
Thread communication and synchronization on massively parallel GPUs
T. Ta; D. Troendle; B. Jang University of Mississippi, Oxford, MS, United States
Abstract
Thread communication and synchronization play an important role in parallel computing. On graphics processing units (GPUs) where thousands of threads run simultaneously, the performance of the processor largely depends on the efficiency of thread communication and synchronization. Understanding which mechanisms are supported on modern GPUs and their implication for algorithm design is also very important in order for GPU programmers to write efficient code. Since most conventional general-purpose computing on GPU workloads are massively parallel with little cooperation among threads, early GPUs supported only coarse-grained thread communication and synchronization. However, the current trend is to accelerate more diverse workloads, and coarse-grained mechanisms have become a major limiting factor in exploiting parallelism. The latest industry standard programming framework, OpenCL 2.0, introduces fine-grained thread communication and synchronization support to address this issue. In this chapter, we present both coarse-grained and fine-grained thread synchronization and communication mechanisms available on modern GPUs along with the impact of their performance.
Keywords
GPGPU; Thread synchronization and communication; Global and local barriers; Atomics; OpenCL 2.0 memory model
1 Introduction
Thread communication and synchronization play an important role in parallel computing. Thread communication refers to information exchange among concurrent threads either via shared memory or a message passing mechanism. In shared memory systems, a thread can update variables and make them visible to other threads. In contrast, a message passing mechanism allows threads in separate memory spaces to communicate with each other. Graphics processing unit (GPUs) adopt a shared memory model; thus threads communicate through memories such as local and global memory. As with other shared memory parallel systems, GPUs encounter the following main issues associated with shared memory access:
[Mutual exclusion:] Concurrently running threads may attempt to update the same memory location simultaneously. Without a mechanism to guarantee mutual exclusion, shared variables may become corrupted, causing an indeterministic result. Such a scenario is called a race condition or data race. One way to avoid it is to protect shared memory using atomic operations. An atomic operation grants serialized exclusive access to shared data. Another way is to divide a program into phases so that threads in a phase can update shared data safely without any interference from the execution of other phases. A barrier divides a program into phases, ensuring that all threads must reach the barrier before any of them can proceed past the barrier. Therefore phases before and after the barrier cannot be concurrent with each other [1].
[Ordering:] Shared memory may appear inconsistent among threads without an ordering policy. This type of problem usually arises when the compiler or hardware reorders load and store operations within a thread or among threads. A memory consistency model is used to resolve this issue. GPUs adopt a relaxed consistency model where ordering is guaranteed only when the programmer explicitly uses a mechanism called a fence.
Thread synchronization is a mechanism to resolve the problems arising from concurrent access to shared memory. It prevents data corruption caused by unconstrained shared memory accesses. In this chapter, we present thread communication and synchronization mechanisms found in modern GPUs. We also discuss the performance implications of some techniques and include examples. Understanding thread communication and synchronization is essential not only to writing correct code but also to fully exploiting GPU’s parallel computation power.
Throughout the chapter, we use OpenCL terminology, except when Compute Unified Device Architecture (CUDA)-specific techniques are presented. The rest of the chapter is structured as follows: Section 2 discusses coarse-grained synchronization operations using explicit barriers and implicit hardware thread batch. Section 3 presents native atomic functions available for shared variables with regular data types. Section 4 presents fine-grained synchronization operations supported in OpenCL 2.0.
2 Coarse-Grained Communication and Synchronization
In parallel programming, it is quite common that work within a group of threads must be done in separate and distinct phases. For example, on GPUs each thread in a work-group may load some data from global to local memory before doing computation on the data in local memory. In this scenario, we have two separate execution phases: loading global data to local memory and computation. All threads in a work-group need to complete the first phase before any thread in the second phase attempts to access local memory. A synchronization mechanism called a barrier implements such separation within a group of threads.
Separating execution phases within a group of threads implies two requirements. First, all threads must reach or execute a barrier before any thread is allowed past that barrier. This requirement constrains the execution order among the group of threads. Since data can be cached and memory instructions can be reordered around a synchronization point, there may not be a consistent view of memory shared among threads once they clear the barrier. This fact leads to the second requirement that all threads after a barrier must have the same view of shared memory. The second constraint can be implemented through a special memory operation called a fence. Since a barrier is applied to a group of threads (typically at least 32 threads on current GPUs), it is considered as a coarse-grained synchronization. In following sections, we discuss barrier operations at the kernel and work-group and wavefront levels in the context of GPU programming.
2.1 Global Barrier at the Kernel Level
A global barrier synchronizes all threads across all work-groups in an NDRange, and it must satisfy the aforementioned two requirements: execution order constraints and memory consistency. A global barrier requires that all threads across all work-groups reach the barrier before any thread proceeds past the global barrier. This requires the suspension of work-groups that have already reached the barrier so that other work-groups can be scheduled and execute to the global barrier. Work-group suspension carries significant overhead as it involves the context switching of many threads. For that reason, there is no built-in global barrier function supported on GPUs. The effects of global barrier, however, can be achieved by splitting a kernel into multiple kernels and launching them in order. When a kernel terminates, all threads reach the end of the kernel, and data in caches are flushed to memory, which gives a consistent view of global memory among all threads in the successor kernel. However, a global synchronization at the kernel level comes with significant overhead. First, launching a new kernel instance incurs initialization cost. It takes significant time to send a kernel launch request to the host command queue via a device driver call and to warm up the hardware. On AMD GPUs, it usually takes hundreds of microseconds up to 1 ms to launch a kernel instance. Second, since all data are flushed to global memory between kernel launches, threads need to load data back to shared memory, L1/L2 caches, and registers. Third, this technique synchronizes all threads, even when only a smaller number of threads require synchronization.
A possible workaround that partially hides kernel launch overhead is to use out of order command queue execution. Fig. 1 shows the strategy. The idea is that instead of launching a new kernel instance after the previous one completes (Fig. 1A), all instances of a kernel are launched at the beginning and then the order of their execution is ensured using OpenCL events. OpenCL event objects can be used to define the sequence of the actual execution of the commands in the host queue. Fig. 1B illustrates how it works. Kernel 1 executes exactly as before, but the launch overhead of Kernel 2 is hidden by Kernel 1’s execution as it is queued in advance. Kernel 2 does not start its execution until Kernel 1 completes. This reduces the overall execution time.

