
Now that we are familiar with cross-validation, we will build a working machine learning system that incorporates cross-validation. The problem at hand will be that of spam classification, in which we will have to determine the likelihood of a given e-mail being a spam e-mail. Essentially, the problem boils down to binary classification with a few tweaks to make the machine learning system more sensitive to spam (for more information, refer to A Plan for Spam). Note that we will not be implementing a classification engine that is integrated with an e-mail server, but rather we will be concentrating on the aspects of training the engine with some data and classifying a given e-mail.
The way this would be used in practice can be briefly explained as follows. A user will receive and read a new e-mail, and will decide whether to mark the e-mail as spam or not. Depending on the user's decision, we must train the e-mail service's spam engine using the new e-mail as data.
In order to train our spam classifier in a more automated manner, we'll have to simply gather data to feed into the classifier. We will need a large amount of data to effectively train a classifier with the English language. Luckily for us, sample data for spam classification can be found easily on the Web. For this implementation, we will use data from the Apache SpamAssassin project.
Note
The Apache SpamAssassin project is an open source implementation of a spam classification engine in Perl. For our implementation, we will use the sample data from this project. You can download this data from http://spamassassin.apache.org/publiccorpus/. For our example, we have used the spam_2 and easy_ham_2 datasets. A Clojure Leiningen project housing our spam classifier implementation will require that these datasets be extracted and placed in the ham/ and spam/ subdirectories of the corpus/ folder. The corpus/ folder should be placed in the root directory of the Leiningen project that is the same folder of the project.clj file.
The features of our spam classifier will be the number of occurrences of all previously encountered words in spam and ham e-mails. By the term ham, we mean "not spam". Thus, there are effectively two independent variables in our model. Also, each word has an associated probability of occurrence in e-mails, which can be calculated from the number of times it's found in spam and ham e-mails and the total number of e-mails processed by the classifier. A new e-mail would be classified by finding all known words in the e-mail's header and body and then somehow combining the probabilities of occurrences of these words in spam and ham e-mails.
For a given word feature in our classifier, we must calculate the total probability of occurrence of the word by taking into account the total number of e-mails analyzed by the classifier (for more information, refer to Better Bayesian Filtering). Also, an unseen term is neutral in the sense that it is neither spam nor ham. Thus, the initial probability of occurrence of any word in the untrained classifier is 0.5. Hence, we use a Bayesian probability function to model the occurrence of a particular word.
In order to classify a new e-mail, we also need to combine the probabilities of occurrences of all the known words found in it. For this implementation, we will use Fisher's method, or Fisher's combined probability test, to combine the calculated probabilities. Although the mathematical proof of this test is beyond the scope of this book, it's important to know that this method essentially estimates the probabilities of several independent probabilities in a given model as a ![]() (pronounced as chi-squared) distribution (for more information, refer to Statistical Methods for Research Workers). Such a distribution has an associated number of degrees of freedom. It can be shown that an
(pronounced as chi-squared) distribution (for more information, refer to Statistical Methods for Research Workers). Such a distribution has an associated number of degrees of freedom. It can be shown that an ![]() distribution with degrees of freedom equal to twice the number of combined probabilities k can be formally expressed as follows:
distribution with degrees of freedom equal to twice the number of combined probabilities k can be formally expressed as follows:
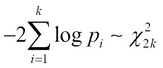
This means that using an ![]() distribution with
distribution with ![]() degrees of freedom, the Cumulative Distribution Function (CDF), of the probabilities of the e-mail being a spam or a ham can be combined to reflect a total probability that is high when there are a large number of probabilities with values close to 1.0. Thus, an e-mail is classified as spam only when most of the words in the e-mail have been previously found in spam e-mails. Similarly, a large number of ham keywords would indicate the e-mail is in fact a ham e-mail. On the other hand, a low number of occurrences of spam keywords in an e-mail would have a probability closer to 0.5, in which case the classifier will be unsure of whether the e-mail is spam or ham.
degrees of freedom, the Cumulative Distribution Function (CDF), of the probabilities of the e-mail being a spam or a ham can be combined to reflect a total probability that is high when there are a large number of probabilities with values close to 1.0. Thus, an e-mail is classified as spam only when most of the words in the e-mail have been previously found in spam e-mails. Similarly, a large number of ham keywords would indicate the e-mail is in fact a ham e-mail. On the other hand, a low number of occurrences of spam keywords in an e-mail would have a probability closer to 0.5, in which case the classifier will be unsure of whether the e-mail is spam or ham.
