
Emerging Topics in Congestion Control
This chapter discusses three different topics that are at the frontiers of research into congestion control: (1) We describe a project from the Massachusetts Institute of Technology called Remy that applies techniques from ML to congestion control. It discovers the optimal congestion control rules for a specific (but partially observed) state of the network by doing an extensive simulation-based optimization of network wide utility functions. (2) Software Defined Networks (SDNs) have been one of the most exciting developments in networking in recent years. Most of their applications have been in the area of algorithms and rules that are used to control the route that a packet takes through the network. However, we describe a couple of instances in which ideas from SDNs can also be used to improve network congestion control. (3) We describe an algorithm called Google Congestion Control that is part of the Web Real-Time Communication project in the Internet Engineering Task Force and is used for controlling real-time in-browser communications. This algorithm has some interesting features such as a unique use of Kalman filtering at the receiver to estimate whether the congestion state at the bottleneck queue in the face of a channel capacity that is widely varying.
Keywords
Project Remy; Remy congestion control algorithm; Machine Learning and congestion control; Software Defined Networking and congestion control; Google Congestion Control; GCC; Kalman filtering and congestion control
9.1 Introduction
In this chapter, our objective is to provide a brief survey of some emerging topics in congestion control. There has been renewed interest in the topic of congestion control in recent years, driven mostly by applications to data center networks and video streaming. Meanwhile, broader trends in networking, such as the emergence of Software Defined Networks (SDNs), are beginning to have their influence felt on this topic as well. Other advances in technology, such as the progress that has been made in artificial intelligence (AI) and Machine Learning (ML) algorithms, are also having an impact on our subject.
In Section 9.2, we describe Project Remy from Massachusetts Institute of Technology (MIT), which uses ML to automatically generate congestion control algorithms; these have been shown to perform better than their human-designed counterparts. These algorithms are based on the theory developed in Chapter 3 in which congestion control rules are derived as a solution to a distributed optimization problem. Unlike the window increase–decrease rules that we have encountered so far, these rules number in the hundreds and are a function of the specific point in the feedback space. The framework of Project Remy also helps us to explore the delay versus throughput tradeoff in congestion control, as well as provide bounds on how well the best performing algorithm can do.
In Section 9.3, we give a brief description of the field of SDNs. They have been used to facilitate routing and switching level functionality, but they may have a significant impact on congestion control as well. We describe a couple of topics in congestion control that can benefit from the centralized control point that SDNs provide. The first topic is on the use of SDNs to choose an appropriate Active Queue Management (AQM) algorithm at a switch as a function of the application running on top of the connection. For example, drop-tail queues are good enough for applications that prioritize throughput over latency, but more sophisticated AQM is needed for applications for which low latency is important. The second topic is on the use of SDNs to set appropriate parameters for the AQM algorithm.
Section 9.4 is on the Google Congestion Control (GCC) algorithm, which was designed for transmitting real-time video streams and is part of the Web Real-Time Communication (WebRTC) project of the Internet Engineering Task Force (IETF). There are some interesting new ideas in GCC, such as the active participation of the receiver in the congestion control algorithm, which are sure to influence the future direction of this subject. The GCC algorithm does not run on top of TCP but instead uses the Real Time Transport protocol (RTP) for sending data and its accompanying Real Time Control Protocol (RTCP) for obtaining feedback from the receiver. The receiver analyzes the pattern of packet inter-arrival times and then uses a Kalman filter to estimate whether the bottleneck queue is changing in size. It chooses a rate based on this information and feeds this information back to the source, which bases the sending rate on this and some other pieces of information.
9.2 Machine Learning and Congestion Control: Project Remy
In this section, we describe the work carried out by Winstein et al. at MIT in which they did a fundamental rethink on how to solve the congestion control problem, based on which they came up with an algorithm called Remy that is radically different from all existing work in this area [1–4]. This algorithm is based on applying ideas from partially observable Markov decision processes (POMDPs) to the congestion control problem.
The basic idea behind the derivation of this algorithm is something that we discovered in Chapter 3, that is, the congestion control problem can be regarded as the solution to the distributed optimization of a network wide utility function (see Section 3.2 and Appendix 3.E in Chapter 3). By using POMDP/ML techniques, the algorithm learns the best possible congestion control action, in the sense of minimizing this utility function, based on its observations of the partial network state at each source.