Listing 1 shows an example skeletal host code that uses events and two kernels to achieve the effect of a global barrier. Lines 5–6 declare an out-of-order command queue. Lines 9–11 launch kernel1, and OpenCL runtime posts its completion to event1. Lines 13–15 launch kernel2, but it is not executed until event1 is posted. The overhead associated with kernel2’s launch is hidden while kernel1 is executing. Line 18 waits for kernel2 to post event2. Lines 20–21 release the events created by the launches.

There are some other attempts to “mimic” the effects of global barrier on GPUs at the software level. Xiao and Feng [2] proposed three implementations that synchronize threads across work-groups: (1) a GPU simple synchronization, (2) a GPU tree-based synchronization, and (3) a GPU lock-free synchronization.1 In order to illustrate the main idea of their proposed techniques, we discuss the first one here. The other two implementations provide some improvements in performance, but they are left to readers for further reading.
Listing 2 shows a custom function2 that tries to achieve the effects of a global barrier, and Listing 3 shows a generic kernel that uses the custom global barrier function to synchronize threads between two execution phases. Two shared variables are stored in global memory: goalVal holds the number of work-groups to be synchronized, and g_mutex keeps track of how many work-groups finished the first execution phase. When g_mutex is equal to goalVal, all work-groups have already reached the global synchronization point, and then they can start their second execution phase. In the gpu_sync function, the first thread of each work-group communicates with other work-groups by atomically incrementing the g_mutex variable to notify that this work-group has just finished the first phase. After that, it must wait at the synchronization point until all other work-groups finish their first execution phase. The first thread continuously checks the g_mutex variable in a tight while loop until g_mutex is equal to goalVal. It is likely that at the beginning of kernel execution, some work-groups are not scheduled to any compute units (CUs) right away, so the function will fail if threads in some active work-groups must wait for unscheduled work-groups without releasing computing resources on GPUs. To solve this problem, Xiao and Feng place a constraint that requires that the number of work-groups be less than or equal to the number of available CUs on GPU and that one work-group be mapped to one CU by allocating all local memory space in a unit to a work-group [2].


However, there are some critical limitations in this technique. First, a deadlock is still possible since it is up to the hardware work-group scheduler to determine how to schedule work-groups to available CUs. Experiments on both AMD and NVIDIA GPUs verify this. On NVIDIA GPUs, these requirements are enough to avoid the deadlock since the work-group scheduler distributes all work-groups evenly to all available CUs. However, on AMD GPUs, the work-group scheduler may not schedule work-groups to all available CUs, which leads to some unscheduled work-groups at the beginning of kernel execution. Second, this technique only guarantees the order of execution among threads but not the consistency of global memory. In the gpu_sync function, there is a local barrier (we discuss this in Section 2.2) that synchronizes all threads in a work-group. As explained in Section 2.2, the memory fence option used inside the local barrier ensures that local and global memory are consistent only with threads in the same work-group. That fence fails to guarantee the consistency among threads across work-groups, so the gpu_sync function does not behave exactly as a true global barrier does.
2.2 Local Barrier at the Work-Group Level
OpenCL provides a scope-limited, built-in barrier function for threads within a work-group. It guarantees the synchronization among threads in the same work-group but not threads across work-groups. (See the discussion on overhead in Section 2.1.) Since its scope is restricted to threads within a work-group, it is also called a local barrier. A local barrier delineates two execution phases—before and after the barrier function. It does this by enforcing all threads in a work-group to execute the barrier function before any thread can proceed past the barrier. Listing 4 shows a simple kernel that uses a local barrier function to separate two phases across the threads of a work-group. Since a local barrier is placed between the input[gid]++ and output[gid] = input[gid] statements, no thread is allowed to update the output buffer until all threads in a work-group execute the barrier function. Hence the order of execution among threads in the same work-group is guaranteed.