Note
For the example that will follow, we will require the file and cdf-chisq functions from the clojure.java.io and Incanter libraries, respectively. The namespace declaration of the example should look similar to the following declaration:
(ns my-namespace
(:use [clojure.java.io :only [file]]
[incanter.stats :only [cdf-chisq]])A classifier trained using Fisher's method, as described earlier, will be very sensitive to new spam e-mails. We represent the dependent variable of our model by the probability of a given e-mail being spam. This probability is also termed as the spam score of the e-mail. A low score indicates that an e-mail is ham, while a high score indicates that the e-mail is spam. Of course, we must also include a third class to represent an unknown value in our model. We can define some reasonable limits for the scores of these categories as follows:
(def min-spam-score 0.7)
(def max-ham-score 0.4)
(defn classify-score [score]
[(cond
(<= score max-ham-score) :ham
(>= score min-spam-score) :spam
:else :unsure)
score])As defined earlier, if an e-mail has a score of 0.7 or more, it's a spam e-mail. And a score of 0.5 or less indicates that the e-mail is ham. Also, if the score lies between these two values, we can't effectively decide whether the e-mail is spam or not. We represent these three categories using the keywords :ham, :spam, and :unsure.
The spam classifier must read several e-mails, determine all the words, or tokens, in the e-mails' text and header, and store this information as empirical knowledge to use later. We need to store the number of occurrences a particular word is found in spam and ham e-mails. Thus, every word that the classifier has encountered represents a feature. To represent this information for a single word, we will use a record with three fields as shown in the following code:
(defrecord TokenFeature [token spam ham]) (defn new-token [token] (TokenFeature. token 0 0)) (defn inc-count [token-feature type] (update-in token-feature [type] inc))
The record TokenFeature defined in the preceding code can be used to store the needed information for our spam classifier. The new-token function simply creates a new record for a given token by invoking the records, constructor. Obviously, a word is initially seen zero times in both spam and ham e-mails. We will also need to update these values, and we define the inc-count function to perform an update on the record using the update-in function. Note that the update-in function expects a function to apply to a particular field in the record as the last parameter. We are already dealing with a small amount of a mutable state in our implementation, so let's delegate access to this state through an agent. We would also like to keep track of the total number of ham and spam e-mails; so, we'll wrap these values with agents as well, as shown in the following code:
(def feature-db
(agent {} :error-handler #(println "Error: " %2)))
(def total-ham (agent 0))
(def total-spam (agent 0))The feature-db agent defined in the preceding code will be used to store all word features. We define a simple error handler for this agent using the :error-handler keyword parameter. The agent's total-ham and total-spam functions will keep track of the total number of ham and spam e-mails, respectively. We will now define a couple of functions to access these agents as follows:
(defn clear-db []
(send feature-db (constantly {}))
(send total-ham (constantly 0))
(send total-spam (constantly 0)))
(defn update-feature!
"Looks up a TokenFeature record in the database and
creates it if it doesn't exist, or updates it."
[token f & args]
(send feature-db update-in [token]
#(apply f (if %1 %1 (new-token token))
args)))In case you are not familiar with agents in Clojure, we can use the send function to alter the value contained in an agent. This function expects a single argument, that is, the function to apply to its encapsulated value. The agent applies this function on its contained value and updates it if there are no errors. The clear-db function simply initializes all the agents we've defined with an initial value. This is done by using the constantly function that wraps a value in a function that returns the same value. The update-feature! function modifies the value of a given token in the feature-db map and creates a new token if the supplied token is not present in the map of feature-db. Since we will only be incrementing the number of occurrences of a given token, we will pass the inc-count function as a parameter to the update-feature! function.
