
Chapter 14
Rigorous Empirical Evaluation
Preparation
Be prepared; that’s the Boy Scouts’ marching song…. Don’t be nervous, don’t be flustered, don’t be scared…. Be prepared!
– Tom Lehrer
Objectives
After reading this chapter, you will:
1. Know how to plan for rigorous empirical UX evaluation in the lab and in the field
2. Be able to select people for team roles
3. Know how to select effective tasks for empirical UX evaluation
4. Be prepared to select an evaluation method and various data collection techniques, including critical incident identification, think-aloud techniques, co-discovery, and questionnaires
5. Have the working knowledge to select, recruit, and prepare for participants
6. Know how to perform pilot testing before evaluation
7. Understand the concepts and issues relating to determining the right number of participants for a given evaluation situation
14.1 Introduction
14.1.1 You Are Here
We begin each process chapter with a “you are here” picture of the chapter topic in the context of the overall Wheel lifecycle template; see Figure 14-1. This chapter, about preparing for evaluation, begins a series of chapters about rigorous empirical UX evaluation.
Figure 14-1 You are here, at preparing for evaluation, within the evaluation activity in the context of the overall Wheel lifecycle template.
This chapter begins a series of four about rigorous empirical UX evaluation methods, of which lab-based testing is the archetype example. Some of what is in these chapters applies to either lab-based or in-the-field empirical evaluation, but parts are specific to just lab based. Field-based rigorous empirical UX evaluation is essentially the same as lab based except the work is done on location in the field instead of in a lab.
Although we do include quantitative UX data collection and analysis, this is emphasized less than it used to be in previous usability engineering books because of less focus in practice on quantitative user performance measures and more emphasis on evaluation to reveal UX problems to be fixed.
14.2 Plan for rigorous empirical UX evaluation
Planning your empirical UX evaluation means making cost-effective decisions and trade-offs. As Dray and Siegel (1999) warn, “Beware of expediency as a basis for decision making.” In other words, do not let small short-term savings undercut your larger investment in evaluation and in the whole process lifecycle.
14.2.1 A Rigorous UX Evaluation Plan
The purpose of your plan for rigorous UX evaluation, whether lab based or in the field, is to describe evaluation goals, methods, activities, conditions, constraints, and expectations. Especially if the plan will be read by people outside your immediate project group, you might want an upfront “boilerplate” introduction with some topics like these, described very concisely:
![]() Goals and purpose of this UX evaluation
Goals and purpose of this UX evaluation
![]() Overview of product or parts of product being evaluated (for people outside the group)
Overview of product or parts of product being evaluated (for people outside the group)
![]() Goals of the product user interface (i.e., what will make for a successful user experience)
Goals of the product user interface (i.e., what will make for a successful user experience)
![]() Description of the intended user population
Description of the intended user population
![]() Overview of approach to informed consent
Overview of approach to informed consent
![]() Overview of how this evaluation fits into the overall iterative UX process lifecycle
Overview of how this evaluation fits into the overall iterative UX process lifecycle
![]() Overview of the UX evaluation process in general (e.g., preparation, data collection, analysis, reporting, iteration)
Overview of the UX evaluation process in general (e.g., preparation, data collection, analysis, reporting, iteration)
![]() General evaluation methods and activities planned for this session
General evaluation methods and activities planned for this session
The body of the plan can include topics such as:
![]() Description of resources and constraints (e.g., time needed/available, state of prototype, lab facilities and equipment)
Description of resources and constraints (e.g., time needed/available, state of prototype, lab facilities and equipment)
![]() Approach to evaluation, choices of data collection techniques
Approach to evaluation, choices of data collection techniques
![]() Mechanics of the evaluation (e.g., materials used, informed consent, location of testing, UX goals and metrics involved, tasks to be explored, including applicable benchmark tasks)
Mechanics of the evaluation (e.g., materials used, informed consent, location of testing, UX goals and metrics involved, tasks to be explored, including applicable benchmark tasks)
![]() All instruments to be used (e.g., benchmark task descriptions, questionnaires)
All instruments to be used (e.g., benchmark task descriptions, questionnaires)
![]() Specifics of your approach to evaluate emotional impact and, if appropriate, phenomenological aspects of interaction
Specifics of your approach to evaluate emotional impact and, if appropriate, phenomenological aspects of interaction
14.2.2 Goals for Rigorous UX Evaluation Session
One of the first things to do in an evaluation plan is to set, prioritize, and document your evaluation goals. Identify the most important design issues and user tasks to investigate. Decide which parts of the system or functionality you simply will not have time to look at.
Your evaluation goals, against which you should weigh all your evaluation choices and activities, can include:
![]() Application scope (parts of the system to be covered by this evaluation)
Application scope (parts of the system to be covered by this evaluation)
![]() Types of data to collect (see Chapter 12)
Types of data to collect (see Chapter 12)
![]() UX goals, targets, and metrics, if any, to be addressed
UX goals, targets, and metrics, if any, to be addressed
![]() Matching this evaluation to the current stage of product design evolution
Matching this evaluation to the current stage of product design evolution
14.3 Team roles for rigorous evaluation
Select your team members for evaluation activities. Encourage your whole project team to participate in at least some evaluation. The greater the extent that the whole team is involved from the start, in both the planning and the execution of the studies, the better chance you have at addressing everyone’s concerns. Broad participation begets buy-in and ownership, necessary for your results to be taken as a serious mandate to fix problems.
However, your evaluation team will practically be limited to practitioners with active roles, perhaps plus a few observers from the rest of your project team or organization. So, everyone on your evaluation team is an “evaluator,” but you also need to establish who will play more specific roles, including the facilitator, the prototype “executor,” and all observers and data collectors. Whether your prototype is low or high fidelity, you will need to select appropriate team roles for conducting evaluation.
14.3.1 Facilitator
Select your facilitator, the leader of the evaluation team. The facilitator is the orchestrator, the one who makes sure it all works right. The facilitator has the primary responsibility for planning and executing the testing sessions, and the final responsibility to make sure the laboratory is set up properly. Because the facilitator will be the principal contact for participants during a session and responsible for putting the participant at ease, you should select someone with good “people skills.”
Participant
“Participant” is the term we use for the subject or outside person who helps the team design and evaluate interaction, usually by performing tasks and giving feedback.
14.3.2 Prototype Executor
If you are using a low-fidelity (e.g., paper) prototype, you need to select a prototype executor, a person to “execute” the prototype as though it were being run on a computer. The person in this role is the computer.
The prototype executor must have a thorough technical knowledge of how the design works. So that the prototype executor responds only to participant actions, he or she must have a steady Vulcan sense of logic. The executor must also have the discipline to maintain a poker face and not speak a single word throughout the entire session.
14.3.3 Quantitative Data Collectors
If you intend to collect quantitative data, you will need quantitative data collectors. Depending on your UX metrics and quantitative data collection instruments, people in these roles may be walking around with stopwatches and counters (mechanical, electronic, or paper and pencil). Whatever quantitative data are called for by the UX metrics, these people must be ready to take and record those data. Quantitative data collectors must be attentive and not let data slip by without notice. They must have the ability to focus and not let their minds wander during a session. If you can afford it, it is best to let someone specialize in only taking quantitative data. Other duties and distractions often lead to forgetting to turn on or off timers or forgetting to count errors.
14.3.4 Qualitative Data Collectors
Although facilitators are usually experienced in data collection, they often do not have time to take data or they need help in gathering all qualitative data. When things are happening fast, the need for facilitation can trump data taking for the facilitator.
