
10
Data Mining for Cyber-Physical Systems
M. Varaprasad Rao1*, D. Anji Reddy2, Anusha Ampavathi3 and Shaik Munawar4
1Department of Computer Science and Engineering, CMR Technical Campus, Kandlakoya, Hyderabad, India
2Department of Computer Science and Engineering, Vaageshwari College of Engineering, Karimnagar, India
3Department of Computer Science and Engineering, JB Institute of Engineering and Technology, Moinabad, Hyderabad, India
4Department of Computer Science and Engineering, Annamalai University, Chidambaram, India
Abstract
The Cyber-Physical System (CPS) combines corporeal gadgets (i.e. sensors) through digital (i.e., illuminating) apparatuses to create an elusive structure that returns wisely towards complexing variations in actual circumstances. The fundamental aspect of the CPS is the analysis and evaluation of data from woody, challenging, and volatile external structures that can only be gradually transformed into usable knowledge. AI evaluation, such as neighborhood surveys, is being used to derive valuable data and insights from data obtained by smart objects, focusing on which various applications of CPS can be used to make informed choices. Throughout this paper, through the use of size and shape-dependent information stream sorting measurements, based on the Numerous Specimen Flocking Model, is suggested for the evaluation of large-scale details produced from various activities, e.g., system observation, well-being tests, sensor organizations. In the proposed method, the estimated findings are available on request at any time so that they are particularly well equipped for actual observation purposes.
Keywords: Checking applications, cyber-physical frameworks, information streams mining, stream grouping, AI evaluation
10.1 Introduction
Cyber-physical system (CPS) is accepting many considerations as of late with models including keen urban communities, savvy homes with the organization of machines, natural checking and transportation frameworks, shrewd network, and so on. These frameworks are furnished with an enormous organization of sensors circulated across various parts, which prompts a gigantic measure of estimation information accessible to framework administrators. Since these numbers are constantly collected over time, this can be used as a significant data analysis mechanism. Particular data can be derived from this huge amount of information and used to make better local economies, to provide better government, to carry out pre-scient inquiries, to obtain similar data by making several different demands. Most of this is feasible as a result of AI and data mining, where occurrences can be discovered in the number of alternatives given every moment. Collection and evaluation of source information [1] require novel calculations that can create models of the information in an online manner, taking a gander at every information record just a single time and inside a restricted measure of time. Albeit standard information examination and information mining calculations zone valuable beginning stage, people should be changed regularly to function in stream environments. In this particular situation, various leveled sorting is undertaken to carry out a bunch inspection of enormous information, to provide continuous and confined storage use. Even though information examination mining experts have successfully resolved a wide range of issues of major concern to enormous information, the region is still new and has many open issues. The multilayered existence of the CPS [2] arising from the variability of relevant parts (e.g. actuators and sensors), the necessarily appropriate nature of such devices, the shortage of performance efficiency, the immense difficulty and variety of situations, render a complicated activity to analyze information and carry out activities. We designed the Rainbow stage to resolve some of these issues. Rainbow shrouds uncertainty by presenting a concept to the Virtual Object and addresses the related definition of CPS through the provision of a distributed multi-specialist system (MAS). This promotes the manipulation of a variety of empirical techniques [3], where increasingly complex behavior emerges from encounters with simpler topics, working purely based on neighborhood information and without the need for a regional participant. MAS in Spectrum can be used for the methods used for data collection, data mixing, layout identification, analysis, and management.
Cyber-physical Systems (CPS) can change how we live and work. Shrewd urban communities, keen force frameworks, savvy homes with the organization of apparatuses, robots helped to live, nature observing, and transportation frameworks are instances of complex frameworks and applications [4]. In a CPS, the physical world is incorporated with detecting, correspondence, and figuring segments. These four parts have complex communications. The intricacy of CPS has brought about model-based plans and advancement, assuming a focal function in building CPS [5–7]. Normally the detecting part of CPS is basic to the demonstrating and the executives of CPS since it gives genuine operational information. The objective of detecting is to give top-notch information great inclusion of all segments requiring little to no effort. In any case, these objectives may not generally be feasible. For example, we can utilize high loyalty sensors, circle indicators, and radars to distinguish the traffic on the street, however, these sensors are costly and thus, can’t be utilized to cover an enormous metropolitan zone. Savvy gadgets with GPS (for example, cell phones or GPS on taxis) can give great inclusion; however, their information quality is low [8]. Customarily, the plan of the detecting segment of a CPS zeroed in on the best way to convey a predetermined number of complex, solid, and costly sensors to streamline the inclusion of a domain or physical wonder [9]. Notwithstanding propels in detecting and correspondence advances in the course of the last 10–15 years have upset the customary way. Sensors have decreased and less expensive, and with the development of remote systems administration, we would now be able to send an enormous number of them to gather huge measure of information effortlessly. The Mobile Millennium traffic data framework wires information from GPS-empowered telephones and GPS in taxis with information from advanced sensors, for example, radar and circle finders, to gauge traffic in the San Francisco metropolitan territory. Today, easy, pervasive detecting is pushing a change in outlook away from asset compelled detecting towards utilizing large information examination to separate data and significant insight from the huge measure of sensor information [10, 11]. In this paper contend that the accessibility of huge observing information on CPS makes difficulties for conventional CPS demonstrating by breaking a portion of the presumptions, yet also gives chances to rearrange the CPS model ID task, accomplish proactive support, and manufacture novel applications by consolidating CPS displaying with information-driven learning and mining strategies.
The whole paper suggests the use of such an entire network sorting estimation [12] for the validation of programs. FlockStream focuses on a multi-operator structure that utilizes a decentralized basis to create a self-organizing technique for collecting potential information. Knowledge emphasizes it linked to specialists and sent to a 2D room, operating at the same time to determine an algorithm technique based on a bio-enlivened model known as a speeding design. Users go to space for a specific duration, and when different specialists undergo a pre-specified perception, they may want to go to maflock, if they are comparative. Herds can join in shaping multitudes of comparable gatherings. FlockStream is especially able for those applications that must screen a tremendous measure of information produced ceaselessly as a succession of occasions and originating from various areas because it enables the creation of the concept of clusters to be followed by showing the creation of specialists in virtual space. This empowers the client to discern outwardly the changes in the environment of the community and gives him little information because, at the end of the day, decisions and choices are constantly made in the light of the changing circumstances. An even more key advantage of FlockStream would be that it allows the users to obtain an estimated performance, very rapidly, by shortening the number that experts can pass to virtual space. This function should only be used when processing time is limited, as in many CPS apps. In comparison, if included in combination with any form of transition discovery [13], it is conceivable to recognize, as a consequence and on an ongoing basis, when the actions of the channel are changing.
10.1.1 Models of Cyber-Physical System
A CPS comprises of a firmly coupled joining of computational components with physical cycles. The computational components depend on sensors to screen and control the physical condition and cycles. The figuring asset controls the physical cycles utilizing an assortment of control goals, where input circles sway calculations also. Before summing up ways to deal with CPS displaying, we need to characterize our utilization of the terms demonstrating and investigation with regards to CPS. We utilize the term displaying to allude to a conventional way to deal with structuring and designing CPS [14], while investigation means learning and digging approaches for separating information from checking information, and this information can prompt significant insight [15]. We accept that displaying will keep on staying a basic piece of CPS plan, improvement, and activities, for example, large information examination will supplement not supplement CPS models. This is because models offer a few focal points [16] are
- (1) they can have formal properties, for example, determinism that we can demonstrate,
- (2) they can be utilized to catch a framework’s development,
- (3) they empower examination and reproduction to assist us with recognizing configuration deserts, and sometimes, they can be utilized to naturally integrate executions (for example, code age).
The scholarly world and industry have manufactured a variety of devices for CPS displaying, for example, MATLAB Simulink and the Ptolemy suite. Nonetheless, with progressions in detecting, interchanges, and distributed computing, the term CPS presently additionally incorporates huge, complex frameworks, for example, the Internet of Things, keen urban communities, the force lattice, transportation organizations, and so on. Displaying these frameworks is testing and frequently includes making disentangling suspicions to accomplish manageability. In the most pessimistic scenarios, it probably won’t be possible to fabricate exact models in any event when nitty-gritty and adequate measure of checking information are accessible. Enormous information investigation can be helpful in such situations [17].
The examination issues of CPS are generally new. In any case, many related themes, for example, recognizing defective sensor signals or target following, have been concentrated widely in the previous decades. The people group of information the executives and information mining likewise propose a few techniques to discover exceptions or abnormalities for sensor network applications. According to the scheme, important studies can generally be categorized into classes: observable model-based methodologies, spatial, and world-wide methods focused on proximity and highlighting recovery procedures.
10.1.2 Statistical Model-Based Methodologies
An enormous classification of factual models has been proposed to recognize flawed sensor information. Deficient knowledge is defined as something that does not obey the interpretation of these models. Researchers used time-differentiating multivariate Gaussian models to respond to preordained queries [18]. The unit responds to the predestined structure of the area of research, treating the sensor network as a knowledge base. Elnahrawy and Nath used the Bayesian Classifier (BC) to clean up the information [19]. They displayed the sensor information as a typical standard appropriation and produced the earlier information on the commotion model from preparing information as Koushanfar built up across the approval technique for Online False Alarm Detection (OFAD) because of different deficiency models [20]. Somewhat, those techniques can assist clients with sifting bogus sensor information. In any case, the vast majority of them need to prepare datasets or earlier information to develop the models and tune the boundaries. Such data isn’t accessible in numerous genuine situations. Additionally, with such numerous measurable models, it is difficult for the client to figure out which one is the most suitable. As referenced in [21], the current models are not sufficient, and the measurable models can’t be good for some mind-boggling cases in genuine applications.
10.1.3 Spatial-and-Transient Closeness-Based Methodologies
The spatial-and-fleeting similitude put-together techniques are based in respect to the suspicion that there are solid connections between the sensor information and their neighbors (spatial likeness), just as their narratives (worldly comparability). Krishnamachari and Iyengar have exploited the structural and transient relationship of fragmented different sensors [22]. Jeffery et al. tried to manipulate both temporal and spatial relationships to fix inaccurate reports [23]. Their techniques agree that all details within each spatial and transient granule are uniform. The shortcoming recognition systems consider any high-value edge worthwhile outdoing as damaged and suggested a non-parametric outlier detection (NPOD) model for sensor data [24]. This system diffusely detects irregularities by testing the nearest neighbors of each sensor. Information circulations are measured by component volume function, and multifaceted variations are identified by testing heterogeneous readings. The system generates clumps of sensor readings and distinguishes variations by measuring the variance of the sensor to its neighbors. There are also some limits on this techniques: (1) The spatial similitude theory may not be legitimate in all the cases, the relationship of sensors are affected by different variables, including the organization of sensors, the general condition, and the objective development; (2) the worldly closeness suspicion may come up short in a few cases. The sensor’s dependability may lessen after some time, e.g., the sensors may be harmed in the brutal condition, or run out of intensity [25].
