnection network, such as Gigabit Ethernet and InfiniBand. One of the nodes is designated as the host node by the SnuCL runtime. The host node executes the host program in an OpenCL application. Other nodes are designated as compute nodes. In a compute node, a set of CPU cores or an accelerator becomes an OpenCL compute device. If the accelerator is a discrete GPU, data are transferred between the compute device memory and the main memory through a PCI-E bus.

SnuCL naturally extends the original OpenCL semantics to the heterogeneous cluster environment. As shown in Fig. 1, SnuCL gives the programmer an illusion of a single OpenCL platform image for the whole heterogeneous cluster. It allows the application to utilize compute devices in a compute node as though they were in the host node. The user can launch a kernel to a compute device or manipulate a memory object in a remote node using only OpenCL API functions. This enables OpenCL applications written for a single operating system instance (a single node) to run on the cluster without any modification. That is, with SnuCL, an OpenCL application becomes portable not only between heterogeneous computing devices in a single node but also between those in the entire cluster environment. Moreover, programmers do not need to explicitly choose different vendor platforms to use different accelerators in the same OpenCL application. OpenCL objects can be shared across different platforms in the same application without explicit data copying through the host main memory.
Many studies have focused on enabling OpenCL or CUDA applications to run on a cluster [5–18]. These approaches all have a host node that executes the host program. Other nodes in the cluster perform computations controlled by the host program. However, most of the previous approaches evaluate their framework with a small-scale cluster with less than 16 nodes. Only SnuCL [12, 13] evaluates itself using a large-scale cluster system and shows its practicality.
2 OpenCL
In this section, we briefly introduce OpenCL.
2.1 Platform Model
The OpenCL platform model shown in Fig. 2 consists of a host processor connected to one or more compute devices. An accelerator or a set of CPU cores is configured as a compute device. Each compute device contains one or more compute units (CUs) and has the compute device memory. The device memory of a compute device is not visible to other compute devices and consists of the global memory and the constant memory. Constant memory is read-only for the compute device. Each CU contains one or more processing elements (PEs) and the local memory. A PE is a processor and has its own private memory. PEs in the same CU share the local memory, and the local memory is not visible to other CUs.

As shown in Fig. 3, an OpenCL application consists of a host program and OpenCL programs. The host program is typically written in C and executes on the host processor. It creates one or more command-queues for each compute device and submits commands to a command-queue using OpenCL host API functions. Command-queues are attached to a compute device and maintained by the OpenCL runtime. Note that different compute devices may not share the same command-queue. If the command-queue is an in-order queue, enqueued commands are issued by the OpenCL runtime in the order they were enqueued and complete in that order. Otherwise, if the command-queue is an out-of-order queue, a command may begin execution before all its previous commands in the command-queue are complete.

The OpenCL program is a set of kernels. A kernel is a function and is written in OpenCL C. It performs computation on the PEs within a compute device. It is submitted to a command-queue in the form of a kernel execution command by the host program. The OpenCL runtime dequeues the kernel command and issues it to the target compute device. OpenCL C is a subset of C99 with some extensions that include support for vector types, images, and memory hierarchy qualifiers. It also has some restrictions as compared to C99. They are related to pointers, recursion, dynamic memory allocation, irreducible control flow, storage classes, and so on.
In addition to kernel execution commands, there are two other types of OpenCL commands: memory commands and synchronization commands. Because the host processor and a compute device do not share an address space, memory objects are used to transfer data between the host processor and the compute device. OpenCL 1.2 has two types of memory objects: buffer objects and image objects. OpenCL 2.0 includes new pipe objects in addition to the buffer and image objects. Because current SnuCL supports OpenCL 1.x, and it is very hard to find an OpenCL application that uses pipe objects, we focus on the buffer and image objects.
A buffer object and an image object are called a buffer and an image for short, respectively. A buffer’s purpose is to contain any type of data and is similar to a byte array in C. It stores a one-dimensional collection of elements that can be a scalar data type, vector data type, or user-defined structure. Image objects are specifically for representing 1D, 2D, or 3D images and facilitate accessing image data. To create, read, write, and copy such memory objects, a memory command is submitted to a command-queue by the host program. A synchronization command in OpenCL enforces an execution order between commands. Synchronization commands are also submitted to a command-queue by the host program.
2.2 Execution Model
Before a kernel is submitted, the host program defines an N-dimensional abstract index space, where 1 ≤ N ≤ 3. A two-dimensional index space is shown in Fig. 4. Each point in the index space is specified by an N-tuple of integers with each dimension starting at 0. Each point is associated with an execution instance of the kernel, which is called a work-item. The N-tuple is the global ID of the corresponding work-item. When the kernel is running, each work-item is able to query its ID using OpenCL C built-in functions. It can perform a different task and access different data based on its ID (i.e., data parallelism and single program, multiple data). An integer array of length N (i.e., the dimension of the index space) specifies the number of work-items in each dimension of the index space. The host program prepares the array for the kernel when the kernel command is enqueued.

