
Chapter 13
Rapid Evaluation Methods
Objectives
After reading this chapter, you will:
1. Understand design walkthroughs, demonstrations, and reviews as early rapid evaluation methods
2. Understand and apply inspection techniques for user experience, such as heuristic evaluation
3. Understand and apply rapid lab-based UX evaluation methods, such as RITE and quasi-empirical evaluation
4. Know how to use questionnaires as a rapid UX evaluation method
5. Appreciate the trade-offs involved with “discount” formative UX evaluation methods
13.1 Introduction
13.1.1 You Are Here
We begin each process chapter with a “you are here” picture of the chapter topic in the context of the overall Wheel lifecycle template; see Figure 13-1. This chapter, about rapid UX evaluation methods, is a very important side excursion along the way to the rest of the fully rigorous evaluation chapters.
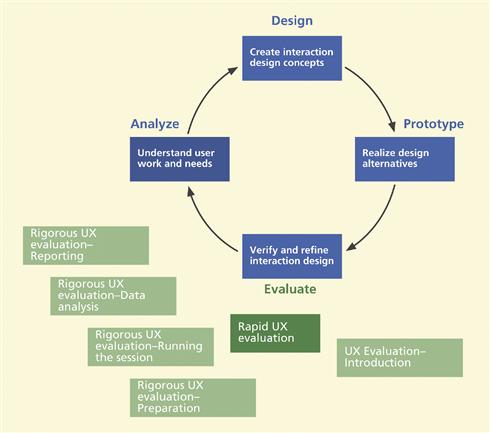
Figure 13-1 You are here, the chapter on rapid evaluation, within the evaluation activity in the context of the overall Wheel lifecycle template.
Some projects, especially large domain-complex system projects, require the rigorous lab-based UX evaluation process (Chapters 14 through 17). However, many smaller fast-track projects, including those for developing commercial products, often demand techniques that are faster and less costly than lab-based evaluation in the hope of achieving much of the effectiveness but at a lower cost. We call these techniques “rapid” because they are about being fast, which means saving cost.
Here are some of the general characteristics of rapid evaluation methods:
![]() Rapid evaluation techniques are aimed almost exclusively at finding qualitative data—finding UX problems that are cost-effective to fix.
Rapid evaluation techniques are aimed almost exclusively at finding qualitative data—finding UX problems that are cost-effective to fix.
![]() Seldom, if ever, is attention given to quantitative measurements.
Seldom, if ever, is attention given to quantitative measurements.
![]() There is a heavy dependency on practical techniques, such as the “think-aloud” technique.
There is a heavy dependency on practical techniques, such as the “think-aloud” technique.
![]() Everything is less formal, with less protocol and fewer rules.
Everything is less formal, with less protocol and fewer rules.
![]() There is much more variability in the process, with almost every evaluation “session” being different, tailored to the prevailing conditions.
There is much more variability in the process, with almost every evaluation “session” being different, tailored to the prevailing conditions.
![]() This freedom to adapt to conditions creates more room for spontaneous ingenuity, something experienced practitioners do best.
This freedom to adapt to conditions creates more room for spontaneous ingenuity, something experienced practitioners do best.
In early stages of a project you will have only your conceptual design, scenarios, storyboards, and maybe some screen sketches or wireframes—usually not enough for interacting with customers or users. Still, you can use an informal rapid evaluation method to get your design on track. You can use interaction design demonstrations, focus groups, or walkthroughs where you do the driving.
Think-Aloud Technique
The think aloud technique is a qualitative data collection technique in which user participants verbally externalize their thoughts about their interaction experience, including their motives, rationale, and perceptions of UX problems. By this method, participants give the evaluator access to an understanding of their thinking about the task and the interaction design.
Beyond these early approaches, when you have an interactive prototype—either a low-fidelity paper prototype or a medium-fidelity or high-fidelity prototype—most rapid evaluation techniques are abridged variations of what have generally been known as inspection techniques or of the lab-based approach. If you employ participants, engage in a give and take of questions and answers, comments, and feedback. In addition, you can be proactive with prescripted interview questions, which you can ask in a kind of structured think-aloud data-gathering technique during or after a walkthrough.
Very few practitioners or teams today use any one “pure” rapid evaluation method; they adapt and combine to suit their own processes, schedules, and resource limitations. We highlight some of the most popular techniques, the suitability of which for your project depends on your design and evaluation context. Inspection is probably the primary rapid evaluation technique, but quasi-empirical methods, abridged versions of lab-based evaluation, are also very popular and effective.
Inspection (UX)
A UX inspection is an analytical evaluation method in which a UX expert evaluates an interaction design by looking at it or trying it out, sometimes in the context of a set of abstracted design guidelines. Expert evaluators are both participant surrogates and observers, asking themselves questions about what would cause users problems and giving an expert opinion predicting UX problems.
Quasi-Empirical Evaluation
Quasi-empirical UX evaluation methods are empirical because they involve taking some kind of data using volunteer participants, but they are quick and dirty versions of empirical methods, being very informal and not following a strict protocol. Quasi-empirical methods focus on qualitative data to identify UX problems that can be fixed and usually do not involve quantitative data.
13.2 Design walkthroughs and reviews
A design walkthrough is an easy and quick evaluation method that can be used with almost any stage of progress but which is especially effective for early interaction design evaluation before a prototype exists (Bias, 1991). Memmel, Gundelsweiler, and Reiterer (2007, Table 8) declare that user and expert reviews are less time-consuming and more cost-effective than participant-based testing and that their flexibility and scalability mean the effort can be adjusted to match the needs of the situation. Even early lab-based tests can include walkthroughs (Bias, 1991). Sometimes the term is used to refer to a more comprehensive team evaluation, more like a team-based UX inspection.
Who is involved? Design walkthroughs usually entail a group working collaboratively under the guidance of a leader. The group can include the design team, UX analysts, subject-matter experts, customer representatives, and potential users.
The goal of a design walkthrough is to explore a design on behalf of users to simulate the user’s view of moving through the design, but to see it with an expert’s eye. The team is trying to anticipate problems that users might have if they were the ones using the design.
What materials do you need upfront? You should prepare for a design walkthrough by gathering at least these items:
![]() Design representation(s), including storyboards, screen sketches, illustrated scenarios (scenario text interspersed with storyboard frames and/or screen sketches), paper prototypes, and/or higher fidelity prototypes
Design representation(s), including storyboards, screen sketches, illustrated scenarios (scenario text interspersed with storyboard frames and/or screen sketches), paper prototypes, and/or higher fidelity prototypes
![]() Descriptions of relevant users, work roles, and user classes
Descriptions of relevant users, work roles, and user classes
Here is how it works. It is usually more realistic and engaging to explore the design through the lens of usage or design scenarios. The leader walks the group through key workflow patterns that the system is intended to support. A characteristic that distinguishes design walkthroughs from various kinds of user-based testing is that the practitioner in charge does the “driving” instead of the customer or users.
As the team follows the scenarios, looking systematically at parts of the design and discussing the merits and potential problems, the leader tells stories about users and usage, user intentions and actions, and expected outcomes. The leader explains what the user will be doing, what the user might be thinking, and how the task fits in the work practice, workflow, and context. As potential UX problems arise, someone records them on a list for further consideration.
Walkthroughs may also include considerations of compliance with design guidelines and style guides as well as questions about emotional impact, including aesthetics and fun. Beyond just the details of UX and other design problems that might emerge, it is a good way to communicate about the design and keep on the same page within the project.
13.3 UX Inspection
When we use the term “UX inspection,” we are aware that you cannot inspect UX but must inspect a design for user experience issues. However, because it is awkward to spell it out that way every time, we use “UX inspection” as a short-hand for the longer phrase. As an analogy, if you hire someone to do a safety inspection of your house, you want them to “inspect the house for safety issues” just as we want a UX inspection to be an inspection of the design for user experience issues. This is consistent with our explanation of how we use the term “UX” in a broader denotation than that of the term “user experience.”
UX
“UX” is an almost ubiquitous term that we use to refer to most things that have to do with designing for a high quality user experience. So this means we will use terms like the UX field, UX work, a UX practitioner, the UX team, the UX role, UX design or UX design process.
13.3.1 What Is UX Inspection?
A UX inspection is an “analytical” evaluation method in that it involves evaluating by looking at and trying out the design yourself as a UX expert instead of having participants exercise it while you observe. Here we generalize the original concept of usability inspection to include inspection of both usability characteristics and emotional impact factors and we call it UX inspection.