10.2 Feature Recovering Methodologies
Feature recovering methods recognize defective information by contrasting distinctive highlights. Such techniques first endeavor a few information highlights like natural sort, associating degree, and fleeting examples, and afterward build classifiers to recognize various kinds of flaws. As Ni built up some regular highlights, including framework highlights, condition highlights, and information features [26]. They consolidated various highlights to characterize and distinguish regularly watched deficiencies. Ni and Pottie conveyed sensors to distinguish the presence of arsenic in groundwater [27]. A Fault Remediation System (FRS) is produced for deciding flaws and recommending arrangements utilizing rule-put together strategies and static limits to the water pressure and other area explicit highlights. Authors proposed a Pattern Growth Graph (PGG) based technique to distinguish varieties and channel clamor over advancing clinical streams [28]. The element of wave-design is proposed to catch the significant data of clinical information advancement and speak to them minimalistically. The varieties are identified by a wave-design coordinating calculation, and significant information changes are recognized from the clamor. Author proposed a two-phase way to deal with discovering inconsistencies in convoluted datasets [29]. The calculation utilizes a proficient deterministic space segment to kill clear, ordinary occurrences and produces a little arrangement of inconsistency competitors, and afterward checks every up-and-comer with thickness based various models to decide the conclusive outcomes. The element-based methodologies generally have preferable exhibitions over different techniques, yet they are more space explicit. Such techniques require clients to give nitty gritty setting data and characterizing the defective records cautiously. Versatility and adaptiveness are the serious issues that forestall their application in a more extensive scope of CPS.
10.3 CPS vs. IT Systems
In our view, four key contrasts make enormous information demonstrating and examination for CPS not the same as comparative issues in the universally useful processing space. The initial two are: (1) The tight connection of figuring components with the physical world through input control circles, and (2) A thorough designing cycle for crucial CPS when contrasted with standard programming building practice for IT applications, where specialists can’t generally depend on steady programming updates to fix prior issues. These straightforwardly lead to a formalized model-based structure worldview [30, 31] exemplified by an assortment of building devices, for example, Simulink/Stateflow, Ptolemy, and so on. Third, CPS frameworks show a lot of additionally working modes contrasted with IT frameworks. We can think about a web administration working in various modes depending on the traffic design, for example, day versus night, however frequently, there are few such modes. With hardly any working modes, we can join space information and “savage power” search to decide the state change focuses and learn separate models. In any case, this methodology won’t scale to numerous discrete states that are difficult to recognize, just like the case for complex CPS [32]. Fourth, we likewise expect the job and translation of investigation to be diverse in CPS. Regularly, when working with IT frameworks information, we can accomplish great speculation with standard AI methods by expanding the state space. For example, rather than utilizing just the quantity of solicitation appearances, we can likewise utilize its first and second subordinates as highlights. This may assist us in recognizing distinctive operational modes. Be that as it may, with the change in perspective to a minimal effort, omnipresent detecting such methodologies become craftsmanship—what number of and which factors to dissect? What do different changes (for example, subordinates, logarithms, and so forth.) speak to? Specially appointed examination approaches are probably not going to affect the CPS region halfway because of the need and entrenched custom of thorough model-based structure and advancement. Because of these distinctions, we accept that huge information demonstrating and investigation for CPS justifies further autonomous examination.
10.4 Collections, Sources, and Generations of Big Data for CPS
The wide variety of applications of sensors, for the most part for micro-electromechanical frames (MEMS, for example, open layout sheets [33] and modern production device designs and sections, have led to sensors becoming stronger for equipment worn from unyielding circumstances. Also, a large number of these sensors fuse actuators which are 1,000× quite impressive for their action than the one used with the Nintendo switch [34]. In this section, we discuss the wide variety of information sources and forms that have been identified by collecting them in the social analysis and setting up a careful registration procedure. The description is shown in Figure 10.1.

Figure 10.1 Shows different sources of big data.
10.4.1 Establishing Conscious Computation and Information Systems
The ultimate sense of cognitive integration and device administration (CACN) was given in [35]. Creating attentive figuring may be known as a CACN operating in higher access management levels. The data collected by sensors for their unique service shall be regarded as original data, which have been legitimately gathered from the earth moving forward without any more handling. With crude information alone, it gets testing to break down and decipher them, and not to mention the enormous information created by the huge scope arrangement of sensors. With data and providing valid and efficiently understandable data, sensors need to participate in the careful registration process.; that is, sensors need to store prepared significant data, otherwise called “setting data”, that is effectively reasonable [36, 37]. A reference to both the comparison among raw sensor data and establishing data will be insulin readings obtained by bio-clinical sensors on patient assemblies that are regarded as original data. At the stage where these measurements are processed with spoken to as the blood glucose level of the person, the data set is indicated. The presence of the perspective (QoC) metric will be used to assess relevance, reliability, quality, and existing structure data [38]. Establishing careful registration to protect, plan, delete, and think can be accomplished by applications themselves, by using libraries and toolboxes, or even by using a middleware stage [39]. The setting data can be additionally ordered into an essential setting and optional setting, which gives data on how the information was acquired. For instance, perusing RFID labels legitimately from various creation parts in mechanical plants is viewed as the essential setting, while at the same time getting similar data from the plant’s information base is alluded to as the optional setting [40, 41].
10.5 Spatial Prediction
Collecting image data on objects in a good way is referred to as far away from detection (RS) [42]. RS is an important part of the analysis of the earth. For context, space-borne and airborne detectors acquire multi-spatial and multi-transient RS information from a multinational environment to allow Earth monitoring and emission evaluation [43]. Numerous different remote sensing technologies comprise Google Earth, which provides images of the world’s atmosphere, environmental degradation, traffic congestion, hydrology, and oceanography [44]. In [45], the creators proposed a major information diagnostic engineering for continuous RS information preparing utilizing earth observatory framework. The ongoing preparation incorporates filtration, load adjusting, and equal handling of the valuable RS information. The RS datasets are regularly geologically disseminated over a few server farms, prompting troubles in stacking, scheduling, and acquisition of experiences. In contrast, the computational complexity of RS information makes their ability and information access very confusing [46]. So that’s why in [47] it suggested a wavelet shift to relate to RS large knowledge by crumbling variables into multi-scale detail coefficients that are measured using preference to improve the likelihood. In [48], the study compared the importance of RS data utilizing evidential extrapolation without using the former database information to deliver a reasonable validity advisor.
10.5.1 Global Optimization
Mostly with a touchy rise in smartphone use, portable information has experienced significant growth, conveying gigantic measures of data on client applications, network execution information, administration attributes, geographic data, endorser’s profile, etc. [49]. This has prompted forming the idea of “enormous portable information”, which, dissimilar to customary huge information in PC organizations, have their extraordinary attributes. One of these attributes is the capacity to segment versatile information in reality spaces, for example, in minutes, hours, days, area, etc. Moreover, because of the highlights of cell phones’ utilization related activity, on the one side, could be almost assured of a grouping of followers in a given time and place; and, on the other hand, emotional connection supporters can demonstrate relative actions and connectivity designs, both of which can help to improve system performance [50]. Public authentication facilitates the convergence of these community activities and web-based contexts to help anticipate cultural characteristics that can execute activities, organize and support social remote organizations more efficiently than any other time [51, 52]. For example, because of high social connections and connections among supporters, an independent group association can be developed in which descriptions of motivation, interest, accessibility, and exchange can be used to create social network networks and disintegrate contact practices. However, one case of Client Social Deployment is the well-known Pokemon Go game, where Clients exchange constant references to the creation of Pokemon characters [53]. Another model where social registering can be useful is in crisis circumstances, for example, the spread of irresistible infections, where taking the suitable strategies by examining human communications and foreseeing the crisis’ development can help secure the general well-being [54]. This paper [55] announced Cybermatics by way of a bigger visualization of IoT (exercise intensity increases-IoT) to solve scientific research problems in heterogeneous digital-physical social reasoning (CPST) hyperspace.
10.5.2 Big Data Analysis CPS
Cloud technology, beyond the data sorting, facilitates the fair management and implementation of undertakings and problems. Scheduling and planning of work activities in a multi-cloud condition improve monitoring and takes into consideration the great intellect of the management. In this area, we examine distributed computing, enormous information bunching, NoSQL, and mist registering for large information work processes preparing.
10.5.3 Analysis of Cloud Data
Mostly with an abundance of data in the exabyte order, it turns out to be almost impossible to manage data on a particular computer, irrespective of how amazing this is. Equal preparing of the information lumps on devoted workers, for example, the MapReduce apparatus proposed by Google offers preferences over regular handling strategies; anyway, it is as yet not exceptionally compelling to deal with a lot of information, primarily because of versatility, inertness, accessibility, and wasteful programming methods, including however not restricted to information base administration frameworks [56, 57]. One appealing answer for committed workers is the preparation on cloud focuses, which offers clients the capacity to lease processing and capacity assets in a pay-more only as costs arise way. Moreover, even though clients will be sharing typical equipment, the mutual assets seem selective to them through machine virtualization employing concealing the stage subtleties [58]. Nonetheless, this methodology can make issues in the pay-more only as costs arise condition because of untruthfulness, injustice, and failure of assets and the remaining task at hand exchanges [59]. The big distinction between parallelization approaches, along with MapReduce and cloud services, would be that MapReduce uses map developers and modifiers to develop outcome variables and expected outcomes separately. Nevertheless, open mists offer clients of virtual machines (VMs) a highly flexible set of scores [60]. The capacity of Map is accountable for handling input key-esteem combines and creating middle key-esteem sets, while Reduce work is utilized to additionally pack the worth set into a littler set dependent on the halfway qualities with similar keys [61]. To amplify the inquiry pace of distantly found information trying to boost framework execution, the creators in [62] structured a unique asset designation calculation that considers the calculations of question streams over the hubs and the restricting number of assets accessible. Because of the volume and speed qualities of large information, streaming information handling and capacity may require distinctive pressure strategies to guarantee effectiveness and adaptability. Yang et al. proposed a novel low information precision misfortune pressure method for cloud information preparation and capacity. A comparability check was performed on parcelled information lumps, and pressure is led over the information pieces as opposed to the essential information units [63]. Another comparability registration pressure method was proposed in [64] utilizing weighted quick pressure separation. Combining cloud technology in IoT will take the planning of the monitoring of available data towards the next level and include pervasive monitoring of entities beyond the capability of autonomous individuals. At the point when joined with computerized reasoning, AI, and neuromorphic registering strategies, it is imagined that new applications will be created with robotized dynamics, which would alter the field of shrewd urban communities, modern plants, General statement, and so on (consider Figure 10.2). Cloud computing can support IoT applications with a minimized lack of mobility, resource utilization, and greater flexibility. The instances of such applications involve, but are not confined to, medical care, where patient information can be collected via a cloud-based system [65]. Cloud services are mists that are closer to customers to support the high implementation of idleness and to cause unreliable mists to be used [66]. Other cloud technology models represent traffic light system vehicles [67], genome research [68], earth’s physical analysis [69], and some others.

Figure 10.2 Show automated CPS cycle.
10.5.4 Analysis of Multi-Cloud Data
In a variety of IoT logical applications, knowledge abundance and duration, measurement, planning, and examination are divided into the work process, consisting of various reporting products. Because of the information-escalated nature of IoT applications, the enormous scope of work processes should be circulated over various cloud communities [70]. To permit the help of numerous applications and to conquer the constraints of current systems that are devoted to a remarkable kind of uses, makers in [71] suggested a distributed implementation of the multi-cloud framework of the panel by using a domain-specific language (DSL) to increasingly represent technologies. In every event, the between cloud interchanges comprise a serious deal of the money-related expenses of handling work processes because of their enormous volume. In [72], to advance framework execution, Wu et al. proposed a spending plan that obliged work process planning in multi-cloud conditions. An effective on-demand cause condition for broadcasting massive information handling in multi-cloud conditions was suggested in [73] to provide a low cost of database load planning while at the same time magnifying the revenue of specialized network organizations. For building trust over various cloud focuses that work together on information stockpiling and preparing, in [74] proposed a trust-mindful observing design among clients and cloud focuses with various leveled criticism system to upgrade the power and dependability of the nature of administration of cloud suppliers, that mostly gives them ratings that rely on their confidence notoriety. It, therefore, helps users to choose domains from various cloud services that rely on reviews and past supporting documentation. In [75], Wang et al.’s Advanced Virtual Machinery (VM) in cloud computing server farms allows reducing the influence of records often used serious entities, such as the global survey. In all of these cloud environments, VMs are assigned to individual employees, granting users a high degree of management, but at the cost of higher productivity usage. The compromise between vitality utilization and the nature of administration is contemplated in the enhancement issue. The expense of information access and capacity restrictions of public cloud communities was considered in [76]. The creators utilized Lagrangian unwinding-based heuristics calculation to acquire the ideal server farms position that can decrease information access costs. The circulation of clients’ undertakings on geologically appropriated cloud communities was tended to in [77], where the creators proposed major information the executives answer for amplify framework throughput with the end goal that reasonableness of restricted assets utilization by clients is ensured and the operational expense of specialist organizations is diminished. To identify client-focused multi-cloud properties, a multi-round combination two-fold closeout based method was proposed in [78] where the existing members and the server farms carried out bartering on separate VMs in many matches to ensure the highest level of safety.