Select one or more others as data collectors and recorders. No evaluation team member should ever be idle during a session. Thoroughness will improve with more people doing the job. Everyone should be ready to collect qualitative data, especially critical incident data; the more data collectors, the better.
Critical Incident
A critical incident is a UX evaluation event that occurs during user task performance or other user interaction, observed by the facilitator or other observers or sometimes expressed by the user participant, that indicates a possible UX problem. Critical incident identification is arguably the single most important source of qualitative data.
14.3.5 Supporting Actors
Sometimes you need someone to interact with the participant as part of the task setting or to manage the props needed in the evaluation. For example, for task realism you may need someone to call the participant on a telephone in the participant room or, if your user participant is an “agent” of some kind, you may need a “client” to walk in with a specific need involving an agent task using the system. Select team members to play supporting roles and handle props.
14.4 Prepare an effective range of tasks
If evaluation is to be task based, including lab-based testing and task-driven UX inspection methods, select appropriate tasks to support evaluation. Select different kinds of tasks for different evaluation purposes.
14.4.1 Benchmark Tasks to Generate Quantitative Measures
If you plan to use UX goals and targets to drive your UX evaluation, everyone in an evaluator role should have already participated with other members of the project team in identifying benchmark tasks and UX target attributes and metrics (Chapter 10). These attributes and metrics must be ready and waiting as a comparison point with actual results to be observed in the informal summative component of the evaluation sessions with participants.
Be sure that descriptions of all benchmark tasks associated with your UX targets and metrics are in final form, printed off, and ready to use by participants to generate data to be measured. Benchmark tasks portray representative, frequent, and critical tasks that apply to the key work role and user class represented by each participant (Chapter 10). Make sure each task description says only what to do, with no hints about how to do it. Also, do not use any language that telegraphs any part of the design (e.g., names of user interface objects or user actions, or words from labels or menus).
14.4.2 Unmeasured Tasks
Like benchmark tasks, additional unmeasured tasks, used especially in early cycles of evaluation, should be ones that users are expected to perform often. Unmeasured tasks are tasks for which participant performance will not be measured quantitatively but which will be used to add breadth to qualitative evaluation. Evaluators can use these representative tasks to address aspects of the design not covered in some way by the benchmark tasks.
In early stages, you might employ only unmeasured tasks, the sole goal of which is to observe critical incidents and identify initial UX problems to root out, to fix at least the most obvious and most severe problems before any measured user performance data can be very useful.
Just as for benchmark tasks created for testing UX attributes, you should write up representative unmeasured task descriptions, which should be just as specific as the benchmark task descriptions, and give them to the participant to perform in the evaluation sessions.
14.4.3 Exploratory Free Use
In addition to strictly specified benchmark and unmeasured tasks, the evaluator may also find it useful to observe the participant in informal free use of the interface, a free-play period without the constraints of predefined tasks. This does not necessarily mean that they are even doing tasks, just exploring.
Be prepared to ask your participants to explore and experiment with the interaction design, beyond task performance. To engage a participant in free use, the evaluator might simply say “play around with the interface for awhile, doing anything you would like to, and talk aloud while you are playing.” Free use is valuable for revealing participant expectations and system behavior in situations not anticipated by designers, often situations that can break a poor design.
14.4.4 User-Defined Tasks
Sometimes tasks that users come up with will address unexpected aspects of your design (Cordes, 2001). You can include user-defined tasks by giving your participants a system description in advance of the evaluation sessions and ask them to write down some tasks they think are appropriate to try or you can wait until the session is under way and ask each participant extemporaneously to come up with tasks to try.
If you want a more uniform task set over your participants but still wish to include user-defined tasks, you can ask a different set of potential users to come up with a number of candidate task descriptions before starting any evaluation session. This is a good application for a focus group. You can vet, edit, and merge these into a set of user-defined tasks to be given to each participant as part of each evaluation session.
14.5 Select and adapt evaluation method and data collection techniques
14.5.1 Select Evaluation Method and Data Collection Techniques
Using the descriptions of the evaluation methods and data collection techniques in Chapter 12, including the descriptions of the kinds of evaluation each is used for, select your evaluation method and data collection techniques to fit your evaluation plan and goals and the particular evaluation needs of your system or product.
For example, at a high level, you should choose first between rigorous or rapid evaluation methods (see Chapter 12). If you choose rigorous, you might choose between a lab-based or in-the-field method. If you choose rapid methods, your next choice should be from among the many such evaluation methods given in Chapter 13.
Your approach to choosing evaluation methods and techniques should be goal driven. For example, when you wish to evaluate usefulness—the coverage, completeness, and appropriateness of functionality and the coverage, completeness, and appropriateness of its support in the user interface—consider doing it:
![]() Objectively, by cross-checks of functionality implied by your hierarchical task inventory, design scenarios, conceptual design, and task intention descriptions.
Objectively, by cross-checks of functionality implied by your hierarchical task inventory, design scenarios, conceptual design, and task intention descriptions.
![]() Subjectively, by user questionnaires (Chapter 12).
Subjectively, by user questionnaires (Chapter 12).
![]() Longitudinally, by following up with real users in the field after a product or system is released. Use downstream questionnaires directed at usefulness issues to guiding functional design thinking for subsequent versions.
Longitudinally, by following up with real users in the field after a product or system is released. Use downstream questionnaires directed at usefulness issues to guiding functional design thinking for subsequent versions.
Your choices of specific data collection techniques should also be goal driven. If you are using participants, as you will in rigorous evaluation, you should strongly consider using the critical incident identification, think-aloud, and co-discovery techniques (Chapter 12). If you are doing a task-driven expert UX inspection (Chapter 13), you can collect data about your own critical incidents.
Think-Aloud Technique
The think aloud technique is a qualitative data collection technique in which user participants verbally externalize their thoughts about their interaction experience, including their motives, rationale, and perceptions of UX problems. By this method, participants give the evaluator access to an understanding of their thinking about the task and the interaction design.
Co-Discovery
Co-discovery is the term for using two or more participants in a team approach to evaluation, usually with a think-aloud data collection technique. Two people can verbalize more naturally, yielding multiple viewpoints expressed within conversational interplay.
Questionnaires (Chapter 12) are a good choice if you want to supplement your objective UX evaluation data with subjective data directly from the user. Questionnaires are simple to use, for both analyst and participant, and can be used with or without a lab. Questionnaires can yield quantitative data as well as qualitative user opinions.
For example, a questionnaire can have numerical choices that participants must choose from to provide quantitative data or it can have open-ended questions to elicit qualitative free-form feedback. Questionnaires are good for evaluating specific predefined aspects of the user experience, including perceived usability and usefulness.
If you want to collect data to evaluate emotional impact, questionnaires are probably the least expensive choice and the easiest to administer. More advanced data collection techniques for evaluating emotional impact include biometrics and other ways to identify or measure physiological responses in users (Chapter 12).
If you choose to use a questionnaire in your evaluation, your next step is to use the information on questionnaires in Chapter 12 to decide which questionnaire to use. For example, you might choose our old standby, the Questionnaire for User Interface Satisfaction (QUIS), for subjective evaluation of, and user satisfaction about, traditional user performance and usability issues in screen-based interaction designs; the System Usability Scale (SUS) for a versatile and broadly applicable general purpose subject user experience evaluation instrument; or the Usefulness, Satisfaction, and Ease of Use (USE) questionnaire for a general-purpose subjective user experience evaluation instrument.