The system uses a simple ON-OFF model for the traffic generation process at each source. The sender is OFF for a duration that is drawn from an exponential distribution. Then it switches to the ON state, where it generates a certain number of bytes that are drawn from an empirical distribution of flow sizes or a closed form distribution.
The important ingredients that go into the algorithm include:
• The form of the utility function that is being minimized
• The observations of the network state at each source
• The control action that the algorithm takes based on these observations
We describe each of these in turn:
1. Utility function: Define the function
(1)
then the form of the network utility function for a connection that Remy uses is given by
(2)
Given a network trace, r is estimated as the average throughput for the connection (total number of bytes sent divided by the total time that the connection was “ON”), and Ts is estimated as the average round-trip delay. Note that the parameters ![]() and
and ![]() express the fairness vs efficiency tradeoffs for the throughput and delay, respectively (see Appendix 3.E in Chapter 3), and
express the fairness vs efficiency tradeoffs for the throughput and delay, respectively (see Appendix 3.E in Chapter 3), and ![]() expresses the relative importance of delay versus throughput. By varying the parameter
expresses the relative importance of delay versus throughput. By varying the parameter ![]() , equation 2 enables us to explicitly control the trade-off between throughput and delay for the algorithm. The reader may recall from the section on Controlled Delay (CoDel) in Chapter 4 that legacy protocols such as Reno or Cubic try to maximize the throughput without worrying about the end-to-end latency. To realize the throughput–delay tradeoff, legacy protocols have to use an AQM such as Random Early Detection (RED) or CoDel, which sacrifice some the throughput to achieve a lower delay. Remy, on the other hand, with the help of the utility function in equation 2, is able to attain this trade-off without making use of an in-network AQM scheme.
, equation 2 enables us to explicitly control the trade-off between throughput and delay for the algorithm. The reader may recall from the section on Controlled Delay (CoDel) in Chapter 4 that legacy protocols such as Reno or Cubic try to maximize the throughput without worrying about the end-to-end latency. To realize the throughput–delay tradeoff, legacy protocols have to use an AQM such as Random Early Detection (RED) or CoDel, which sacrifice some the throughput to achieve a lower delay. Remy, on the other hand, with the help of the utility function in equation 2, is able to attain this trade-off without making use of an in-network AQM scheme.
2. Network state observations: Remy tracks the following features of the network history, which are updated every time it receives an ACK:
a. ack_ewma: This is an exponentially weighted moving average of the inter-arrival time between new ACKs received, where each new sample contributes 1/8 of the weight of the moving average.
b. send_ewma: This is an exponentially weighted moving average of the time between TCP sender timestamps reflected in those ACKs, with the same weight 1/8 for new samples.
c. rtt_ratio: This is the ratio between the most recent Round Trip Latency (RTT) and the minimum RTT seen during the current connection.
Winstein et al. [3] arrived at this set of observations by doing a comprehensive test of other types of feedback measurements that are possible at a source. Traditional measurements, such as most recent RTT sample or a smoothed estimate of the RTT sample, were tested and discarded because it was observed that they did not improve the performance of the resulting protocol. In particular, Remy does not make use of two variables that almost every other TCP algorithm uses: the packet drop rate p and the round trip latency T. The packet drop rate is not used because a well-functioning algorithm should naturally lead to networks with small queues and very few losses. The round trip latency T was intentionally kept out because the designers did not want the algorithm to take T into account in figuring out the optimal action to take.
Note that Remy does not keep memory from one busy period to the next at a source, so that all the estimates are reset every time a busy period starts.
3. Control actions: Every time an ACK arrives, Remy updates its observation variables and then does a look-up from a precomputed table for the action that corresponds to the new state. A Remy action has the following three components:
a. Multiply the current congestion window by b, i.e., W←bW.
b. Increment the current congestion window by a, i.e., W←W+a.
c. Choose a minimum of ![]() ms as the time between successive packet sends.
ms as the time between successive packet sends.
Hence, in addition to the traditional multiplicative decrease/additive decrease actions, Remy implements a combination of window+rate-based transmission policy, where the interval between transmissions does not exceed ![]() seconds.
seconds.
