
Data placement on GPUs
X. Shen1; B. Wu2 1 North Carolina State University, Raleigh, NC, United States
2 Colorado School of Mines, Golden, CO, United States
Abstract
Modern graphics processing unit (GPU) memory systems consist of a number of components with different properties. How data are placed on the various memory components often causes a significant difference in a program’s performance. This chapter discusses the complexity of GPU memory systems and describes a software framework named PORPLE to show how to automatically resolve the complexity for a given GPU program.
Keywords
Cache; Compiler optimization; Data placement; Hardware specification language; GPUs; Memory systems
1 Introduction
To meet the relentless demands for data by the large number of cores, graphics processing unit (GPU) memory systems are by necessity complex and sophisticated. They are typically heterogeneous memory systems (HMS). One HMS often consists of a number of components, with each having some different properties (e.g., access bandwidth, access latency, endurance, memory organization, preferable access patterns, and programming paradigms). For example, on a NVIDIA Kepler GPU, there are more than eight types of memories (global, texture, shared, constant, and various caches), with some on-chip, some off-chip, some directly manageable by software, and some not. The trend of memory heterogeneity is stressed by the emergence of new memory technologies (e.g., 3D stacked memory) that are getting into GPUs.
The sophistication of an HMS is a double-edged sword. It has the potential for narrowing the gap between a GPU and data by meeting the demands from different types of applications. At the same time, its complexity and fast evolvement make that potential extremely difficult to tap into. For instance, recent studies show that many memory-intensive GPU applications carefully written by developers sometimes cannot yet reach half of the performance that they could achieve with a better memory system [1]. The studies all indicate that relying on programmers to match an application with HMS such that it taps into its full potential is impractical, yet that is what existing programming systems (e.g., CUDA, OpenCL, OpenACC, OpenMP) all require. Lack of systematic support needed for applications to best benefit HMS is a key reason for the poor memory performance of today’s applications. As future memory systems get more complicated and multicore process become get more thirsty for solving data, the solve in order to maintain a sustained improvement of computing efficiency will become more pressing.
One solution explored by researchers [2] was to use autotuning to search for the best way to use HMS for a program. It is time-consuming and more importantly cannot easily adapt the memory usage to changes in program inputs or memory systems. Some prior work tried to come up with high-level rules to guide the usage of an HMS [3]. These rules are easy to follow, but they often fail to produce suitable placements, and their effectiveness degrades further when memory systems evolve across generations (as shown later in Section 6).
In this chapter, we describe a systematic solution for automatically tapping into the full potential of an HMS. The new solution is a software framework with a set of novel compiler and runtime techniques included. We name the solution PORPLE, which stands for a portable data placement engine. With PORPLE, programmers will be freed from concerns about tailoring their programs to different memory systems, and at the same time, the sophisticated designs of memory systems can become fully translated into computing efficiency of modern applications. PORPLE transforms the programs such that they are customized—in terms of where data are placed in memory—to the underlying HMS at runtime and attain near-optimal memory usage. Evolvement of memory systems is not problem but an opportunity; applications can automatically tap into the full power of the new system without the need of refactoring or retuning (given the specifications of the new system). By closing the gap between memory design and memory usage, PORPLE is promising to raise the capability of existing programming systems to a new level, opening up many new opportunities for addressing memory performance issues, which is a serious bottleneck in modern computing.
2 Overview
PORPLE leverages a synergy between a source-to-source compiler and a runtime library. To use PORPLE, an application just needs to go through its compiler before being compiled into the native code. Then, during the execution of the application, the runtime library will be activated and will automatically enhance the data placement of the program (including migration of data if necessary) on the fly such that the execution can match up with the current program inputs and underlying memory systems, translating the sophisticated design of HMS into the best performance or energy efficiency of the application.
Fig. 1 provides a conceptual overview of the major components of PORPLE and their relations. At a high level, PORPLE contains three key components: the specification language MSL that provides specifications of a memory system, the source-to-source compiler PORPLE-C that reveals the data access patterns of the program and that stages the code for runtime adaptation, and the online data placement engine Placer that consumes the specifications and access patterns to find the best data placements at runtime. Working together, these systems equip PORPLE with several appealing properties:

• User-transparency: PORPLE enhances data placement and memory usage without the involvement of programmers. All analysis and transformations are enabled by the compiler and runtime support.
