
6
Data Mining Implementation Process
Kamal K. Mehta1, Rajesh Tiwari2* and Nishant Behar3
1Computer Science & Engineering, MPSTME NMIMS, Shirpur, Maharashtra, India
2Computer Science & Engineering, CMR Engg. College, Hyderabad, Telangana, India
3Computer Science & Engineering, S.O.S. (Engg. & Tech.), G.G.V. Bilaspur, Chhattisgarh, India
Abstract
Data mining assumes a significant job in different human exercises since it removes obscure valuable examples (or data). Because of its abilities, data mining has become a basic assignment in a huge number of use spaces, for example, banking, retail, clinical, protection, bioinformatics, and so on. To take an all-encompassing perspective on exploration patterns in the region of data mining, a far-reaching study is introduced in this paper. This paper presents an efficient and thorough study of different data mining errands and procedures. Further, different genuine utilization of data mining is introduced in this paper. The difficulties and issues in the region of data mining research are additionally introduced in this paper.
Keywords: Data mining implementation, data mining techniques, data mining calculations, data mining applications
6.1 Introduction
The advancement of knowledge in various fields of human life has contributed to vast amounts of information accumulating in numerous gatherings, such as documents, books, images, sound accounts, chronicles, coherent information, and various new information systems. The information assembled from different applications requires a genuine part of removing information/information from immense files for better uniqueness. Information divulgence in information bases (KDD), normally called information mining, centers around the disclosure of significant information from tremendous arrangements of data [1]. Different methods and calculations are used to discover and concentrate on the occurrences of defined-aside information [2]. Leading to its vastness in special, data mining and knowledge exposure applications have a rich emphasis since the last twenty years and have become a critical part of major associations. The area of data mining was competitive and implemented with different compromises and styles of advancement in the fields of Statistics, Machine Learning, Artificial Intelligence Databases, Computation Limits, and Pattern Reorganization, etc. The distinctive application regions of information mining are LS (Life Sciences), CRM (Customer Relationship Management), Manufacturing, Web Applications, Competitive Intelligence, Banking/Retail/Finance, Security/Computer/Network, Monitoring, Forecasting of Climate, Teaching Support, showing, Behavioral Ecology & Astronomy and so on. Essentially every field of human life has become information heightened, which made information mining a basic section. Consequently, this paper reviews various examples of information mining and its relative areas from past to present and researches its future zones.
6.2 Data Mining Historical Trends
The data mining system squared is a region for occurrences of various approaches, consolidating database management systems (DBMS), Figures, Machine Learning (ML), and Artificial Intelligence (AI). In the year 1980, the hour of data mining techniques was envisaged essentially by research-driven tools concentrated on single tasks [3]. Early-day data mining techniques are database patterns in initial days, knowledge digging estimates function best for qualitative knowledge gathered from a specific data repository, and distinctive information-digging techniques have advanced for level libraries, daily and social information collections where information is held in clear context. Later, with a fork in the road of simulations and artificial intelligence techniques, numerous datasets advanced to explore non-statistical data and social information computing patterns. The development of mining techniques was enormously driven by the concept of fourth-period computing affiliations and identifiable finding processes. At the beginning of data mining, almost all of the statistics utilized strictly definable methods. Soon they progressed with various techniques, including AI, ML, and sequence reconfiguration. Various data processing methods (induction, compression, and approximation) and estimates of enormous quantities of diverse data set aside in knowledge stores.
6.3 Processes of Data Analysis
The data mining phase is divided into two parts: data structure or preprocessing and data mining. The data planning step involves data cleaning, data reconciliation, data collection, and data adjustment while the next stage involves information gathering, design evaluation, and information extraction [4].
6.3.1 Data Attack
During the data mining era, the data is cleaned up. As we all know, data is loud and aggressive, contradictory, and scattered. This integrates different approaches. For example, filling in missing qualities consolidated register. The yield of data cleaning measure is satisfactorily cleaned data [5].
6.3.2 Data Mixing
During this period, data mining measures were incorporated into a set of data from different sources. In the same way, the dataset occurs in different configurations in an alternative field. Designers could maintain data in databases, text records, spreadsheets, files, 3D data squares, etc. Even though we may say the data mix is so complex, unstable, and challenging. This is because, as a rule, the information does not coordinate various sources [6].
