
Chapter 7
Nucleic Acids in Chemical Sensors
Nucleic acids are essential compounds in all living organisms. They provide the means of storing and transferring genetic information. The determination of nucleic acid composition and content in biological samples is a key issue in biosciences and medicine. It is therefore not surprising that nucleic acid sensors are one of the main areas of the biosensor science and technology [1–4]. In such a sensor, nucleic acids can act as both receptors and analytes. Moreover, nucleic acids can also interact in a specific way with a number of small molecules and proteins. This property expands the field of application of nucleic acids as receptors in chemical sensors for such compounds. Applications of nucleic acid sensors encompass a very broad area including not only biomedical sciences but also environment monitoring, food industry and forensic science.
This chapter includes an overview of the main properties of nucleic acids as far as the chemical structure and reactivity are concerned. The applications of nucleic acids as recognition components in biosensors, as well as the transduction strategies in nucleic acid sensors are closely associated with the properties of these compounds. Transduction strategies and applications of nucleic acid sensors are considered later in the chapter.
7.1 Nucleic Acid Structure and Properties
Nucleic acids are biopolymers belonging to the polynucleotide class. The most common representative types of polynucleotide are the deoxyribonucleic acids (DNAs) and the ribonucleic acids (RNAs) that are involved in the storage and transfer of genetic information [5, 6]. Both DNAs and RNAs are polymeric compounds that incorporate nucleotides as basic units. The nucleotide unit consists of three structural fragments: a heterocyclic nucleobase bound to a pentose sugar molecule that in turn is attached to a phosphate residue via an ester linkage at the 5′ position on the sugar (see Figure 7.1A). The canon bases found in natural nucleic acids are adenine, guanine, cytosine thymine and uracil (Figure 7.1B). Adenine and guanine are purines, whereas cytosine thymine and uracil are pyrimidines. The first four bases occur in DNA; in RNA, uracil replaces thymine. In addition, a series of less-common nucleobases may occur in RNAs. An example of this kind is hypoxanthine (a purine derivative) that forms, in combination with a sugar, the inosine nucleoside.
Figure 7.1 (A) Structure of a nucleotide. X is H in DNA (2′-deoxyribose sugar) and OH in RNA (ribose sugar). (B) Natural nucleobases.
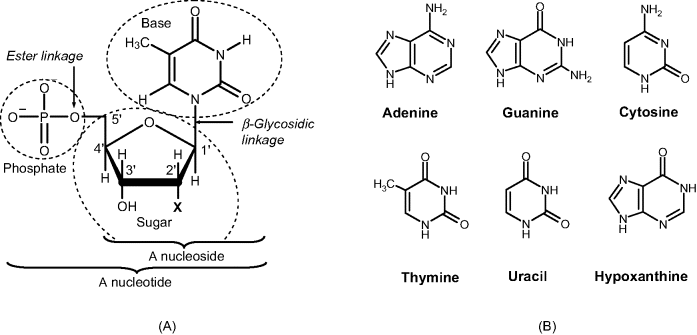
A key structural difference between DNAs and RNAs is apparent from their names. This difference is in the sugar component of each classes of polynucleotide; ribose is the sugar in RNA and 2′-deoxyribose is the sugar in DNA (Figure 7.1A). The sugar plus base combination forms a nucleoside. The sugar plus base plus phosphate combination is termed a nucleotide. Nucleotides are identified by the first letter (as a capital) in the name of the particular base (that is, A, G, C, T and U).
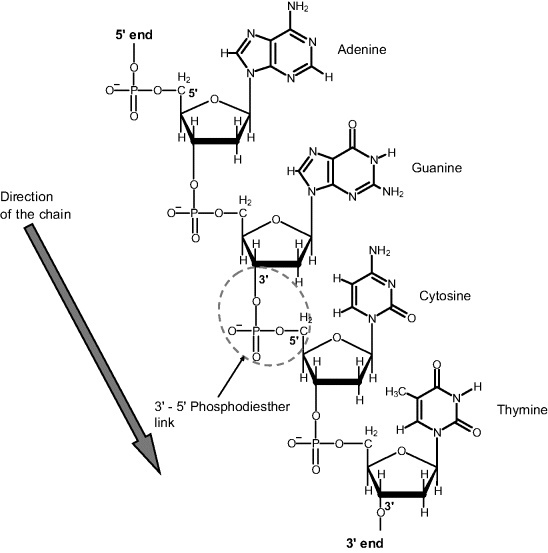
In the nucleic acid structure, nucleotides are associated in polymer chains through intermediate phosphate residues attached to 3′ and 5′ carbons in the sugar moiety (Figure 7.2). By convention, the direction of the chain is recorded from the 5′ to the 3′ end as shown by the arrow in Figure 7.2. This sequence of nucleobases in a polynucleotide gives the primary structure of a nucleic acid. Shorthand notation of the primary structure consists of the sequence of nucleotide acronyms (starting from the 5′ end) proceeded by the symbol d or r for DNA and RNA, respectively. Sometimes, the symbol p is inserted between base symbols to denote the phosphate linkage. Thus, a single-strand structures (ss-nucleic acid) can be symbolized as:
Figure 7.2 A polynucleotide chain (DNA primary structure).
or more simply as:
Two complementary polynucleotide chains can form a duplex by association involving hydrogen bonds between A–T and C–G pairs (Watson–Crick model) as shown in Figure 7.3A. The set of interactions between complementary bases gives the secondary structure of a nucleic acid. Base pairing produces a double strand (ds) that folds into a double helix (Figure 7.3B), which is the typical conformation of DNA. An antiparallel double-strand sequence (ds-nucleic acid) can be symbolized as follows:
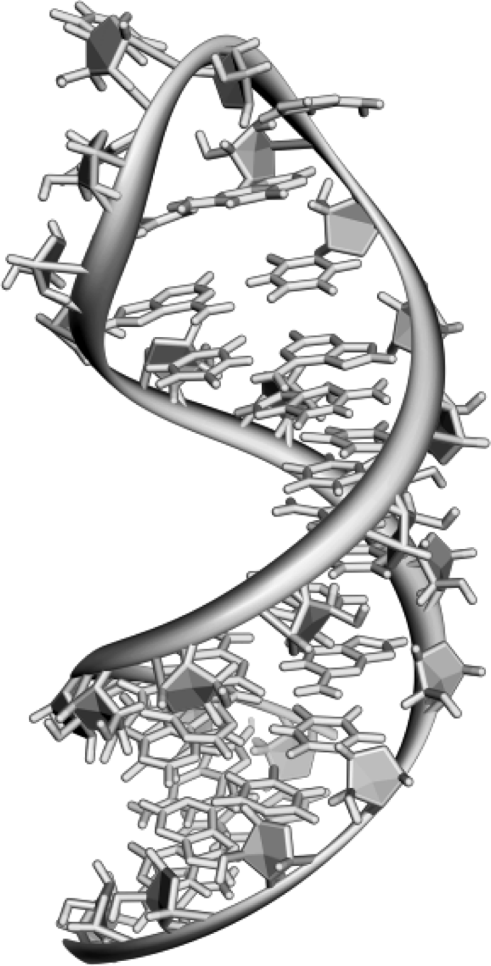
Polynucleotides can adopt a large variety of conformations involving double-strand association. On the other hand, a single polynucleotide strand can fold into a specific conformation stabilized by intramolecular hydrogen bonds according to the Watson–Crick model. This is exemplified in Figure 7.4 that displays a hairpin conformation. The conformation of the nucleic acid molecule in three-dimensional space forms the tertiary structure. Particular features in the tertiary structure are minor and major grooves (Figure 7.3B) that play an essential role in supramolecular interactions of nucleic acids with proteins or small molecules leading to mixed adducts stabilized by shape fitting and noncovalent bonds.
Figure 7.3 Structure of DNA. (A) Association of two identical polynucleotide strands in DNA. Dotted lines represent hydrogen bonds between nucleobases. Note the opposite orientation of the strands. (B) Schematics of the DNA double helix with the sugar–phosphate (S-P) backbones shown as ribbons. (A) Adapted from http://commons.wikimedia.org/wiki/File:DNA_chemical_structure.svg Last accessed 17/05/2012. Credit Madeleine Price Ball.