10.6 Clustering of Big Data
Information bundling denotes the bundling of several features in separate sets of comparable papers and insights [79]. Information grouping turns out to be exceptionally helpful Comprehensive data applications where there is a substantial necessity to assess and evaluate the significant amount of data available. Analyzing the number of gatherings is becoming important as the arrangement promotes the movement of working frameworks, activities advancement [80]. Figure 10.3 shows two gatherings of bunching strategies investigated top to bottom in writing:
- i. various leveled grouping, and
- ii. centroid-based grouping.
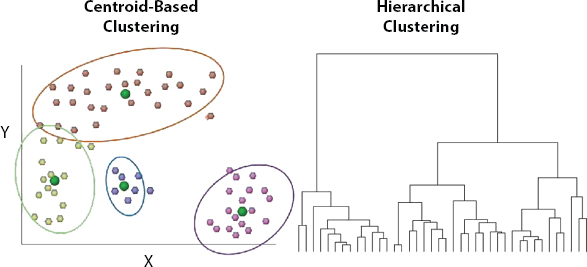
Figure 10.3 Show clustering of big data.
In different leveled clustering, close objects are more likely to be collected than far away items. Besides that, in the centroid-based bundling, the bundle of protests is mounted. The paper [81] looked at the ability to adapt the composition of the different conceptual and administrative groupings or the newly developed tensor-based multi-cluster system (TMCs). Among the most popular centroid-based groups are k means, analytical abilities, and narrow-intricacy usage. Notwithstanding, as the quantity of bunches builds, k-implies grouping experiences the vacant grouping issue and the expansion in the number of cycles for the union. This implies customary k-implies aren’t appropriate for huge information applications. Various works have recommended upgraded adaptations of k-implies grouping for reasons for improving bunching quality, execution time, and precision. For example, in [82], the creators utilized an improved variant of the means bunching, where the underlying centroids of the group are not chosen arbitrarily however dependent on averaging the information focuses. This accomplishes higher exactness than ordinary k means. Another upgraded form of kimplies bunching was proposed in [83] to help dispose of the vacant grouping issue of customary k-implies. The selection process was based on several Fireworks, and algorithm-search estimates, with the descriptive focus was given as the centroids. In [84], the developers have used the centroid approximation algorithms to further boost the sorting performance by increasing the number of bunches. In [85], for example, the developers used proactive clustering in their suggested estimation, in which the number of participants was calculated as externally depending on the reorganized separating system. Learning tests were grouped to use a single link (SL) that divides large sorting tree centers into the main switching tree (MST). The estimate was shown to be unmatched in terms of bundling speed and efficiency relative to other labeling calculations as k-implies. A further radical bundling has been discussed throughout [86], where clients themselves characterize the number of groups dependent on various likeness estimates, for example, homogeneity and the overall populace of each bunch. This improves client fulfillment of the grouping calculation. A different leveled k-implies bundling method was presented in [87] to discover the smart approach of the centroids. The centroids have become reliant on the established work of the k-implies, which consists of a few levels, where the main level is the first dataset. Subsequent levels are compromised by smaller database sizes, which provide comparable examples as the first dataset. Fluffy bundling, another bundling technique, is like k-implies; in any case, an article may be connected to more than one single package, depending on its degree of involvement that is normally determined dependent on Euclidean separations between the item and the server farm [88]. Either broad data collection is the Class Highlights (CF) where the CF-tree incorporates a description of the data formats into the group. It utilizes a user limit to decide the quantity of the sized gatherings in the CF-tree. Consequently, this method can also have complexity and consistency problems, particularly with the amount of information that needs to be investigated and examined to build a graph. The design, which is focused on detailed assessment, allows the edge to be distinguishable for various miniature groups by equilibrium positions it by development and sustainability [89]. The grouping of diagrams aims to gather the information that is based on the layout of the organization and the relationships of hubs, where the similarities between hubs enable them to be correlated with the creation of a network. The system will establish a Tweet schematic for Twitter’s social networking application where Tweets (hubs) with similarities (comparable URL count, comparable keyword quest, or corresponding username count) are linked to edges [90]. Throughout the long run, continuous mining helps to solve the rising challenges of network size and awareness growth by constantly updating groups without the need to duplicate them without any preparation. As far as the implementation of CPS is concerned [91], attempts have been made to incorporate structural CPS-based sensor groupings for reasons that reduce the vitality of the sensor organization. The sensor network is divided into small equivalent groups, each consisting of a lot of bunches, the sum of which is carefully chosen, focusing on the high-end segment of the delegate and its division to the core network, to accomplish resilience quality. In [92], the development teams sought to address the frustration of the CPS subnetworks by increasing the upper limit on the size of small groups to alleviate the frustration of the organizations, particularly once they are strongly connected. In [93], the authors proposed a safe grouping technique for CPS vehicles, where a trust metric is defined for each vehicle that is dependent on its transmission characteristics to generate secure bundles. Another safe grouping for CPS vehicles was proposed in [94], where the bundling problem is described as an alliance game thinking about the relative speed, location, and transmitting capability of vehicles. Moreover, motivating forces and punishment systems are recommended to keep egotistical hubs from corrupting the correspondence quality execution. A thickness-based stream information bunching for constant checking CPS applications was proposed in [95], where the creators utilized FlockStream calculation to amass comparative information streams. Every information point is related to an operator, and comparable specialists inside a perceptibility scope of one another in the virtual space, structure a group considering constant stream bunching.
10.7 NoSQL
Conventional social information base administration frameworks are not appropriate for heterogeneous large information preparing, as they comprise of severe information Predefined information technology and criteria model with a defined schematic [96]. NoSQL (Structured Query Language not only) loosens up a considerable lot of the social information bases’ properties, for example, ACID conditional properties to take into consideration more noteworthy questioning adaptability, operational versatility and effortlessness, higher accessibility, and quicker read/compose activities of large unstructured information through repeating and parceling the information over a few hubs [97, 98]. NoSQL information bases can store information in three distinct structures: key-esteem stores, archive information bases, and section situated information bases [99]. In the archive information bases structure, the information is put away in a perplexing structure, for example, XML records. Section situated information bases store segments of information in information tables, permitting more prominent simplicity of adding and erasing segments contrasted with column arranged information bases. Also, there are two primary categories of NoSQL frameworks: Operating NoSQL structures. (The main difference between OLTP and DSSs though, is that it includes handling greater tables and, therefore, it implies the planning of difficult issues (verifying, entering, and totaling), while OLTP conducts reading/composing tasks for smaller parts in the knowledge base. For example, in [100], the developers used NoSQL for large-scale information work processes to enhance flexibility, synchronization primitives, and execution compared to the traditional MapReduce framework.
10.8 Cyber Security and Privacy Big Data
In the field of digital–physical systems, the close relationship between structural elements that collect and transmit a huge quantity of information puts safety hazards under the glare. With this enormous measure of knowledge that continues to flow through the enterprise, it is important to secure the system from cyber threats [101]. In this area, we give a diagram of the diverse security arrangements proposed for enormous information stockpiling, access, and investigation.
10.8.1 Protection of Big Computing and Storage
Cloud-based information storage provides the capacity for vindictive attacks, despite the possible security attacks by systems. This seriously undermines if cloud information storage is feasible, especially for administrative bodies and strategic companies. In [102] it suggested a strategy that would record parts into fragmented pieces and preserve them in a cloud-based transmitted workforce lacking clear access to client information from performance monitoring. In [103], the creators proposed that information ought to be scrambled and unscrambled before being sent to mists. The paper [104] focused on the potential applications for blending mode in iOS gadgets. In [105] it proposed a protected information move plot where clients scramble the information hinders before transferring to the cloud. Cloud information deduplication presents another test, particularly when information is shared among numerous clients. Even though synchronous replication can reserve 95% of the advantages offered for clinically tested and 68% for statistical data shows structures [106], it spends resources and consumes productivity and entangles the authority’s knowledge. In [107], Yan et al. attempted to resolve virtualization concerns by introducing a proposal for clients to pass encoded information to the cloud with an information replication verification token that can then be used by specialised cloud organizations to verify if the content has also been deleted. A program to verify the presence of records has been placed in place to ensure the safe information of executives.
10.8.2 Big Data Analytics Protection
Supporting security and defense aspects of the large-scale information analysis has attracted the attention of established researchers, essentially for a range of factors. To start with, the information is more probable put away, handled, and broke down in a few cloud places prompting security issues because of the irregular areas of information. Second, large information examination comparably treats delicate information to other information without taking safety efforts, for example, encryption or visually impaired handling into thought [108]. Third, huge information calculations should be shielded from malignant assaults to protecting the trustworthiness of the separated outcomes. In the domain of CPS, a colossal measure of information make the reconnaissance of security-related data for oddity discovery a difficult undertaking for experts. In health care, for example, the security problems of extracting data from an immense availability of data and accurate analysis are of great significance. Delicate information recorded in information bases should be ensured through observing which applications and clients get gets to the information [109]. To ensure a solid secure large information examination, the accompanying undertakings can be performed [110]:
- Surveillance and checking of ongoing information streams,
- Implementation of cutting edge security controls, for example, extra confirmation and obstructing dubious exchanges,
- Anomaly identification in conduct, use, access, and organization traffic,
- Defending the framework against noxious assaults in realtime,
- Adoption of perception methods that give a full outline of organization issues and progress continuously.
