
Software-level task scheduling on GPUs
B. Wu1; X. Shen2 1 Colorado School of Mines, Golden, CO, United States
2 North Carolina State University, Raleigh, NC, United States
Abstract
Task scheduling is critical for exploiting the full power of multicore processors such as graphics processing units (GPUs). Unlike central processing units, GPUs do not provide necessary APIs for the programmers or compilers to use to control scheduling. On the contrary, the hardware scheduler on modern GPUs makes flexible task scheduling difficult. This chapter presents a compiler and runtime framework with the capability to automatically transform and optimize GPU programs to enable controllable task scheduling to the streaming multiprocessors (SMs). At the center of the framework is SM-centric transformation, which addresses the complexities of the hardware scheduler and provides the scheduling capability. The framework presents many opportunities for new optimizations, of which this chapter presents three: parallelism, locality, and processor partitioning. We show in extensive experiments that the optimizations can substantially improve the performance of a set of GPU programs in multiple scenarios.
Keywords
Scheduling; GPGPU; Data affinity; Compiler transformation; Program co-run; Resourcepartitioning
Acknowledgments
This material is based upon work supported by the National Science Foundation under Grant No. 1464216. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
1 Introduction, Problem Statement, and Context
Graphics processing units (GPUs) integrate thousands of cores onto a single chip and support the simultaneous execution of tens of thousands of threads. This massive parallelism greatly improves peak throughput compared to central processing units (CPUs). However, the sustainable performance for many GPU applications, especially data-intensive applications, is below 30% of the peak throughput [1–5]. One source of such inefficiency comes from the difficulty of scheduling the huge number of threads.
Thread scheduling comprises two dimensions: temporal scheduling and spatial scheduling. Temporal scheduling decides when the threads should run; spatial scheduling decides where the threads should run. On CPUs, many studies explored both dimensions and showed scheduling’s central role for tapping into the full power of processors [6–10] and for enforcing fairness for co-running applications [11–13]. The operating system provides flexible APIs to bind CPU threads to specific cores, which serve as the building blocks to apply various software-level scheduling strategies. However, scheduling on the GPU is complicated by the thread hierarchy: Some threads compose a warp, some warps compose a thread block (i.e., a CTA)1 and some thread blocks compose a grid. The threads in a grid execute the same kernel function. The hardware scheduler, despite being able to quickly schedule thread blocks to processors, cannot be controlled by compilers or programmers. Furthermore, the mechanism of the scheduler is not disclosed, which manifests obscure and nondeterministic behaviors.
The hardware scheduler on modern GPUs makes suboptimal decisions in both the temporal and spatial dimensions, seriously slowing down various applications, as shown in previous research [2, 14, 15]. In the temporal dimension, the hardware scheduler always schedules thread blocks, each of which contains the same number of threads and represents a unit for scheduling, to GPU processors, whenever there are enough hardware resources—such as registers and shared memory—to support their execution. The rationale behind such a greedy scheduling strategy is that a higher level of utilization should lead to better performance. Unfortunately, as previous work showed [14], the greedy scheduling approach results in up to 4.9× increase in performance degradations on a set of applications, because all the threads compete for memory bus accesses or data caches, slowing down each other’s performance. In the spatial dimension, the hardware scheduler randomly distributes thread blocks to processors, ignoring the different amounts of data sharing among them. Such arbitrary schedules forfeit some locality optimizations. For example, an NVIDIA Tesla M2075 GPU contains 14 streaming multiprocessors (SMs), each having a private data cache. If some thread blocks share a common data set, scheduling them to the same SM may improve data reuse significantly, because some blocks may act as data prefetchers for others.
In this chapter, we describe a framework consisting of a code transformation component (SM-centric transformation) and three optimizations enabled by it. The SM-centric transformation comprises two techniques. The first technique, SM-based task selection, breaks the mapping between thread blocks and tasks, but directly associates tasks to GPU processors. In a traditional GPU kernel execution, with or without persistent threads, what task a thread block executes is usually based on the block’s ID; whereas with SM-based task selection, what task a thread block executes is based on the ID of the SM that the block runs on. By replacing the binding between tasks and threads with the binding between tasks and SMs, the scheme enables a direct, precise control of task placement on the SM.
The second technique is a filling-retreating scheme, which offers flexible control of the number of concurrent thread blocks on an SM. Importantly, the control is resilient to the randomness and obscuration in GPU hardware thread scheduling. It helps SM-centric transformation in two aspects. First, it ensures an even distribution of active threads across SMs for load balancing. Second, it facilitates online determination of the parallelism level suitable for a kernel, which not only helps kernels with complicated memory reference patterns but also benefits multiple kernel co-runs.
The optimizations, namely parallelism control, affinity-based scheduling, and SM partitioning, are enabled by the flexible scheduling support and are made applicable to off-the-shelf GPUs. The central challenges are to find the optimal task scheduling parameters in both spatial and temporal dimensions to optimize parallelism, data locality, and hardware resource allocation. We present both static and dynamic analysis to efficiently search for the appropriate parameters for each optimization or their combinations.