Part of choosing a questionnaire will involve deciding the timing of administration, for example, after each task or at the end of each session.
14.5.2 Adapt Your Choice of Evaluation Method and Data Collection Techniques
For UX evaluation, as perhaps for most UX work, our motto echoes that old military imperative: Improvise, adapt, and overcome! Be flexible and customize your methods and techniques, creating variations to fit your evaluation goals and needs. This includes adapting any method by leaving out steps, adding new steps, and changing the details of a step.
14.6 Select participants
The selection and recruitment of participants are about finding representative users outside your team and often outside your project organization to help with evaluation. This section is mainly focused on participants for lab-based UX evaluation, but also applies to other situations where participants are needed, such as some non-lab-based methods for evaluating emotional impact and phenomenological aspects.
In formal summative evaluation, this part of the process is referred to as “sampling,” but that term is not appropriate here because what we are doing has nothing to do with the implied statistical relationships and constraints.
14.6.1 Establish Need and Budget for Recruiting User Participants Upfront
Finding and recruiting evaluation participants might be part of the process where you are tempted to cut corners and save a little on the budget or might be something you think to do at the last minute.
In participant recruiting, to protect the larger investment already made in the UX lifecycle process and in setting up formative evaluation so far, you need to secure a reasonable amount of resources, both budget money and schedule time to recruit and remunerate the full range and number of evaluation participants you will need. If you do this kind of evaluation infrequently, you can engage the services of a UX evaluation consulting group or a professional recruiter to do your participant recruiting.
14.6.2 Determine the Right Participants
Look for participants who are “representative users,” that is, participants who match your target work activity role’s user class descriptions and who are knowledgeable of the general target system domain. If you have multiple work roles and corresponding multiple user classes, you must recruit participants representing each category. Prepare a short written demographic survey to administer to participants to confirm that each one meets the requirements of your intended work activity role’s user class characteristics.
Participants must also match the user class attributes in any UX targets they will help evaluate. For example, if initial usage is specified, you need participants unfamiliar with your design. So, for example, even though a user may be a perfect match to a given key work role’s user class characteristics, if the UX target involved specifies “initial performance” as the UX attribute and this participant has already seen and used the interaction design, maybe in a previous iteration, this person is not the right participant for this part of the evaluation.
“Expert” participants
Recruit an expert user, someone who knows the system domain and knows your particular system, if you have a session calling for experienced usage. Expert users are good at generating qualitative data. These expert users will understand the tasks and can tell you what they do not like about the design. But you cannot necessarily depend on them to tell you how to make the design better.
Recruit a UX expert if you need a participant with broad UX knowledge and who can speak to design flaws in terms of design guidelines. As participants, these experts may not know the system domain as well and the tasks might not make as much sense to them, but they can analyze user experience, find subtle problems (e.g., small inconsistencies, poor use of color, confusing navigation), and offer suggestions for solutions.
Consider recruiting a so-called double expert, a UX expert who also knows your system very well, perhaps the most valuable kind of participant. But the question of what constitutes being an expert of value to your evaluation is not always clear-cut. Also, the distinction between expert and novice user is not a simple dichotomy. Not all experts make good evaluation participants and not all novices will perform poorly. And being an expert is relative: an expert in one thing can very well be a novice at something else. And even the same person can be an expert at one thing today and less of an expert in a month due to lack of practice and retroactive interference (intervening activities of another type).
14.6.3 Determine the Right Number of Participants
The question of how many participants you need is entirely dependent on the kind of evaluation you are doing and the conditions under which you are doing it. There are some rules of thumb, such as the famous “three to five participants is enough” maxim, which is quoted so often out of context as to be almost meaningless. However, real answers are more difficult. See the end of this chapter for further discussion about the “three to five users” rule and its limitations.
The good news is that your experience and intuition will be good touchstones for knowing when you have gotten the most of an iteration of UX evaluation and when to move on. One telltale sign is the lack of many new critical incidents or UX problems being discovered with additional participants.
You have to decide for yourself every time you do UX testing—how many participants you can or want to afford. Sometimes it is just about achieving your UX targets, regardless of how many participants and iterations it takes. More often it is about getting in, getting some insight, and getting out.
14.7 Recruit participants
Now the question arises as to where to find participants. Inform your customer early on about how your evaluation process will proceed so you will have the best chance of getting representative users from the customer organization at appropriate times.
14.7.1 Recruiting Methods and Screening
Here are some hints for successful participant recruiting.
![]() Try to get the people around you (co-workers, colleagues elsewhere in your organization, spouses, children, and so on) to volunteer their time to act as participants, but be sure their characteristics fit your key work role and the corresponding user class needs.
Try to get the people around you (co-workers, colleagues elsewhere in your organization, spouses, children, and so on) to volunteer their time to act as participants, but be sure their characteristics fit your key work role and the corresponding user class needs.
![]() Newspaper ads and emailings can work to recruit participants, but these methods are usually inefficient.
Newspaper ads and emailings can work to recruit participants, but these methods are usually inefficient.
![]() If the average person off the street fits your participant profile (e.g., for a consumer software application), hand out leaflets in shopping malls and parking lots or post notices in grocery stores or in other public places (e.g., libraries).
If the average person off the street fits your participant profile (e.g., for a consumer software application), hand out leaflets in shopping malls and parking lots or post notices in grocery stores or in other public places (e.g., libraries).
![]() Use announcements at meetings of user groups and professional organizations if the cross section of the groups matches your user class needs.
Use announcements at meetings of user groups and professional organizations if the cross section of the groups matches your user class needs.
![]() Recruit students at universities, community colleges, or even K–12, if appropriate.
Recruit students at universities, community colleges, or even K–12, if appropriate.
![]() Consider temporary employment agencies as another source for finding participants.
Consider temporary employment agencies as another source for finding participants.
A possible pitfall with temporary employment agencies is that they usually know nothing about UX evaluation, nor do they understand why it is so important to choose appropriate people as participants. The agency goal, after all, is to keep their pool of temporary workers employed, so screen their candidates with your user classes.
14.7.2 Participant Recruiting Database
No matter how you get contact information for your potential participants (advertising campaign, references from marketing, previously used participants), if you are going to be doing evaluation often, you should maintain a participant recruiting database. Because all the participants you have used in the past should be in this database, you can draw on the good ones for repeat performances.
You can also sometimes use your own customer base or your customer’s contact lists as a participant recruiting source. Perhaps your marketing department has its own contact database.
14.7.3 Incentives and Remuneration
Generally, you should not ask your participants to work for free, so you will usually have to advertise some kind of remuneration. Try to determine the going rate for evaluation participants in your local area.
You will usually pay a modest hourly fee (e.g., about a dollar above minimum wage for an off-the-street volunteer). Expert participants cost more, depending on your specialized requirements. Do not try to get by too cheaply; you might get what you pay for.
Instead of or in addition to money, you can offer various kinds of premium gifts, such as coffee mugs with your company logo, gift certificates for local restaurants and shops, T-shirts proclaiming they survived your UX tests, free pizza, or even chocolate chip cookies! Sometimes just having a chance to learn about a new product before it is released or to help shape the design of some new technology is motivation enough.
14.7.4 Difficult-to-Find User Participants
Be creative in arranging for hard-to-find participant types. Sometimes, the customer—for whatever reasons—simply will not let the developer organization have access to representative users. The Navy, for example, can be rightfully hesitant about calling in its ships and shipboard personnel from the high seas to evaluate a system being developed to go on board.