Now, let's define how the classifier will extract words from a given e-mail. We'll use regular expressions to do this. If we want to extract all the words from a given string, we can use the regular expression [a-zA-Z]{3,}. We can define this regular expression using a literal syntax in Clojure, as shown in the following code. Note that we could also use the re-pattern function to create a regular expression. We will also define all the MIME header fields from which we should also extract tokens. We will do all this with the help of the following code:
(def token-regex #"[a-zA-Z]{3,}")
(def header-fields
["To:"
"From:"
"Subject:"
"Return-Path:"])To match tokens with the regular expression defined by token-regex, we will use the re-seq function, which returns all matching tokens in a given string as a sequence of strings. For the MIME headers of an e-mail, we need to use a different regular expression to extract tokens. For example, we can extract tokens from the "From" MIME header as follows:
user> (re-seq #"From:(.*)
"
"From: [email protected]
")
(["From: [email protected]
" " [email protected]"])We can then proceed to extract words from the values returned by matching the regular expression defined in the preceding code. Let's define the following few functions to extract tokens from a given e-mail's headers and body using this logic:
(defn header-token-regex [f]
(re-pattern (str f "(.*)
")))
(defn extract-tokens-from-headers [text]
(for [field header-fields]
(map #(str field %1) ; prepends field to each word from line
(mapcat (fn [x] (->> x second (re-seq token-regex)))
(re-seq (header-token-regex field)
text)))))
(defn extract-tokens [text]
(apply concat
(re-seq token-regex text)
(extract-tokens-from-headers text)))The header-token-regex function defined in the preceding code returns a regular expression for a given header, such as From:(.*)
for the "From" header. The extract-tokens-from-headers function uses this regular expression to determine all words in the various header fields of an e-mail and appends the header name to all the tokens found in the header text. The extract-tokens function applies the regular expression over the text and headers of an e-mail and then flattens the resulting lists into a single list using the apply and concat functions. Note that the extract-tokens-from-headers function returns empty lists for the headers defined in header-fields, which are not present in the supplied e-mail header. Let's try this function out in the REPL with the help of the following code:
user> (def sample-text
"From: [email protected]
Return-Path: <[email protected]>
MIME-Version: 1.0")
user> (extract-tokens-from-headers sample-text)
(() ("From:mailbot" "From:web")
() ("Return-Path:mailbot" "Return-Path:web"))Using the extract-tokens-from-headers function and the regular expression defined by token-regex, we can extract all words comprising of three or more characters from an e-mail's header and text. Now, let's define a function to apply the extract-tokens function on a given e-mail and update the feature map using the update-feature! function with all the words found in the e-mail. We will do all this with the help of the following code:
(defn update-features!
"Updates or creates a TokenFeature in database
for each token in text."
[text f & args]
(doseq [token (extract-tokens text)]
(apply update-feature! token f args)))Using the update-features! function in the preceding code, we can train our spam classifier with a given e-mail. In order to keep track of the total number of spam and ham e-mails, we will have to send the inc function to the total-spam or total-ham agents depending on whether a given e-mail is spam or ham. We will do this with the help of the following code:
(defn inc-total-count! [type]
(send (case type
:spam total-spam
:ham total-ham)
inc))
(defn train! [text type]
(update-features! text inc-count type)
(inc-total-count! type))The inc-total-count! function defined in the preceding code updates the total number of spam and ham e-mails in our feature database. The train! function simply calls the update-features! and inc-total-count! functions to train our spam classifier with a given e-mail and its type. Note that we pass the inc-count function to the update-features! function. Now, in order to classify a new e-mail as spam or ham, we must first define how to extract the known features from a given e-mail using our trained feature database. We will do this with the help of the following code:
(defn extract-features "Extracts all known tokens from text" [text] (keep identity (map #(@feature-db %1) (extract-tokens text))))
The extract-features function defined in the preceding code looks up all known features in a given e-mail by dereferencing the map stored in feature-db and applying it as a function to all the values returned by the extract-tokens function. As mapping the closure #(@feature-db %1) can return () or nil for all tokens that are not present in a feature-db agent, we will need to remove all empty values from the list of extracted features. To do this, we will use the keep function, which expects a function to apply to the non-nil values in a collection and the collection from which all nil values must be filtered out. Since we do not intend to transform the known features from the e-mail, we will pass the identity function, which returns its argument itself as the first parameter to the keep function.
