
Chapter 3. Behaviors
As a prelude to learning how to structure our process supervision trees and architect our concurrency models, let’s spend some time understanding the underlying principles behind behaviors. Instead of diving straight into the world of interface functions and callbacks, we explain what goes on behind the scenes, ensuring you use OTP behaviors efficiently and understand their benefits and advantages. So, what are they?
Erlang processes that solve radically different tasks follow similar design patterns. The most commonly used patterns have been abstracted and implemented in a set of generic library modules called the OTP behaviors. When reading about behaviors, you should see them as a formalization of process design patterns.
Although the strict concept of design patterns used in object-oriented programming hasn’t been applied to Erlang, OTP provides a powerful, reusable solution for concurrent processes that hides and abstracts away all of the tricky aspects and borderline conditions. It ensures that projects do not have to reinvent the wheel, while maximizing reusability and maintainability through a solid, well-tested, generic, and reusable code base. These behaviors are, in “design pattern speak,” implementation libraries of the concurrency models.
Process Skeletons
If you try to picture an Erlang process managing a key-value store and a process responsible for managing the window of a complex GUI system, they might at first glance appear very different in functionality and to have very little in common. That is often not the case, though, as both processes will share a common lifecycle. Both will:
Be spawned and initialized
Repeatedly receive messages, handle them, and send replies
Be terminated (normally or abnormally)
Processes, irrespective of their purpose, have to be spawned. Once spawned, they will initialize their state. The state will be specific to what that particular process does. In the case of a window manager, it might draw the window and display its contents. In the case of a key-value store, it might create the empty table and fill it with data stored in backup files or populate it using other tables spread across a distributed cluster of nodes.
Once the process has been initialized, it is ready to receive events. These events could, in the case of the window manager, be keystrokes in the window entry boxes, button clicks, or menu item selections. They could also be dragging and dropping of widgets, effectively moving the window or objects within it. Events would be programmed as Erlang messages. Upon receiving a particular message, the process would handle the request accordingly, evaluating the content and updating its internal state. Keystrokes would be displayed and clicking buttons or choosing menu items would result in window updates, while dragging and dropping would result in objects being moved across the screen. A similar analogy could be given for the key-value store. Asynchronous messages could be sent to insert and delete elements in the tables, and synchronous messages—messages that wait for a reply from the receiver—could be used to look up elements and return their values to the client.
Finally, processes will terminate. A user might have picked the Close entry in the menus or clicked on the
Destroy button. If that happens in the window manager,
resources allocated to that window have to be released and the window
hidden or shut down. Once the cleanup procedure is completed, there will
be no more code for the process to execute, so it should terminate
normally. In the case of the key-value store, a stop message
might have been sent to the process, resulting in the table being backed
up on another node or saved on a persistent medium.
Abnormal termination of the process might also occur, as a result of a trapped
exception or an exit signal from one of the processes in the link set.
Where possible, if caught through a trap_exit flag or a try-catch expression, the exception should
prompt the process to call the same set of commands that would have been
called as a result of a normal termination. We say “where possible,” as
the power cord of the computer might have been pulled out, the hard drive
might have failed, the administrator might have tripped over the network
cable, or the process might have been terminated unconditionally through
an exit signal with the reason kill.
Figure 3-1 shows a typical process flow diagram outlining the lifecycle of a process.
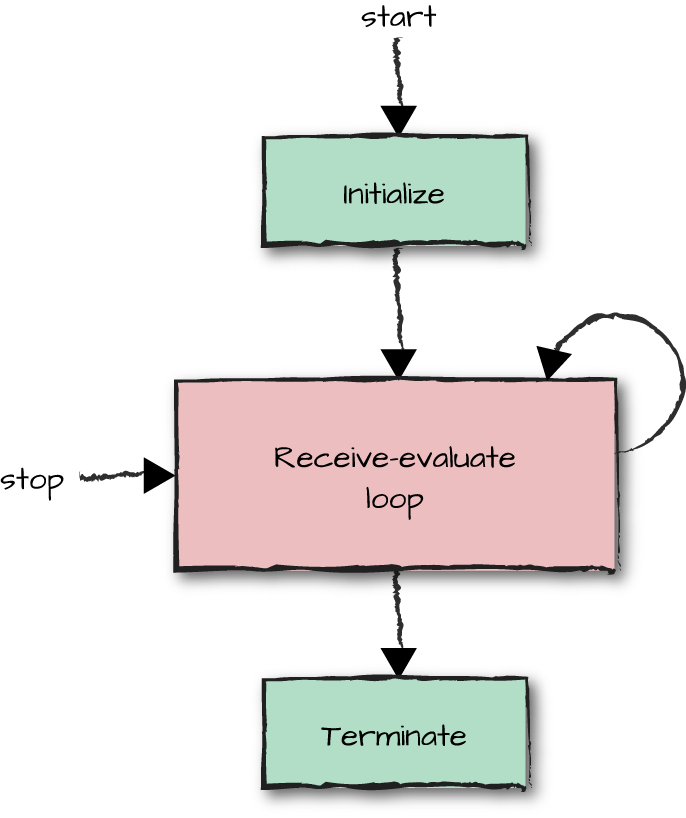
Figure 3-1. The process skeleton
As we’ve described, even if processes perform different tasks, they will perform these tasks in a similar way, following particular patterns. As a result of following these patterns, processes share a similar code base. A typical Erlang process loop, which has to be started, must handle events, and is finally terminated, might look like this:
start(Args)->% Start the server.spawn(server,init,[Args]).init(Args)->% Initialize the internal process state.State=initialize_state(Args),loop(State).loop(State)->% Receive and handle messages.receive{handle,Msg}->NewState=handle(Msg,State),loop(NewState);stop->terminate(State)% Stop the process.end.terminate(State)->% Clean up prior to termination.clean_up(State).
This pattern is typical of a client-server behavior. The server is
started, then it receives requests in the handle/2 function, where
necessary sends replies, changes the state, and loops ready to handle the
next incoming message. Upon receiving a stop message, the
process terminates after having cleaned up its resources.