Specialized roles (such as an ER physician) have time constraints that make if difficult, or impossible, to schedule them in advance. Sometimes you can have an “on call” agreement through which they call you if they have some free time and you do your best to work them in.
Sometimes when you cannot get a representative user, you can find a user representative, someone who is not exactly in the same role but who knows the role from some other angle. A domain expert is not necessarily the same as a user, but might serve as a participant, especially in an early evaluation cycle. We once were looking for a particular kind of agent of an organization who worked with the public, but had to settle, at least at the beginning, for supervisors of those agents.
14.7.5 Recruiting for Co-Discovery
Consider recruiting pairs of participants specifically for co-discovery evaluation. Your goal is to find people who will work well together during evaluation and, as a practical matter, who are available at the same time. We have found it best not to use two people who are close friends or who work together on a daily basis; such close relationships can lead to too much wise-cracking and acting out.
In extreme cases, you might find two participants who are friends or work together who exemplify a kind of “married couple” phenomenon. They finish each other’s sentences and much of their communication is implicit because they think alike. This is likely to yield less useful think-aloud data for you.
Look for people whose skills, work styles, and personality traits complement each other. Sometimes this is a good place to give them the Myers–Briggs test (Myers et al., 1998) for collaborative personality types.
14.7.6 Manage Participants as Any Other Valuable Resource
Once you have gone through the trouble and expense to recruit participants, do not let the process fail because a participant forgot to show up. Devise a mechanism to manage participant contact to keep in touch, remind in advance of appointments, and to follow up, if useful, afterward.
You need a standard procedure, and fool-proof way to remind you to follow it, for calling your participants in advance to remind them of their appointment, just as they do in doctor’s offices. No-show participants cost money in unused lab facilities, frustration in evaluators, wasted time in rescheduling, and delays in the evaluation schedule.
14.7.7 Select Participants for Subsequent Iterations
A question that commonly arises is whether you should use the same participants for more than one cycle of formative evaluation. Of course you would not use a repeat participant for tasks addressing an “initial use” UX attribute.
But sometimes reusing a participant (maybe one out of three to five) can make sense. This way, you can get a reaction to design changes from the previous cycle, in addition to a new set of data on the modified design from the two new participants. Calling on a previously used participant tells them you value their help and gives them a kind of empowerment, a feeling that they are helping to make a difference in your design.
14.8 Prepare for participants
14.8.1 Lab and Equipment
If you are planning lab-based evaluation, the most obvious aspect of preparation is to have the lab available and configured for your needs. If you plan to use specialized equipment, such as for physiological measurement, you also need to have that set up and an expert scheduled to operate it.
If you plan to collect quantitative UX data, prepare by having the right kind of timers on hand, from simple stopwatches to instrumented software for automatically extracting timing data. You can also get high-precision timing data from video recordings of the session (Vermeeren et al., 2002).
Using video to compute timing originated with the British data collection system called DRUM (Macleod & Rengger, 1993). DRUM was the tool support for the larger usability evaluation methodology called MUSiC (Macleod et al., 1997). Today, most software available to control and analyze digital video streams (e.g., TechSmith’s Morae) can do this routinely. As part of your post-session processing, you just tag the start and end of task performance in the video stream and the elapsed time is computed directly.
A Modern UX Lab at Bloomberg LP
Bloomberg LP, a leader in financial informatics, unveiled a modern UX evaluation lab in 2011. We describe some of the main features of the lab in this sidebar.
The lab has two areas—a participant room and an observation room—separated by a one-way mirror. Each has an independent entrance. The participant room has a multi-monitor workstation on which Bloomberg’s desktop applications are evaluated. The following photos depict a formative evaluation session in progress at this station.


On the other side of this participant room, another station is designed for evaluations with paper prototypes or mobile devices. In the following photo we show a formative evaluation session using paper prototypes where the facilitator (left) is responding to the actions of the participant (center) as the note taker (right) observes.

In the photos that follow, we show the same station being used to evaluate a mobile prototype (left). The photo on the right shows a close-up of the mobile device holder with a mounted camera. This setup allows the participant to hold and move the mobile device as she interacts while allowing a full capture of the user interface and her actions using the mounted camera.


The following photos are views of the observation room. This room is kept dark to prevent people in the participant room from seeing through. The lab is set up to pipe up to five selections of the seven video sources and four screen capture sources from the participant room to the large screens seen at the top in the observation room.
In the photo on the left you can see the participant room showing through the one-way mirror. In this photo we see stakeholders observing and tagging the video stream of the ongoing evaluation at four different stations.
In the photo on the right, you can see a view of the evaluation using the mobile prototype. Note on the left-hand screen above a close-up view of the evaluation from the overhead camera. The feed from the camera mounted on the mobile device holder is not shown in this photo.


This UX lab has been instrumental in defining the interaction designs of Bloomberg’s flagship desktop and mobile applications. Special thanks to Shawn Edwards, the CTO; Pam Snook; and Vera Newhouse at Bloomberg L.P. for providing us these lab photos.
14.8.2 Session Parameters
Evaluators must determine protocol and procedures for conducting the testing—exactly what will happen and for how long during an evaluation session with a participant.
Task and session lengths
The typical length of time of evaluation session for one participant is anywhere from 30 minutes to 4 hours. However, most of the time you should plan on an average session length of 2 hours or less.
However, some real-world UX evaluation sessions can become a day-long experience for a participant. The idea is to get as much as possible from each user without burning him or her out.
If you require sessions longer than a couple of hours, it will be more difficult for participants. In such cases, you should:
![]() Prepare participants for possible fatigue in long sessions by warning them in advance.
Prepare participants for possible fatigue in long sessions by warning them in advance.
![]() Mitigate fatigue by scheduling breaks between tasks, where participants can get up and walk around, leave the participant room, get some coffee or other refreshment, and even run screaming back home.
Mitigate fatigue by scheduling breaks between tasks, where participants can get up and walk around, leave the participant room, get some coffee or other refreshment, and even run screaming back home.
![]() Have some granola bars and/or fruit available in case hunger becomes an issue.
Have some granola bars and/or fruit available in case hunger becomes an issue.
![]() Always have water, and possibly other beverages, on hand to assuage thirst from the hard work you are putting them through.
Always have water, and possibly other beverages, on hand to assuage thirst from the hard work you are putting them through.
Number of full lifecycle iterations
Just as a loose rule of thumb from our experience, the typical number of full UX engineering cycle iterations per version or release is about three, but resource constraints often limit it to fewer iterations. In many projects you can expect only one iteration. Of course, any iterations are better than none.
14.8.3 Informed Consent
As practitioners collecting empirical data involving human subjects, we have certain legal and ethical responsibilities. There are studies, of course, in which harm could come to a human participant, but the kinds of data collection performed during formative evaluation of an interaction design are virtually never of this kind.
Nonetheless, we have our professional obligations, which center on the informed consent form, a document to establish explicitly the rights of your participants and which also serves as legal protection for you and your organization. Therefore, you should always have all participants, anyone from who you collect data of any kind, sign an informed consent form regardless of whether data are collected in the lab, in the field, or anywhere else.
Informed consent permission application
Your preparation for informed consent begins with an application to your institutional review board (IRB), an official group within your organization responsible for the legal and ethical aspects of informed consent (see later). The evaluator or project manager should prepare an IRB application that typically will include:
![]() summary of the evaluation plan
summary of the evaluation plan
![]() statement of complete evaluation protocol
statement of complete evaluation protocol
![]() statement of exactly how human subjects will be involved
statement of exactly how human subjects will be involved
![]() your written subject/participant instructions
your written subject/participant instructions
Because most UX evaluation does not put participants at risk, the applications are usually approved without question. The details of the approval process vary by organization, but it can take up to weeks and can require changes in the documents. The approval process is based on a review of the ethical and legal issues, not the quality of the proposed evaluation plan.