Researchers practice metadata to diminish faults in data joining measures. An alternative concern threatened is data repetition. In this case, identical data may be found in a common database in different tables. Data combination tends to reduce redundancy to the most severe possible degree, without compromising the unfailing consistency of the data.
6.3.3 Data Collection
It is a loop during which analysis data is retrieved from the database. This cycle needs massive amounts of reported data for analysis. Mostly along these lines, a data archive with structured data contains considerably more data than needed. Open data should pick and store exciting details [7].
6.3.4 Data Conversion
In this step, we must modify and merge data into different structures. Mining must be fair. This process usually involves standardization, confluence, speculation, etc.
A data table accessible as −5, “37, 100, 89, and 78” could be updated as −0.05, “0.37, 1.00, 0.89, and 0.78.” Here data seems to be more appropriate for data mining. Open data is prepared for data mining after variation.
6.3.4.1 Data Mining
In this period of Data Mining measure, we have applied strategies to extricate designs from data as these techniques are mind-boggling and wise. Likewise, this mining incorporates a few assignments—for example, arrangement, expectation, bunching, time arrangement investigation, etc. [8].
6.3.4.2 Design Evaluation
The example assessment recognizes genuinely fascinating examples. So this is data based on different interesting steps. An instance is seen as interesting in the circumstance that it is feasibly beneficial. In contrast, people are effectively fair. It also supports several of the concepts. That everyone wants to verify a certain degree of belief in the existing research.
6.3.4.3 Data Illustration
During the Data Mining measurement era, we have to engage in talking to customer data. Similarly, information is sourced from data. Similar methods should be followed to yield.
6.3.4.4 Implementation of Data Mining in the Cross-Industry Standard Process
The common benefits-industry system involves six phases. It’s also a repeated loop.
Data mining measure is a revelation through huge informational collections of examples, connections, and experiences that guide undertakings estimating and overseeing where they are and anticipating where they will be later on. A huge measure of data and data sets can emerge out of different data sources and might be put away in various data warehouses. Furthermore, data mining procedures, for example, AI, man-made brainpower (AI), and prescient demonstrating can be included. The data mining measure requires duty. However, specialists concur, overall enterprises, data mining measure is equivalent. What’s more, it ought to follow a recommended way [9] (Figure 6.1).

Figure 6.1 Data mining implementation process.
Here are six fundamental strides of data mining measure:
6.3.5 Business Understanding
In business getting stage, in any case, it is expected to understand business objections clearly and find what the business needs are.
It centers on understanding venture objectives and prerequisites, structures a business perspective, then, turning the data into an information mining problem, a starting plan is aimed at achieving the objectives [10].
Assignments:
- Decide business goals
- Access circumstance
- Decide data mining objectives
- Produce an undertaking plan.
Decide business goals:
- It understands undertaking targets and essentials from a business perspective.
- Altogether comprehend what the client needs to accomplish.
- Uncover noteworthy components, at the beginning, it can affect the aftereffect of the undertaking.
Access circumstance:
- It requires a more definite examination of realities pretty much all assets, imperatives, presumptions, and others that should be thought of.
Decide data mining objectives:
- A business objective expresses the objective of business wording. For instance, increment inventory deals with the current client.
- A data mining objective portrays task goals. For instance, it expects what number of articles a client will purchase, given their socioeconomics subtleties (Age, Salary, and City) and cost of things in recent years.
Produce a task plan:
- Expresses its emphasis on market and data mining plans.
- This undertaking strategy ought to characterize the normal arrangement of steps to be performed during the remainder of the venture, including the most recent strategy and better determination of devices.
6.3.6 Data Understanding
Information understanding begins with a unique information assortment and continues with tasks to get acquainted with information, to information quality issues, to discover better knowledge in information, or to distinguish intriguing subsets for covered data theory [11].
First, “gross” or “surface” products of knowledge gained should be cautiously revealed. Furthermore, data can be discussed by answering data mining issues that could be used to answer, discover, and represent. Finally, information quality must be investigated by tending to some critical requests, for instance, “Is the gotten information complete?”, “Are there any missing characteristics in obtained information?”
Assignments:
- Gathers beginning data
- Depict data
- Investigate data
- Check data quality.
Gather the beginning data:
- It procures the data referenced in venture assets.
- It incorporates data stacking, if necessary, for data understanding.
- It might prompt unique data readiness steps.
- On the off chance that different data sources are gained, at that point, coordination is an additional issue, either here or at the ensuing phase of data arrangement.