In addition, the consistency of shared memory regions is guaranteed by an explicit memory fence implemented inside the local barrier function. Section 4 discusses in more detail how a fence can ensure the memory consistency among threads. Recall that threads in a work-group share two memory regions: local and global memory. Because their latency is significantly different, ensuring consistency in global memory is generally more expensive than having threads in a work-group see a consistent view of local memory. Therefore OpenCL allows programmers to choose in which memory region they want to implement consistency. The CLK_LOCAL_MEM_FENCE flag ensures that all threads in a work-group have a consistent view of local memory after a local barrier, while the CLK_GLOBAL_MEM_FENCE flag ensures consistency in global memory. Both flags may be used together if consistency is required in both local and global memory.
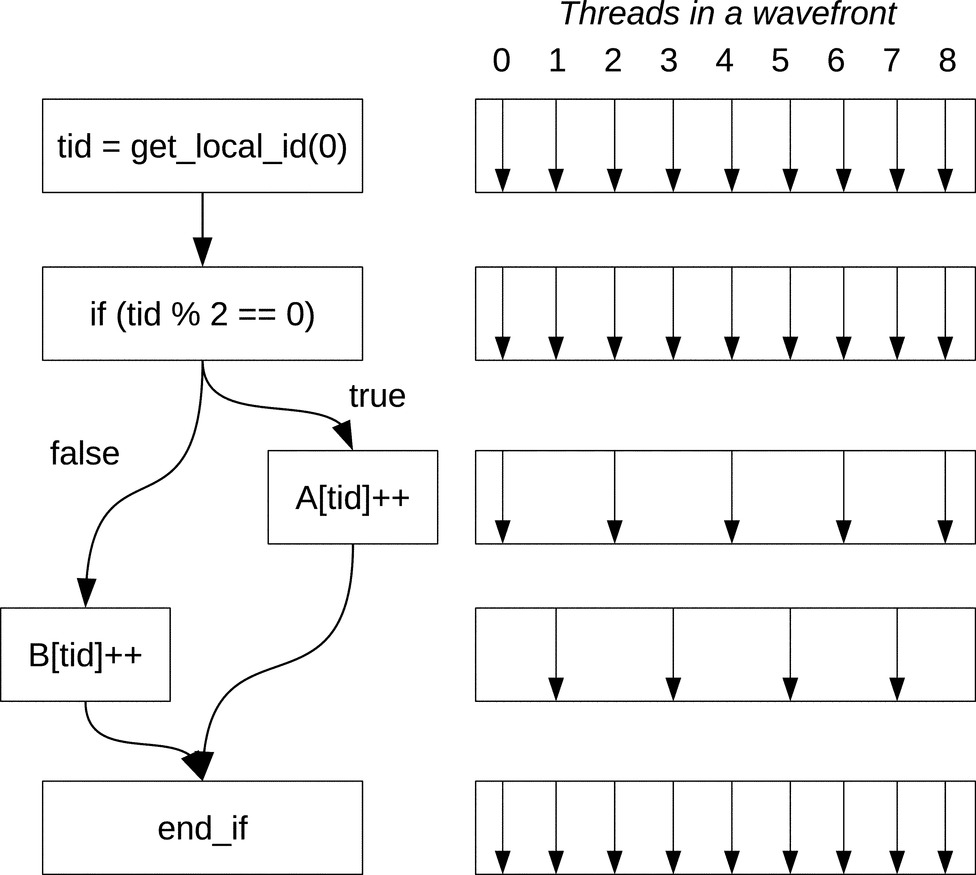
A deadlock may occur when the local barrier is incorrectly placed inside branching statements. Listing 5 shows an example of such a scenario in which the local barrier is placed inside the if statement that allows only threads with even thread IDs to execute the barrier function. Threads with odd IDs will never be able to reach the barrier because of the branching statement.

Local barriers at the work-group level are widely used in GPU programs. Listing 6 shows an example of using a barrier to implement a simple work donation algorithm among threads in the same work-group. On GPUs load imbalance could become a critical performance issue when workload per thread cannot be determined at compile time. When the workload is not evenly distributed, only a few threads may do most of work, while others may finish early because they have little work to do. Nasre et al. [3] presents a general work donation scheme to balance workloads among threads in the same work-group. The main idea of work donation is that the amount of work assigned to a thread should be roughly equal to the average workload for all threads.

In this algorithm, a donation box is shared by all work-items in a work-group so that threads assigned too much work can “donate” or transfer their extra tasks to others. Three phases are separated by local barriers in this algorithm. First, each thread determines the number of tasks assigned to it, and then the per-thread workload is atomically added to the total number of tasks assigned to all threads in the work-group. In the second phase, the average workload per thread is calculated by dividing the total work for all tasks by the number of threads in a work-group. Since each thread must finish calculating its workload and update the total number of tasks before any thread proceeds to the next phase, a local barrier is used to separate the two phases. Without this barrier, some threads could compute the average workload before all threads have contributed their workload to the task total. If any thread gets too many tasks (i.e., greater than the average plus a certain threshold), the excess work will be donated to the shared box. Another barrier is placed at the end of this phase to ensure the donation box is updated and visible to all threads in the work-group. Lastly, all work-items do their assigned jobs and then get some extra tasks from the donation box if the box is not empty. Since work-items exchange tasks within the scope of work-group, shared variables are placed in local memory instead of global memory to minimize access latency. CL_LOCAL_MEM_FENCE is chosen to avoid the unnecessary overhead of making global memory consistent.
In this example, the work-group barriers impact the algorithm’s correctness in two ways. First, they order the three phases so that no instruction in later phases is executed until all threads finish all instructions in their current phase. Second, after the synchronization point, the local barriers guarantee that all threads in a work-group have a consistent view of shared variables including the donation box and total work. If the consistency was not ensured at the barriers, threads would see different values in the donation box and total workload.
2.3 Implicit Barrier at the Wavefront Level
In addition to the built-in local barrier discussed in Section 2.2, GPU hardware intrinsically implements another smaller-scoped barrier. We call it an implicit barrier. To understand how an implicit barrier works, we need to go back to how threads are organized and executed on a GPU. A GPU is composed of multiple computing cores called CUs in OpenCL terminology (or equivalently streaming multiprocessors in CUDA terminology). Since hardware vendors use different terminologies to describe their architectures, for the purpose of this discussion, we explain the AMD GPU architecture and use its corresponding terminology. Fig. 2 shows the hierarchical structure of AMD Southern Islands GPUs. Each CU is further divided into smaller hardware blocks called processing elements (PEs). The way PEs are structured within a CU is an architecture design choice. For example, in AMD Southern Islands architecture, each CU consists of 4 vector units, each of which contains a group of 16 PEs [4]. These 16 PEs are able to handle 16 work-items in parallel, which is called the single instruction multiple data (SIMD) unit. All elements in an SIMD unit share a single instruction but operate on 16 possibly different operands.

