
Chapter 14. Systems That Never Stop
You need at least two computers to make a fault-tolerant system. Built-in Erlang distribution, no shared memory, and asynchronous message passing give you the foundations needed for replicating data across these computers, so if one computer crashes, the other can take over. The good news is that the error-handling techniques, fault isolation, and self-healing that apply to single-node systems also help immensely when multiple nodes are involved, allowing you to transparently distribute your processes across clusters and use the same failure detection techniques you use on a single node. This makes the creation of fault-tolerant systems much easier and more predictable than having to write your own libraries to handle semantic gaps, which is typically what’s required with other languages. The catch is that Erlang on its own will not give you a fault-tolerant system out of the box—but its programming model will, and at a fraction of the effort required by other current technologies.
In this chapter, we continue explaining approaches to distributed programming commonly used in Erlang systems. We focus on data replication and retry strategies across nodes and computers, and the compromises and tradeoffs needed to build systems that never stop. These approaches affect how you distribute your data, and how you retry requests if they have failed for reasons out of your control.
Availability
Availability defines the uptime of a system over a certain period of time. High availability refers to systems with very low downtime, software maintenance and upgrades included. While some claim having achieved nine-nines availability,1 these claims tend not to be long-lived. Nine nines of uptime means only 31.6 milliseconds of downtime per year! It will take you 10 times longer to blink, let alone figure out something has gone wrong. A realistic number often achieved with Erlang/OTP is 99.999% uptime, equating to just over 5 minutes of downtime each year, upgrades and maintenance included.
High availability is the result of your system having no single point of failure, and being fault-tolerant, resilient, and reliable. It can also be the result of having a system that even in the face of partial failure can still provide some degree of service, albeit reduced from normal levels. Let’s look in detail at what these terms entail for the system you are trying to build.
Fault Tolerance
Fault tolerance refers to the ability of a system to act predictably under failure. Such failure could be due to a software fault, where a process crashes because of a bug or corrupt state. Or it could be due to a network or hardware fault, or the result of a node crashing. Acting predictably can mean looking for alternative nodes and ensuring that requests are fulfilled, or just returning errors back to the callers.
In the example in Figure 14-1, a client sends a request to the front-end node running the web servers. The request is parsed and forwarded to the logic node (Figure 14-1, part 1). At this point, the logic node, or a process in the logic node, crashes (Figure 14-1, part 2). If we are lucky, the front-end node detects this crash and receives an error. If we’re unlucky, an internal timeout is triggered. When the error or timeout is received, an error is sent back to the client.
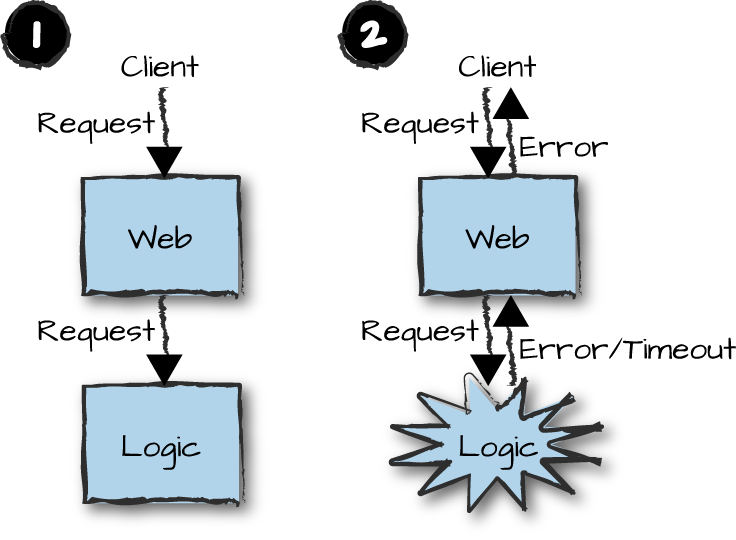
Figure 14-1. Fault tolerance
This system acts in a predictable way and is considered fault tolerant because a response has been sent back to the client. It allows the client to act in a predictable way, as long as the server, the type of request, and the protocol allow for it. The response might not be the one the client was hoping for, but it was a valid response. It is now up to the client to decide what to do next. It might retry sending the request, escalate the failure, or do nothing.
The hardest part in this use case is knowing whether the logic node actually failed, or if the failure is in the network between the nodes—or, even worse, if the logic node is just incredibly slow in responding, triggering a timeout in the front-end node while actually executing the request. There is no practical difference between a slow node and a dead node. Your front-end nodes need to be aware of all these conditions and handle the resulting uncertainty. This is done through unique identifiers, idempotence, and retry attempts, all of which we discuss later in this chapter. It might even require audit logs and human intervention. The last thing you want is for your purchase request to time out and for the client to keep on retrying until a request is actually acknowledged. You might wake to discover you purchased 50 copies of the same book.
Erlang has dedicated, asynchronous error channels that work across nodes. It does not matter if the node or process crashed, or if the crash was in a local or remote node. You can use the same proven error-handling techniques, such as monitors, links, and exit signals, within your node as well as within your distributed environment. The only difference will be latency if the exit signals are originating in remote nodes, something already taken care of through asynchronous message passing. Make sure that errors are propagated accordingly in your call chain, taking actions on every level that might address the issue. This includes the handling of false positives, as an action can be enacted, but crash or time out before its success is reported. Or it can time out due to network issues, but succeed asynchronously after the time out. This is one of the biggest challenges of asynchronous distributed systems.
Resilience
Resilience is the ability of a system to recover quickly from failure. In the example in Figure 14-2, the client sends a request to a web server node that crashes prior to handling the request (Figure 14-2, part 1). This might be caused by the client request, by a request from another client, or simply as the result of the Erlang runtime hitting a system limit such as running out of memory. The node could have failed even before the client sent its request. A heartbeat script detects the node failure and, depending on the number of restarts in the last hour, decides whether to restart the process or reboot the machine itself (as the error might be in one of the interfaces and could be eliminated through an OS restart). The client keeps on sending the same request, which repeatedly fails as the node is not available. But once the machine is rebooted or the node restarted, if it is safe to do so, the client request is accepted and successfully handled. The node failed, but quickly recovered on its own (Figure 14-2, part 2), minimizing downtime.