Although we say that this is typical Erlang client-server behavior,
it is in fact the pattern behind all patterns. It is so common that even
code written without the OTP behavior libraries tends to use the same
function names. This allows anyone reading the code to know that the
process state is initialized in init/1, that messages are received in loop/1 and individually handled in the
handle/2 call, and finally, that any cleaning up of resources
is managed in the terminate/1 function. Someone trying to
maintain the code later will understand the basic behavior without
needing any knowledge of the communication protocol, underlying
architecture, or process structure.
Design Patterns
Let’s start drilling down into a more detailed example, focusing on client-server architectures implemented in Erlang. Clients and servers are represented as Erlang processes, with their requests and replies sent as messages. Have a look at Figure 3-2 and think of examples of client-server architectures that you have worked with or read about, preferably architectures with few similarities among them (as in our examples of a key-value store and a window manager). Focusing on Erlang constructs and patterns in the code of these applications, try to list the similarities and differences between the implementations. Ask yourself which parts of the code are generic and which parts are specific. What code is unique to that particular solution, and what code could be reused in other client-server applications?
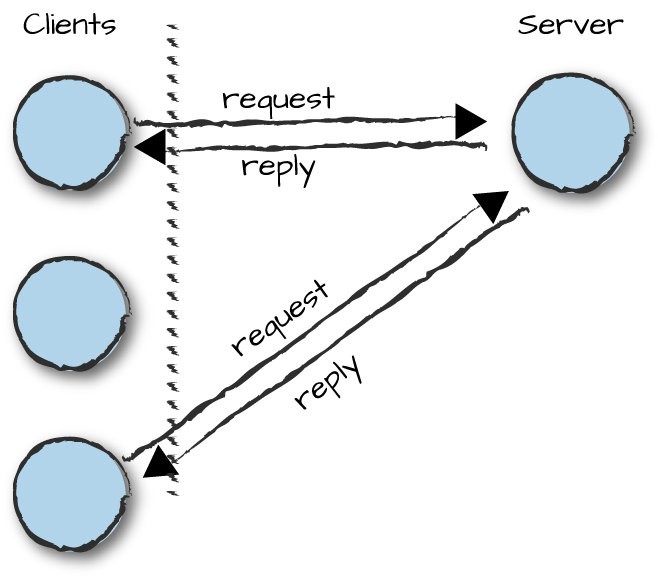
Figure 3-2. The client-server process architecture
Let’s give you a hint in the right direction: sending a client request to a server will be generic. It can be done in a uniform manner across any client-server architecture, irrespective of what the server does. What will be specific, however, are the contents of that message.
We start off by spawning a server. Creating a process that calls the
init/1 function is generic. What is specific are the
arguments passed to the call and the expressions in the function that
initialize the process state returning the loop data. The loop data plays
the role of a variable that stores process data between calls.
Storing the loop data in between calls will be the same from one process to another, but the loop data itself will be specific. It changes not only according to the particular task the process might execute, but for each particular instance of the task.
Sending a request to the server will be generic, as is the client-server protocol used to manage replies. What is specific are the types and contents of the requests sent to the server, how they are handled, and the responses sent back to the client. While the response is specific, sending it back to the client process is handled generically.
It should be possible to stop servers. While sending a
stop message or handling an exception or EXIT
signal is generic, the functions called to clean up the state prior to
termination will be specific.
Table 3-1 summarizes which parts of a client-server architecture are generic and which parts are specific.
| Generic | Specific |
|---|---|
|
|
Callback Modules
The idea behind OTP behaviors is to split up the code into two modules: one for the generic pattern, referred to as the behavior module, and one for specifics, referred to as the callback module (Figure 3-3). The generic behavior module can be seen as the driver. While it doesn’t know anything about what the callback module does, it is aware of a set of exported callback functions it has to invoke and the format of their return values. The callback module isn’t aware of what the generic module does either; it only complies with the format of the data it has to return when its callback functions are invoked.
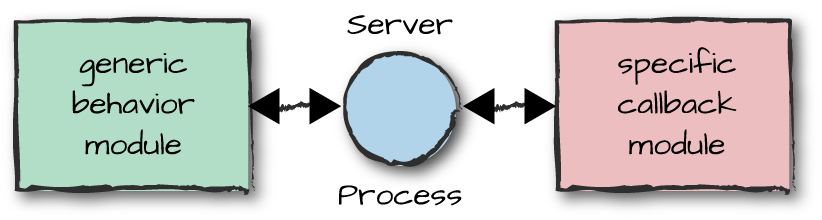
Figure 3-3. The callback module
Another way of explaining this is as a contract between the behavior and callback modules. They have to agree on a set of names and types for the functions in the callback API and respect the return values.
The behavior module contains all of the generic functionality reused from one implementation to another. Behaviors are provided by OTP as library modules. The callback module is implemented by the application developer. It contains all of the specific code for the implementation of that particular process.
OTP provides five behaviors that cover the majority of all cases. They are:
- Generic server
Used to model client-server behaviors
- Generic finite state machine
Used for FSM programming
- Generic event handler/manager
Used for writing event handlers
- Supervisor
Used for fault-tolerant supervision trees
- Application
Used to encapsulate resources and functionality
Generic servers are the most commonly used behavior. They are used to model processes using the client-server architecture, including the examples of the key-value store and the window manager we’ve already discussed.
Generic FSM behaviors provide all of the generic constructs needed when working with FSMs. Developers commonly use FSMs to implement automated control systems, protocol stacks, and decision-making systems. The code for the FSMs can be implemented manually or generated by another program.
Generic event handlers and managers are used for event-driven programming, where events are received as messages and one or more actions (called handlers) are applied to them. Typical examples of handler functionality include logging, metrics gathering, and alarming.
You can view handlers as a publish-subscribe communication layer, where publishers are processes sending events of a specific type and subscribers are consumers who do something with the events.
A supervisor is a behavior whose only tasks are to start, stop, and monitor its children, which can be workers as well as other supervisors. Allowing supervisors to monitor other supervisors results in process structures we call supervision trees. We cover supervision trees in the upcoming chapters. Supervisors restart children based on configuration parameters defined in the callback functions.
Supervision trees are packaged in a behavior we call an application. The application starts the top-level supervisor, encapsulating processes that depend on each other into the main building blocks of an Erlang node.