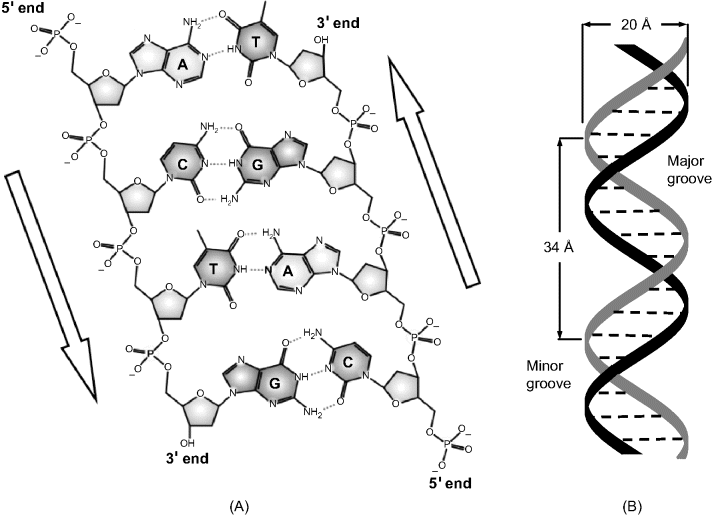
Figure 7.4 A hairpin loop from a pre-mRNA. Note that some nucleobases are not paired. Adapted from http://commons.wikimedia.org/wiki/File:Pre-mRNA-1ysv.png-tubes.png Last accessed 17/05/2012.
{kind=link}
Owing to the negative charge at the phosphate moieties in the nucleic acid chain, polynucleotides are polyanions. For this reason, cations such as Na+ and Mg2+ are essential for stabilizing the structure.
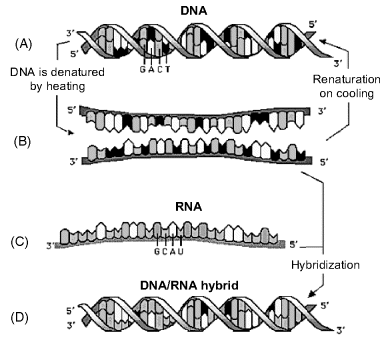
When DNA duplex molecules are subjected to extreme conditions of temperature or pH, the hydrogen bonds of the double helix are cleaved and the two strands separate from each other in a process called denaturation. When heat is used to this end, the DNA is said to melt; this process occurs at a specific melting temperature ![]() that is, by definition, the temperature at which only 50% of DNA is present in the duplex form. If the conditions change back to the natural parameters, two DNA strands may reassociate to restore the double helix. Denaturation–renaturation processes can also occur with single-strand tertiary structures.
that is, by definition, the temperature at which only 50% of DNA is present in the duplex form. If the conditions change back to the natural parameters, two DNA strands may reassociate to restore the double helix. Denaturation–renaturation processes can also occur with single-strand tertiary structures.
Nucleic acids are the means by which genetic information is stored and transferred in living cells. The cell uses the sequence of nucleic acids (or more exactly the sequence of bases) to produce a sequence of amino acids in order to construct a particular protein that the cell needs. In other words, the primary structure of each protein is encoded by a nucleic acid fragment called gene. In a gene, each amino acid is indicated by a sequence of three nucleobases (a codon). The structure of a particular gene may vary slightly from individual to individual in a given species. Each particular form of a gene is called an allele. Hair color, for example, is encrypted in an allele that is specific to each individual and display only minute deviation from the similar allele of another individual.
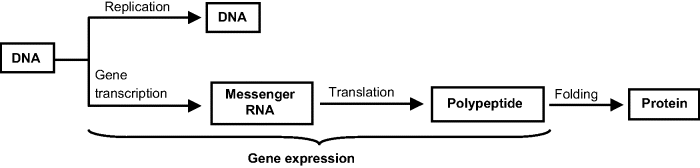
Genetic information is stored in DNA molecules that are found in complex combination with proteins (chromatin) that make up chromosomes. Each gene is located at a particular site, termed the locus, along the chromosome. During cell reproduction, DNA molecules are replicated to produce identical DNA molecules in other cells. Protein synthesis, on the other hand, occurs in ribosomes under the control of messenger RNA (mRNA) that is synthesized as a replica of the relevant gene in DNA (transcription) before traveling to the ribosome. Conversion of genetic information from the codon language to the amino acid sequence during protein biosynthesis is called translation. The mechanism of transfer of genetic information is summarized in Figure 7.5. The process of protein biosynthesis under the control of genetic information is known as gene expression.
Figure 7.5 Mechanism of transfer of genetic information.
Polynucleotides are available for use in sensors from various natural sources. However, for many applications, custom-made oligonucleotides are required and are prepared automatically by solid-phase synthesis [7]. In this technique, a nucleotide is first covalently linked to a solid support (such as controlled-pore glass or macroporous polystyrene) and then chain elongation is carried out by assembling further nucleotides according to a predetermined sequence. Finally, the olygonucleotide is released by the cleavage of its bond to the support. This technique can be used to produce immobilized polynucleotides directly at the surface of a transducer.
7.2 Nucleic Acid Analogs
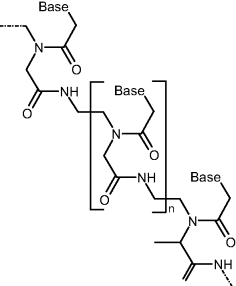
In addition to natural nucleic acids, medicine and molecular biology research make use of synthetic nucleic acid analogs [8]. Such an analog may include one or more of the natural components of a nucleic acid altered. Thus, in peptide nucleic acids (PNAs), the phosphate–sugar backbone is replaced by a polypeptide chain to which nucleobases are linked by methylene carbonyl bonds (Figure 7.6). Despite the different backbone structure, such compounds can bind according to the Watson–Crick model. Since the backbone of PNAs contain no charged phosphate groups, the binding between PNA/DNA strands is stronger than between DNA/DNA ones owing to the lack of electrostatic repulsion. This brings about a higher melting temperature than that of the natural analog.
Figure 7.6 Structure of peptide nucleic acids (PNAs).
Hydrogen bonds in nucleobase pairs can be replaced by coordinated metal ion bridges such as T–Hg–T, A–Zn–T and G–Zn–C if the pH is sufficiently high to stimulate base deprotonation at the binding site. This allows the formation of additional linkages between bases that do not match the Watson–Crick model and led to development of metal ion sensors using nucleobases or oligonucleotides as receptors.
Nucleic acid analogs can be synthesized by inserting noncanon nucleobases. This confers different base pairing and base stacking properties. Examples of this kind include trivial nucleobases, which can pair with all canon bases.
7.3 Nucleic Acids as Receptors in Recognition Processes
7.3.1 Hybridization: Polynucleotide Recognition
An oligonucleotide can be used as the receptor for the recognition of a complementary strand by a process called hybridization (Figure 7.7) [9, 10]. To this end, the recognition component (a hybridization capture probe) is attached to a solid support and incubated with a sample containing the target polynucleotide in the form of a single strand. A perfect match of the target–probe couple leads to the formation of a very stable duplex. Any mismatch results in a less-stable duplex. A properly selected probe of about 25 nucleotides length can recognize specifically very long polynucleotides. Compared with a very long probe, a short probe has the advantage of a much faster hybridization. Moreover, long olygonucleotide probes tend to fold over themselves, which impedes the hybridization process. At the same time, a longer probe is more selective as it binds to a longer sequence in the target. The introduction of four-to-six mismatches between the sensing interface and the target nucleic acid is sufficient to prevent hybridization and discriminates against a mutant. Ideally, one single mismatch should be sufficient for detecting a mutant.
Figure 7.7 Thermal denaturation of a DNA duplex and hybridization with a complementary RNA sequence. (A) Double strand DNA; (B) two single-strand DNAs; (C) complementary RNA; (D) DNA–RNA hybrid. Adapted with permission from [11] by courtesy of Ewa Paszek. Last accessed 3/05/2012.
For hybridization to occur it is essential to maintain the probe strand oriented perpendicularly to the support surface. Hydrophobic or positively charged surfaces promote a parallel orientation by interaction with the nucleobases or the backbone, respectively. Conversely, negatively charged surfaces compel the probe by electrostatic repulsion to adopt a perpendicular orientation to the support surface.