In the remainder of this chapter, we first show the complexities from the hardware scheduler and then describe the detailed idea and implementation of SM-centric transformation, which circumvents the complexities. We then show two use cases that benefit from the three optimizations, together with some evaluation results. Finally, we draw a conclusion.
2 Nondeterministic behaviors caused by the hardware
Although a software-level control may enable interesting optimizations, modern hardware scheduler design, however, presents a set of complexities. What makes the scheduling-based optimizations harder is that the scheduling mechanism is never disclosed. Nevertheless, our investigations [16–18] showed that the GigaThread engine in NVIDIA Fermi GPUs [19] has the following properties.
2.1 P1: Greedy
The scheduler always distributes thread blocks to an SM if that SM has enough hardware resources to support the blocks’ execution. This design choice is not surprising, as the design philosophy of GPUs is to hide memory access latency through multithreading among a large number of threads. It has been shown that achieving high occupancy (i.e., the number of active threads on a device) is one of the key factors to obtaining high performance for streaming applications [20, 21]. However, as GPU computing went mainstream, its scope expanded quickly, covering many more domains, such as data mining [22, 23], machine learning [24, 25], database [26, 27], and graph analytics [28–32]. A common characteristic of those applications is their strong reliance on efficient data cache performance. Unfortunately, the greedy scheduling always tries to achieve the highest level of utilization, which may degrade cache performance significantly due to cache contention.
2.2 P2: Not Round-Robin
Various studies [3, 5, 33, 34] assumed that the mapping between thread blocks and SMs is round-robin style. That is, the ith thread block should be scheduled with the (i mod M)th SM, where M represents the number of SMs. However, our investigation shows that this common perception does not hold. For example, in an execution of MD (a benchmark for molecular dynamics simulation from the SHOC [35] benchmark suite) on a 14-SM NVIDIA M2075 GPU, we generated 14 thread blocks but found that one SM obtained 2 thread blocks, while another SM got no thread blocks. This property leads to serious load balancing problems for persistent threads, as the generated small number of threads do not utilize the SMs evenly.
2.3 P3: Nondeterministic Across Runs
Even with the same input, the mapping between thread blocks and SMs may change across executions of the same program. As such, it is not feasible to rely on traditional techniques, such as offline profiling and intelligent data-to-thread block mapping, to explore the benefits.
2.4 P4: Oblivious to Nonuniform Data Sharing
In many applications, the data sharing among threads is nonuniform. For instance, in MD the simulated atoms form neighborhood relations with one another according to their positions. The processing of one atom needs to access its neighbors. Therefore, if two groups of atoms have many of the same neighbors, the thread blocks, which process those atoms, share a lot of data. Scheduling these blocks to the same SM would enhance the private data cache performance because of efficient data reuses. Unfortunately, the scheduler is oblivious to the nonuniform data sharing among thread blocks, as shown in Wu et al. [17].
2.5 P5: Serializing Multikernel Co-Runs
Fermi and newer generation GPUs support concurrent kernel executions. However, if the number of thread blocks exceeds the maximum number of supported concurrent thread blocks, the executions of different kernels are serialized [15]. As shown in multiple studies [14, 15, 36], this property forfeits optimizations on enforcing fairness, exploiting nonuniform frequencies of SMs and handling different scaling properties of the co-run kernels.
In the next section, we present compiler and runtime techniques to circumvent these complexities for a flexible software-level task scheduler.
3 SM-centric transformation
3.1 Core Ideas
3.1.1 SM-centric task selection
We present a code transformation technique to enable spatial scheduling. It is based on the observation that what matters is the mapping between tasks and processors rather than that the mapping between thread blocks to processors. The transformation binds tasks to SMs instead of thread blocks as in traditional GPU programming. We illustrate the basic idea by using an abstract model of GPU kernel executions.
The GPU threads are organized in a hierarchy. Many threads compose a thread block; many thread blocks compose a grid. We view a thread block as a worker, which needs to finish a task. As Fig. 1A shows, in the original kernel, a worker uses its ID to select a task to process. Persistent threads, as illustrated in Fig. 1B, breaks the mapping between workers and tasks. It creates one shared task queue, containing all tasks that should be processed. When a worker is scheduled for execution, it fetches a task in the queue. Because the thread block scheduling is not round-robin and nondeterministic (P2 and P3), persistent threads cannot enable spatial scheduling, as they cannot control the mapping between workers and SMs.

The central idea of SM-centric task selection is to directly map tasks to SMs. As shown in Fig. 1C, it creates a task queue for each SM (the tasks in the queues depend on optimizations and will be discussed in Section 4). A worker first retrieves the ID of its host SM2 and then uses it to fetch a task in the corresponding queue. The association of a task to a specific SM is simple: just place the ID of that task to the preferred task queue. Note that the transformation introduces extra overhead (around 1–2% of the original kernel execution time), which, as will be shown in Section 4, is usually outweighed by the performance benefits.
Correctness issues
The idea is straightforward. One worker processes exactly one task from a queue of the SM it runs on. However, since block scheduling is nondeterministic, it causes a correctness issue: The task queue is created before the kernel’s invocation, but an SM may not obtain enough workers to process all tasks in its queue. For example, on a NVIDIA Tesla M2075 card of 14 SMs, a kernel’s execution creates 1400 tasks (i.e., thread blocks) evenly distributed in 14 queues. However, the number of workers scheduled to each SM varies from 92 to 110. The SMs, which obtained less than 100 workers, could not finish all tasks, leading to incorrect results.