At a high level, Remy Congestion Control (RemyCC) consists of a set of piecewise constant rules, called the Rule Table, where each rule maps a rectangular region of the observation space to a three dimensional action. On receiving an ACK, RemyCC updates its values for (ack_ewma, send_ewma, rtt_ratio) and then executes the corresponding action (b, a, ![]() ).
).
We now describe how these rules are generated:
Remy randomly generates millions of different network configurations by picking up random values (within a range) for the link rates, delays, the number of connections, and the on-off traffic distributions for the connections. At each evaluation step, 16 to 100 sample networks are drawn and then simulated for an extended period of time using the RemyCC algorithm. At the end of the simulation, the objective function given by equation 2 is evaluated by summing up the contribution from each connection to produce a network-wide number. The following two special cases were considered:
(3)
corresponding to proportional throughput and delay fairness and
(4)
which corresponds to minimizing the potential delay of a fixed-length transfer.
RemyCC is initialized with the following default rule that applies to all states: b=1, a=1, ![]() . This means that initially there is a single cube that contains all the states. Each entry in the rule table has an “epoch,” and Remy maintains a global epoch number initialized to zero.
. This means that initially there is a single cube that contains all the states. Each entry in the rule table has an “epoch,” and Remy maintains a global epoch number initialized to zero.
The following offline automated design procedure is used to come up with the rule table:
1. Set all rules to the current epoch.
2. Find the most used rule in this epoch: This is done by simulating the current RemyCC and tracking the rule that receives the most use. At initialization because there is only a single cube with the default rule, it gets chosen as the most used rule. If we run out of rules to improve, then go to step 4.
3. Improve the action for the most used rules until it cannot be improved further: This is done by drawing at least 16 network specimens and then evaluating about 100 candidate increments to the current action, which increases geometrically in granularity as they get further from the current value. For example, evaluate ![]() , while taking the Cartesian product with the choices for a and b. The modified actions are used by all sources while using the same random seed and the same set of specimen networks while simulating each candidate action.
, while taking the Cartesian product with the choices for a and b. The modified actions are used by all sources while using the same random seed and the same set of specimen networks while simulating each candidate action.
If any of the candidate actions lead to an improvement, then replace the original action by the improved action and repeat the search, with the same set of networks and random seed. Otherwise, increment the epoch number of the current rule and go back to step 2. At the first iteration, this will result in the legacy additive increase/multiplicative decrease (AIMD)–type algorithm because the value of the parameters a, b are the same for every state.
4. If we run out of rules in this epoch: Increment the global epoch. If the new epoch is a multiple of a parameters K, set to K=4, then go to step 5; otherwise, go to step 1.
5. Subdivide the most-used rule: Subdivide the most used rule at its center point, thus resulting in 8 new rules, each with the same action as before. Then return to step 1.
An application of this algorithm results in a process whereby areas of the state space that are more likely to occur receive more attention from the optimizer and get subdivided into smaller cubes, thus leading to a more granular action.
Figure 9.1 shows the results of a comparison of TCP Remy with legacy congestion control protocols (the figure plots the throughput averaged over all sources on the y-axis and the average queuing delay at the bottleneck on the x-axis). A 15-mbps dumbbell topology with a round trip of 150 ms and n=8 connections was used, with each source alternating between a busy period that generates an exponentially distributed byte length of 100 Kbytes and an exponentially distributed off time of 0.5 sec. RemyCC is simulated with the utility function in equation 3 and with three different values of ![]() , with higher values corresponding to more importance given to delay. The RemyCC algorithm that was generated for this system had between 162 and 204 rules.
, with higher values corresponding to more importance given to delay. The RemyCC algorithm that was generated for this system had between 162 and 204 rules.
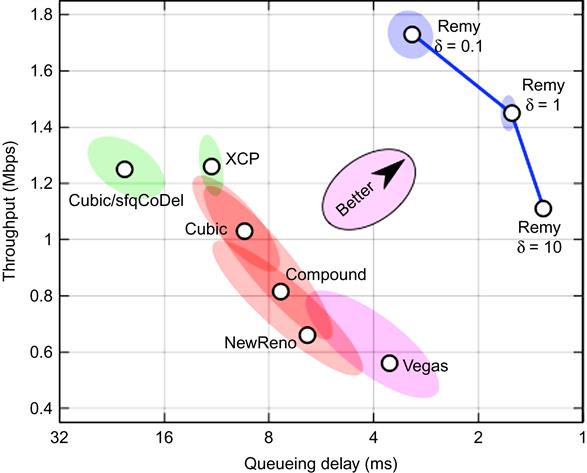
The results in Figure 9.1 show that RemyCC outperformed all the legacy algorithms, even those that have an AQM component, such as CUBIC over CoDel with stochastic fair queuing. Further experimental results can be found in Winstein [3].