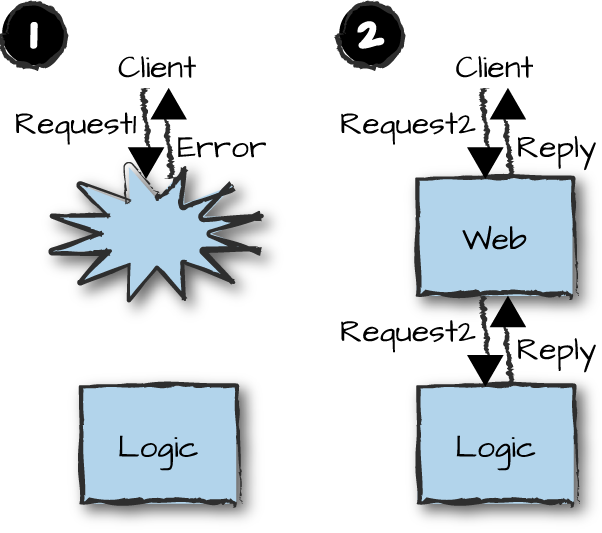
Figure 14-2. Resilience
As we’ve seen in many of the previous chapters in this book, the trick is to isolate failure, separating the business logic from the error handling. If a process crashes, its dependencies are terminated and quickly restarted. If a node goes down, a heartbeat script triggers an immediate restart. If a network or hardware outage occurs, the redundant network is used. By isolating functionality in manageable quantities in different node types, isolating failure becomes a straightforward and easy task. If you have a node that does too much, you increase the possible causes of a node crash through increased complexity, and you increase the recovery time.
Reliability
The reliability of a system is its ability to function under particular predefined conditions. In software and distributed systems, these conditions often include failure and inconsistency. In other words, the system has to continue functioning even when components that comprise it fail themselves or when data becomes inconsistent because it fails to replicate across nodes. When looking at reliability, you need to start thinking of the redundancy of these components. When we mention components, we do not mean only hardware and software. We also mean data and state, which need to be replicated and consistent across nodes.
A single point of failure means that if a particular component in your system fails, your whole system fails. That component could be a process, a node, a computer, or even the network tying it all together. This means that in order for your system to have no single point of failure, you need to have at least two of everything. At least two computers with software distributed and running a failover strategy across them. At least two copies of your data and state. Two routers, gateways, and interfaces, so that if the primary one fails, the secondary takes over. Alternative power supplies (or battery backups) for the same reason. And if you have the luxury, place the two computers in separate, geographically remote data centers. You should also keep in mind that having only two of everything might itself be a problem waiting to happen, since if one of something goes down, the remaining instance automatically becomes a single point of failure. For this reason, using three or more instances instead of just two is normally a given when high reliability is a critical requirement. All of this comes at a higher bandwidth and latency cost.
What does having two or three of everything mean for your software? Your request hits one of the load balancers, which forwards it to one of the front-end nodes. The node used is chosen by the load balancer using a variety of strategies—random, round robin, hashing, or sending the request to the front-end node with the least CPU load or the one with the smallest number of open TCP connections. We prefer hashing algorithms, as they are fast and give you predictability and consistency with low overheads. When troubleshooting what is going (or what went) wrong with a request, having a deterministic route across nodes makes debugging much easier, especially if you have hundreds of nodes and decentralized logs.
Let’s look at an example of how we avoid a single point of failure. The front-end node receives the request, parses it, and forwards it to a logic node (Figure 14-3, part 1). Soon after the request is forwarded, something goes wrong. The failure could have occurred anywhere, and we are unsure of the state of the request itself. We do not know whether the request ever reached the logic node, or whether the logic node started or even finished handling it. It could have been this very request that caused a process to crash, caused a synchronous call to time out, or caused the whole node to crash. Or perhaps the node might not have crashed at all; it might be extremely overloaded and slow in responding, or network connectivity might have failed. We should be able to distinguish between something crashing in the node itself and the node not responding. But beyond that, we just don’t know.
What we do know, though, is that we have a client waiting for a reply. So, upon detecting the error, the front-end node forwards the request to a secondary logic node. This node handles the request (Figure 14-3, part 2) and returns the reply to the front-end node, which formats it and sends it back to the client (Figure 14-3, part 3). All along, the client has no idea of the drama happening behind the scenes. The resilience in the node where the error occurs ensures that it comes up again, reconnects to the front-end nodes, and starts handling new requests. So, despite part of our system failing, it still provided 100% uptime to the client thanks to our “no single point of failure” strategy.