Informed consent form
The informed consent form, an important part of your IRB application and an important part of your lab-based UX evaluation, is a requirement; it is not optional. The informed consent form is to be read and signed by each participant and states that the participant is volunteering to participate in your evaluation, that you are taking data that the participant helped generate, and that the participant gives permission to use data—usually with the provision that the participant’s name or identity will not be associated with data, that the participant understands the evaluation is in no way harmful, and that the participant may discontinue the session at any time. The consent form may also include non-disclosure requirements.
This form must spell out participant rights and what you expect the participants to do, even if there is overlap with the general instructions sheet. The form they sign must be self-standing and must tell the whole story.
Be sure that your informed consent form contains:
![]() a statement that the participant can withdraw anytime, for any reason, or for no reason at all
a statement that the participant can withdraw anytime, for any reason, or for no reason at all
![]() a statement of any foreseeable risks or discomforts
a statement of any foreseeable risks or discomforts
![]() a statement of any benefits (e.g., educational benefit or just the satisfaction of helping make a good design) or compensation to participants (if there is payment, state exactly how much; if not, say so explicitly)
a statement of any benefits (e.g., educational benefit or just the satisfaction of helping make a good design) or compensation to participants (if there is payment, state exactly how much; if not, say so explicitly)
![]() a statement of confidentiality of data (that neither the name of the participant nor any other kind of identification will be associated with data after it has been collected)
a statement of confidentiality of data (that neither the name of the participant nor any other kind of identification will be associated with data after it has been collected)
![]() all project/evaluator contact information
all project/evaluator contact information
![]() a statement about any kind of recording (e.g., video, audio, photographic, or holodeck) involving the participant you plan to make and how you intend to use it, who will view it (and not), and by what date it will be erased or otherwise destroyed
a statement about any kind of recording (e.g., video, audio, photographic, or holodeck) involving the participant you plan to make and how you intend to use it, who will view it (and not), and by what date it will be erased or otherwise destroyed
![]() a statement that, if you want to use a video clip (for example) from the recording for any other purpose, you will get their additional approval in writing
a statement that, if you want to use a video clip (for example) from the recording for any other purpose, you will get their additional approval in writing
An example of a simple informed consent form is shown in Figure 14-2.


Figure 14-2 Sample informed consent form for participants.
Informed consent may or may not also be required in the case where your participants are also organization employees. In any case you should have two copies of the consent form ready for reading and signing by participants when they arrive. One copy is for the participant to keep.
14.8.4 Other Paperwork
General instructions
In conjunction with developing evaluation procedures, you, as the evaluator, should write introductory instructional remarks that will be read uniformly by each participant at the beginning of the session. All participants thereby start with the same level of knowledge about the system and the tasks they are to perform. This uniform instruction for each participant will help ensure consistency across the test sessions.
These introductory instructions should explain briefly the purpose of the evaluation, tell a little bit about the system the participant will be using, describe what the participant will be expected to do, and the procedure to be followed by the participant. For example, instructions might state that a participant will be asked to perform some benchmark tasks that will be given by the evaluator, will be allowed to use the system freely for awhile, then will be given some more benchmark tasks, and finally will be asked to complete an exit questionnaire.
In your general instructions to participants, make it clear that the purpose of the session is to evaluate the system, not to evaluate them. You should say explicitly “You are helping us evaluate the system—we are not evaluating you!” Some participants may be fearful that if somehow their performance is not up to “expectations,” participation in this kind of test session could reflect poorly on them or even be used in their employment performance evaluations (if, for example, they work for the same organization that is designing the interface they are helping evaluate). They should be reassured that this is not the case. This is where it is important for you to reiterate your guarantee of confidentiality with respect to individual information and anonymity of data.
The instructions may inform participants that you want them to think aloud while working or, for example, may indicate that they can ask the evaluator questions at any time. The expected length of time for the evaluation session, if known (the evaluator should have some idea of how long a session will take after performing pilot testing), should also be included. Finally, you should always say, clearly and explicitly, that the participant is free to leave at any time.
Print out and copy the general instructions so that you can give one to each participant.
Non-disclosure Agreements (NDAs)
Sometimes an NDA is required by the developer or customer organizations to protect the intellectual property contained in the design. If you have an NDA, print out copies for reading, signing, and sharing with the participant.
Questionnaires and surveys
If your evaluation plan includes administration of one or more participant questionnaires, make sure that you have a good supply available. It is best to keep blank questionnaires in the control room or away from where a newly arriving participant could read them in advance.
Data collection forms
Make up a simple data collection form in advance. Your data collection form(s) should contain fields suitable for all types of quantitative data you collect and, probably separate, data collection forms for recording critical incidents and UX problems observed during the sessions. The latter should include spaces for the kind of supplementary data you like to keep, including associated task, effect on user (e.g., minor or task-blocking), guidelines involved, potential cause of problem in design, relevant designer knowledge (e.g., how it was supposed to work), etc. Keep your data collection forms simple and easy to use on the fly. Consider a spreadsheet form on a laptop.
14.8.5 Training Materials
Use training materials for participants only if you anticipate that a user’s manual, quick reference cards, or any sort of training material will be available to and needed by users of the final system. If you do use training materials in evaluation, make the use of these materials explicit in the task descriptions.
If extensive participant training is required, say for an experienced participant role, it should have been administered in advance of evaluation. In general, training the user how to use a system during the evaluation session must be avoided unless you are evaluating the training. If the materials are used more as reference materials than training materials, participants might be given time to read any training material at the beginning of the session or might be given the material and told they can refer to it, reading as necessary to find information as needed during tasks. The number of times participants refer to the training material, and the amount of assistance they are able to obtain from the material, for example, can also be important data about overall UX of the system.
14.8.6 Planning Room Usage
As part of the evaluation plan for each major set of evaluation sessions, you need to document the configurations of rooms, equipment connections, and evaluator roles plus the people in these roles. Post diagrams of room and equipment setups so you do not have to figure this out at the last minute, when participants are due to arrive.
14.8.7 Ecological Validity in Your Simulated Work Context
Ecological Validity
Ecological validity refers to the realism with which a design of evaluation setup matches the user’s real work context. It is about how accurately the design or evaluation reflects the relevant characteristics of the ecology of interaction, i.e., its context in the world or its environment.
Thomas and Kellogg (1989) were among the first to warn us of the need for realistic contextual conditions in usability testing. If an element of work or usage context could not be addressed in the usability lab, they advised us to leave the lab and seek other ways to assess these ecological concerns. The challenge is to ensure that usability evaluation conditions reflect real-world usage conditions well enough to evoke the corresponding kinds of user performance and behavior. Your response to this challenge is especially important if you are addressing issues beyond the usual UX concepts to the full user experience and the out-of-the-box experience.
How do you know what you need for ecological validity? Usage or design scenarios are a good source of information about props and roles needed for tasks. Does your service agent user talk with a person through a hole in a glass panel or across a desk sitting down? Do they talk with patients, clients, or customers on the telephone? How does holding a telephone affect simultaneous computer task performance? Have your props and task aids ready at hand when the sessions begin.