• Portability: With PORPLE an application that executes on different memory systems will automatically run with the data placements appropriate to the respective memory system, which happens because PORPLE is able to determine and materialize the best data placements at runtime on the fly.
• Adaptivity: The on-the-fly enhancement of data placement also makes PORPLE optimizations able to adapt to program input changes.
• Extensibility: It is easy to add support to a new memory system. Architects just need to put in a specification of the memory system written in MSL, a language that will be designed in this project. When applications run on the new system, PORPLE will automatically adjust the data placement to fit its properties.1 No code refactoring or retuning of applications is necessary.
• Generality: PORPLE can support both regular and irregular applications. It uses compiler analysis for finding out data access patterns in regular programs and uses lightweight online profiling for irregular programs. It leverages a novel semantic-aware hardware profiling mechanism to further enrich the profiled information to effectively guide data placement decisions.
We next elaborate on each component of PORPLE and how all of them work as a synergy to enhance memory usage with these appealing properties.
3 Memory specification through MSL
We introduce MSL, a specification language in which the architect or expert users develop an architecture specification. By separating architectural specifications from the development of other parts of PORPLE, the design enables a good portability of the optimization of data management across different architectures: When the target program runs on a different architecture, the other parts of PORPLE will automatically optimize the data management during the program executions, according to the properties of that architecture specified in its MSL specification. No changes need to be made to either the program or the other components of PORPLE (except some minor extensions to the compiler when new kinds of statements are introduced with the new memory system).
An important part of MSL is the specification of the memory system, which provides a simple, uniform way to specify a type of memory and its relationships with other pieces of memory in a system. Fig. 2 shows the design, including the keywords, operators, and syntax written in BackusNaur Form. The memory part of an MSL specification contains an entry for the processor and a list of entries for memory. The processor entry shows the composition of a die, an streaming multiprocessor (SM), and other scopes. Each memory spec corresponds to one type of memory, indicating the name of the memory (started with letters) and a unique ID (in numbers), and other attributes.

The name and ID could be used interchangeably; having both is just a convenience. The field “swmng” indicates whether the memory is software manageable. The data placement engine can put an explicit data array onto a software-manageable memory (vs hardware-managed cache for instance). The field “rw” indicates whether a GPU kernel can read or write the memory. The field “dim,” if it is not “?,” indicates that the spec entry is applicable only when the array dimensionality equals the value of “dim.” The field after “dim” indicates memory size. Because a GPU memory typically consists of a number of equal-sized blocks or banks, “blockSize” (which could be multidimensional) and the number of banks are the next two fields in a spec. Then the next field describes memory access latency. To accommodate the access latency difference between read and write operations, the spec allows the use of a tuple to indicate both. We use “upperLevels” and “lowerLevels” to indicate memory hierarchy; they contain the names or IDs of the memories that sit above (i.e., closer to computing units) or blow the memory of interest. The “shareScope” field indicates in what scope the memory is shared. For instance, “sm” means that a piece of the memory is shared by all cores on an SM. The “concurrencyFactor” is a field that indicates parallel transactions a memory (e.g., global memory and texture memory) may support for a GPU kernel. Its inverse is the average number of memory transactions that are serviced concurrently for a GPU kernel. As shown in previous studies [4], such a factor depends on not only memory organization and architecture but also kernel characterization. MSL broadly characterizes GPU kernels as compute-intensive and memory-intensive and allows the “concurrencyFactor” field to be a tuple containing two elements, respectively, corresponding to the values for memory-intensive and compute-intensive kernels (e.g., 〈0.1, 0.5〉). The field “serialCondition” allows the use of simple logical expressions to express the special conditions, under which multiple accesses to a memory are serialized. MSL has three special tokens: the question mark “?” indicating that the information is unavailable, “om” indicating that the information is omitted because it appears in some other entries, and “na” indicating that the field is not applicable to the entry. A default value predefined for each field allows the use of “?” for unknowns (e.g., 1 for the concurrencyFactor field).
