
Chapter 3: Enterprise Data Security, Including Secure Cloud and Virtualization Solutions
An organization must ensure that proper due diligence and due care are exercised when considering the storage and handling of data. Data will be stored and accessed across complex, hybrid networks. Data types may include sensitive data, intellectual property, and trade secrets. Regulatory compliance and legal requirements will need to be carefully considered when planning for the storage and handling of data. Data needs to be labeled and classified according to the business value, controls put in place to prevent data loss, and an alert needs to be raised if these controls have any gaps. We need to plan how to handle data throughout the life cycle, from creation/acquisition to end of life. We must understand the implications of storing our data with third parties, such as B2B partners and cloud providers. We must ensure that appropriate protection is applied to data at rest, in transit, and in use.
In this chapter, we will cover the following topics:
- Implementing data loss prevention
- Implementing data loss detection
- Enabling data protection
- Implementing secure cloud and virtualization solutions
- Investigating cloud deployment models
- Extending appropriate on-premises controls
- Examining cloud storage models
Implementing data loss prevention
It is important to identify sensitive data and put in place preventative controls to control the unwanted exfiltration or leakage of this data. There are many different controls for managing this requirement. We can use policy to ensure that correct data handling and operational procedures are followed. We can use DLP filters at the network egress points, using capability within our Next Generation Firewall (NGFW) or Unified Threat Management (UTM) appliance. Your cloud provider may offer Cloud Access Security Broker (CASB), protecting your organization when users access the cloud. Microsoft365 offers this protection with a collection of pre-set rules and templates that can be applied. We will look at some additional methods within this section.
Blocking the use of external media
To prevent the local exfiltration of sensitive data, it is important to put in place local controls, also known as Group Policy or Local Policy, for Windows workstations. Mobile Device Management (MDM) could be used to disable access to mobile devices' external storage. When considering non-Windows systems (macOS, Linux, Unix, and so on), Group Policy will not be an option, so restrictions could be addressed by scripting or configuration files. Figure 3.1 shows Group Policy options for the blocking of removable storage:

Figure 3.1 – Group Policy for controlling removable storage
Group policy offers a comprehensive range of enhancements and restrictions for Windows operating systems.
Print blocking
It is important to recognize other means of exfiltrating data from systems. Screengrabs and the printing of sensitive information should also be restricted. By way of an experiment, open your mobile banking application and try to use the print screen function. You will not be able to perform this action. To restrict unauthorized printing, Digital Rights Management (DRM) can be utilized for sensitive documents, as shown in Figure 3.2:

Figure 3.2 – DRM controls
Remote Desktop Protocol blocking
Due to the widespread use of Virtual Desktop Infrastructure (VDI) and remote support capabilities, this is also an area that requires careful consideration and appropriate security controls. We can use robust authentication and authorization to restrict the use of this technology. Figure 3.3 shows an example of a remote desktop being disabled:
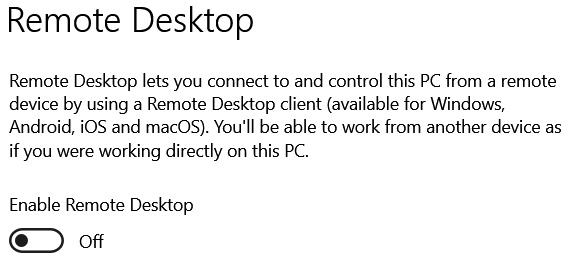
Figure 3.3 – Remote Desktop controls
If it is necessary to make provision for a Remote Desktop Protocol (RDP) to access a desktop for administration or business productivity, then controls should be implemented to control functionality within the session. These controls should include the following:
- Clipboard privacy controls
- Remote audio capabilities
- Access to local storage
- Plug and play devices
In Figure 3.4, we can some of the restrictions available through Group Policy to control access to resources during a remote session:

Figure 3.4 – Restricted VDI implementation
RDP configuration allows for granular controls to be applied to the session.
Implementing data loss detection
It is not always possible to implement a 100% Data Loss Protection (DLP) solution, since a determined insider threat actor may find a workaround. In this case, the objective may be to identify the threat. So, we will now look at methods to detect how the data was exfiltrated from our organization.
Watermarking
If an organization wants to detect the theft or exfiltration of sensitive data, then documents can be checked out from an information system, but an automatic watermark will be applied to the document using the identity of the user who checked out the document, as shown in Figure 3.5. If the document is shared or printed, it will clearly show that user's identity.

Figure 3.5 – Watermarking
This type of control is also used to deter the user from distributing protected content.
Digital rights management
Digital rights management (DRM) is used to protect digital content, typically copyright material. It can be applied to most digital media types. Examples include video, images, books, music, and software code. Usually, it allows the copyright owner to control the publishing of content and receive payment for their work.
You may have been restricted from printing an Adobe document or found that you are unable to highlight a section of text to copy – this is an example of DRM.
It is also useful within an enterprise for allowing the protection of sensitive document types and can be a useful addition to existing DLP solutions.
Network traffic decryption/deep packet inspection
In some cases, it may be necessary to inspect traffic that has been encrypted. A common deployment is a Secure Sockets Layer (SSL) decryptor. This allows an organization to decrypt the outgoing packets to apply enterprise DLP rulesets. Careful consideration is required when implementing this technology as our users would not want their employers to monitor connections to their personal bank account sessions. The whitelisting of URLs would be one approach to consider in this regard.
Network traffic analysis
When the detection of data leakage or exfiltration is being considered, one of the common methods is to analyze data flows, in terms of both volume and content. We could use this information to identify unusual user behaviors, such as high volumes of research data being uploaded to Cloud Data Networks (CDNs).
Enabling data protection
It is important to address all aspects of the Confidentiality Integrity Availability (CIA) triad. We need to understand the importance of data and label or classify accordingly. We must ensure that data is protected from unauthorized access and that integrity is maintained. Data must also be made available so that business functionality can be maintained.
Data classification
The appropriate data owner needs to be consulted within the enterprise to establish the classification of data to ensure that appropriate controls are implemented.
Due to the amount of data that is typically held by large enterprises, automation is a common approach. For example, keyword or string searches could be utilized to discover documents containing a driver's license number, social security number, debit card numbers, and so on. We have data classification blocking where necessary to prevent data leakage. In Figure 3.6, we can see categories that could be used to label data:

Figure 3.6 – Data type tagging
Metadata/attributes
Metadata is the data that describes data. Metadata can be very useful when searching across stores with large files. We can tag data using common attributes or store the data within the file itself. Figure 3.7 shows metadata data of an image:

Figure 3.7 – Metadata store alongside an image file
Attributes are used with tags; they consist of the identifier followed by a value, as shown in Figure 3.8:

Figure 3.8 – Document attributes
Data labeling or tagging allows data to be handled appropriately according to the importance/value of the data. Once we have established the data type and labeled it accordingly, we can look to automate the management of the data (retention settings, archiving, and so on). In Figure 3.9, we can see data classification being applied to a folder within the filesystem:
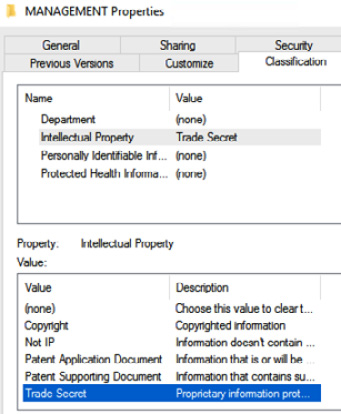
Figure 3.9 – Data labeling
Microsoft file servers allow for classification labels enabled within Directory Services.
Obfuscation
Obfuscation is defined in the Oxford dictionary as the act of making something less clear and more difficult to understand, usually deliberately. We can use this approach to protect data.
It is important to protect data in use and data at rest, and there are many ways to achieve this, including strong Access Control Lists (ACLs) and data encryption. When considering the use of records or processing transactions, certain strings or keys may be hidden from certain parts of the system. Here are some common approaches:
- Data tokenization: This is often associated with contactless payments. Your debit card is implemented in the Google Pay app as a token. The bank allocates a unique token to your mobile app but your actual payment details (including the security code on the reverse of the card) are not stored with the token.
- Data scrubbing: This can be used to detect or correct any information in a database that has some sort of error. Errors in databases can be the result of human error in entering the data, the merging of two databases, a lack of company-wide or industry-wide data coding standards, or due to old systems that contain inaccurate or outdated data. This term can also be used when data has been removed from log files; the user is likely hiding the evidence.
- Data masking: This is a way to create a bogus, but realistic, version of your organizational data. The goal is to protect sensitive data while providing a practical alternative when real data is not needed. This would be used for user training, sales demos, or software testing. The format would remain the same, but, of course, the original data records would not be visible.
The data masking process will change the values of the data while using the same format. The goal is to create a version that cannot be deciphered or reverse engineered.
Anonymization
The use of big data and the use of business intelligence presents significant regulatory challenges. Take, for example, a situation where governments need to track the effectiveness of strategies during a pandemic. A goal may be to publish the fact that 25,000 citizens within the age range of 65-75 years old have been vaccinated within the city of Perth (Scotland). It should not be possible to extract individual Personally Identifiable Information (PII) records for any of these people. Fraser McCloud, residing at 25 Argyle Avenue, telephone 01738 678654, does not expect his personal details to be part of this published information.
Encrypted versus unencrypted
One method to addressing confidentiality would be to encrypt sensitive data. The overhead, however, means that it is important to identify files or records that meet the criteria for encryption. Data that has no value or sensitivity label should be stored unencrypted. We can use database encryption or file encryption for data at rest. For data in transit, we should use Transport Layer Security (TLS) or IPSEC tunnels.
Data life cycle
It is important to have a plan and organizational policies and procedures to manage data throughout the life cycle, from the initial creation or capture of the data to the point where the data is no longer required. Without knowledge of the data we hold, the importance of the data, and a plan to manage it, we cannot ensure good governance of the data. In Figure 3.10, we can see a five-step process depicting the data life cycle:
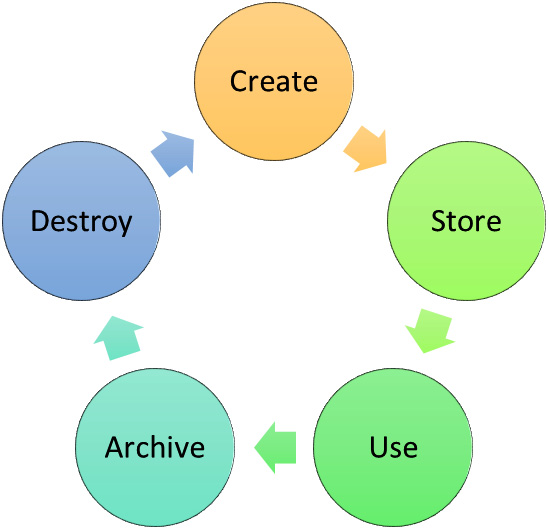
Figure 3.10 – Data life cycle
The following is a detailed explanation of the various stages of the data life cycle shown in Figure 3.10:
- Create: Phase one of the life cycle is the creation/capture of data. Examples include documents, images, mapping data, and GPS coordinates.
- Store: We must store the data within appropriate systems, including file shares, websites, databases, and graph stores.
- Use: Once the data is held within our information system, we must ensure that data governance is applied. This means classifying data, protecting data, and retaining it. We must ensure we take care of legal and regulatory compliance.
- Archive: Data should be preserved to meet regulatory and legal requirements; this should map across to data retention policies.
- Destroy: Data should be purged based upon regulatory and legal requirements. There is no business advantage in retaining data that is not required. When we store data for too long, we may be more exposed as a business in the event of a lawsuit. A legal hold would require a business to make available all records pertaining to the lawsuit.
Data inventory and mapping
Data inventory allows an enterprise to gain visualization of the data that is held and where it is physically located. Any access will be logged and audited. Data mapping can help an organization understand how the data is used and who owns the data.
Data integrity management
The data held by an organization can be critical for business processes to be completed. The data that is held and processed could include sales order processing, records in a CRM database, and financial transactions in a bank.
There are many ways to guarantee the authenticity of data, including File Integrity Monitoring (FIM). Data could become corrupt, or your organization may be targeted with crypto-malware. Consequently, there must be a plan to recover the data to its previous state.
Data storage, backup, and recovery
Due to the complexities of a modern hybrid computing model, backups and the subsequent restoration of data can be a big challenge. Is the data on-premises or held by a third-party cloud provider? Who is responsible for data backup and restoration?
When planning for data backups, we need to refer to legal and regulatory requirements, as well as operational requirements for the actual routines we will put in place. As regards operational planning, think about Data Retention Policy (DRP) and Business Continuity Planning (BCP), especially in relation to Recovery Point Objectives (RPOs).
It may be cost-effective to back up a directory to cloud storage, often costing a few cents per GB per month.
Types of backups could also be very important. If working with limited time windows to complete full backups every day, then incremental or differential backup types should be considered.
Full backup
A full backup will back up all the files in the backup set every time it is run. Imagine this is a Network Attached Storage (NAS) array containing 100 terabytes of data. It may take a significant amount of time to back up all the data every day, while also considering the storage overheads.
The advantages are as follows:
- A full backup of the dataset every time
- Quick to restore (only a single backup set is required)
The disadvantages are as follows:
- It is time-consuming.
- Additional storage space is required.
Differential backup
A differential backup is usually run in conjunction with a full backup. The full backup would be run when there is a generous time window, on a Sunday, for example. Each day, the differential backup would back up any changes since Sunday's full backup. So, Monday's backup would be relatively quick, but by the time Friday's differential backup is run, it will have grown to perhaps five times the size of Monday's backup.
The advantages are as follows:
- It is quicker than a full backup.
- It is quicker to restore than an incremental backup (only two backup sets are required – the full differential and the last differential)
The disadvantage is as follows:
- Additional storage space is required (over and above the incremental backup).
Incremental backup
An incremental backup is usually run in conjunction with a full backup. The full backup would be run when there is a generous time window – Sunday, for example. Each day, the incremental backup would back up any changes since the previous backup. So, each daily incremental backup would take approximately the same amount of time, while the volume of data stored would be similar.
The advantages are as follows:
- It is the quickest to back up.
- It requires the least amount of storage space.
The disadvantage is as follows:
- It is the slowest to restore (all the backup datasets will be required)
Redundant array of inexpensive disks
When we need to provide for high availability, with data storage in mind, it is important to consider the Redundant Array Of Inexpensive Disks (RAID) implementations available. With the majority of the first line enterprise storage residing within Storage Area Networks (SANs) or hosted on Network Attached Storage (NAS), it is normally these applications that will host the redundant storage. Here are some of the most popular RAID types:
- RAID 0: This is used to aggregate multiple disks across a single volume. It will allow for fast disk I/O operations, and there is no redundancy (hence the 0). It achieves this performance by spreading the write operations across multiple physical disks. It also speeds up read operations by a similar margin (25-30%). This requires two or more disks, as shown in Figure 3.11:
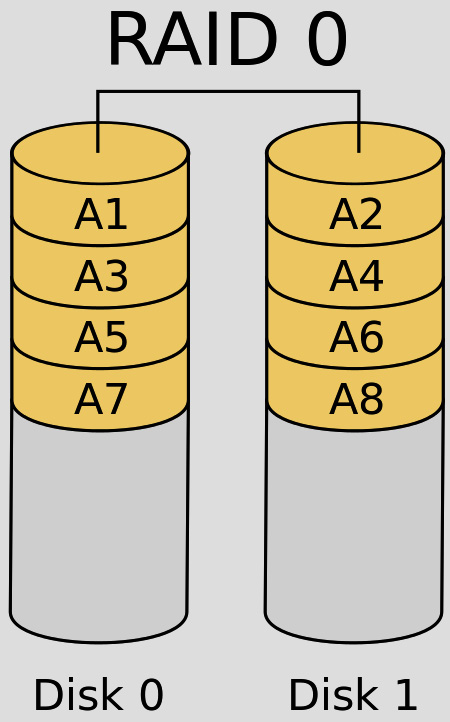
Figure 3.11 – RAID 0 disk striping
The advantages of RAID 0 are as follows:
- Read/write operations are fast.
- Efficient use of available storage (100% of the disks are available for data).
- It is a simple solution to deploy.
The disadvantage of RAID 0 is as follows:
- There is no fault tolerance. If we lose one physical disk, then the volume is unavailable.
- RAID 1: This is disk mirroring and uses two disks. The data is written to both disks synchronously, creating a mirror of the data. There is no real performance gain when deploying this RAID level (compared to a single disk). If one of the mirrored disks fails, we can continue to access the storage. Figure 3.12 shows an example of RAID 1 disk mirroring:

Figure 3.12 – RAID 1 disk mirroring
The advantages of RAID 1 are as follows:
- RAID 1 offers good read and write speed (it is equal to that of a single drive).
- If a drive fails, the data does not have to be rebuilt; it is copied to the replacement drive (which is a quick process).
- RAID 1 is a very simple technology.
The disadvantage of RAID 1 is as follows:
- The effective storage capacity is only half of the total drive capacity because all the data is written twice.
- RAID 5: This uses a minimum of three disks. The data is written to all disks synchronously, creating a single logical disk. There is a performance gain for read operations. If one of the RAID 5 disks fails, we can continue to access the storage. This technology uses a single parity stripe to store the redundant data, as shown in Figure 3.13:
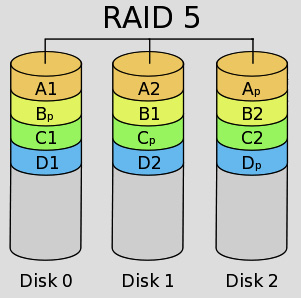
Figure 3.13 – RAID 5 striping with parity
The advantages of RAID 5 are as follows:
- Read operations are very fast, while write data transactions will be slower (due to the parity that must be calculated).
- If one drive fails, you still have access to your data.
The disadvantages of RAID 5 are as follows:
- Write operations can cause latency (in calculating the parity value).
- Drive failures will slow down access (every read operation will require a parity calculation).
- The rebuild time, following a failure, can be lengthy.
- RAID 6: This uses a minimum of four disks. The data is written to all disks synchronously, creating a single logical disk. There is a performance gain for read operations. If two of the RAID 6 disks fail, we can continue to access the storage. This technology uses a dual parity stripe to store the redundant data, as shown in Figure 3.14:

Figure 3.14 – RAID 6 dual stripe with parity
The advantages of RAID 6 are as follows:
- Read operations are very fast, while write data transactions will be slower (due to the parity that must be calculated).
- If two drives fail, you still have access to your data.
The disadvantages of RAID 6 are as follows:
- Write operations can cause latency (in calculating the parity value) that exceeds that of RAID 5 as two parity calculations must be performed during each write operation.
- Drive failures will slow down access (every read operation will require a parity calculation).
- The rebuild time, following a failure, can be lengthy (and longer still if two drives have failed).
- RAID 10: This uses a minimum of four disks. It combines RAID 0 and RAID 1 in a single system. It provides security by mirroring all data on secondary drives while using striping across each set of drives to speed up data transfers, as shown in Figure 3.15:

Figure 3.15 – RAID 10 nested raid 1 + 0
The advantages of RAID 10 are as follows:
- Fast read and write operations (no parity calculation to worry about)
- Fast recovery from a failed disk; the rebuild time is quick
The disadvantage of RAID 10 is as follows:
- 50% of the available storage is lost to the mirror (much less cost-effective than striping with parity).
Implementing secure cloud and virtualization solutions
Virtualization allows software to control access to the underlying hardware. It uses a thin layer of code to control access to resources, including networking, CPU, storage, and memory.
Pretty much any compute node can be run virtually on top of a software layer. This software layer is the hypervisor. User desktops, email servers, directory servers, switches, firewalls, and routers are just a few examples of virtual machines (VMs).
Virtualization allows for more flexibility in the data center, rapid provisioning, and scalability as workloads increase. Additional benefits include reducing an organization's footprint in the data center (less hardware, reduced power, and so on). Figure 3.16 shows resources being allocated to a virtual guest operating system using Microsoft Hyper-V:
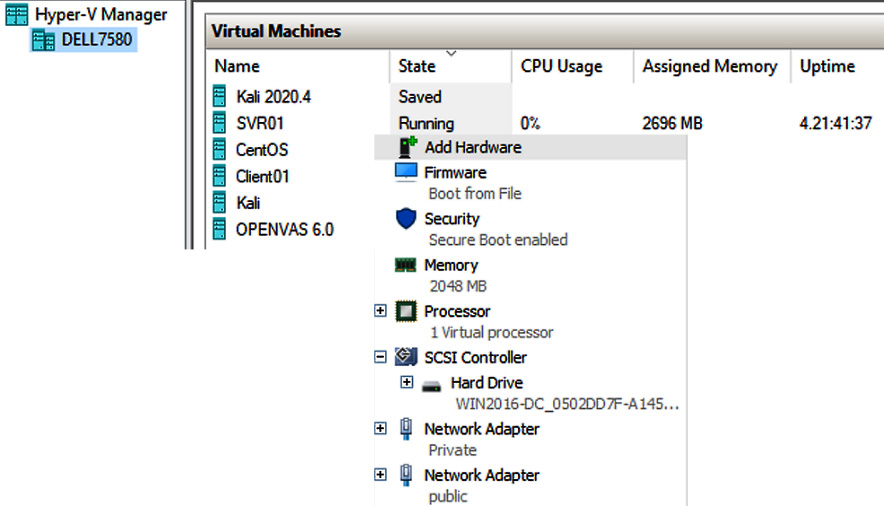
Figure 3.16 – Microsoft Hyper-V
Virtualization strategies
When considering virtualization, an important choice will be the type of hypervisor. If you are planning for the computing requirements of the data center, then you will need to choose a bare-metal hypervisor, also known as Type 1. This is going to require minimal overhead, allowing for maximum efficiency of the underlying hardware. Testing and developing may require desktop virtualization tools, where compatibility will be important. If we need to move the development virtual workloads into production, it makes sense to choose compatible models, for example, VMWare Workstation for the desktop and VMWare ESXi for the production data center. Application virtualization may also be a useful strategy when we have a mixture of desktop users, where compatibility may be an issue. Containers should also be considered for their efficient use of computing resources.
Type 1 hypervisors
In effect, a type 1 hypervisor takes the place of the host operating system. Type 1 tends to be more reliable as they are not dependent on their underlying operating system and have fewer dependencies, which is another advantage. Type 1 hypervisors are the default for data centers. While this approach is highly efficient, it will need management tools to be installed on a separate computer on the network. For security, this management computer will be segmented from regular compute nodes. Figure 3.17 shows the diagram of Type 1 hypervisors:

Figure 3.17 – Type 1 hypervisor
Examples of type 1 hypervisors include the following:
- A VMware Elastic Sky X Integrated (ESXi) hypervisor.
- Hyper-V is Microsoft's hypervisor designed for use on Windows systems.
- Citrix XenServer, now known as Citrix Hypervisor.
- The Kernel-Based Virtual Machine (KVM) hypervisor is used on Linux. This hypervisor is built directly into its OS kernel.
- Oracle VMServer for x86 incorporates the free and open source Xen hypervisor technology.
Type 2 hypervisors
A type 2 hypervisor requires an installed host operating system. It is installed as an additional software component. It is a useful tool for any job role that requires access to more than one operating system. This type of hypervisor would allow an Apple Mac user to run native Microsoft Windows applications using VMware Fusion.
The reason type 2 hypervisors are not suitable for the data center is that they are not as efficient as type 1 hypervisors. They must access computing resources from the main installed host operating system. This will cause latency issues when dealing with enterprise workloads. Type 2 is more common when we require virtualization on a desktop computer for testing/development purposes. Figure 3.18 type 2 hypervisors:
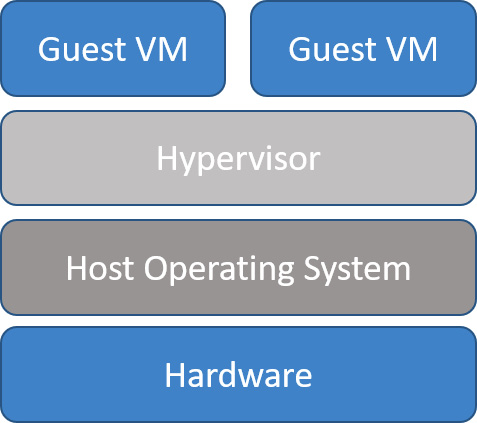
Figure 3.18 – Type 2 hypervisor
Examples of type 2 hypervisors include the following:
- VMware Fusion: Allows Mac users to run a large range of guest operating systems.
- VMware Workstation: Allows Linux and Windows users to run multiple operating systems on a single PC.
- VMware Player: This is free but only supports a single guest OS.
- Oracle VirtualBox: Can run on Linux, macOS, and Windows operating systems. It is a free product.
Security considerations for virtualization
VM escape is a term used for an exploit where an attacker uses a guest operating system (VM) to send commands directly to the hypervisor. Vendors such as VMware and Microsoft will pay $250,000 to bounty hunters if they have a workable model, such is the importance associated with this threat. This is not a common type of attack, although there have been a number of instances of compromised hypervisor exploits in the past. In 2008, CVE-2008-0923 was posted. This documents a vulnerability on VMware Workstation 6.0.2 and 5.5.4 making a VM escape possible.
VM sprawl Describes unmanaged and unpatched VMs installed on the hypervisor platform. This makes the hypervisor host vulnerable to exploits such as backdoor access or could result in reduced levels of available services.
Containers
Containers are a more efficient way of deploying workloads in the data center. A container is a package containing the software application and all the additional binary files and library dependencies. Because the workload is isolated from the host operating system, any potential bugs or errors thrown by the container-based application will not affect any other applications.
Containers allow for isolation between different applications. It is important to consider the security aspects of containers. If we are using a cloud platform, we need to be sure that we have segmentation from other customers' containers.
Containers allow easy deployment on multiple operating system platforms and make migration an easy process. They have a relatively low overhead as they do not need to run on a VM.
To support containers, you will need a container management system (often called the engine); the most popular product at the moment is Docker. There are versions of Docker that developers can run on their desktops, to then migrate into the data center. Figure 3.19 shows a container:

Figure 3.19 – Containers
Emulation
Emulation allows for the running of a program or service that would not run natively on a given platform. Examples could include running legacy arcade games on a modern computer by installing an emulator program. Terminal emulators are used to remote to another device, replacing the need to connect a serial cable direct from a terminal to a network appliance. Linux commands can be used on a Windows 10 desktop computer by emulating the Linux command shell, as shown in Figure 3.20:

Figure 3.20 – Windows 10 Linux Bash shell (emulation)
Application virtualization
Application virtualization can be useful when there is a need to support a Line of Business (LOB) application or a legacy application across multiple platforms. We can publish an application on a Microsoft (Remote Desktop Services) server and host multiple sessions to that single deployed application across an RDP connection. To scale out to an enterprise, we could deploy a server farm. We could, for example, access Windows applications from a Linux host using this deployment model. We also allow the application to be streamed across the network and run locally. Microsoft calls this technology App-V. Citrix has a similar technology, named XenApp. Figure 3.21 shows application virtualization:
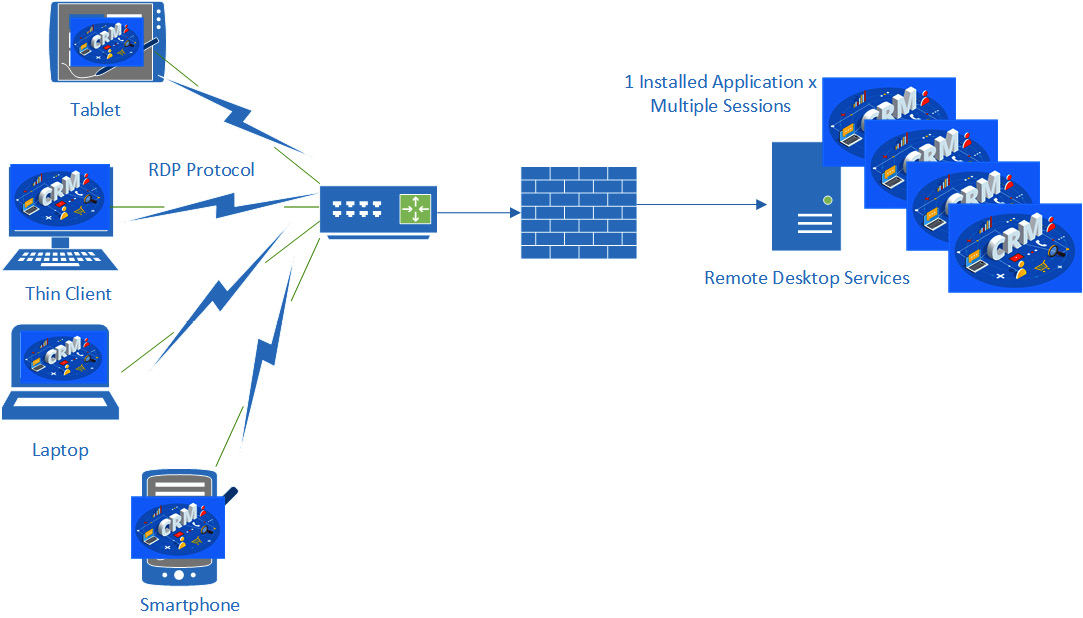
Figure 3.21 – Application virtualization
VDI
VDI allows the provision of compute resources to be controlled from within the data center or cloud. A typical model is an employee using a basic thin client to access a fully functional desktop with all required applications. The user can access their desktop using any device capable of hosting the remote software. Microsoft has an RDP client that can run on most operating systems. The advantages of this approach are resilience, speed of deployment, and security. Figure 3.22 shows a VDI environment:
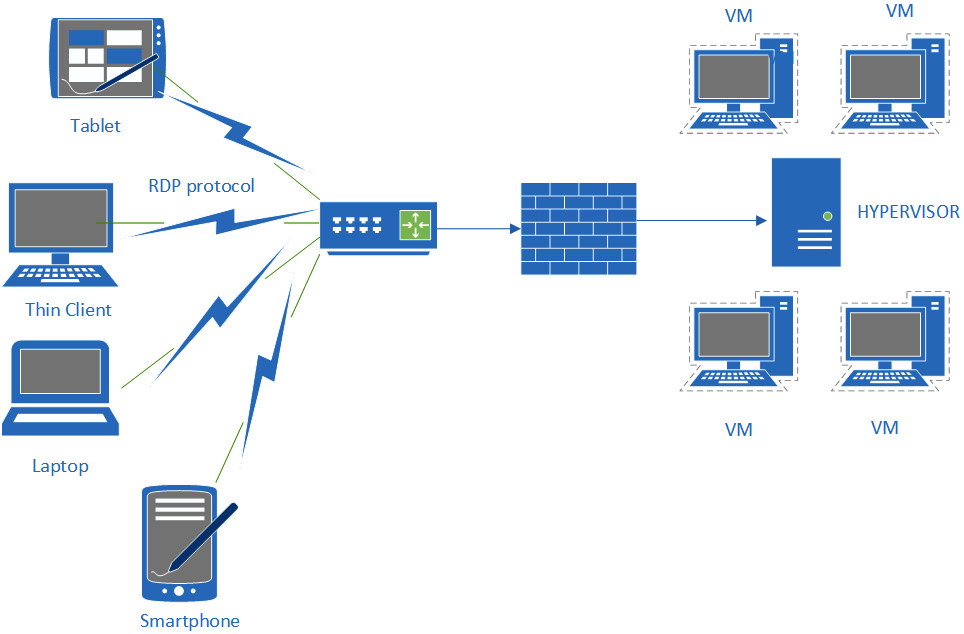
Figure 3.22 – VDI environment
Provisioning and deprovisioning can be automated for VM instances or container deployments. Orchestration tools could be used in an enterprise. For small-scale deployments, templates are created and VMs can be easily built and deployed when needed. Figure 3.23 shows how you can provision a VM:

Figure 3.23 – VM provisioning
For more granular and configurable provisioning options, we may use tools such as Microsoft System Center Virtual Machine Manager (SCVMM) or the VMware vSphere suite of tools. To orchestrate the deployment of containers, we would use tools such as Kubernetes.
It is important to consider all available options when supporting workloads in data centers, giving business users access to tools, allowing for access to multiple operating systems, or allowing non-compatible applications to be accessed from a desktop. Organizations need to consider the benefits of reducing their footprint in the data center by making better use of computing resources.
Investigating cloud deployment models
Cloud computing has been a mainstay service for many years, becoming more accepted as a serious business model as many enterprises move to more hybrid networks. The power of the cloud is based upon flexibility. There is a much-used phrase, Elastic Cloud, which represents cost savings and scalability. It is estimated that around 50% of enterprise workloads are hosted by cloud providers and around 46% of data is hosted in the cloud (based upon estimates for 2021). Growth rates are predicted to remain high. There are many cloud providers; however, the current market leaders are Amazon Web Services (AWS), Microsoft Azure, and Google.
Deployment models and considerations
When considering a Cloud Service Provider (CSP), many considerations will affect this important enterprise decision.
Cybersecurity
The most critical consideration is cybersecurity. When we are storing data, such as intellectual property, PII, PHI, and many other types of data, we must consider all the risks before deploying cloud models.
Business directives
Does the CSP align with our regulatory requirements? Government agencies will only be able to work with providers who meet the FedRAMP criteria. Federal Risk and Authorization Management Program (FedRAMP) is a US government-wide program that provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services. Amazon Web Services (AWS) and Microsoft Azure cloud offerings have multiple accreditations, including PCI-DSS, FedRAMP, ISO27001, and ISO27018 to name but a few.
Cost
The cost of operating services in the cloud is one of the most important drivers when choosing a cloud solution. Unfortunately for the Chief Financial Officer (CFO), the least expensive may not be a workable solution. Certain industries are tied into legal or regulatory compliance, meaning they will need to consider a private cloud or, in some cases, community cloud models.
Scalability
What scalability constraints will there be? It was interesting in early 2020 when organizations were forced to adopt a much more flexible remote working model, which fully tested the scalability of the cloud. Web conferencing products such as Zoom and Microsoft Teams reported a 50% increase in demand from March to April 2020.
Resources
What resources does the CSP have? Many CSPs operate data centers that are completely self-sufficient regarding power, typically powered by renewable energy (wind farms, hydroelectric, and the like). How many countries do they operate in? Do they have data centers close to your business? Do they have a solid financial basis?
Location
The location of the CSP data centers could be critically important. Think about legal issues relating to data sovereignty and jurisdiction. Also, does the provider offer redundancy using geo-redundancy. If the New York data center has an environmental disaster, can we host services in the Dallas data center?
Data protection
We must ensure that we can protect customer data with the same level of security as on-premises data stores. We would need to ensure data is protected at rest and in transit.
In Figure 3.24, we can see the main options for cloud deployment models:

Figure 3.24 – Cloud deployment models
Private cloud
A private cloud allows an enterprise to host their chosen services in a completely isolated data center. Legal or regulatory requirements may be the deciding factor when looking at this model. Economies of scale will often result in a higher cost when implementing this model. Government agencies, such as the Department of Defense (DoD), are prime candidates for the security benefits of this approach. The United Kingdom's Ministry of Defence (MoD) has been a user of the private cloud since 2015, awarding a multi-million-pound contract for the use of Microsoft 365 services. In the USA, the DoD has followed suit, also signing up for multi-billion dollar contracts with Microsoft and Amazon.
Government requirements are very strict. Currently, there are two ways to provide cloud services to the United States government. One approach is to go through the Joint Authorization Board (JAB) or directly through a government agency, the requirements are strict, and there is a requirement for continuous monitoring. The program is managed as part of The Federal Risk and Authorization Management Program (FedRAMP). To allow a CSP to prepare for this process, there are baseline security audit requirements and additional documentation available through the following link: https://www.fedramp.gov/documents-templates/.
Public cloud
Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) are examples of public cloud providers. They offer a service in which you can enroll and configure your workloads.
Public cloud providers operate from large geolocated data centers to offer services to a wide range of customers.
Range International Information Group hosts the world's largest data center. It is located in Langfang, China. It covers an area equivalent to 110 football pitches (around 6.3 million square feet). In comparison, Microsoft's main Dublin data center occupies an area of around 10 football pitches.
Millions of global customers are using this model. There is more flexibility and less commitment when using the public cloud.
Most cloud providers' customers will benefit from this shared model, achieving cost savings compared with the private cloud.
Hybrid cloud
A hybrid cloud allows an organization to use more than one cloud model. For example, a utility provider delivering critical infrastructure may be required by regulatory compliance to host critical services in a private cloud. The sales and marketing division of the same enterprise may want to use business productivity tools such as salesforce.com using a cost-effective public cloud model. A hybrid cloud allows an enterprise to meet operational requirements using a blended model.
A community cloud allows organizations operating within the same vertical industry to share costs. They may have the same strict regulatory requirements not suited to a multi-tenant public cloud, but can still look to benefit from a shared cost model. Obviously, they will not achieve the same cost savings as public cloud customers.
Hosting models
When you choose a cloud deployment model, you have, in effect, signed up for either a totally isolated data center or a shared experience. Think of where you live. If you are wealthy, then you can afford to live in a secure compound with your own private security team. If you don't have that sort of money, then maybe you could live in a secure gated community (think community cloud). If you don't want to spend too much of your salary on housing, then maybe you could rent an apartment within a building, sharing common walkways and elevators (think public cloud). However, other options are available.
If you pay the least amount of money possible to host services in a public cloud, then you will most likely be using a multi-tenant model. Your hosted web server will be running as a VM alongside other customers' VMs on the same hypervisor. Maybe your database will be hosted on the same server as the other customers using the same schema.
Many public cloud providers will offer single-tenant services, but at a cost. So, the provider has a public cloud, but allows customers to host services on a separate hardware stack. Obviously, they will want to charge more money for this.
Service models
Once you have chosen the cloud deployment model, you can choose the services that your organization will need. It is important to understand the responsibility of the level of involvement that your employees will need. When buying in services for end users' business productivity, you may want to pay a fixed annual cost without any further involvement, or perhaps you need to host critical infrastructure that enables engineers to have total responsibility for a hosted Supervisory Control and Data Acquisition (SCADA) network. Figure 3.25 shows examples of cloud service models:
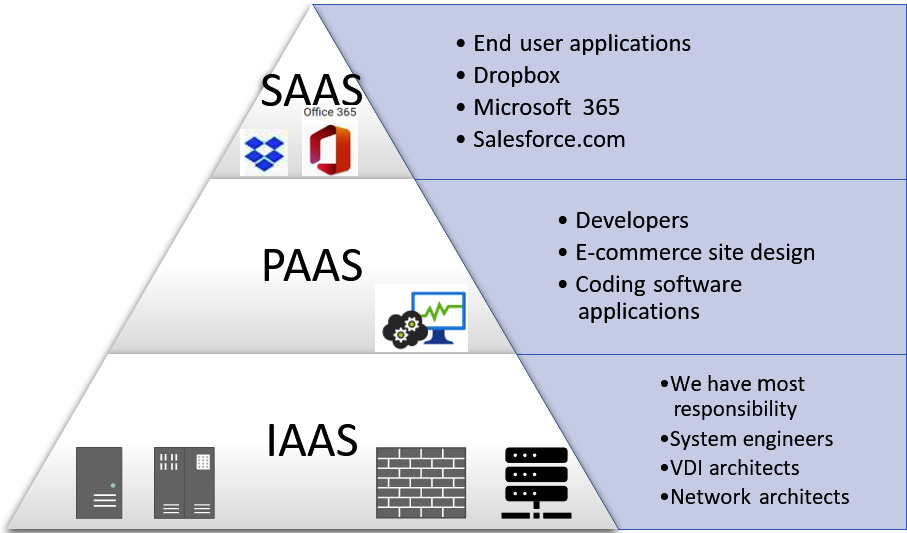
Figure 3.25 – Cloud service model
This simple model helps to define responsibilities when using Cloud Service Providers (CSPs).
Software as a service
Software as a service (SaaS) is where you have the least responsibility. You pay for a license to use a software product or service. Microsoft has a product catalog available for customers to choose from, totaling around 3,000 items.
In a small school, there is no dedicated staff to manage servers and storage or to develop software applications. Instead, the teachers may use Moodle to set work and monitor student progress. They may have Microsoft 365 educational licenses to assign to the students, allowing access to an entire software suite. This is where you would use SaaS. You can see some examples of SaaS applications that can be selected from the Microsoft Azure portal in Figure 3.26:

Figure 3.26 – SaaS catalog
With SaaS, you do not perform any development; you just need to pay for licenses for your users.
Platform as a service
When choosing Platform as a service (PaaS) as a service model, you will be wanting to maintain control of existing enterprise applications while moving the workloads into the cloud. Or you are looking to develop new applications using a CSP to host the workloads. The CSP will deploy an environment for your development team, which may consist of a Linux Enterprise Server, Apache Web Server, and MySQL database.
The servers, storage, and networking will be managed by the CSP, while developers will still have control and management of their applications.
Infrastructure as a service
Infrastructure as a service (IaaS) offers the best solution to enterprises who need to reduce capital expenditure but access a fully scalable data center. The cloud provider will need to provide power, Heating, Ventilation, and Air Conditioning (HVAC), and the physical hardware. But we will manage the day-to-day operations using management tools and application programming interfaces (APIs).
When using IaaS, you will have the most responsibility. You may be managing servers, VDI, access to storage, and controlling network flows. The hardware, however, is managed by the cloud provider.
You would not physically work in the cloud data center, so you cannot install a server in a rack or swap out a disk drive.
It is important to recognize the responsibilities of the CSP and the customer, using the three popular service models. Figure 3.27 shows the responsibilities each party will have:
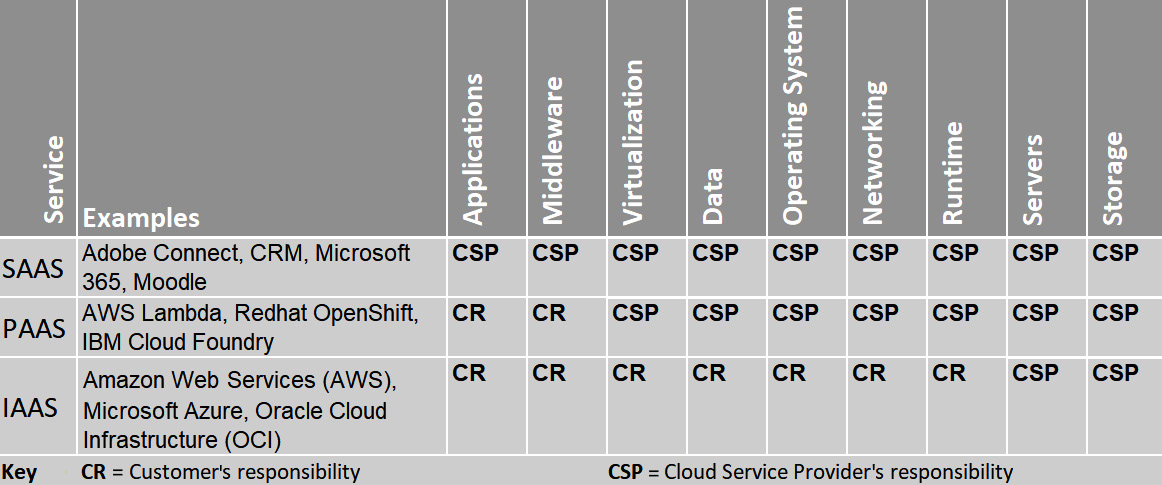
Figure 3.27 – Cloud shared responsibility matrix
This service model matrix will help you to understand the various responsibilities when adopting a service model.
Cloud provider limitations
Most cloud-based services will make the best use of limited public IP addresses. You will most likely find that your virtual network has a Network Address Translation (NAT) gateway with a publicly accessible IP address, leaving you free to allocate your own preferred private addressing scheme. However, to facilitate fast low-latency connections between your hosted networks or a partner, it is not necessary to route traffic through a NAT to access other virtual networks hosted by the same CSP. In this instance, we will use Virtual Private Cloud (VPC) peering.
VPC peering allows connectivity between workloads within a single CSP or allows connectivity with other CSP tenants, such as B2B partners. The advantage of this approach is that traffic is not routed out to the edge of the CSP network and then back to another VPC. It is a much more efficient process whereby a low-latency connection is made directly between the VPCs. This can also be done between different regions. In Figure 3.28, we can see an example of VPC peering:
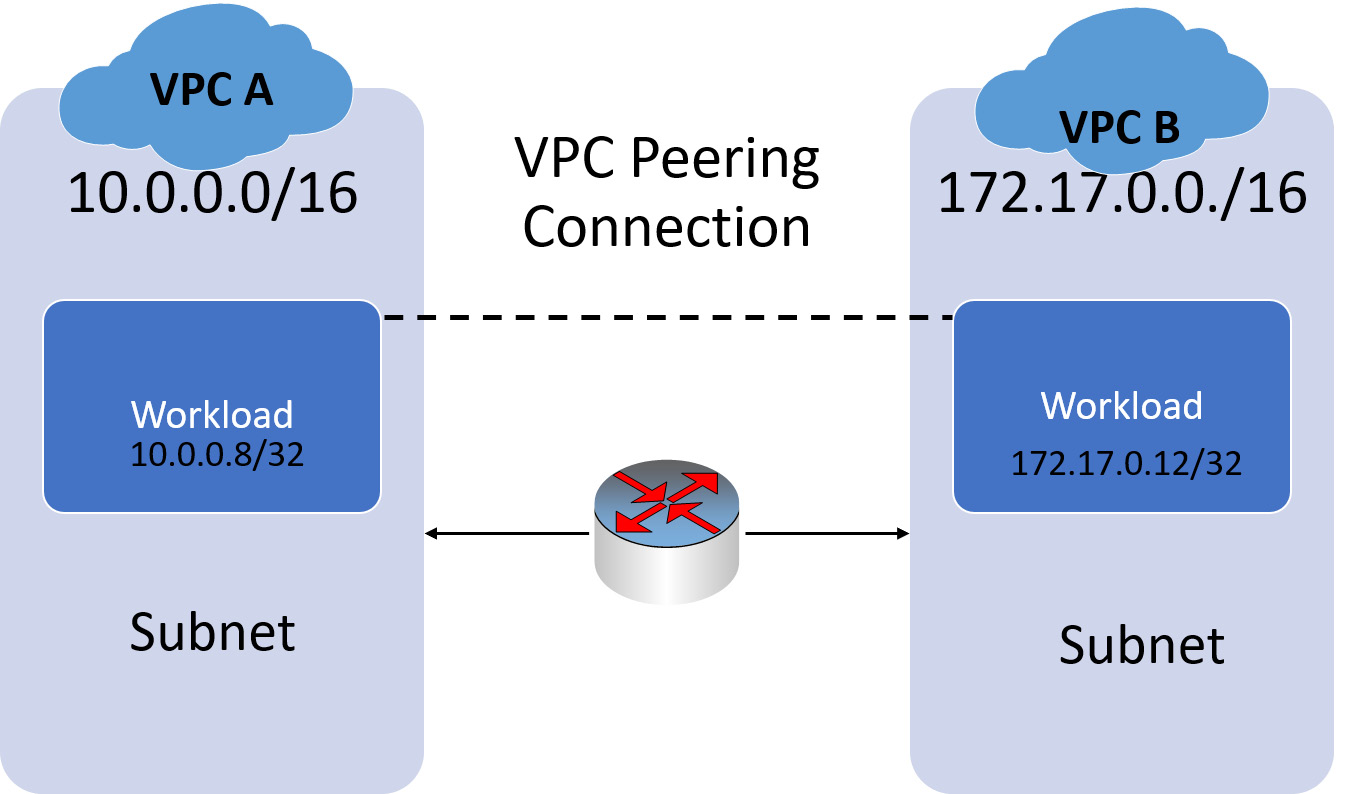
Figure 3.28 – VPC peering
VPC peering is useful for enterprises that need to connect multiple cloud-based workloads.
Extending appropriate on-premises controls
It is important to assess all risks when co-operating with a third-party CSP. Is your data secure? Will it be available? What accreditations does the provider have? Have they been audited by recognized authorities?
Micro-segmentation
Micro-segmentation is used to separate workloads, securely, in your data center or a hosted cloud data center. In practice, this means creating policies that restrict communication between workloads where there is no reason for east-west (server to server) traffic. Network zoning is an important concept and can dynamically restrict communication between the zones when a threat is detected.
Traditional security is based on north-south traffic (data moving through the network perimeter), but now we see thousands of workloads all being hosted within the same data center (inside the perimeter). Virtualization can allow a single hardware compute node to host thousands of VMs. By isolating these workloads using micro-segmentation, we can reduce the attack surface, isolate breaches, and implement more granular policies for given workloads. Figure 3.29 shows an example of isolated workloads in the data center:
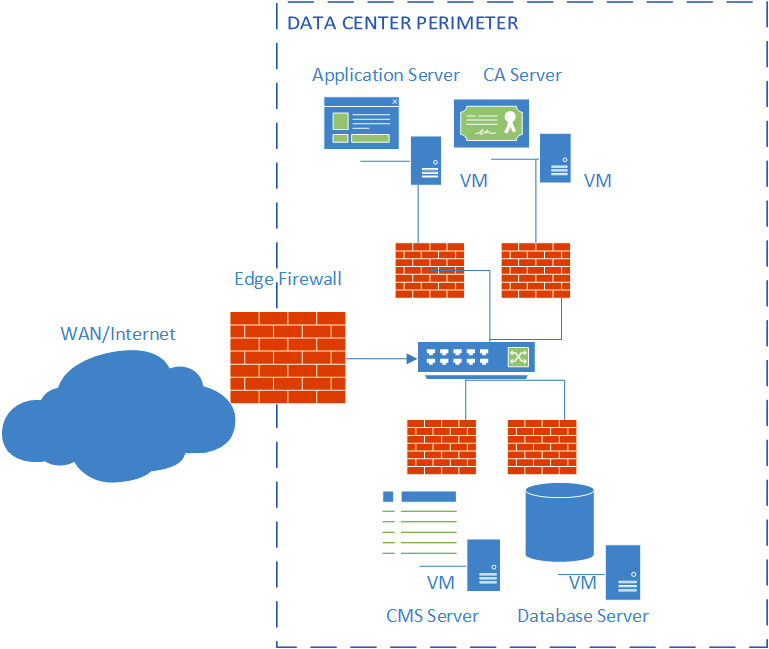
Figure 3.29 – Application-level micro-segmentation
The benefits of this approach is that each individual workload can be secured.
Benefits of micro-segmentation
Organizations that adopt micro-segmentation will gain the following benefits:
- It is a key element of zero-trust architecture.
- A reduced attack surface.
- Improved breach containment.
- Stronger regulatory compliance.
- Streamlined policy management.
Jump box
Remote management is a key requirement when managing on-premises and cloud-based data centers. Network assets will include servers and workloads with valuable data or may host Industrial Control Systems (ICS). To manage these environments, there is a requirement for highly specialized management tools. It would be difficult for an engineer to manage the SCADA systems and monitor sensitive systems without specialist tools hosted on the SCADA network. Likewise, network engineers may need to remote into the data center to offer 24/7 support on critical systems. One approach is to securely connect to a designated server that has secure access to the data center or ICSes. These servers will have the appropriate management tools already installed and the connection will be made from validated trusted external hosts. Figure 3.30 shows an example of where a jump box would be deployed:

Figure 3.30 – Remote administration using a jump box
A Jump box ensures no code or software can be introduced to vulnerable network systems.
Examining cloud storage models
An enterprise will typically create and manage increasingly large volumes of heterogeneous data. We would expect the finance team to store spreadsheets and use finance databases, marketing may create promotional video clips, while transport and logistics planning will need access to graphing and locational data.
This mix of data types means that a single data store is usually not the most efficient approach. Instead, it's more effective to store different types of data in different data stores, each optimized for a specific workload or usage pattern. Therefore, it's important to understand the main storage models and the pros and cons of each model.
File-based storage
These are regular files that are used in a traditional client-server model. Examples would be user-mapped drives accessing shared folders on a NAS device or a file server. Other file types could be VMs hosted by a hypervisor platform.
Database storage
Databases are described as relational and consist of two-dimensional tables with rows and columns. A common vendor approach is to use Structured Query Language (SQL) for retrieving and managing data. This ensures that a record is added or updated only when it can be validated (ensuring the integrity of the data).
A Relational Database Management System (RDBMS) requires a schema, which will consist of allowed objects and attributes. All read or write operations must use the schema. Examples of relational databases include Microsoft SQL, MySQL, PostgreSQL, and Oracle SQL. In Figure 3.31, we can see a user object with associated attributes. This schema is used for the Active Directory database.
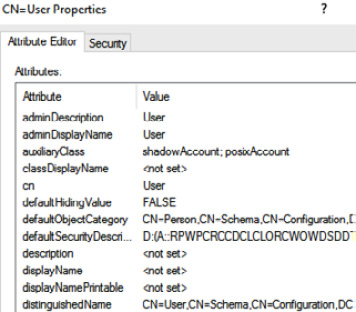
Figure 3.31 – Schema object and attributes
Relational databases support a schema to define objects and attributes allowed within the database.
Block storage
Block storage stores data in fixed-sized chunks called blocks. A block will only store a fragment of the data. This is typically used on a SAN iSCSI or Fiber Channel (FC). Requests are generated to find the correct address of the blocks; the blocks are then assembled to create the complete file. Block storage does not store any metadata with the blocks. Its primary strength is fast performance, but the application and storage need to be local (ideally on a SAN). Performance will degrade if the application and blocks are farther apart. This storage is typically used by database applications.
Blob storage
Object storage is optimized for storing and retrieving large binary objects (images, files, video and audio streams, large application data objects and documents, and virtual machine disk images). To optimize searching through these stores, metadata tags can be linked to a file. These may be customizable by the user (it would be difficult to search through the raw data of a video image). These stores are ideal for large files and large data stores as they will be very scalable.
Key/value pairs
A key/value pair is useful for storing identifiers and values. It is a useful storage type for configuration files or hash lookups, such as rainbow table or any kind of lookup table.
This may be useful when performing a compliance scan. The database could contain a series of identifiers and the actual value it is expecting to be set.
Summary
In this chapter, you have gained an understanding of the security considerations when hosting data on-premises and off-premises. You learned how an enterprise will implement secure resource provisioning and deprovisioning, and the differences between type 1 and type 2 hypervisors. We then looked at containerization and learned how to choose an appropriate cloud deployment model. Then we learned the differences between the different cloud service models and gained an understanding of micro-segmentation and VPC peering, which will help us to select the correct storage model based on the storage technologies offered by cloud providers.
In this chapter, you have acquired the following skills:
- An understanding of how to implement data loss prevention
- An understanding of how to implement data loss detection
- An understanding of what is meant by data protection
- An understanding of how to implement secure cloud and virtualization solutions
- An understanding of the cloud deployment models available
- An understanding of the storage models available in cloud environments
In the next chapter, we will learn about managing identities using authentication and authorization, including Multi-Factor Authentication (MFA), Single Sign-On (SSO), and Identity Federation.
Questions
Here are a few questions to test your understanding of the chapter:
- What security setting is it when Group Policy prevents my flash drive from being recognized by my Windows computer?
- Watermarking
- Blocking the use of external media
- Print blocking
- Data classification blocking
- What stops me from capturing bank account details using my mobile banking app?
- Watermarking
- Blocking the use of external media
- Print blocking
- Data classification blocking
- What stops me from printing on my home printer when accessing my work computer using RDP?
- Watermarking
- Blocking the use of external media
- Restricted VDI
- Data classification blocking
- Ben has asked a colleague to collaborate on a project by connecting remotely to his desktop. What would prevent this from happening?
- Remote Desktop
- Protocol (RDP) blocking
- Clipboard privacy controls
- Web Application Firewall
- How can you reduce the risk of administrators installing unauthorized applications during RDP admin sessions?
- Remote Desktop
- Protocol (RDP) blocking
- Clipboard privacy controls
- Web Application Firewall
- How can I ensure that my sales team can send quotations and business contracts out to customers, but not send confidential company data?
- Data classification blocking
- Data loss detection
- Watermarking
- Clipboard privacy controls
- The CISO needs to know who has been sharing signed-out company confidential documents on a public web server. How can this be done?
- Data classification blocking
- Data loss detection
- Watermarking
- Clipboard privacy controls
- Jenny wants to share a useful business-related video file with her colleague, but when Charles attempts to play it using the same player and codecs it cannot be viewed. What is the most likely cause?
- DRM
- Deep packet inspection
- Network traffic analysis
- Watermarking
- What allows a forensics investigator to discover the time and location that a digital image was taken?
- Metadata
- Obfuscation
- Tokenization
- Scrubbing
- What may have allowed a rogue administrator to remove evidence from the access logs?
- Scrubbing
- Metadata
- Obfuscation
- Tokenization
- What stops the bank support desk personnel from accessing Ben's 16-digit VISA card number and CVC code?
- Metadata
- Obfuscation
- Key pairs
- Masking
- What ensures that medical researchers cannot unwittingly share PHI data from medical records?
- Anonymization
- Encryption
- Metadata
- Obfuscation
- What allows an organization to manage business data from the moment it is stored to final destruction?
- Data life cycle
- Containers
- Metadata
- Storage area network
- What is another name for a bare-metal hypervisor deployed in a data center?
- Type 1
- Emulation
- Type 2
- Containers
- What allows the isolation of workloads, allowing easy migration between vendor platforms?
- Type 1
- Emulation
- Type 2
- Containers
- What allows Amy to play 16-bit Nintendo console games on her Windows desktop computer?
- Emulation
- Middleware
- PaaS
- Database storage
- What allows a legacy Microsoft office application to run on Ben's desktop alongside Microsoft Office 365 applications?
- Application virtualization
- Database storage
- Middleware
- PaaS
- How can we make sure that when a user leaves the organization, we can re-assign their software licenses to the new user?
- Deprovisioning
- IaaS
- Emulation
- Off-site backups
- What type of data is used to provide information about data?
- Metadata
- Indexes
- Emulation
- Off-site backups
- What is the primary reason that a small family coffee shop business would choose a public cloud model?
- Cost
- Scalability
- Resources
- Location
- What type of cloud customer am I likely supporting if I am offering a private cloud and customers require that I have the Federal Risk and Authorization Management Program (FedRAMP) attestation?
- Government
- Finance
- Utility company
- Small online retailer
- What is used to describe the situation when multiple customers are hosted on a common hardware platform?
- Multi-tenant
- Platform sharing
- Single tenant
- Service model
- What type of cloud service model would be used when buying 50 licenses to access a customer relationship management (CRM) application?
- SaaS
- PaaS
- IaaS
- Security as a service (SecaaS)
- What type of cloud service model would be used when I need to host my in-house enterprise resource planning (ERP) suite with a CSP?
- SaaS
- PaaS)
- IaaS
- d) SecaaS
- What type of cloud service model would be used when the Acme corporation needs to deploy and manage 500 VDI instances across four geographical regions?
- SaaS
- PaaS
- IaaS
- SecaaS
- What will my CSP configure so that I have direct communication between multiple instances of VPC?
- IPSEC tunnel
- VPN
- Inter-domain routing
- VPC peering
- What kind of storage model would be best for images, files, video, and audio streams?
- File-based storage
- Database storage
- Block storage
- Blob storage
- Key/value pairs
- What kind of storage model would be provided on a storage area network (SAN)?
- File-based storage
- Database storage
- Block storage
- Blob storage
- Key/value pairs
- What kind of storage model would be useful when performing a compliance scan and the database could contain a series of identifiers and the actual value it is expecting to be set?
- File-based storage
- Database storage
- Block storage
- Blob storage
- Key/value pairs
- What is used when a customer is considering their responsibilities when buying in-cloud services.
- A coud-shared responsibility matrix
- A cloud-shared cost matrix
- FedRAMP
- Platform sharing
Answers
- B
- C
- C
- B
- C
- A
- C
- A
- A
- A
- D
- A
- A
- A
- D
- A
- A
- A
- A
- A
- A
- A
- A
- B
- C
- D
- D
- C
- E
- A