Generic servers, FSMs, and event handlers are examples of workers: processes that perform the bulk of the computations. They are held together by supervisors and application behaviors. If you need other behaviors not included as part of the standard library, you can implement them following a set of specific rules and directives explained in Chapter 10. We call them special processes.
Now you might be wondering: what is the point of adding a layer of complexity to our software? The reasons are many. Using behaviors, we are reducing the code base while creating a standardized programming style needed when developing software in the large. By encapsulating all of the generic design patterns in library modules, we reuse code while reducing the development effort. The behavior libraries we use consist of a solid, well-tested base that has been used in production systems since the mid-90s. They cover all the tricky aspects of concurrency, hiding them from the programmer. As a result, the final system will have fewer bugs1 while being built on a fault-tolerant base. The behaviors have built-in functionality such as logs, tracing, and statistics, and are extensible in a generic way across all processes using that behavior.
Another important advantage of using behaviors is that they
promote a common programming style. Anyone reading the code in a
callback module will immediately know that the process state is
initialized in the init function, and that
terminate contains the cleanup code executed whenever the
process is stopped. They will know how the communication protocol will
work, how processes are restarted in case of failure, and how
supervision trees are packaged. Especially when programming in the
large, this approach allows anyone reading the code to focus on the
project specifics while using their existing knowledge of the generics.
This common programming style also brings a component-based terminology
to the table, giving potentially distributed teams a way to package
their deliverables and use a standard vocabulary to communicate with
each other. At the end of the day, much more time is spent reading and
maintaining code than writing it. Making code easy to understand is
imperative when dealing with complex systems that never fail.
So, with lots of advantages, what are the disadvantages? Learning to use behaviors properly and proficiently can be difficult. It takes time to learn how to properly create systems using OTP design principles, but as documentation has improved, training courses and books have become available, and tools have been written, this has become less of an issue. Just the fact that you are reading a book dedicated largely to OTP says it all.
Behaviors add a few layers to the call chain, and slightly more data will be sent with every message and reply. While this might affect performance and memory usage, in most cases the impact will be negligible, especially considering the improvement in quality and free functionality. What is the point of writing code that is fast but buggy? The small increase in memory usage and reduction in performance is a small price to pay for reliability and fault tolerance. The rule of thumb is to always start with behaviors, and optimize when bottlenecks occur. You will find that optimizations as a result of inefficient behavior code are rarely if ever needed.
Extracting Generic Behaviors
Having introduced behaviors, let’s look at a familiar client-server example
written in pure Erlang without using behaviors. We use the frequency
server featured in the Erlang
Programming book and implemented in the frequency module. No worries if you have not
read the book and are not familiar with it; we explain what it does as we
go along. The server is a frequency allocator for cell phones. When a phone connects a call, it needs to
have a frequency allocated for it to use as a communication channel for
that conversation. The client holds this frequency until the call is
terminated, after which the frequency is deallocated, allowing other
subscribers to reuse it (Figure 3-4).
As this is the first major Erlang example in the book, we step through it in more detail than usual. In the subsequent chapters, we speed up the pace, so if your Erlang is a bit rusty, take this opportunity to get up to speed. Here, we take the code from the frequency server example, find the generic parts embedded in the module, and extract them into a library module. The outcome will be two modules: one containing generic reusable code, the other containing specific code with the frequency server’s business logic.
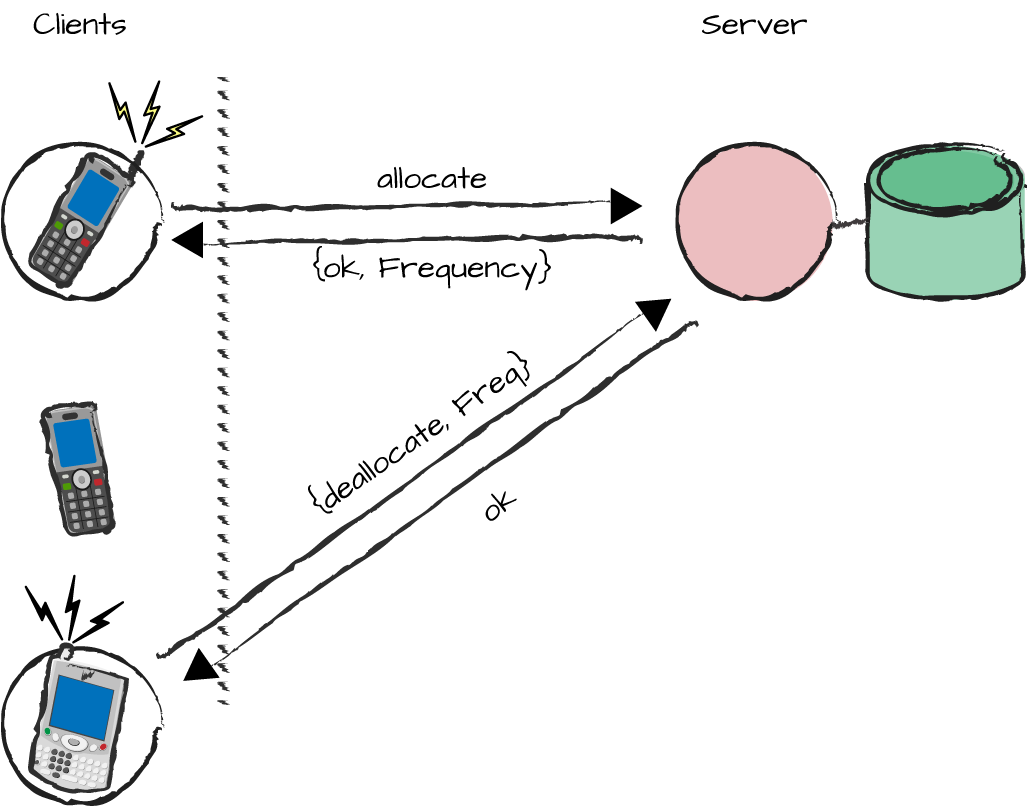
Figure 3-4. The frequency server
The clients and server are represented as Erlang processes, and the
exchange of information between them occurs via message passing hidden
behind a functional interface. The functional interface used by the
clients contains the functions allocate/0 and
deallocate/1:
allocate()->{ok,Frequency}|{error,no_frequency}deallocate(Frequency)->ok
The
allocate/0 function returns the result {ok,
Frequency} if there is at least one available frequency. If all
frequencies are in use, the tuple {error, no_frequency} is
returned instead. When the client is done with a phone call, it can
release the frequency it’s using by making a function call to
deallocate/1, passing the Frequency in use as an
argument.
