
The most common approach for converting a time-domain signal into its frequency-domain representation is the short-time fourier transform (STFT), which can be expressed by the following equation
10.1 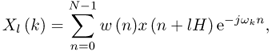
where ![]() is the complex spectrum of a given time frame,
is the complex spectrum of a given time frame, ![]() is the input sound,
is the input sound, ![]() is a complex sinusoid with frequency ωk expressed in radians,
is a complex sinusoid with frequency ωk expressed in radians, ![]() is the analysis window, l is the frame number, k is the frequency index, n is the time index, H is the time index hop size, and N is the FFT size.
is the analysis window, l is the frame number, k is the frequency index, n is the time index, H is the time index hop size, and N is the FFT size.
The STFT results in a general technique from which we can implement loss less analysis/synthesis systems. Many sound-transformation systems are based on direct implementations of the basic algorithm, and several examples have already been presented in previous chapters.
In this chapter, we extend the STFT framework by presenting higher-level modeling of the spectral data obtained with it. There are many spectral models based on the STFT that have been developed for sound and music signals and that fulfill different compromises and applications. The decision as to which one to use in a particular situation is not an easy one. The boundaries are not clear and there are compromises to take into account, such as: (1) sound fidelity, (2) flexibility, (3) coding efficiency, and (4) computational requirements. Ideally, we want to maximize fidelity and flexibility while minimizing memory consumption and computational requirements. The best choice for maximum fidelity and minimum computation time is the direct implementation of the STFT that, anyhow, yields a rather inflexible representation and inefficient coding scheme.
Here we introduce two different spectral models: sinusoidal and sinusoidal plus residual. These models represent an abstraction level higher than the STFT and from them, but with different compromises, we can identify and extract higher-level information on a musical sound, such as: harmonics, fundamental frequency, spectral shape, vibrato, or note boundaries. These models bring the spectral representation closer to our perceptual understanding of a sound. The complexity of the analysis will depend on the sound to be analyzed and the transformation desired. The benefits of going to this higher level of analysis are enormous and open up a wide range of new musical applications.
10.2.1 Sinusoidal Model
Using the STFT representation, the sinusoidal model is a step towards a more flexible representation while compromising both sound fidelity and computing time. It is based on modeling the time-varying spectral characteristics of a sound as sums of time-varying sinusoids. The sound ![]() is modeled by
is modeled by
10.2 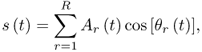
where ![]() and
and ![]() are the instantaneous amplitude and phase of the rth sinusoid, respectively, and R is the number of sinusoids [MQ86, SS87].
are the instantaneous amplitude and phase of the rth sinusoid, respectively, and R is the number of sinusoids [MQ86, SS87].
To obtain a sinusoidal representation from a sound, an analysis is performed in order to estimate the instantaneous amplitudes and phases of the sinusoids. This estimation is generally done by first computing the STFT of the sound, as described in Chapter 7, then detecting the spectral peaks (and measuring the magnitude, frequency and phase of each one), and finally organizing them as time-varying sinusoidal tracks. We can then reconstruct the original sound using additive synthesis.
The sinusoidal model yields a quite general analysis/synthesis technique that can be used in a wide range of sounds and offers a gain in flexibility compared with the direct STFT implementation.
10.2.2 Sinusoidal Plus Residual Model
The sinusoidal plus residual model can cover a wide compromise space and can in fact be seen as the generalization of both the STFT and the sinusoidal models. Using this approach, we can decide what part of the spectral information is modeled as sinusoids and what is left as STFT. With a good analysis, the sinusoidal plus residual representation is very flexible, while maintaining a good sound fidelity, and the representation is quite efficient. In this approach, the sinusoidal representation is used to model only the stable partials of a sound. The residual, or its approximation, models what is left, which should ideally be a stochastic component. This model is less general than either the STFT or the sinusoidal representations, but it results in an enormous gain in flexibility [Ser89, SS90, Ser96]. One of its main drawbacks is that it is not suitable for transient signals, thus several extensions have been proposed to tackle these (e.g., [VM98, VM00]). The sound ![]() is modeled in the continuous domain by
is modeled in the continuous domain by
10.3 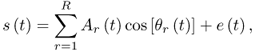
where ![]() and
and ![]() are the instantaneous amplitude and phase of the rth sinusoid, R is the number of sinusoids and
are the instantaneous amplitude and phase of the rth sinusoid, R is the number of sinusoids and ![]() is the residual component. The sinusoidal plus residual model assumes that the sinusoids are stable partials of the sound with a slowly changing amplitude and frequency. With this restriction, we are able to add major constraints to the detection of sinusoids in the spectrum and we might omit the detection of the phase of each peak. For many sounds the instantaneous phase that appears in the equation can be taken to be the integral of the instantaneous frequency
is the residual component. The sinusoidal plus residual model assumes that the sinusoids are stable partials of the sound with a slowly changing amplitude and frequency. With this restriction, we are able to add major constraints to the detection of sinusoids in the spectrum and we might omit the detection of the phase of each peak. For many sounds the instantaneous phase that appears in the equation can be taken to be the integral of the instantaneous frequency ![]() , and therefore satisfies
, and therefore satisfies
10.4 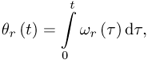
where ![]() is the frequency in radians, and r is the sinusoid number. When the sinusoids are used to model only the stable partials of the sound, we refer to this part of the sound as the deterministic component.
is the frequency in radians, and r is the sinusoid number. When the sinusoids are used to model only the stable partials of the sound, we refer to this part of the sound as the deterministic component.
Within this model we can either leave the residual signal ![]() to be the difference between the original sound and the sinusoidal component, resulting in an identity system, or we can assume that
to be the difference between the original sound and the sinusoidal component, resulting in an identity system, or we can assume that ![]() is a stochastic signal. In this case, the residual can be described as filtered white noise
is a stochastic signal. In this case, the residual can be described as filtered white noise
10.5 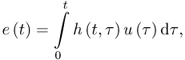
where ![]() is white noise and
is white noise and ![]() is the response of a time-varying filter to an impulse at time t. That is, the residual is modeled by the time-domain convolution of white noise with a time-varying frequency-shaping filter.
is the response of a time-varying filter to an impulse at time t. That is, the residual is modeled by the time-domain convolution of white noise with a time-varying frequency-shaping filter.
The identification of the sinusoids is done by adding restrictions to a standard sinusoidal analysis approach. Then the residual is obtained by subtracting the sinusoids from the original sound. The residual can also be considered a stochastic signal and thus represent it with a noise-filter model. We can then reconstruct the original sound using additive synthesis for the sinusoidal component and subtractive synthesis for the residual component.
The sinusoidal plus residual model yields a more general analysis/synthesis framework than the one obtained with a sinusoidal model and it has some clear advantages for specific applications and types of sounds. It has also led to other different spectral models that still share some of its basic principles [DQ97, FHC00, VM00].