Figure 9.1 also illustrates that existing congestion control algorithms can be classified by their throughput versus delay performance. Algorithms that prioritize delay over throughput, such as Vegas, lie in lower right hand corner, and those that prioritize throughput over delay lie in the upper left-hand part of the graph. The performance numbers for RemyCC trace an outer arc, which corresponds to the best throughput that can be achieved, for a particular value of the delay constraint. Thus, this framework provides a convenient way of measuring the performance of a congestion control algorithm and how close they are to the ideal performance limit.
Because of the complexity of the rules that RemyCC uses, so far the reasons of its superior performance are not well understood and are still being actively investigated.
9.3 Software Defined Networks and Congestion Control
Software Defined Networks were invented with the objective of simplifying and increasing the flexibility of the network control plane (NCP) algorithms such as routing and switching. In general, these algorithms are notoriously difficult to change because they involve the creation and maintenance of a network-wide distributed system model that maintains a current map of the network state and is capable of functioning under uncertain conditions in a wide variety of scenarios. Rather than running an instance of the NCP in every node, as is done in legacy networks, an SDN centralizes this function in a controller node. This leads to a number of benefits as explained below.
Figure 9.2 shows the basic architecture for an SDN network, which is made up of two principal components, namely OpenFlow-controlled switches and the SDN controller. Note that the NCP located in the controller is centralized and exists separately from the data plane located in the network switches. The controller communicates with the switches using an out-of-band communication network (shown with the dotted line) using the OpenFlow protocol.
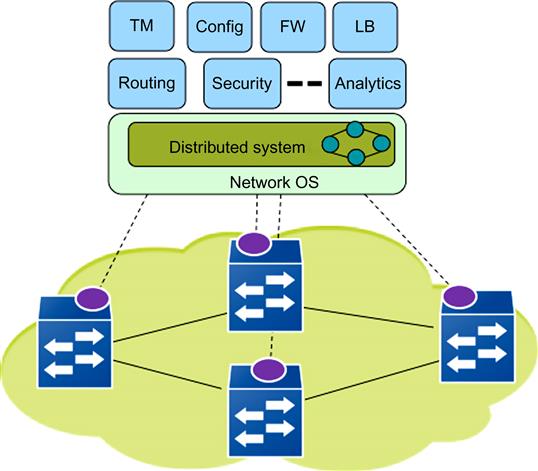
The SDN controller can be implemented in software on a standard server platform. It is implemented using a layered architecture, with the bottom layer called the Network Operating System (NOS) and the upper layer consisting of one or more applications, such as routing, that are used to control the OpenFlow switches. The NOS layer is responsible for managing the communications between the controller and the switches. In addition it also responsible for creating and maintaining a current topology map of the network. This topology map is exposed to the applications running in the controller on its northbound interface (Figure 9.2 shows some example applications running in the SDN network, such as Traffic Management (TM), Network Configuration (Config), Packet Forwarding (FW), and Load Balancing (LB)). As a result of this design, every control application shares a common Distributed System, unlike in current networks, where every application needs to implement its own Distributed System (e.g., the network map maintained by Layer 3 protocol such as OSPF is different from that maintained by a Layer 2 protocol such as Spanning Tree). Moreover, the problem of designing a distributed control algorithm is reduced to a pure software problem because the control algorithm can operate on the network abstraction created by the NOS rather than the real network.
Even though most of the initial work in SDNs has gone into the investigation of its impact on the NCP, researchers have begun to investigate ways in which it might be used to improve the operation of the data plane as well. We describe a couple of ways in which this can be done in Sections 3.1 and 3.2.