A distinctive feature of MSL design is the concept of “serialization condition.” The introduction of this feature is based on our following observation: many HMS have special characteristics. How to allow simple but yet well-structured descriptions of these various properties such that they can be easily exploited by the other parts of data management frameworks is a big challenge. For example, accesses to global memory could be coalesced, accesses to texture memory could come with a 2D locality (i.e., caching benefits accesses in a 2D neighborhood), accesses to shared memory could suffer from bank conflicts, accesses to constant memory could get broadcast, and so on. A challenge is how to allow simple but well-structured descriptions of these various properties such that they can be easily exploited by the other parts of data management frameworks. The MSL design addresses the problem based on an important insight: All of those special properties are essentially about the conditions through which concurrent access requests are serialized. A “serialization condition” field is introduced in the design of MSL, which allows the specification of all those special properties in logical expressions of a simple format.
Fig. 3 demonstrates how MSL can be used for specifying the memory systems of Tesla M2075 GPU. The bottom line in the example, for instance, indicates that the specification is about the “shared memory” in the system: Its ID is 4; it is software manageable (e.g., directly allocated at user level), readable and writeable; its size is 48 KB; it has 32 banks; access latency is 48 clock cycles; it is shared by all cores on one SM; its serialization condition indicates that two accesses to shared memory from the same thread block will get serialized if they access different memory locations on the same bank.

4 Compiler support
The compiler has two main functionalities: getting the data access patterns of GPU kernels that the runtime can use to figure out the best data placement and preparing the code such that it can work well regardless how data are placed in memory at runtime.
4.1 Deriving Data Access Patterns: A Hybrid Approach
The first functionality is to derive the data access patterns of the given program. Data access patterns include how frequently a data object is accessed, in regular strides or not, the number of reads versus the number of writes, and so on. Knowing these patterns is essential for deciding the appropriate ways to organize, place, and migrate data in memory.
PORPLE employs a hybrid approach to attaining data access patterns. In particular, this approach includes the compiler framework PORPLE-C that analyzes the source code of a GPU program to figure out the patterns for accessing data. For an irregular kernel whose patterns are hard to know at compile time, this approach derives a shadow kernel, which is a CPU function that involves much less work than the original kernel, but at the same time captures the data access patterns of the original kernel. During an execution of the target program, the runtime support will collect the size of data objects, and invoke the shadow kernels to find the missing info about the data access patterns of the program.
4.1.1 Reuse distance model
One important part of the data access patterns is the data reuse distance histogram of each array in a GPU kernel. Such a histogram is important for PORPLE to determine how many accesses of the array could be hits in a higher level memory hierarchy (e.g., cache), which in turn, is essential for the PORPLE runtime to estimate the quality of a particular data placement.
Reuse distance is a classical way to characterize data locality [5]. The reuse distance of an access A is defined as the number of distinct data items accessed between A and a prior access to the same data item as accessed by A. For example, the reuse distance of the second access to “b” in a trace “b a c c b” is two because two distinct data elements “a” and “c” are accessed between the two accesses to “b.” If the reuse distance is no smaller than the cache size, enough data have been brought into cache such that A is a cache miss. Although this relation assumes a fully associative cache, prior studies have shown that it is also effective for approximating the cache miss rates for set-associative cache [6, 7].
What PORPLE builds, from the data access patterns of an array, is a reuse distance histogram, which records the percentage of data accesses whose reuse distances fall into each of a series of distance ranges. For example, the second bar in Fig. 4 shows that 17% of the references to the array have reuse distances in the range [2K, 4K). With the histogram, it is easy to estimate the cache miss rate for an arbitrary cache size: it is simply the sum of the heights of all the bars appearing on the right side of the cache size, as shown in Fig. 4.

The histogram-based cache miss rate estimation comes in handy especially for the runtime search for the best data placement by PORPLE. During the search, PORPLE needs to assess the quality of many placement plans, some of which have multiple arrays sharing a single cache. Following a common practice [8], upon the cache contention, the effects can be modeled as each array (say array i) gets a portion of the cache, the size of which is proportional to the array size. That is, the cache it gets equals ![]() , where sizej is the size of the jth array that shares the cache. PORPLE then can immediately estimate the cache miss rates of the array by comparing that size to the bars in the reuse distance histogram. In one run of a GPU program, PORPLE needs to construct the histogram for a GPU kernel only once, which can be used many times in that run for estimating the cache performance of all possible data placements during the search by PORPLE. With the cache miss rates estimated, PORPLE knows the portions of accesses to an array that get a hit at each level of a memory hierarchy.