To address these issues, as well as provide temporal scheduling support, we propose a second technique to complement SM-centric task selection.
3.1.2 Filling-retreating scheme
The correctness issue comes from the mismatch between the number of assigned tasks and the number of distributed thread blocks to an SM. The one-to-one mapping between tasks and thread blocks requires that the number of thread blocks should be no less than the assigned tasks. The basic idea of filling-retreating is to run a small number of workers on each SM, which keep fetching and processing tasks in the task queues until all tasks are finished.
There are two challenges to realizing the idea. First, how can each SM run the same number of workers on each SM? This is important for load balancing but is hard to enforce because of P2 (the randomness of the hardware-controlled scheduling). Second, how can the exact number of workers on each SM be specified? As discussed in Section 2, the highest level of parallelism may not lead to the optimal performance. The flexibility to set the number of workers on each SM is critical for several optimizations, as shown in Section 4.
The solution leverages the P1 (Greedy) nature of the hardware scheduler. Since the scheduler always distributes thread blocks to SMs as long as the remaining hardware resource permits, we generate only the number of workers the GPU can accommodate at the same time. This can be easily done by analyzing the generated parallel thread execution (PTX) code (i.e., assembly code for CDUA devices) to obtain the hardware resources that one thread block’s execution requires. We hence guarantee that each SM runs the maximum number of concurrent workers. This process is called Filling.
To precisely control the number of concurrent workers on each SM, we stop some workers by using atomic operations, as illustrated in Fig. 2. We maintain a global variable for each SM to record how many workers have been distributed to it. Whenever a worker begins execution, it first figures out its host SM and updates the corresponding variable through an atomic increase. If the number of workers already exceeds a predefined threshold, that worker immediately exits its execution. Otherwise, the worker belongs to the set of active workers, which should process the tasks.

The simple design of the filling-retreating scheme not only solves the correctness issue raised by SM-centric task selection but also provides the flexibility to control the exact number of concurrent workers on each SM.
3.2 Implementation
Thanks to its simplicity, we can easily apply SM-centric transformation either manually or through a compiler. We extend the Cetus [37] compiler to include SM-centric transformation as a pass to transform CUDA code. Before showing its full details, we next highlight two important considerations in the design.
First, although the while loop in Fig. 2 illustrates the basic idea of SM-centric transformation, it has serious performance problems: Its dequeue operation involves an atomic operation in each iteration. All these atomic operations are serialized as they access the same global variable. We circumvent this problem by parallelizing the atomic operations over the SMs. According to the design of the filling-retreating scheme, each SM processes exactly W jobs. If an SM is supposed to concurrently run L workers, a worker should then process W/L jobs. We put the index range of the jobs assigned to an SM into a global index array in which each worker running on that SM can obtain the beginning and ending indices of its section of jobs. When a worker is distributed to an SM, it first checks whether the SM already obtains enough workers via an atomic operation. Hence, different SMs modify different global variables, providing better performance than the original design. Based on this idea, we transform the code to be something like lines 9–16 in Listing 1. Each worker, if needed by the SM, attains the starting and ending indices in the index array and processes corresponding jobs.
Second, we leverage the property of C-like features of CUDA to efficiently obtain the IDs of SMs. We insert PTX code, which is similar to assembly code, into the CUDA program. As shown in line 27 in Listing 1, one “mov” instruction copies the value in a register %smid, which stores the SM ID, to an integer variable.


3.2.1 Details
On GPUs, a CTA is the unit for spatial scheduling. Since a CTA processes a job chunk in the original program, the thread ID is used to distinguish jobs. Our design concerns the distribution of jobs to SMs, thereby assigning job chunks as units to SMs.
We encapsulate SM-centric transformation into four macros to minimize changes on the original GPU program. Listing 2 shows the application of the macros on the CPU-side code. The macro __SMC_init is inserted before the invocation of the GPU kernel to initialize the transformation, such as filling up the index array. Note that we append three arguments to the kernel call in order to pass in necessary information for the job assignment. The change to the kernel code is also minimal. Two macros, __SMC_Begin and __SMC_End, are inserted at the beginning and end of the kernel code, respectively. We also replace the appearance of the ID of the CTA with __SMC_chunkID. Our compiler can easily transform the code in one pass.
The preceding four macros are defined in Listing 1. The first macro, __SMC_init, initiates the three variables with the number of needed workers on each SM, the index array to indicate job chunks, and an all-zero counter array to count active workers. The functions used to initiate the first two variables depend on specific optimizations, which can be provided by the programmer or the optimizing compiler/runtime. __SMC_Begin obtains the SM ID of the host SM by calling the fourth macro and checks whether the SM already has enough active CTAs; then it obtains the section of job chunks the CTA should work on if it is active. The third macro, __SMC_End, just appends the ending bracket of the for loop in the second macro for syntax correctness.