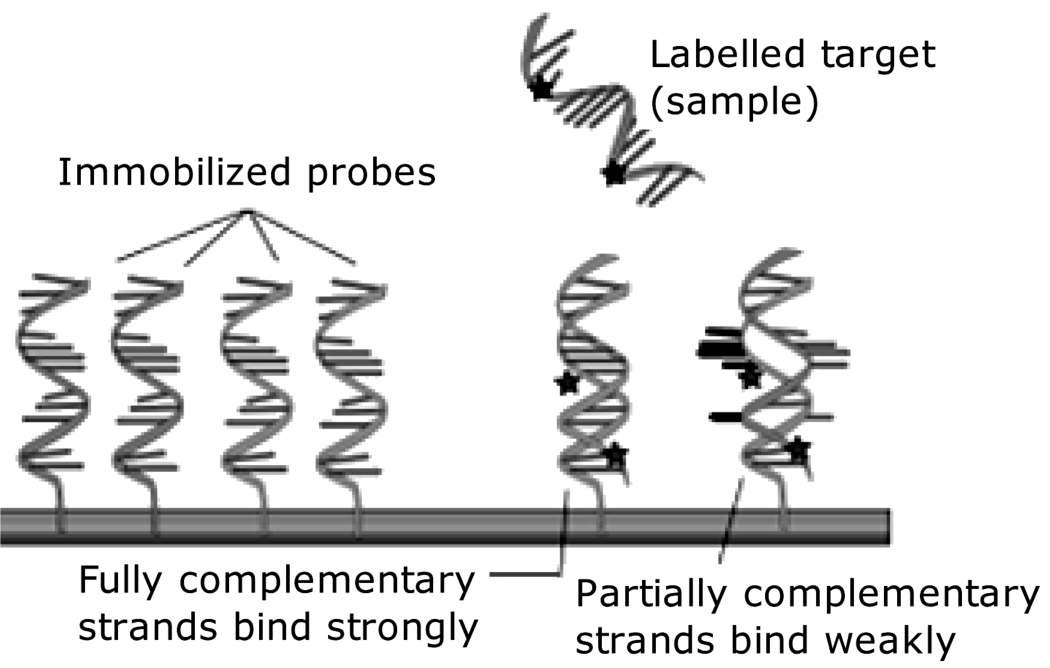
The hybridization event can be detected by means of a physical effect, such as mass change or modifications in the optical properties of the interface. Alternatively, indirect transduction can be carried out by means of a tag such as a fluorescent or electrochemically active compound that is brought by hybridization to be within the active region of the transducer (Figure 7.8).
Figure 7.8 Hybridization of a target polynucleotide with a surface-immobilized probe and transduction by means of a reporter tag. Adapted from http://en.wikipedia.org/wiki/File:NA_hybrid.svg Last accessed 17/05/2012.
The throughput of a hybridization assay depends on the reaction velocity. As hybridization at surface-attached probes involves prior target diffusion, this process dictates the overall reaction rate at low target concentrations. In this case, hybrid formation obeys the first-order Langmuir model:
(7.1) ![]()
where t is the time, ![]() is the surface concentration of the hybrid,
is the surface concentration of the hybrid, ![]() is the limiting
is the limiting ![]() (at infinite time) and
(at infinite time) and ![]() , c being the target concentration and D its diffusion coefficient.
, c being the target concentration and D its diffusion coefficient.
For hybridization to occur, the temperature should be below the melting temperature. The melting temperature depends on DNA sequence and length, cation concentration, target concentration, and the presence of denaturants (formamide or DMSO).
Any mismatch causes the melting temperature of the hybrid (![]() ) to be lower that that of a faultless double strand (
) to be lower that that of a faultless double strand (![]() ). In order to detect the latter, transduction should be performed at an intermediate temperature between
). In order to detect the latter, transduction should be performed at an intermediate temperature between ![]() and
and ![]() .
.
Hybridization can be accompanied by nonspecific adsorption of the target to the support material that gives rise to a background response. This problem can be alleviated by adding a mixture of high molecular weight polymers (Denhardt's solution) capable of saturating nonspecific binding sites at the solid support.
A high cation concentration is essential in hybridization assays in order to lessen the electrostatic repulsion between polynucleotide strands. When using peptide nucleic acids, the cation effect is less important.
Hybridization is a relatively slow process because it involves multiple site interactions of two oligonucleotides, accompanied by a radical change in molecular configuration. If the probe is immobilized at a solid support, diffusion of the target to the surface introduces an additional kinetic restriction. Moreover, the restricted mobility of the immobilized probe results in a marked sluggishness of the hybridization process compared with the process occurring in a homogeneous phase. In order to give the probe some freedom of movement, it is recommended to attach it to the surface through a long and flexible spacer arm. The hybridization rate is therefore the main limiting factor as far as the response time of the DNA sensor is concerned. The response time can be a few minutes under well-optimized conditions, but it can be a few hours in some cases, particularly at very low target concentrations.
If the sensor is exposed to crude cell extracts, care should be taken in order to avoid oligonucleotide decay by nuclease-catalyzed hydrolysis. A nuclease is an endogenous enzyme capable of cleaving the phosphodiester bonds between the nucleotide subunits of nucleic acids. RNA becomes nuclease resistant if the 2′ hydroxyl is methylated or substituted by fluoride. Another method for preventing nuclease degradation relies on substituting the phosphate in the backbone by phosphorothioate in which nonbridging oxygens are replaced by sulfur. This modification renders the internucleotide linkage resistant to nuclease degradation.
PNA probes are often more convenient that their DNA counterparts. As a PNA probe is neutral, it can function at a lower cation concentration. For the same reason, under similar conditions a PNA–DNA duplex is more stable than the DNA–DNA analog and, consequently a shorter PNA probe may give rise to a sufficiently stable hybrid. Moreover, the greater stability of the PNA–DNA duplex allows hybridization to be effected at higher temperatures, to induce a higher reaction rate. In addition, peptide nucleic acids that are missing phosphodiester bonds are immune to nuclease degradation.
Hybridization sensors can be used to reveal mutant genes associated with genetically determined diseases. This is because genetic mutations result in mismatching in the hybridization process. Another application of hybridization consists of identifying pathogen micro-organisms in water supplies, foodstuffs and biological samples. In such an assay, a pathogen can be detected by means of its specific nucleic acids. Similarly, genetically modified organisms can be detected by means of hybridization of a probe with a specific sequence in the target [12].
7.3.2 Recognition of Non-Nucleotide Compounds
Non-nucleotide molecules can interact with nucleic acids by noncovalent bonding to produce relatively stable adducts. This process may disturb the DNA function (that is, storage and transfer of genetic information) and is widely used in therapy of cancer or viral diseases or for disinfection purposes. Similar processes can be employed advantageously in order to perform recognition of non-nucleotide compounds in chemical sensors based on nucleic acid receptors.
Small molecules can form adducts with DNA by intercalation. Intercalation occurs when ligands of an appropriate size and chemical nature fit themselves in between base pairs of DNA (Figure 7.9A) [13]. Optimum intercalation occurs with planar, polycyclic molecules bearing a positive charge (for example, proflavine, Figure 7.9B). Intercalation proceeds as follows. In aqueous isotonic solution, the cationic intercalator is attracted electrostatically to the polyanionic DNA. The ligand displaces a cation (that is balancing the DNA charge) and forms a weak electrostatic bond with the outer surface of the DNA. From this position, the ligand may then slide into the hydrophobic environment found between the base pairs and away from the hydrophilic outer environment surrounding the DNA. The ensuing conformation is stabilized by hydrogen bonds and van der Waals interactions between the planar ligand and the base pairs around it.
Figure 7.9 (A) Intercalative binding of a small molecule (ligand) into the DNA helix. (B) Intercalating organic molecules: proflavine, daunomycin (R = H) and doxorubicin (R = OH). (C) Two daunomycin molecules intercalated in a d(CGATCG) duplex. The upper part shows the planar, polycyclic moiety of the molecule inserted between two base pairs with the lateral ring accommodated in a minor groove. (A) Adapted from http://commons.wikimedia.org/wiki/File:DNA_intercalation.svg Last accessed 17/05/2012. (C) Adapted from http://www.rcsb.org/pdb/explore/explore.do?structureId=1da0 Last accessed 15/05/2012.
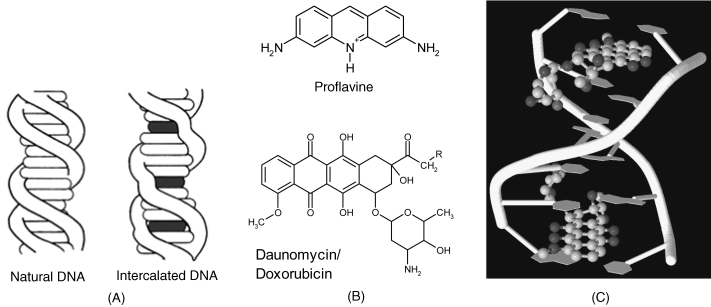
As a result of intercalation, the helix expands because the distance between the bases pairs on either side of the ligand increases. This brings about a slight alteration in the helical twist (Figure 7.9A).
A small intercalator can be selected so as to be either electrochemically active or optically detectable. It can therefore be used as a label tag for detecting the DNA duplex.