, where sizej is the size of the jth array that shares the cache. PORPLE then can immediately estimate the cache miss rates of the array by comparing that size to the bars in the reuse distance histogram. In one run of a GPU program, PORPLE needs to construct the histogram for a GPU kernel only once, which can be used many times in that run for estimating the cache performance of all possible data placements during the search by PORPLE. With the cache miss rates estimated, PORPLE knows the portions of accesses to an array that get a hit at each level of a memory hierarchy.
Many methods have been developed for constructing reuse distance histograms that leverage affine reference patterns [9] or reference traces [10]. Construction from a trace has a near-linear time complexity [10]; construction from a pattern is even faster. Overall, the time overhead is only a small portion of the online profiling process. The collection of the trace could take some time, which will be discussed in the later section on online profiling.
In the data access patterns derived by the compiler, some parameters (e.g., the data size, thread numbers) are often symbolic, because their values remain unknown until the execution time. The compiler inserts some simple recording instructions into the GPU program to obtain such values at the program’s execution time such that the data access patterns can get substantialized at runtime.
4.1.2 Staging code to be agnostic to placement
The second functionality is to transform the original program such that it can work with an arbitrary data placement decided by the data placement engine at runtime. A program written on a system with multiple types of memory typically does not meet the requirement because of its hardcoded data access statements that are valid only under a particular data placement (e.g., declaration “_shared_” for an array on GPU shared memory). The source-to-source compiler PORPLE-C that we will develop will transform a program into a placement-agnostic form. The form is equipped with some guarding statements which ensure that executions of the program can automatically select the appropriate version of code to access data according to the current data placement. A problem with this solution is the tension between the size of the generated code and the overhead of the guarding statements, which is addressed in our solution by a combination of coarse-grained and fine-grained versioning.
Fig. 5 shows this idea. The coarse-grained versioning creates multiple versions of the GPU kernel, with each corresponding to one possible placement of the arrays (e.g., in Fig. 5B; kernel_I is for the case when A0 is in texture and A1 is in shared memory). The appropriate version is invoked through a runtime selection based on the result from the runtime decisions on appropriate data placement, as Fig. 5A shows. When there are too many possible placements, the coarse-grained versions are created for only some of the placements (e.g., five most likely ones); for all other placements, a special copy of the kernel is invoked. This copy has fine-grained versioning on data accesses, as shown in Fig. 5C. The combination of the two levels of versioning helps strike a balance between code size and runtime overhead.

The compiler follows these steps to generate the placement-agnostic form of the code:
Step 1: Find all arrays that are on global memory in the kernel functions, assign ID numbers, and generate access expressions for the arrays.
Step 2: Identify the feasible placement options for each array to avoid generating useless code in the follow-up steps.
Step 3: Create global declarations for the constant buffer and texture references (as shown in Fig. 5A).
Step 4: Customize PROPLE_place function accordingly (as shown in Fig. 5B).
Step 5: Insert code at the start and end of each kernel function and change data access statements (as shown in Fig. 5C).
In addition, the compiler inserts invocations of the PORPLE runtime library calls (e.g., the invocation of the online profiling function, the call to trigger the search for the best data placement) at the appropriate places in the program of interest such that the runtime support is invoked in an execution of the program.
5 Runtime support
This section describes Placer, PORPLE’s runtime engine for finding the appropriate placement for the data of a kernel at runtime.
5.1 Lightweight Performance Model
An important component of the Placer is a performance model through which, for a given data placement plan and data access patterns (or traces), the Placer can easily approximate the memory throughput, and hence assess the quality of the plan.
PORPLE features a lightweight memory performance model for fast assessment of different data placement plans. The model takes as input the program data access patterns and architecture specifications (written in MSL), and outputs the estimated memory performance of the given program if it uses a certain data placement. Unlike prior GPU performance models that focus on accuracy [4], the lightweight model is easy to build and can quickly meet the requirements of online usage. The model is path-based. It estimates the amount of time taken by data transfers over each of the data transfer paths in the system. On NVIDIA Kapler GPUs, for instance, there are three data transfer paths: one between a core and the global memory, one between a core and the texture memory, and one between a core and the constant memory. Note that the first one also covers accesses between a core and the shared memory since those transfers take a part of that first path. Similarly, the second one also covers accesses to and from the read-only cache. Because the three paths transfer data concurrently, the performance model uses the maximum times estimated on those paths to assess the quality of a data placement.