The case of cellular organizations [111], vast information is seen as large pulling global integration of 1) an enormous number of control messages toensure unwavering consistency, protection, and communication skills; 2) major traffic information requiring traffic observation and analysis to change the network stack and streamline the system execution; 3) major area data given by GPS sensors; for example, transportation frameworks, open well-being, wrongdoing problem areas investigation, etc., 4) major radio waveforms information exuding from 5G huge MIMO frameworks to appraise clients’ moving pace for motivations behind discovering relationship among communicated flags just as aid channel assessment, and 5) major heterogeneous information, for example, information rate, parcel drop, versatility, etc. that can be dissected to guarantee cybersecurity. The work [112] proposed a safe high-request bunching calculation through quick pursuit thickness tops on half and half cloud for the modern Internet of Things. AI provides a better response amongst these multiple networks to mechanize a substantial proportion of security-related undertakings, in general, the continuous production of movement from one place on a scale and wide-ranging design. Through the way toward preparing datasets, AI makes conceivable the location of future security peculiarities through distinguishing unordinary exercises in the respective authorities. To attain greater reliability, an incredible amount of repository planning is required, but this may be at the expense of each of those workloads and a conceptual approach. The method of preparing may be directed, either solo or moderately controlled, depending on whether the outcome of a particular data set is now recognized. Especially, the framework begins by characterizing comparable datasets into bunches to decide their inconsistency. A human examiner would then be able to investigate and recognize any abnormal information. The result found by the examiner would then be able to be taken care of back to the preparation framework to make it more “directed” [112]. It will help the design process to adapt to emerging types of danger without user interaction so that improvements can be made rapidly while serious damage occurred. Various methodologies for peculiarity identification exist in writing, for example, discretizing the persistent space into various measurements, for example, in the reconnaissance framework in [113], for which the researcher has divided the observing region into a grid pattern, where the locations and speeds of moving objects falling in each cell are shown by a Poisson point scale. Another technique is the Gaussian probability test, where the knowledge is celebrated as odd when multiple standard deviations from the mean are identified. For instance, in [114], the creators utilized multivariate Gaussian investigation to distinguish Internet assaults and interruptions through dissecting the measurable properties of the IP traffic caught. In bunching techniques, for example, k-implies grouping, information focuses can be gathered into groups dependent on their separation to the focal point of the bunch. Again at this point, if there is an awareness point beyond the collecting community, these are assumed to be uncertainty. The designers the [115] utilized piece k-implies grouping with nearby neighborhood data to distinguish an adjustment in a picture by ideally figuring the portion loads of the picture highlights, for example, force and surface highlights. Concerning the counterfeit neural organization approach, one execution of such a model is the autoencoder, otherwise called replicator neural organization, which banners irregularities dependent on estimations of the distinction between the test information and the reproduced one. This implies if the blunder among test and remade information surpasses a predetermined limit, at that point, it is considered far away from a sound framework appropriation [116]. A case of such a methodology is given in [117], for which developers used the auto-encoder as high efficiency and low idleness model to discern the characteristics of the use of productivity and the operation of the higher meters. Security protecting information investigation and mining can be very testing assignments since breaking down scrambled information is a wasteful, exorbitant, and non-direct arrangement. Homomorphic encryption is one of the arrangements proposed to empower explanatory activities to be performed on figure messages utilizing different numerical tasks [118, 119]. For example, in [120], the creators utilized Efficient Privacy-protecting Outsourced estimation with Multiple keys (EPOM) homomorphic encryption to encode information before sending it to the cloud. The cloud, at that point, uses the ID3 estimation to conduct data mining on complicated information. The relevant control of a dynamic tree selection to decide the qualities of a lot of tests deliver the best expectations or data benefit. A further technique for optimizing mining for coded cloud information using homomorphic encryption has been proposed [121]. The Cloud Specialist Co-op (CSP) collects and stores encrypted information, while the worker, referred to as the Evaluator, teams up with the CSP to carry out the mining of scrambled information. A digger submits scrambled mining questions to the CSP, which thus defines the internal point between the vectors to determine the recurrence of the mining objects without the CSP and the Evaluator approaching the touch information. However, the encryption algorithm can be computationally intensive and illogical for large datasets [122]. One possible way to deal with safe, private information during the investigation processes is by using the h t-anonymization suggested in [123]. To start with, clients who access the information should be confirmed and approved dependent fair and square of shared outcomes’ security. Now at this stage, a breakdown of encrypted and necessary markers is created to be used as an information channel for the data that can be accessed by the authorized client. K-anonymization is then applied to the known segments in the data-set to summarise or remove the significance of the yield dataset. The effect is a k-anonymized list on which the investigation and mining of the authorized open access can be carried out. Even though k-anonymization has all the hallmarks of being a compelling flexible way to deal with security safety of information investigations independently of the specific cycles, its probability for spatial frequencies and simulation efficiency is feasibly not further assessed in the vast information settings. Also, k-anonymization can be difficult if different datasets have the same sensitive characteristics [124]. One methodology that endeavors to tackle this issue are the cosine closeness calculation convention recommended in [125]. The proposed approach takes into consideration bigger datasets adaptability for both twofold and mathematical information types in a periodic proficient way. The thought is to permit information to be shared without uncovering the touchy data to unapproved clients. This should be possible using figuring the scalar item between various vectors of mathematical qualities, for example, computing the edge cosine among both. Getting a result more like one indicates that variables are just like each other. Then again, a significant number of the huge information applications have various leveled structures in nature, and in this manner, require progressive protection safeguarding arrangements. For example, in [126], various leveled cloud and network access control can be executed to reinforce security protection in savvy homes and keen meters. The home regulator, which ensures family close to home information, is associated with a cloud stage through a network organization, which gives protection saving answers for homes through information detachment, total, and combination. The cloud consolidates the entrance control plans for homes and networks in more mind-boggling and more grounded security assurance measures.
10.8.3 Big Data CPS Applications
We are actively presenting a portion of key CPS large-scale information applications in various areas, such as the use of productivity, city officials, and failed projects, along with an open security contextual investigation model. Figure 10.6 demonstrates identifiable CPS technologies and their enormous knowledge age. For instance, the shrewd transport infrastructure will yield tremendous details on the behavior of operators, traveler data, vehicles’ areas, traffic lights the executives, mishaps’ announcing, mechanized charge figurings, etc. Every last one of the CPS applications creates a lot of information that should be put away, prepared, and investigated to improve administrations and applications’ exhibition.
10.9 Smart Grids
Smart lattices comprise a significant part of manageable vitality usage and are getting more famous, particularly with the advances in detecting and sign handling advances. Robotized shrewd choices dependent on the huge number of information and control focus assume a significant function in dealing with the vitality utilization designs, understanding clients’ practices, decreasing the need to manufacture power plants, and tending to flexibly vacillations by utilizing inexhaustible assets [127]. The enormous number of implanted force generator sensors and their interchanges with various home sensors and apparatuses are required to create a lot of information shown in Figure 10.4. These serious detecting and control innovations utilized in keen frameworks are regularly restricted to a little district, for example, a city; anyway, they are imagined to be conveyed on a lot bigger scope, for example, the entire nation. This will present a few difficulties, among which data the board, handling, and investigation are the fundamental ones [128]. These enormous information assignments get much more confounded with the expanding number of exchanges that should be prepared for many clients. For example, one brilliant network utility is relied upon to deal with 2,000,000 clients with 22 GB of information every day [129]. That is the reason huge information apparatuses from distributed computing [130], mining and examination [131], execution enhancement [132], and others have been devoted for brilliant lattices applications. Additionally, for solid force networks, savvy matrices profoundly rely upon the digital framework. This represents a few difficulties, for example, uncovering the physical activities of savvy matrix frameworks to digital security assaults [133]. Besides, the assortment of clients’ vitality utilization data, for example, the sorts of machines they use, the eating/resting designs, etc., can be useful in enhancing savvy matrices’ exhibition; anyway, clients’ protection can likewise be influenced. In [134], Yassine et al. proposed a hypothetical game system to adjust between clients’ private data and the gainful employment of information. In [135], major information design for brilliant frameworks dependent on irregular grid hypothesis was proposed to lead a high dimensional investigation, distinguish information relationships, and oversee information and vitality streams among utilities. The proposed design permits enormous scope large information examination as well as can be utilized as an inconsistency identification apparatus to recognize security imperfections in keen lattices. For security dangers that happen in a brief timeframe, a security situational mindfulness procedure was proposed in [136], which utilizes fluffy bunch investigation dependent on game hypothesis and support figuring out how to improve security in keen frameworks. A major information processing design for keen frameworks was proposed in [137] with four fundamental components:

Figure 10.4 Shows CPS smart grid.
- 1) information asset where brilliant matrices information is produced by various gadgets, organizations, and frameworks with the complexities associated relationship among them
- 2) information stockpiling where just significant data is put away and handled with in-stream mode or clump mode
- 3) information examination utilizing request side administration or burden anticipating for reasons for classifying the complete interest reaction in a particular district
- 4) information transmission, which connects the past components
Utilizing this engineering with a vitality planning plan dependent on game hypothesis and a nonexclusive calculation-based improvement to acquire the ideal sending of vitality stockpiling gadgets for every client, the outcomes show a critical decrease in all-out expenses of customers over the long haul. In [138], the consolidated worldly encoding, postponed input organizations (DFNs), supply registering (RC) usage, and a multi-layer perceptron (MLP) were utilized to execute powerful assault identification for savvy lattice organizations.
10.10 Military Applications
Big information can likewise be misused to improve military encounters, administrations, and preparation. Constant verification of order and control messages in digital–physical foundations is of high significance for military administrations to guarantee security is shown in Figure 10.5. In [139], the creators built up a novel transmission confirmation conspire to utilize extraordinary computerized marks for quicker mark age and check and bundle misfortune resilience. This can be valuable to effectively and quickly secure military correspondences. In [140], the creators utilized the Markov choice cycle to propose a way to deal with distinguishing and lessen assaults’ expense in military tasks to ensure significant data through acquiring assault arrangements. Military satellite correspondences require being tough to guarantee missions’ prosperity. This can be accomplished utilizing a network put together security evaluation approach based on conventional danger examination, where an assault can be surveyed as far as both simplicities of assault and effect of assault [141]. Moderating the accompanying five center dangers permits the satellite correspondences to be liberated from frail weaknesses that can be handily misused by assailants: waveform, RF admittance to foe, unfamiliar presence, physical access, and traffic focus [142].
Figure 10.5 Shows CPS military application.
10.11 City Management
Big data will promote day-to-day activities by using amazing systems and administrations. With such the different sensors being sent cosmopolitan conditions, whether indoor or open-air, from developed mobile phones, smart cards, on-board vehicle detectors, etc., the city is confronted with a lot of data that should be misused to discern identifiable metropolitan distinct [143]. For example, traffic examples can be examined, and courses can be registered to permit individuals to arrive at their objections quicker is shown in Figure 10.6. In [144], the creators proposed to convey street sensors to acquire data on the general traffic, for example, speed and area of individual vehicles. This data is then handled utilizing chart calculations by exploiting enormous information instruments, for example, Giraph, Spark, and Hadoop. This gives continuous wise choices to keen productive transportation. Since remote sensor organizations (WSN) are the principal frameworks for keen urban communities to screen and accumulate data from nature, a few works have zeroed in on broadening the organization’s lifetime. For example [145], the creators proposed utilizing programming characterized organizing (SDN) regulator to lessen WSN traffic and improve choice making.

Figure 10.6 Shows CPS smart city application.
IoT-based general engineering for shrewd urban communities was introduced in , which comprises of four distinct layers:
- 1) advancements layer comprising of self-arranged and distantly controlled sensors and actuators,
- 2) middleware layer where information from various sensors are gathered to give setting data,
- 3) the board layer where diverse information logical apparatuses are utilized to separate data, test theory and reach inferences, and
- 4) administrations layer comprising of administrations gave by keen urban areas dependent on the past layers, for example, ecological observing, vitality effectiveness in structures, astute transportation frameworks, and so on.
Security frameworks, for instance, the transmission of tactile sensors, are vast knowledge applications from the other city to the board. A CP vision deep learning estimation for the identification of human gestures has been proposed. The platform is developed for the interpretation of twelve types of human exercises with extreme accuracy without the need for any prior knowledge, which makes it useful for security observation purposes. Community identification and appreciation is yet another wellbeing mechanism for a broad application of knowledge. An impartial person should be derived successfully from sensor information. In, the developers suggested a system that would be able to identify the target area and update the movement data without too much stretch to enhance the discovery.