4 Scheduling-enabled optimizations
Flexible scheduling removes restrictions from hardware and opens opportunities for many optimizations. We investigate three novel optimizations not previously applicable on modern GPUs. We describe their basic ideas and main challenges to bring them to realization, as well as some experiment results.
4.1 Parallelism Control
The many cores on GPUs can accommodate a large number of threads, which on one hand hides memory latency through multithreading, but on the other hand competes for limited hardware resources—such as private or shared data cache. Several studies have shown that cache performance is critical for many GPU applications [5, 38, 39]. However, a GPU’s scheduler always tries to achieve the maximum parallelism, while, as Kayiran et al. [14] show in simulations, choosing the appropriate level of parallelism results in a speedup of around five times that of the default speed.
By limiting the number of concurrent thread blocks on the GPU, our scheduling framework enables flexible control of parallelism. The main challenge is to find the optimal number of concurrent thread blocks to maximize performance. Since most benchmarks invoke the same kernel many times, we leverage a typical hill-climbing process in the first several invocations. For example, given M as the maximum allowed concurrent thread blocks on an SM, we first run M thread blocks on each SM for the first invocation and decrease the number by one for each following invocation. We stop once we observe decreased performance.
Because of limited space, we show the evaluation results of parallelism control with the other two optimizations in the following sections.
4.2 Affinity-Based Scheduling
Many scientific applications (e.g., molecular dynamic simulation and computational fluid dynamic) and graph algorithms have complicated memory reference patterns. As such, the threads often manifest nonuniform data sharing among threads: some tasks share a lot of data, while some other tasks share no data. With flexible scheduling support, to better utilize the private data cache, we can schedule the tasks that share more data to the same SM and set them as data prefetchers for each other.
We present a graph-based approach to model the nonuniform data sharing and an efficient partitioning algorithm for the task assignment. In the graph construction stage, we establish an affinity graph, in which a vertex represents a task and the weight of an edges represents the affinity score between two tasks. Affinity score is defined as follows. Let S1 and S2 be the set of cache lines accessed by two tasks T1 and T2, respectively. Their affinity score is defined as ![]() . For instance, three tasks (A, B, and C) of a kernel each access 10 cache lines during their execution. The number of overlapped cache lines for A and B is 2, while this number is 4 and 6 for the task pairs B and C, and A and C, respectively. We have affinity_score(A,B) = 2/18, affinity_score(B,C) = 4/16, and affinity_score(A,C) = 6/14. There is no edge between two vertices when their affinity score is less than a threshold (0.05 in the experiments). It is hence possible to have multiple disconnected subgraphs, which makes the next stage more efficient.
. For instance, three tasks (A, B, and C) of a kernel each access 10 cache lines during their execution. The number of overlapped cache lines for A and B is 2, while this number is 4 and 6 for the task pairs B and C, and A and C, respectively. We have affinity_score(A,B) = 2/18, affinity_score(B,C) = 4/16, and affinity_score(A,C) = 6/14. There is no edge between two vertices when their affinity score is less than a threshold (0.05 in the experiments). It is hence possible to have multiple disconnected subgraphs, which makes the next stage more efficient.
With the established affinity graph, the goal is to partition the tasks to SMs. Graph partitioning is an NP-complete problem in general. Most existing graph partitioning algorithms are quite costly, as they prefer high-quality partitioning. However, for online use, the overhead can easily outweigh the benefit. Therefore we design an algorithm to carefully balance the partitioning overhead and quality. The algorithm has three steps. The first step is seed selection. Let C denote the number of disconnected subgraphs in the affinity graph and M the number of SMs. If C ≥ M, we random select M vertices as seeds, each in a different subgraph. If C < M, we randomly select a vertex in each subgraph and iterate the remaining vertices for the remaining M − C seeds. In each iteration, we include the vertex if its affinity score for any seed is less than or equal to a threshold. We stop the iteration once we have M seeds. Initially, we set the threshold as 0 and increase it by 0.1 if we find less than M seeds. At most, we increase the threshold by 10 times to successfully select M seeds, but usually no more than two rounds is needed. The second step is sorted list creation, which, for each seed, creates a sorted list of all remaining vertices according to their affinity score to that seed. The third step, cluster enlargement, repetitively iterates all the sorted lists. In each iteration, it draws the vertex, whose affinity score with the corresponding seed is the largest, to join the same cluster. The process stops once all vertices are partitioned.
4.2.1 Evaluation
We experiment with a NVIDIA M2075 GPU hosted by an Intel 8-core Xeon X5672 machine with 48 GB of main memory. We run a 64-bit Redhat Enterprise 6.2 Linux operating system with a 4.2 CUDA runtime. We repeat each experiment 10 times and report the average.