More voluminous and asymmetrical molecules can be accommodated in DNA grooves where they are stabilized by van der Waals interactions and, in addition, by hydrogen bonds with adjacent bases, allowing site-selective interaction. Figure 7.9C demonstrates the binding of daunomycin (an anticancer drug shown in Figure 7.9B) that combines intercalation and minor groove interactions.
A number of metal chelates recognize specific sites in DNA by intercalation of the planar fragment, whilst the bulky nonplanar moiety of the complex fits closely against the walls and floor of a major groove [14]. Such complexes can act as optical or electrochemical indicators for nucleic acids.
Many drugs, as well as mutagenic pollutants perform as DNA intercalating compounds. Intercalation can therefore be employed for recognizing such analytes and allows the development of DNA sensors for these classes of substances [15]. In addition, intercalation has proved useful for attaching transduction tags to ds-nucleic acids.
7.3.3 Recognition by Nucleic Acid Aptamers
Nucleic acid aptamers are synthetic nucleic acids that manifest selective affinity for proteins or some small molecule compounds. The name of this class of compounds has been derived from the Latin ![]() (meaning. “fitted”) and the Greek
(meaning. “fitted”) and the Greek ![]() (meaning “part”). Such compounds are being actively investigated for therapeutic applications [16, 17]. At the same time, the high affinity of aptamers for specific analytes make them very useful as receptors in a series of analytical applications including biosensor development [18–21].
(meaning “part”). Such compounds are being actively investigated for therapeutic applications [16, 17]. At the same time, the high affinity of aptamers for specific analytes make them very useful as receptors in a series of analytical applications including biosensor development [18–21].
The design of aptamers is done by an automatic combinatorial procedure (systematic evolution of ligands by exponential enrichment (SELEX)), which is a trial and error method. This process begins with the synthesis of a very large library of oligonucleotides consisting of randomly generated sequences of fixed length flanked by constant 5′ and 3′ ends that serve as primers. For a randomly generated sequence including n nucleotides, the number of possible sequences in the library is ![]() . The sequences in the library are exposed to the target ligand and those that do not bind the target are removed. The bound sequences are separated and multiplied to prepare for subsequent rounds of selection in which the stringency of the separation conditions is increased in order to identify the tightest-binding sequences.
. The sequences in the library are exposed to the target ligand and those that do not bind the target are removed. The bound sequences are separated and multiplied to prepare for subsequent rounds of selection in which the stringency of the separation conditions is increased in order to identify the tightest-binding sequences.
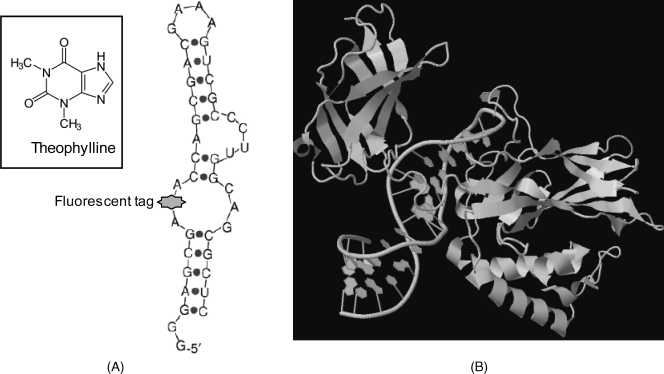
Aptamers are tailored so as to develop by folding a specific binding site for the target compound. As an example Figure 7.10A shows an aptamer with affinity to the small molecule of theophylline, a drug used in therapy of respiratory diseases. This figure demonstrates that a functional tag can be inserted readily in the aptamer molecule at the most convenient site. Small molecules are accommodated as a rule in a pocket, shaped by aptamer folding. Figure 7.10B displays the complex of an RNA aptamer with a protein (NF-kappaB p50 transcription factor). The aptamer molecule binds to the p50 N-terminal domain of the protein due to its particular secondary structure. Thus, the guanines, placed at the edge of the helix, together with the major groove, form the binding surface for the protein.
Figure 7.10 Examples of aptamers. (A) An antitheophylline aptamer. A site-specific fluorescent tag is inserted in the backbone by phosphodiesther links. (B) Structure of a protein–RNA aptamer complex. The aptamer in the hairpin configuration binds to the NF-kappaB p50 transcription factor protein. (A) Adapted with permission from [17]. Copyright 2006 Elsevier; (B) Adapted from pdb1ooa. (B) Adapted from http://www.rcsb.org/pdb/explore/explore.do?structureId=1OOA Last accessed 15/05/2012.
Aptamers are useful in affinity sensors in which they play a role similar to that of antibodies. However, when compared with antibodies, aptamers demonstrate a series of advantages. Aptamers can be obtained by chemical synthesis and are less expensive. They are more stable than antibodies and can be easily modified and immobilized on a solid support. After performing the recognition function, an aptamer can be efficiently regenerated without loss of either integrity or selectivity.
Aptamer selectivity for a selected target is expressed by the dissociation constant of the complex. This was found to be below 10−6 M for some thrombin aptamers, which demonstrates a huge stability of the aptamer–protein complex, comparable with that of an antigen–antibody conjugate.
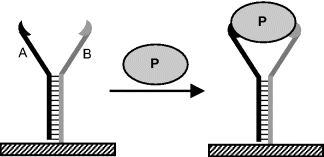
Like monoclonal antibodies, aptamers can be prepared in epitope-selective form and by this means different aptamers for the same target molecules become available. For example, Figure 7.11 shows two aptamers partially hybridized and bearing on each arm an epitope-specific binding site. A protein molecule can be attached to both aptamer arms, which results in enhanced selectivity and better stability of the complex. The term aptabody was proposed to denote a duplex oligonucleotides that binds to two different sites of the target molecule [22].
Figure 7.11 Schematic representation of protein binding by two partially hybridized epitope selective aptamers (A and B).
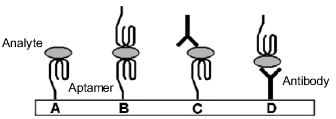
Aptamer-analyte recognition can be approached in several ways, as emphasized in Figure 7.12. Note that aptamers and antibodies can be used jointly in the sandwich format, as both of them act as affinity reagents. An overview of aptamer sensor design is presented in ref. [23].
Figure 7.12 Possible configurations of aptamer-based sensors. (A) single-site format; (B) dual-site (sandwich) format with two aptamers; (C) and (D) mixed sandwich format with an a aptamer and an antibody. Adapted with permission from [24]. Copyright 2009 Wiley-VCH Verlag GmBH & Co. KGaA.
Aptamers are therefore promising substitutes, or complements for antibodies in affinity sensors. Aptamers demonstrate some advantages in this respect. Thus, they can be readily synthesized in crude or modified form. Compared with antibodies, aptamers are more stable, are more resistant to multiple analysis–regeneration cycles, and show a lower propensity to nonspecific binding. RNA aptamers can decay in contact with biological samples by nuclease-catalyzed cleavage. Substitution of –OH at the 2′ position of the sugar by fluoride or amino groups stabilizes the oligonucleotide against this reaction.
7.4 Immobilization of Nucleic Acids
Probe immobilization is a crucial step in manufacturing DNA chips [25] and methods developed to this end are also applicable in the fabrication of DNA sensors [26, 27]. Adsorption, covalent linking, chemisorption at surfaces or affinity reactions are the most common methods for attaching nucleic acid probes to a solid surface. Various materials such as polymers (polystyrene, polyacrylamide, nylon), inorganic materials (glass, carbon, gold) and bio-organic products (cellulose, chitosan) have been used as supports for probe immobilization. Immobilization of aptamers can be performed by similar methods [28].
An alternative to the immobilization of a preformed probe is the direct synthesis of the probe on the transducer surface. This approach is less time consuming but purification of the product as well as conventional purity assessment cannot be achieved in this case.
7.4.1 Adsorption
Adsorption is a facile method for attaching nucleic acids to surfaces since no reagents or modified polynucleotides are required. Although various noncovalent interactions could contribute to probe adsorption, electrostatic attraction between a positively charged surface and the negative adsorbate backbone is the most common procedure. Thus, a ![]() functionalized solid support binds oligonucleotides in an almost parallel orientation to the surface by electrostatic interactions involving multiple phosphate residues. If a positively charged gel is attached to the support, oligonucleotides bind by incorporation of a terminal phosphate residue in the gel and adopt an almost perpendicular orientation to the surface.
functionalized solid support binds oligonucleotides in an almost parallel orientation to the surface by electrostatic interactions involving multiple phosphate residues. If a positively charged gel is attached to the support, oligonucleotides bind by incorporation of a terminal phosphate residue in the gel and adopt an almost perpendicular orientation to the surface.