10.12 Clinical Applications
CPS wellbeing frameworks are predicted to shape the eventual fate of tele-medication in various regions, for example, cardiology, medical procedure, patients’ wellbeing observing, which will altogether improve the medical care framework by giving opportune, proficient, and compelling clinical choices for a bunch of wellbeing applications, for example, diabetes the executives, pulse and heart cadence checking, old help, etc. With 774 million associated wellbeing related gadgets, a huge volume of information from little scope organizations, for example, e-wellbeing frameworks or versatile wellbeing frameworks, should be put away, prepared, and investigated to empower opportune mediation and better administration of patients’ wellbeing. With e-wellbeing frameworks getting broadly conveyed in emergency clinics and wellbeing focuses, research has been centered around productively sending clinical body territory organizations (MBANs) to diminish obstruction on clinical groups from different gadgets. In MBANs, biomedical sensors are set in the region of the patient’s body or even inside her to detect wellbeing related indispensable signs utilizing short-run remote advancements. The gathered information is then multi-bounced to far off stations, so the clinical staff can productively screen patients’ physiological conditions and infection movement. For example, in, old patients’ wellbeing following application was proposed, where a blended situating calculation takes into consideration 24-hour observing of patients’ exercises and sends an alert to clinical staff through SMS, email or phone if there should be an occurrence of an irregular occasion or crisis. Notwithstanding, sending this wellbeing data in an ideal and vitality effective way is of the most extreme significance for e-wellbeing frameworks. In, Structured engineering accomplishes lower memory overhead, lower programming segment load time, and lower occasion proliferation time than other comparable propositions, which are, on the whole, basic prerequisites for vitality proficiency, unwavering quality, and adaptability of e-wellbeing frameworks. The paper proposed region delicate hashing to learn sensor designs for observing the well being states of scattered clients.
10.13 Calamity Events
Applications Network strength and survivability are the most extreme prerequisites for open security organizations. If there should arise an occurrence of a fiasco or crisis occasion, the individuals who are first on the scene are alluded to as specialists on call, and they incorporate law requirements, firemen, clinical faculty, and others (Figure 10.7). A portion of the significant open security prerequisites identifies with the need for specialists on call for trade data (voice and additionally information) in an opportune way. The large information can be utilized to help calamity occasions, for example, by examining huge information. The distant detecting large information can be examined utilizing a versatile half and half parallelism way to deal with decrease the examination execution time. The huge measure of information gathered from past quakes can be utilized to anticipate the future help accessibility regions, which can improve readiness and reaction to such occasion. A fiasco space explicit web index can be built utilizing ample information to comprehend and plan calamity assaults simpler and quicker for specialists.

Figure 10.7 Shows CPS environmental application.
10.14 Data Streams Clustering by Sensors
Remote sensor networks are conveyed independent organizations comprised of miniature hubs with sensors, information preparing unit, and remote correspondence segment. Remote sensor networks give solid tasks in different application regions, including ecological checking, wellbeing checking, vehicle global positioning framework, military watch spear, and quake perception. Sensors networks encourage the way toward checking the physical condition and settle on a constant choice about occasions in nature. In such checking applications, programmed occasion identification is a fundamental assignment that targets distinguishing new physical wonders of specific worry to the clients. Specifically, the difference in bunching designs frequently demonstrates something significant is happening. For instance, bunching network occasion streams can assist us with understanding the typical examples, and assault alerts can be raised if the grouping design changes. In an inescapable figuring condition, sensors are frequently dispersed and, as a rule, installed in a few gadgets. Information, perhaps as streams, might be exuded from different sensors, and these streams must be collected, combined, put away, oversaw, and examined for different applications. Rather than endeavoring to stream an enormous measure of information into a focal handling office, we propose to incorporate the outer sources into an organization for portable specialist registering. This organization of specialist handling hubs is an equal PC for design location. Bunching streaming sensors is the assignment of grouping various wellsprings of information streams because of the information similitude. This cycle attempts to remove information about the closeness between information created by various sensors through time. The necessities as a rule introduced for bunching information streams are that the framework must have a smaller portrayal of groups, must deal with information quickly and gradually, and ought to recognize changes in the bunching structure. Calculations intend to discover gatherings of sensors that have comparable conduct through time. In the following segments, after a prologue to the rushing model, a methodology for bunching information streams because of a bio-motivated model is described.
10.15 The Flocking Model
The Flocking model is a learning algorithm of nature that mimics the behavior of a herd of components. In this design, every individual (likely referred to as a fowl) decides on creation preferences without consultation with others. Instead, it works as suggested by a few basic concepts, subject only to flock adjacent individuals and ecological snags. These simple guidelines establish a dynamic worldwide course of action. The basic speeding model was introduced by Craig where only he referred to every human as a “boid.” This design consists of three basic control rules that the body needs to follow in each example over time: divergence (leading to stay away from crashing with neighbors); synchronization (leading towards the normal direction and controlling the speed of neighbors); harmony (leading towards the normal situation of neighbors). A Multiple Species Flocking (MSF) method has been built to replicate rushing behavior among a heterogeneous population of substances more precisely. MSF implements a part comparability decision that allows each body to segregate from its neighbors and to aggregate only those like itself. The extension of this pattern allows the herd to filter out heterogeneous multi-species populations into homogeneous segments containing only people of similar species. Different bodies try to escape different bodies that have divergent highlights by an awkward force which, in turn, correlates to the distinction between the bodies and the closeness between the bodies. The advantage of the operating estimation is the algorithm function of the person looking through the device. The algorithm’s way of looking through all the instruments encourages the bodies to quickly form the group.
10.16 Calculation Depiction
Blockstream is an algorithm thickness-related data flow clustering analysis based on the Numerous Specimen Flocking Method. The measurement requires experts with distinctive simple features to replicate the action of the operation. Each multifaceted knowledge element is connected to a specialty. In our approach, despite the normal operation rules of the running model, we are mindful of the increase in the running model by talking about its type of user. Consultants can be of three types: simple (trying to represent any point in one unit time), p-representative, and o-representative. The description of the last two categories of users reflects the differentiated issues presented by their width-based bundling calculation DenStream for information streams of the micro-group. In the following method, we inspect efficiently the conceptual frameworks used in this procedure. A micro bundle is an extension of the concept of a center point defined by the grouping method DBS May to store a packed image of the knowledge focuses inspected up to now and to compare it with the thoughts of the possible core micro cluster (p-micro bundle) and anomaly micro bundle (o-micro bundle) of these authors. A center point is an object in which the general load of the focal points is, in any case, an integer μ. Bunching is a lot of center objects with group names. The objective of the micro-bundles depends on the idea of schematic specifications and weights. Subsequently allowing for an incorrect representation of the data guides assigned to the micro-bundle, and therefore for the collection of run-down information on the definition of the collection of knowledge. The above gives less importance to intelligence as a means of timing. The mass w of the micro bundle must be at the end of the target that w ≥ μ, for example, must be above the predefined edge μ, to be perceived as the middle. As controlled entirely, the quantity of knowledge in streaming applications is enormous or maybe unlimited, too large to even think of fitting into the primary memory of the Computer. In this manner, a component to store run-down of information seen so far is fundamental.
10.17 Initialization
To establish a lot of main operators, for instance, a lot of emphases are arbitrarily transmitted to the virtual environment and operates at the same time as a predefined number of accents. Basic specialists move as per the MSF classifier and, compared to birds operators who share comparable item vector highlights, will aggregate and become a herd, while different flying creatures will move away from the group. In our measure, we use the Euclidean separation to gauge the consistency between the two data points A and B and consider A and B to be analogous if their Euclidean distance is equal. d(A,B) ≤ ∈. The Euclidean separation is picked because it is required in the calculation of the run-down measurements, just as in DenStream.
While emphasizing, the conduct (speed) of every specialist A with position Pa is affected by all the operators X with position Px in its neighborhood. The operator’s speed is figured by applying the nearby principles of Reynolds and the likeness rule. The comparability rule prompts versatile conduct to the calculation since the operators can leave the gathering they partake for another gathering containing specialists with the higher likeness. Along these lines, during this predefined number of cycles, the focuses join and leave the gatherings shaping various groups. Toward the finish of the cycles, for each made gathering, synopsis insights are registered, and the surge of information is disposed of. As an aftereffect of this underlying stage, we have two sorts of specialists: p-representative and o-representative operators.
10.18 Representative Maintenance and Clustering
At the point when another information stream greater part of operators is embedded into the virtual space, at a fixed stream speed, the upkeep of the p-and o-representative specialists and internet bunching are per-framed for a fixed number of cycles. Various cases can happen (see Figure 10.8).
- A p-representative cp or an o-representative co-experience another representative operator. On the off chance that the separation between them is below ∈, at that point, they register the speed vector by applying the Reynolds’ and comparability rule (step 5) and join to frame a swarm (i.e. a, a group) of comparable representative (stage 6).
- A fundamental specialist A meets either a p-representative cp or an o-representative co in its permeability run. The similitude between An and the representative is figured and, if the new range of cp (co individually) is beneath or equivalent to ∈, An is consumed by cp(co) (stage 9). Note that at this stage, FlockStream doesn’t refresh the run-down insights because the accumulation of the essential specialist A to the micro bunch could be dropped if A, during its development on the virtual space, experiences another operator more like it.
- An essential specialist A meets another fundamental operator B. The similitude between the two specialists is determined, and if d(A, B) ≤ ∈, at that point, the speed vector is registered (stage 11), and A is gotten together with B to shape an o-representative (step12).

Figure 10.8 FlockStream Algorithm’s pseudo-code.
At the finish of the most extreme number of cycles permitted, for each multitude, the outline measurements of the representative operators it contains are refreshed and, if the weight w of a p-representative decrease below βμ, where β is a fixed exception ness edge, it is debased to turn into an o-representative. In actuality, if the weight w of an o-representative becomes above βμ, another p-representative is made. It is worth taking note of that multitudes of operators speak to bunches; hence the grouping age on request by the client can be fulfilled whenever by essentially demonstrating all the multitudes processed up until now.
10.19 Results
In this section, we are studying the feasibility of FlockStream on the databases generated. The analysis was modified in Java, and all analysis methods were conducted on an Intel(R) Core(TM)2 6600 with 2 Gb of memory. The developed databases used, DS1, DS2, and DS3, are shown in Figure 10.9(a). Each of them comprises 10,000 points and is similar to those used to test DenStream. For a fair analysis, the progress of the information stream indicated by the EDS was rendered by obtaining a similar method [10]. Each dataset was haphazardly chosen ten times, resulting in the creation of an interconnection network of an absolute length of 100,000 with a block of 10,000 for each time unit. The limits used by FlockStream in the tests are comparable to those adopted which are starting focus/representatives Na = 1,000, stream velocity v = 1,000, rot factor λ = 0.25, supply = 16, μ = 10, exception limit β = 0.2, and MaxIterations = 1,000. We evaluated the FlockStream calculation for the non-advanced datasets DS1, DS2, and DS3 (2(a)) to verify the ability of the way to deal with the acceptable status of each category. The results are shown in Figure 10.9(b). In this figure, the circles represent the micro bundle defined by the measurement. We could see that FlockStream precisely restores the shape of the group. The results obtained by FlockStream on the creation of the EDS information stream are shown in Figure 10.9(c) on several occasions. In the figure, the emphasis shows the raw data, whereas the circles display the micro bunches. It can be seen that FlockStream efficiently captures the status of each bunch as information streams grow.

Figure 10.9 (a) Synthetic information sets. (b) Clustering was performed by FlockStream on the manufactured datasets. (c) Clustering performed by FlockStream on the developing information stream EDS.
10.20 Conclusion
The rising CPS advances commonly advantage the innovative progressions in enormous information preparation and investigation. At the point when joined with man-made consciousness, AI, and neuromorphic processing strategies, CPS can accomplish new projects, management, and opportunities, all of which are supposed to be fully automated with little to no human involvement. This would help shift the concept of the “keen world” where the more intelligent water the executives have, the more clever medical treatment, the more perceptive infrastructure, more astute vitality, and more intelligent food will make an extreme move in our lives. In this paper, an extensive description of CPS presented an extensive array of perspectives, accumulating, entry, reservation, steering, handling, and investigation to help us understand and identify the problems faced by CPS, the proposed new solutions, and the key challenges are yet to be addressed.