One or more work-items are grouped in work-groups in the index space. Each work-group also has a unique ID that is also an N-tuple. An integer array of length N (i.e., the dimension of the index space) specifies the number of work-groups in each dimension of the index space. A work-item in a work-group is assigned a unique local ID within the work-group, treating the entire work-group as the local index space. The global ID of a work-item can be computed with its local ID, its work-group ID, and the work-group size. The OpenCL runtime distributes the kernel workload to CUs in the target device. The granularity of the distribution is a work-group. Work-items in a work-group execute concurrently on the PEs of the CU.
2.3 Memory Model
OpenCL C defines four distinct memory regions in a compute device according to the platform model (Fig. 2): global, constant, local, and private. These regions are accessible to work-items, and OpenCL C has four address space qualifiers to distinguish these memory regions: __global, __constant, __local, and __private. They are used in variable declarations in the kernel code. Accesses to the global memory or the constant memory may be cached in the global/constant memory data cache if such a cache exists in the device.
The host program enqueues memory commands to manipulate memory objects. Only the host program can dynamically create memory objects (i.e., buffers and images) in the global or constant memory using OpenCL API functions. A kernel may statically allocate constant memory space. Pointers to the memory objects are passed as arguments to a kernel that accesses the memory objects. Local memory spaces are shared by all work-items in the same work-group. The host program can dynamically allocate a local memory space using a clSetKernelArg() host API function. A kernel may statically allocate a local memory space. The private memory is local to each work-item. A kernel statically allocates a private memory space. The host program may not access the private memory space.
Using OpenCL API functions or pointers, only the host program can transfer data between the main memory and the memory objects allocated in the compute device memory. The host program enqueues blocking (synchronous) or nonblocking (asynchronous) memory transfer commands. Another way is enqueueing blocking or nonblocking memory map commands. The host program maps a region from the memory object allocated in the device memory into the host program’s address space.
Fig. 5 shows a sample host program. A kernel, vec_add, is embedded in the host program as a string. The OpenCL C built-in function get_global_id(0) returns the first element (i.e., 0 for the first dimension, 1 for the second, and 2 for the last) of the global ID of the work-item that executes the kernel. The kernel is executed on the one-dimensional index space. The first three kernel arguments are pointers to memory objects in the global memory of the compute device where the kernel is running.

The host program allocates memory spaces for arrays h_A, h_B, and h_C in the host main memory and initializes them appropriately. Using the clGetPlatformIDs() host API function, the host program obtains the list of OpenCL platforms available in the system. Then the host obtains the list of devices available on the platform using clGetDeviceIDs(). The code in Fig. 5 assumes that least one OpenCL platform exits and that at least one GPU device exits in this platform.
The next step is creating an OpenCL context. The OpenCL runtime uses the context to manage compute devices and OpenCL objects, such as command-queues, memory, program, and kernel objects. A context to which a kernel object belongs is an execution environment for the kernel. Using clCreateContext(), the host creates a context. In the context, the host creates a command-queue on the GPU device using clCreateCommandQueue() and an OpenCL program object using clCreateProgramWithSource(). An OpenCL program executable is compiled and linked by clBuildProgram(). Then the host API function clCreateKernel() creates a kernel object from the program executable.
To execute the kernel, the host prepares memory objects for the kernel. Using the clCreateBuffer() API function, the host creates three buffers, buff_A, buff_B, and buff_C. Because of CL_MEM_COPY_HOST_PTR flag, the contents of h_A and h_B are copied to buff_A and buff_B, respectively, when buff_A and buff_B are created.
Kernel arguments are set by clSetKernelArg(). After defining work-group size, lws[0], and the kernel index space, gws[0], the host enqueues a kernel command using the nonblocking API function clEnqueueNDRangeKernel() to execute the kernel on the GPU device. The OpenCL runtime issues the kernel to the target GPU device. Then the kernel executes on the GPU. The synchronization API function clFinish() blocks until the kernel command in the command-queue is issued to the GPU and has completed. The blocking memory command clEnqueueReadBuffer() reads the contents of buff_C to h_C. It is blocking because of the flag CL_TRUE. After reading the contents, the host prints the contents of h_C. Finally, the host releases OpenCL objects and frees dynamically allocated host memory spaces.
2.4 Synchronization
A work-group barrier used in the kernel synchronizes work-items in the same work-group. Every work-item in the work-group must execute the barrier and cannot proceed beyond the barrier until all other work-items in the work-group reach the barrier. No synchronization mechanism is available between work-groups in OpenCL.
Synchronization between commands in a single command-queue can be specified by a command-queue barrier using clEnqueueBarrierWithWaitList(). To synchronize commands in different command-queues, event objects are used. Each OpenCL API function that enqueues a command returns an event object that encapsulates one of the four distinct states of the command: CL_QUEUED, CL_SUBMITTED, CL_RUNNING, and CL_COMPLETE. It also takes an event wait list as an argument. This command cannot be issued for execution until the states of all the commands in the event wait list go to CL_COMPLETE. A user-defined event can be used to trigger some action when the host program detects that a certain condition is met.
2.5 Memory Consistency
OpenCL [4] defines a relaxed memory consistency model [19, 20] for the consistent memory view. An update to a device memory location by a work-item may not be visible to all the other work-items at the same time. Instead, the local view of memory from each work-item in the same work-group is guaranteed to be consistent at work-group barriers. The work-group barrier enforces a global memory fence for the consistent view of the global memory or a local memory fence for the consistent view of the local memory.
Updates to a shared memory object across different command-queues (e.g., different compute devices) are visible at synchronization points. The synchronization points defined in OpenCL include the following:
• The end of a blocking API function that enqueues a command
• A command-queue barrier
• The end of clFinish()
• The point when a kernel is launched onto a device after all events on which the kernel is waiting have been set to CL_COMPLETE
• The point when a kernel completes after all of its work-groups have completed
2.6 OpenCL ICD
OpenCL implementations are provided as ICD. This mechanism enables multiple OpenCL implementations to coexist under the same operating system instance. Users should choose the specific OpenCL platform for use in their applications, as shown in Fig. 6. At each OpenCL API function call, the ICD loader in the OpenCL runtime infers the vendor ICD function to call using the arguments to the function. Then it dispatches the OpenCL API call to the particular vendor implementation using a function pointer dispatch table.