We start the server with the start/0 call, later
terminating it with stop/0:
start()->truestop()->ok
The server is registered
statically with the alias frequency, so
no pids need to be saved and used for message passing.
A trial run of the frequency module from the shell might look like
this. We start the server, allocate all six available frequencies, and
fail to allocate a seventh one. Only by deallocating frequency 11 are we
then able to allocate a new one. We terminate the trial run by stopping
the server:
1>frequency:start().true 2>frequency:allocate(), frequency:allocate(), frequency:allocate(), frequency:allocate(),frequency:allocate(), frequency:allocate().{ok,15} 3>frequency:allocate().{error,no_frequency} 4>frequency:deallocate(11).ok 5>frequency:allocate().{ok,11} 6>frequency:stop().ok
If you need a deeper understanding of the code, feel free to download the module from the book’s code repository and run the example. Next, we go through the code in detail, explain what it does, and separate out the generic and the specific parts.
Starting the Server
Let’s begin with the functions used to create and initialize the server. The
start/0 function spawns a process that calls the
frequency:init/0 function, registering it with the
frequency alias. The init function initializes
the process state with a tuple containing the list of available
frequencies, conveniently hardcoded in the
get_frequencies/0 function, and the list of allocated
frequencies, represented by the empty list. We bind the frequency tuple,
referred to in the rest of the example as the process state or loop
data, to the Frequencies variable. The process
state variable changes with every iteration of the loop when available
frequencies are moved between the lists of allocated and available
ones.
Note how we export the init/0 function, because it
is passed as an argument to the spawn BIF, and how we register the
server process with the same name as the module. The latter, while not
mandatory, is considered a good Erlang programming practice as it
facilitates debugging and troubleshooting live systems:
-module(frequency).-export([start/0,stop/0,allocate/0,deallocate/1]).-export([init/0]).start()->register(frequency,spawn(frequency,init,[])).init()->Frequencies={get_frequencies(),[]},loop(Frequencies).get_frequencies()->[10,11,12,13,14,15].
Have a look at the preceding code and try to spot the generic expressions. Which expressions will not change from one client-server implementation to another?
Starting with the export directives, you always have to start and stop servers, irrespective of what they do. So, we consider these functions to be generic. Also generic are the spawning, registering, and calling of an initialization function containing the expressions used to initialize the process state. The process state will be bound to a variable and passed to the process loop. Note, however, that while the functions and BIFs might be considered generic, expressions in the functions and arguments passed to them aren’t. They will differ between different client-server implementations. We’ve highlighted all the parts we consider generic in the following code example:
-module(frequency).-export([start/0,stop/0,allocate/0,deallocate/1]).-export([init/0]).start()->register(frequency,spawn(frequency,init,[])).init()->Frequencies={get_frequencies(),[]},loop(Frequencies).get_frequencies()->[10,11,12,13,14,15].
From the generic,
let’s move on to the specific, which is the nonhighlighted code in the
previous example. The first server-specific detail that stands out in the
example is the module name frequency.
Module names obviously differ from one server implementation to another.
The client functions allocate/0 and
deallocate/1 are also specific to this particular
client-server application, as you will probably not find them in a
window manager or a key-value store (and if they did happen to share
the same name, the functions would be doing something completely
different). Although starting the server, spawning the server process,
and registering it are generic, the registered name and module
containing the init function are
considered specific.
The arguments passed to the init function are also specific. In our
example, we are not passing any arguments (hence the arity 0), but that
could change in other client-server implementations. The expressions in
the init/0 function are used to initialize the process
state. Initializing the state is different from one implementation to
another. Various applications might initialize window settings and
display the window, create an empty key-value store, and upload a
persistent backup, or, in this example, generate a tuple containing the
list of available frequencies.
When the process state has been initialized, it is bound to a
variable. Storing the process state is considered generic, but the
contents of the state itself are specific. In the code example that
follows, we highlight the Frequency variable as specific.
This means that the content of the variable is specific, whereas the
mechanism of passing it to the process loop is generic. Finally, the
get_frequencies/0 call used in init/0 is also
specific. In a real-world implementation, we would probably read the
frequencies from a configuration file or a persistent database, or through
a query to the base stations. For the sake of this example, we’ve been
lazy and hardcoded them in the module.
Let’s highlight the specific code:
-module(frequency).-export([start/0,stop/0,allocate/0,deallocate/1]).-export([init/0]).start()->register(frequency,spawn(frequency,init,[])).init()->Frequencies={get_frequencies(),[]},loop(Frequencies).get_frequencies()->[10,11,12,13,14,15].
Are you seeing the pattern and line of thought we are emphasizing? Let’s continue doing the same with the rest of the module, starting with the client functions.
The Client Functions
We refer to the functions called by client processes to control and access
the services of a server process as the client
API. It is always good practice, for readability and
maintainability, to hide message passing and protocol in a functional
interface. The client functions in the running example do exactly this.
In fact, we’ve taken it a step further here, encapsulating the sending
of requests and receiving of replies in the call/1 and
reply/2 functions. They contain code that otherwise would
have to be cloned for every message sent and received:
stop()->call(stop).allocate()->call(allocate).deallocate(Freq)->call({deallocate,Freq}).call(Message)->frequency!{request,self(),Message},receive{reply,Reply}->Replyend.reply(Pid,Reply)->Pid!{reply,Reply}.
The stop/0 function sends the atom stop
to the server. The server, upon receiving stop in its
receive-evaluate loop, interprets it and takes appropriate action. For
readability and maintainability reasons, it is good practice to use
keywords that describe what we are trying to do, but for all it matters,
we could have used the atom foobar, as it is not the name
of the atom but the meaning we give it in our program that is important.