With the expanding volume in the gathered huge information from digital–physical frameworks, we need an overall instrument to recognize spatial-fleeting examples in an organization of heterogeneous wellsprings of ongoing information. This paper proposes a new knowledge streaming approximation for concept exploration in emerging identify relevantly. The estimate depends on the perceptual thickness of the model developed together for the Multiple Species Flocking. The technique uses a nearby probabilistic multi-specialist search method that allows users to behave independently from each other and to address it exotically only with immediate neighbors. Decentralization and non-competition make the measurement adaptable to exceptionally enormous databases. Future work will zero in on procedures to naturally screen the advancement of the groups, exploiting from the versatile update of bunches previously actualized in the framework. Moreover, we are setting up the arrangement of the framework in the Rainbow stage to all the more likely evaluate the affectability and focal points of the framework regarding limited assets necessities.
References
1. Amini, A., Saboohi, H., Wah, T.Y., Herawan, T., A Fast Density-Based Clustering Algorithm for Real-Time Internet of Things Stream. Sci. World J., Hindawi Publishing Corporation, 5, 326, 2–11, 2014.
2. Stojmenovic, I., Machine-to-Machine Communications With In-Network Data Aggregation, Processing, and Actuation for Large-Scale Cyber-Physical Systems. Internet Things J., IEEE, 1, 2, 122–128, 2014.
3. Giordano, A., Spezzano, G., Vinci, A., Rainbow: An Intelligent Platform for Large-Scale Networked Cyber-Physical Systems. UBICITEC2014, pp. 70–85, 2014.
4. Eberhart, R.C., Shi, Y., Kennedy, J., Swarm Intelligence, The Morgan Kaufmann Series in Artificial Intelligence, USA, 2001.
5. Forestier, A., Pizzuti, C., Spezzano, G., A Single Pass Algorithm for Clustering Evolving Data Streams based on Swarm Intelligence. Data Min. Knowl. Discovery J., Springer, 26, 1, 1–26, 2013.
6. Vallim, R.M.M., Filho, J.A.A., de Carvalho, A.C.P.L.F., Gama, J., A Density-Based Clustering Approach for Behavior Change Detection in Data Streams. Neural Networks (SBRN), 2012 Brazilian Symposium on, pp. 37–42, 20–25 Oct. 2012.
7. Gama, J., Rodrigues, P.P., Lopes, L.M.B., Clustering Distributed Sensor Data Streams Using Local Processing and Reduced Communication. Intell. Data Anal., 15, 1, 3–28, 2011.
8. Reynolds, C.W., Flocks, herds and schools: A distributed behavioral model. SIGGRAPH ‘87: Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, ACM, pp. 25–34, 1987.
9. Cui, X. and Potok, T.E., A Distributed Agent Implementation of Multiple Species Flocking Model for Document Partitioning Clustering. Cooperative Information Agents, pp. 124–137, 2006.
10. Caom, F., Ester, M., Qian, W., Zhou, A., Density-based Clustering over Evolving Data Stream with noise. Proceedings of the Sixth SIAM International Conference on Data Mining (SIAM 2006), pp. 326–337, 2006.
11. Ester, M., Kriegelm, H.P., Sander, J., Xu, X., A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. Proceedings of the Second ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’96), 1996.
12. Tang, L., Yu, X., Kim, S., Han, J., Hung, C., Peng, W., Trualarm: Trustworthiness analysis of sensor networks in cyber-physical systems, in: ICDM, 2010.
13. Tang, L., Gu, Q., Yu, X., Han, J., La Porta, T., Leung, A., Abdelzaher, T., Kaplan, L., Intrumine: Mining intruders in untrustworthy data of cyber-physical systems, in: Proc. Of SIAM International Conference on Data Mining (SDM), 2012.
14. Deshpande, A., Guestrin, C., Madden, S., Hellerstein, J.M., Hong, W., Model-driven data acquisition in sensor networks, in: VLDB, 2004.
15. Elnahrawy, E. and Nath, B., Cleaning and querying noisy sensors, in: WSNA, 2003.
16. Koushanfar, F., Potkonjak, M., Sangiovanni-Vincentelli, A., On-line fault detection of sensor measurements, in: IEEE Conference on Sensors, 2003.
17. Subramaniam, S., Palpanas, T., Papadopoulos, D., Kalogeraki, V., Gunopulos, D., Online outlier detection in sensor data using non-parametric models, in: VLDB, 2006.
18. Xiao, X., Peng, W., Hung, C., Lee, W., Using senior ranks for in-network detection of faulty readings in wireless sensor networks, in: DEWMA, 2007.
19. Wu, J., Bisio, I., Gniady, C., Hossain, E., Valla, M., Li, H., Context-aware networking and communications: Part 1 [guest editorial]. IEEE Commun. Mag., 52, 6, 14–15, June 2014.
20. Nugroho, A.P., Okayasu, T., Horimoto, M., Arita, D., Hoshi, T., Kurosaki, H., Yasuda, K.-i., Inoue, E., Hirai, Y., Mitsuoka, M., Development of a field environmental monitoring node with over the air update function. Agric. Inf. Res., 25, 3, 86–95, 2016.
21. Tang, L., Cui, B., Li, H., Miao, G., Yang, D., Zhou, X., Effective variation management for pseudo periodical streams, in: SIGMOD, 2007.
22. Krishnamachari, B. and Iyengar, S., Distributed Bayesian algorithms for fault-tolerant event region detection in wireless sensor networks. IEEE Trans. Comput., 53, 3, 241–250, 2004.
23. Jeffery, S.R., Alonso, G., Franklin, M.J., Hong, W., Widom, J., Declarative support for sensor data cleaning, in: ICPC, 2006.
24. Yu, X., Tang, L., Han, J., Filtering and refinement: A two-stage approach for efficient and effective anomaly detection, in: ICDM, 2009.
25. Lin, C., Peng, W., Tseng, Y., Efficient in-network moving object tracking in wireless sensor network. IEEE Trans. Mob. Comput., 5, 8, 1044–1056, 2006.
26. Ni, K., Ramanathan, N., Chehade, M.N.H., Balzano, L., Nair, S., Zahedi, S., Kohler, E., Pottie, G.J., Hansen, M.H., Srivastava, M.B., Sensor network data fault types. ACM Trans. Sens. Netw., 5, 360, 1–29, 2009.
27. Ni, K. and Pottie, G., Bayesian selection of non-faulty sensors, in: IEEE International Symposium on Information Theory, 2007.
28. Chorafas, D.N., Business, Marketing, and Management Principles for IT and Engineering, Auerbach Publications, Boca Raton, FL, USA, June 22, 2011.
29. Sanchez, L., Bauer, M., Lanza, J., Olsen, R., Girod-Genet, M., A generic context management framework for personal networking environments, in: Proc. the 2006 Third Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services, IEEE Computer Society, Los Alamitos, CA, USA, pp. 1–8, 2006.
30. Bellavista, P., Corradi, A., Fanelli, M., Foschini, L., A survey of context data distribution for mobile ubiquitous systems. ACM Comput. Surv., 44, 4, 24:1–24:45, Sep. 2012. [Online]. Available: http://doi.acm.org/10.1145/2333112.2333119.
31. Perera, C., Zaslavsky, A., Christen, P., Georgakopoulos, D., Context-aware computing for the internet of things: A survey. IEEE Commun. Surv. Tutorials, 16, 1, 414–454, First 2014.
32. Atzori, L., Iera, A., Morabito, G., The Internet of Things: A survey. Comput. Netw., 54, 15, 2787–2805, Oct. 2010. [Online]. Available: http://dx.doi.org/10.1016/j.comnet.2010.05.010.
33. Swapna, and Raja, R., An Improved Network-Based Spam Detection Framework for Review In online Social Media. Int. J. Sci. Res. Eng. Manage. (IJSREM), 03, 09, 748–752, Sep 2019.
34. Zhang, L., Zhang, L., Du, B., Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag., 4, 2, 22–40, June 2016.
35. Rathore, M.M.U., Paul, A., Ahmad, A., Chen, B.W., Huang, B., Ji, W., Real-time big data analytical architecture for remote sensing application. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 8, 10, 4610–4621, Oct 2015.
36. Wang, L., Zhong, H., Ranjan, R., Zomaya, A., Liu, P., Estimating the statistical characteristics of remote sensing big data in the wavelet transform domain. IEEE Trans. Emerging Top. Comput., 2, 3, 324–337, Sept 2014.
37. Xie, H., Tong, X., Meng, W., Liang, D., Wang, Z., Shi, W., A multilevel stratified spatial sampling approach for the quality assessment of remote- sensing-derived products. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 8, 10, 4699–4713, Oct 2015.
38. Alsheikh, M.A., Niyato, D., Lin, S., Tan, H.P., Han, Z., Mobile big data analytics using deep learning and apache-spark. IEEE Network, 30, 3, 22–29, May 2016.
39. Zhang, X., Yi, Z., Yan, Z., Min, G., Wang, W., Elmokashfi, A., Maharjan, S., Zhang, Y., Social computing for mobile big data. Computer, 49, 9, 86–90, Sept 2016.
40. Tang, M., Zhu, H., Mao, X., A lightweight social computing approach to emergency management policy selection. IEEE Trans. Syst. Man Cybern.: Syst., 46, 8, 1075–1087, Aug 2016.
41. Parameswaran, M. and Whinston, A.B., Social computing: An overview. Commun. Assoc. Inf. Syst., 19, 762–780, 2007, [Online]. Available: http://aisel.aisnet.org/cais/vol19/iss1/37/.
42. Ning, H., Liu, H., Ma, J., Yang, L.T., Huang, R., Cybermatics: Cyber physicalsocial thinking hyperspace based science and technology. Future Gener. Comput. Syst., 56, 504–522, March 2016.
43. Kraska, T., Finding the needle in the big data systems haystack. IEEE Internet Comput., 17, 1, 84–86, Jan 2013.
44. DeWitt, D.J. and Stonebraker, M., Mapreduce: A major step backward. Accessed on July 10, 2017. [Online]. Available: http://databasecolumn.vertica.com/database-innovation/mapreduce-a-major-step-backwards/.
45. Wang, D. and Liu, J., Optimizing big data processing performance in the public cloud: opportunities and approaches. IEEE Network, 29, 5, 31–35, September 2015.
46. Armbrust, M., Fox, A., Griffith, R., Joseph, A.D., Katz, R., Konwinski, A., Lee, G., Patterson, D., Rabkin, A., Stoica, I., Zaharia, M., A view of cloud computing. Commun. ACM, 53, 4, 50–58, Apr. 2010, [Online]. Available: http://doi.acm.org/10.1145/1721654.1721672.
47. Tang, S., Lee, B.S., He, B., Towards economic fairness for big data processing in pay-as-you-go cloud computing, in: Proc. 2014 IEEE 6th International Conference on Cloud Computing Technology and Science (CloudCom), pp. 638–643, Dec 2014.
48. Blanas, S., Patel, J.M., Ercegovac, V., Rao, J., Shekita, E.J., Tian, Y., A comparison of join algorithms for log processing in MapReduce, in: Proc. the 2010 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ‘10, ACM, New York, NY, USA, pp. 975–986, 2010, [Online]. Available: http://doi.acm.org/10.1145/1807167.1807273.
49. Destounis, A., Paschos, G.S., Koutsopoulos, I., Streaming big data meets backpressure in distributed network computation, in: Proc. IEEE INFOCOM 2016—The 35th IEEE International Conference on Computer Communications, pp. 1–9, April 2016.