Even though OpenCL ICD provides users with a convenient way of using multiple platforms in a single OpenCL application, there are some limitations in the current OpenCL ICD implementation. Fig. 7 shows an example of using ICD. We assume there are two OpenCL implementations available in the system, and each platform has only one compute device. Because each compute device belongs to a different OpenCL platform, the current OpenCL implementation does not allow creating a single context for the two devices. We need to create a context for each of them. In addition, to copy the contents of one buffer (buffer[0]) to another buffer (buffer[1]) that belongs to a different context (context[1]), we may not use clEnqueueCopyBuffer(). Instead, a temporary host-side memory space, tmp, is allocated. The buffers are copied through tmp with clEnqueueReadBuffer() and clEnqueueWriteBuffer().

3 Overview of SnuCL framework
In this section, we address limitations of OpenCL and present the methods to overcome them.
3.1 Limitations of OpenCL
As mentioned before, one of the limitations of OpenCL comes from its ICD. Even though ICD enables different OpenCL platforms from different vendors to coexist under a single operating system instance, programmers need to explicitly choose a specific OpenCL platform for each compute device in the application to use different compute devices from different vendors in the same application. As a result, an OpenCL context needs to be created for each vendor-specific platform. Thus a compute device may not access memory objects that belong to a different context without explicit data copying through a temporary space in the host main memory (Fig. 7). In addition, commands for different compute devices from different vendors cannot be synchronized using event objects. It is also impossible to share other OpenCL objects (programs, kernels, and so on) across different contexts.
To overcome this limitation, SnuCL integrates multiple OpenCL platforms from different vendors into a single platform. Using OpenCL ICD, SnuCL enables an OpenCL application to share objects (buffers, events, and so on) between different compute devices from different vendors.
For example, the code shown in Fig. 7 can be rewritten to the code shown in Fig. 8 using SnuCL. The SnuCL framework provides a unified platform called SnuCL Single under a single operating system instance. Because the two devices from two different vendor-specific OpenCL platforms belong to SnuCL Single, we create only one context for the two devices. As a result, to copy the contents of one buffer (buffer[0]) to another buffer (buffer[1]), we just use clEnqueueCopyBuffer(). An extra host-side memory space in the host program is not needed to transfer data from one buffer to another.

Another limitation of current OpenCL is that it is a programming model under a single operating system instance. An OpenCL application does not work for a cluster of multiple nodes each of which runs an operating system instance. Programmers are required to use communication libraries, such as MPI, in addition to OpenCL. This mixed programming model complicates workload and data distribution. The resulting application may not be executed under a single operating system instance.
SnuCL provides the programmer with an illusion of a single OpenCL platform image as shown in Fig. 1. SnuCL designates a node in the cluster as the host node where the OpenCL host program runs. SnuCL allows the OpenCL application to utilize compute devices in a remote node as they were in the host node. Using SnuCL, OpenCL applications written for multiple compute devices under a single operating system instance can run on the cluster without any modifications.
As shown in Fig. 9, SnuCL provides three different OpenCL platforms: SnuCL CPU, SnuCL Single, and SnuCL Cluster.

• SnuCL CPU platform is for general-purpose multicore CPUs under a single operating system instance. A set of CPU core in the system can be configured as an OpenCL compute device. The platform provides an ICD dispatch table. Thus SnuCL Single or SnuCL Cluster chooses this platform for CPU devices.
• SnuCL Single is a unified OpenCL platform that integrates all ICD-compatible OpenCL implementations installed under a single operating system instance.
• SnuCL Cluster is another unified OpenCL platform for heterogeneous clusters. It integrates all ICD-compatible OpenCL implementations in the cluster nodes and provides the programmer with an illusion of a single OpenCL platform image.
Assume that the developer uses a mix of OpenCL and MPI as a programming model for a heterogeneous cluster. The developer wants to launch a kernel to an OpenCL-compliant compute device in an OpenCL application. Assume that the kernel accesses a buffer, buff_A, that has been written by another compute device in a different compute node. Then the developer needs to explicitly insert communication and data transfer operations using MPI in the OpenCL application. To do so, as shown in Fig. 10A, the developer makes the source device to copy buff_A into a main memory space tmp using clEnqueueReadBuffer(). The source node sends the data to the target node using MPI_Send(). The target node receives the data in its own tmp from the source node using MPI_Recv(). The contents of tmp is copied to a new buffer object buff_B in the target device memory by clEnqueueWriteBuffer(). Finally, the developer sets buff_B as an argument of the kernel and invokes clEnqueueNDRangeKernel() to execute the kernel.

On the other hand, SnuCL Cluster fully hides the communication and data transfer from the developer. Thus the developer executes the kernel by invoking only clEnqueueNDRangeKernel() without any additional data movement operations (clEnqueueReadBuffer(), MPI_Send(), MPI_Recv(), and clEnqueueWriteBuffer()). This improves software developers’ productivity and increases portability. As a result, SnuCL achieves both high performance and ease of programming for a system running a single operating system instance and a cluster running multiple operating system instances.
3.2 SnuCL CPU
SnuCL CPU’s target architecture is a system that consists of multicore CPUs and that runs a single operating system instance. The user may use a vendor-specific OpenCL implementation for the multicore CPU instead of using SnuCL CPU. While vendor-specific OpenCL implementations typically use some kind of lightweight context switching to run OpenCL kernels on multicore CPUs [21], SnuCL CPU uses a source-to-source loop transformation technique called work-item coalescing [22].
The runtime for SnuCL CPU defines a mapping between the components of the OpenCL platform model and those of the target architecture. The mapping is summarized in Table 1. A set of CPU cores is configured as a compute device. Each CPU core in the set becomes a CU. Because there is no component in a CPU core that is similar to a PE in the OpenCL platform model, the core emulates the PEs using a kernel transformation technique. This technique is called work-item coalescing [22] and is provided by the SnuCL OpenCL-C-to-C translator. The runtime maps all of the memory components in the compute device to disjoint regions in the main memory.
Table 1
Mapping Between the OpenCL Platform Model and the Multicore CPU System
| OpenCL Platform Model | Multicore CPU System |
| Compute device | A set of CPU cores |
| Compute unit | A CPU core |
| Processing element | Emulated by a CPU core |
| Global memory | Main memory |
| Constant memory | Main memory |
| Local memory | Main memory |
| Private memory | Main memory and registers |
| Global/constant memory data cache | Data caches and coherence mechanism between cores |
The work-item coalescing technique makes the CPU core execute each work-item in a work-group sequentially, one by one. It uses a loop that iterates over the local work-item index space (i.e., inside a work-group). The triple-nested loop in Fig. 11B is such a loop. The code in Fig. 11B is obtained after the work-item coalescing technique has been applied to the kernel code in Fig. 11A. The size of the local work-item index space is determined by the array __local_size provided by the SnuCL runtime. It is the array passed to the runtime through clEnqueueNDRangeKernel(). The runtime also provides the array __global_id that contains the global ID of the first work-item in the work-group.