Depict data:
- It inspects the “gross” or “surface” attributes of the data acquired.
- It gives an account of the results.
Investigate data:
- Tending to data mining issues that can be settled by questioning, imagining, and detailing, including:
- Conveyance of significant attributes, consequences of straightforward conglomeration.
- Set up a connection between a modest number of traits.
- Qualities of significant sub-populaces, straightforward statical investigation.
- It might refine data mining destinations.
- It might contribute or refine data depiction and quality reports.
- It might take care of change and other vital data arrangements.
Check data quality:
- It inspects the data quality and tending to questions.
6.3.7 Data Preparation
The information status regularly exhausts about 90.00% of the great importance of errands. The after effect of the information plan stage is the last information record. At the point when open information sources are remembered, they ought to be picked, cleaned, formed, and planned into the ideal structure. The information examination task at a more unmistakable significance may be passed on during this phase to see topics reliant on business understanding [12].
Assignments:
- Select data
- Clean data
- Build data
- Incorporate data
- Arrangement data [13].
Select data:
- It chooses which data to be utilized for assessment.
- In data, choice measures incorporate hugeness to data mining destinations, quality, and specialized constraints, for example, data volume limits or data types.
- It covers the choice of attributes and decisions of archives in the table [14].
Clean data:
- It might include the choice of clean subsets of data, embeddings proper defaults, or more eager strategies, for example, assessing missing data by demonstrating [15].
Build data:
- It contains a Constructive data arrangement, for example, creating inferred attributes, total new records, or changed estimations of current qualities [16].
Incorporate data:
- Incorporate data alludes to the strategies whereby data is consolidated from different tables or archives to make new records or qualities.
Configuration data:
- Designing data allude basically to etymological changes delivered to data that doesn’t modify their criticalness; however, it may require a demonstrating apparatus [17].
6.3.8 Modeling
In displaying, different demonstrating techniques are chosen and applied, and their boundaries are estimated to ideal qualities. A few techniques gave specific prerequisites for the type of information. Hence, venturing back to the information arrangement stage is important [18].
Assignments:
- Select displaying strategy
- Produce test structure
- Fabricate model
- Access model.
Select the modeling strategy:
- It chooses a genuine displaying technique that will be utilized—for instance, choice tree, neural system.
- On the off chance that different techniques are applied, then it plays out this assignment exclusively for every strategy [19].
Produce test Design:
- Produce a strategy or component for testing the legitimacy and nature of the model before developing a model.
- For instance, in the grouping, mistake rates are typically utilized as quality data mining models.
- Consequently, regularly separate data index into train and test set, form the model on a train set, and evaluate its quality on the different test sets [20].
Build model:
- To make at least one demonstration, we have to run displaying instruments on readied data collection.
Assess model:
- It deciphers the models as indicated by its space ability, data mining achievement rules, and necessary plan.
- It evaluates the achievement of the utilization of displaying and finds strategies all more actually.
- It contacts business examination and area pros later to talk about the results of data mining in a business setting.
6.3.9 Evaluation
At the remainder of this stage, a choice on the utilization of information mining results ought to be reached. It assesses the model proficiently, and survey means executed to manufacture the model and to guarantee that business destinations are appropriately accomplished.
The fundamental goal of assessment is to decide some noteworthy business issue that has not been respected satisfactorily. At the remainder of this stage, a choice on the utilization of information mining results ought to be reached [21].
Assignments:
- Assess results
- Survey measure
- Decide the following stages [22].
Evaluate results:
- It evaluates how much the model meets the association’s business goals [23].
- It tests the model on test applications in genuine execution when time and spending constraints grant and evaluates other data mining results created.
- It reveals extra challenges, proposals, or data for future directions.
Survey measure:
- The survey cycle does a more nitty-gritty assessment of data mining commitment to decide when there is a huge factor or errand that has been in one way or another overlooked [24].
- It surveys quality affirmation issues.
Decide on the following stages:
- It concludes how to continue at this stage.
- It concludes whether to finish the undertaking and proceed onward to sending when fundamental or whether to start further cycles or set up new data-mining initiatives.
- It incorporates assets investigation and spending that impact choice.
6.3.10 Deployment
It incorporates scoring an information base, using results as organization rules, intuitive web scoring. The data gained should be composed and introduced in a manner that can be utilized by the customer. Nonetheless, the sending stage can be as simple as delivering. Likewise, the transmitting step can be as simple as producing a report or as confused as implementing a consistent data mining algorithm across connections [25].