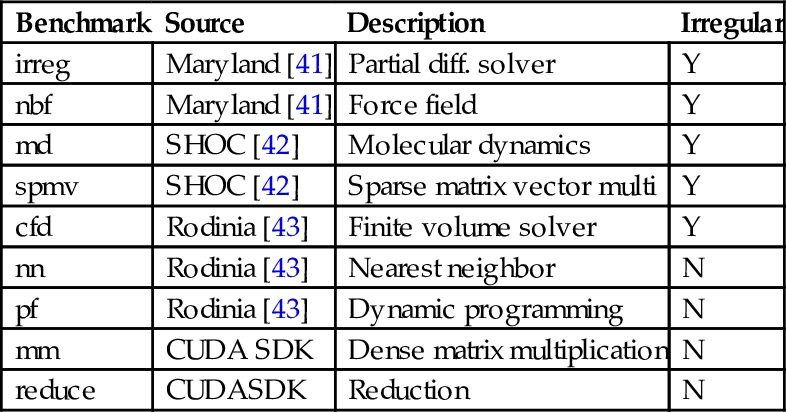
We adopt four commonly used irregular benchmarks to evaluate both parallelism control and affinity-based scheduling. We give a very brief description of the benchmarks. IRREG is extracted from a partial differential solver. NBF is the key component of molecular dynamics simulation. These two benchmarks were rewritten from C to CUDA. SPMV calculates sparse matrix vector multiplication, which comes from the SHOC benchmark suite. CFD, from the RODINIA benchmark suite, simulates fluid dynamics.
We compare SM-centric transformation to persistent threads. Persistent threads run a fixed number of concurrent thread blocks through the whole execution. The difference is that persistent threads, because of the complexity from the hardware scheduler described in Section 2, cannot bind threads and hence tasks to specific SMs. To enable affinity-based scheduling with persistent threads, we generate M (the number of SMs) persistent thread blocks and make sure the thread block size is the maximum size supported by the hardware resources. The tasks partitioned to the same SM are consumed by the same thread block.
Fig. 3A shows the performance results. The baseline is the original benchmark. Persistent threads without affinity-based scheduling suffers a 22% performance degradation caused by insufficient parallelism and poor data sharing among tasks running on the same SM. Affinity-based scheduling helps persistent threads by reducing its slowdown to 11%. The results show that persistent threads cannot balance locality and parallelism well. Though running only one thread block on one SM improves locality, the benefit is not enough to compensate for the degradation caused by insufficient parallelism. SM-centric transformation, together with affinity-based scheduling, runs multiple thread blocks on an SM, which execute tasks with a great affinity for data. On average, it brings a 21% speedup over the baseline. It is worth noticing that CFD is an anomaly, for which persistent threads with affinity-based scheduling produce the best result. A plausible reason is that warp scheduling affects the performance significantly, but neither approach has any control over it.
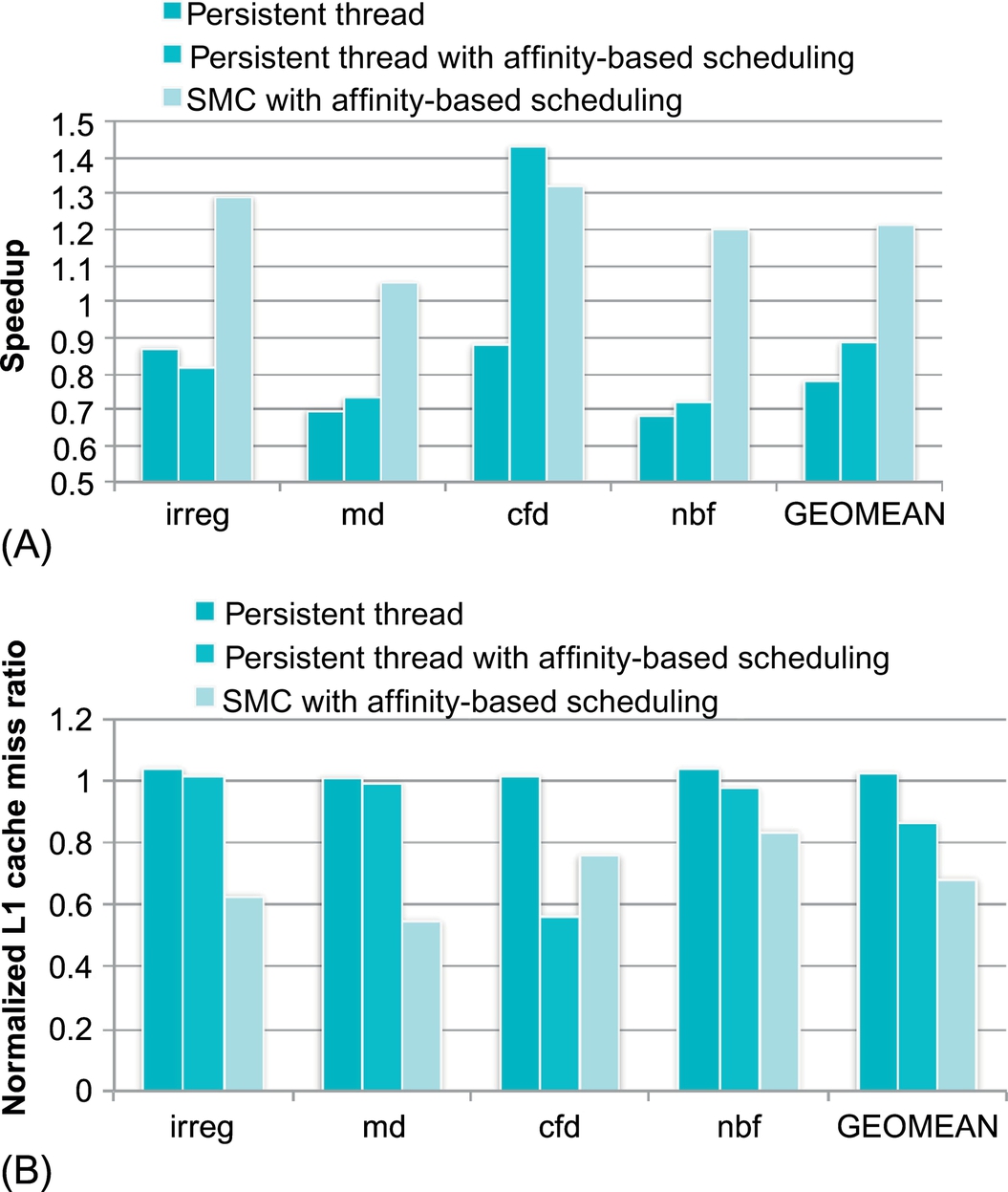
Fig. 3B shows normalized L1 cache miss ratios collected through the CUDA hardware performance monitor. The trend aligns well with the performance results, which confirms that the improved performance of L1 cache is the main contributor to the gain in performance.