Specifically, letting P be the set of paths, A(p) be the set of arrays whose accesses take path p, Nij be the number of memory transactions of array i that happen on memory whose ID equals j, PORPLE assesses the quality of a data placement plan through the following performance model:
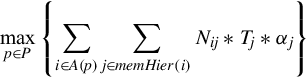
The inner summation estimates the total time that accesses to array i occur, and the outer summation sums across all arrays going through path p. In the formula, memHier(i) is the memory hierarchy that accesses to array i go through (which can be estimated through the reuse distance histogram mentioned earlier in the compiler section), and Tj is the latency of a memory transaction on memory j. The parameter αj is the concurrency factor of the memory, which takes into account that multiple memory transactions may be served concurrently. For instance, multiple memory transactions can be served concurrently on the global and texture memories (hence for them, 0 < αj < 1), while only one memory transaction occurs on the constant memory (αj = 1). The values of the concurrency factor are given in the MSL specification; in our experiments, we use 0.2 for the global and texture memories and 1 for others.
5.2 Finding the Best Placements
With the lightweight model, Placer can quickly determine the quality of an arbitrary data placement plan. For a given GPU kernel, to find the best data placements for the kernel, Placer could just enumerate all possible plans and apply the model to each of them. It could employ some sampling or fast search algorithms for better efficiency.
PORPLE could use many search algorithms, such as A*-search, simulated annealing, genetic algorithm, branch-and-bound algorithm, and so on. PORPLE has an open design by offering a simple interface; any search algorithm that is compatible with the interface can be easily plugged into PORPLE. The interface includes a list of IDs of software-managed memory, a list of array IDs, and a data structure for a data placement plan. PORPLE offers a built-in function (i.e., the memory performance model) that a search algorithm can directly invoke to assess the quality of a data placement plan. Users of PORPLE can configure it to use any search algorithm. All the aforementioned algorithms can find the placement plan that has the lowest total latency; they could differ in empirical computational complexity.
5.2.1 Dealing with phases
Some complexities arise when a GPU program contains the invocations of multiple kernels. These kernels may need different data placements; if Placer gives different data placements for them, there could be some overhead in moving data from one placement to another. To determine the best data placements for the entire GPU program, Placer must take these complexities into account.
A solution could center on a representation named Data Placement and Migration Graph (DPMG). Some representations have been used for data reorganizations, such as Data Layout Graph [11]. But these representations are for homogeneous systems and mostly about cache performance, failing to accommodate the new constraints from hybrid memory systems (e.g., differences in memory sizes, latency, migration cost) DPMG is an acyclic directed graph and is shown in Fig. 6. For a program with K phases (e.g., K kernels for a GPU program), the nodes in the program’s DPMG, except for two special ones (e.g., n0 and n9 in Fig. 6), fall into K groups. Every group corresponds to the set of legitimate (i.e., meeting the size and other constraints of various types of memory) data placements for one phase of the program. Here a data placement is an A-dimensional vector, 〈v1, v2, …, vA〉, where the value of vi indicates the type of memory that the ith container object (e.g., an array) resides on, and A is for the total number of container objects in the program.

Every node in group i represents one legitimate placement—represented by an integer vector shown in the angle parentheses in Fig. 6—of all the program data on memory in the ith phase of the program. Each integer value corresponds to one type of memory (e.g., global memory, texture memory, constant memory). The nodes in adjacent phases are fully connected; the edges represent all possible data migrations across phases. Every edge in the graph carries a weight. The weight on the edge from nodei in group l to nodej in group (l + 1) (denoted as ![]() ) equals the cost of the (l + 1)th kernel when it uses nodej’s data placement, plus the cost of the data migrations needed for changing nodei’s data placement to nodej’s. The definition of cost shall combine energy and performance (e.g., production of energy and delay to evaluate energy efficiency).