The evaluator is both participant surrogate and observer. Inspectors ask themselves questions about what would cause users problems. So, the essence of these methods is the inspector giving an expert opinion predicting UX problems.
Because the process depends on the evaluator’s judgment, it requires an expert, a UX practitioner or consultant, which is why this kind of evaluation method is also sometimes called “expert evaluation” or “expert inspection.” These evaluation methods are also sometimes called “heuristic evaluation (HE)” but that term technically applies only to one particular version, “the heuristic evaluation method” (Nielsen, 1994b), in which “heuristics” or generalized design guidelines are used to drive an inspection (see later).
Heuristic
A heuristic is an informal maxim, rule of thumb, or generalized guideline about interaction design.
Heuristic Evaluation
A heuristic evaluation is a kind of UX evaluation involving expert inspection guided by a set of heuristics.
13.3.2 Inspection Is a Valuable Tool in the UX Toolbox
Not all human–computer interaction (HCI) literature is supportive of inspection as an evaluation tool, but practitioners in the field have been using it for years with great success. In our own practice, we definitely find value in inspection methods and highly recommend their use in cases (for example):
![]() Where they are applied in early stages and early design iterations. It is an excellent way to begin UX evaluation and pick the low-hanging fruit and clear out the mass of obvious problems.
Where they are applied in early stages and early design iterations. It is an excellent way to begin UX evaluation and pick the low-hanging fruit and clear out the mass of obvious problems.
![]() Where you should save the more expensive and more powerful tools, such as lab-based testing, for later to dig out the more subtle and difficult problems. Starting with lab-based testing on an immature and quickly evolving design can be like using a precision shovel on a large snow drift.
Where you should save the more expensive and more powerful tools, such as lab-based testing, for later to dig out the more subtle and difficult problems. Starting with lab-based testing on an immature and quickly evolving design can be like using a precision shovel on a large snow drift.
![]() Where you have not yet done any other kind of evaluation. It is especially appropriate when you are brought in to evaluate an existing system that has not undergone previous UX evaluation and iterative redesign.
Where you have not yet done any other kind of evaluation. It is especially appropriate when you are brought in to evaluate an existing system that has not undergone previous UX evaluation and iterative redesign.
![]() Where you cannot afford or cannot do lab-based testing for some reason but still want to do some evaluation. UX inspection can still do a good job for you when you do not have the time or other resources to do a more thorough job.
Where you cannot afford or cannot do lab-based testing for some reason but still want to do some evaluation. UX inspection can still do a good job for you when you do not have the time or other resources to do a more thorough job.
13.3.3 How Many Inspectors Are Needed?
In lab-based UX testing, you can improve evaluation effectiveness by adding more participants until you get diminishing returns. Similarly, in UX inspection, to improve effectiveness you can add more inspectors. But does it help? Yes, for inspections, a team approach is beneficial, maybe even necessary, because low individual detection rates preclude finding enough problems by one person.
Experience has shown that different experts find different problems. But this diversity of opinion is valuable because the union of problems found over a group of inspectors is much larger than the set of problems found by any individual. Most heuristic inspections are done by a team of two or more usability inspectors, typically two or three inspectors.
But what is the optimal number? It depends on conditions and a great deal on the system you are inspecting. Nielsen and Landauer (1993) found that, under some conditions, a small set of experts, in the range of 3 to 5, is optimal before diminishing returns. See the end of Chapter 14 for further discussion about the “3 to 5 users” rule and its limitations. As with almost any kind of evaluation, some is better than none and, for early project stages, we often are satisfied with a single inspection by one or two inspectors working together.
13.3.4 What Kind of Inspectors Are Needed?
Not surprisingly, Nielsen (1992a) found that UX experts (practitioners or consultants) make the best inspection evaluators. Sometimes it is best to get a fresh view by using an expert evaluator who is not on the project team. If those UX experts also have knowledge in the subject-matter domain of the interface being evaluated, all the better. Those people are called dual experts and can evaluate through both a design guidelines perspective and a work activity, workflow, and task perspective. The equivalent of having a dual expert can be approximated by a team approach—pairing up a UX expert with a work domain expert.
13.4 Heuristic evaluation, a UX inspection method
13.4.1 Introduction to Heuristic Evaluation
For most development projects in the 1990s, the “default usability person,” the unqualified software developer pressed into usability service, was the rule. Few trained UX specialists actually worked in design projects. Now the default practitioner is slowly moving toward becoming the exception. As more people specifically prepared for the UX practitioner role became available, the definition of “novice evaluator” has shifted from the default practitioner who perhaps had an SE day job to a trained practitioner, just with less experience than an expert.
But in reality there still is, and will be for some time, a shortage of good UX practitioners, and the heuristic method is intended to help these novices perform acceptably good usability inspections. It has been described as a method that novices can grab onto and use without a great deal of training. The effectiveness of a rule-based method used by a novice, of course, cannot be expected to be on a par with a more sophisticated approach or by any approach used by an expert practitioner.
As Nielsen (1992a; Nielsen & Molich, 1990) states, the heuristic evaluation (HE) method has the advantages of being inexpensive, intuitive, and easy to motivate practitioners to do, and it is effective for use early in the UX process. Therefore, it is no surprise that of all the inspection methods, the HE method is the best known and the most popular. Another important point about the heuristics is that they teach the designers about criteria to keep in mind while doing their own designs so they will not violate these guidelines.
A word of caution, however: Although the HE method is popular and successful, there will always be some UX problems that show up in real live user-based interaction that you will not see in a heuristic, or any other, inspection or design review.
13.4.2 How-to-Do-It: Heuristic Evaluation
Heuristics
Following publication of the original heuristics, Nielsen (1994a) enhanced the heuristics with a study based on factor analysis of a large number of real usability problems. The resulting new heuristics (Nielsen, 1994b) are given in Table 13-1.
Table 13-1 Nielsen’s refined heuristics, quoted with permission from www.useit.com
| Visibility of System Status |
| The system should always keep users informed about what is going on through appropriate feedback within reasonable time. |
| Match Between System and The Real World |
| The system should speak the users’ language, with words, phrases, and concepts familiar to the user rather than system-oriented terms. Follow real-world conventions, making information appear in a natural and logical order. |
| User Control and Freedom |
| Users often choose system functions by mistake and will need a clearly marked “emergency exit” to leave the unwanted state without having to go through an extended dialogue. Support undo and redo. |
| Consistency and Standards |
| Users should not have to wonder whether different words, situations, or actions mean the same thing. Follow platform conventions. |
| Error Prevention |
| Even better than good error messages is a careful design that prevents a problem from occurring in the first place. Either eliminate error-prone conditions or check for them and present users with a confirmation option before they commit to the action. |
| Recognition Rather Than Recall |
| Minimize the user’s memory load by making objects, actions, and options visible. The user should not have to remember information from one part of the dialogue to another. Instructions for use of the system should be visible or easily retrievable whenever appropriate. |
| Flexibility and Efficiency of Use |
| Accelerators—unseen by the novice user—may often speed up the interaction for the expert user such that the system can cater to both inexperienced and experienced users. Allow users to tailor frequent actions. |
| Aesthetic and Minimalist Design |
| Dialogues should not contain information that is irrelevant or rarely needed. Every extra unit of information in a dialogue competes with the relevant units of information and diminishes their relative visibility. |
| Help Users Recognize, Diagnose, and Recover from Errors |
| Error messages should be expressed in plain language (no codes), indicate the problem precisely, and suggest a solution constructively. |
| Help and Documentation |
| Even though it is better if the system can be used without documentation, it may be necessary to provide help and documentation. Any such information should be easy to search, focused on the user’s task, list concrete steps to be carried out, and not be too large. |
The procedure
Despite the large number of variations in practice, we endeavor to describe what roughly represents the “plain” or “standard” version. These inspection sessions can take from a couple of hours for small systems to several days for larger systems. Here is how to do it:
![]() The project team or manager selects a set of evaluators, typically three to five.
The project team or manager selects a set of evaluators, typically three to five.
![]() The team selects a small, tractable set, about 10, of “heuristics,” generalized and simplified design guidelines in the form of inspection questions, for example, “Does the interaction design use the natural language that is familiar to the target user?” The set of heuristics given in the previous section are a good start.
The team selects a small, tractable set, about 10, of “heuristics,” generalized and simplified design guidelines in the form of inspection questions, for example, “Does the interaction design use the natural language that is familiar to the target user?” The set of heuristics given in the previous section are a good start.