These six stages represent the Cross-Business Standard Data Mining Cycle, defined as CRISP-DM. That is an application platform period design representing standard methods and techniques used by data mining specialists. Very commonly used test design.
Assignments:
- Plan organization
- Plan observing and upkeep
- Produce the last report
- Audit venture.
Plan deployment:
- To convey data mining results into a business takes appraisal results and closes a methodology for an organization.
- It alludes to the documentation of the cycle for later sending [26].
Plan observing and upkeep:
- It is significant when data mining results become some portion of everyday business and its condition.
- It assists with maintaining a strategic distance from pointlessly extensive stretches of abuse of data mining results.
- It needs a point-by-point investigation of the checking cycle.
Produce the last report:
- The last report can be drawn up by the undertaking chief and his group.
- It might just be an outline of the task and its experience.
- It might be a last and exhaustive introduction to data mining.
6.3.11 Contemporary Developments
The data mining industry has turned out to be a direct product of its great accomplishment in terms of deepening application achievements and a steady improvement in learning. Distinguishable data mining technologies have been extensively applied in different areas such as medicinal operation, currency, marketing, marketing communication tool, misinformation detection, risk assessment, etc. Accurately increasing challenges in different fields, and progress enhancements have resulted in new data mining problems; various difficulties are linked to a variety of data frameworks, data from various districts, progress in assessment and corporate resource structures, research and legitimate fields, constant creation of business difficulties, etc. Sorts of advancement in data mining with different blends and implications of procedures and tools have shaped current data mining solutions to solve numerous issues, current examples of data mining techniques [27].
6.3.12 An Assortment of Data Mining
The table presents a range of data mining techniques commonly being used marks for several an out plans in different application divisions.
6.3.12.1 Using Computational & Connectivity Tools
Data mining has expanded with the use of authentic strategy and operating system tools such as Parallel, Distributed, and Grid propellers. Comparable data mining applications have been created using parallel processing, and basic equivalent information mining technologies use probabilistic reasoning numbers [25]. Equivalent figuring and scattered information mining are both composed in Grid headways [26]. Grid-based help Vector Machine framework is being used for process improvement processing [27]. Starting late, unique, fragile enlisting methodologies have been applied in information digging, for instance, fleecy basis, disagreeable set, neural frameworks, formative figuring (Genetic Algorithms and Genetic Programming), & sponsorship vector machinery towards exploring several courses for the action of the information set aside in appropriated informational indexes achieves a more sharp and enthusiastic structure giving a human-interpretable, ease, estimated game plan, when stood out from standard techniques [28] for exact assessment, a generous preprocessing system, versatile information planning, information assessment and dynamic.
6.3.12.2 Web Mining
The development and utilization of the World Wide Web will keep increasing, the production of substance, structure, and use of data and the estimate of Web mining will seek to grow. The investigation must be performed to develop the correct arrangement of web measurements and their calculation systems, to distinguish measured variables from usage data, seeing how different sections of the cycle model impact different web quantities of interest, seeing how cycle models adjust due to various changes that are made—to modify client updates, to establish web mining procedures to boost different performance [29].
6.3.12.3 Comparative Statement
The following table represents the general announcement of the various trends of data mining from past to future.
6.3.13 Advantages of Data Mining
- Used for retrieval of information (Table 6.1).
- It can be used as a tool which can segregate the information according to the user requirements in no time.
Table 6.1 Data mining developments qualified statement.
| Data mining patterns | Algo./techniques utilized | Data designs | Computing resources | Prime territories of uses |
| Past | Statistical, Machine Learning Techniques | Numerical data and organized data put away in customary data sets | Evolution of 4G PL and different related strategies | Business |
| Current | Statistical, Machine Learning, Artificial Intelligence, Pattern Reorganization Techniques | Heterogeneous data designs incorporate organized semiorganized and unstructured data | High-speed systems, High end stockpiling gadgets and Parallel, Distributed figuring, and so on | Business, Web, Medical analysis, and so on |
| Future | Soft Computing methods like Fuzzy rationale, Neural Networks, and Genetic Programming | Complex data objects incorporate high dimensional, fast data streams, succession, commotion in time arrangement, chart, Multicase objects, Multi-spoke to articles and worldly data, and so on | Multi-operator advancements and Cloud Computing | Business, Web, Medical finding, Scientific and Research investigation fields (bio, distant detecting, and so forth.), Social systems administration, and so on |
- It can be used for building a model from the past experiences.