) equals the cost of the (l + 1)th kernel when it uses nodej’s data placement, plus the cost of the data migrations needed for changing nodei’s data placement to nodej’s. The definition of cost shall combine energy and performance (e.g., production of energy and delay to evaluate energy efficiency).
By capturing various constraints in a graph form, DPMG simplifies the problem of data placement to a shortest path problem. A path here refers to a route from the starting node to the ending node in the graph. The length of a path is the sum of the weights of all edges on the path, which equals the total cost when the data placements represented by the nodes on the path are used for the program phases. A shortest path in a DPMG hence gives a data placement that minimizes the accumulated cost.
A complexity is to effectively minimize the size of DPMG, which is essential for the solution to be applicable at runtime. The size of DPMG grows with the number of phases, number of arrays, and number of types of memory. However, for most programs, many possible data placements can be filtered out as unlikely choices through the use of heuristics.
6 Results
This section reports some experimental results of PORPLE on three generations of GPUs; their memory latencies are listed in Table 1.
Table 1
Memory Latency Description
| Machine Name | Constant | cL2 | cL1 | Global | gL2 | gL1 | Read-Only | Texture | tL2 | tL1 | Shared |
| Tesla K20c | 250 | 120 | 48 | 345 | 222 | N/A | 141 | 351 | 222 | 103 | 48 |
| Tesla M2075 | 360 | 140 | 48 | 600 | 390 | 80 | N/A | 617 | 390 | 208 | 48 |
| Tesla C1060 | 545 | 130 | 56 | 548 | N/A | N/A | N/A | 546 | 366 | 251 | 38 |

Notes: cL1 and cL2 are L1 and L2 caches for constant memory, respectively. gL1 and gL2 are L1 and L2 caches for global memory, respectively. tL1 and tL2 are L1 and L2 caches for texture memory, respectively.
We evaluate PORPLE on a diverse set of benchmarks, as shown in Table 2. The experiments focus on only one kernel per program; the benefits on multiple kernels (including data migrations) are not covered in the experimental results. These benchmarks include all of the level-1 benchmarks from the SHOC benchmark suite [12] that come from various application domains. To further evaluate PORPLE with complicated memory access patterns, we add three benchmarks from the RODINIA benchmark suite [13] and three from CUDA SDK. The bottom five benchmarks in Table 2 have irregular memory accesses. Their memory access patterns depend highly on inputs and can be known only during runtime. Hence static analysis cannot work for them, and online profiling must be employed. They all have a loop surrounding the GPU kernel call. The loop in bfs has a fixed number of iterations (100), while the number of iterations of the loops in the other four benchmarks are decided by the input argument of the benchmark. In our experiments, we use 100 for all of them. We focus on the optimization of the most important kernel in each of the benchmarks. To optimize data placement for multiple kernels, PORPLE would need to consider the data movements that might possibly be required across the kernels.
Table 2
Benchmark Description
| Benchmark | Source | Description | Irregular |
| mm | SDK | Dense matrix multiplication | N |
| convolution | SDK | Signal filter | N |
| trans | SDK | Matrix transpose | N |
| reduction | SHOC | Reduction | N |
| fft | SHOC | Fast Fourier transform | N |
| scan | SHOC | Scan | N |
| sort | SHOC | Radix sort | N |
| traid | SHOC | Stream triad | N |
| kmeans | Rodinia | kmeans clustering | N |
| particlefilter | Rodinia | Particle filter | Y |
| cfd | Rodinia | Computational fluid | Y |
| md | SHOC | Molecular dynamics | Y |
| spmv | SHOC | Sparse matrix vector multi | Y |
| bfs | SHOC | Breadth-first search | Y |

The results were compared with the state-of-the-art memory selection algorithm on GPU by Jang et al. [3]. In their algorithm, the data placement decisions were made according to several high-level rules derived from some empirical studies. For data arrays whose access patterns cannot be inferred through static analysis, the algorithm simply leaves them in the global memory space. We call this algorithm, the rule-based approach. Another comparison counterpart is the optimal data placement obtained through an offline exhaustive search, which produces the best speedup a data placement method can achieve.
6.1 Results With Irregular Benchmarks
The results on the irregular benchmarks are shown in Fig. 7. The rule-based approach and the optimal data placement are labeled as “Rule-Based” and “POTENTIAL” in the figure, respectively.