Much attention has been paid to adsorption at carbon materials for the purpose of fabricating electrochemical DNA sensors [27, 29]. Various bare carbon materials (such as glassy carbon and pyrolytic graphite), composite carbon materials (such as carbon paste, rigid carbon composites [30] or screen-printed supports [31]) have been investigated to this end.
Adsorption of a single-strand sequence at glassy carbon is triggered by hydrophobic interaction of free bases with the surface. Conversely, a double-strand form is poorly adsorbed because its bases are hidden in the double-helix structure. As a rule, carbon electrodes are subject to energetic oxidation prior to adsorption in order to create oxygenated functionalities (–OH; ![]() ) that enhance the adsorption by hydrogen bonding. Performing adsorption at a positively polarized electrode also contributes to increasing the surface coverage by electrostatic interaction with the oligonucleotide backbone.
) that enhance the adsorption by hydrogen bonding. Performing adsorption at a positively polarized electrode also contributes to increasing the surface coverage by electrostatic interaction with the oligonucleotide backbone.
Adsorption yields a layer of sparsely bound molecules that do not resist thorough washing steps that are required to remove mismatched sequences. In addition, most of the immobilized probe lies in a position that is not favorable to hybridization causing this process to be relatively inefficient. Despite these inconveniencies, adsorption is considered as a promising immobilization method, particularly in conjunction with mass fabrication of disposable screen-printed sensors. The intrinsically poor sensitivity of such sensors can be ameliorated by prior polymerase chain reaction (Section 7.5.3).
7.4.2 Immobilization by Self-Assembly
This method is based on the spontaneous reaction of the thiol group with gold to form a strong S–Au bond [32, 33]; see also section 5.4.8). The sulfur-containing nucleotides are often supplied in the form of disulfides (for example, ![]() ) to avoid thiol degradation before use. Prior to probe chemisorption, the disulfide linkage must be cleaved by reduction with dithiothreitol. As a rule, probe immobilization is followed by chemisorption of a mercapto-alcohol (for example, mercaptohexanol, Figure 7.13). The latter process prevents nonspecific adsorption of oligonucleotides and blocks the access of interferents to the transducer surface. Such sensors should be used with caution at elevated temperatures where the sulfur–gold bond becomes weak.
) to avoid thiol degradation before use. Prior to probe chemisorption, the disulfide linkage must be cleaved by reduction with dithiothreitol. As a rule, probe immobilization is followed by chemisorption of a mercapto-alcohol (for example, mercaptohexanol, Figure 7.13). The latter process prevents nonspecific adsorption of oligonucleotides and blocks the access of interferents to the transducer surface. Such sensors should be used with caution at elevated temperatures where the sulfur–gold bond becomes weak.
Figure 7.13 Immobilization of an oligonucleotide probe by self-assembly at a gold surface. Adapted with permission from [28]. Copyright 2000 Elsevier.
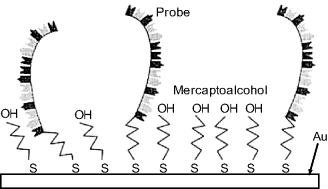
Sulfur–gold self-assembly enables a single-point attachment of the probe that gives it conformational mobility that, in turn, results in a relatively high hybridization velocity.
Probe immobilization by thiol self-assembly is a very popular immobilization method due to its simplicity, and because gold layers are widely used in various kinds of chemical sensors.
7.4.3 Immobilization by Polymerization
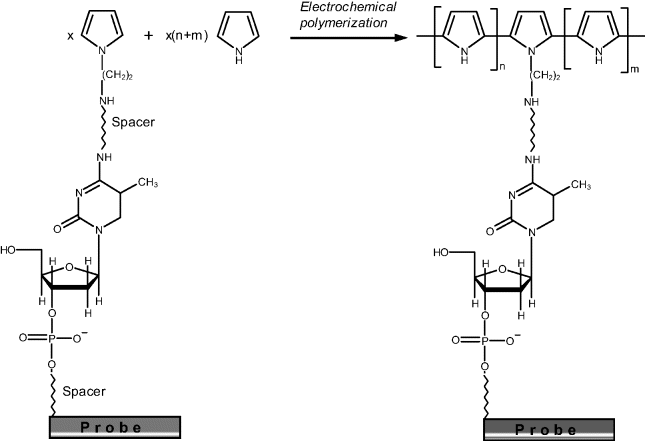
Oligonucleotides can be incorporated into a polypyrrole layer at a carbon electrode by electrochemical polymerization of pyrrole. As the polymer backbone has a positive charge, oligonucleotides bind electrostatically as a counteranion. As an alternative to the electrostatic binding, covalent linking of the probe to the polymer backbone can be achieved by copolymerization of pyrrole with pyrrole-grafted probe molecules. This technique is outlined in Figure 7.14. Polymerization is conducted at high pyrrole monomer excess (n + m = 20 000) in order to allow the probe enough mobility. This method is suited for one-step spotting on continuous conducting surfaces (gold, silicon) or on individually addressable conducting spots [34].
Figure 7.14 Grafting of a nucleic acid probe on a polypyrrole chain. Adapted with permission from [36]. Copyright 2004 Oxford University Press.
Oligonucleotide probes have also been incorporated in redox hydrogels in order to allow an enzyme tag to exchange electrons with the underlying electrode. Care should be taken in this case to allow the probe sufficient mobility in order to react efficiently in the hybridization step.
7.4.4 Covalent Immobilization on Functionalized Surfaces
Covalent coupling of probes to a solid support may be time consuming and costly but it results in a rugged recognition layer that is suitable for multiple use. This method often requires prior formation of suitable functional groups on the support surface in order to perform further crosslinking of the probe. The most common groups for covalent immobilization of nucleic acids are carboxyl, amine and hydroxyl. Thus, carbon surfaces can be functionalized with carboxyl groups by energetic oxidation with a nitric acid and potassium dichromate mixture. Silicon, glass and carbon surfaces can be modified with organosilanes bearing various functionalities that are susceptible to crosslinking. So, materials with exposed hydroxyls at the surface (glass, cellulose, pretreated carbon) can be modified with amine groups by reaction with an aminosilane (for example, APTES, ![]() ). A similar treatment can be applied to silicon surfaces after preparing a silicon oxide layer by oxidation and hydrolysis to yield hydroxyl groups. Gold and indium-tin oxide can be modified by self-assembly of functionalized thiols containing a reactive group at the distal end. For example, gold surfaces can be modified with amine groups by self-assembly of an amino-thiol (
). A similar treatment can be applied to silicon surfaces after preparing a silicon oxide layer by oxidation and hydrolysis to yield hydroxyl groups. Gold and indium-tin oxide can be modified by self-assembly of functionalized thiols containing a reactive group at the distal end. For example, gold surfaces can be modified with amine groups by self-assembly of an amino-thiol (![]() ). A functionalized polymer layer can be prepared by electrochemical copolymerization of pyrrole and a pyrrole derivative containing a linker (e.g., 3-carboxypyrrole).
). A functionalized polymer layer can be prepared by electrochemical copolymerization of pyrrole and a pyrrole derivative containing a linker (e.g., 3-carboxypyrrole).
As far as the binding site in the probe is concerned, it can be a pre-existing group, such as the 5′ end phosphate residue or an exocyclic amine group in guanine. Often, the probe is synthesized so as to include a linking end, such as an amine or a short guanine sequence.
Figure 7.15A shows the coupling of the phosphate end to an amine-derivatized support through carbodiimide activation to yield a phosphoramide linking. Such a reaction is conducted in the presence of methylimidazole and N-hydroxy-succinimide (NHS) as stabilizers of intermediate products.
Figure 7.15 Covalent immobilization of a probe to a functionalized support. (A) Probe coupling to a ![]() functionalized support. (B) Coupling to a carboxyl-modified support. (C) Coupling to a hydroxyl-functionalized support.
functionalized support. (B) Coupling to a carboxyl-modified support. (C) Coupling to a hydroxyl-functionalized support.
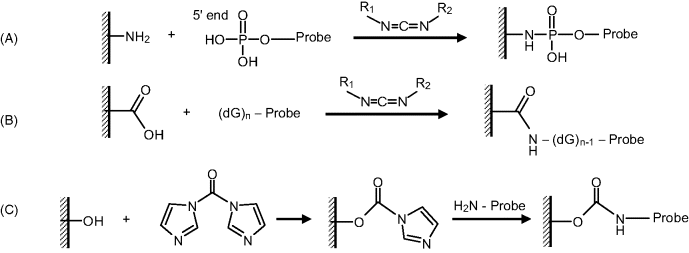
Covalent coupling to a carboxyl functionalized surfaces through guanine linkage is shown in Figure 7.15B. This method also makes use of carbodiimide activation and works equally well with amine-tethered probes.