50. Yang, C. and Chen, J., A scalable data chunk similarity-based compression approach for efficient big sensing data processing on cloud. IEEE Trans. Knowl. Data Eng., 29, 6, 1144–1157, 2016.
51. Lillo-Castellano, J.M., Mora-Jimenez, I., Santiago-Mozos, R., Chavarria-Asso, F., Cano-Gonzalez, A., Garcia-Alberola, A., Rojo-Alvarez, J.L., Symmetrical compression distance for arrhythmia discrimination in cloud-based big-data services. IEEE J. Biomed. Health Inf., 19, 4, 1253–1263, July 2015.
52. Tawalbeh, L.A., Mehmood, R., Benkhlifa, E., Song, H., Mobile cloud computing model and big data analysis for healthcare applications. IEEE Access, 4, 6171–6180, 2016.
53. Whaiduzzaman, M., Gani, A., Naveed, A., Pfc: Performance enhancement framework for cloudlet in mobile cloud computing, in: Proc. 2014 IEEE International Symposium on Robotics and Manufacturing Automation (ROMA), pp. 224–229, Dec 2014.
54. Zhang, D., Shou, Y., Xu, J., The modeling of big traffic data processing based on cloud computing, in: Proc. 2016 12th World Congress on Intelligent Control and Automation (WCICA), pp. 2394–2399, June 2016.
55. Yeo, H. and Crawford, C.H., Big data: Cloud computing in genomics applications, in: Big Data (Big Data), 2015 IEEE International Conference on, pp. 2904–2906, Oct 2015.
56. Zinno, I., Mossucca, L., Elefante, S., Luca, C.D., Casola, V., Terzo, O., Casu, F., Lanari, R., Cloud computing for earth surface deformation analysis via spaceborne radar imaging: A case study. IEEE Trans. Cloud Comput., 4, 1, 104–118, Jan 2016.
57. Wu, C.Q. and Cao, H., Optimizing the performance of big data workflows in multi-cloud environments under a budget constraint, in: Proc. 2016 IEEE International Conference on Services Computing (SCC), pp. 138–145, June 2016.
58. Pham, L.M., Thana, A., Donsez, D., Zurczak, V., Gibello, P.Y., de Palma, N., An adaptable framework to deploy complex applications onto multicloud platforms, in: Proc. 2015 IEEE International Conference on Computing Communication Technologies—Research, Innovation, and Vision for the Future (RIVF), pp. 169–174, Jan 2015.
59. Li, H., Dong, M., Ota, K., Guo, M., Pricing and repurchasing for big data processing in multi-clouds. IEEE Trans. Emerging Top. Comput., 4, 2, 266–277, April 2016.
60. Li, X., Ma, H., Yao, W., Gui, X., Data-driven and feedback-enhanced trust computing pattern for large-scale multi-cloud collaborative services. IEEE Trans. Serv. Comput., 11, 4109, 671–684, 2015.
61. Wang, S., Zhou, A., Hsu, C.H., Xiao, X., Yang, F., Provision of data-intensive services through energy- and QoS-aware virtual machine placement in national cloud data centers. IEEE Trans. Emerging Top. Comput., 4, 2, 290–300, April 2016.
62. Zhang, J., Chen, J., Luo, J., Song, A., Efficient location-aware data placement for data-intensive applications in geo-distributed scientific data centers. Tsinghua Sci. Technol., 21, 5, 471–481, Oct 2016.
63. Xia, Q., Xu, Z., Liang, W., Zomaya, A.Y., Collaboration- and fairness-aware big data management in distributed clouds. IEEE Trans. Parallel Distrib. Syst., 27, 7, 1941–1953, July 2016.
64. Zhao, Y., Huang, Z., Liu, W., Peng, J., Zhang, Q., A combinatorial double auction-based resource allocation mechanism with multiple rounds for geo-distributed data centers, in: Proc. 2016 IEEE International Conference on Communications (ICC), pp. 1–6, May 2016.
65. Kumar, D., Bezdek, J.C., Palaniswami, M., Rajasegarar, S., Leckie, C., Havens, T.C., A hybrid approach to clustering in big data. IEEE Trans. Cybern., 46, 10, 2372–2385, Oct 2016.
66. Reddy, C.K.K., Chandrudu, K.E.B., Anisha, P.R., Raju, G.V.S., High performance computing cluster system and its future aspects in processing big data, in: Proc. 2015 International Conference on Computational Intelligence and Communication Networks (CICN), pp. 881–885, Dec 2015.
67. Zhao, Y., Yang, L.T., Zhang, R., A tensor-based multiple clustering approach with its applications in automation systems. IEEE Trans. Ind. Inf., 14, 1, 283–291, 2018.
68. Shettar, R. and Purohit, B.V., A MapReduce framework to implement enhanced k-means algorithm, in: Proc. 2015 International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), pp. 361–363, Oct 2015.
69. Chandrakar, R., Raja, R., Miri, R., Tandan, S.R., Ramya Laxmi, K., Detection and Identification of Animals in Wild Life Sanctuaries using Convolutional Neural Network. Int. J. Recent Technol. Eng. (IJRTE), 8, 5, 181–185, January 2020 in Regular Issue on 30 January 2020.
70. Karimov, J., Ozbayoglu, M., Dogdu, E., k-Means performance improvements with centroid calculation heuristics both for serial and parallel environments, in: Proc. 2015 IEEE International Congress on Big Data, pp. 444–451, June 2015.
71. Data Visualization Tips, Accessed on December 17, 2016. [Online] Available: http://www.sthda.com/english/wiki/hierarchical-clustering-essentialsunsupervised-machine-learning.
72. Kabul, I.K., Understanding data-mining clustering methods, SAS Research & Development, India, 2016, May 26. Accessed on December 17, 2016. [Online]. Available: http://blogs.sas.com/content/subconsciousmusings/2016/05/26/data-mining-clustering/.
73. Zhao, Y., Chi, C.H., Ding, C., Wong, R., Zhao, W., Wang, C., Hierarchical clustering using homogeneity as a similarity measure for big data analytics, in: Proc. 2015 IEEE International Conference on Services Computing (SCC), pp. 348–354, June 2015.
74. Xu, T., Chiang, H., Liu, G., Tan, C., Hierarchical K-means Method for Clustering Large-Scale Advanced Metering Infrastructure Data. IEEE Trans. Power Deliv., 32, 2, 609–616, 2017.
75. AlShami, A., Guo, W., Pogrebna, G., Fuzzy partition technique for clustering big urban dataset, in: Proc. 2016 SAI Computing Conference (SAI), pp. 212–216, July 2016.
76. Fu, J., Liu, Y., Zhang, Z., Xiong, F., Big data clustering based on summary statistics, in: Proc. 2015 First International Conference on Computational Intelligence Theory, Systems and Applications (CCITSA), pp. 87–91, Dec 2015.
77. Dutta, S., Ghatak, S., Roy, M., Ghosh, S., Das, A.K., A graph-based clustering technique for tweet summarization, in: Proc. 2015 4th International Conference on Reliability, Infocom Technologies, and Optimization (ICRITO) (Trends and Future Directions), pp. 1–6, Sept 2015.
78. Cao, J. and Li, H., Energy-efficient structuralized clustering for sensor-based cyber-physical systems, in: Proc. 2009 Symposia and Workshops on Ubiquitous, Autonomic and Trusted Computing, pp. 234–239, July 2009.
79. Huang, Z., Wang, C., Nayak, A., Stojmenovic, I., Small cluster in cyberphysical systems: Network topology, interdependence, and cascading failures. IEEE Trans. Parallel Distrib. Syst., 26, 8, 2340–2351, Aug 2015.
80. Bali, R.S. and Kumar, N., Secure clustering for efficient data dissemination in vehicular cyber-physical systems. Future Gener. Comput. Syst., 56, 476–492, 2016. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0167739X15002836.
81. Huo, Y., Dong, W., Qian, J., Jing, T., Coalition game-based secure and effective clustering communication in the vehicular cyber-physical system (vcps). Sensors, 17, 3, 475, 2017.
82. Spezzano, G. and Vinci, A., Pattern detection in cyber-physical systems. Proc. Comput. Sci., 52, 1016–1021, 2015. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1877050915008960.
83. Kang, Y.S., Park, I.H., Rhee, J., Lee, Y.H., Mongodb-based repository design for IoT-generated RFID/sensor big data. IEEE Sens. J., 16, 2, 485–497, Jan 2016.
84. Cattell, R.R., Scalable SQL and NoSQL data stores. SIGMOD Rec., 39, 4, 12–27, May 2011, [Online]. Available: http://doi.acm.org/10.1145/1978915.1978919.
85. Patel, J.M., Operational NoSQL systems: What’s new and what’s next? Computer, 49, 4, 23–30, Apr 2016.
86. Strauch, C., Sites, U.-L.S., Kriha, W., NoSQL databases, Stuttgart Media University, Germany, URL: http://www.Christof-Strauch.de/NoSQLDbs.pdf (łł Łłł 07.11. 2012), 2011.
87. Mohan, A., Ebrahimi, M., Lu, S., Kotov, A., A NoSQL data model for scalable big data workflow execution, in: Proc. 2016 IEEE International Congress on Big Data (BigData Congress), pp. 52–59, June 2016.
88. Atat, R., Liu, L., Chen, H., Wu, J., Li, H., Yi, Y., Enabling cyber-physical communication in 5G cellular networks: Challenges, spatial spectrum sensing, and cyber-security. IET Cyber-Phys. Syst.: Theory Appl., 2, 1, 49–54, Apr. 2017.
89. Gai, K., Qiu, M., Zhao, H., Security-aware efficient mass distributed storage approach for cloud systems in big data, in: Proc. 2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), pp. 140–145, April 2016.
90. Kang, S., Veeravalli, B., Aung, K.M.M., A security-aware data placement mechanism for big data cloud storage systems, in: Proc. 2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), pp. 327–332, April 2016.
91. Sekar, K. and Padmavathamma, M., Comparative study of encryption algorithm over big data in cloud systems, in: Proc. 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), pp. 1571–1574, March 2016.
92. Dorazio, C.J., Choo, K.-K.R., Yang, L.T., Data exfiltration from internet of things devices: iOS devices as case studies. IEEE Internet Things J., 4, 2, 524–535, April 2017.
93. Ni, J., Lin, X., Zhang, K., Yu, Y., Shen, X.S., Secure outsourced data transfer with integrity verification in cloud storage, in: 2016 IEEE/CIC International Conference on Communications in China (ICCC), pp. 1–6, July 2016.
94. opened up., Dedupe your data to local or cloud storage Gateway and Filesystem, Backblaze B2, 2016, Accessed on July 1, 2017. [Online]. Available: http://opendedup.org/.
95. Meyer, D.T. and Bolosky, W.J., A study of practical deduplication, in: 9th USENIX Conference on File and Storage Technologies, pp. 14:1–14:20, Feb. 2011.
96. Yan, Z., Ding, W., Yu, X., Zhu, H., Deng, R.H., Deduplication on encrypted big data in the cloud. IEEE Trans. Big Data, 2, 2, 138–150, June 2016.
97. Gahi, Y., Guennoun, M., Mouftah, H.T., Big data analytics: Security and privacy challenges, in: 2016 IEEE Symposium on Computers and Communication (ISCC), pp. 952–957, June 2016.
98. Rao, S., Suma, S.N., Sunitha, M., Security solutions for big data analytics in healthcare, in: Advances in Computing and Communication Engineering (ICACCE), 2015 Second International Conference on, pp. 510–514, May 2015.
99. Mahmood, T. and Afzal, U., Security analytics: Big data analytics for cybersecurity: A review of trends, techniques, and tools, in: Information Assurance (NCIA), 2013 2nd National Conference on, pp. 129–134, Dec 2013.
