Time—frequency representations give the evolution over time of a spectrum calculated from temporal frames. The notion of the spectral envelope extracted from such representations mostly comes from the voice production and recognition system: the voice production uses vocal chords as an excitation and the mouth and nose as a resonator system or anti-resonator. Voiced signals (vowels) produce a harmonic spectrum on which a spectral envelope is superimposed. This fact about voice strongly influences our way of recognizing other sounds, whether because of the ear or the brain; we are looking for such a spectral envelope as a cue to the identification or classification of sounds. This excitation-resonance model is also called source-filter model in the literature. Thus we can understand why the vocoding effect, which is the cross-synthesis of a musical instrument with voice, is so attractive for the ear and so resistant to approximations. We will make use of a source-filter model for an audio signal and modify this model in order to achieve different digital audio effects.
However, the signal-processing problem of extracting a spectral envelope from a spectrum is generally badly conditioned. If the sound is purely harmonic we could say that the spectral envelope is the curve that passes through the points related to these harmonics. This leaves two open questions: how to retrieve these exact values of these harmonics, and what kind of interpolation scheme should we use for the completion of the curve in-between these points? But, more generally, if the sound contains inharmonic partials or a noisy part, this definition no longer holds and the notion of a spectral envelope is then completely dependent on the definition of what belongs to the excitation and what belongs to the resonance. In a way it is more a “envelope-recognition” problem than a “signal-processing” one.
With this in mind we will state that a spectral envelope is a smoothing of a spectrum, which tends to leave aside the spectral line structure while preserving the general form of the spectrum. To provide source-filter sound transformation, two different steps are performed:
1. Estimate the spectral envelope
2. Perform the source-filter separation, and sound-filter combination after transformation of one or the other.
There are three techniques with many variants which can be used for both steps:
1. The channel vocoder uses frequency bands and performs estimations of the amplitude of the signal inside these bands and thus the spectral envelope.
2. Linear prediction estimates an all-pole filter that matches the spectral content of a sound. When the order of this filter is low, only the formants are taken, hence the spectral envelope.
3. Cepstrum techniques perform smoothing of the logarithm of the FFT spectrum (in decibels) in order to separate this curve into its slowly varying part (the spectral envelope) and its quickly varying part (the source signal).
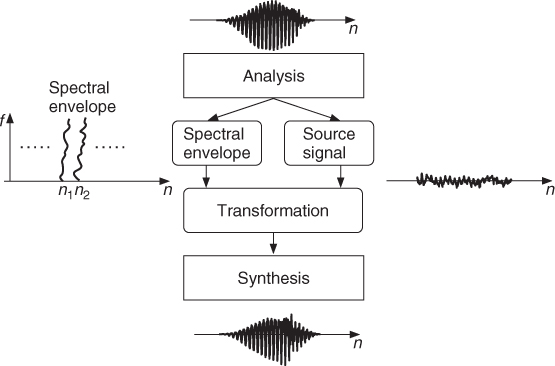
For each of these techniques, we will describe the fundamental algorithms in Section 8.2 which allow the calculation of the spectral envelope and the source signal in a frame-oriented approach, as shown in Figure 8.1. Then transformations are applied to the spectral envelope and/or the source signal and a synthesis procedure reconstructs the output sound. Some basic transformations are introduced in Section 8.3. The separation of a source and a filter is only one of the features we can extract from a sound, or more precisely from a time-frequency representation.
Figure 8.1 Spectral processing based on time-varying spectral envelopes and source signals. The analysis performs a source and filter separation.