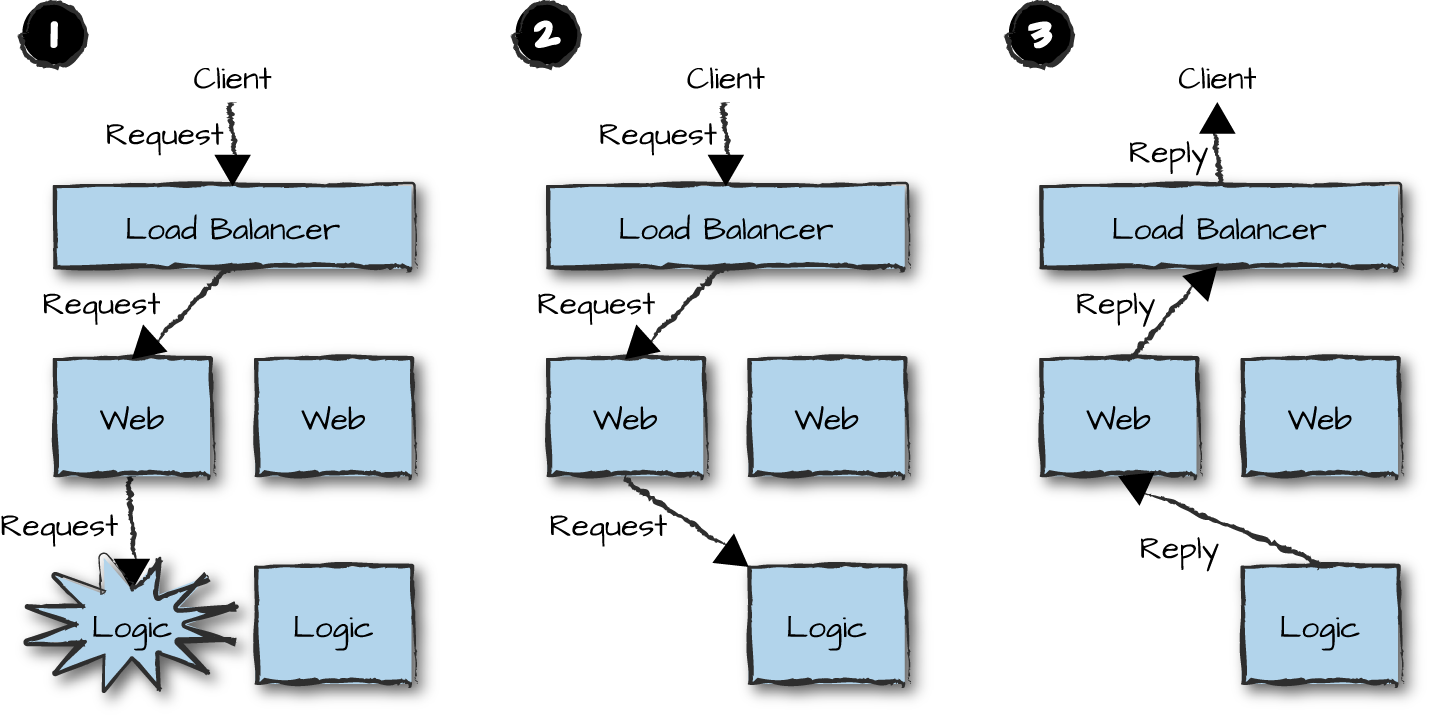
Figure 14-3. Single points of failure
At most once, exactly once, and at least once
When handling failure strategies, you need to start getting clever and make sure you have all edge cases covered. There are three approaches you can take for every request, because how you handle requests maps to message delivery semantics across nodes in distributed systems. In our example in Figure 14-3, the only guarantee you have is that your request has been executed at least once. If you are logging on to the system and the first logic node is so slow that the front-end node tries another one and succeeds with it, the worst-case scenario is that you log on twice and two sessions are created, one of which will eventually expire.
Similarly, if you are sending an SMS or an instant message, you might be happy with the at most once approach. If your system sends billions of messages a day, the loss of a few messages is acceptable relative to the load and the cost associated with guaranteed delivery. You send your request and forget about it. In our example with no single point of failure, when the front-end node sends the request to the logic node, it also immediately sends a reply back to the client.
But what if you were sending money or a premium rate SMS? Losing money, making the transfer more than once, or sending and charging for the same premium SMS multiple times because of an error will not make you popular. Under these circumstances, you need the exactly once approach. A request can succeed or fail. If failure is in your business logic, such as where a user is not allowed to receive premium rate SMSs, we actually consider the failed request to be successful, as it falls within the valid return values. Errors that should worry us are timeouts, software bugs, or corrupt state causing a process or node to terminate abnormally, leaving the system in a potentially unknown or undefined state. As long as you use the exactly once approach in a single node, abnormal process termination can be detected. As soon as you go distributed, however, the semantics of the request cannot be guaranteed.
The successful case is when you send a request and receive a response. But if you do not receive a response, is it because of the request never reaching the remote node, because of a bug in the remote node, or because the acknowledgment and reply of the successful execution got lost in transit? The system could be left in an inconsistent state and need cleaning up. In some systems, the cleanup is executed automatically by a script that tries to determine what went wrong and address the problem. In other cases, cleaning up might require human intervention because of the complexity of the code or seriousness of the failed transaction. If a request to send a premium rate SMS failed, a script could start by investigating if the mobile device received the remote SMS, if the user was charged for it, or if the request ever made it to the system. Having comprehensive logs, as we show in “Logs”, becomes critical.
A common pattern in achieving exactly once semantics with at most once calls is to use unique sequence numbers in the client requests. A client sends a request that gets processed correctly (Figure 14-4, part 1). If the response from the front-end node is lost or delayed, a timeout in the client is triggered. The client resends the request with the same identifier, and the logic node identifies it as a duplicate request and returns the original reply, possibly tagging it as a duplicate (Figure 14-4, part 2). You are still not guaranteed success, as the connectivity between the client and the server might not come up again. But it will work in the presence of transient errors.
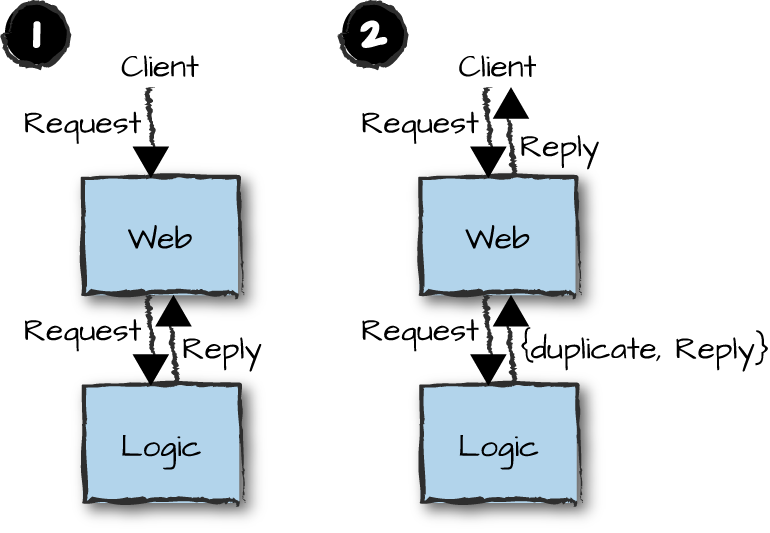
Figure 14-4. Duplicate requests
This approach relies on idempotence. The term describes an operation that the user can apply multiple times with the same effect as applying it once. For example, if a request changes a customer’s shipping address, whether the system performs the request successfully once or multiple times has the same result, assuming the shipping address is the same in each request. Such a request can actually be executed multiple times because the side effects of any second or subsequent executions essentially have no observable effect. With our request identification scheme, though, the second and subsequent executions never occur.