To hide latency, SIMD units are further grouped to form a hardware thread batch called wavefront (equivalently warp in NVIDIA’s terminology). On AMD GPUs, the wavefront size is 4 SIMD units (i.e., 64 threads), and all 64 work-items in a wavefront execute the same instruction in a lock-step fashion, completing one before moving on to the next instruction. They are always implicitly synchronized with each other, and no explicit barrier is required to synchronize them.
When branching causes divergent thread paths within a wavefront, the hardware maintains lock-step execution by either disabling some threads that are not in the current branch or forcing all threads to execute all branches and masking invalid results. Fig. 3 visualizes a simple case where an if statement splits the control flow inside a wavefront and some threads not on the current branch are disabled. No matter how hardware deals with thread divergence, all threads in a wavefront always stay synchronized.
Since threads in a wavefront automatically and implicitly stay synchronized, there is no synchronization overhead as is the case with explicit barriers. Several algorithms have already exploited this characteristic for efficiency. We discuss two scenarios where implicit synchronization is used efficiently: (1) a fast parallel scan algorithm and (2) a software prefetching scheme.
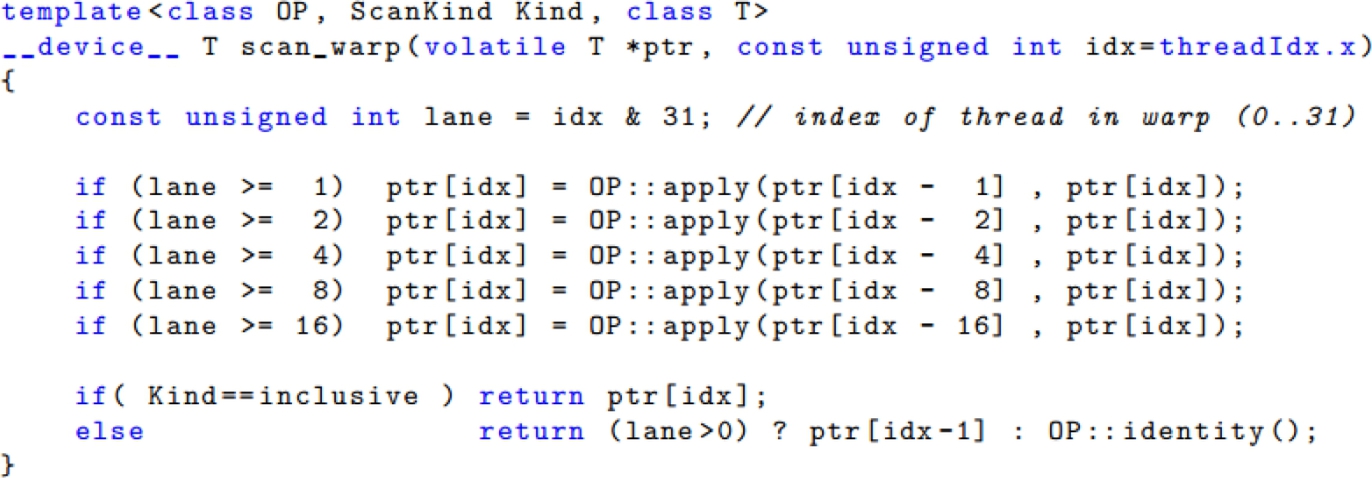
Sengupta et al. [5] proposed a better GPU parallel scan algorithm.3 Fig. 4 shows the original scan algorithm that uses explicit local barrier to synchronize threads in a block. Assuming that the work-group size is 256 (i.e., n = 256), the number of local barriers that are executed by each thread is 16 (i.e., 8 iterations and 2 barriers per iteration). Such local synchronizations incur runtime overhead.

Let us look at another way to implement the parallel scan using an implicit barrier. The algorithm is separated into two phases: (1) intrawarp scan (Fig. 5) and (2) intrablock scan (Fig. 6). First, each warp does the scanning on its own threads. After the intrawarp scan is complete in all warps of a block, a single thread in each warp (e.g., lane == 31) collects and consecutively writes partial results from each warp to an array. Finally, a single warp does scanning on that array to get the final result. With this improvement, the number of local barriers required is only 5 compared to 16 in the original algorithm with 256 threads in a block. In addition, the number of local barriers in the improved parallel scan does not increase with the block size. Therefore the second way improves the performance by reducing the number of local barriers needed.