In our case, stop ensures a normal termination of the
process. We will see how it is handled later in the example.
The client functions allocate/0 and
deallocate/1 are called and executed in the scope of the
client process. The client sends a message to the server by executing
one of the client functions in the frequency module. The
message is passed as an argument to the call/1 function and
bound to the Message variable. The Message is
in turn inserted in a tuple of the form {request, Pid,
Message}, where the pid is the client process identifier,
retrieved by calling the self() BIF and used by the server
as the destination for a response in the format {reply,
Reply}. We refer to this extra padding as the “protocol” between
the client and the server (see Figure 3-5).
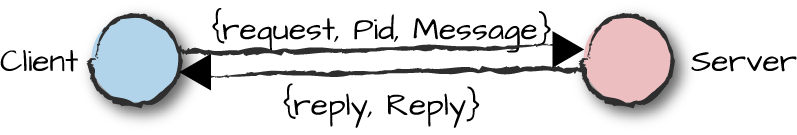
Figure 3-5. The message protocol
The server receives the request, handles it, and sends a reply
using the reply/2 call. It passes the pid sent in the
client request as the first argument and its reply message as the
second. This message is pattern matched in the receive clause of the
call/1 function, returning the contents of the variable
Reply as a result. This will be the result returned by the
client functions. A sequence diagram with the exchange of messages
between the cell phones and the frequency server is shown in Figure 3-6.
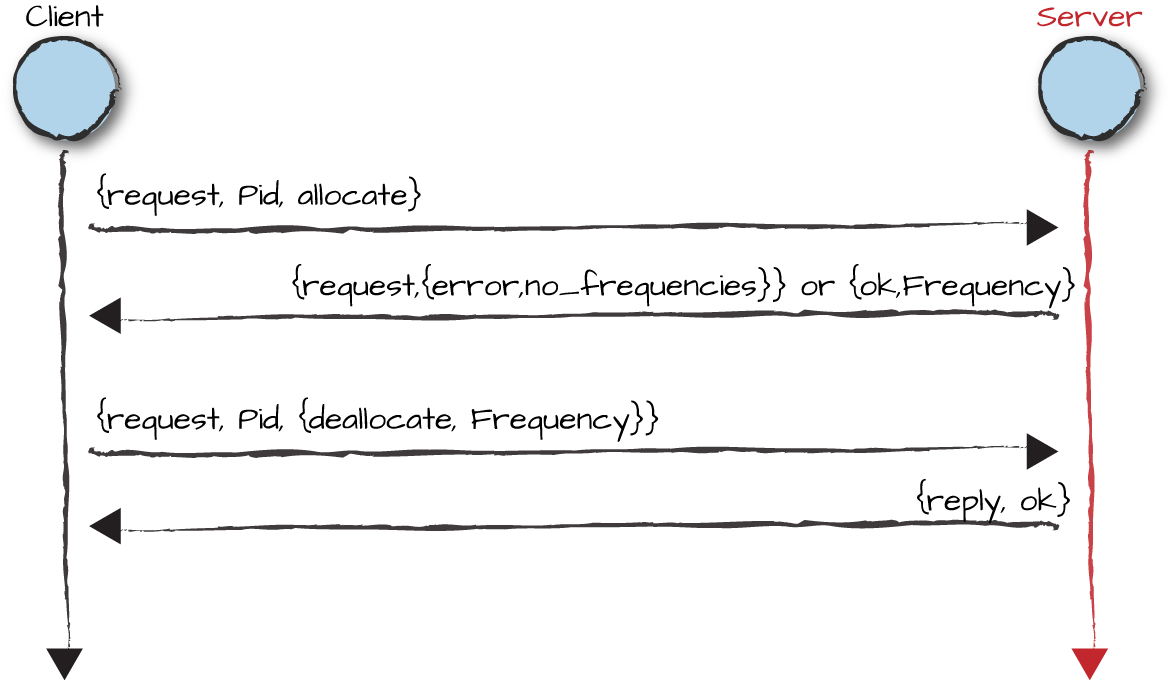
Figure 3-6. The frequency server messages
So, which parts of the code are generic? Which will not change
from one client-server implementation to another? First in line is the
stop/0 function, used whenever we want to inform the server
that it has to terminate. This code can be reused, as it is universal in
what it does. Every time we want to send a message, we use
call/1. There is a catch, however, as this function is not
completely generic. Have a look at the code and try to spot the anomaly:
stop()->call(stop).allocate()->call(allocate).deallocate(Freq)->call({deallocate,Freq}).call(Message)->frequency!{request,self(),Message},receive{reply,Reply}->Replyend.reply(Pid,Reply)->Pid!{reply,Reply}.
We are sending a message
to a registered process frequency.
This name will change from one server implementation to the next.
However, everything else in the call is generic. The function
reply/2, called by the server process, is also completely
generic. So what remains specific in the client functions are the client
functions themselves, their message content to the server, and the name
of the server:
stop()->call(stop).allocate()->call(allocate).deallocate(Freq)->call({deallocate,Freq}).call(Message)->frequency!{request,self(),Message},receive{reply,Reply}->Replyend.reply(Pid,Reply)->Pid!{reply,Reply}.
By hiding the message protocol in a
functional interface and abstracting it, we are able to change it
without affecting the code outside of the frequency module, client calls included. We
show how this comes in handy later in the chapter, when we start dealing
with some of the common error patterns that occur when working with
concurrent programming.
The Server Loop
Server processes iterate in a receive-evaluate loop. They wait for client requests, handle them, return a result, and loop again, waiting for the next message to arrive. With every iteration, they may update their process state and might generate side effects:
loop(Frequencies)->receive{request,Pid,allocate}->{NewFrequencies,Reply}=allocate(Frequencies,Pid),reply(Pid,Reply),loop(NewFrequencies);{request,Pid,{deallocate,Freq}}->NewFrequencies=deallocate(Frequencies,Freq),reply(Pid,ok),loop(NewFrequencies);{request,Pid,stop}->reply(Pid,ok)end.
In our frequency server example the
loop/1 function receives the allocate,
{deallocate, Frequency}, and stop commands.