Now that we have extracted all known features from a given e-mail, we must calculate all the probabilities of these features occurring in a spam e-mail. We must then combine these probabilities using Fisher's method we described earlier to determine the spam score of a new e-mail. Let's define the following functions to implement the Bayesian probability and Fisher's method:
(defn spam-probability [feature]
(let [s (/ (:spam feature) (max 1 @total-spam))
h (/ (:ham feature) (max 1 @total-ham))]
(/ s (+ s h))))
(defn bayesian-spam-probability
"Calculates probability a feature is spam on a prior
probability assumed-probability for each feature,
and weight is the weight to be given to the prior
assumed (i.e. the number of data points)."
[feature & {:keys [assumed-probability weight]
:or {assumed-probability 1/2 weight 1}}]
(let [basic-prob (spam-probability feature)
total-count (+ (:spam feature) (:ham feature))]
(/ (+ (* weight assumed-probability)
(* total-count basic-prob))
(+ weight total-count))))The spam-probability function defined in the preceding code calculates the probability of occurrence of a given word feature in a spam e-mail using the number of occurrences of the word in spam and ham e-mails and the total number of spam and ham e-mails processed by the classifier. To avoid division-by-zero errors, we ensure that the value of the number of spam and ham e-mails is at least 1 before performing division. The bayesian-spam-probability function uses this probability returned by the spam-probability function to calculate a weighted average with the initial probability of 0.5 or 1/2.
We will now implement Fisher's method of combining the probabilities returned by the bayesian-spam-probability function for all the known features found in an e-mail. We will do this with the help of the following code:
(defn fisher
"Combines several probabilities with Fisher's method."
[probs]
(- 1 (cdf-chisq
(* -2 (reduce + (map #(Math/log %1) probs)))
:df (* 2 (count probs)))))The fisher function defined in the preceding code uses the cdf-chisq function from the Incanter library to calculate the CDF of the several probabilities transformed by the expression ![]() . We specify the number of degrees of freedom to this function using the
. We specify the number of degrees of freedom to this function using the :df optional parameter. We now need to apply the fisher function to the combined Bayesian probabilities of an e-mail being spam or ham, and combine these values into a final spam score. These two probabilities must be combined such that only a high number of occurrences of high probabilities indicate a strong probability of spam or ham. It has been shown that the simplest way to do this is to average the probability of a spam e-mail and the negative probability of a ham e-mail (or 1 minus the probability of a ham e-mail). We will do this with the help of the following code:
(defn score [features]
(let [spam-probs (map bayesian-spam-probability features)
ham-probs (map #(- 1 %1) spam-probs)
h (- 1 (fisher spam-probs))
s (- 1 (fisher ham-probs))]
(/ (+ (- 1 h) s) 2)))Hence, the score function will return the final spam score of a given e-mail. Let's define a function to extract the known word features from a given e-mail, combine the probabilities of occurrences of these features to produce the e-mail's spam score, and finally classify this spam score as a ham or spam e-mail, represented by the keywords :ham and :spam respectively, as shown in the following code:
(defn classify
"Returns a vector of the form [classification score]"
[text]
(-> text
extract-features
score
classify-score))So far, we have implemented how we train our spam classifier and use it to classify a new e-mail. Now, let's define some functions to load the sample data from the project's corpus/ folder and use this data to train and cross-validate our classifier, as follows:
(defn populate-emails
"Returns a sequence of vectors of the form [filename type]"
[]
(letfn [(get-email-files [type]
(map (fn [f] [(.toString f) (keyword type)])
(rest (file-seq (file (str "corpus/" type))))))]
(mapcat get-email-files ["ham" "spam"])))The populate-emails function defined in the preceding code returns a sequence of vectors to represent all the ham e-mails from the ham/ folder and the spam e-mails from the spam/ folder in our sample data. Each vector in this returned sequence has two elements. The first element in this vector is a given e-mail's relative file path and the second element is either :spam or :ham depending on whether the e-mail is spam or ham. Note the use of the file-seq function to read the files in a directory as a sequence.