The preceding example shows how to avoid expensive explicit local barriers by using implicit barriers. In another work, Bauer et al. [6] discussed a way to prefetch data into local memory in parallel with computation. The idea is to preload data into local memory before the data is actually used. To do that, they separated wavefronts in a work-group into two different groups.4 The first group called DMA-wavefronts (DMA-warps as in the original paper) was dedicated to loading data from global into local memory for the next computation iteration, while wavefronts in the second group called compute-wavefronts (compute-warps as in the original paper) did actual computation on the data preloaded in local memory. The numbers of compute and DMA wavefronts were not necessarily equal. The authors discussed three ways to implement the prefetching: (1) single-buffering, (2) double-buffering, and (3) manual double-buffering. Here we discuss only the third, manual double-buffering.
Two buffers named A and B are kept in local memory. The DMA wavefronts load data from global memory into one buffer while the compute wavefronts do computation on the other buffer. Fig. 7 shows how two groups of wavefronts interchange buffers in each iteration. At the end of each iteration, an explicit local barrier ensures compute and DMA wavefronts are in sync and data in the two buffers are not corrupted.

3 Built-In Atomic Functions on Regular Variables
Sharing memory across concurrent threads becomes problematic when one thread attempts an unsynchronized update. This is called a data race. A data race happens when (1) at least two threads are concurrently accessing the same memory location; (2) at least one thread is trying to update the value stored in that location; and (3) there is no synchronization mechanism to ensure that these accesses are mutually exclusive [7]. Listing 7 shows a very simple kernel in which a data race problem results in an unpredictable final value of the variable counter. Suppose two threads A and B try to increment counter. Both threads must read counter first, add one to it, and then write the new value back to counter. The final new value will be incorrect if a thread reads counter after the other one reads it but has not yet written the new value back. Such an indeterministic data race can occur unless operations are guaranteed to be mutually exclusive.

Since a data race can lead to corrupted shared memory and indeterministic program behavior, most parallel and distributed computing systems, including GPUs, provide built-in atomic functions. These functions ensure that memory operations are indivisible and not interrupted by any other concurrent threads. The list of atomic functions supported in OpenCL and CUDA can be found in their specifications [7, 8]. These atomic functions can work on shared variables declared with a regular data type in both local and global memory, and guarantee mutually exclusive access to the variable across all threads without constraining in which order concurrent memory operations occur. We call them regular atomic functions to differentiate them from the atomic operations discussed later in Section 4.
Atomic operations come at a price. An atomic operation serializes memory accesses from different threads. While a thread is accessing a shared location, a lock is issued on that location until the occupying thread completes its atomic update. Other threads must wait on the lock, and the order in which they occur is undefined. The overhead of atomic functions can vary across different access patterns and hardware implementations. Consider the microbenchmark kernels in Listings 8 and 9 adopted from Ref. [9]. Listing 8 shows four different atomic access patterns on global memory. The first kernel, CoalescedAtomicOnGlobalMem, has all threads access consecutive memory addresses (aka, coalesced memory accesses) without contentions among threads. The second and third kernels, AddressRestrictedAtomicOnGlobalMem and ThreadRestrictedAtomicOnGlobalMem, have all threads within a wavefront (or warp) access consecutive memory addresses and the same address, respectively. The last kernel, SameAddressAtomicOnGlobalMem, has all threads access the same address, causing high contentions among threads. Table 1 shows their performance measured on modern AMD and NVIDIA GPUs.