One interesting “far-out” example of a prop for ecological validity is the “third age suit” developed at Loughborough University and used by architects, automobile designers, and others whose users include older people. The suit is like an exoskeleton of Velcro and stiff material, limiting mobility and simulating stiffness, osteoarthritis, and other confining and restricting conditions. New designs can be evaluated with this prop to appreciate their usability by older populations.
The early A330 Airbus—An example of the need for ecological validity in testing
We experienced a real-world example of a product that could have benefited enormously from better ecological validity in its testing. We traveled in an A330 Airbus airplane when that model first came out; our plane was 1 week old. (Advice: for many reasons, do not be the first to travel in a new airplane design.) We were told that a human-centered approach was taken in the A330 Airbus design, including UX testing of buttons, layout, and so on of the passenger controls for the entertainment system. Apparently, though, they did not do enough in situ testing. Each passenger had a personal viewing screen for movies and other entertainment, considered an advantage over the screens hanging from the ceiling. The controls for each seat were more or less like a TV remote control, only tethered with a “pull-out” cord. When not in use, the remote control snapped into a recessed space on the seat arm rest. Cool, eh?
The LCD screen had nice color and brightness but a low acceptable viewing angle. Get far off the axis (away from perpendicular to the screen) and you lose all brightness and, just before it disappears altogether, you see the picture as a color negative image. But the screen is right in front of you, so no problem, right? Right, until in a real flight the person in front of you tilts back the seat. Then we could barely see it. We could tell it was affecting others, too, because we could see many people leaning their heads down into an awkward position just to see the screen. After a period of fatigue, many people gave up, turned it off, and leaned back for comfort. If the display screen was used in UX testing, and we have to assume it was, the question of tilting the seat never entered the discussion, probably because the screen was propped up on a stand in front of each participant in the UX lab. Designers and evaluators just did not think about passengers in front of screen users tilting back their seats. Testing in a more realistic setting, better emulating the ecological conditions of real flight, would have revealed this major flaw.
It does not end there. Once the movie got going, most people stowed the remote control away in the arm rest. But, of course, what do you also rest on an arm rest? Your arm. And in so doing, it was easy to bump a button on the control and make some change in the “programming.” The design of this clever feature almost always made the movie disappear at a crucial point in the plot. And because we were syncing our movie viewing, the other one of us had to pause the movie while the first one had to go back through far too many button pushes to get the movie back and fast-forwarded to the current place.
It still does not end here. After the movie was over (or for some viewers, after they gave up) and we wanted to sleep, a bump of the arm on the remote caused the screen to light up brightly, instantly waking us to the wonderful world of entertainment. The flight attendant in just 1 week with this design had already come up with a creative workaround. She showed us how to pull the remote out on its cord and dangle it down out of the way of the arm rest. Soon, and this is the UX-gospel truth, almost everyone in the plane had a dangling remote control swinging gracefully in the aisle like so many synchronized reeds in the breeze as the plane moved about on its course. All very reminiscent of a wonderful Gary Larson cartoon showing a passenger sitting in flight. Among the entertainment controls on his arm rest is one switch, labeled “Wings stay on” and “Wings fall off.” The caption reads, “Fumbling for his recline button, Ted unwittingly instigates a disaster.”
The Social Security Administration (SSA) Model District Office (MDO)—An extreme and successful example
In the mid-1990s we worked extensively with the SSA in Baltimore, mainly in UX lifecycle training. A system we worked with there is used by a public service agent who serves clients, people who walk in off the street or call on the phone. The agent is the user, but the clients are essential to usage ecology; client needs provide the impetus for the user to act, the need for a system task. For evaluation then, they need people to act as clients, perhaps using scripts that detail the services needed, which then drive the computer-based tasks of the agent. And they need telephones and/or “offices” into which clients can come for service.
We worked with a small group pioneering the introduction of usability engineering techniques into an “old school,” waterfall-oriented, mainframe software development environment. Large Social Security systems were migrating slowly from mainframes (in Baltimore) plus terminals (by the thousands over the country) to client–server applications, some starting to run on PCs, and they wanted UX to be a high priority. Sean Wheeler was the group spark plug and UX champion, strongly supported by Annette Bryce and Pat Stoos.
What impressed us the most about this organization was their Model District Office. A decade earlier, as part of a large Claims Modernization Project, a program of system design and training to “revolutionize the way that SSA serves the public,” they had built a complete and detailed model of a Social Security Administration district office from middle America right in the middle of SSA headquarters building in Baltimore. The MDO, with its carpeting, office furniture, and computer terminals, right down to the office lamps and pictures on the wall, was indistinguishable from a typical agency office in a typical town. They brought in real SSA employees from field offices from all over the United States to sit in the MDO to pilot and test new systems and procedures.
When SSA was ready to focus on UX, the MDO provided a perfect evaluation environment; simply put, it was an extreme and successful example of leveraging ecological validity for application development and testing, as well as for user training. In the end, the group created a UX success story upstream against the inertia and enormous weight of the rest of the organization and ended up winning a federal award for the quality of their design!
As a testament to their seriousness about ecological validity and UX, the SSA was spending about $1 million a year to bring employees in to stay and work at the MDO, sometimes for a few months at a time. Their cost justification calculations proved the activity was saving many times more.
14.8.8 The UX Evaluation Session Work Package
To summarize, as you do the evaluation preparation and planning described in this chapter, you need to gather your evaluation session work package, all the materials you will need in the evaluation session. Bring this evaluation session work package to each evaluation session.
Examples of package contents include:
![]() The evaluation configuration plan, including diagrams of rooms, equipment, and people in evaluation roles
The evaluation configuration plan, including diagrams of rooms, equipment, and people in evaluation roles
![]() Informed consent forms, with participant names and date entered
Informed consent forms, with participant names and date entered
![]() All questionnaires and surveys, including any demographic survey
All questionnaires and surveys, including any demographic survey
![]() All printed benchmark task descriptions, one task per sheet of paper
All printed benchmark task descriptions, one task per sheet of paper
![]() All printed unmeasured task descriptions (these can be listed several to a page)
All printed unmeasured task descriptions (these can be listed several to a page)
![]() For each evaluator, a print out (or laptop version) of the UX targets associated with the day’s sessions
For each evaluator, a print out (or laptop version) of the UX targets associated with the day’s sessions
![]() All data collection forms, on paper or on laptops
All data collection forms, on paper or on laptops
![]() Any props needed to support tasks
Any props needed to support tasks
![]() Any training materials to be used as part of the evaluation
Any training materials to be used as part of the evaluation
![]() Any compensation to be given out (e.g., money, gift cards, T-shirts, coffee mugs, used cars)
Any compensation to be given out (e.g., money, gift cards, T-shirts, coffee mugs, used cars)
![]() Any special instructions to watch out for particular parts of the design, evaluation scripts, things to do before each participant session (e.g., to reset browser caches so that no auto complete entries from previous participant’s session interferes with the current session), etc.
Any special instructions to watch out for particular parts of the design, evaluation scripts, things to do before each participant session (e.g., to reset browser caches so that no auto complete entries from previous participant’s session interferes with the current session), etc.
Why should benchmark tasks be printed just one per sheet of paper? What about the trees? We want our participants to focus on just the task at hand. If you give them descriptions of additional tasks, they will read them prematurely and distract themselves by thinking about those, too. It is just human nature. You need to control their mental focus.
Also, focusing on the participant, it is possible that not all participants will complete all tasks. There is no need for anyone to see that they have not accomplished them all. If they see only one at a time, they will never know and never feel bad.