9.3.1 Using Software Defined Networks to Choose Active Queue Management Algorithms on a Per-Application Basis
In the discussion of the CoDel AQM algorithm in Chapter 4, we first introduced the notion that the most appropriate AQM algorithm is a function of the application, and this line of reasoning is developed further here. In general, based on their performance requirements, applications fall into the following three categories:
1. Throughput maximization: Applications in this category, such as File Transfer Protocol (FTP), are only interested in maximizing their data throughput, regardless of the latency.
2. Power maximization: Recall that the power of a connection was defined as a function of the average throughput Rav, and average latency Ts as
(5)
Applications such as video conferencing are interested in achieving a high throughput, but at the same time, they like to keep their latencies low. Hence, they belong to the power maximization category.
3. Minimization of Flow Completion Time (FCT): Web surfing (or HTTP transfer) is a typical application in this category, in which the transfer size is smaller compared with FTPs and the user is interested in minimizing the total time needed to complete a page download.
Note that throughput maximization for a connection also leads to FCT minimization; hence, the first and third categories are related. In the context of a network where both types of connections pass through a common link, the presence of the FTP connection can severely downgrade the FCT of a web page download if they both share a buffer at the bottleneck node. Ways in which this problem can be avoided are:
a. By using an AQM scheme such as CoDel to control the queue size at the bottleneck node: CoDel will keep the buffer occupancy and hence the latency low but at the expense of a reduction in the throughput in both the FTP and HTTP connection. This is not an ideal situation because the FTP connection has to give up some of its throughput to keep the latency for the HTTP connection down.
b. By isolating the FTP and HTTP connections at the bottleneck node into their own subqueues, by using a queue scheduling algorithm such as Fair Queuing: In this case, neither subqueue requires an AQM controller. The HTTP connection will only see the contribution to its latency caused by its own queue, which will keep it low, and the FTP connection can maintain a large subqueue at the bottleneck to keep its throughput up without having to worry about the latency. This is clearly a better solution than a).
If an FTP and video conferencing flow (as representatives of categories 1 and 2) share a bottleneck node buffer, then again we run into the same problem, that is, the queuing delay attributable to the FTP will degrade the video conferencing session. Again, we can use an AQM scheme at the node to keep the queuing delay low, but this will be at a cost of decrease in FTP throughput of 50% or more (see Sivaraman et al. [5]). A better solution would be to isolate the two flows using Fair Queuing and then use an AQM scheme such as CoDel only on the video conferencing connection.
From this discussion, it follows that the most appropriate AQM scheme at a node is a function of the application that is running on top of the TCP connection. By using fair queuing, a node can isolate each connection into its own subqueue and then apply a (potentially) different AQM scheme to each subqueue. Sivaraman et al. [5] propose that this allocation of an AQM algorithm to a connection can be done using the SDN infrastructure. Hence, the SDN controller can match the type of application using the TCP connection to the most appropriate AQM algorithm at each node that the connection passes through. Using the OpenFlow protocol, it can then configure the queue management logic to the selected algorithm.
The capability of dynamically reconfiguring the AQM algorithm at a switch does not currently exist in the current generation of switches and routers. These are somewhat inflexible because the queue management logic is implemented in hardware to be able to function at high speeds. Sivaraman et al. [5] propose that the queue management logic be implemented in an Field Programmable Gate Array (FPGA), so that it can be reconfigured by the SDN controller. They actually implemented the CoDel and RED AQM algorithms in a Xilinx FPGA, which was able to support a link speed of 10 Gbps, to show the feasibility of this approach. The other hurdle in implementing this system is that currently there is no way for applications to signal their performance requirements to the SDN controller.
9.3.2 Using Software Defined Networks to Adapt Random Early Detection Parameters
Recall from the analysis in Chapter 3 that a RED algorithm is stable (in the sense of not causing large queue fluctuations) for number of connections greater than N− and round trip latency less than T+, if the following conditions are satisfied:
(6)
Hence, a RED algorithm can become unstable if
• The number of connections passing through the link becomes too small, or
• The round trip latency for the connection becomes too big, or
One way in which instability can be avoided was described in Chapter 4, which is by using the Adaptive RED (ARED) algorithm that changes the parameter maxp as a function of the observed queue size at the node. We propose that another way of adapting RED is by making direct use of equation 6 and using the SDN controller to change RED parameters as the link conditions change.