Imagine a billing system for premium rate SMSs. You need to guarantee that if you charge the user, you will do so exactly once, and only after the SMS is received. An approach typically taken to guarantee this result is reserving the funds in the recipient account before sending the SMS. When reserving them, the billing system returns a unique identifier. The SMS is sent, possibly multiple times. The charge is made only when the first report notifying that it has been delivered is received by the billing system. The unique identifier is then used to execute the payment and charge the account. Subsequent attempts to use the same identifier, possibly when receiving multiple copies of the same delivery report, do not result in additional charges. And if the SMS never reaches its recipient, the reserved funds are eventually released after timing out. The timeout also invalidates the identifier.
At most once, at least once, and exactly once approaches all have advantages and tradeoffs. While deciding what strategy to use, keep in mind that requests and the messaging infrastructure that underpins them are unreliable. This unreliability needs to be managed in the business logic and semantics of every request. The easiest to implement and least memory- and CPU-intensive approach is the “at most once” approach, where you send off your request and forget about it. If something fails, you have lost the request, but without affecting the performance of all of the other requests that succeeded. The “at least once” approach is more expensive, because you need to store the state of the request, monitor it, and upon receiving timeouts or errors, forward it to a different node. Along with higher memory and CPU usage, it can generate additional network traffic. Theoreticians will argue that the at least once approach cannot be guaranteed to be successful, as all nodes receiving the request can be down. We’ll leave them scratching their heads and figuring out what double and triple redundancy are all about. The hardest strategy is the “exactly once” approach, because you need to provide guarantees when executing what is in effect a transaction. The request can succeed or fail, but nothing in between.
These guarantees are impossible with distributed systems, since failure can also mean a request being successfully executed but its acknowledgment and reply being lost. You need algorithms that try to retrace the call through the logs and understand where a failure occurred to try to correct it or compensate for it. In some systems, this is so complex or the stakes are so high that human intervention is required.
Until now, we’ve said, “Let it crash.” Yes, let it crash, and no matter which of the three strategies you pick, put your effort into the recovery, ensuring that after failure, your system returns to a consistent state. The beauty of error handling and recovery in Erlang is that your recovery strategy will be the same when dealing with all of your errors, software, hardware, and network faults included. If you do it right, there will be no need to duplicate code in a process recreating its state after a crash or recovering after a network partition or packet loss.
Sharing Data
When you are thinking about your strategies for avoiding a single point of failure and for recovery, you have to make a new set of decisions about whether and how you are going to replicate data across your nodes, node families, and clusters. Your decisions will affect your system’s availability (which includes fault tolerance, resilience, and reliability) and, ultimately, also scalability. Luckily, you can defer some of these decisions to when you stress test and benchmark your system. You might want to make other decisions up front based on the requirements you already know and on past experiences in designing similar systems. But whatever your decision is, one of the hardest things when dealing with distributed systems is accessing and moving your data; it can be the cause of your worst bottlenecks. For every table and state, you have three approaches you can choose from: share nothing, share something, and share everything. Choose your data replication strategy wisely, and pick the one that most closely matches the level of scale or availability for which you are aiming.
Share nothing
The share-nothing architecture is where no data or state is shared. This could be specific to a node, a node family, or a cluster. Once you have addressed the underlying infrastructure, such as hardware, networks, and load balancing, share-nothing architectures can result in linearly scalable systems. Because each collection of nodes has an independent copy of its own data and state, it can operate on its own. When you need to scale, all you need to do is add more infrastructure and reconfigure your load balancers.
Figure 14-5, part 1 shows two front-end and two logic nodes. Using a login request, Client1 and Client2 send their credentials to initiate a session. This request is forwarded to one of the two front-end nodes using the load-balancing strategy configured in the load balancer. In our example, each node gets a request that it forwards to its primary logic node. These nodes each check the client credentials and create a session, storing the session state in a database.
Client1 now sends a new request right after the node storing its session data has crashed, losing everything (Figure 14-5, part 2). The front-end node forwards it to its standby logic node, which rejects the request because it is unaware of the session. The client, upon receiving an unknown session error, sends a new login request that is forwarded and handled by the second logic node. All future requests from this client should now be forwarded to the logic node containing the session. If they aren’t and the node that crashed comes up again, the client will have to log on again (Figure 14-5, part 3), and we just assume that the session in the standby node will eventually time out and be deleted.