When work-group barriers are in the kernel, the work-item coalescing technique divides the kernel code into work-item coalescing regions (WCRs) [22]. A WCR is a code region that does not contain any work-group barrier. Because a work-item private variable whose value is defined in one WCR and used in another needs a separate location for each work-item to transfer the value across different WCRs, a code transformation technique called variable expansion [22] is applied to WCRs. Then the work-item coalescing technique executes each WCR using a loop that iterates over the local work-item index space.
In SnuCL CPU, the kernel workload is dynamically distributed across different CPU cores (i.e., CUs) in a compute device. The unit of workload distribution is a work-group. Work-group scheduling across different CPU cores is similar to parallel loop scheduling for traditional multiprocessor systems because each work-group is essentially a loop because of the work-item coalescing technique.
SnuCL CPU uses the conventional parallel loop scheduling algorithm, called factoring, proposed by Ref. [23]. The runtime of SnuCL CPU groups one or more work-groups together and dynamically assigns them to a currently idle CPU cores in order to balance the load. The set of work-groups assigned to a CPU core is called a work-group assignment. To minimize the scheduling overhead, the size of each work-group assignment is large at the beginning, and the size decreases progressively. When there are N remaining work-groups, the size S of the next work-group assignment to an idle CPU core is computed by S = ⌈N/(2P)⌉, where P is the number of all CPU cores in the CPU device [23]. The runtime repeatedly schedules the remaining work-groups until N is equal to zero. Factoring [23] is similar to guided self-scheduling (GSS) proposed by Ref. [24], where S is given by ⌈N/P⌉. Factoring is better than GSS when the variation of the workload in each iteration is large.
3.3 SnuCL Single
Every ICD-compatible OpenCL implementation has an ICD dispatch table that contains all OpenCL API function pointers. The runtime for SnuCL Single keeps the ICD dispatch tables of all available OpenCL platforms under a single operating system instance. It uses the tables to direct calls to a particular vendor implementation. The unified OpenCL platform, SnuCL Single, can be obtained with clGetPlatformIDs() in the host program. SnuCL Single implements clEnqueueCopyBuffer() using a temporary host main memory space if the source buffer and the destination buffer are allocated to two different compute devices that belong to different OpenCL platforms.
3.4 SnuCL Cluster
Fig. 12 shows the organization of the runtime for SnuCL Cluster. The runtime designates a node in the cluster as the host node where the host program runs. It consists of two different parts: the runtime for the host node and the runtime for other compute nodes. The runtime for the host node consists of two threads: host thread and command scheduler thread. When an OpenCL application executes on the host node, the host thread in the host node executes the host program in the application. The host thread and the command scheduler share command-queues. A compute device may have one or more command-queues as shown in Fig. 12. The host thread enqueues a command to a command-queue (➊ in Fig. 12). The command scheduler schedules enqueued commands across compute devices in the cluster one by one (➋).
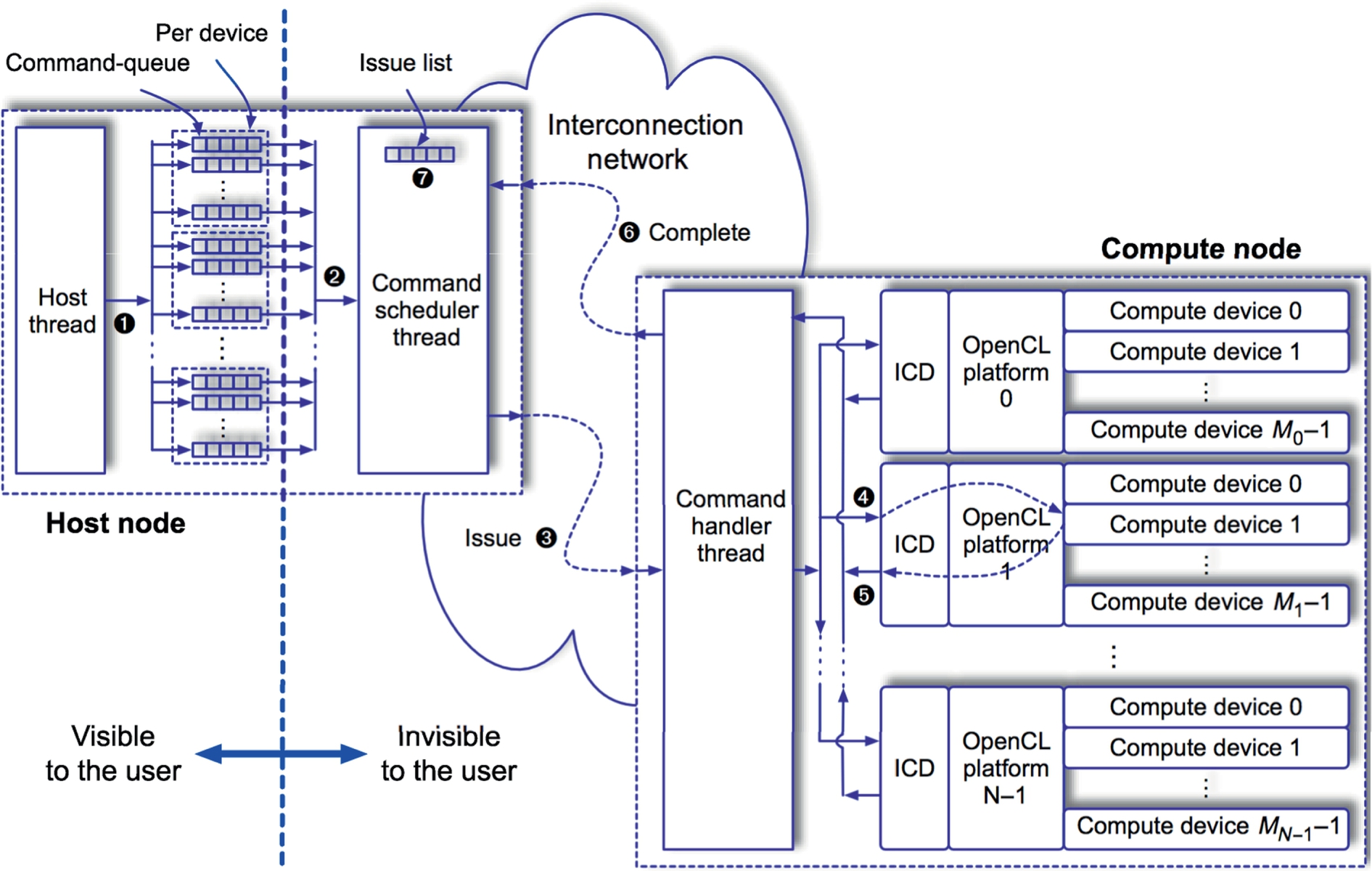
The command scheduler visits all the command-queues in a round-robin manner. After dequeueing a command from a command-queue, it issues the command by sending a command message (➌) to the target compute node. The target compute node contains the target compute device. A command message contains the information required to execute the original command. To identify OpenCL objects, the runtime assigns a unique ID to each OpenCL object, such as contexts, compute devices, memory objects, programs, kernels, events, and so on. The command message contains these IDs.
After sending the command message to the target compute node, the command scheduler calls a nonblocking receive communication API function to wait for the completion message sent from the target node. The command scheduler encapsulates this information in an event object. To communicate the status of commands, an event object is used in OpenCL. Then the command scheduler adds the event object in the issue list. The issue list contains event objects associated with the commands that have been issued but have not been completed.
A command handler thread resides in each compute node. It receives command messages from the command scheduler and executes them across compute devices in the node. After extracting the target device information from the message, the command handler dispatches the command to the target compute device using the vendor-specific OpenCL ICD (➍). We assume that there are N different OpenCL platforms and that platform i has Mi compute devices in a compute node. When the compute device completes executing the command (➎), the command handler sends a completion message to the host node (➏).
After receiving the completion message, the command scheduler in the host node updates the status of the associated event in the issue list to CL_COMPLETE (➐). Then it removes the event object from the issue list. The command scheduler repeats scheduling commands and continues checking the event objects in the issue list in turn until the OpenCL application terminates.
The command scheduler and command handlers are in charge of communication between different nodes. This communication mechanism is implemented with a low-level communication API, such as MPI.
3.4.1 Processing synchronization commands
The command scheduler in the host node honors the type (in-order or out-of-order) of each command-queue and event synchronization enforced by the host program. When the command scheduler dequeues a synchronization command, the command scheduler uses it for determining execution ordering between commands in different command-queues. It maintains a data structure to store the events that are associated with queued commands and maintains bookkeeping of the ordering between those commands. When there is no event for which a queued command waits, the command is dequeued and issued to its target.
4 Memory management in SnuCL Cluster
In this section, we describe how SnuCL Cluster manages memory objects and executes memory commands.
4.1 Space Allocation to Memory Objects
In OpenCL, the host program creates a memory object by invoking an API function, clCreateBuffer(). Even though the space for a buffer is allocated in the global memory of a specific device, the buffer is not bound to the compute device in OpenCL [4]. Binding a buffer and a compute device is implementation-dependent. As a result, clCreateBuffer() has no parameter that specifies a compute device. This implies that when a buffer is created, the runtime has no information about which compute device accesses the buffer.
The SnuCL runtime does not allocate any memory space to a buffer when the host program invokes clCreateBuffer(). Instead, when the host program issues to a compute device a memory command that manipulates the buffer or a kernel-execution command that accesses the buffer, the runtime checks whether a space is allocated to the buffer in the target device’s global memory. If not, the runtime allocates a global memory space to the buffer.
However, there is an exception to this rule. When clCreateBuffer() is invoked with the CL_MEM_COPY_HOST_PTR flag, the application wants to allocate a space to the buffer and copy data from the host main memory to the buffer. If the runtime delays the space allocation until the buffer binds to a specific compute device, the runtime may lose the original data because the data may have been updated. To avoid this situation, the runtime allocates a temporary space in the host main memory and copies the data to the temporary space. After the buffer binds to a compute device, the runtime allocates a space in the device’s global memory and copies the data from the temporary space to the allocated space. Then the temporary space is discarded.