Note that the number of connections N and the link capacity C are the two link parameters that influence the stability condition (equation 6), and the end-to-end latency T is a property of the connection path. As explained in Chapter 4, C is subject to large fluctuations in cellular wireless links; however, it may not be possible to do real-time monitoring of this quantity from the SDN controller. On the other hand, for wireline connections, C is fixed, and the only variables are N and T, which change relatively slowly. Moreover, the SDN controller tracks all active connections in the network as part of its base function, and hence it can easily figure out the number of active connections passing through each node. The round trip latency can be reported by applications to the SDN controller using a yet to be defined interface between the two.
Using these two pieces of information, the SDN controller can then use equation 6 to compute the values of Lred and K to achieve stability and thereby set the RED parameters maxp, maxth, minth, and wq. Following ARED, it can choose to vary only maxp while keeping the other parameters fixed, but it has more flexibility in this regard.
Another example of this is the use of the equation
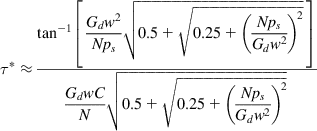
which gives the stability threshold for the QCN algorithm in Ethernet networks as a function of the link speed C, number of connections N and algorithm parameters (ps, w, Gd) (see Chapter 8, Section 8.5). As the number of connections N varies, the SDN controller can vary the algorithm parameters to maintain the stability threshold in the desired range.
9.4 The Google Congestion Control (GCC) Algorithm
The GCC algorithm [6,7] belongs to the category of congestion control algorithms that are used for real-time streams such as telephony and video conferencing. Delivery of real-time media is actually a fairly large subcategory in itself that is characterized the by following:
• Rather than TCP, real-time streams make use of the Real Time Transport Protocol (RTP) for transport, which is implemented on top of UDP. This is because reliable delivery is not as important as additional services provided by RTP, such as jitter compensation and detection of out-of-sequence frames.
• Unlike TCP, every RTP packet is not ACK’d. Instead, the receiver provides feedback by using the Real Time Control Protocol (RTCP). It generates periodic RTCP Receiver Report (RR) packets that are sent back to the source. These contain information such as number of received packets, lost packets, jitter, round trip delay time, and so on.
The information in the RTCP RR report is then used by the source to control its transmission rate. Traditionally, the TCP Friendly Rate Control Algorithm (TFRC) has been used for this purpose (see Floyd et al. [8] for a description of TFRC). This algorithm controls the transmit rate as a function of the loss event rate statistic that is reported by the receiver.
There are a number of problems in using TFRC in modern cellular networks, including:
• The packet loss rate in these networks is close to zero, as explained in Chapter 4, because of the powerful ARQ and channel coding techniques that they use. The only losses may be due to buffer overflow, but even these are very infrequent because of the large buffers in the base stations. Loss-based protocols such as TFRC tend to fill up the buffer, leading to unacceptably large delays.
• Cellular links are subject to large capacity variations, which lead to congestion in the form of the bufferbloat problem described in Chapter 4, which are not taken into account by TFRC.
The GCC algorithm is designed to address these shortcomings. It is part of the RTCWeb project within the IETF, which also includes other specifications to enable real-time audio and video communication within web browsers without the need for installing any plug-in or additional third-party software. GCC is available in the latest versions of the web browser Google Chrome.
The GCC algorithm tries to fully use the bottleneck link while keeping the queuing delay small. We came across the problem of minimizing queuing delays on a variable capacity link in the context of TCP in Chapter 4, where the solutions included using AQM techniques such as CoDel or end-to-end algorithms such as Low Extra Delay Background Transport (LEDBAT). The GCC algorithm belongs to the latter category since it does not require any AQM at the intermediate nodes. (Note that LEDBAT is not directly applicable here because it relies on the regular flow of TCP ACKs for feedback.) GCC uses a sophisticated technique using Kalman filters to figure out if the bottleneck queue is increasing or decreasing and uses this information to compute a number called the Receive Rate. It sends the Receive Rate back to the source in a special control packet called REMB, which then combines it with other information such as the packet loss rate to determine the final transmit rate.
The GCC algorithm is composed of two modules, one of which runs at the sender and the other at the receiver. These are described in the next two sections.