- It can be use in operational and manufacturing industry to identify the faulty equipment.
- It can be helpful for the government by analyzing the financial details of individual and build a patter so that it can be helpful to identify the criminal and money laundering activity [30].
6.3.14 Drawbacks of Data Mining
Information mining programs are difficult to write and at the same time difficult to manage. Therefore it always requires advance skills to manage.
- The information mining strategies are not definite; in this way, they can cause certifiable outcomes in explicit conditions.
- Nowadays internet and social media is a common platform which everyone uses therefore there is always a concern of privacy of the information. It is always possible that unethically someone retrieve that information and use the information in a bad way and it create a trouble to others.
6.3.15 Data Mining Applications
Table 6.2 represents different applications and usage of data mining.
Table 6.2 Shows application and usage of data mining.
| Applications | Usage |
| Communications | Data mining methods can be used as a tool to segment the customers according to their targets and interests. |
| Insurance | It can used as tool in the insurance industry to identify the gain of the company, analysis the existing policies and interest of the customers in these policies. |
| Education | Data mining methods can be used for the classification and prediction of the student’s performance for the course and programs. It can be used as a tracker to improve the student teaching learning process, also used for helping the students for choosing the course efficiently. |
| Manufacturing | It can be use in operational and manufacturing industry to identify the faulty equipment. They can analyze and manage their resources with the help of mining tools. |
| Banking | Data mining can be used in banking sector. Using data mining model banks can analyze the financial behavior of the customers. Using this data bank professional can identify the faulty customers and the loyal customers. |
| Retail | Data mining is helpful for the retail industry because it can collect large amount of customer data, sales data, history of customer purchase and their consumption. This data is always increasing because easy availability of data and continuous usage of wed applications for shopping. This model can help the retail industry to make the better relationship with the customers. |
| Administration Providers | Most of the service based telecommunication company can use this as an analysis tool. It can be used to identify that why customers are leaving their services and check the customers grievance. They can improve the services from user point of view. |
| E-Commerce | Most of the e-commerce sites are using data mining tools to attract the customers by offering various stratigical plan. |
| Super Markets | Super markets can also use this as data analysis tool. E.g. They can observe their daily customers like: their gender, age, and product. Suppose most of the female customers are visiting the supermarket then they can focus on the products like: Facial creams, Shampoos, Baby products, sanitary products, etc., |
| Wrongdoing Investigation | Data Mining can be used for the investigation purpose also. Investigation officers can track the people who try to cross boarders, LOC and the deatis can send to the local police officers. |
| Bioinformatics | It can also be used in the science and Biomedical field. |
6.3.16 Methodology
An audit cum preliminary methodology is used. Through the expansive request of composition and discussion with pros on understudy execution, different components that are considered to have sway on the introduction of an understudy are perceived. These affecting variables are arranged as data factors. For this work, progressing genuine information is assembled from the optional school. Information can be filtered out using manual methods. Further, it can be changed into the standard format used by WEKA tool. Starting now and into the foreseeable future, features and limits assurance are perceived.
By then, examination of recognized limits and use is performed on gadgets. After successful execution, results are compared and analyzed. The stepwise representation is shown in Figure 6.2 and it recorded 152.00 understudies of auxiliary school which is used as a dataset and understudy related elements are described in Table 6.3 close by their space regards.
Tools and Techniques Utilized:
The different data mining methods are used to understand the concept of educational Data Mining. The various methods are: classification, density estimation and regression. The various datasets are used for analysis purpose and different classification strategies are implemented such as: Naïve Bayes classifier, SMO, Multi-layer perception and REPTree and J48. The execution is done with the help of a WEKA tool.

Figure 6.2 Shows flowchart of the research.