![]() Each inspector individually browses through each part of the interaction design, asking the heuristic questions about that part:
Each inspector individually browses through each part of the interaction design, asking the heuristic questions about that part:
![]() assesses the compliance of each part of the design
assesses the compliance of each part of the design
![]() notes places where a heuristic is violated as candidate usability problems
notes places where a heuristic is violated as candidate usability problems
![]() notes places where heuristics are supported (things done well)
notes places where heuristics are supported (things done well)
![]() identifies the context of each instance noted previously, usually by capturing an image of the screen or part of the screen where the problem or good design feature occurs
identifies the context of each instance noted previously, usually by capturing an image of the screen or part of the screen where the problem or good design feature occurs
![]() All the inspectors get together and, as a team, they:
All the inspectors get together and, as a team, they:
![]() select the most important ones to fix
select the most important ones to fix
![]() brainstorm suggested solutions
brainstorm suggested solutions
![]() decide on recommendations for the designers based on the most frequently visited screens, screens with the most usability problems, guidelines violated most often, and resources available to make changes
decide on recommendations for the designers based on the most frequently visited screens, screens with the most usability problems, guidelines violated most often, and resources available to make changes
A heuristic evaluation report should:
![]() start with an overview of the system being evaluated
start with an overview of the system being evaluated
![]() give an overview explanation of inspection process
give an overview explanation of inspection process
![]() list the inspection questions based on heuristics used
list the inspection questions based on heuristics used
![]() report on potential usability problems revealed by the inspection, either:
report on potential usability problems revealed by the inspection, either:
![]() by heuristic—for each heuristic, give examples of design violations and of ways the design supports the heuristic
by heuristic—for each heuristic, give examples of design violations and of ways the design supports the heuristic
![]() by part of the design—for each part, give specific examples of heuristics violated and/or supported
by part of the design—for each part, give specific examples of heuristics violated and/or supported
![]() include as many illustrative screen images or other visual examples as possible.
include as many illustrative screen images or other visual examples as possible.
The team then puts forward the recommendations they agreed on for design modifications, using language that will motivate others to want to make these changes. They highlight a realistic list of the “Top 3” (or 4 or 5) suggestions for modifications and prioritize suggestions, to give the biggest improvement in usability for the least cost (perhaps using the cost-importance analysis of Chapter 16).
Reporting
We have found it best to keep HE reporting simple. Long forms with lots of fields can capture more information, but tend to be tedious for practitioners who have to report large numbers of problems. Table 13-2 is a simple HE reporting form that we have adapted, with permission, from one developed by Brad Myers. You can make up a Word document or spreadsheet form to put these headings in columns as an efficient way to report multiple problems, but they do not fit that way in the format of our book.
Table 13-2 Simple HE reporting form, adapted from Brad Myers

Description of columns in Table 13-2 is as follows:
Prototype screen, page, location of problem: On which screen and/or which location on a screen of the user interface was critical incident or problem located?
Name of heuristic: Which of the 10 heuristics is being referenced? Enter the full name of the heuristic.
Reason for reporting as negative or positive: Explain reasons why the interface violates or upholds this heuristic. Be sure to be clear about where in the screen you are referencing.
Scope of problem: Describe the scope of the feedback or the problem; include whether the scope of the issue is throughout the product or within a specific screen or screens. If the problems are specific to a page, include the appropriate page numbers.
Severity of problem (high/medium/low): Your assessment as to whether the implication of the feedback is high, medium, or low severity.
Justification of severity rating: The reason why you gave it that rating.
Suggestions to fix: Suggestion for the modifications that might be made to the interaction design to address the issue or issues.
Possible trade-offs (why fix might not work): Mentioning trade-offs adds to your credibility.
Critical Incident
A critical incident is a UX evaluation event that occurs during user task performance or other user interaction, observed by the facilitator or other observers or sometimes expressed by the user participant, that indicates a possible UX problem. Critical incident identification is arguably the single most important source of qualitative data.
Be specific and insightful; include subtlety and depth. Saying “the system does not have good color choices because it does not use color” is pretty trivial and is not helpful. Also, if you evaluated a prototype, saying that functions are not implemented is obvious and unhelpful.
Variations abound
The one “constant” about the HE method and most other related rapid and inspection methods is the variation with which they are used in practice. These methods are adapted and customized by almost every team that ever uses them usually in undocumented and unpublished ways.
Task-based or heuristic-based expert UX inspections can be conducted with just one evaluator or with two or more evaluators, each acting independently or all working together. Other expert UX inspections can be scenario based, persona based, checklist based, or as a kind of “can you break it?” test.
As an example of a variation that was described in the literature, participatory heuristic evaluation extends the HE method with additional heuristics to address broader issues of task and workflow, beyond just the design of user interface artifacts to “consider how the system can contribute to human goals and human experience” (Muller et al., 1998, p. 16). The definitive difference in participatory HE is the addition of users, work domain experts, to the inspection team.
Sears (1997) extended the HE method with what he calls heuristic walkthroughs. Several lists are prepared and given to each practitioner doing the inspection: user tasks, inspection heuristics, and “thought-focusing questions.” Each inspector performs two inspections, one using the tasks as a guide and supported by the thought-focusing questions. The second inspection is the more traditional kind, using the heuristics. Their studies showed that “heuristic walkthroughs resulted in finding more problems than cognitive walkthroughs and fewer false positives than heuristic evaluations.”
Perspective-based usability inspection (Zhang, Basili, & Shneiderman, 1999) is another published variation on the HE method. Because a large system can present a scope too broad for any given inspection session, Zhang et al. (1999) proposed “perspective-based usability inspection,” allowing inspectors to focus on a subset of usability issues in each inspection. The resulting focus of attention afforded a higher problem detection rate within that narrower perspective.
Examples of perspectives that can be used to guide usability inspections are novice use, expert use, and error handling. In their study, Zhang et al. (1999) found that their perspective-based approach did lead to significant improvement in detection of usability problems in a Web-based application. Persona-based UX inspection is a variation on the perspective-based inspection in that it includes consideration of context of use via the needs of personas (Wilson, 2011).
As our final example, Cockton et al. (2003) developed an extended problem-reporting format that improves heuristic inspection methods by finding and eliminating many of the false positives typical of the usability inspection approach. Traditional heuristic methods poorly support problem discovery and analysis. Their Discovery and Analysis Resource (DARe) model allows analysts to bring distinct discovery and analysis resources to bear to isolate and analyze false negatives as well as false positives.
Limitations
While a helpful guide for inexperienced practitioners, we find that heuristics usually get in the way of the experts. To be fair to the heuristic method, the heuristic method was intended as a kind of “scaffolding” to help novice practitioners do usability inspections so it should not really be compared with expert usability inspection methods anyway.
It was perhaps self-confirming when we read that others found the actual heuristics to be similarly unhelpful (Cockton, Lavery, & Woolrych, 2003; Cockton & Woolrych, 2001). In their studies, Cockton et al. (2003) found that it is experts who find problems with inspection, not experts using heuristics. Cockton and Woolrych (2002, p. 15) also claim that the “inspection methods do not encourage analysts to take a rich or comprehensive view of interaction.” While this may be true for heuristic methods, it does not have to be true for all inspection methods.
A major drawback with any inspection method, including the HE method, is the danger that novice practitioners will get too comfortable with it and think the heuristics are enough for any evaluation situation. There are few indications in its usage that let the novice practitioner know when it is not working well and when a different method should be tried.
Also, like all UX inspection methods, the HE method can generate a lot of false negatives, situations in which inspectors identified “problems” that turned out to be not real problems or not very important UX problems. Finally, like most other rapid UX evaluation methods, the HE method is not particularly effective in finding usability problems below the surface—problems about sequencing and workflow.
13.5 Our practical approach to UX Inspection
We have synthesized existing UX inspection methods into a relatively simple and straightforward method that, unlike the heuristic method, is definitely for UX experts and not for novices. Sometimes we have novices sit in and observe the process as a kind of apprentice training, but they do not perform these inspections on their own.
13.5.1 The Knock on Your Door
It is the boss. You, the practitioner, are being called in and asked to do a quick UX assessment of a prototype, an early product, or an existing product being considered for revision. You have 1 or 2 days to check it out and give feedback. You feel that if you can give some valuable feedback on UX flaws, you will gain some credibility and maybe get a bigger role in the project next time.
What method should you use? No time to go to the lab, and even the “standard” inspection techniques will take too long, with too much overhead. What you need is a practical, fast, and efficient approach to UX inspection. As a solution, we offer an approach that evolved over time in our own practice. You can apply this approach at almost any stage of progress, but it usually works better in the early stages. We believe that most real-world UX inspections are more like our approach than like the somewhat more elaborate techniques to inspection described in the literature.