9.4.1 Sender Side Rate Computation
The sender combines several pieces of information to come up with the transmit rate, including the packet loss rate (as conveyed by the RTCP RR packets), the rate of an equivalent TFRC source, and the rates coming from the receiver in the REMB packets.
tk: Arrival time of the kth RTCP RR packet
tr: Arrival time of the rth REMB packet
Rs(tk): Sender transmit rate at time t=tk
Rr(tr): Receiver computed rate in the REMB message received t=tr
X(tk): Sending rate as computed using the TFRC algorithm at time t=tk
On receipt of the kth RTCP RR packet, the sender uses the following formula to compute its rate:
(7)
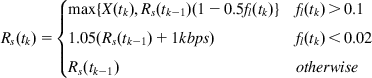 (7)
(7)The reasoning behind these rules is the following:
• When the fraction of lost packets exceeds 10%, then the rate is multiplicatively decreased but not below the equivalent TFRC rate.
• When the fraction of lost packets is less than 2%, then the rate is multiplicatively increased.
• When the packet loss rate is between 2% and 10%, then the rate is kept constant.
Hence, in contrast to TCP, the GCC sender does not decrease its rate even for loss rates as high as 10%, and actually increases the rate for loss rates under 2%. This is done because video streams are capable of hiding the artifacts created because of smaller packet loss rates.
When the sender receives the rth REMB packet, it modifies its sending rate as per the following equation:
(8)
9.4.2 Receiver Side Rate Computation
The novelty of the GCC algorithm lies in its receiver side rate computation algorithm. By filtering the stream of received packets, it tries to detect variations in the bottleneck queue size and uses this information to set the receive rate. It can be decomposed into three parts: an arrival time filter, an overuse detector, and a remote rate control.
9.4.2.1 Arrival Time Model and Filter
In the RTCWeb protocol, packets are grouped into frames, such that all packets in a frame share the same timestamp.
ti: Time when all the packets in the ith frame have been received
![]() : RTP timestamp for the ith frame
: RTP timestamp for the ith frame
Note that a frame is delayed relative to its predecessor if ![]() . We define the sequence di to be the difference between these two sequences, so that
. We define the sequence di to be the difference between these two sequences, so that
(9)
Variations in di can be caused by the following factors: (1) changes in the bottleneck link capacity C, (2) changes in the size of the video frame L, (3) changes in bottleneck queue size b, or (4) network jitter. All of these factors are captured in the following model for di:
(10)
Note that the network jitter process n(ti) has zero mean because the drift in queue size is captured in the previous term b(ti).
Using equation 10, GCC uses a Kalman filter (see Appendix 9.A) to obtain estimates of the sequences C(ti) and b(ti) and then uses these values to find out if the bottleneck queue is oversubscribed (the queue length is increasing) or undersubscribed. The calculations are as follows:
Define ![]() as the “hidden” state of the system, which obeys the following state evolution equation:
as the “hidden” state of the system, which obeys the following state evolution equation:
(11)
where ui is a white Gaussian noise process with zero mean and covariance Qi.
From equation 10, it follows that the observation process di obeys the following equation
(12)
where ![]() and vi is a white Gaussian noise process with zero mean and variance Si.
and vi is a white Gaussian noise process with zero mean and variance Si.
Let ![]() be the sequence representing the estimate for
be the sequence representing the estimate for ![]() . From Kalman filtering theory, it follows that
. From Kalman filtering theory, it follows that
(13)
where Ki is the Kalman gain given by
(14)
The variance Si is estimated using an exponential averaging filter modified for variable sampling rate, as
Qi is chosen to be a diagonal matrix with the main diagonal elements given by
These filter parameters are scaled with the frame rate to make the detector respond as quickly to low frame rates as at high frame rates.
9.4.2.2 Remote Rate Control
Assuming that the last packet in the ith frame is received at time ti, the receiver computes the rate Rr(ti) according to the following formula:
(15)
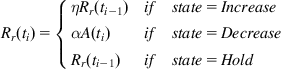 (15)
(15)where ![]() ,
, ![]() and A(ti) is the receiving rate measured in the last 500 ms. Also, the Rr(ti) cannot exceed 1.5*A(ti) in order to prevent the receiver from requesting a bitrate that the sender cannot satisfy.
and A(ti) is the receiving rate measured in the last 500 ms. Also, the Rr(ti) cannot exceed 1.5*A(ti) in order to prevent the receiver from requesting a bitrate that the sender cannot satisfy.