Allocating a frequency is done through the helper function
allocate/2, which, given the loop data and the pid of the
client, moves a frequency from the available list to the allocated list.
Deallocating a frequency invokes the deallocate/2 call to
do the opposite, moving the frequency from the list of allocated
frequencies to the available list.
Both calls return the pair of updated frequency lists that make up
the process state; this new state is bound to the variable
NewFrequencies and passed to the tail-recursive
loop/1 call. In both cases, a reply is sent back to the
clients. When allocating a frequency, the contents of the variable
Reply are either {error, no_frequency} or
{ok, Frequency}. When deallocating a frequency, the server
sends back the atom ok.
When stopping the server, we acknowledge having received the
message through the ok response, and by the lack of a call
to loop/1 we make the process terminate normally, as
opposed to an abnormal termination that results from a runtime error. In
this example, there is nothing to clean up, so we don’t do anything
other than acknowledge the stop message. Had this server
handled some resource such as a key-value store, we could have ensured
that the data was safely backed up on a persistent medium. Or in the
case of a window server, we’d close the window and release any allocated
objects associated with it.
With all of this in mind, what functionality do you think is generic?
For starters, looping is generic. The protocol used to send and receive messages is
generic, but the messages and replies themselves aren’t. Finally,
stopping the server is generic, as is acknowledging the stop
message. The generic parts of the code are highlighted here:
loop(Frequencies)->receive{request,Pid,allocate}->{NewFrequencies,Reply}=allocate(Frequencies,Pid),reply(Pid,Reply),loop(NewFrequencies);{request,Pid,{deallocate,Freq}}->NewFrequencies=deallocate(Frequencies,Freq),reply(Pid,ok),loop(NewFrequencies);{request,Pid,stop}->reply(Pid,ok)end.
We have not highlighted the variables
Frequencies and NewFrequencies used to store
the process state. Although storing the process state is generic, the
state itself is specific. That is, the type of the state and the
particular value that this variable has are specific, but not the
generic task of storing the variable itself.
With the generic contents out of the way, the specifics include the loop data, the client messages, how we handle the messages, and the responses we send back as a result:
loop(Frequencies)->receive{request,Pid,allocate}->{NewFrequencies,Reply}=allocate(Frequencies,Pid),reply(Pid,Reply),loop(NewFrequencies);{request,Pid,{deallocate,Freq}}->NewFrequencies=deallocate(Frequencies,Freq),reply(Pid,ok),loop(NewFrequencies);{request,Pid,stop}->reply(Pid,ok)end.
Had there been specific code to be executed when
stopping the server, it would also have been marked as specific. This
code is usually placed in a function called terminate,
which, given the reason for termination and the loop data, handles all
of the cleaning up.
Functions Internal to the Server
The functions that actually perform the work of allocating or
deallocating a frequency within the server are not “visible” outside the
server module itself, and so we call them
internal to the server. The
allocate/1 call returns a tuple with the new frequencies
and the reply to send back to the client. If there are no available
frequencies, the first function clause will pattern match because the
list is empty. The frequencies are not changed, and {error,
no_frequency} is returned to the client. If there is at least one
frequency, the second function clause will match.
The available frequency list is split into a head and a tail,
where the head contains the available frequency, and the tail (a
possibly empty list) contains the remaining available frequencies. The
frequency with the client pid is added to the allocated list, and the
response {ok, Freq} is sent back to the client.
When deallocating a frequency in the deallocate/2
function, we delete it from the allocated list and add it to the
available one. Have a look at the functions and try to figure out what
is generic and what is specific:2
allocate({[],Allocated},_Pid)->{{[],Allocated},{error,no_frequency}};allocate({[Freq|Free],Allocated},Pid)->{{Free,[{Freq,Pid}|Allocated]},{ok,Freq}}.deallocate({Free,Allocated},Freq)->NewAllocated=lists:keydelete(Freq,1,Allocated),{[Freq|Free],NewAllocated}.
This should have been an easy question to answer, as these internal functions are all specific to our frequency server. When did you last allocate and deallocate frequencies when working with a key-value store or a window manager?
The Generic Server
Now that we’ve gone through this example and distinguished the generic from
the specific code, let’s get to the core of this chapter, namely the
separation of the code into two separate modules. Figure 3-7 shows we can now put all of
the generic code into the server module
and all of the specific code into frequency. Despite these changes, we maintain
the same functionality and interface. Calling the frequency
module in our new implementation should be no different from the trial run
we did in “Extracting Generic Behaviors”.
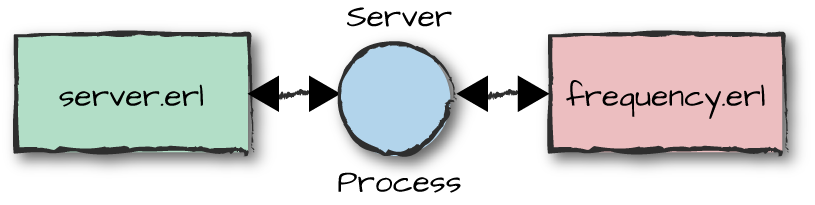
Figure 3-7. The frequency and server modules
The server module is in control,
managing the process activities. Whenever it has to handle specific
functionality it does not know how to execute, it hands over to the
callback functions in the frequency module. Let’s start with
the generic code in the server module that starts and
initializes the server:
-module(server).% server.erl-export([start/2,stop/1,call/2]).-export([init/2]).start(Name,Args)->register(Name,spawn(server,init,[Name,Args])).init(Mod,Args)->State=Mod:init(Args),loop(Mod,State).
Spawning a process, registering it, and
calling the init function are all
generic, whereas the alias with which we register the process, the name of
the callback module, and the arguments we pass to the init function are all specific. We pass this
specific information as parameters to the server:start/2
function, using them where needed. Name is used both as the
registered name of the frequency process and as the name of the callback
module. Args is passed to the init function and is used to initialize the
process state.