4.3 SM Partitioning for Multi-Kernel Co-Runs
Modern GPUs are embracing more features from CPUs to target general purpose computing, in which an important one is multiprogram co-runs. Although GPUs do not support the concurrent execution of different programs yet, they can support multikernel co-runs in the same execution context (i.e., within the same program). Unfortunately, as Sreepathi et al. [15] showed, the executions of different kernels are often serialized, because GPU applications typically generate a large number of thread blocks, but the GPU can accommodate only a small portion of them at the same time. The serialization hence impedes fairness among the concurrent kernels. Moreover, Adriaens et al. [2] showed by simulation that the GPU kernels usually differ significantly in terms of computation and memory access intensity. Simultaneously co-running kernels with different properties may significantly improve overall system throughput (STP), but the serialization resulting from the hardware scheduler design sets an obstacle for us to explore.
With the spatial scheduling support from SM-centric transformation, we can easily partition SMs to kernels, avoiding the serialization. Given two co-run kernels, K1 and K2, we can assign the first M1 SMs to execute tasks of K1 and the remaining M2 SMs to K2, where M1 + M2 = M. We launch both kernels using two CUDA streams, respectively. When a thread block is distributed to an SM, it first obtains the SM ID to see whether it is supposed to execute the corresponding kernel. If so, the thread block continues execution. Otherwise, the block terminates immediately. Note that even if the original kernel has a large number of thread blocks, the filling-retreating scheme maintains a small number of thread blocks on an SM partition to process all their corresponding tasks.
The central challenge then is how to find the optimal partition (the number of SMs allocated to each specific kernel), which is further complicated when we also consider parallelism control. For 2 kernels on a 14-SM GPU, if an SM supports at most 6 active thread blocks, the search space contains 6 × 6 × 14 = 504 cases.
We use a simple sampling approach to search for an optimal (suboptimal) configuration online. The process contains two stages. The first stage tries to find the best level of parallelism, which is the same as described in Section 4.1, except that we need to take care of two kernels simultaneously. In the second stage, we fix the number of concurrent CTAs and assign a different number of SMs to one co-run kernel, which increases from 1 to M − 1 with a stride of 3. All remaining SMs are partitioned to the other kernel.
4.3.1 Evaluation
Since current GPUs do not support more than one execution context, we combine the kernels of two different programs into one, which are executed by two different streams. To cover various co-run scenarios, we experiment with every pair out of the selected nine benchmarks, as shown in Table 1. We use two metrics, STP and average normalized turnaround time (ANTT), to consider both overall throughput and responsiveness. These two metrics are defined in the equations [40]
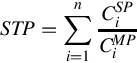
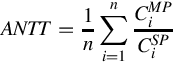
where n is the number of co-running kernels and ![]() and
and ![]() are the execution times of single-run and co-run of program i, respectively.
are the execution times of single-run and co-run of program i, respectively.
Table 1
Benchmarks
| Benchmark | Source | Description | Irregular |
| irreg | Maryland [41] | Partial diff. solver | Y |
| nbf | Maryland [41] | Force field | Y |
| md | SHOC [42] | Molecular dynamics | Y |
| spmv | SHOC [42] | Sparse matrix vector multi | Y |
| cfd | Rodinia [43] | Finite volume solver | Y |
| nn | Rodinia [43] | Nearest neighbor | N |
| pf | Rodinia [43] | Dynamic programming | N |
| mm | CUDA SDK | Dense matrix multiplication | N |
| reduce | CUDASDK | Reduction | N |
Since we are only interested in the overlapped execution, we launch the two co-run kernels together and restart a kernel once it is finished. The process stops when both kernels are executed at least seven times. Note that we discard the last instance of the kernel, which is finished after the seven invocations of the other kernel, as its execution is not fully overlapped.