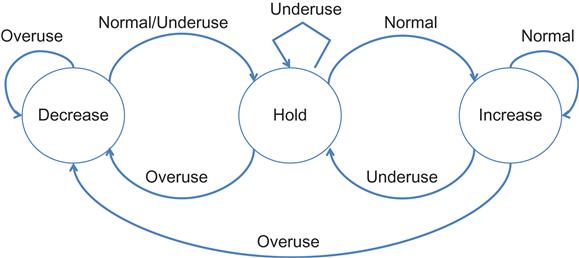
Note that the rates are controlled by the state of the Finite State Machine (FSM) in Figure 9.3, which is called the Remote Rate Controller. The state of this FSM is changed according to the signal produced by the Overuse Detector, which is based on the output of the Arrival Time Filter, as follows:
• If ![]() increases above a threshold and keeps increasing for a certain amount of time or for a certain amount of consecutive frames, it is assumed that the network is congested because the bottleneck queue is filling up, and the “overuse” signal is triggered.
increases above a threshold and keeps increasing for a certain amount of time or for a certain amount of consecutive frames, it is assumed that the network is congested because the bottleneck queue is filling up, and the “overuse” signal is triggered.
• If ![]() decreases below a threshold, this means that the bottleneck queue is being emptied. Hence, the network is considered underused, and the “underuse” signal is generated. Upon this signal, the FSM enters the Hold state, where the available bandwidth estimate is held constant while waiting for the queues to stabilize at a lower level.
decreases below a threshold, this means that the bottleneck queue is being emptied. Hence, the network is considered underused, and the “underuse” signal is generated. Upon this signal, the FSM enters the Hold state, where the available bandwidth estimate is held constant while waiting for the queues to stabilize at a lower level.
• When ![]() is close to zero, the network is considered stable, and the “normal” signal is generated.
is close to zero, the network is considered stable, and the “normal” signal is generated.
The REMB messages that carry the value of Rr from the receiver to the sender are sent either every 1 sec if Rr is decreasing or immediately if Rr decreases more than 3%.
Appendix 9.A Kalman Filtering
Consider a linear system, with an n×1 dimensional state variable xt, which evolves in time according to the following equation:
(F1)
where ut is a m×1 dimensional control vector driving xt, At is a square matrix of size n×n, Bt is n×m matrix, and ![]() is a n×1 Gaussian random vector with mean 0 and covariance given by Rt. A state transition of the type (F1) is known as linear Gaussian to reflect the fact that it is linear in its arguments with additive Gaussian noise.
is a n×1 Gaussian random vector with mean 0 and covariance given by Rt. A state transition of the type (F1) is known as linear Gaussian to reflect the fact that it is linear in its arguments with additive Gaussian noise.
The system state xt is not observable directly; its value has to be inferred through the k×1 dimensional state observation process zt given by
(F2)
where Ct is k×n dimensional matrix and ![]() is the observation (or measurement) noise process. The distribution of
is the observation (or measurement) noise process. The distribution of ![]() is assumed to be multivariate Gaussian with zero mean and covariance Qt.
is assumed to be multivariate Gaussian with zero mean and covariance Qt.
The Kalman filter is used to obtain estimates of the state variable xt at time t, given the control sequence ut and output sequence zt. Because xt is a Gaussian random variable, the estimates are actually estimates for its mean ![]() and covariance
and covariance ![]() at time t.
at time t.
The Kalman filter uses an iterative scheme, which works as follows:
1. At time t=0, start with initial estimates for the mean and covariance of xt given by ![]() .
.
2. At time t–1, assume that the estimates for the mean and covariance of xt−1 have been computed to be ![]() . Given the control ut and output zt at time t, the estimates
. Given the control ut and output zt at time t, the estimates ![]() are computed recursively as follows, in two steps.
are computed recursively as follows, in two steps.
3. In step a, the control ut is incorporated (but not the measurement zt), to obtain the intermediate estimates ![]() given by
given by
(F3)
(F4)
4. In step b, the measurement zt is incorporated to obtain the estimates ![]() at time t, given by
at time t, given by
(F5)
(F6)
(F7)
The variable Kt computed in equation F6 is called the Kalman gain, and it specifies the degree to which the new measurement is incorporated into the new state estimate.