Table 6.3 Understudy related factors.
| Variable name | Depiction | Area |
| SEX | Sex of Student | M,F |
| INS-HIGH | High-Level Institution | Government, Private |
| TOB | Board’s Type | CBSE, State Board |
| MOI | Supervision’s Medium | English, Hindi |
| TOS | School Type | Girls, Co-ed, Boys |
| PTUI | Cost of Coaching | No, Yes |
| S-AREA | School’s Locality | Rural, Urban |
| MOB | Students have cellphones/tablets | No, Yes |
| COM-HM | Students have Computer/Laptop | No, Yes |
| NETACS | Students have internet | No, Yes |
| ROLL NO | Roll no. of Student | Specified through school administration |
| INT-GR | Evaluation of understudy internally | A A+, B, C |
| ATTN | Students Attendance tally | School’s Attendance record |
| CLASS (Response Variable) | If eligible or not | Q, NQ |
Reproduction Case Study:
For the investigation purpose total 152 records are taken into consideration [31]. For the quality analysis Chi-Squared, info Gain, Symmetrical Uncert attribute, and ReliefF characteristic are used. To estimate the rank, ranker search method is used. High potential variables are recorded underneath close by their situations in Table 6.4.
Table 6.4 High potential variables.
| Variable rank value’s name | Values of rank |
| INT-GR | 01.650 |
| ATTN | 02.2250 |
| SEX | 03.600 |
| PTUI | 03.5250 |
| MOB | 05.3750 |
| INS-HIGH | 05.9250 |
| COM-HM | 08.3250 |
| NET-ACS | 09.200 |
6.3.17 Results
The experiments are performed on different classifier and results are represented in Table 6.5. The various parameters are used to check the performance of the model and these parameters are also mentioned in Table 6.5.
As per the analysis, the precision of the multilayer perception method is 74.99% and it is better than other methods. Table 6.6 represents comparative analysis of various classifiers with their precision rates.
Table 6.5 Analysis of various classifiers.
| Classified algorithm’s name | Student’s class | Rate of TP | Rate of FP | Precision | F-Measure | Recall | Area of ROC |
| Multi-layer Perception | NQ | 0.830 | 0.440 | 0.808 | 0.823 | 0.830 | 0.770 |
| Q | 0.550 | 0.163 | 0.606 | 0.577 | 0.553 | 0.774 | |
| Naive Bayes | NQ | 0.760 | 0.595 | 0.742 | 0.752 | 0.761 | 0.647 |
| Q | 0.400 | 0.238 | 0.432 | 0.418 | 0.404 | 0.648 | |
| SMO | NQ | 0.880 | 0.766 | 0.721 | 0.795 | 0.886 | 0.56 |
| Q | 0.230 | 0.114 | 0.478 | 0.314 | 0.314 | 0.56 | |
| J48 | NQ | 0.810 | 0.574 | 0.761 | 0.789 | 0.819 | 0.713 |
| Q | 0.420 | 0.181 | 0.513 | 0.465 | 0.426 | 0.713 | |
| REPTree | NQ | 0.830 | 0.681 | 0.733 | 0.762 | 0.838 | 0.667 |
| Q | 0.310 | 0.162 | 0.469 | 0.38 | 0.319 | 0.667 |
Table 6.6 Comparative analysis of various classifiers with their precision rates.
| Technique for mining | Precision |
| Multi-layer perception | 74.99% |
| Naïve Bayes | 65.09% |
| SMO | 68.39% |
| J48 | 69.80% |
| REPTree | 67.80% |
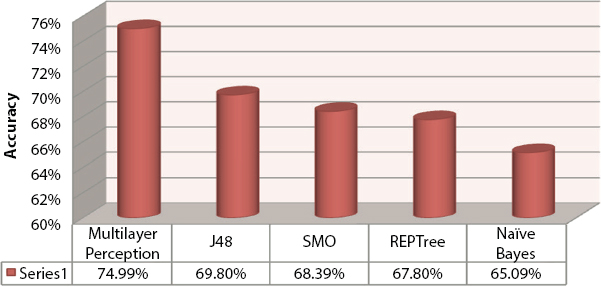
Figure 6.3 Exactness classifier’s comparison.

Figure 6.4 Datastream model.
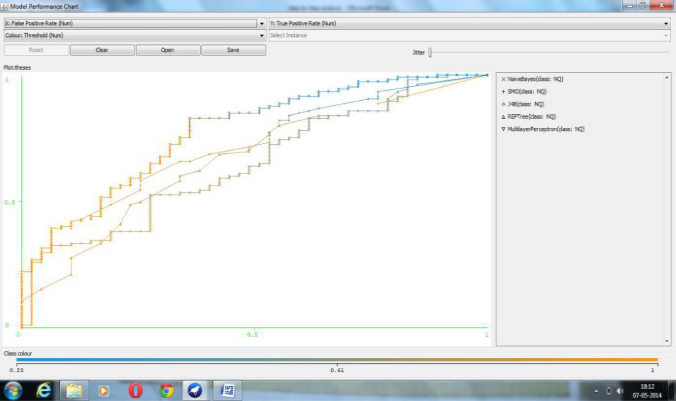
Figure 6.5 Model execution graph.