We still compare SM-centric transformation with persistent threads because the latter can indirectly partition SMs to the two kernels. We launch M thread blocks of the largest possible size and assign P CTAs to execute the tasks of one kernel and the remaining M − P ones for the other kernel. Because of the randomness of hardware scheduling, it is not guaranteed that each SM obtains exactly one CTA. We run the experiments multiple times until each SM happens to obtain one CTA. We enumerate all possible choices for P and report the best performance to compare with SM-centric transformation.
Fig. 4 shows the speedups defined as the ratio between the original ANTT and the optimized ANTT. To obtain the original ANTT, we run the co-running kernels in the default way: each original kernel is executed by a separate CUDA stream. “SMC Predicted” and “SMC Optimal” represent the speedups brought by SM-centric transformation using predicted configurations and optimal configurations, respectively. We obtain the optimal configuration by exhaustively searching the entire space. We observe that the potential performance gain from SM-centric transformation is around 38%. Our prediction successfully exploits most of the benefit by producing 1.36× speedup on average. The performance, however, varies greatly across benchmarks from 2.35× speedup to a 2% slowdown. The benchmarks cannot benefit much from SM partitioning and parallelism control for two reasons. First, the original scalability is already good with few wasted computational resources. Second, the benchmarks are not sensitive to cache-level locality improvement because of the small amount of data reuses. Persistent threads, on the other hand, slow down the benchmarks by around 18% on average. To enable SM partitioning, persistent threads can support only concurrent execution of M thread blocks, which is not sufficient to fully leverage the many GPU cores.
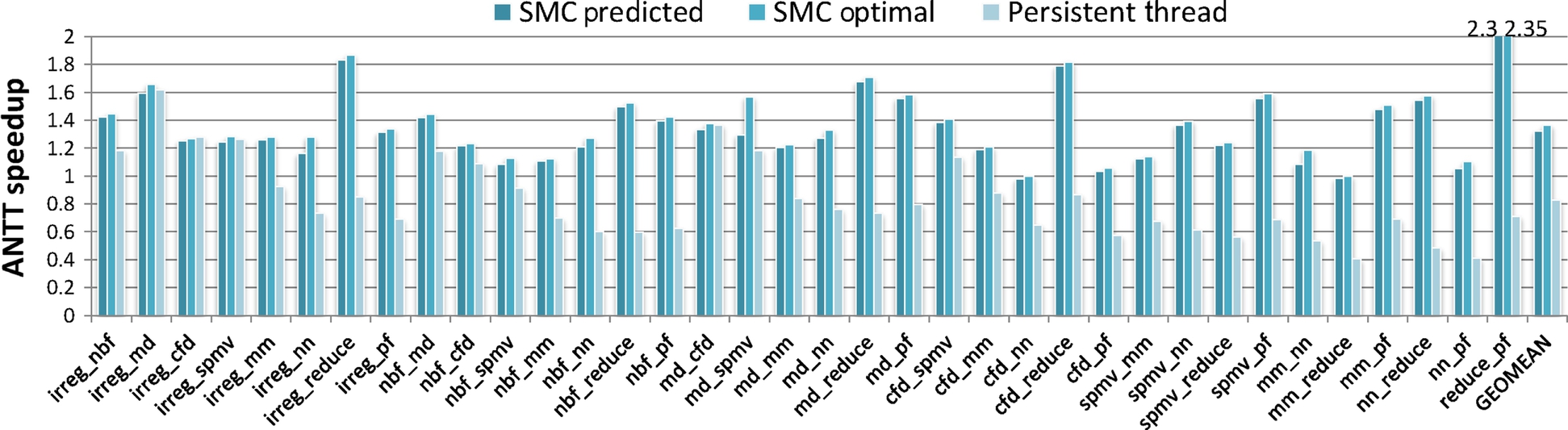
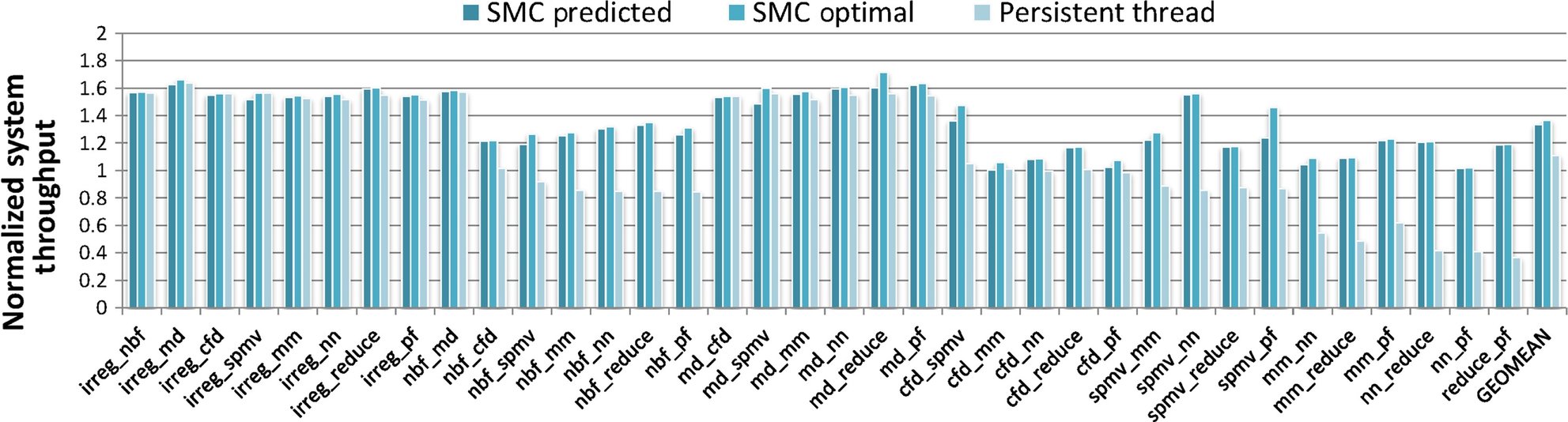
Fig. 5 shows the improved performance in terms of STP. SM-centric transformation consistently outperforms persistent threads by producing an extra 17% throughput gain. One interesting observation is that, different from the ANTT result, persistent threads provide an 11% improvement on average over the baseline. Because STP and ANTT measure different aspects of the system, an optimization may improve one but degrade the other, which was also observed by Eyerman and Eeckhout [40]. The results show that SM-centric transformation consistently outperforms persistent threads, and hence is a better choice for SM partitioning.