We keep the client functions in the frequency module,
using it as a wrapper around the server. By doing so, we are hiding
implementation details, including the very use of the server
module. Just like in our previous example, we start the server using
frequency:start/0, resulting in a call to
server:start/2. The newly spawned server, through the
Mod:init/1 call, invokes the init/1 callback
function in the frequency module, initializing the process
state by creating the tuple containing the available and allocated
frequencies. Mod is bound to the callback module frequency and Args is bound to
[]. The frequency tuple gets bound to the State
variable, which along with Mod is passed as an argument to
the loop in the server module:
-module(frequency).% frequency.erl-export([start/0,stop/0,allocate/0,deallocate/1]).-export([init/1,terminate/1,handle/2]).start()->server:start(frequency,[]).init(_Args)->{get_frequencies(),[]}.get_frequencies()->[10,11,12,13,14,15].
The init/1 callback is required to return the initial
process state, stored and used in the server receive-evaluate loop. In the
init/1 callback function, note that we are not using the
value of the _Args parameter. Because init/1 is
a callback function, we have to follow the required protocol and
functional interface for that callback API. In the general case,
init/1 requires an argument because there might be server
implementations that need data at startup. This particular example
doesn’t, so we pass the empty list and ignore it.
Let’s jump back to the server
module. When a client process wants to send a request to the server, it
does so by calling server:call(frequency, Msg). The server,
when responding, does so using the reply/2 call. We are, in
effect, hiding all of the message passing behind a functional
interface.
Another generic function is server:stop/1. We
distinguish this function from call/2 because we want to fix its meaning
and therefore differentiate it from server:call(frequency, {stop,
self()}), which could be treated by the developer as a specific
call rather than as a generic server control message. Instead, by calling
stop, we invoke the terminate/1 callback
function, which is given the process state and will contain all of the
specific code executed when shutting down the server. In our case, we have
kept the example to a minimum. Note, however, that we could have chosen to
terminate all of the client processes that had been allocated a frequency:
stop(Name)->% server.erlName!{stop,self()},receive{reply,Reply}->Replyend.call(Name,Msg)->Name!{request,self(),Msg},receive{reply,Reply}->Replyend.reply(To,Reply)->To!{reply,Reply}.
To ensure that we maintain the same
interface, we export exactly the same functions in our new implementation
of the frequency module:
stop()->server:stop(frequency).% frequency.erlallocate()->server:call(frequency,{allocate,self()}).deallocate(Freq)->server:call(frequency,{deallocate,Freq}).
These
functions send requests and stop messages to the server. When the process
receives the messages, the relevant callback functions in the frequency module are invoked. In the case of the
stop message, it is the function terminate/1. It takes the
process state as an argument and its return value is sent back to the
client, becoming the return value of the stop/1 call:
loop(Mod,State)->% server.erlreceive{request,From,Msg}->{NewState,Reply}=Mod:handle(Msg,State),reply(From,Reply),loop(Mod,NewState);{stop,From}->Reply=Mod:terminate(State),reply(From,Reply)end.
In the case of a call request, the
handle/2 callback is invoked. The call takes two arguments,
the first being the message bound to the variable Msg and the
second the process state bound to the variable State. Pattern
matching on the Msg picks the function clause that handles
the message. The callback has to return a tuple in the format
{NewState, Reply}, where NewState contains the
updated frequencies and Reply is the reply sent back to the
client. Have a look at the implementation of allocate/2. It
returns exactly that: a tuple where the first element is the updated
process state and the second element either {ok, Frequency}
or {error, no_frequency}.
The first clause of the receive
in loop/2 takes the return value from handle/2,
sends back a reply to the client using reply/2, and loops
with the new state, awaiting the next request:
terminate(_Frequencies)->% frequency.erlok.handle({allocate,Pid},Frequencies)->allocate(Frequencies,Pid);handle({deallocate,Freq},Frequencies)->{deallocate(Frequencies,Freq),ok}.allocate({[],Allocated},_Pid)->{{[],Allocated},{error,no_frequency}};allocate({[Freq|Free],Allocated},Pid)->{{Free,[{Freq,Pid}|Allocated]},{ok,Freq}}.deallocate({Free,Allocated},Freq)->NewAllocated=lists:keydelete(Freq,1,Allocated),{[Freq|Free],NewAllocated}.
The same applies to the deallocate request. The frequency is
deallocated, the handle/2 call
returns a tuple with the new state returned by the
deallocate/2 call, and the response, the atom
ok, is sent back to the client.
So what we now have is our frequency example split up into a generic
library module we call server and a
specific callback module we call frequency. This is all there is to understanding
Erlang behaviors. It is all about splitting up the code into generic and
specific parts, and packaging the generic parts into reusable libraries to
hide as much of the complexity as possible from the developers. We’ve kept
this example simple to show our point, and barely scratched the surface of
the corner cases that are handled behind the scenes in the proper behavior
libraries. We cover these details in the next section, and introduce them
as we talk about the individual behavior library modules.
Message Passing: Under the Hood
Concurrent programming is not easy. You need to deal with race conditions, deadlocks, and critical sections as well as many corner cases. Despite this, you rarely hear Erlang developers complain, let alone discuss these problems. The reason is simple: most of these issues become nonissues as a result of the OTP framework. In this chapter, we extracted the generic code from a particular client-server system, but in doing so we kept our example as simple as possible. There are many error conditions in a scenario like this that are handled behind the scenes by the behavior library modules we cover in the next chapter. Just to emphasize the point, they are handled without the programmer having to be aware of them. Race conditions, especially with multicore architectures, have become more common, but they should be picked up with appropriate modeling and testing tools such as Concuerror, McErlang, PULSE, and QuickCheck.
Having said that, let’s look at an example of how behavior libraries
help us hide a lot of the tricky cases an inexperienced developer might
not think of when first implementing a concurrent system. We use the
call/2 function from the previous example, expanding it as we
go along:
call(Name,Message)->Name!{request,self(),Message},receive{reply,Reply}->Replyend.reply(Pid,Reply)->Pid!{reply,Reply}.
We send a message to the server of the format {request, Pid,
Message} and wait for a response of the format {reply,
Reply}. When we receive the reply, as shown in Figure 3-8, how can we be confident that the reply is
actually a reply from the server, and not a message sent by another
process but also complying with the protocol?