4.2 Minimizing Copying Overhead
To efficiently handle buffer sharing between multiple compute devices, the SnuCL runtime maintains a device list for each buffer. The device list contains compute devices that have the same latest copy of the buffer in their global memory. It is empty when the buffer is created. When a command that accesses the buffer completes, the command scheduler updates the device list of the buffer. If the buffer contents are modified by the command, it empties the list and adds the device that has the modified copy of the buffer in the list. Otherwise, it just adds in the list the device that has recently obtained a copy of the buffer because of the command.
When the command scheduler dequeues a memory command or kernel-execution command, it checks the device list of each buffer that is accessed by the command. If the target compute device is in the device list of a buffer, the compute device has a copy of the buffer. Otherwise, the runtime checks whether a space is allocated to the buffer in the target device’s global memory. If not, the runtime allocates a space for the buffer in the global memory of the target device. Then it copies the buffer contents from a device in the device list of the buffer to the allocated space.
To minimize the memory copy overhead, the runtime selects a source device in the device list that incurs the minimum copying overhead. For example, memory copy overhead in a node increases in the following order: a GPU to the same GPU, a CPU to the same CPU, a CPU to a GPU, a GPU to a CPU, and a GPU to another GPU. The copying overhead between two different nodes is usually much higher than that between two devices in the same node. The overhead also increases as the amount of copy increases. The runtime prefers a source device that has a latest copy of the buffer and resides in the same node as that of the target device. If there are multiple such devices, a CPU device is preferred. When all of the potential source devices reside in other nodes, a CPU device is also preferred to other compute devices. This is because the lower-level communication API does not typically support reading directly from the device memory of an accelerator, such as GPUs. It requires one more copying step from the compute device memory to a temporary space in the node’s main memory.
To avoid such an unnecessary memory copy overhead, we define a distance metric between compute devices as shown in Table 2. We assume that there are two types of compute devices in the cluster: CPUs and GPUs. Based on this metric, the runtime selects the nearest compute device in the device list of the buffer and copies the buffer contents to the target device from the selected device.
Table 2
Distance Between Compute Devices
| Distance | Compute Devices |
| 0 | Within the same device |
| 1 | A CPU and another CPU in the same node |
| 2 | A CPU and a GPU in the same node |
| 3 | A GPU and another GPU in the same node |
| 4 | A CPU and another CPU in a different node |
| 5 | A CPU and a GPU in a different node |
| 6 | A GPU and another GPU in a different node |
4.3 Processing Memory Commands
There are three representative memory commands in OpenCL: write (clEnqueueWriteBuffer()), read (clEnqueueReadBuffer()), and copy (clEnqueueCopyBuffer()). When the runtime executes a write command, it copies the buffer contents from the host main memory to the global memory of the target device. When the runtime executes a read command, it copies the buffer contents from the global memory of a compute device in the device list of the buffer to the host main memory. A CPU device is preferred to avoid the unnecessary memory copy overhead. When the runtime executes a copy command, based on the distance metric (Table 2), it selects the nearest device to the target device in the device list of the source buffer. Then it copies the buffer contents from the global memory of the source device to that of the target device.
4.4 Consistency Management
In OpenCL, multiple kernel-execution and memory commands can be executed simultaneously, and each of them may access a copy of the same memory object (e.g., a buffer). If they update the same set of locations in the memory object, we may choose any copy as the last update for the memory object according to the OpenCL memory consistency model. However, when they update different locations in the same memory object, the case is similar to the false sharing problem that occurs in a traditional, page-level software shared virtual memory system [25].
One solution to this problem is introducing a multiple writer protocol [25] that maintains a twin for each writer and updates the original copy of the memory object by comparing the modified copy with its twin. Each node that contains a writer device performs the comparison and sends the result (e.g., diffs) to the host that maintains the original memory object. The host updates the original memory object with the diffs. However, this introduces significant communication and computation overhead in the cluster environment if the degree of sharing is high.
Instead, the SnuCL runtime solves this problem by executing kernel-execution and memory commands atomically in addition to keeping the most up-to-date copies using the device list. When the command scheduler issues a memory command or kernel-execution command, say C, it records the memory objects that are written by the command C in a list called written-memory-object list. When the command scheduler dequeues another command D, and D writes to any memory object in the written-memory-object list, it delays issuing D until the memory objects accessed by D are removed from the written-memory-object list. This mechanism is implemented by adding those commands that write to the memory objects and have not completed yet into the event wait list of the dequeued command D. Whenever a kernel-execution or memory command completes its execution, the command scheduler removes memory objects written by the command from the written-memory-object list.
4.5 Detecting Memory Objects Written by a Kernel
The consistency management described before requires detecting memory objects that are written by an OpenCL kernel. In OpenCL, each memory object has a flag that represents its read/write permission: CL_MEM_READ_ONLY, CL_MEM_WRITE_ONLY, and CL_MEM_READ_WRITE. Thus the runtime may use the read/write permission of each memory object to obtain the necessary information. However, this may be too conservative. When a memory object has CL_MEM_READ_WRITE and the kernel does not write to it at all, relying on read/write permission cannot detect this case.
Instead, SnuCL performs a conservative pointer analysis on the kernel source when the kernel is built. A simple and conservative pointer analysis [26] is enough to obtain the necessary information because OpenCL 1.2 imposes a restriction on the usage of global memory pointers used in a kernel. Specifically, a pointer to address space A can be assigned only to a pointer to the same address space A. Casting a pointer to address space A to a pointer to another address space B (≠ A) is illegal.
When the host builds a kernel by invoking clBuildProgram(), the SnuCL OpenCL-C-to-C translator at the host node generates the memory object access information from the OpenCL kernel code. Fig. 13 shows the information generated from the OpenCL kernel in Fig. 11A. It is an array of integer for each kernel. The ith element of the array represents the access information of the ith buffer argument of the kernel. Fig. 13 indicates that the first and second buffer arguments (a and b) are read and that the third buffer argument (c) is written by kernel vec_add. The runtime uses this information to manage memory object consistency. When the source code of the kernel is not available (e.g., the kernel is built from binary), the runtime conservatively uses each buffer’s read/write permission flag.