5 Other scheduling work on GPUs
5.1 Software Approaches
Kato et al. [44] considered GPU command scheduling in multitasking environments, in which many applications shared the same GPU. Their scheduler, TimeGraph, implemented two scheduling polices: predictable response time (PRT) and high throughput (HT), to optimize response time and throughput, respectively. Their model allows flexible implementation of other scheduling policies to optimize for different objectives. However, TimeGraph does not allow two applications to simultaneously run on the same GPU. Once off-the-shelf GPUs support co-running of multiple applications, SM-centric transformation can work together with TimeGraph to exploit a much larger scheduling space. Prior work on software-level scheduling for single application runs mainly focused on persistent threads with static or dynamic partitioning of tasks [45–49]. The approach runs maximum possible concurrent threads on the GPU and enforces a mapping of tasks to those persistent threads. Gupta et al. [50] showed that by leveraging persistent threads, they significantly improved the performance of producer-consumer applications and irregular applications. SM-centric transformation is inspired by the work on persistent threads, but shows one salient distinction. Persistent threads assign tasks to threads, while SM-centric transformation assigns tasks to SMs. Hence SM-centric transformation enables two optimizations that persistent threads cannot: interthread block locality enhancement and SM partitioning between concurrent kernels.
Two independent studies, Kernelet [29] and Elastic Kernels [15] investigated software scheduling for optimal kernel co-runs. Kernelet sliced multiple kernels from the same application into small pieces. Pieces of different characteristics (compute-intensive and memory-intensive ones) were scheduled for concurrent execution on the GPU. Sreepathi et al. [15] developed the framework to transform GPU kernels into an elastic form, enabling flexible online tuning of resource allocation for each co-run kernel to fully utilize the hardware. Spatial scheduling (i.e., scheduling tasks to SMs) enabled by SM-centric transformation is complementary to these approaches.
5.2 Hardware Approaches
Thread block scheduling recently gained some attention from the computer architecture community. Nath et al. [51] exploited the thermal heterogeneity across kernels and mixed them in the scheduling to reduce thermal hotspots. Adriaens et al. [2] proposed a hardware-based SM partitioning framework to enable spatial multitasking. Similar to Kernelet’s work [29], kernels of different characteristics simultaneously shared one GPU. Kayiran et al. [14] designed a hardware thread block scheduler to dynamically adapt to the monitored memory access intensity and to throttle concurrent thread blocks. To the contrary, SM-centric transformation enabled spatial multitasking and thread block scheduling without hardware support.
There is abundant work on warp scheduling targeting improvements in memory performance. Narasiman et al. [52] proposed to use large warps and dynamically form small warps for single instruction multiple data execution to minimize memory divergence. Rogers et al. [39] observed the subtle interaction between warp scheduling and data reuses in the L1 data cache. Round-robin warp scheduling led to early eviction of L1 cache lines which will be used by some warps in the near future. They proposed cache-conscious warp scheduling to improve intrawarp locality through monitoring thread-level data reuse inside each warp, and they prefer to schedule warps whose data are already present in the L1 data cache. Jog et al. [5] used a similar idea to prioritize warps to improve L1 cache hit ratios. Furthermore, they scheduled consecutive thread blocks on the same SM to enhance memory bank-level parallelism.
6 Conclusion and future work
We have shown that the SM-centric transformation successfully circumvents the complexities of the GPU hardware scheduler and enables flexible task scheduling. We designed three optimizations to leverage the transformation to optimize for parallelism, locality, and SM resource partitioning. The experiments on a Fermi GPU demonstrate that the optimizations can be easily applied to widely used GPU benchmarks and can improve their performance significantly.
Possible future work can go in two directions. The first direction is to further develop our compiler to cover more complicated GPU programs, especially the ones with multiple kernels. The second direction is to design more optimizations to utilize the framework. For example, we could apply SM partitioning with individual SM voltage scaling. The SMs partitioned to memory-intensive kernels can scale down their voltage to save power.