Exercise
See Exercise 14-1, Formative UX Evaluation Preparation for Your System
14.9 Do final pilot testing: fix your wobbly wheels
If your UX evaluation plan involves using a prototype, low or high fidelity, make sure it is robust before you do anything more to prepare for your UX evaluation, regardless of whether your evaluation is lab based. If the evaluation team has not yet performed thorough pilot testing of the product or prototype, now is the time to give it a final shakedown. Exercise the prototype thoroughly. Pilot testing is essential to remove any major weaknesses in the prototype and any “show stopper” problems.
You need to be confident that the prototype will not “blow up” unceremoniously the first time it is brought into the proximity of real user participants. It is embarrassing to have to apologize and dismiss a participant because the hardware or software wheels came off during an evaluation session. And, because good representative participants may be hard to find, you do not want to add to your time and expense by “burning” user participants unnecessarily.
While pilot testing of the prototype may be obvious to prepare for lab-based testing, it is similarly important prior to critical reviews and UX inspections by outside human–computer interaction (HCI) experts. These experts do not work for free, and you will not want things going amiss during a session, causing delays while a hefty hourly fee is being paid for expert advice.
In addition to shaking down your prototype, think of your pilot testing as a dress rehearsal to be sure of your lab equipment, benchmark tasks, procedures, and personnel roles:
![]() Make sure all necessary equipment is available, installed, and working properly, whether it be in the laboratory or in the field.
Make sure all necessary equipment is available, installed, and working properly, whether it be in the laboratory or in the field.
![]() Run through the evaluation tasks completely at least once using the intended hardware and software (i.e., the interface prototype) by someone other than the person(s) who created the task descriptions.
Run through the evaluation tasks completely at least once using the intended hardware and software (i.e., the interface prototype) by someone other than the person(s) who created the task descriptions.
![]() Make sure the prototype supports all the necessary user actions.
Make sure the prototype supports all the necessary user actions.
![]() Make sure the participant instructions and benchmark task descriptions are worded clearly and unambiguously.
Make sure the participant instructions and benchmark task descriptions are worded clearly and unambiguously.
![]() Make sure all session materials, such as any instruction sheets, the informed consent, and so on, are sufficient.
Make sure all session materials, such as any instruction sheets, the informed consent, and so on, are sufficient.
![]() Make sure that the metrics the benchmark tasks are intended to produce are practically measurable. Counting the number of tasks completed in either 5 seconds or 5 hours, for example, is not reasonable.
Make sure that the metrics the benchmark tasks are intended to produce are practically measurable. Counting the number of tasks completed in either 5 seconds or 5 hours, for example, is not reasonable.
![]() Be sure that everyone on the evaluation team understands his or her role.
Be sure that everyone on the evaluation team understands his or her role.
![]() Be sure that all the roles work together in the fast-paced events associated with user interaction.
Be sure that all the roles work together in the fast-paced events associated with user interaction.
14.10 More about determining the right number of participants
One of your activities in preparing for formative evaluation is finding appropriate users for the evaluation sessions. In formal summative evaluation, this part of the process is referred to as “sampling,” but that term is not appropriate here because what we are doing has nothing to do with the implied statistical relationships and constraints.
14.10.1 How Many Are Needed? A Difficult Question
How many participants are enough? This is one of those issues that some novice UX practitioners take so seriously and yet it is a question to which there is no definitive answer. Indeed, there cannot be one answer. It depends so much on the specific context and parameters of your individual situation that you have to answer this question for yourself each time you do formative evaluation.
There are studies that lead UX gurus to proclaim various rules of thumb, such as “three to five users are enough to find 80% of your UX problems,” but when you see how many different assumptions are used to arrive at those “rules” and how few of those assumptions are valid within your project, you realize that this is one place in the process where it is most important for you to use your own head and not follow vague generalizations.
And, of course, cost is often a limiting factor. Sometimes you just get one or two participants in each of one or two iterations and you have to be satisfied with that because it is all you can afford. The good news is that you can do a lot with only a few good participants. There is no statistical requirement for large numbers of “subjects” as there is for formal summative evaluation; rather, the goal is to focus on extracting as much information as possible from every participant.
14.10.2 Rules of Thumb Abound
There are bona fide studies that predict the optimum number of participants needed for UX testing under various conditions. Most “rules of thumb” are based empirically but, because they are quoted and applied so broadly without regard to the constraints and conditions under which the results were obtained, these rules have become among the most folklorish of folklore out there.
Nielsen and Molich (1990) had an early paper about the number of users/participants needed to find enough UX problems and found that 80% of their known UX problems could be detected with four to five participants, and the most severe problems were usually found with the first few participants. Virzi (1990, 1992) more or less confirmed Nielsen and Molich’s study.
Nielsen and Landauer (1993) found that detection of problems as a function of the number of participants is well modeled as a Poisson process, supporting the ability to use early results to estimate the number problems left to be found and the number of additional participants needed to find a certain percentage.
Depending on the circumstances, though, some say that even five participants is no way near enough (Hudson, 2001; Spool & Schroeder, 2001), especially for complex applications or large Websites. In practice, each of these numbers has proven to be right for some set of conditions, but the question is whether they will work for you in your evaluation.
14.10.3 An Analytic Basis for the Three to Five Users Rule
The underlying probability function
In Figure 14-3 you can see graphs, related to the binomial probability distribution, of cumulative percentages of problems likely to be found for a given number of participants used and at various detection rates, adapted from Lewis (1994).
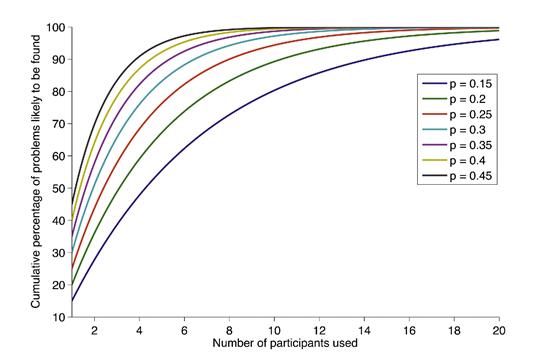
Figure 14-3 Graphs of cumulative percentages of problems likely to be found for a given number of participants used and at various detection rates
[adapted from Lewis (1994)].
Y-axis values in these curves are for “discovery likelihood,” expressed as a cumulative percentage of problems likely to be found, as a function of the number of participants or evaluators used. These curves are based on the probability formula:
discovery likelihood (cumulative percentage of problems likely to be found = 1– (1 – p)n, where n is the number of participants used (X-axis values) and p is what we call the “detection rate” of a certain category of participants.
As an example, this formula tells us that a sample size of five participant evaluators (n) with an individual detection rate (p) of at least 0.30 is sufficient to find approximately 80% of the UX problems in a system.
The old balls-in-an-urn analogy
Let us think of an interaction design containing flaws that cause UX problems as analogous to the old probability setting of an urn containing various colored balls. Among an unknown number of balls of all colors, suppose there are a number of red balls, each representing a different UX problem.
Suppose now that a participant or evaluator reaches in and grabs a big handful of balls from the urn. This is analogous to an evaluation session using a single expert evaluator, if it is a UX inspection evaluation, or a single participant, if it is a lab-based empirical session. The number of red balls in that handful is the number of UX problems identified in the session.