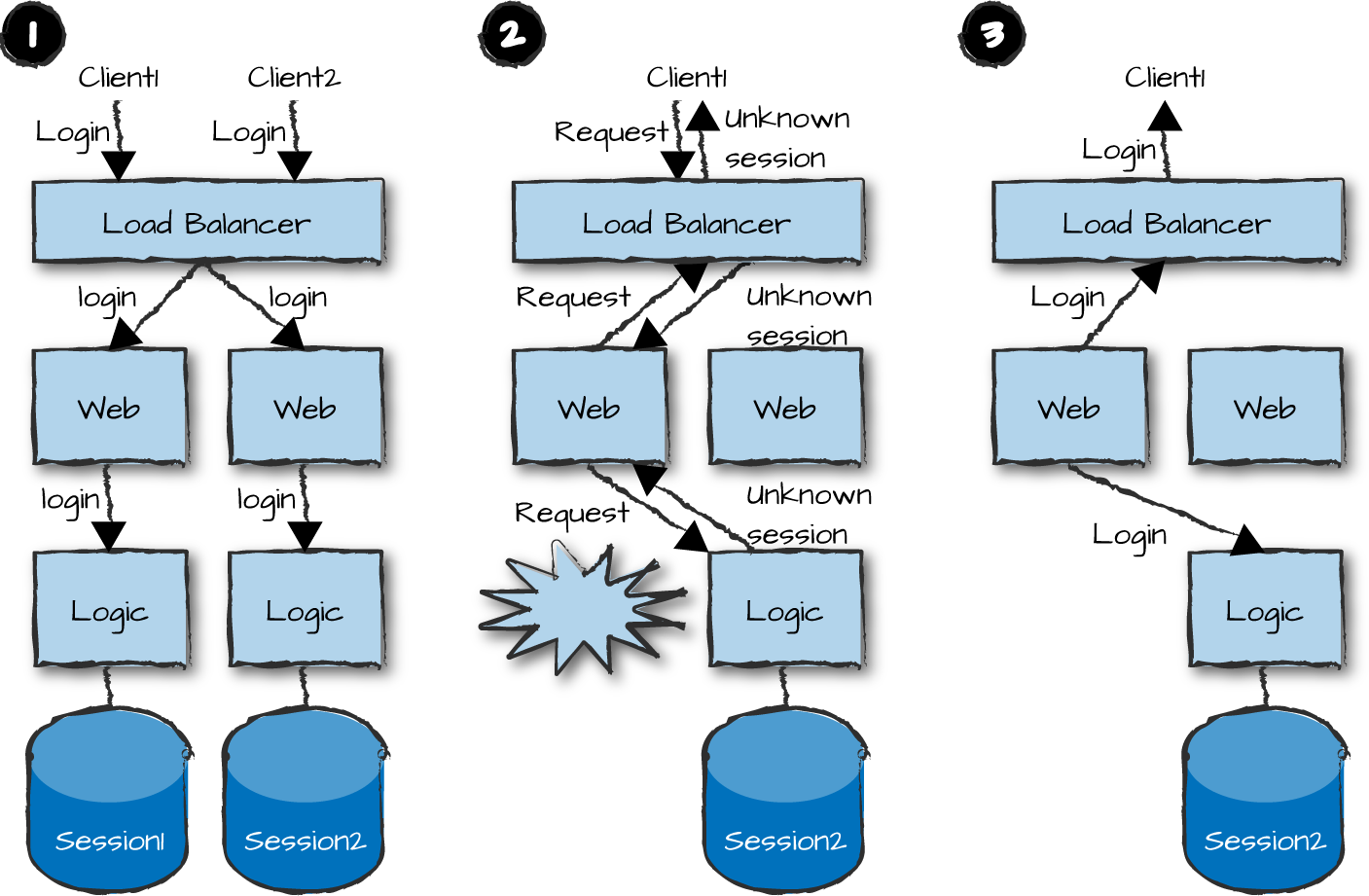
Figure 14-5. Share-nothing architecture
As we don’t have to copy our session state across nodes, we get better scalability, because we can continue adding front-end and logic nodes as the number of simultaneously connected users increases. The downside of this strategy is that if you lose a node, you lose the state and all of the data associated with it. In our example, all sessions are lost, forcing users to log on again and establish a new session in another node. You also need to choose how to route your requests across nodes, ensuring that each request is routed to the logic node that stores its matching session data. This guarantees continuity after a node failure and recovery.
Share something
What do we do if we want to ensure that users are still logged on and have a valid session after a node failure? The share-something architecture, where you duplicate some but not all of your data, might address some of your concerns. In Figure 14-6, we copy the session state across all logic nodes. If a node terminates, is slow, or can’t be reached, requests are forwarded to logic nodes that have copies of the session data. This approach ensures that the client does not have to go though a login procedure when switching logic nodes. But it trades off some scalability, because the session data needs to be copied across multiple nodes every time a client logs in and deleted when the session is terminated. Things get even more expensive whenever a node is added to the cluster or restarts, because sessions from the other nodes might have to be copied to it and kept consistent.
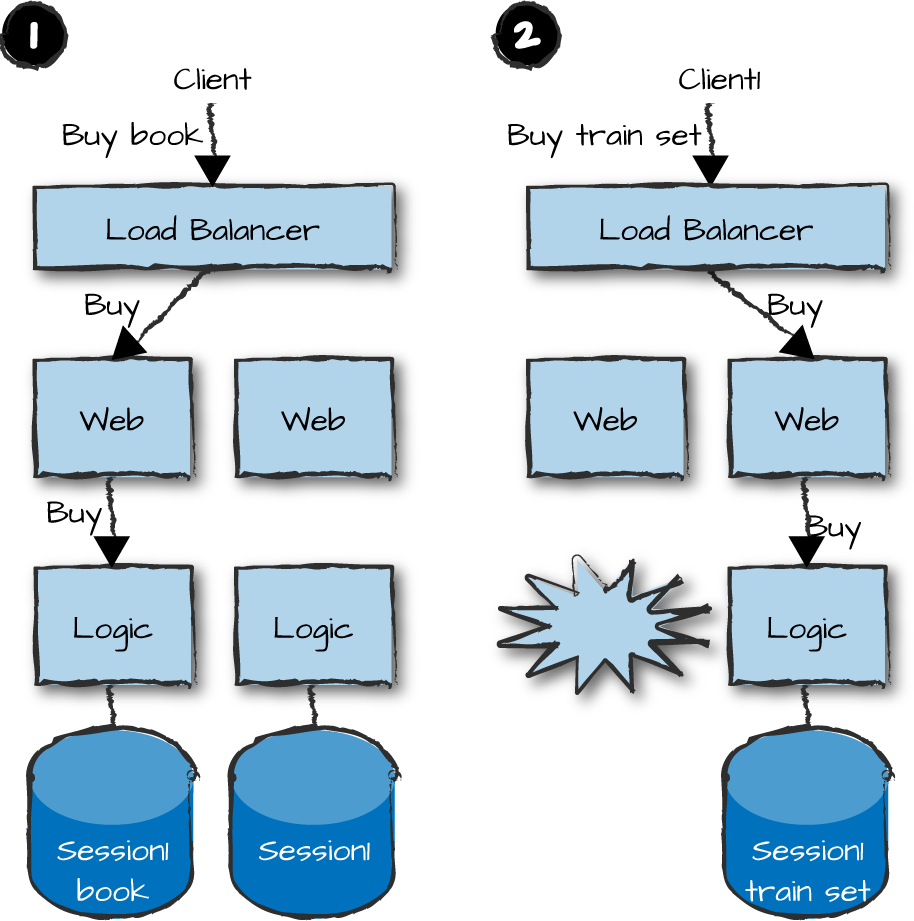
Figure 14-6. Share-something architecture
The strategy just described is called share something because it is a compromise: you copy some, but not all of the data and state associated with each session. The strategy reduces the overhead of copying while increasing the level of fault tolerance. Let’s return to our e-commerce site. The session data is copied, so if a node is lost, the user does not have to log on again. However, the contents of the shopping cart are not copied, so upon losing a node, the users unexpectedly have their carts emptied. When a user is checking out and paying for the selected items, only those items in the active logic node’s shopping cart will appear.
