
The human brain is far better at processing a narrative or story than it is at looking at individual data points. Grouping data assists in providing context to, and the corroboration of, a story. Consider the reveal in a detective show; the detective explains the crime as a timeline, from the motive through to the actions, to any cover-ups. Several streams of physical evidence, witness testimony, and other information need to be brought together to form the story, almost all of which is given to the viewer; however, until it is presented as a story, it barely makes sense.
One of the best examples of standardizing formatting occurs with time stamping. In Chapter 6, Network Security Data Analysis, we saw how Wireshark and tcpdump displayed different date and time stamps for the same PCAP file. The reason for this, and the reason that both systems were able to generate valid and reasonable results from the same data, is that human-readable date and time stamps are inefficient in terms of memory and processing; computers store dates, instead, as a number on a continuous scale, translating these numbers back to times and dates on demand.
A number of different time systems exist in the world. Calendars that have a different Year 0 include the Jewish calendar starting in 3761 BCE or the Japanese era names starting with each new emperor; various calendars (particularly lunar calendars) vary in year length. The common date/time systems in the computer domain are the Unix epoch time (counting seconds since 00:00 1 Jan 1970) and Windows GetSystemTimeAsFileTime (which counts 100-nanosecond intervals since 00:00 1 Jan 1601). Storing timestamps as integer values are much more efficient than in RFC 8601 (YY-MM-DD hh:mm:ss) format, which makes it perfect for log files, which may have thousands of entries very quickly.
The Unix (and Linux) CLI strftime command can be used to reformat the integer string from a Unix timestamp to human readable formats. The most common commands are strftime("%c",<time>) and strftime("%F",<time>), where %c denotes current locale representation, %F denotes RFC 8601 formatting, and <time> is the timestamp in Unix time. The awk command can be used to separate out the fields around a field separator (most commonly a comma (,), semicolon (;), space ( ), or pipe |).
In the following code, the awk command is used to separate the fields in a orig_log.csv ({FS=OFS=","}). The Unix time in the 2 ($2) field is then replaced (using the strftime function) with the RFC 8601 date (%F), and 24-hour time with seconds (%T), and outputting it to the new_log.csv file. For brevity, we have used a tail to show just the last five lines of the file on the screen. The awk command will have carried out the replacement on the entire contents of the original file:
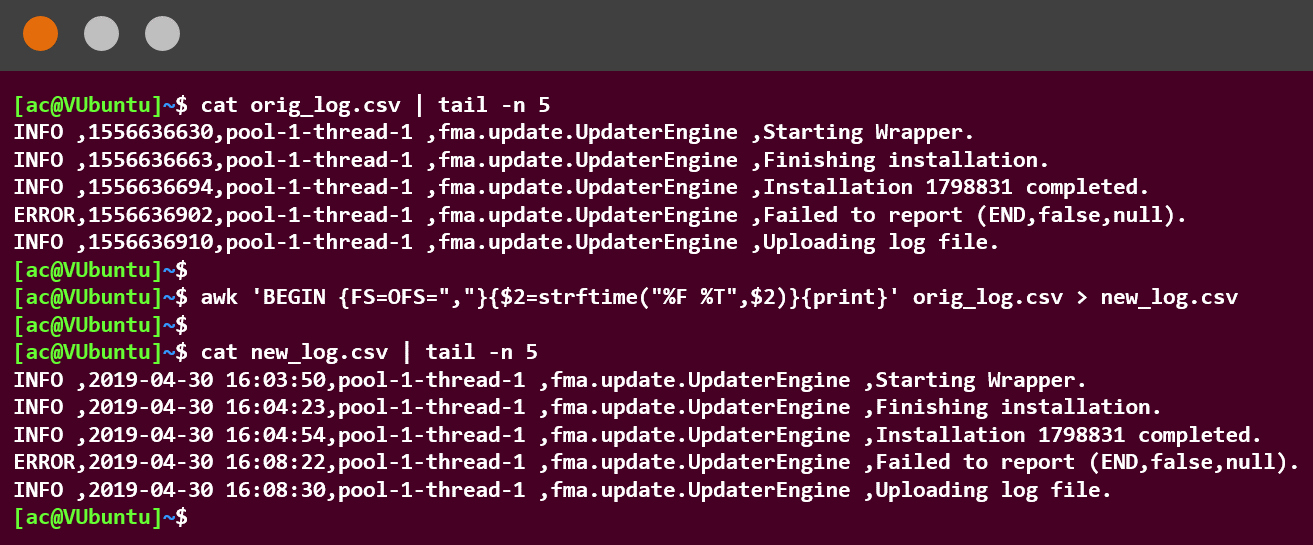
Time is just one of the many discrepancies that can appear between different system logs. In Chapter 4, Identifying Rogue Data from a Dataset, we also looked at the different MAC address representations. A similar process could be done here using pcregrep to remove any formatting in the source or to reformat it for the desired output.
Standardized formatting should be as generic as possible. As we have seen, the Unix epoch time can be converted into a number of different formats; a MAC address with no formatting or delimiters can be extracted into any number of formats as required.