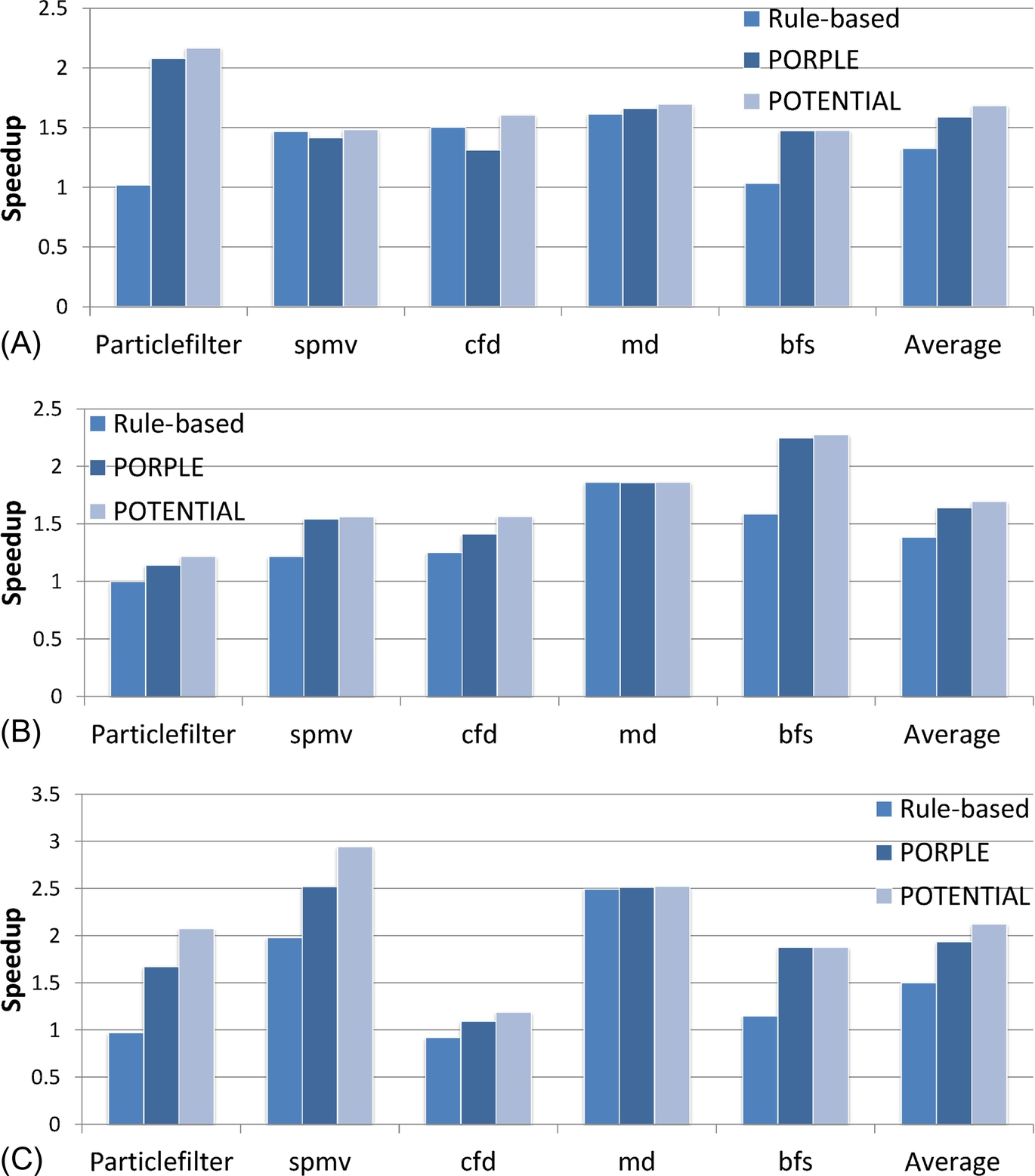
Simply relying on limited static analysis and without cooperative detection of memory access patterns and prediction of data placement results, the rule-based approach favors one type of memory (i.e., global memory) and cannot determine optimal data placement for HMS. This fact is especially pronounced in the benchmarks bfs and particlefilter. In contrast, PORPLE appropriately spread data between diverse memory systems. In general, PORPLE provides 59% performance improvement on average over the original, only 9% less than the optimal, but 26% more than the rule-based approach. This salient performance improvement comes from accurate characterization of memory access patterns and lightweight runtime management. Furthermore, we notice that PORPLE works consistently well across different GPU architectures and across different input problem sizes. This demonstrates the good portability of PORPLE.