Figure 6.3 shows exactness classifier’s comparison and Figure 6.4 represents Datastream model. Ensuing to stacking information record run the model and a model show chart as shown in Figure 6.5 for various classifiers, for instance, Multilayer Perceptron, Naive Bayes, J48, REP Tree & SMO. Figure 6.5 shows the region of mixing twist (ROC) for each classifier.
6.3.18 Conclusion and Future Scope
In this chapter, we immediately kept an eye on distinctive information mining designs from their root to what exactly to come. This review would be valuable to authorities to focus on various issues of information mining. In the future course, we will review distinctive gathering estimations and the vitality of the extraordinary figuring (innate programming) approach in arranging gainful portrayal computations for information mining.
We, in like manner, dismember, request strategies are used for conjecture on a dataset of 152 understudies to foresee, and research understudy’s introduction likewise moderate understudies among them. In this assessment, a model was made reliant on some picked understudy-related information factors accumulated from the veritable world. According to the comparative studies the performance of the Multi-Layer Perception is better with 74.99% accuracy. Therefore it can be concluded that MLP winds up being perhaps practical and capable classifier. Furthermore, the connection of all of the five classifiers with the help of the WEKA experimenter is similarly made; for this circumstance in like manner, MLP winds up being best with an F-extent of 82%. Consequently, the execution of MLP is tolerably higher than various classifiers. A model presentation chart is furthermore plotted. This assessment helps establishments to perceive understudies who are moderate understudies, which further offers a base for picking exceptional manuals for them. EDM is in its beginning phases, and it has part of the potential for instruction. It can be used as a tool for future assessment. In future, database management system, e-learning tools and mining tools can be integrated to find the better precision and results. Accordingly, the destiny of EDM is promising for extra investigation. It can be applied in various zones like drug, sports, and offer market as a result of the openness of monstrous information bases.
References
1. Manila, H., Data mining: Machine learning, statistics, and databases, IEEE, 1996.
2. Fayad, U., Piatesky-Shapiro, G., Smyth, P., From Data Mining To Knowledge Discovery in Databases, AAAI Press/The MIT Press, Massachusetts Institute of Technology, Springer, Berlin, Heidelberg, 1996.
3. Piatetsky-Shapiro, G., The Data-Mining Industry Coming of Age. IEEE Intell. Syst., 14, 32–34, 1999.
4. Romero, C., Educational Data Mining: A Review of the State-of-the-Art. IEEE Trans. Syst. Man Cybern.—Part C: Appl. Rev., 40, 6, 601–618, 2010.
5. Zaïane, O., Web usage mining for a better web-based learning environment. Proceedings of Conference on Advanced Technology For Education, pp. 60–64, 2001.
6. Zaïane, O., Building a recommender agent for e-learning systems. Proceedings of the International Conference on Computers in Education, pp. 55–59, 2002.
7. Baker, R.S., Corbett, A.T., Koedinger, K.R., Detecting Student Misuse of Intelligent Tutoring Systems. Proceedings of the 7th International Conference on Intelligent Tutoring Systems, pp. 531–540, 2004.
8. Tang, T. and McCalla, G., Smart recommendation for an evolving e-learning system: Architecture and experiment. Int. J. E-Learn., 4, 1, 105–129, 2005.
9. Merceron, A. and Yacef, K., A web-based tutoring tool with mining facilities to improve learning and teaching. Proceedings of the 11th International Conference on Artificial Intelligence in Education, pp. 201–208, 2003.
10. Romero, C., Ventura, S., De Bra, P., Castro, C., Discovering prediction rules in aha! Courses. Proceedings of the International Conference on User Modelling, pp. 25–34, 2003.
11. Beck, J. and Woolf, B., High-level student modeling with machine learning. Proceedings of the 5th International Conference on Intelligent Tutoring Systems, pp. 584–593, 2000.
12. Dringus, L.P. and Ellis, T., Using data mining as a strategy for assessing asynchronous discussion forums. Comput. Educ. J., 45, 141–160, 2005.