We have been assuming all along that if the logic node crashed, all of its data would be lost. What if the shopping cart were stored in a persistent key-value store which, upon restart, was reread? Or what if a network partition occurred, or the node was just slow in responding and, as such, presumed dead? When the node becomes available, you need to decide on your routing strategy—namely, which of the two logic nodes receives new requests. And because you have two shopping carts, they now need to be merged (Figure 14-7, part 1), or one of them has to be discarded.
How is this done? Do you join all of the items? What if we had added an item to the shopping cart in the second node? Will we end up with one or two copies of the item? Or what if we had sent a delete operation to the second node, but the operation failed because the item was not there? How you solve these problems depends on your business and your risks. Some distributed databases, such as Riak and Cassandra, provide you with options. In our example, the node that crashed becomes the primary again, and we move the contents of the second shopping cart to it (Figure 14-7, part 2).
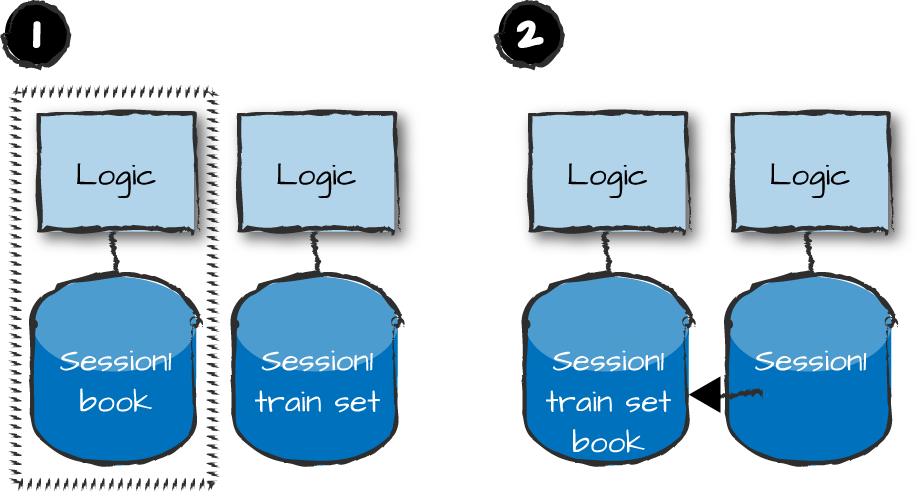
Figure 14-7. Network partitions with the share-something architecture
The Dynamo paper discussed in “Riak Core” describes the Amazon way of merging its shopping cart when recovering from failures. If, during the merge, there is uncertainty over the deletion of an item, it gets included, leaving the responsibility to the shopper to either remove it when reviewing the final order or return it for a refund if it actually gets shipped. How many times, upon checkout, have you found an item in your Amazon shopping cart you were sure you had deleted? It has happened to us a few times.
The share-something architecture is ideal for use cases where you are allowed to lose an occasional odd request but need to retain state for more expensive operations. We used a shopping cart example. Think of an instant messaging server instead. The most expensive operation, and biggest bottleneck, is users logging in and starting a session. The session needs to access an authentication server, retrieve the user’s contact list, and send everyone a status update. Imagine a server handling a million users. The last thing you want as the result of a network partition or a node crash is for a million users to be logging back on, especially when the system is still recovering from having sent 30 million offline status updates (assuming 60 contacts per user, of whom half are online).
One good solution is to distribute the session record across multiple nodes. What you do not share, however, are the status notifications and messages. You let them go through a single node with the “at most once” approach for sending messages in order to preserve speed. You assume that if the node crashes or is separated from the rest of the cluster through a network error, you either delay the delivery of the notifications and messages or lose some or all of them. How many times have you sent an SMS to someone close to you, only for them to receive it hours (or days) later, or never at all?
Share everything
Share-nothing and share-something architectures might work for some systems and data sets, but what if you want to make your system as fault tolerant and resilient as possible? While it is not possible to have a distributed system where losing requests is not an option, you might be dealing with money, shares, or other operations where inconsistency or the risk of losing a request is unacceptable. Each transaction must execute exactly once, its data has to be strongly consistent, and operations on it must either succeed or fail in their entirety. Although you can get away with not receiving an SMS or instant message, finding an equity trade you thought had been executed missing in your portfolio or money missing from your bank account is indefensible. This is where the share-everything architecture comes into the picture. All your data is shared across all of the nodes, any of which might, upon hardware or software failure, take over the requests. If there is any uncertainty over the outcome of a request, an error is returned to the user. When things go wrong, they have to be reconciled after the fact. For example, if you try to withdraw from multiple ATMs more funds than you have in your account, you get the money, but then later the bank penalizes you for overdrawing your account. But with no single point of failure, using redundant hardware and software, the risk for this error should be reduced to a minimum.
In Figure 14-8, we duplicate the sessions and shopping cart contents in two logic nodes, each handling a subset of clients and duplicating the session state and shopping cart to the other nodes. If a node terminates, the other one takes over. Should the node recover, it will not accept any requests until all of the data from the active node has been copied over and is consistent with other nodes.