13.5.2 Driven by Experience, Not Heuristics or Guidelines
We should say upfront that we do not explicitly use design guidelines or even “heuristics” to drive or guide this kind of UX inspection. In our own industry and consulting experience, we have just not found specific heuristics as useful as we would like.
To be clear, we are saying that we do not employ user design guidelines to drive the inspection process. The driving perspective is usage. We focus on tasks, work activities, and work context. We do insist, however, that an expert working and practical knowledge of design guidelines is essential to support the rapid analysis used to decide what issues are real problems and to understand the underlying nature of the problems and potential solutions. For this analysis, intertwined with inspection activities, we depend on our knowledge of design guidelines and their interpretation within the design.
We like a usage-based approach because it allows the practitioner to take on the role of user better, taking the process from purely analytic to include at least a little “empirical” flavor. Using this approach, and our UX intuition honed over the years, we can see, and even anticipate, UX problems, many of which might not have been revealed under the heuristic spotlight.
13.5.3 Use a Co-Discovery or Team Approach in UX Inspection
Expert UX practitioners as inspectors are in the role of “UX detectives.” To aid the detective work, it can help to use two practitioners, working together as mutual sounding boards in a give-and-take interplay, potentiating each other’s efforts to keep the juices flowing, to promote a constant flow of think-aloud comments from the inspectors, and to maintain a barrage of problem notes flying.
It is also often useful to have a non-UX person with you to look at the design from a global point of view. Teaming up with customers, users, designers, and other people familiar with the overall system can help make up for any lack of system knowledge you may have, especially if you have not been with the team during the entire project. Teaming up with users or work domain experts (which you might already have on your team) can reinforce your user-surrogate role and bring in more work-domain expertise (Muller et al., 1998).
13.5.4 Explore Systematically with a Rich and Comprehensive Usage-Oriented View
As an inspector, you should not just look for individual little problems associated with individual tasks or functions. Use all your experience and knowledge to see the big picture. Keep an expert eye on the high-level view of workflow, the overall integration of functionality, and emotional impact factors that go beyond usability.
For example, how are the three design perspectives covered in Chapter 8 accounted for by the system? Does the system ecology make sense? Is the conceptual design for interaction appropriate for envisioned workflows? What about the conceptual design for emotional impact?
Representative user tasks help us put ourselves in the users’ shoes. By exploring the tasks ourselves and taking our own think-aloud data, we can imagine what real users might encounter in their usage. This aspect of our inspections is driven as systematically as possible by two things: the task structure and the interaction design itself. A hierarchical task inventory (Chapter 6) is helpful in attaining a good understanding of the task structure and to ensure broad coverage of the range of tasks.
If the system is highly specialized and complex and you are not a work domain expert, you might not be able to comprehend it in a short time so get help from a subject-matter expert. Usage scenarios and design scenarios (Chapter 6) are fruitful places to look to focus on key user work roles and key user tasks that must be supported in the design.
Driving the inspection with the interaction design itself means trying all possible actions on all the user interface artifacts, trying out all user interface objects such as buttons, icons, and menus. It also means being opportunistic in following leads and hunches triggered by parts of the design.
The time and effort required for a good inspection are more or less proportional to the size of the system (i.e., the number of user tasks, choices, and system functions). System complexity can have an even bigger impact on inspection time and effort.
The main skill you need for finding UX problems as you inspect the design is your detective’s “eagle eye” for curious or suspicious incidents or phenomena. The knowledge requirement centers on design guidelines and principles and your mental inventory of typical interaction design flaws you have seen before. You really have to know the design guidelines cold, and the storehouse of problem examples helps you anticipate and rapidly spot new occurrences of the same types of problems.
Soon you will find the inspection process blossoming into a fast-moving narration of critical incidents, UX problems, and guidelines. By following various threads of UX clues, you can even uncover problems that you do not encounter directly within the tasks.
13.5.5 Emotional Impact Inspection
In the past, inspections for evaluating interaction designs have been almost exclusively usability inspections. But this kind of evaluation can easily be extended to a more complete UX inspection by addressing issues of emotional impact, too. The process is essentially the same, but you need to look beyond a task view to the overall usage experience. Ask additional questions.
Among the emotional impact questions to have in mind in a UX inspection are:
![]() Is the visual design attractive (e.g., colors, shapes, layout) and creative?
Is the visual design attractive (e.g., colors, shapes, layout) and creative?
![]() Will the design delight the user visually, aurally, or tactilely?
Will the design delight the user visually, aurally, or tactilely?
![]() Is the packaging and product presentation aesthetic?
Is the packaging and product presentation aesthetic?
![]() Is the out-of-the-box experience exciting?
Is the out-of-the-box experience exciting?
![]() Does the product feel robust and good to hold?
Does the product feel robust and good to hold?
![]() Can the product add to the user’s self-esteem?
Can the product add to the user’s self-esteem?
![]() Does the product embody environmental and sustainable practices?
Does the product embody environmental and sustainable practices?
![]() Does the product convey the branding of the organization?
Does the product convey the branding of the organization?
![]() Does the brand stand for progressive, social, and civic values?
Does the brand stand for progressive, social, and civic values?
![]() Are there opportunities to improve emotional impact in any of the aforementioned areas?
Are there opportunities to improve emotional impact in any of the aforementioned areas?
Most of the questions in a questionnaire for assessing emotional impact are also applicable as inspection questions here. As an example, using attributes from AttrakDiff:
13.5.6 Use All Your Personalities
Roses are red;
Violets are blue.
I’m schizophrenic, …
And I am, too.
You need to be at least a dual personality, with a slightly schizophrenic melding of the UX expert perspective and a user orientation. As a surrogate for users, you must think like a user and act like a user. But you must simultaneously think and act like an expert, observing and analyzing yourself in the user role.
Your UX expert credentials have never been in doubt, but demands of the user surrogate role can take you outside your comfort zone. You have to shed the designer and analyst mind-sets in favor of design-informing views of the world. You must immerse yourself in the usage-oriented perspective; become the user and live usage!
If you have doubts about your ability to play the user-surrogate role, as we said in a previous section, you should recruit an experienced user (hopefully one who is familiar with UX principles) or user representative to sit with you and help direct the interaction, informing the process with their work domain, user goal, and task knowledge.
13.5.7 Take Good Notes
As you do your inspection and play user, good note taking is essential for capturing precious critical incidents and UX problem data in the moment that they occur. Just as prompt capture of critical incidents is essential in lab-based testing to capture the perishable details while they are still fresh, you need to do the same during your inspections. You cannot rely on your memory and write it all down at the end. Once you get going, things can happen fast, just as they do in a lab-based evaluation session.
We often take our notes orally, dictating them on a handheld digital recorder. Because we can talk much faster than we can write or type, we can record our thoughts with minimal interruption of the flow or of your intense cognitive focus. Try to include as much analysis and diagnosis as you can, stating causes in the design in terms of design guidelines violated. As with most skill-based activities, you get better with practice.
You may not be able to suggest immediate solutions for more complex problems (e.g., reorganizing workflow) that require significant thought and discussion. However, you can usually suggest a cause and a fix for most problems. Given enough detail in the problem description, the solutions are often self-suggesting. For example, if a label has low color contrast between the text and the background, the solution is to increase the color contrast.
Dumas and Redish (1999) suggest that you should be more specific in suggesting this kind of solution, including what particular colors to use. It is a good idea to capture these design solution ideas, but treat them only as points of departure. Those decisions still need to be thought out carefully by someone with the requisite training in the use of colors and with knowledge of organizational style standards concerning color, branding, and so on. If you give an example of some colors that might work, you need to ensure that the designers do not take those colors as the exact solution without thinking about it further.
13.5.8 Analyze Your Notes
Sort out your inspection notes and organize them by problem type or design feature. If necessary, you can use a fast affinity diagram approach (see Chapter 4) on the top of a large work table. Print all notes on small pieces of paper and organize them by topic. Prioritize your recommendations for fixing, maybe with cost-importance analysis (Chapter 16).
13.5.9 Report Your Results
Your inspection report (Chapter 17) will be a lot like the one we described for the heuristic method earlier in this chapter, only you will not refer to heuristics. Tell about how you did the process in enough detail for your audience to understand the evaluation context.
Sometimes UX inspection, as does any evaluation method, raises questions. In your report, you should include recommendations for further evaluation, with specific points to look for and specific questions to answer.