13. Lenka, R.K., Rath, A.K., Tan, Z., Sharma, S., Puthal, D., Simha, N.V.R., Raja, R., Tripathi, S.S., Prasad, M., Building Scalable Cyber-Physical-Social Networking Infrastructure Using IoT and Low Power Sensors. IEEE Access, 6, 1, 30162–30173, 2018.
14. Nguyen, T.-N., Busche, A., Schmidt Thieme, L., Improving Academic Performance Prediction by Dealing with Class Imbalance. Ninth International Conference on Intelligent Systems Design and Applications, 2009.
15. Arockiam, L., Charles, S., Kumar, A. et al., Deriving Association between Urban and Rural Students Programming Skills. Int. J. Comput. Sci. Eng., 02, 03, 687–690, 2010.
16. Salmon, S. et al., Ubiquitous Secretary: A Ubiquitous Computing Application Based on Web Services Architecture. Int. J. Multimed. Ubiquitous Eng., 4, 4, 53–70, October 2009.
17. Hsu, J., Data Mining Trends and Developments: The Key Data Mining Technologies and Applications for the 21st Century. The Proceedings of the 19th Annual Conference for Information Systems Educators (ISECON 2002), http://colton.byuh.edu/isecon/2002/224b/Hsu.pdf.
18. Krishnaswamy, S., Towards Situation-awareness and Ubiquitous Data Mining for Road Safety: Rationale and Architecture for a Compelling Application. Proceedings of Conference on Intelligent Vehicles and Road Infrastructure 2005, pp. 16–17, 2005, Available at: http://www.csse.monash.edu.au/~mgaber/CameraReadyI.
19. Kotsiantis, S., Kanellopoulos, D., Pintelas, P., Multimedia mining. WSEAS Trans. Syst., 3, 3263–3268, 2004.
20. Abdulvahit, T. and Eminem, D., Using spatial data mining techniques to reveal the vulnerability of people and places due to oil transportation and accidents: A case study of Istanbul strait. ISPRS Technical Commission II Symposium, 1st edition, Addison–Wesley, Vienna, 2006.
21. Jain, S., Mahmood, Md.R., Raja, R., Laxmi, K.R., Gupta, A., Multi-Label Classification for Images with Labels for Image Annotation. SAMRIDDHI: A Journal of Physical Sciences, Engineering and Technology, 12, Special Issue (3), 183–188, 2020.
22. Mitchell, T.M., Generalization as Search. Artif. Intell., 18, 2, 203–226, 1982.
23. Michalski, R., Mozetic, I., Hong, J., Lavrac, N., The AQ15 Inductive Learning System: An Overview and Experiments. Reports of Machine Learning and Inference Laboratory, MLI-86-6, George Mason University, University of Illinois at Urbana-Champaign, 1986.
24. Tiwari, L., Raja, R., Awasthi, V., Miri, R., Sinha, G.R., Alkinani, M.H., Polat, K., Detection of lung nodule and cancer using novel Mask-3 FCM and TWEDLNN algorithms. Measurement, 172, 108882, 2021.
25. Baker, Z.K. and Prasanna, V.K., Efficient Parallel Data Mining with the Apriori Algorithm on FPGAs. Submitted to the IEEE International Parallel and Distributed Processing Symposium (IPDPS ‘05), 2005.
26. He, J., Advances in Data Mining: History and Future. Third International Symposium on Information Technology Application, 978-0-7695-3859-4/09 IEEE, 2009.
27. Meligy, A., A Grid-Based Distributed SVM Data Mining Algorithm. Eur. J. Sci. Res., 27, 3, 313–321, 2009, http://www.eurojournals.com/ejsr.htm.
28. Sahu, A.K., Sharma, S., Tanveer, M., Internet of Things attack detection using hybrid Deep Learning Model. Comput. Commun., 176, 146–154, 2021, https://doi.org/10.1016/j.comcom.2021.05.024.
29. Mitra, S., Pal, S.K., Mitra, P., Data mining in soft computing framework: A survey. IEEE Trans. Neural Netw., 13, 3–14, 2001.
30. Embrechts, M.J., Introduction to Scientific Data Mining: Direct Kernel Methods & Applications, in: Computationally Intelligent Hybrid Systems: The Fusion of Soft Computing and Hard Computing, pp. 317–365, Wiley, New York, 2005.
31. Han, J. and Kamber, M., Data mining: Concepts and techniques, Academic Press, Morgan-Kaufman Series of Data Management Systems, San Diego, 2001.
- *Corresponding author: [email protected]