5 SnuCL extensions to OpenCL
In this section, we describe SnuCL’s collective communication extensions to OpenCL. Although a buffer copy command (clEnqueueCopyBuffer()) is available in OpenCL and can be used for point-to-point communication in a cluster environment, OpenCL does not provide any collective communication mechanisms that facilitate exchanging data between many devices. SnuCL provides collective communication operations between buffers. These are similar to MPI collective communication operations. They can be efficiently implemented with the lower-level communication API or multiple clEnqueueCopyBuffer() commands. Table 3 lists each collective communication operation and its MPI equivalent.
Table 3
Collective Communication Extensions
| sniCL | MPI Equivalents |
| clEnqueueAlltoAllBuffer | MPI_Alltoall |
| clEnqueueBroadcastBuffer | MPI_Bcast |
| clEnqueueScatterBuffer | MPI_Scatter |
| clEnqueueGatherBuffer | MPI_Gather |
| clEnqueueAllGatherBuffer | MPI_Allgather |
| clEnqueueReduceBuffer | MPI_Reduce |
| clEnqueueAllReduceBuffer | MPI_Allreduce |
| clEnqueueReduceScatterBuffer | MPI_Reduce:scatter |
| clEnqueueScanBuffer | MPI_Scan |
For example, the format of clEnqueueAlltoAllBuffer() operation is shown in Fig. 14.