Exercise
See Exercise 13-1, Formative UX Inspection
13.6 Do UX Evaluation rite
13.6.1 Introduction to the Rapid Iterative Testing and Evaluation (RITE) UX Evaluation Method
There are many variations of rapid UX evaluation techniques. Most are some variation of inspection methods, but one in particular that stands out is not based on inspection: the approach that Medlock, Wixon, and colleagues (Medlock et al., 2002, 2005; Wixon, 2003) call RITE, for “rapid iterative testing and evaluation,” is an empirical rapid evaluation method and is one of the best.
RITE employs user-based UX testing in a fast collaborative (team members and participants) test-and-fix cycle designed to pick the low-hanging fruit at relatively low cost. In other methods, the rest of the team is usually not present to see the process, so problems found by UX evaluators in the mystical methods are sometimes not believed. This is solved by the collaborative evaluation process in RITE; the whole team is involved in arriving at the results.
The key feature of RITE is the fast turnaround. UX problems are analyzed right after the product is evaluated with a number of user participants and the whole project team decides on which changes to make. Changes are then implemented immediately. If warranted, another iteration of testing and fixing might ensue.
Because changes are included in all testing that occurs after that point, further testing can determine the effectiveness of the changes—whether the problem is, in fact, fixed and whether the fix introduces any new problems. Fixing a problem immediately also gives access to any aspects of the product that could not be tested earlier because they were blocked by that problem.
In his inimitable Wixonian wisdom, our friend Dennis reminds us that, “In practice, the goal is to produce, in the quickest time, a successful product that meets specifications with the fewest resources, while minimizing risk” (Wixon, 2003).
13.6.2 How-to-Do-It: The RITE UX Evaluation Method
This description of the RITE UX evaluation method is based mainly on Medlock et al. (2002).
The project team starts by selecting a UX practitioner, whom we call the facilitator, to direct the testing session. The UX facilitator and the team prepare by:
![]() identifying the characteristics needed in participants
identifying the characteristics needed in participants
![]() deciding on which tasks they will have the participants perform
deciding on which tasks they will have the participants perform
![]() agreeing on critical tasks, the set of tasks that every user must be able to perform
agreeing on critical tasks, the set of tasks that every user must be able to perform
![]() constructing a test script based on those tasks
constructing a test script based on those tasks
![]() deciding how to collect qualitative user behavior data
deciding how to collect qualitative user behavior data
![]() recruiting participants (Chapter 14) and scheduling them to come into the lab
recruiting participants (Chapter 14) and scheduling them to come into the lab
The UX facilitator and the team conduct the evaluation session for one to three participants, one at a time:
![]() gathering the entire project team and any other relevant project stakeholders, either in the observation room of a UX lab or around a table in a conference room
gathering the entire project team and any other relevant project stakeholders, either in the observation room of a UX lab or around a table in a conference room
![]() bringing in the participant playing the role of user
bringing in the participant playing the role of user
![]() introducing everyone and setting the stage, explaining the process and expected outcomes
introducing everyone and setting the stage, explaining the process and expected outcomes
![]() making sure that everyone knows the participant is helping evaluate the system and the team is not in any way evaluating the participant
making sure that everyone knows the participant is helping evaluate the system and the team is not in any way evaluating the participant
![]() having the participant perform a small number of selected tasks, while all project stakeholders observe silently
having the participant perform a small number of selected tasks, while all project stakeholders observe silently
![]() having the participants think aloud as they work
having the participants think aloud as they work
![]() working together with the participants to find UX problems and ways the design should be improved
working together with the participants to find UX problems and ways the design should be improved
![]() taking thorough notes on problem indicators, such as task blocking and user errors
taking thorough notes on problem indicators, such as task blocking and user errors
![]() focusing session notes on finding usability problems and noting their severity
focusing session notes on finding usability problems and noting their severity
The UX facilitator and other UX practitioners:
![]() identify from session notes the UX problems observed and their causes in the design
identify from session notes the UX problems observed and their causes in the design
![]() give everyone on the team the list of UX problems and causes
give everyone on the team the list of UX problems and causes
The UX practitioner and the team address problems:
![]() identifying problems with obvious causes and obvious solutions, such as those involving wording or labeling, to be fixed first
identifying problems with obvious causes and obvious solutions, such as those involving wording or labeling, to be fixed first
![]() determining which other problems can also reasonably be fixed
determining which other problems can also reasonably be fixed
![]() determining which problems need more discussion
determining which problems need more discussion
![]() determining which problems require more data (from more participants) to be sure they are real problems
determining which problems require more data (from more participants) to be sure they are real problems
![]() sorting out which problems they cannot afford to fix right now
sorting out which problems they cannot afford to fix right now
![]() deciding on feasible solutions for the problems to be addressed
deciding on feasible solutions for the problems to be addressed
![]() implementing fixes for problems with obvious causes and obvious solutions
implementing fixes for problems with obvious causes and obvious solutions
![]() starting to implement other fixes and bringing them into the current prototype as soon as feasible
starting to implement other fixes and bringing them into the current prototype as soon as feasible
The UX practitioner and the team immediately conduct follow-up evaluation:
![]() having them perform the tasks associated with the fixed problems, using the modified design
having them perform the tasks associated with the fixed problems, using the modified design
![]() working with the participants to see if the fixes worked and to be sure the fixes did not introduce any new UX problems
working with the participants to see if the fixes worked and to be sure the fixes did not introduce any new UX problems
The entire process just described is repeated until you run out of resources or the team decides it is done (all major problems found and addressed).
13.6.3 Variations in RITE Data Collection
Although RITE is unusual as a rapid evaluation method that employs UX testing with user participants, what really distinguishes RITE is the fast turnaround and tight coupling of testing and fixing. As a result, it is possible to consider alternative data collection techniques within the RITE method. For example, instead of testing with user participants, the team could employ a UX inspection method, heuristic evaluation or otherwise, for data collection while retaining the fast analysis and fixing parts of the cycle.
13.7 Quasi-empirical UX evaluation
13.7.1 Introduction to Quasi-Empirical UX Evaluation
Quasi-empirical UX evaluation methods are empirical because they involve taking some kind of data using volunteer participants. Beyond that, their similarities to other empirical methods fade rapidly. Most empirical methods are characterized by formal protocols and procedures; rapid methods are anything but formal or protocol bound. Thus, the qualifier “quasi.”
Most empirical methods have at least some focus on quantitative data; quasi-empirical approaches have none. The single paramount mission is qualitative data to identify UX problems that can be fixed efficiently.
Although formal empirical evaluations often take place in a UX lab or similar setting, quasi-empirical testing can occur almost anywhere, including UX lab space, a conference room, an office, a cafeteria, or in the field. Like other rapid evaluation methods, practitioners using quasi-empirical techniques thrive on going with what works. While most empirical methods require controlled conditions for user performance, it is now not only acceptable but recommended to interrupt and intervene at opportune moments to elicit more thinking aloud and to ask for explanations and specifics.
Quasi-empirical methods are defined by the freedom given to the practitioner to innovate, to make it up as they go. Quasi-empirical evaluation sessions mean being flexible about goals and approaches. When conducted by the best practitioners, quasi-empirical evaluation is punctuated with impromptu changes of pace, changes of direction, and changes of focus—jumping on issues as they arise and milking them to get the most information about problems, their effects on users, and potential solutions.
This innovation in real time is where experience counts. Because of the ingenuity required and the need to adapt to each situation, experienced practitioners are usually more effective at quasi-empirical techniques, as they are with all rapid evaluation techniques. Each quasi-empirical session is different and can be tailored to the project conditions. Each session participant is different—some are more knowledgeable whereas some are more helpful. You must find ways to improvise, go with the flow, and learn the most you can about the UX problems.
Unlike other empirical methods, there are no formal predefined “benchmark tasks,” but a session can be task driven, drawing on usage scenarios, essential use cases, step-by-step task interaction models, or other task data or task models you collected and built up in contextual inquiry and analysis and modeling. Quasi-empirical sessions can also be driven by exploration of features, screens, widgets, or whatever suits.
13.7.2 How-to-Do-It: Quasi-Empirical UX Evaluation
Prepare
Begin by ensuring that you have a set of representative, frequently used, and mission-critical tasks for your participants to explore. Draw on your contextual data and task models (structure models and interaction models). Have some exploratory questions ready (see next section).
Assign your UX evaluation team roles effectively, including evaluator, facilitator, and data collectors. If necessary, use two evaluators for co-discovery. Further prepare for your quasi-empirical session the same way you would for a full empirical session, only less formally and less thoroughly, to match the more rapid and more opportunistic nature of the quasi-empirical approach.