Table 1
Performance of Global Atomic Operations With Different Access Patterns (Numbers in Milliseconds)
| Kernels | AMD Radeon R9 290a | NVIDIA GTX 980b |
| CoalescedAtomicOnGlobalMem | 1.485 | 1.820 |
| AddressRestrictedAtomicOnGlobalMem | 2.155 | 9.712 |
| ThreadRestrictedAtomicOnGlobalMem | 6.393 | 2.722 |
| SameAddressAtomicOnGlobalMem | 33.614 | 25.908 |
a WF_SIZE is set to 64.
b WF_SIZE is set to 32 (warp size in NVIDIA GPU).
Listing 9 shows microbenchmark kernels that perform atomic operations on local memory with the same patterns as in Listing 8, and Table 2 shows their corresponding performance.
Table 2
Performance of Local Atomic Operations With Different Access Patterns (Numbers in Milliseconds)
| Kernels | AMD Radeon R9 290a | NVIDIA GTX 980b |
| CoalescedAtomicOnLocalMem | 0.181 | 0.114 |
| AddressRestrictedAtomicOnLocalMem | 0.192 | 0.085 |
| ThreadRestrictedAtomicOnLocalMem | 2.037 | 1.474 |
| SameAddressAtomicOnLocalMem | 2.089 | 1.474 |
a WF_SIZE is set to 64.
b WF_SIZE is set to 32 (warp size in NVIDIA GPU).
4 Fine-Grained Communication and Synchronization
The coarse-grained synchronization operations discussed in Section 2 are applied to a group of threads in an NDRange, a work-group, or a wavefront. They are efficient if communication needs involve all threads in the group. In regular workloads, whose computation patterns and execution dependencies are known at compile time, programmers can pack threads that need synchronization into as small a group as possible to minimize the cost of triggering barriers. The fast parallel scan algorithm discussed in Section 2.3 is a good example of such regular programs. However, redesigning an algorithm to reduce the cost of barrier is a difficult and sometimes even impossible task. There are many algorithms whose computation pattern and control flow cannot be determined at compile time. So where a barrier should be placed and how large its scope should be are hard to know. In such situations, programmers must use a wide-scoped barrier that synchronizes only a few threads in order to make their programs run correctly. This incurs very high overhead. Therefore more fine-grained communication among threads is desirable in general-purpose workloads on GPUs. Fortunately, the OpenCL 2.0 memory model (aka, memory consistency) includes new synchronization operations that allow fine-grained thread communication on GPUs. In Section 4.1, we first revisit briefly the concept of memory consistency and explain two general memory models: sequential and relaxed consistency. Section 4.2 discusses the details of the OpenCL 2.0 memory model and how to synchronize threads using a stand-alone fence and new atomic operations.
4.1 Memory Consistency Model
A memory model helps programmers ensure the correctness of their programs in multicore (or multiprocessor) systems by ordering the visibility of the effects of load and store instructions from different cores. To understand why a memory model is important, consider the typical producer-consumer code shown in Table 3. Assume that only two cores are sharing a single memory space.
Table 3
An Indeterministic Program on Dual-Core System Without Consistency Model [10]
| Core 1 | Core 2 |
| S1: data | |
| S2: flag | L1: R1 |
| B1: if (R1 != SET) goto L1 | |
| L2: R2 |
Programmers expect that variable R2 will eventually store the NEW’s value because they assume S1 is always executed before S2, as shown in the program order. In fact, without an additional mechanism to strictly order S1 and S2, these instructions can be reordered by either the compiler (e.g., through instruction scheduling) or hardware (e.g., through out-of-order execution). If S1 and S2 are reordered, flag is set before data gets NEW’s value. Thus it is possible that R2 will get the old value stored in data on Core 2. Notice that L1 and L2 could also be reordered on Core 2 for similar reasons. This example shows the importance of a consistency model in a multicore system because it ensures the correctness of multithreaded programs. Based on how strictly a memory model enforces the order of load and store instructions, memory models are categorized into two groups: (1) sequential consistency that strictly preserves memory instructions’ order and (2) relaxed consistency that allows memory instructions to be reordered to some extent for better performance. OpenCL 2.0 implements a relaxed memory consistency model.
4.1.1 Sequential consistency
Lamport [11] first introduced the sequential consistency model. On multicore systems with shared memory, it ensures the runtime order of memory instructions in the order specified in the program. Sequential consistency is the most intuitive model—the hardware follows the order of instructions specified in the program. Lamport specified two requirements for the sequential consistency model: (1) all memory requests issued by a single core (processor) execute in the order specified by programmer and (2) the memory system must service memory requests from different cores in an FIFO order [11]. Going back to the example shown in Table 3, a programmer expects the system to execute instruction S1 before S2 on Core 1. That order is specified by the programmer and is called the program order [10]. If sequential consistency is applied, Core 1 must issue S1 before S2, and also S1 must be executed before S2 since S1 arrives at the memory system before S2 does.
4.1.2 Relaxed consistency
Sequential consistency is a conservative memory model that does not allow any instruction reordering on each core. This prevents many optimizations and degrades performance. However, not all memory instructions on a single core need to preserve their program order. Some memory instructions can be reordered, achieving better performance without losing correctness. This is the motivation for more relaxed or weaker memory models. In order to do that, programmers are responsible for specifying program order through fence instructions. A memory fence is basically a special instruction that orders memory operations around it. In relaxed models, without an explicit fence, load and store instructions are assumed to be order-independent and thus eligible for reordering [10]. All memory instructions before a fence must be issued and executed before any one after the fence. Table 4 shows an example of how to place fence instructions to guarantee that R2 will eventually get NEW value.
Table 4
Two Fence Instructions, F1 and F2, Are Placed to Ensure NEW Value Is Assigned to R2 [10]
| Core 1 | Core 2 |
| S1: data | |
| F1: fence | |
| S2: flag | L1: R1 |
| B1: if (R1 != SET) goto L1 | |
| F2: fence | |
| L2: R2 |
4.2 The OpenCL 2.0 Memory Model
Inherited from previous OpenCL versions, the coarse-grained barriers and regular built-in atomic functions are still available in OpenCL 2.0. In addition to these synchronization mechanisms, OpenCL 2.0 provides stand-alone fence and special atomic functions that can order memory instructions around them. This support allows programmers to do fine-grained thread communication. In this section, we first define relationships that may exist between any two memory operations (i.e., load or store instructions). These relationships help us precisely discuss (1) special atomic operations and stand-alone memory fences (Section 4.2.2), (2) acquire/release semantics (Section 4.2.3), and (3) memory ordering options (Section 4.2.4). Lastly, we present memory scope options that help reduce synchronization overhead.
4.2.1 Relationships between two memory operations
OpenCL 2.0 defines the following relationships between two memory operations in a single thread or multiple threads. They can be applied to operations on either global or local memory.
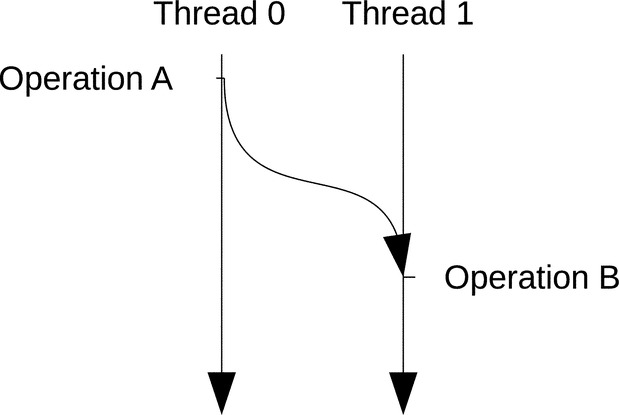
• Sequenced-before relationship. In a single thread (or unit of execution), a memory operation A is sequenced before a memory operation B if A is executed before B. All effects made by the execution of A in memory are visible to operation B. If the sequenced-before relationship between A and B is not defined, A and B are neither sequenced nor ordered [7]. This defines a relationship between any two memory operations in a single thread and how the effects made by one operation are visible to the other (Fig. 8).