It is similar to the MPI collective operation MPI_Alltoall(). The first argument, cmd_queue_list, is the list of command-queues that are associated with the compute devices where the destination buffers (dst_buffer_list) are located. The command is enqueued to the first command-queue in the list. The meaning of this API function is the same as enqueueing N-independent clEnqueueCopyBuffer()s to each command-queue in cmd_queue_list, where N is the number of buffers. An example of this operation is shown in Fig. 15.

6 Performance evaluation
This section describes the performance evaluation result of SnuCL. SnuCL implementation is open to the public at http://snucl.snu.ac.kr.
6.1 Evaluation Methodology
We evaluate SnuCL using a medium-scale GPU cluster and a large-scale CPU cluster. Configurations of the clusters are summarized in Tables 4 and 5. Applications used in the evaluation are from the SNU NAS Parallel Benchmarks (NPB) suite [27], PARSEC [28], NVIDIA SDK [29], AMD [30], and Parboil [31]. Table 6 summarizes the applications used. The SNU NPB suite is an OpenCL implementation of the NPB suite [32]. It provides OpenCL NPB applications for multiple compute devices. Blackscholes, BinomialOption, CP, N-body, and MatrixMul are manually translated to OpenCL applications for multiple compute devices.
Table 4
System Configuration of the Medium-Scale GPU Cluster
| Medium-Scale GPU Cluster | |
| Number of nodes | 36 |
| CPU | 2 × Intel 2.0 GHz octa-core Xeon E5-2650 for each node |
| GPU | 4 × AMD Radeon HD 7970 (2 GB RAM each) for each node |
| Memory | 128 GB for each node |
| OS | Red Hat Enterprise Linux 6.3 |
| Interconnect | Mellanox Infiniband QDR |
| OpenCL | AMD APP SDK v2.8 |
| MPI | Open MPI 1.6.4 |
| C compiler | GCC 4.4.6 |

Table 5
System Configuration of the Large-Scale CPU Cluster
| Large-Scale CPU Cluster | |
| Number of nodes | 512 |
| CPU | 2 × Intel 2.93 GHz quad-core Xeon X5570 for each node |
| Memory | 24 GB for each node |
| OS | Red Hat Enterprise Linux 5.3 |
| Interconnect | Mellanox Infiniband QDR |
| OpenCL | AMD APP SDK v2.9 |
| MPI | Open MPI 1.6.3 |
| C compiler | GCC 4.4.6 |
| Fortran compiler | GNU Fortran 3.4.6 |

Table 6
Applications Used
| Input | |||
| Application | Source | CPU Cluster | GPU Cluster |
| Blackscholes | PARSEC | 64M options | 128M options |
| BinomialOption | AMD SDK | 1M samples | 1M samples |
| CP | Parboil | 16K × 16K | 16K × 16K |
| N-body | NVIDIA | 2.5M bodies | 10M bodies |
| MatrixMul | NVIDIA | 16K × 16K | 10,752 × 10,752 |
| EP | NPB | Class E | Class E |
| FT | NPB | Class D | Class C |
| CG | NPB | Class E | Class C |
| MG | NPB | Class E | Class C |
| SP | NPB | Class E | Class D |
| BT | NPB | Class E | Class D |

6.2 Performance
For all applications but FT, CG, MG, SP, and BT, SnuCL on a GPU cluster is an order to three orders of magnitude faster than a CPU core depending on the number of GPUs used [12, 13]. For FT, CG, MG, SP, and BT, it is a few times faster than a CPU core. On a CPU cluster, SnuCL is a few times or an order of magnitude faster than a CPU core depending on the number of nodes used. They report that the performance of SnuCL for NPB is comparable to MPI-Fortran on a CPU cluster that consists of up to 64 nodes.
6.2.1 Scalability on the medium-scale GPU cluster
To show the scalability of SnuCL, we evaluate it on a 36-node GPU cluster. Fig. 16 shows the evaluation result. The x-axis shows the number of nodes. The number of GPUs used is recorded in parentheses. The y-axis shows the speedup over two nodes (eight GPUs) in logarithmic scale. It is better to show the speedup over a single GPU device, but a single GPU device cannot satisfy the memory requirement of the applications. Note that SP and BT require the number of devices to be a perfect square number. The speedups of SP and BT are obtained over 4 nodes (16 GPU devices) and 9 nodes (36 GPU devices), respectively. Because BT’s memory footprint exceeds the available memory in 4 nodes (16 GPUs), we do not execute BT on 4 nodes (16 GPUs).