Thus preparation includes lightweight selection and recruiting of participants, preparation of materials such as the informed consent form, and establishment of protocols and procedures for the sessions. You should also do pilot testing to shake down the prototype and the procedures, but getting the prototype bug-free is a little less important for quasi-empirical evaluation, as you can be very flexible during the session.
Conduct session and collect data
As you, the facilitator, sit with each participant:
![]() Cultivate a partnership; you get the best results from working closely in collaboration.
Cultivate a partnership; you get the best results from working closely in collaboration.
![]() Make extensive use of the think-aloud data collection technique. Encourage the participant by prompting occasionally: “Remember to tell us what you are thinking as you go.”
Make extensive use of the think-aloud data collection technique. Encourage the participant by prompting occasionally: “Remember to tell us what you are thinking as you go.”
![]() Make sure that the participant understands the role as that of helping you evaluate the UX.
Make sure that the participant understands the role as that of helping you evaluate the UX.
![]() Although recording audio or video is sometimes helpful in rigorous evaluation methods, to retain a rapidness in this method, it is best not to record audio or video; just take notes. Keep it simple and lightweight.
Although recording audio or video is sometimes helpful in rigorous evaluation methods, to retain a rapidness in this method, it is best not to record audio or video; just take notes. Keep it simple and lightweight.
![]() Encourage the participant to explore the system for a few minutes and get familiarized with it. This type of free-play is important because it is representative of what happens when users first interact with a system (except in cases where walk up and use is an issue).
Encourage the participant to explore the system for a few minutes and get familiarized with it. This type of free-play is important because it is representative of what happens when users first interact with a system (except in cases where walk up and use is an issue).
![]() Use some of the tasks that you have at hand, from the preparation step given earlier, more or less as props to support the action and the conversation. You are not interested in user performance times or other quantitative data.
Use some of the tasks that you have at hand, from the preparation step given earlier, more or less as props to support the action and the conversation. You are not interested in user performance times or other quantitative data.
![]() Work together with the participant to find UX problems and ways the design should be improved. Take thorough notes; they are sole raw data from the process.
Work together with the participant to find UX problems and ways the design should be improved. Take thorough notes; they are sole raw data from the process.
![]() Let the user choose some tasks to do.
Let the user choose some tasks to do.
![]() Be ready to follow threads that arise rather than just following prescripted activities.
Be ready to follow threads that arise rather than just following prescripted activities.
![]() Listen as much as you can to the participant; most of the time it is your job to listen, not talk.
Listen as much as you can to the participant; most of the time it is your job to listen, not talk.
![]() It is also your job to lead the session, which means saying the right thing at the right time to keep it on track and to switch tracks when useful.
It is also your job to lead the session, which means saying the right thing at the right time to keep it on track and to switch tracks when useful.
Think-Aloud Technique
The think aloud technique is a qualitative data collection technique in which user participants verbally externalize their thoughts about their interaction experience, including their motives, rationale, and perceptions of UX problems. By this method, participants give the evaluator access to an understanding of their thinking about the task and the interaction design.
At any time during the session, you can interact with the participant with questions such as:
![]() Ask participants to describe initial reactions as they interact with this system.
Ask participants to describe initial reactions as they interact with this system.
![]() Ask questions such as “How would you describe this system to someone who has never seen it before? What is the underlying “model” for this system? Is that model appropriate? Where does it deviate? Does it meet your expectations? Why and how? These questions get to the root of determining the user’s mental model for the system.
Ask questions such as “How would you describe this system to someone who has never seen it before? What is the underlying “model” for this system? Is that model appropriate? Where does it deviate? Does it meet your expectations? Why and how? These questions get to the root of determining the user’s mental model for the system.
![]() Ask what parts of the design are not clear and why.
Ask what parts of the design are not clear and why.
![]() Inquire about how the system compares with others they have used in the past.
Inquire about how the system compares with others they have used in the past.
![]() Ask if they have any suggestions for changing the designs.
Ask if they have any suggestions for changing the designs.
![]() To place them in the context of their own work, ask them how they would use this system in their daily work. In other words, ask them to walk you through some tasks they would perform using this system in a typical workday.
To place them in the context of their own work, ask them how they would use this system in their daily work. In other words, ask them to walk you through some tasks they would perform using this system in a typical workday.
Analyze and report results
Because the UX data analysis procedure (Chapter 16) pretty much applies regardless of how you got data, use the parts of that chapter about analyzing qualitative data.
13.8 Questionnaires
A questionnaire, discussed at length in Chapter 12, is a fast and easy way to collect subjective UX data, either as a supplement to any other rapid UX evaluation method or as a method on its own.
Questionnaires with good track records, such as the Questionnaire for User Interface Satisfaction (QUIS), the System Usability Scale (SUS), or Usefulness, Satisfaction, and Ease of Use (USE), are all easy and inexpensive to use and can yield varying degrees of UX data. Perhaps the AttrakDiff questionnaire might be the best choice for a rapid stand-alone method, as it is designed to address both pragmatic (usability and usefulness) and hedonic (emotional impact) issues.
For a general discussion of modifying questionnaires for your particular evaluation session, see Chapter 12 about modifying the AttrakDiff questionnaire.
13.9 Specialized rapid UX evaluation methods
13.9.1 Alpha and Beta Testing and Field Surveys
Alpha and beta testing are useful post-deployment evaluation methods. After almost all development is complete, manufacturers of software applications sometimes send out alpha and beta (pre-release) versions of the application software to select users, experts, customers, and professional reviewers as a preview. In exchange for the early preview, users try it out and give feedback on the experience. Often little or no guidance is given for the review process beyond just “tell us what you think is good and bad and what needs fixing, what additional features would you like to see, etc.”
An alpha version of a product is an earlier, less polished version, usually with a smaller and more trusted “audience.” Beta is as close to the final product as they can make it and is sent out to a larger community. Most companies develop a beta trial mailing list of a community of early adopters and expert users, mostly known to be friendly to the company and its products and helpful in their comments.
Alpha and beta testing are easy and inexpensive ways to get feedback. But you do not get the kind of detailed UX problem data observed during usage and associated closely with user actions and their consequences in the context of specific interaction design features—the kind of data essential for isolating specific UX problems within the formative evaluation process.
Alpha and beta testing are very much individualized to a given development organization and environment. Full descriptions of how to do alpha and beta testing are beyond our scope. Like alpha and beta testing, user field survey information is retrospective and, while it can be good for getting at user satisfaction, it does not capture the details of use within the usage experience. Anything is better than nothing, but let us hope this is not the only formative evaluation used within the product lifecycle in a given organization.
13.9.2 Remote UX Evaluation
Remote UX evaluation methods (Dray & Siegel, 2004; Hartson & Castillo, 1998) are good for evaluating systems after they have been deployed in the field. Methods include:
![]() simulating lab-based UX testing using the Internet as a long extension cord to the user (e.g., UserVue by TechSmith)
simulating lab-based UX testing using the Internet as a long extension cord to the user (e.g., UserVue by TechSmith)
![]() online surveys for getting after-the-fact feedback
online surveys for getting after-the-fact feedback
![]() software instrumentation of click stream and usage event information
software instrumentation of click stream and usage event information
![]() software plug-ins to capture user self-reporting of UX issues
software plug-ins to capture user self-reporting of UX issues
The Hartson and Castillo (1998) approach uses self-reporting of UX problems by users as the problems occur during their normal usage, allowing you to get at the perishable details of the usage experience, especially in real-life daily work usage. As always, the best feedback for design improvement is feedback deriving from Carter’s (2007) “inquiry within experience,” or formative data given concurrent with usage rather than retrospective recollection. A full description of how to do remote UX testing is highly dependent on the type of technology used to mediate the evaluation, and therefore not possible to describe in detail here.
13.9.3 Local UX Evaluation
Local UX evaluation is UX evaluation using a local prototype. A local prototype is very limited in both depth and breadth, restricted to a single interaction design issue involving particular isolated interaction details, such as the appearance of an icon, wording of a message, or behavior of an individual function. If your design team cannot agree on the details of a single feature, such as a particular dialogue box, you can mockup local prototypes of the alternatives and take them to users to compare in local UX evaluation.
Local Prototype
A local prototype represents the small area where horizontal and vertical slices intersect. A local prototype, with depth and breadth both limited, is used to evaluate design alternatives for a particular isolated interaction detail.