Coupling of an amine-tethered probe to a hydroxyl-modified surface can be achieved in the presence of carbonyldiimidazole (CDI) as shown in Figure 7.15C.
7.4.5 Coupling by Affinity Reactions
The outstanding stability of the avidin–biotin linkage is the basis of a general procedure for assembling DNA sensors [36]. In this immobilization method, a biotinylated oligonucleotide probe is grafted to surface-linked avidin or strepavidin. However, the protein layer at the surface may induce nonspecific binding with negative effects on the sensitivity and the selectivity of some sensors. Biotin can be immobilized by any of the general methods for protein immobilization. It is also possible to synthesize biotin-tethered thioalkanes or pyrrole monomers for immobilization by chemisorption or gold or electropolymerization, respectively. Avidin–biotin interaction is also frequently used for obtaining oligonucleotide–enzyme conjugates in which the enzyme functions as a reactive hybridization reporter.
7.4.6 Polynucleotides–Nanoparticles Hybrids
Nanoparticles are widely used in nucleic acid sensor research either as label tags, structural components, or for other purposes [37, 38]. Conjugation of nucleic acids with properly functionalized nanoparticles can, as a rule, be achieved using the immobilization methods described above. Metal nanoparticles, semiconductor nanoparticles, carbon nanotubes and magnetic nanoparticle are among the nanomaterials currently investigated for applications in nucleic acid sensors.
Gold nanoparticles provide various possibilities for improving genetic assays either as supports for probe–target hybridization, as optical labels or as catalytic centers for chemical amplification [39, 40]. Chemisorption of thiol-tethered probes allows straightforward immobilization on gold nanoparticles. As an alternative, gold nanoparticles can be functionalized first with biotin or an amine in view of further crosslinking of the probe by pertinent reactions.
Binding of amine-tethered nucleic acids to carbon nanotubes can be achieved by crosslinking to carboxyl groups at the nanotube terminus by means of carbodiimide activation. Vertically aligned carbon nanotubes allow the achievement of optimum spatial arrangement of nucleic acid probes for DNA arrays and sensors. A high density of probe molecules is achieved by immobilization at multiwalled carbon nanotubes that display multiple binding sites at the terminus.
Attaching nucleic acids to magnetic nanoparticles allows facile separation, concentration purification, and identification by the effect of a magnetic field. In order to attach nucleic acids to pure magnetite or silica-coated magnetite, nanoparticles will be first functionalized with an ![]() linker by reaction with an aminosilane. Next, glutaraldehyde is used for attaching an amine-derivatized nucleic acid. Alternatively, magnetic nanoparticles can be functionalized with avidin in view of the avidin–biotin linking of the nucleic acid.
linker by reaction with an aminosilane. Next, glutaraldehyde is used for attaching an amine-derivatized nucleic acid. Alternatively, magnetic nanoparticles can be functionalized with avidin in view of the avidin–biotin linking of the nucleic acid.
7.5 Transduction Methods in Nucleic Acids Sensors
Recognition by nucleic acid receptors is essentially an affinity reaction. It is therefore not surprising that the transduction procedures used in conjunction with nucleic acid recognition are rather similar to those encountered in immunosensors. By the same reason, the response function of DNA sensors is similar to that of noncompetition immunosensors in that it displays a saturation trend at high analyte concentration.
7.5.1 Label-Free Transduction Methods
As in the case of standard affinity sensors, changes in the physical state of the recognition layer as a result of the recognition process can be used for direct, label-free transduction. Thus, a mass change can be detected by means of mass-sensitive transducers, whereas alteration in some optical properties (for example, the refractive index) can be detected by optical methods. A series of label-free transduction methods rely on the intrinsic electrochemical activity of nucleobases in nucleic acids.
Since both the nucleic acid probe and target are polyanions, their hybridization on an electrode enhances the surface negative charge that repels anionic redox probes such as ![]() . Electrostatic repulsion inhibits the electrochemical reaction of the redox probe and enhances in this way the electron-transfer resistance, which can be monitored by electrochemical impedance spectrometry [41].
. Electrostatic repulsion inhibits the electrochemical reaction of the redox probe and enhances in this way the electron-transfer resistance, which can be monitored by electrochemical impedance spectrometry [41].
7.5.2 Label-Based Transduction
Transduction tags of various types are widely used in nucleic acids sensors for indirect detection by means of optical or electrochemical methods. Several label-based transduction strategies for hybridization sensors are given next.
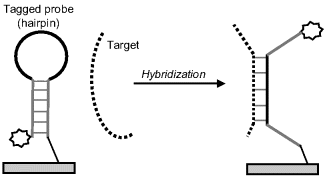
Some procedures rely on selective linking of a signaling tag to the hybrid resulting from the recognition step. Thus, Figure 7.16 demonstrates a procedure based on the fact that the target could be longer than the probe and preserves after recognition a single-strand fragment. A tagged oligonucleotide (signaling probe) that is complementary to this overhanging fragment can be attached to the initial hybrid in a second hybridization process leading to a tagged hybrid that can be detected in order to assess the extent of the recognition process. This technique is often termed sandwich hybridization.
Figure 7.16 Labeling by hybridization of a tagged strand with the overhanging moiety of the target (sandwich hybridization).
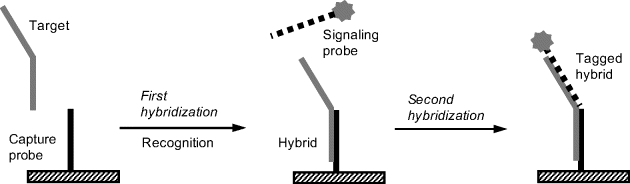
Figure 7.17 illustrates an alternative postrecognition labeling method, which relies on the intercalation of a tagged intercalator. This method may be less specific than that based on sandwich hybridization, but it requires only some common chemicals and avoids the synthesis of a tagged oligonucleotide.
Figure 7.17 Posthybridization labeling using a label-tagged intercalator.
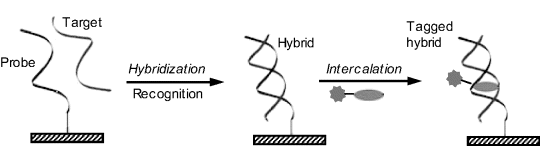
A frequently used transduction method relies on hairpin-shaped probes (Figure 7.18). The probe molecule includes complementary peripheral stems that form base pairs to stabilize the hairpin conformation. The label attached to the end of the chain shows a property that is decisively dependent on its position with respect to the transducer surface or the second end of the hairpin (spatially resolved transduction). Thus, an electrochemical label can accept electrons from the underlying electrode only if it is localized in the immediate proximity of the electrode. The recognition fragment of the probe is localized in the loop region such that the hybridization brings about the collapse of the hairpin conformation and shifts the label to a position where it is no longer active. So, in the case of electrochemical transduction, the label is moved too far from the electrode surface and current flow is interrupted (“signal-off”). Other strategies based on configuration change after hybridization have also been envisaged [42]. It is sometimes more advantageous to design a “signal-on” format that relies on a signal enhancement after hybridization. A much better signal:background ratio is obtained in this way. The term “molecular beacon” is often used to designate the DNA sensor configuration based on a hairpin probe.
Figure 7.18 Configuration of a DNA hybridization sensor based on a hairpin-shaped probe (molecular beacon configuration).
7.5.3 DNA Amplification
Often, the amount of available DNA analyte is too low to allow reliable quantitation by a nucleic acid sensor and some amplification procedure has to be included in the protocol in order to enhance the sensitivity [43]. A straightforward amplification method relies on application of enzyme tags. High turnover of enzymes brings about an intrinsic signal enhancement as a single label can produce a large amount of product per time unit.
A general amplification method is based on multiplication of the original target by the polymerase chain reaction (PCB) [44–46]. This method aims at enhancing of the amount of analyte DNA prior to the assay by a sequence of enzyme-catalyzed reactions.