We will now use the train! function to feed the content of all e-mails into our spam classifier. To do this, we can use the slurp function to read the content of a file as a string. For cross-validation, we will classify each e-mail in the supplied cross-validation data using the classify function and return a list of maps representing the test result of the cross-validation. We will do this with the help of the following code:
(defn train-from-corpus! [corpus]
(doseq [v corpus]
(let [[filename type] v]
(train! (slurp filename) type))))
(defn cv-from-corpus [corpus]
(for [v corpus]
(let [[filename type] v
[classification score] (classify (slurp filename))]
{:filename filename
:type type
:classification classification
:score score})))The train-from-corpus! function defined in the preceding code will train our spam classifier with all e-mails found in the corpus/ folder. The cv-from-corpus function classifies the supplied e-mails as spam or ham using the trained classifier and returns a sequence of maps indicating the results of the cross-validation process. Each map in the sequence returned by the cv-from-corpus function contains the file of the e-mail, the actual type (spam or ham) of the e-mail, the predicted type of the e-mail, and the spam score of the e-mail. Now, we need to call these two functions on two appropriately partitioned subsets of the sample data as follows:
(defn test-classifier! [corpus cv-fraction]
"Trains and cross-validates the classifier with the sample
data in corpus, using cv-fraction for cross-validation.
Returns a sequence of maps representing the results
of the cross-validation."
(clear-db)
(let [shuffled (shuffle corpus)
size (count corpus)
training-num (* size (- 1 cv-fraction))
training-set (take training-num shuffled)
cv-set (nthrest shuffled training-num)]
(train-from-corpus! training-set)
(await feature-db)
(cv-from-corpus cv-set)))The test-classifier! function defined in the preceding code will randomly shuffle the sample data and select a specified fraction of this randomized data as the cross-validation set for our classifier. The test-classifier! function then calls the train-from-corpus! and cv-from-corpus functions to train and cross-validate the data. Note that the use of the await function is to wait until the feature-db agent has finished applying all functions that have been sent to it via the send function.
Now we need to analyze the results of cross-validation. We must first determine the number of incorrectly classified and missed e-mails from the actual and expected class of a given e-mail as returned by the cv-from-corpus function. We will do this with the help of the following code:
(defn result-type [{:keys [filename type classification score]}]
(case type
:ham (case classification
:ham :correct
:spam :false-positive
:unsure :missed-ham)
:spam (case classification
:spam :correct
:ham :false-negative
:unsure :missed-spam)))The result-type function will determine the number of incorrectly classified and missed e-mails in the cross-validation process. We can now apply the result-type function to all the maps in the results returned by the cv-from-corpus function and print a summary of the cross-validation results with the help of the following code:
(defn analyze-results [results]
(reduce (fn [map result]
(let [type (result-type result)]
(update-in map [type] inc)))
{:total (count results) :correct 0 :false-positive 0
:false-negative 0 :missed-ham 0 :missed-spam 0}
results))
(defn print-result [result]
(let [total (:total result)]
(doseq [[key num] result]
(printf "%15s : %-6d%6.2f %%%n"
(name key) num (float (* 100 (/ num total)))))))The analyze-results function defined in the preceding code simply applies the result-type function to all the map values in the sequence returned by the cv-from-corpus function, while maintaining the total number of incorrectly classified and missed e-mails. The print-result function simply prints the analyzed result as a string. Finally, let's define a function to load all the e-mails using the populate-emails function and then use this data to train and cross-validate our spam classifier. Since the populate-emails function will return an empty list, or nil when there are no e-mails, we will check this condition to avoid failing at a later stage in our program:
(defn train-and-cv-classifier [cv-frac]
(if-let [emails (seq (populate-emails))]
(-> emails
(test-classifier! cv-frac)
analyze-results
print-result)
(throw (Error. "No mails found!"))))In the train-and-cv-classifier function shown in the preceding code, we first call the populate-emails function and convert the result to a sequence using the seq function. If the sequence has any elements, we train and cross-validate the classifier. If there are no e-mails found, we simply throw an error. Note that the if-let function is used to check whether the sequence returned by the seq function has any elements.