13.9.4 Automatic UX Evaluation
Lab-based and UX inspection methods are labor-intensive and, therefore, limited in scope (small number of users exercising small portions of large systems). But large and complex systems with large numbers of users offer the potential for a vast volume of usage data. Think of “observing” a hundred thousand users using Microsoft Word. Automatic methods have been devised to take advantage of this boundless pool of data, collecting and analyzing usage data without need for UX specialists to deal with each individual action.
The result is a massive amount of data about keystrokes, click-streams, and pause/idle times. But all data are at the low level of user actions, without any information about tasks, user intentions, cognitive processes, etc. There are no direct indications of when the user is having a UX problem somewhere in the midst of that torrent of user action data. Basing redesign on click counts and low-level user navigation within a large software application could well lead to low-level optimization of a system with a bad high-level design. A full description of how to do automatic usability evaluation is beyond our scope.
13.10 More about “discount” UX engineering methods
13.10.1 Nielsen and Molich’s Original Heuristics
The first set of heuristics that Nielsen and Molich developed for usability inspection (Molich & Nielsen, 1990; Nielsen & Molich, 1990) were 10 “general principles” for interaction design. They called them heuristics because they are not strict design guidelines. Table 13-3 lists these original heuristics from Nielsen’s Usability Engineering book (Nielsen, 1993, Chapter 5).
Table 13-3 Original Nielsen and Molich heuristics
13.10.2 “Discount” Formative UX Evaluation Methods
Although the concepts have been challenged, mainly by academics, as inferior and scientifically unsound, we use the term “discount method” in a positive sense. UX evaluation is the center of the iterative process and, despite its highly varied effectiveness, somehow in practice it still works. Here we wholeheartedly affirm the value of discount UX methods among your UX engineering tools!
What is a “discount” evaluation method?
Because UX inspection techniques are less costly, they have been called “discount” evaluation techniques (Nielsen, 1989). Although the term was intended to reflect the advantage of lower costs, it soon was used pejoratively to connote inferior bargain-basement goods (Cockton & Woolrych, 2002; Gray & Salzman, 1998) because of the reduced effectiveness and susceptibility to errors in identifying UX problems.
Inspection methods have been criticized as “damaged merchandise” (Gray & Salzman, 1998) or “discount goods” (Cockton & Woolrych, 2002); however we feel that, as in most things, the value of these methods depends on the context of their use. Although the controversy could be viewed by those outside of HCI research as academic fun and games, it could be important to you because it is about very practical aspects of your choices of UX evaluation methods and bounds in their use.
Do “discount” methods work?
It depends on what you mean by “work.” Much of the literature by researchers studying the effectiveness of UX evaluation methods decries the shortcomings of inspection methods when measured by a science-oriented yardstick.
Studies have established that even with a large number of evaluators, some evaluations reveal only a percentage of the existing problems. We know that there is a broad variability of results across methods and across people using the same method. Different evaluators even report very different problems when observing the same evaluation session. Different UX teams interpret the same evaluation report in different ways.
However, in an engineering context, “working” means being effective and being cost-effective, and in this context discount UX engineering methods have a well-documented record of success. From a practical perspective, it is difficult to avoid the conclusion that using these methods is still better than not doing anything about evaluating UX.
Yes, you might miss many real user experience problems, but you will get some good ones, too. That is the trade-off you must be willing to accept if you use “discount” methods. You might even get some false positives, things that look like problems but really are not. It is hoped that you can sort those out. In any case, the idea is that you will be able to achieve a good engineering result much faster and with far less cost than a full empirical treatment that some authors demand.
Finally, although lab-based evaluation is often held up as the “gold standard” or yardstick against which other evaluation methods are compared, lab testing is not perfect, either, and does not escape criticism for limitations in effectiveness (Molich et al., 1998, 1999; Newman, 1998; Spool & Schroeder, 2001). The lab-based approach to UX testing suffers from many of the same kinds of flaws as do discount and other inspection methods.
Pros and cons as engineering tools
Of course, with any discount approach, there are trade-offs. The upside is that, in the hands of an experienced evaluator, inspection methods can be very effective—you can get a lot of UX problems dealt with and out of the way at a low cost. Another advantage is that UX inspection methods can be very fast, more quickly responsive than lab testing, for example, to fast iteration. Under the right conditions, you can do a UX inspection and its analysis, fix the major problems, and update the prototype design in a day!
The major downsides are that because inspection methods do not employ real users, they can be error-prone, can tend to find a higher proportion of lower severity problems, and can suffer from validity problems. This means they will yield some false positives (UX issues that turn out not to be real problems) and will miss some UX problems because of false negatives. Having to deal with low-severity problems and false positives can be distracting to UX practitioners and can be wasteful of resources.
Another potential drawback is that the UX experts doing the inspection may not know the subject-matter domain or the system in depth. This can lead to a less effective inspection but can be offset somewhat by including a subject-matter expert on the inspection team.
Evaluating UX evaluation methods
Some of the value of current methods for assessing and improving UX in interactive software systems is somewhat offset by a general lack of understanding of the capabilities and limitations of each. Practitioners need to know which methods are more effective and in what ways and for what purposes. Thus emerged the need to evaluate and compare usability evaluation methods. The literature has a number of limited studies and commentaries on the effectiveness of usability evaluation methods, each report with its own different goals, results, and inferences.
However, there are no standard criteria for usability evaluation method comparison from study to study. And researchers planning full formal summative studies of competing methods in a real-world commercial development project environment are faced with virtually prohibitive difficulty and expense. It is hard enough to develop a system once, let alone redeveloping it over and over with multiple different approaches.
So we have a few imperfect but still enlightening studies to go by, mostly studies emerging as a by-product or afterthought attached to some other primary effort. In sum, usability evaluation methods have not been evaluated and compared reliably.
In the literature, usability inspection methods are often compared with lab-based testing, but we do not see inspection as a one-or-the-other alternative or a substitute for lab-based testing. Each method is one of the available UX engineering tools, each appropriate under its own conditions.
Andrew Sears made some of the most important early contributions about usability metrics (e.g., thoroughness, validity, and reliability) in usability evaluation methods (Sears, 1997; Sears & Hess, 1999). Hartson, Andre, and Williges (2003) introduced usability evaluation method comparison criteria and extended the measures of Sears to include effectiveness, an overall metric taking into account both thoroughness and validity. Their weightings between thoroughness and validity have the potential to enhance the possibilities for usability evaluation method performance measures in comparison studies. Hartson, Andre, and Williges (2003) include a modest review of 18 comparative usability evaluation method studies.
Gray and Salzman (1998) spoke to the weaknesses of most usability evaluation method comparison studies conducted to that date. Their critical review of usability evaluation method studies concluded that flaws in experimental design and execution “call into serious question what we thought we knew regarding the efficacy of various usability evaluation methods.” Using specific critiques of well-known usability evaluation method studies to illustrate, they argued the case that experimental validity (of various kinds) and other shortcomings of statistical analyses posed a danger in using the “conclusions” to recommend usability evaluation methods to practitioners.
To say that this paper was controversial is an understatement. Perhaps it was in part the somewhat cynical title (“Damaged Merchandise”) or the overly severe indictment of the research arm of HCI, but the comments, rebuttals, and rejoinders that followed added more than a little fun and excitement into the discipline.
Also, we have noticed a trend since this paper to transfer the blame from the studies of discount usability evaluation methods to the methods themselves, a subtle attempt to paint the methods with the same “damaged merchandise” brush. The CHI’95 panel called “Discount or Disservice?” (Gray et al., 1995) is an example. In Gray and Salzman (1998), the term “damaged merchandise” was, at least ostensibly, aimed at flawed studies comparing usability evaluation methods. But many have taken the term to refer to the usability evaluation methods themselves and this panel title does nothing to disabuse us of this semantic sleight of hand.
More recently, in a comprehensive meta study of usability methods and practice, Hornbaek (2006) looked at 180 (!) studies of usability evaluation methods. Hornbaek proposed more meaningful usability measures, both objective and subjective, and contributed a useful in-depth discussion of what it means to measure usability, an elusive but fundamental concept in this context.
Finally, one of the practical problems with evaluation methods and their evaluation is the question of “Now that you have found the usability problems, what is next?” John and Marks (1997) consider downstream (after usability data gathering) utility, the usefulness of usability evaluation method outputs (problem reports) in convincing team members of the need to fix a problem and the usefulness in helping to effect the fixes. Only a few others also consider this issue, including Medlock et al. (2005), Gunn (1995), and Sawyer, Flanders, and Wixon (1996).