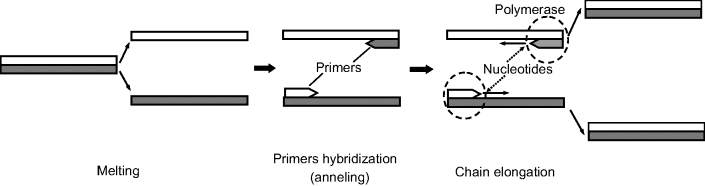
PCR involves a polymerase enzyme and two primers. Polymerases are enzymes that catalyze the polymerization of a polynucleotide as a complementary form to a template strand. The final product of this reaction is a double helix composed of the template and the newly synthesized complementary polynucleotide. The thermostable Taq polymerase is used in PCR because it allows the reaction to be carried out at a high temperature and consequently with a high reaction velocity. A primer is a short strand that is complementary to a specific sequence in the template chain. There are three basic steps in this method (Figure 7.19). First, the original ds-nucleic acid must be denatured, that is, the strands of its helix must be unwound and separated by heating to 90–96 °C. The second step (at about 50–55 °C) consists of primer hybridization in which the primers bind to their complementary sequences in the ss-DNA molecules. The third step is the synthesis of a complementary nucleic acid strand under the effect of the polymerase, at 72 °C. Starting from the primer, the polymerase can read the template strand and match it with complementary nucleotides. The products are two new double helices each composed of one of the original strands plus its newly assembled complement. This cycle can be repeated many times, the amount of final product molecules being ![]() , where n is the number of cycles. As each cycle takes 1–3 min, millions of copies of the original DNA can be generated in about 1 h.
, where n is the number of cycles. As each cycle takes 1–3 min, millions of copies of the original DNA can be generated in about 1 h.
Figure 7.19 Schematics of the polymerase chain reaction (PCR). Nucleotides should be present in the triphospahate form.
During the PCR process, label tags can be introduced into the newly synthesized sequence. This is achieved by including a tagged nucleotide in the reaction mixture.
Genetic assays are performed using amplicons, which are pieces of DNA formed as the products of natural or artificial amplification events. For example, amplicons can be formed via polymerase chain reactions or ligase chain reactions, but also by natural gene duplication.
Preliminary multiplication of the target is the most straightforward application of PCR. Sensitivity enhancement can also be achieved by posthybridization PCR. To this end, the PCR is effected after hybridization, using the probe as primer and the overhanging target moiety in the hybrid as template. For example, a complementary chain grown by PCR on the ss-fragment of the target will increase the mass variation in a mass-sensitive transduction method.
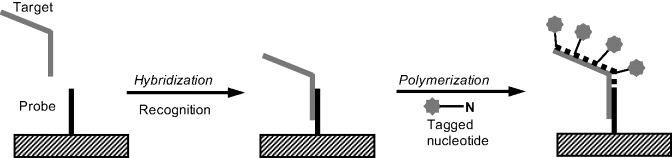
Moreover, template polymerization of a second chain provides the possibility of adding multiple transduction tags to the probe–target hybrid. (Figure 7.20). In order to include the label in the resulting structure, a tagged nucleotide is made available to the polymerization process, along with three normal ones. Consequently, an amplification of the response is achieved, each linked target being signaled by multiple tags.
Figure 7.20 PCR application for adding multiple transduction tags after hybridization.
7.6 DNA Microarrays
An essential process in cell growth is the transfer of genetic information from DNA to ribosomes via messenger RNAs (mRNAs). Anomalies in this process are responsible for many diseases. That is why a genetic screen is an essential tool in medicine and molecular biology. A genetic screen consists of seeking sample genes by means of a set of hybridization probes assembled in the form of a DNA microarray, also known as a DNA chip [47–50]. A microarray consists of a set of different probes each of them being specific to a particular gene and placed at a particular site on a small plate. A DNA microarray allows parallel and simultaneous detection of a great number of target genes. For example, more than ten thousands spots of the micrometer size can be fabricated on a plate a few centimeters in diameter. In standard microarrays, the probes are attached by covalent linking to a solid support (glass, polymers or silicon).
In a microarray assay (Figure 7.21), mRNA is first separated from the sample cells and then reverse transcription is applied in order to produce complementary DNA (cDNA) bearing similar genetic information. This step is necessary because RNA is decomposed by nuclease enzymes in real samples. Thereafter, PCR is applied in order to increase the amount of cDNA and fluorescent (or other type) labels are affixed during this step by supplying labeled nucleotides. The labeled targets mixture is then incubated with the array and the hybridization is left to proceed. After washing out of nonspecific bonding targets, only strongly paired strands persist. Finally, the array is examined in order to measure the amount of label bound to each location. The identity of each target is indicated by its position, whereas the strength of the signal arising from a specific spot indicates the amount of each target in the sample. As a rule, a reference sample of healthy cells, labeled with a different color is run simultaneously. As a microarray generates a large amount of data, statistical algorithms are essential in data processing [51].
Figure 7.21 Main steps in a DNA microarray assay. Reproduced with permission from [53]. Copyright 2005 Springer Science + Business Media B.V.
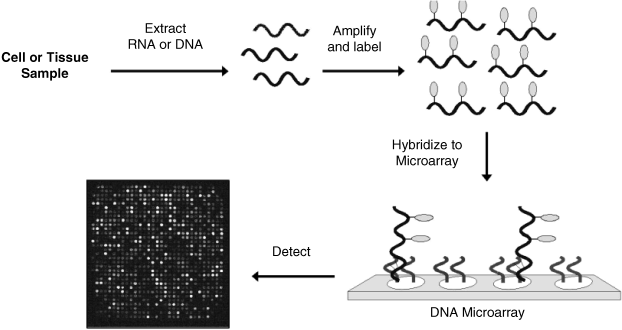
Although fluorescence is the standard method for examining a DNA microarray, other methods, (for example, electrochemical [53]), are actively investigated.
DNA microarrays are widely used for diagnostic purposes or for developing drugs against gene expression related diseases, such as cancer. The goal of such an assay is to assess the level or volume at which a certain gene is expressed (microarray expression analysis). Also, DNA microarrays are employed for detecting mutations or polymorphisms in a gene sequence. In this case, genomic DNA is targeted. A probe placed on a given spot will differ from other probes by only one or a few nucleotides.
The array throughput is determined by the spot density and spot miniaturization is the main way of improving the throughput. Much progress in this direction has been achieved by designing arrays of reaction chambers of nanoliter capacity or lower [54].
7.7 Outlook
Polynucleotides are used in affinity biosensors as recognition components for a series of applications. First, polynucleotide probes can recognize, by hybridization, complementary chains. By this means, key applications in medicine and molecular biology have been developed. Furthermore, double-strand nucleic acids can recognize by intercalation or covalent bonding some genotoxic substances with relevance to environment monitoring or the food industry. Intercalating analytes belong to various classes of organic substances, such as carcinogenic aromatic amines, polychlorinated biphenyls, aflatoxins, anthracene and acridine derivatives. Moreover, the ability of nucleic acid sensors to identify micro-organisms through their gene code render them valuable for detecting pathogens in foods, water and environment samples as well as for identification of biological warfare agents.
In addition, the advent of nucleic acid aptamers greatly expands the field of application of nucleic acid sensor. Aptamers perform recognition of proteins or certain small organic molecules with substantial advantages as compared with antibodies.
1. Liu, J.W., Cao, Z.H., and Lu, Y. (2009) Functional nucleic acid sensors. Chem. Rev., 109, 1948–1998.
2. Yang, M.S., McGovern, M.E., and Thompson, M. (1997) Genosensor technology and the detection of interfacial nucleic acid chemistry. Anal. Chim. Acta, 346, 259–275.
3. Wang, J. (2000) From DNA biosensors to gene chips. Nucleic Acids Res., 28, 3011–3016.
4. Sassolas, A., Leca-Bouvier, B.D., and Blum, L.J. (2008) DNA biosensors and microarrays. Chem. Rev., 108, 109–139.
5. Walker, J.M. and Wilson, K. (2010) Principles and Techniques of Biochemistry and Molecular Biology, Cambridge University Press, Cambridge.
6. Neidle, S. (2008) Principles of Nucleic Acid Structure, Elsevier, Amsterdam.
7. Reese, C.B. (2005) Oligo- and poly-nucleotides: 50 years of chemical synthesis. Org. Biomol. Chem., 3, 3851–3868.
8. Khudjakov, J.E. and Fields, H.A. (2003) Artificial DNA: Methods and Applications, CRC Press, Boca Raton.
9. Buzdin, A.A. and Lukyanov, S.A. (eds) (2007) Nucleic Acids Hybridization: Modern Applications, Springer, Dordrecht.
10. Caruana, D.J. (2004) Hybridization at oligonucleotide sensitive electrodes, in Biosensors: A Practical Approach (eds J.M. Cooper and A.E.G. Cass), Oxford University Press, New York, pp. 19–39.