Figure 3-8. Message race conditions
Given this implementation, we can’t. The solution to this problem is
to use references. By creating a unique reference with the make_ref() BIF, adding it to the message,
and including it in the reply, we will be guaranteed that the response is
actually the reply to our request, and not just a message that happens to
comply with our protocol. Adding references, our code looks like
this:3
call(Name,Msg)->Ref=make_ref(),Name!{request,{Ref,self()},Msg},receive{reply,Ref,Reply}->Replyend.reply({Ref,To},Reply)->To!{reply,Ref,Reply}.
Note how Ref is already bound when entering the receive
clause, ensuring replies are the result of the original message. This
solves the problem, but is this enough? What happens if the server crashes
before we send a request? If Name is an alias, we are covered
because the client process will terminate when trying to send a message to
a nonexistent registered process. But if Name is a pid, the
message will be lost and the client will hang in the receive clause of the call function. Or
similarly, what happens if the server crashes between receiving the
message and sending the reply? This could be as a result of our request,
or as the result of another client request it might be handling. Having a
registered process will not cover this case either, as the process is
alive when the message is sent.
The solution is to monitor the server. In doing so, let’s use the
monitor BIF instead of a link, because
links are bidirectional and might cause side effects on the server if the
child process were to be killed during the request. While the client wants
to monitor termination of the server, terminating the client should not
affect the server. The monitor BIF returns a unique reference, so we can drop the
make_ref() BIF and use the monitor reference to tag our
messages:
call(Name,Msg)->Ref=erlang:monitor(process,Name),Name!{request,{Ref,self()},Msg},receive{reply,Ref,Reply}->erlang:demonitor(Ref),Reply;{'DOWN',Ref,process,_Name,_Reason}->{error,no_proc}end.
Have we covered everything that can go wrong? No, not really. By monitoring the process, we are now exposing ourselves to another race condition. Consider the following sequence of events:
The client monitors the server.
The client sends a request to the server.
The server receives the request and handles it.
The server sends back a response to the client.
The server crashes as the result of another request.
The client receives a
DOWNmessage as a result of the monitor.The client extracts the server response from its mailbox.
The client demonitors the (now defunct) server.
We are stuck with a DOWN message in the client mailbox
containing a reference that will never match. Now, what are the chances of that
happening? Do you really think someone would think of that particular test
case where the server terminates right after it sends the client its reply,
but before the client executes the erlang:demonitor/2 call?
While this is an extreme corner case, we still need to handle the
DOWN message as it might cause a memory leak. We do this by
passing the [flush] option to the
second argument in the demonitor/2 call, ensuring that any
DOWN messages belonging to that monitor are not left
lingering in the process mailbox.
Are we there yet? No, not really: what if Name is not
an alias of a registered process? We need a catch to trap any
exception raised as a result of the client sending a message to a
nonexistent registered process. We don’t really care about the result of
the catch—if we did, we would have used
try-catch instead—because if the server does not exist,
monitor/1 will send a DOWN message. Our new code
now looks like this:
call(Name,Msg)->Ref=erlang:monitor(process,Name),catchName!{request,{Ref,self()},Msg},receive{reply,Ref,Reply}->erlang:demonitor(Ref,[flush]),Reply;{'DOWN',Ref,process,_Name,_Reason}->{error,no_proc}end.
Unfortunately, though, these changes are still not enough. What
happens if process A does a synchronous call to B at the same time as
process B calls A? By “synchronous call,” we mean an Erlang message exchange
where the sending process expects a response, and the message and response
are each sent as asynchronous messages. Process A enters the receive clause right
after sending its request matching on a unique reference sent with the
request, and B does the same. Back to answering our original question, if
two processes synchronously call each other using this code, we get a
deadlock. While deadlocks are a result of a design flaw, they might happen
in live systems, and a recovery mechanism (preferably a generic one) needs
to be put in place. The easiest way to resolve deadlocks is through a
timeout in your receive statement, terminating the process. We go into
more detail on deadlocks and timeouts and show you how OTP solves this
problem in the next chapter.
Summing Up
In this chapter, we’ve covered the principles behind concurrency design patterns, introducing the concept of behavior libraries. We hope we have made our point about the importance and power of behavior libraries, as understanding them is fundamental to understanding the underlying principles of OTP. Decades of experience in process-oriented programming are reflected in them, removing the burden from the developers, reducing their code bases, and ensuring that corner cases are handled in a consistent, efficient, and correct manner. Be honest: how many of the corner cases discussed in this example would you have handled in a first iteration? What about your colleagues? Imagine testing and maintaining a system where everyone has reinvented the wheel with their own representation of these concurrent conditions and corner cases! The bottom line is that standard OTP behaviors handle all of these issues; that is why you should use them.
If you have the time, pick a simple client-server example you might have written when learning Erlang. It could be a key-value store, a chat server, or any other process that receives and handles requests. If you do not have any examples at hand, use the mobile subscriber database example from the ETS and DETS chapter of the Erlang Programming book. You can download the code from the authors’ GitHub repositories.
Another useful exercise is to extend the call function with an
after clause, making the process exit with reason
timeout. Create a new function:
call(Name,Message,Timeout)
which,
given a Timeout integer value in milliseconds or the atom
infinity, allows users to set their
own timeouts. Keep the call/2 call, setting the default to 5
seconds. If the server does not respond within the given timeout value,
make the client process terminate abnormally with the reason
timeout. Don’t forget to clean up before exiting, as the exit
signal might be caught in a try-catch expression in the code using the
server library.
What’s Next?
In the next chapters, we introduce the library modules that together
give us the OTP behaviors. We start with the gen_server library, and then later use a similar
approach to introduce FSMs, event handlers, supervisors, and applications.
We have not yet covered deadlocks, timeouts, and error cases that can
arise when dealing with distribution or messages that never match. These
are all topics we discuss when covering the individual behavior
libraries.
1 Bug-free systems exist only in the dreams of the bureaucrats. When using Erlang/OTP, equal focus should be placed on correctness and error recovery, as the bugs will manifest themselves in production systems whether you like it or not.
2 Warning, this is a trick question.
3 Minor changes are also needed to the code in order to get the
stop call to work. We skip them in this example.