100. He, D., Chan, S., Zhang, Y., Wu, C., Wang, B., How effective are the prevailing attack-defense models for cybersecurity anyway? IEEE Intell. Syst., 29, 5, 14–21, Sept 2014.
101. Ristic, B., Detecting anomalies from a multitarget tracking output. IEEE Trans. Aerosp. Electron. Syst., 50, 1, 798–803, January 2014.
102. Kumar, S., Jain, A., Prakash Shukla, A., Singh, S., Rani, S., Harshitha, G., AlZain, M.A., Masud, M.A., A Comparative Analysis of Machine Learning Algorithms for Detection of Organic and Nonorganic Cotton Diseases. Math. Probl. Eng., 2021, Article ID 1790171, 18 pages, 2021, https://doi.org/10.1155/2021/1790171.
103. Jia, L., Li, M., Zhang, P., Wu, Y., Zhu, H., Sar image change detection based on multiple kernel k-means clustering with local-neighborhood information. IEEE Geosci. Remote Sens. Lett., 13, 6, 856–860, June 2016.
104. Murphree, J., Machine learning anomaly detection in large systems, in: 2016 IEEE Autotestcon, pp. 1–9, Sept 2016.
105. Yuan, Y. and Jia, K., A distributed anomaly detection method of operation energy consumption using smart meter data, in: 2015 International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), pp. 310–313, Sept 2015.
106. Plantard, T., Susilo, W., Zhang, Z., Fully homomorphic encryption using hidden ideal lattice. IEEE Trans. Inf. Forensics Secur., 8, 12, 2127–2137, Dec 2013.
107. Kumarage, H., Khalil, I., Alabdulatif, A., Tari, Z., Yi, X., Secure data analytics for cloud-integrated internet of things applications. IEEE Cloud Comput., 3, 2, 46–56, Mar 2016.
108. Li, Y., Jiang, Z.L., Wang, X., Yiu, S.M., Privacy-preserving id3 data mining over encrypted data in outsourced environments with multiple keys, in: Proc. 2017 IEEE International Conference on Computational Science and Engineering (CSE) and the IEEE International Conference on Embedded and Ubiquitous Computing (EUC), vol. 1, pp. 548–555, July 2017.
109. Qiu, S., Wang, B., Li, M., Liu, J., Shi, Y., Toward practical privacy- preserving frequent itemset mining on encrypted cloud data. IEEE Trans. Cloud Comput., 8, 1127, 312–323, 2017.
110. Lu, R., Zhu, H., Liu, X., Liu, J.K., Shao, J., Toward efficient and privacy-preserving computing in the big data era. IEEE Network, 28, 4, 46–50, July 2014.
111. Chakravorty, A., Wlodarczyk, T., Rong, C., Privacy-preserving data analytics for smart homes, in: Proc. 2013 IEEE Security and Privacy Workshops, pp. 23–27, May 2013.
112. Truta, T.M. and Vinay, B., Privacy protection: p-sensitive k-anonymity property, in: Proc. 22nd International Conference on Data Engineering Workshops (ICDEW’06), pp. 94–94, 2006.
113. Gheit, Z. and Challah, Y., An efficient and privacy-preserving similarity evaluation for big data analytics, in: Proc. 2015 IEEE/ACM 8th International Conference on Utility and Cloud Computing (UCC), pp. 281–289, Dec 2015.
114. Lee, Y.T., Hsiao, W.H., Lin, Y.S., Chou, S.C.T., Privacy-preserving data analytics in the cloud-based smart home with community hierarchy. IEEE Trans. Consum. Electron., 63, 2, 200–207, May 2017.
115. Simmhan, Y., Aman, S., Kumbhare, A., Liu, R., Stevens, S., Zhou, Q., Prasanna, V., Cloud-based software platform for big data analytics in smart grids. Comput. Sci. Eng., 15, 4, 38–47, July 2013.
116. Mo, L., Li, F., Zhu, Y., Huang, A., Human physical activity recognition based on computer vision with a deep learning model, in: Proc. 2016 IEEE International Instrumentation and Measurement Technology Conference Proceedings, pp. 1–6, May 2016.
117. Zitouni, M.S., Dias, J., Al-Mualla, M., Bhaskar, H., Hierarchical crowd detection and representation for big data analytics in visual surveillance, in: Proc. 2015 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 1827–1832, Oct 2015.
118. Kumar Lenka, R., Kumar Rath, A., Tan, Z., Sharma, S., Puthal, D., Simha, N.V.R., Raja, R., Tripathi, S.S., Prasad, M., Building Scalable Cyber-Physical-Social Networking Infrastructure Using IoT and Low Power Sensors. IEEE Access, Special Section on Cyber-Physical-Social Computing and Networking, 6, 1, 30162–30173.
119. Ukil, A. and Zivanovic, R., Automated analysis of power systems disturbance records: Smart grid big data perspective, in: Proc. 2014 IEEE Innovative Smart Grid Technologies—Asia (ISGT ASIA), pp. 126–131, May 2014.
120. Yang, J., Zhao, J., Wen, F., Kong, W., Dong, Z., Mining the big data of residential appliances in the smart grid environment, in: Proc. 2016 IEEE Power and Energy Society General Meeting (PESGM), pp. 1–5, July 2016.
121. Liu, L. and Han, Z., Multi-block admm for big data optimization in smart grid, in: Proc. 2015 International Conference on Computing, Networking, and Communications (ICNC), pp. 556–561, Feb 2015.
122. Cui, S., Han, Z., Kar, S., Kim, T.T., Poor, H.V., Tajer, A., Coordinated data-injection attack and detection in the smart grid: A detailed look at enriching detection solutions. IEEE Signal Process. Mag., 29, 5, 106–115, Sept 2012.
123. Yassine, A., Shirehjini, A.A.N., Shirmohammadi, S., Smart meters big data: Game-theoretic model for fair data sharing in deregulated smart grids. IEEE Access, 3, 2743–2754, 2015.
124. He, X., Ai, Q., Qiu, R.C., Huang, W., Piao, L., Liu, H., A big data architecture design for smart grids based on random matrix theory. IEEE Trans. Smart Grid, 8, 2, 674–686, March 2017.
125. J. Wu, K. Ota, M. Dong, J. Li and H. Wang, Big Data Analysis-Based Security Situational Awareness for Smart Grid. IEEE Trans. Big Data, 4, 3, 408–417, 2018.
126. Wang, K., Wang, Y., Hu, X., Sun, Y., Deng, D.J., Vinel, A., Zhang, Y., Wireless big data computing in smart grid. IEEE Wireless Commun., 24, 2, 58–64, April 2017.
127. Hamedani, K., Liu, L., Rachad, A., Wu, J., Yi, Y., Reservoir computing meets smart grids: Attack detection using delayed feedback networks. IEEE Trans. Ind. Inf., 14, 2, 2743–2754, 2017.
128. Yavuz, A.A., An efficient real-time broadcast authentication scheme for command and control messages. IEEE Trans. Inf. Forensics Secur., 9, 10, 1733–1742, Oct 2014.
129. Raja, R., Sinha, T.S., Patra, R.K., Tiwari, S., Physiological Trait Based Biometrical Authentication of Human-Face Using LGXP and ANN Techniques. Int. J. Inf. Comput. Secur., 10, 2/3, 303–320, 2018.
130. Lehto, G.M., Edlund, G., Smigla, T., Afinidad, F., Protection evaluation framework for tactical Satcom architectures, in: Proc. MILCOM 2013—2013 IEEE Military Communications Conference, pp. 1008–1013, Nov 2013.
131. Moreno, M.V., Terroso-Saenz, F., Gonzalez-Vidal, A., Valdez-Vela, M., Skarmeta, F., Zamora, M.A., Chang, V., Applicability of big data techniques to smart cities deployments. IEEE Trans. Ind. Inf., 13, 2, 800–809, April 2017.
132. Sahu, A.K., Sharma, S., Tanveer, M., Internet of Things attack detection using hybrid Deep Learning Model. Comput. Commun., 176, 146–154, 2021, https://doi.org/10.1016/j.comcom.2021.05.024.
133. de Oliveira, B.T. and Margi, C.B., Distributed control plane architecture for software-defined wireless sensor networks, in: Proc. 2016 IEEE International Symposium on Consumer Electronics (ISCE), pp. 85–86, Sept 2016.
134. Rawat, N. and Raja, R., Moving Vehicle Detection and Tracking using Modified Mean Shift Method and Kalman Filter and Research. Int. J. New Technol. Res. (IJNTR), 2, 5, 96–100, 2016.
135. Raja, R., Kumar, S., Rashid, Md., Color Object Detection Based Image Retrieval using ROI Segmentation with Multi-Feature Method. Wirel. Pers. Commun. Springer J., 1, 1–24, 2020, https://doi.org/10.1007/s11277-019-07021-6.
136. Yuce, M.R., Implementation of wireless body area networks for healthcare systems. Sens. Actuators A: Phys., 162, 1, 116–129, 2010, [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0924424710002657.
137. Yan, H., Huo, H., Xu, Y., Gidlund, M., Wireless sensor network based e-health system—Implementation and experimental results. IEEE Trans. Consum. Electron., 56, 4, 2288–2295, November 2010.
138. Martinez, J.F., Familiar, M.S., Corredor, I., Garcia, A.B., Bravo, S., Lopez, L., Composition and deployment of e-health services over wireless sensor networks. Math. Comput. Modell., 53, 3–4, 485–503, 2011, Telecommunications Software Engineering: Emerging Methods, Models, and Tools. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0895717710001548.
139. Mahmood, Md. R., Raja, R., Gupta, A., Jain, S., Implementation of Multi- Sensor and Multi-Functional Mobile Robot for Image Mosaicking. SAMRIDDHI: A Journal of Physical Sciences, Engineering and Technology, 12, Special Issue (3), 189–196, 2020.
140. Dewangan, A.K., Raja, R., Singh, R., Multi-Sensor and Multifunctional Robot with Image Mosaic. Int. J. Sci. Eng. Technol. Res. (IJSETR)., 3, 4, 677–680, 2014.
141. Dewangan, A.K., Raja, R., Singh, R., An Implementation of Multi Sensor- Based Mobile Robot With Image Stitching Application. Int. J. Comput. Sci. Mob. Comput., 3, 6, 603–609, 2014.
142. Cui, D., Risk early warning index system in the field of public safety in the big data era, in: Proc. 2015 Sixth International Conference on Intelligent Systems Design and Engineering Applications (ISDEA), pp. 704–707, Aug 2015.
143. Tiwari, L., Raja, R., Awasthi, V., Miri, R., Sinha, G.R., Alkinani, M.H., Polat, K., Detection of lung nodule and cancer using novel Mask-3 FCM and TWEDLNN algorithms. Measurement, 172, 108882, https://doi.org/10.1016/j.measurement.2020.108882, 2021.
144. Zhong, L., Takano, K., Ji, Y., Yamada, S., Big data-based service area estimation for mobile communications during natural disasters, in: Proc. 2016 30th International Conference on Advanced Information Networking and Applications Workshops (WAINA), pp. 687–692, March 2016.
145. Tin, P., Zin, T.T., Toriu, T., Hama, H., An integrated framework for disaster event analysis in big data environments, in: Proc. 2013 Ninth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, pp. 255–258, Oct 2013.
146. Ma, Y., Wu, H., Wang, L., Huang, B., Ranjan, R., Zomaya, A., Jie, W., Remote sensing big data computing. Future Gener. Comput. Syst., 51, C, 47–60, Oct. 2015. [Online]. Available: http://dx.doi.org/10.1016/j.future.2014.10.029
- *Corresponding author: [email protected]