We have all the parts needed to create and train a spam classifier. Initially, as the classifier hasn't seen any e-mails, the probability of any e-mail or text being spam is 0.5. This can be verified by using the classify function, as shown in the following code, which initially classifies any text as the :unsure type:
user> (classify "Make money fast") [:unsure 0.5] user> (classify "Job interview today! Programmer job position for GNU project") [:unsure 0.5]
We now train the classifier and cross-validate it using the train-and-cv-classifier function. We will use one-fifth of all the available sample data as our cross-validation set. This is shown in the following code:
user> (train-and-cv-classifier 1/5)
total : 600 100.00 %
correct : 585 97.50 %
false-positive : 1 0.17 %
false-negative : 1 0.17 %
missed-ham : 9 1.50 %
missed-spam : 4 0.67 %
nilCross-validating our spam classifier asserts that it's appropriately classifying e-mails. Of course, there is still a small amount of error, which can be corrected by using more training data. Now, let's try to classify some text using our trained spam classifier, as follows:
user> (classify "Make money fast") [:spam 0.9720416490829515] user> (classify "Job interview today! Programmer job position for GNU project") [:ham 0.19095646757667556]
Interestingly, the text "Make money fast" is classified as spam and the text "Job interview … GNU project" is classified as ham, as shown in the preceding code. Let's have a look at how the trained classifier extracts features from some text using the extract-features function. Since the classifier will initially have read no tokens, this function will obviously return an empty list or nil when the classifier is untrained, as follows:
user> (extract-features "some text to extract")
(#clj_ml5.spam.TokenFeature{:token "some", :spam 91, :ham 837}
#clj_ml5.spam.TokenFeature{:token "text", :spam 907, :ham 1975}
#clj_ml5.spam.TokenFeature{:token "extract", :spam 3, :ham 5})As shown in the preceding code, each TokenFeature record will contain the number of times a given word is seen in spam and ham e-mails. Also, the word "to" is not recognized as a feature since we only consider words comprising of three or more characters.
Now, let's check how sensitive to spam e-mail our spam classifier actually is. We'll first have to select some text or a particular term that is classified as neither spam nor ham. For the training data selected for this example, the word "Job" fits this requirement, as shown in the following code. Let's train the classifier with the word "Job" while specifying the type of the text as ham. We can do this using the train! function, as follows:
user> (classify "Job") [:unsure 0.6871002132196162] user> (train! "Job" :ham) #<Agent@1f7817e: 1993> user> (classify "Job") [:unsure 0.6592140921409213]
After training the classifier with the given text as ham, the probability of the term being spam is observed to decrease by a small amount. If the term "Job" occurred in several more e-mails that were ham, the classifier would eventually classify this word as ham. Thus, the classifier doesn't show much of a reaction to a new ham e-mail. On the contrary, the classifier is observed to be very sensitive to spam e-mails, as shown in the following code:
user> (train! "Job" :spam) #<Agent@1f7817e: 1994> user> (classify "Job") [:spam 0.7445135045480734]
An occurrence of a particular word in a single spam e-mail is observed to greatly increase a classifier's predicted probability of the given term belonging to a spam e-mail. The term "Job" will subsequently be classified as spam by our classifier, at least until it's seen to appear in a sufficiently large number of ham e-mails. This is due to the nature of the chi-squared distribution that we are modeling.
We can also improve the overall error of our spam classifier by supplying it with more training data. To demonstrate this, let's cross-validate the classifier with only one-tenth of the sample data. Thus, the classifier would be effectively trained with nine-tenths of the available data, as follows:
user> (train-and-cv-classifier 1/10)
total : 300 100.00 %
correct : 294 98.00 %
false-positive : 0 0.00 %
false-negative : 1 0.33 %
missed-ham : 3 1.00 %
missed-spam : 2 0.67 %
nilAs shown in the preceding code, the number of misses and wrongly classified e-mails is observed to reduce when we use more training data. Of course, this is only shown as an example, and we should instead collect more e-mails to feed into the classifier as training data. Using a significant amount of the sample data for cross-validation is a good practice.
In summary, we have effectively built a spam classifier that is trained using Fisher's method. We have also implemented a cross-validation diagnostic, which serves as a kind of unit test for our classifier.