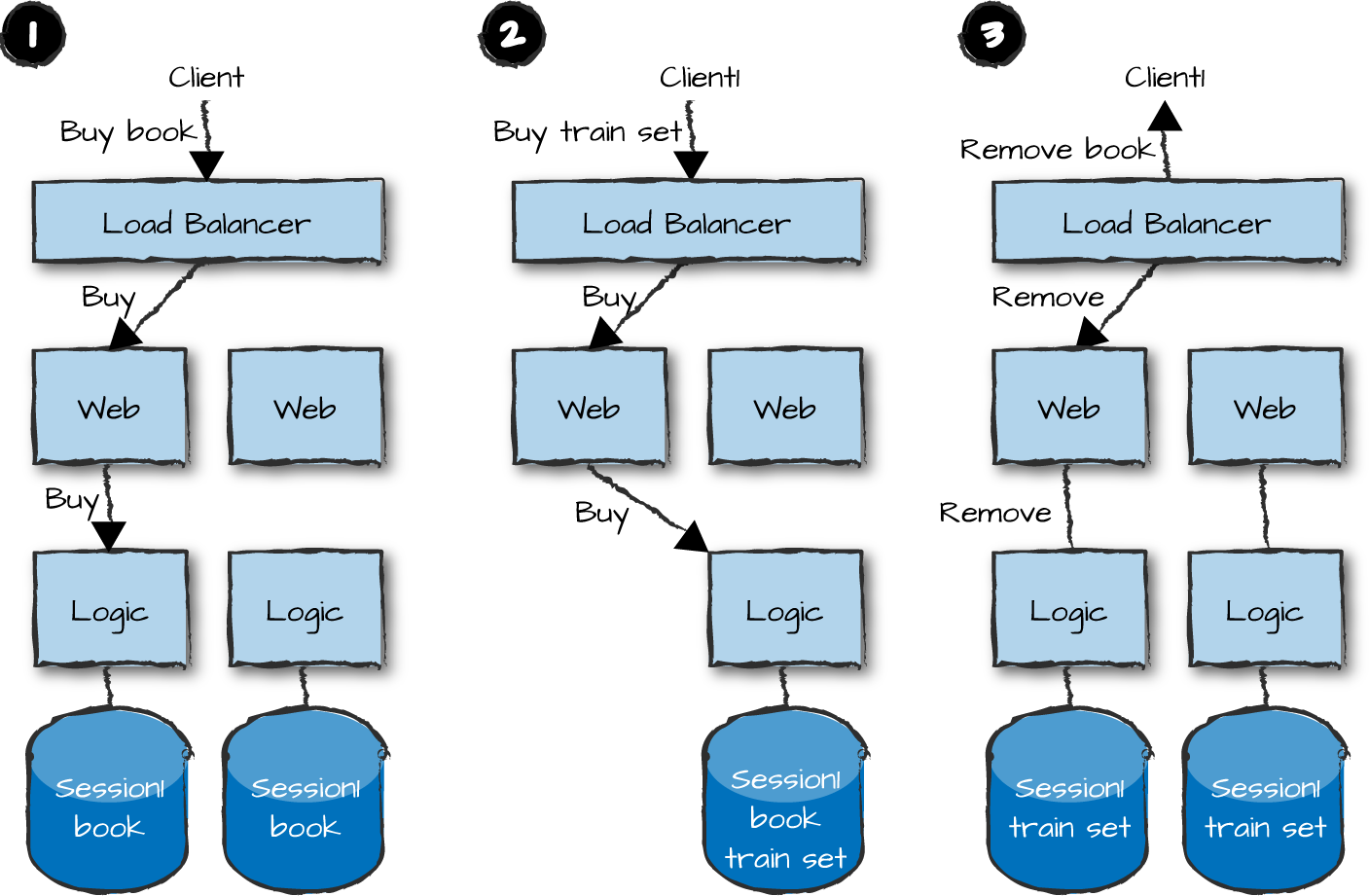
Figure 14-8. Share-everything architecture
We call this primary-primary replication. This contrasts with primary-secondary replication, where a single primary node is responsible for the data. The secondary nodes can access the data, but must coordinate any destructive operations such as inserts or deletes with the primary if they wish to modify the data. If the primary is lost, either the system stops working entirely, or it provides a degraded service level where writes and updates are not allowed, or one of the secondaries takes over as primary.
The share-everything architecture is the most reliable of all data-sharing strategies, but this reliability comes at the cost of scalability. It tolerates the loss of nodes without impacting consistency of data, but if some nodes go wrong, it also loses availability. This strategy is also the most expensive to run and maintain, because every operation results in computational overhead and multiple requests across the network to ensure that the data is kept replicated and consistent. Upon restarting, nodes must connect to a primary and retrieve a copy the data to bring them back in sync with the primary node, ensuring they have a correct and current view of the state and the data.
Although share-everything architectures do not necessarily require distributed transactions across nodes, you will need them when dealing with data such as money or shares you cannot afford to lose. This contrasts with the requirements we saw for messaging, where duplicating the messages through eventual consistency will greatly reduce the risk of them getting lost if you lose a node, but with no strong guarantee that you will never lose a message.
When you have decided on your data-sharing strategy, you need to go through each request in your API, trace the call, and try to map everything that can go wrong. Within the node itself, for synchronous calls, you need to consider behavior timeouts and abnormal process termination. If dealing with asynchronous messaging, ensure that message loss (when the receiving process has terminated) is handled correctly. Across nodes, you need to consider network errors, partitions, slow nodes, and node termination. When you’re done, pick the recovery strategy that best suits the particular calls. This needs to be done for every external call, and will often result in a mixture of the three recovery strategies, depending on the importance of the state change.
Tradeoffs Between Consistency and Availability
We were refactoring a system where the customer claimed they had never had an outage, servicing all requests with 100% availability, software upgrades included, for years on end. They were not using Erlang, and to add icing on the cake, were running everything on mainframes! When we began to scratch under the surface, we found out that their definition of availability meant that the front-end nodes were always up, accepting and acknowledging requests. In the case of errors and outages in their logic and service nodes, however, requests were logged and processed manually! We could argue that this system was indeed highly available, but unreliable, as it did not always function as defined. Getting it into a consistent state after failure required manual intervention. The choices you make in your recovery strategy are all about tradeoffs between consistency and availability, while your data-sharing strategy is about tradeoffs between latency and consistency.