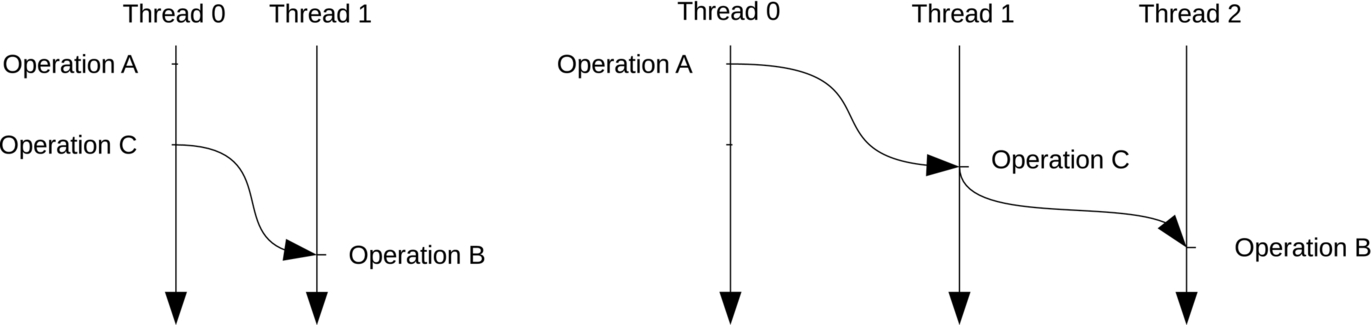
• Synchronizes-with relationship. When two memory operations are from different threads, they need to be executed in a particular order by the memory system. Given two memory operations A and B in two different threads, A synchronizes with B if A is executed before B. Hence all effects made by A in shared memory are also visible to B [7] (Fig. 9).
• Happens-before relationship. Given two memory operations A and B, A happens before B if
– A synchronizes with B, or
– For some operation C, A happens before C, and C happens before B [7] (Fig. 10).
4.2.2 Special atomic operations and stand-alone memory fence
The regular atomic functions discussed in Section 3 ensure only that concurrent accesses to a shared memory location are mutually exclusive. They can be applied to a shared variable declared with a regular data type so that it can be protected from race condition. Special atomic operations in OpenCL 2.0 are able to do more than just ensuring mutually exclusive access to a shared location. They place ordering constraints on memory instructions before and after them in program order. The ordering constraints are discussed in detail in later sections. These special atomic operations must work on a predefined subset of shared variables called atomic objects. These objects are declared with special atomic data types (e.g., atomic_int, atomic_float, etc.). Programmers have to declare, initialize, and use these objects through special built-in functions. For example, atomic_init initializes an atomic object to a constant, and atomic_load returns the value stored in an atomic object [7]. The full list of available special atomic functions can be found in the OpenCL 2.0 C specification.
Section 2.2 described the memory fence implemented inside a local barrier to order memory instructions before and after the barrier. The OpenCL 2.0 memory model supports a stand-alone fence function, atomic_work_item_fence, with more ordering constraint and scope options. There is a difference between a special atomic operation and a memory fence. No specific atomic object is associated with a fence. In contrast, any special atomic operation requires a corresponding atomic object [7]. A special atomic operation, in addition to its capability of ordering memory instructions, provides globally exclusive access to its corresponding atomic object. Programmers can do a read-modify-write operation on an atomic object atomically through a special atomic operation (e.g., atomic_fetch_add function).
4.2.3 Release and acquire semantics
In OpenCL 2.0, release and acquire semantics specify the aforementioned relationships between two memory operations through either a stand-alone fence or a special atomic operation. They are mostly used to broadcast a change(s) made by a thread in shared memory to one or more other threads. Let us go back to the producer-consumer pattern in which a producer thread wants to broadcast to consumer thread(s) all values it has written to shared memory through fence and atomic instructions (we use fence and atomic function as stand-alone operations in this example for the purpose of clarification). We give an example of OpenCL 2.0 code in which they are fused into a single atomic function in a later section (Table 5).
Table 5
An Example of Acquire and Release Semantics
| Producer Thread | Consumer Thread |
| LS1: Some loads and stores in shared memory | |
| F1: Release fence | |
| Atomic S1: flag | Atomic L1: R1 |
| B1: if (R1 != SET) goto L1 | |
| F2: Acquire fence | |
| LS2: Some loads and stores in shared memory |
The release fence F1 guarantees that LS1 is sequenced before Atomic S1 instructions. Therefore, all changes made by LS1 are visible in shared memory when Atomic S1 is executed. Without the release fence, the problem discussed in Section 4.1 would happen. Similarly, the acquire fence F2 ensures that Atomic L1 is sequenced before LS2 instructions. In this case, the release fence F1 synchronizes with the acquire fence F2. In short, the execution chain will be LS1 ![]() F1
F1 ![]() Atomic S1
Atomic S1 ![]() Atomic L1
Atomic L1 ![]() F2
F2 ![]() LS2 (operation at the left of the arrow happens before the one at the right of the arrow).
LS2 (operation at the left of the arrow happens before the one at the right of the arrow).
4.2.4 Memory order parameters
In either a memory fence or a special atomic operation, programmers can pass one of the following enumeration constants to specify how they want to order memory instructions around a synchronization operation.
• memory_order_relaxed. This constant implies that there is no order constraint specified among memory instructions [7]. Only the atomicity of operations is guaranteed. This option can be used to implement a global counter as shown next.