In a UX inspection, it is the expert evaluator, or inspector, who finds the UX problems. In an empirical UX test, participants are a catalyst for UX problem detection—not necessarily detecting problems themselves but encountering critical incidents while performing tasks, enabling evaluators to identify the corresponding UX problems. Because the effect is essentially the same, for simplicity in this discussion we will use the term “participant” for both the inspector and the testing participant and “find problems” for whatever way the problems are found in a session.
Participant detection rates
The detection rate, p, of an individual participant is the percentage of existing problems that this participant can find in one session. This corresponds to the number of red balls a participant gets in one handful of balls. This is a function of the individual participant. For example, in the case of the balls in the urn, it might be related to the size of the participant’s hand. In the UX domain, it is perhaps related to the participant’s evaluation skills.
In any case, in this analysis, if a participant has a detection rate of p = 0.20, it means that this participant will find 20% of the UX problems existing in the design. The number of participants with that same individual detection rate who, in turn, reach into the urn is the value on the X axis. The curve shown with a green line is for a detection rate of p = 0.20. The other curves are for different detection rates, from p = 0.15 up to p = 0.45.
Most of the time we do not even know the detections rates of our participants. To calculate the detection rate for a participant, we would have to know how many total UX problems exist in a design. But that is just what we are trying to find out with evaluation. You could, we guess, run a testing session with the participant against a design with a certain number of known flaws. But that would tell you that participant’s detection rate for that day, in that context, and for that system. Unfortunately, a given participant’s detection rate is not constant.
Cumulative percentage of problems to be found
The Y axis represents values of the cumulative percentage of problems to be found. Let us look at this first for just one participant. The curve for p = 0.20, for example, has a Y axis value of 20%, for n = 1 (where the curve intersects the Y axis). This is consistent with our expectation that one participant with p = 0.20 will find 20% of the problems, or get 20% of the red balls, in the first session.
Now what about the “cumulative” aspect? What happens when the second participant reaches into the urn depends on whether you replaced the balls from the first participant. This analysis is for the case where each participant returns all the balls to the urn after each “session”; that is, none of the UX problems are fixed between participants.
After the first participant has found some problems, there are fewer new problems left to find by the second participant. If you look at the results with the two participants independently, they each help you find a somewhat different 20% of the problems, but there is likely to be overlap, which reduces the cumulative effect (the union of the sets of problems) of the two.
This is what we see in the curves of Figure 14-3 as the percentage of problems likely to be found drops off with each new participant (moving to the right on the X axis) because the marginal number of new problems found is decreasing. That accounts for the leveling off of the curves until, at some high number of participants, essentially no new problems are being found and the curve is asymptotically flat.
Marginal added detection and cost–benefit
One thing we do notice in the curves of Figure 14-3 is that, despite the drop-off of effective detection rates, as you continue to add more participants you will continue to uncover more problems. At least for a while. Eventually, high detection rates coupled with high numbers of participants will yield results that asymptotically approach about 100% in the upper right-hand part of the figure and virtually no new problems will be found with subsequent participants.
But what happens along the way? Each new participant helps you find fewer new problems, but because the cost to run each participant is about the same, with each successive participant the process becomes less efficient (fewer new problems found for the same cost).
As a pretty good approximation of the cost to run a UX testing session with n participants, you have a fixed cost to set up the session plus a variable cost (or cost per participant) = a + bn. The benefit of running a UX testing session with n participants is the discovery likelihood. So the cost benefit is the ratio benefit/cost, each as a function of n, or benefit/cost = (1– (1 – pn)/ (a + bn).
If you graph this function (with some specific values of a and b) against n = 1, 2, … , you will see a curve that climbs for the first few values of n and then starts dropping off. The values of n around the peak of cost–benefit are the optimum (from a cost–benefit perspective) number of participants to use. The range of n for which the peak occurs depends on parameters a, b, and p of your setup; your smileage can vary.
Nielsen and Landauer (1993) showed that real data for both UX inspections and lab-based testing with participants did match this mathematical cost–benefit model. Their results showed that, for their parameters, the peak occurred for values of n around 3 to 5. Thus, the “three to five users” rule of thumb.
Assumptions do not always apply in the real world
This three-to-five users rule, with its tidy mathematical underpinning, can and does apply to many situations similar to the conditions Nielsen and Landauer (1993) used, and we believe their analysis brings insight into the discussion. However, we know there are many cases where it just does not apply.
For starters, all of this analysis, including the analogy with the balls-in-an-urn setting, depends on two assumptions:
If UX problems were balls in an urn, our lives would be simpler. But neither of these assumptions is true and the UX life is not simple.
Assumptions about detection rates. Each curve in Figure 14-3 is for a fixed detection rate and the cost–benefit calculation given earlier was based on a fixed detection rate, p. But the “evaluator effect” tells us not only will different evaluators find different problems, but it tells us that even the detection rate can vary widely over participants (Hertzum & Jacobsen, 2003).
In fact, a given individual does not even have a fixed “individual detection rate”; it can be influenced from day to day or even from moment to moment by how rested the participant is, blood caffeine and ethanol levels, attitude, the system, how the evaluators conduct the evaluation, what tasks are used, the evaluator’s skills, and so on.
Also, what does it really mean for a testing participant to have a detection rate of p = 0.20? How long does it take in a session for that participant to achieve that 20% discovery? How many tasks? What kinds of tasks? What if that participant continues to perform more tasks? Will no more critical incidents be encountered after 20% detection is achieved?
Assumptions about problem detectability. The curves in Figure 14-3 are also based on an assumption that all problems are equally detectable (like all red balls in the urn are equally likely to be drawn out). But, of course, we know that some problems are almost obvious on the surface and other problems can be orders of magnitude more difficult to ferret out. So detectability, or likelihood of being found, can vary dramatically across various UX problems.
Task selection. One reason for the overlap in problems detected from one participant to another, causing the cumulative detection likelihood to fall off with additional participants, as it does in Figure 14-3, is the use of prescribed tasks. Participants performing essentially the same sets of tasks are looking in the same places for problems and are, therefore, more likely to uncover many of the same problems.
However, if you employ user-directed tasks (Spool & Schroeder, 2001), participants will be looking in different places and the overlap of problems found could be much less. This keeps the benefit part of the curves growing linearly for more participants, causing your optimum number of participants to be larger.
Application system effects. Another factor that can torpedo the three-to-five users rule is the application system being evaluated. Some systems are very much larger than others. For example, an enormous Website or a large and complex word processor will harbor many more possibilities for UX problems than, say, a simple inter-office scheduling system. If each participant can explore only a small portion of such an application, the overlap of problems among participants may be insignificant. In such cases the cost–benefit function will peak with many more participants than three to five.
You have to settle for a sensible approach with a practical outcome
Okay, so what is the answer? What is the best number of participants to use in testing? Our friend Jim Foley’s answer to any HCI question was never more appropriate than it is here: It depends! It takes as many participants as it takes for your situation, your application, your design, your resources, and your goals.
You have to decide for yourself every time you do UX testing—how many participants can you afford. You cannot compute and graph all the curves we have been talking about because you will never know how many UX problems exist in the design so you will never know what percentage of the existing problems you have found. You do not have to use those curves, anyway, to have a pretty good intuitive feeling for whether you are still detecting useful new problems with each new participant. Look at the results from each participant and each iteration and ask if those results were worth it and whether it is worth investing a little more. Based on how much time and money you can afford and how easily you can recruit participants, use your UX practitioner thinking skills and ask yourself, do you feel lucky? Huh? Do you think there are more reasonably significant UX problems still out there that you can still find and fix and thereby improve the product? Then go ahead; make the UX practitioner’s day—iterate.