On one side, you have the exactly once approach, ensuring that an operation executes to completion or fails. However, this is also the least available solution (Figure 14-9, part 1), as strong consistency requirements mean choosing consistency over availability. If things go wrong, the system might under certain circumstances become unavailable in order to ensure consistency. On the other end of the spectrum is weak consistency with high availability. By accepting the loss of occasional requests, you accept an inconsistent view of the state or data, handling this inconsistency in the semantics of your system. As a result, you can continue servicing your requests even under network partitions. The compromise is the at least once approach, which guarantees that a request has successfully executed on at least one node. It is then up to the semantics of the system, where necessary, to handle the propagation and merging of this state change to other nodes.
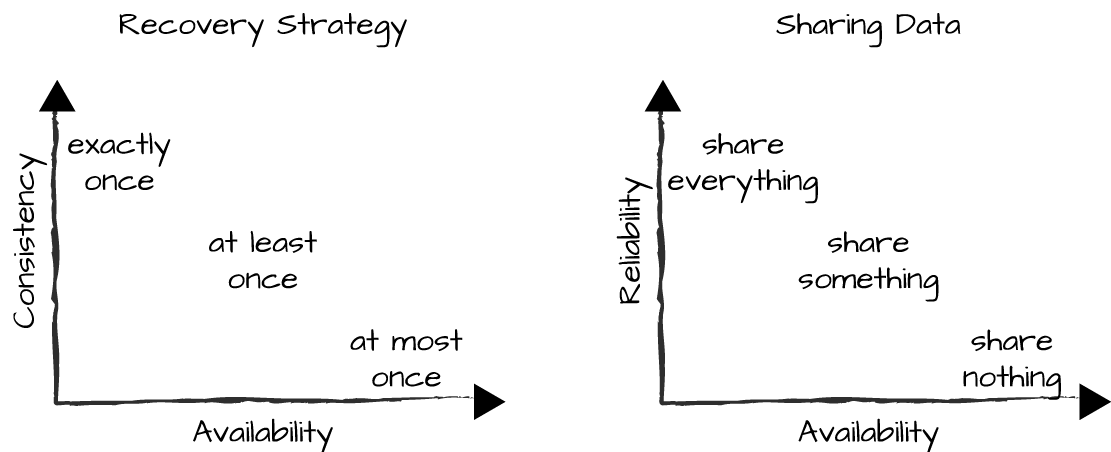
Figure 14-9. Tradeoffs between consistency, reliability, and availability
A similar argument can be made on the sharing of data approach (Figure 14-9, part 2), where the tradeoffs are between availability and reliability. Using the share-everything approach across nodes, you make your system more reliable, as any node with a copy of the data and state can take over the request correctly. While it is not always possible to guarantee that data is replicated, it is a safer approach than the share-something or share-nothing architectures, where some or all of the data and state are lost in the event of failure.
Nirvana would be reaching the top right of both graphs: a system that is consistent, reliable, and available. If you lose a node, the state is guaranteed to be replicated on at least one other node, and guaranteeing that your requests are either executed exactly once or fail and return an error message to the client will leave your system in a consistent state. Alas, having it all is not possible. If it were, everyone would just choose to do it this way, and distributed systems wouldn’t be difficult at all!
Summing Up
In this chapter, we introduced the concept of availability, defined as the uptime of a system, errors and maintenance included. Availability is a term that encompasses the following additional concepts:
Fault tolerance, allowing your system to act in a predictable way during failure. Failure could be loss of processes, nodes, network connectivity, or hardware.
Resilience, allowing your system to quickly recover from failure. This could mean a node restarting after a crash or a redundant network kicking in after the primary one fails.
Reliability, where under particular, predefined conditions, errors included, your system continues to function. If a node is unresponsive because it has terminated, is slow, or got separated from the rest of the system in a network partition, your business logic should be capable of redirecting the request to a responsive node.
Your levels of fault tolerance, resilience, and reliability, and ultimately availability, are the result of correctly applying the Erlang/OTP programming model and choices you make in your data-sharing and recovery strategies. This brings us to the next steps in determining our distributed architecture. The steps we covered in Chapter 13 included:
Split up your system’s functionality into manageable, standalone nodes.
Choose a distributed architectural pattern.
Choose the network protocols your nodes, node families, and clusters will use when communicating with each other.
Define your node interfaces, state, and data model.
You now need to pick your retry and data-sharing strategies:
For every interface function in your nodes, you need to pick a retry strategy.
Different functions will require different retry strategies. When deciding if you want to use the at most once, at least once, or exactly once approach, you need to examine all possible failure scenarios in the call chain, software, hardware, and network included. Take particular care of your failure scenarios for the exactly once strategy.
For all your data and state, pick your sharing strategy across node families, clusters, and types, taking into consideration the needs of your retry strategy.
In a data-sharing strategy, for both state and data, you need to decide if you want to share nothing, share something, or share everything across node families, clusters, and systems. You could also use consistent hashing to have multiple copies of the data, but not necessarily on all nodes.
In deciding on your sharing and retry strategies, you might need to review and change the design choices you made in steps 1–4. You mix and choose a variety of sharing and recovery alternatives specific to particular data, state, and requests. Not all requests have to be executed exactly once, and not all the data needs to be shared across all nodes. Guaranteed-delivery share-everything approaches are expensive, so use them only for the subset of data and requests that require them. And remember, things will fail. Try to isolate state, and share as little of it as possible among processes, nodes, and node families. Embrace failure and embed it in your architecture. Although it would be great to achieve the impossible and have systems that share everything and are strongly consistent, reliable, and available, in practice you have to choose your tradeoffs wisely based on system requirements, guarantees you want to provide to your customers, and the cost of operations.
What’s Next?
Having covered distributed architectures and how we use replication of data and retry strategies to increase availability, the time has come to look at scalability. In the next chapter, we cover a new set of tradeoffs required for scale. We look at load-testing techniques, load regulation, and the detection of bottlenecks in your system.
1 British Telecom issued a press release claiming nine-nines availability during a six-month trial of an AXD301 ATM switch network that carried all of its long-distance-traffic calls.