A global atomic variable named globalCounter that is initialized by the host program is incremented by each thread. Since addition is commutative, the order threads increment globalCounter does not matter. So we only need memory_order_relaxed to enforce the atomicity of that operation. Since no ordering constraint is specified, this option would yield the best performance.
• memory_order_acquire and memory_order_release. These two constants specify the release and acquire semantics as discussed in Section 4.2.3. They can be used in parallel code that have a producer-consumer pattern, like the following example.

In this example, a single global atomic lock variable is used to notify consumer thread(s) that a producer thread has updated shared memory with its results. The first thread in work-group 0 is a consumer who waits for the output returned by the first thread in the last work-group (i.e., the producer). The producer writes a value to a global variable, and then the consumer loads the value and stores it in a different variable. A tight while loop is used to guarantee that the release operation (i.e., atomic_store_explicit) synchronizes with the acquire operation (i.e., atomic_load_explicit). Without that loop, the load acquire may happen earlier than the store release, and thus no synchronization is achieved. Note that this kind of producer-consumer paradigm could fail and lead to a deadlock situation. For example, consider the situation where there are many consumer threads in multiple work-groups waiting on the lock that is supposed to be updated by a single producer thread. Because of some resource constraints, the work-group that has the producer thread could never be scheduled and executed. In that case, all consumer threads are executing a tight loop waiting for the producer to give them work. Since no consumer thread completes and frees resources, the producer cannot be scheduled. Therefore, when using fine-grained thread communication, programmers need to carefully design their algorithms to avoid such a deadlock.
• memory_order_acq_rel. This option implies both acquire and release orderings on load and store instructions around a synchronization point. It can be used in a read-modify-write atomic operation. For example, in OpenCL 2.0, the function atomic_fetch_key can first load a value in a shared variable, do an operation on it, and then update that variable with the modified value [7].
• memory_order_seq_cst. This constant specifies that sequential consistency is desired for all load and store instructions from different units of execution. No reordering is allowed for these instructions in a single thread. The program order from multiple threads appears to be interleaved [7]. Choosing this option will lead to additional overhead because no instruction ordering is allowed.
4.2.5 Memory scope parameters
Another parameter passed to OpenCL 2.0 synchronization operations is memory scope. The OpenCL execution model groups threads into different scopes (wavefront, work-group, NDRange, etc.). As reasoned in Section 2, communication among threads under a larger scope is generally more expensive than one under a smaller scope. Therefore programmers can improve performance by specifying as small a scope as possible under which threads communicate with each other. Any two threads involved in a synchronization must be under the same scope. Otherwise, the runtime would result in undefined behaviors. The memory scope constants used in synchronization operation are
• memory_scope_work_item. Ordering constraints are applied within a single work-item.
• memory_scope_work_group. Ordering constraints are applied to work-items within a work-group. Any synchronization across work-groups leads to undefined behaviors.
• memory_scope_device. Ordering constraints are applied to work-items across work-groups and running within a device.
• memory_scope_all_svm_devices. Ordering constraints are applied to work-items across devices provided that those devices share the same memory address space.
5 Conclusion and Future Research Direction
Throughout the chapter, we discussed various thread communication and synchronization mechanisms available in current GPUs. We presented several ways to achieve coarse-grained synchronization among threads under different scopes, and the performance implications of each technique in particular situations. We discussed built-in atomic operations on regular, shared variables to avoid data race problems and also the impact of such atomic functions on performance for different GPUs. We presented the current trend toward more fine-grained thread communication and synchronization that have been recently introduced as core functionalities in OpenCL 2.0 and HSA standards. We described the release-consistency-based memory model in OpenCL 2.0 by discussing concepts underlying that model and explaining how to correctly use newly introduced OpenCL 2.0 functions to achieve fine-grained communication at the thread level.
There is interesting ongoing research on fine-grained thread communication and synchronization that is essential in order for current GPUs to handle irregular workloads efficiently at both the software and the architecture levels. Various lock-free concurrent data structures (doubly ended queue, linked list, skip list, etc.) that have been implemented using traditional coarse-grained synchronization and atomic operations on GPUs [12, 13] can be more easily and efficiently implemented using fine-grained synchronization. The new HSA memory model opens more optimization opportunities for a class of irregular graph-based and mesh-based workloads whose performance is limited by coarse-grained synchronization. At the architecture level, implementation of such fine-grained thread communication mechanisms and the choice of a memory model for GPUs are interesting research directions [14–16]. As GPUs become more tightly coupled with CPUs, supporting a single memory model for these different processors becomes an increasingly important and challenging research topic.