The Comparative Usability Evaluation (CUE) series
In a series of usability evaluation method evaluation studies that became known as the Comparative Usability Evaluation series (seven studies that we know of as of this writing), a number of usability evaluation methods were tested under a variety of conditions and a major observation emerged under the name of the evaluator effect (Hertzum & Jacobsen, 2003), which essentially states that the variation among results from different evaluators using the same method on the same target application can be so large as to call into question the effectiveness of the methods. These studies have been called by some the studies that discredit usability engineering, but we think they just bring some important issues about reality to light.
In CUE-1 (Molich et al., 1998), four professional usability labs performed usability tests of a Windows calendar management application. Of the 141 usability problems reported overall, 90% were reported by only one lab and only one problem was reported by as many as four labs.
In CUE-2 (Molich et al., 2004), nine organizations evaluated a Website, focusing on a prescribed task set. Seventy-five percent of the 310 overall problems were reported by just one team, while only 2 problems were reported by as many as six groups.
CUE-3 (Hertzum, Jacobsen, & Molich, 2002) again evaluated a Website using a specific task set. This time the experimenters began with 11 individuals. The subject evaluators then met in four groups to combine their individual results. Following group discussions, the individuals “felt that they were largely in agreement,” despite only a 9% overlap in reported problems between any two evaluators. This perception of agreement in the face of data apparently to the contrary seemed to be based on the feeling that the different problem reports were actually about similar underlying problems but coming at them from different directions.
In a secondary part of CUE-4, the authors concluded that a large proportion of recommendations given following a usability evaluation were neither useful nor usable for making design changes to improve product usability (Molich, Jeffries, & Dumas, 2007). The authors concluded that designers have difficulty acting on most problem descriptions because problem reports are often poorly written, unconvincing, and ineffective at guiding a design solution. To make it worse, in many cases the entire outcome rides on the report itself as there is no opportunity to explain the problems or argue the case afterward.
As of this writing, the latest in the CUE series was CUE-9 (Molich, 2011).
13.10.3 Yet Somehow Things Work
Press on
So what is all the fuss in the literature about damaged merchandise, discount methods, heuristic methods, and so on? Scientifically, there are valid issues with these methods. However, the evaluator effect applies to virtually all kinds of UX evaluation, including our venerable yardstick of performance, the lab-based formative evaluation. Formative evaluation, in general, just is not very reliable or repeatable.
There is no one evaluation method that will reveal all the UX problems. So what is a UX newbie to do? Give it up? No, this is engineering and we just have to get over it, be practical, and do our best—and sometimes it works really well.
While researchers continue to pursue and validate better methods, we make things work and we use tools and methods that are far less than perfect. We always seem to get a better design by evaluating and iterating and that is the goal. One application of our methods may not find all UX problems, but we usually get some good ones. If we fix those, maybe we will get the others the next time.
We will find the important ones in other ways—we are not doing the whole process with our eyes closed. In the meantime, experienced practitioners read about how these evaluation methods do not work and smile as they head off to the lab or to an inspection session.
Among the reasons we have to be optimistic in the long run about our UX evaluation methods are:
Practical engineering goals
Approaching perfection is expensive. In engineering, the goal is to make it good enough. Wixon (2003) speaks up for the practitioner in the discussion of usability evaluation methods. From an applied perspective, he points out that a focus on validity and proper statistical analysis in these studies is not serving the needs of practitioners in finding the most suitable usability evaluation method and best practices for their work context in the business world.
Wixon (2003) would like to see more emphasis on usability evaluation method comparison criteria that take into account factors that determine their success in real product development organizations. As an example, the value of a method might be less about absolute numbers of problems detected and more about how well a usability evaluation method fits into the work style and development process of the organization. And to this we can only say amen.
Managing risk by mitigating evaluation errors
Cockton and Woolrych (2002) cast errors made with usability evaluation methods (discount inspection methods and “lite” lab-based usability testing methods) in terms of risks, “But are discount methods really too risky to justify the ‘low’ cost?” What kinds of risks are there? There is the risk of not fixing usability issues missed by the method and the risk of “fixing” false alarms.
To be sure, however, the risks associated with errors are real and are part of any engineering activity involving evaluation and iterative improvement. But we have to ask, how serious are the risks? Rarely can an error of these types make or break the success of the system. As Cockton and Woolrych (2002, pp. 17–18) point out, “errors … may be more costly in some contexts than others.”
Where human lives are at risk, we are compelled to spend more resources to be more thorough in all our process activities and will surely not allow an evaluation error to weaken the design in the end. In most applications, though, each error simply means that we missed an opportunity to improve usability in one detail of the design.
Managing the risk of false negatives with iteration
Many of the comparisons of usability inspection methods point out the susceptibility of these methods to making errors in identifying usability problems, with disparaging conclusions. However, these conclusions are usually made in the context of science, where evaluation errors can count heavily against the method. In balance, others (Manning, 2002) question the working assumptions of such problem validity arguments when examined in the light of real-world development projects.
One kind of problem identification error, a false negative—failure to detect a real usability problem—can lead to missing out on needed fixes. The risk here, of course, is not greater than it would be if no evaluation is done. So every problem you do find is one for the good. What, then, are the alternatives? Discount methods are being used presumably because of budget constraints, so the more expensive lab-based testing is not going to be the answer.
One important factor that some studies of evaluation methods neglect is iteration. To temper the consequences of missing some problems the first time around, you always have other iterations and other evaluation methods that might well catch them by the end of the day. If we look at the results over a few iterations instead of each attempt in isolation, we are likely to see net occurrences of false negatives reduced greatly.
If we find a set of bona fide problems and fix them, we remove them from contention in the next cycle of evaluation, which helps us focus on the remaining problems. If we combine different results (i.e., different problems uncovered) from different evaluators or different iterations, the overall process can still converge.
Managing the risk of false positives with UX expertise
Another kind of problem identification error is a false positive—identifying something as a problem when it is not. The risk associated with this kind of error, that of trying to fix a problem that is not real, could exact a penalty. For example, false positives in problem identification can lead to unneeded and possibly damaging “fixes.” But, as we said, this risk occurs with any kind of evaluation method.
The important point to remember here is that UX inspection is only an engineering tool. You, the practitioner, must maintain your engineering judgment and not let evaluation results be interpreted as the final word. You are still in charge.
Also, as many point out, this is just the initial finding of candidate problems. To abate the effects of false positives, think of the method as an engineering tool not giving you absolute indicators of problems but suggesting possible problems, possibilities that you, the expert practitioner, must still investigate, analyze, and decide upon. Then, if there are still false positives, you can blame yourself and not the inspection method. In the discount methods controversy, we lay a lot of responsibility on the methods for finding problems without considering that the UX evaluation methods are backed up by UX specialists.
One important way that a UX specialist can augment the limited power of a UX evaluation method is by learning from problems that are found and keeping alert for similar issues elsewhere in the design. An interaction design is a web of features and relationships. If you detect one instance of a UX problem in a particular design feature, you are likely to encounter similar problems in similar situations elsewhere as you go about the fixes and redesign.
Suppose there are 10 instances of a UX problem of a certain general type in your application, but our UX evaluation method finds only 1. There is still a good chance that analysis and redesign for that problem will lead a dedicated and observant UX specialist eventually to find and fix some other similar or related problems, giving you a UX evaluation method/practitioner team with a higher net problem detection rate.
Look at the bright side of studies
In CUE-3 (Hertzum, Jacobsen, & Molich, 2002), the dissimilarity among results across individual evaluators was not viewed as disagreements by the evaluators but as different expressions of the same underlying problems. Although statistically the evaluators had a relatively small overlap in problems reported, after a group discussion the evaluators all felt they “were largely in agreement.” The evaluators perceived their disparate observations as multiple sources of evidence in support of the same issues, not as disagreements.
We have also experienced this in our consulting work when different problem reports at first seemed not comparable, but further discussion revealed that they were saying different things about essentially the same underlying problems, and we felt that even if we had not detected this in the analysis stage, the different views would have converged in the process of fixing the problems.
This seems to say that the evaluation methods were not as bad at problem detection as data initially implied. However, it also seems to shift the spotlight to difficulties in how we analyze and report problems in those methods. There is a large variation in the diagnoses and expressions used to describe problems.
Finally, in situations where thoroughness is low, low reliability across evaluators can actually be an asset. As long as each evaluator is not finding most or all of the problems, differences in detection across evaluators mean that, by adding more evaluators, you can find more problems in their combined reports through a diversity in detection abilities.
In sum, although criticized as false economy in some HCI literature, especially the academic literature, these so-called “discount” methods are practiced heavily and successfully in the field.