Because Blackscholes, BinomialOptions, and CP are applications that scale well, SnuCL shows good scalability. The total amount of transferred data in N-body and MatrixMul increases as the number of devices increases. Thus the speedup increases slowly when the number of devices becomes large. Because EP is an embarrassingly parallel application, it also scales well with SnuCL.
The OpenCL kernels in FT, CG, MG, SP, and BT contain a relatively small amount of work. The amount of work in each kernel is too small to amortize the node-local, vendor-specific OpenCL runtime overhead. When the number of GPU devices increases, the amount of work in each kernel decreases because the total amount of work remains constant. In turn, the node-local, vendor-specific OpenCL runtime overhead becomes relatively large compared to the kernel workload. Because the total amount of memory in a GPU is limited (e.g., 2 GB), we cannot increase the input size further. Moreover, CG, MG, SP, and BT execute a large number of commands. Thus the command-scheduling and delivery overhead to remote devices dominates their performance. These are the reasons why SnuCL does not scale well with FT, CG, MG, SP, and BT on the GPU cluster.
6.2.2 Scalability on the large-scale CPU cluster
We compare the performance of SnuCL with that of MPI. The original NPB applications are written in Fortran using MPI. Fig. 17 shows the result. The x-axis shows the number of nodes, and the y-axis shows speedup over 256 MPI processes running on 32 nodes (i.e., 256 CPU cores) in logarithmic scale. Because E-class NPB applications do not run with less than 32 nodes because of the memory size, we run the applications on 32, 128, and 512 nodes. An exception is FT. Because E-class FT requires the memory size that is bigger than the total amount of memory of 32 nodes, we use the D-class input for FT (Table 6). The bars labeled MPI-Fortran and SnuCL show the performance of MPI and SnuCL, respectively. Because Blackscholes, BinomialOption, CP, N-body, and MatrixMul do not have an MPI version, we just obtain their speedup over SnuCL on 32 nodes (i.e., 256 CPU cores).

Blackscholes, BinomialOption, CP, N-body, MatrixMul, and EP execute a relatively small number of commands. Thus they scale well, except for MatrixMul at 512 nodes. MatrixMul initializes large 16, 384 × 16, 384 float-type matrices and multiplies them. The host should transfer at least 1 GB to each compute node without regard to the number of nodes to perform the matrix multiplication. As a result, MatrixMul does not scale well at 512 nodes.
SnuCL does not scale at all for FT. MPI-Fortran is much faster than SnuCL when the number of node is large. The performance of SnuCL decreases as the number of nodes increases. Because clEnqueueAlltoAllBuffer() commands used in FT make the host to deliver a point-to-point communication message to each compute node one by one, the amount of communication overhead between the centralized host and compute nodes becomes much more severe as the number of nodes becomes large.
As mentioned before, CG, MG, SP, and BT execute a large number of commands. Thus command-scheduling and delivery overhead dominate their performance in SnuCL. In addition, because the amount of work in the OpenCL kernel for 512 nodes is much smaller than that in the kernel for 32 or 128 nodes, the execution time of a kernel is not big enough to amortize the inherent overhead of the local, vendor-specific OpenCL runtime. On the contrary, MPI just executes the code immediately. Because the largest input class allowed for the NPB applications is class E, we cannot increase the input size further. In addition, the buffer-copy overhead of SnuCL is much bigger for a large number of nodes, and CG, MG, SP, and BT execute many buffer-copy commands. This is another reason why they do not scale well with SnuCL.
Overall, we see that SnuCL does not scale well for applications that have the following characteristics:
• The amount of work contained in kernels is too small, and a large number of such kernels are executed. As a result, the local, vendor-specific OpenCL runtime overhead and the command-scheduling overhead to remote devices dominate performance.
• A large number of memory commands are executed. The data movement overhead to remote devices dominates performance.
Actually, applications having these characteristics do not fit well with any heterogeneous programming model, such as CUDA and OpenCL.
7 Conclusions
In this chapter, we introduced the design and implementation of SnuCL. SnuCL unifies multiple OpenCL platforms from different vendors into a single OpenCL platform. It provides the single OpenCL platform image of a heterogeneous cluster to the programmer. Unlike OpenCL, SnuCL’s unified OpenCL platform enables an OpenCL application to share OpenCL objects between compute devices of different OpenCL platforms from different vendors. It allows the OpenCL application to utilize compute devices in a remote compute node as though they were in the host node. The user launches a kernel to any compute device in the cluster and manipulates memory objects using standard OpenCL API functions. SnuCL shows that OpenCL can be a unified programming model for heterogeneous clusters with different types of accelerators. Moreover, SnuCL’s collective communication extensions to OpenCL facilitate achieving high performance and provide ease of programming. SnuCL achieves high performance, ease of programming, and comparable scalability to MPI-Fortran for medium-scale clusters. However, applications that contain many small kernels and execute many memory commands do not scale well with SnuCL. These applications do not seem to fit well with any heterogeneous programming model, such as CUDA and OpenCL. For large-scale clusters, SnuCL may lead to performance degradation because of its centralized command-scheduling model. SnuCL source files are freely downloadable from the website http://snucl.snu.ac.kr.