11. Paszek, E. (2007) cDNA-Detailed Information (http://cnx.org/content/m12385/1.5/).
12. Minunni, M., Tombelli, S., Mariotti, E., et al. (2001) Biosensors as new analytical tool for detection of Genetically Modified Organisms (GMOs). Fresenius J. Anal. Chem., 369, 589–593.
13. Demeunynck, M., Bailly, C., and David Wilson, W. (eds) (2003) Small Molecule DNA and RNA Binders: From Synthesis to Nucleic Acid Complexes, Wiley-VCH, Weinheim.
14. Zeglis, B.M., Pierre, V.C., and Barton, J.K. (2007) Metallo-intercalators and metallo-insertors. Chem. Commun., 4565–4579.
15. Mascini, M., Palchetti, I., and Marrazza, G. (2001) DNA electrochemical biosensors. Fresenius J. Anal. Chem., 369, 15–22.
16. Klussmann, S. (2006) The Aptamer Handbook: Functional Oligonucleotides and their Applications, Wiley-VCH, Weinheim.
17. Lee, J.F., Stovall, G.M., and Ellington, A.D. (2006) Aptamer therapeutics advance. Curr. Opin. Chem. Biol., 10, 282–289.
18. Jayasena, S.D. (1999) Aptamers: An emerging class of molecules that rival antibodies in diagnostics. Clin. Chem., 45, 1628–1650.
19. Mairal, T.T. (2008) Aptamers: molecular tools for analytical applications. Anal. Bioanal. Chem., 390, 989–1007.
20. Tombelli, S., Minunni, A., and Mascini, A. (2005) Analytical applications of aptamers. Biosens. Bioelectron., 20, 2424–2434.
21. Song, S.P., Wang, L.H., Li, J., et al. (2008) Aptamer-based biosensors. TrAC-Trends Anal. Chem., 27, 108–117.
22. Hianik, T., Porfireva, A., Grman, I. et al. (2008) Aptabodies - New type of artificial receptors for detection proteins. Protein Pept. Lett., 15, 799–805.
23. Cai, Z., Li, Z., Kang, Z., et al. (eds) (2009) Aptasensors design considerations, in Computational Intelligence and Intelligent Systems, Springer, Berlin, pp. 118–127.
24. Hianik, T. and Wang, J. (2009) Electrochemical aptasensors - recent achievements and perspectives. Electroanalysis, 21, 1223–1235.
25. Heise, C. and Bier, F.F. (2005) Immobilization of DNA on microarrays, in Immobilisation of DNA on Chips II (ed. C. Wittmann), Springer, Berlin, pp. 1–25.
26. de-los-Santos-Alvarez, P., Lobo-Castanon, M.J., Miranda-Ordieres, A.J. et al. (2004) Current strategies for electrochemical detection of DNA with solid electrodes. Anal. Bioanal. Chem., 378, 104–118.
27. Pividori, M.I., Merkoci, A., and Alegret, S. (2000) Electrochemical genosensor design: Immobilisation of oligonucleotides onto transducer surfaces and detection methods. Biosens. Bioelectron., 15, 291–303.
28. Balamurugan, S., Obubuafo, A., Soper, S.A. et al. (2008) Surface immobilization methods for aptamer diagnostic applications. Anal. Bioanal. Chem., 390, 1009–1021.
29. Pividori, M.I. and Alegret, S. (2005) DNA adsorption on carbonaceous materials, in Immobilisation of DNA on Chips I (ed. C. Wittmann), Springer, Berlin, pp. 1–36.
30. Pividori, M.I. and Alegret, S. (2005) Electrochemical genosensing based on rigid carbon composites. A review. Anal. Lett., 38, 2541–2565.
31. Palchetti, I. and Mascini, M. (2005) Electrochemical adsorption technique for immobilization of single-stranded oligonucleotides onto carbon screen-printed electrodes, in Immobilisation of DNA on Chips II (ed. C. Wittmann), Springer, Berlin, pp. 27–43.
32. Luderer, F. and Walschus, U. (2005) Immobilization of oligonucleotides for biochemical sensing by self-assembled monolayers: thiol-organic bonding on gold and silanization on silica surfaces, in Immobilisation of DNA on Chips I (ed. C. Wittmann), Springer, Berlin, pp. 37–56.
33. Lucarelli, F., Marrazza, G., Turner, A.P.F. et al. (2004) Carbon and gold electrodes as electrochemical transducers for DNA hybridisation sensors. Biosens. Bioelectron., 19, 515–530.
34. Bidan, G., Billon, M., Calvo-Munoz, M.L. et al. (2004) Bio-assemblies onto conducting polymer support: Implementation of DNA-chips. Mol. Cryst. Liquid Cryst., 418, 983–998.
35. Livache, T., Roget, A., Dejean, E., et al. (1994) Preparation of a DNA matrix via an electrochemically directed copolymerization of pyrrole and oligonucleotides bearing a pyrrole group. Nucleic Acids Res., 22, 2915–2921.
36. Smith, C.L., Milea, J.S., and Nguyen, G.H. (2005) Immobilization of nucleic acids using biotin-strept(avidin) systems, in Immobilisation of DNA on Chips II (ed. C. Wittmann), Springer, Berlin, pp. 63–90.
37. de Dios, A.S. and Diaz-Garcia, M.E. (2010) Multifunctional nanoparticles: Analytical prospects. Anal. Chim. Acta, 666, 1–22.
38. Chiu, T.C. and Huang, C.C. (2009) Aptamer-functionalized nano-biosensors. Sensors, 9, 10356–10388.
39. Lin, Y.W., Liu, C.W., and Chang, H.T. (2009) DNA functionalized gold nanoparticles for bioanalysis. Anal. Methods, 1, 14–24.
40. Wang, J., Katz, E., and Willner, I. (2005) Biomaterial-nanoparticle hybrid systems for sensing and electronic devices, in Bioelectronics: From Theory to Applications (eds I. Willner and E. Katz), Wiley-VCH, Weinheim, pp. 231–264.
41. Katz, E. (2003) Probing biomolecular interactions at conductive and semiconductive surfaces by impedance spectroscopy: Routes to impedimetric immunosensors, DNA-sensors, and enzyme biosensors. Electroanalysis, 15, 913–947.
42. Miranda-Castro, R., de-los-Santos-Alvarez, N., Lobo-Castanon, M.J., et al. (2009) Structured nucleic acid probes for electrochemical devices. Electroanalysis, 21, 2077–2090.
43. Willner, I., Shlyahovsky, B., Willner, B. et al. (2009) Amplified DNA biosensors, in Functional Nucleic Acids for Analytical Applications (eds Y. Li and Y. Lu), Springer, New York, pp. 199–252.
44. Mullis, K.B. (1990) The unusual origin of the polymerase chain-reaction. Sci. Am., 262, 56–65.
45. Arnheim, N. and Levenson, C.H. (1990) Polymerase chain-reaction. Chem. Eng. News, 68, 36–47.
46. Erlich, H.A. (1989) Polymerase chain-reaction. J. Clin. Immunol., 9, 437–447.
47. Hegde, P., Qi, R., Abernathy, K., et al. (2000) A concise guide to cDNA microarray analysis. Biotechniques, 29, 548–562.
48. Müller, H.J. and Röder, T. (2006) Microarrays, Elsevier, San Diego.
49. Bier, F.E., von Nickisch-Rosenegk, M., Ehrentreich-Forster, E. et al. (2008) DNA microarrays, in Biosensing for the 21st Century, Springer, Berlin, pp. 433–453.
50. Liljedahl, U., Fredriksson, M., and Syvänen, A.C. (2005) Analysis of DNA sequence variation in the microarray format, in Microarray Technology and Its Applications (eds R. Müller and V. Nicolau), Springer, Berlin, pp. 211–227.
51. Dr![]() ghici, S. (2003) Data Analysis Tools for DNA Microarrays, Chapman & Hall/CRC, Boca Raton, Fla.
ghici, S. (2003) Data Analysis Tools for DNA Microarrays, Chapman & Hall/CRC, Boca Raton, Fla.
52. Storhoff, J.J., Marla, S.S., Garimella, V. et al. (2005) Labels and detection methods, in Microarray Technology and its Applications (eds R. Müller and V. Nicolau), Springer, Berlin, pp. 147–179.
53. Dill, K. and Ghindilis, A. (2009) Electrochemical detection on microarrays, in Microarrays (eds K. Dill, R.H. Liu, and P. Grodzinski), Springer, New York, pp. 25–34.
54. Yamamura, S., Sathuluri, R.R., and Tamiya, E. (2007) Pico/nanoliter chamber array chip for single-cell, DNA and protein analysis, in Nanomaterials for Biosensors (ed. C. Kumar), Wiley-VCH, Weinheim, pp. 368–397.