6.2 Results With Regular Benchmarks
Fig. 8 shows the performance results for regular benchmarks on Tesla K20c. PORPLE provides on average 13% speedup, successfully exploiting almost all potential (i.e., 14%) from data array placement. The rule-based approach, however, provides only a 5% improvement in performance. We observe that for all benchmarks, except mm, trans, and triad, the data placement strategies in the original programs are optimal or close to optimal, as the benchmark developers manually optimized the GPU kernels. Hence little potential (<10%) exits for further improvement. PORPLE and the rule-based approach both find the optimal placement strategy, which is almost the same as in the original programs.

The experiments are all on CUDA benchmarks on NVIDIA devices because the current PORPLE implementation is CUDA-based. However, the method is applicable to OpenCL and other GPUs. For instance, after manually applying the transformation to the program in OpenCL SDK, we saw 1.76× speedups on K20c. Fully porting PORPLE to OpenCL is future work.
7 Related work
The previous sections compared PORPLE with a rule-based placement approach designed by Jang et al. [3]. Besides that related work, Ma et al. [14] considered the optimal data placement on shared memory only. Wang et al. [15] studied the energy and performance tradeoff for placing data on DRAM versus nonvolatile memory. Other work has focused on easing GPU programming when the data working set is too large to fit into GPU memory [16, 17].
Data placement is also a significant problem for CPUs with heterogeneous memory architectures. Jevdjic et al. [18] designed a server CPU that has 3D stacked memory. Because of the various technical constraints, especially heat dissipation, the stacked memory has a limited size and is managed by hardware like traditional cache. Similarly, some heterogeneous memory designs [19, 20] involving phase change memory (PCM) also use hardware-managed data placement.
To our best knowledge, PORPLE is the first portable, extensible optimizer that systematically allows data placement on various types of GPU programs, which is enabled by its novel design of the memory specification language and the placement-agnostic code generator.
GPU programs rely heavily on memory performance; therefore memory optimizations have received lots of attention [21–24]. Yang et al. [25] designed a source-to-source offline compiler to enhance memory coalescing or shared memory use. Zhang et al. [26] focused on irregular memory references and proposed a pipelined online data reorganization engine to reduce memory access irregularity. Wu et al. [27] addressed the problem of using data reorganization to minimize noncoalesced memory accesses, provided the first complexity analysis, and proposed several efficient reorganization algorithms. All these studies focused mainly on optimizing the memory access pattern rather than choosing the most suitable type of memory for data arrays. In this sense, PORPLE is complementary to them.
Simply relying on limited static analysis and without cooperative detection of memory access patterns and prediction of data placement results, the rule-based approach favors one type of memory (i.e., global memory) and cannot determine optimal data placement for HMS. This fact is especially pronounced in the benchmarks bfs and particlefilter. In contrast, PORPLE appropriately spread data between diverse memory systems. In general, PORPLE provides a 59% performance improvement over the original, only 9% less than the optimal, but 26% more than the rule-based approach. This salient improvement in performance comes from accurate characterization of memory access patterns and lightweight runtime management. Furthermore, we notice that PORPLE works consistently well across different GPU architectures and across different input problem sizes, which demonstrates the good portability of PORPLE.
8 Summary
Good system software support is essential for translating carefully designed memory systems into actual program performance. The PORPLE system described in this chapter demonstrates a promising solution. Its use of MSL helps separate hardware complexities from other concerns, enabling cross-device portability of the optimization. Its carefully designed compiler-and-runtime synergy helps address input sensitivity of data placements. Future memory systems are expected to become even more sophisticated and complex, evidenced by the various emerging memory technologies (e.g., PCM, stacked memory). Because of its distinctive advantages on portability, the PORPLE approach may open up many other opportunities for tapping into the full power of future memory systems.