Thinking Like a Service
The majority of the focus of this book has been the player experience and the way that building games as a service adapts and adjusts to the evolving engagement of the player over their lifecycle. However, as a designer we can’t ignore the changes we have to consider from the delivery side of the experience, including the necessary changes to the development process itself.
This manifests itself most obviously in one term that is thrown about by consultants and panelists at conferences all the time: the minimum viable product (MVP). It’s a pretty simple principle but one I believe is often misunderstood. This just isn’t about making the smallest thing possible or the cheapest thing possible before launching it. This principle is about building something you can test and learn from. If we are going to test something, we have to be able to measure it and we have to create something from which we can build further. Of course we will have to decide to constrain what we are going to build to something we can release in a sensible timeframe, but more than that, we are building a foundation for our eventual service. This doesn’t mean we have to compromise on the vision we have for our game, it just means we have to focus on the core values first and be willing to pivot as we discover the players’ reactions.
Success Is Not a Straight Line
Pivoting is an often used phrase in business strategy and many designers might find it uncomfortable to take on board. Yes, it means changing what you are doing. Yes, it can be hard. However, successful pivoting for creative content still has to stick to what was valuable in the original creative vision, it shouldn’t ignore the original core objectives, even if the changes have to be radical. If the core vision is wrong there is no point trying to pivot, instead we need to rethink from scratch using the information we have learnt. Usually, it’s not the core vision that is at fault but the implementation approach we took. This might be about the playing mechanics, the longevity of play, even the art-style, but essentially any failure means that our hypothesis about our players’ reactions was wrong. But rather than seeing this as just failure on our part we can use it as an opportunity to learn. I have no problem with failure, which is a good thing as I’ve been involved in many more “near misses” than outright success stories, and usually it’s been because the concept was way too early. Each one has provided me with a way to review the way I think and many of the lessons in this book come from those “failures.” You rarely learn as much when you are truly successful, but you can only learn from failures where you are honest about the process. I know how easy it is to blame yourself or others, rather than looking objectively at the circumstances.
The Lean Startup
One of the most important lessons of The Lean Startup1 and other such guides is that we shouldn’t fear failing,2 but rather make sure we fail fast, and before we have spent all our money. Better yet, we should make sure that we take special effort to ensure we can measure our results in a way that will yield the best insight allowing us to learn as much as possible for the next release.
This probably sounds like it’s just iteration. All game developers and designers understand the importance of iterating in order to perfect gameplay. However, this is profoundly different. We are looking to minimize the development impact and release something to our audience before it is complete. We can’t spend months or years perfecting every aspect of the game. Instead we have to pick our battles and focus on something we can deliver efficiently and quickly. That also means we should try to avoid making the same mistakes we have made before and learn from other developers’ failures to avoid their mistakes too, or at least the most obvious ones.3
Simply Focus
Development is always about compromise and there is the classic conundrum described in the Triangle of Development, where we can choose any two of the best quality, time to market, or cost; but never all three. However, we can always choose to reduce our scope, to reduce the number of features down to a level where it is possible to deliver good quality, in good time, and at a reasonable cost.
The curious thing is that this kind of focus is that we often get the best results by simplifying the game complexity down to a level that also happens to be much more accessible to a wider audience. I believe this is one (of many) reasons why some of the successful mobile and tablet games are based on relatively basic gameplay concepts. If we use the data capture principles outlined in Chapter 11, we can then measure the meaningful control points in the game allowing us to work out where improvements are likely to have the biggest effect.
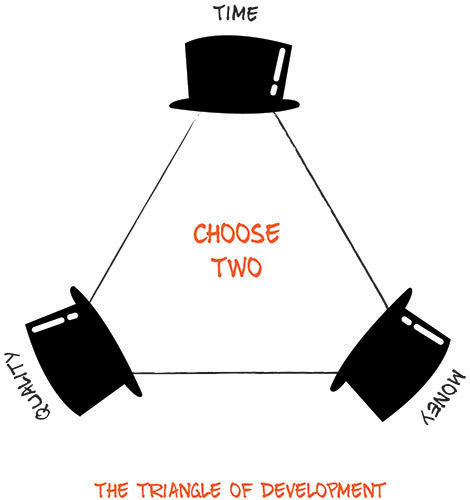
Figure 12.1 The Triangle of Development.
This kind of simplification is precisely why we spent time talking about the game anatomy. If we can start with a repeatable core mechanic, build that into a narrative context, set within a wider metagame, then this allows us to better structure a game experience that can be tested and developed further, iteration by iteration. Simplification for our game becomes easy to achieve by focusing our attention on that very repeatable core mechanic.
Getting Things in Order
Choosing the right features to concentrate on is incredibly emotional. I have spent most of my career having to do this and it’s always painful. The only way I have found to do this successfully is to make a simple list of all the features and put them in order, the most important first. Each feature needs to be defined as a distinct, single piece of work that takes no more than a sprint (usually 1–2 weeks) to complete and test. Anything larger than that needs to be broken down further into its component parts. For example, implementing a commerce platform needs authentication, inventory management, purchase flow design, UI design, UI implementation, merchant process, etc.
Once we have our list then we put the list in absolute priority order. This has to be entirely honest and you have to find ways to avoid emotional decisions as far as possible. Where there is a decision to make, try to consider the perspectives of our target players—at the end of the day, it’s their needs we have to satisfy to be successful. Importantly we are not deciding which features we want to deliver, simply the order in which we will work on them. This is good news because that we never need lose our most favorite feature,4 we only have to defer it to a later release. That takes some of the emotional sting out of the decision-making process. That one thing that you hold most precious in the design concept might not fit into the initial release, but we can bring it into a later update and use that to help make a big deal out of that later release. Of course if a feature never makes it into a release then we will come to realize that perhaps it wasn’t that important in the first place. At times like this we have to “kill our darlings” (or perhaps use them to inspire our next game).
Creating an absolute list is just the start of the planning process. This information feeds into the development process and is used to create schedules of work, but let’s come back to that when we talk about agile development. Suffice it to say that we will find that we need to find an advantage to staggering our precious features between different releases, not least in order to sustain engagement. This allows us to “tell” our players our vision for the game, step by step, building a progressive anticipation of what is to come and, hopefully, trust that we deliver on our promises.
What is Minimum? What is Viable?
As we work with the development team to allocate our priority tasks to the available resources, we will find out quickly that it will take a number of different sprints to build a product that is suitable for the initial release. We have already worked out the priority so the question will come down to which sprint delivers a product with sufficient functionality to release. This will rarely be a level of quality of product that you are happy with. Indeed if you are not at least slightly embarrassed by the experience, then you have probably waited too long. What’s important is that the initial release needs to convey the intention of the vision of your game (at least at its core) and be sufficiently self-contained to function … i.e., it won’t crash and has just enough playable material to make sure players won’t immediately give you a terrible rating. Deciding if your game is viable is incredibly challenging and it depends on the specific market segment you are targeting. Always start with a friendly alpha or closed beta audience.5 If you can’t manage that then perhaps consider external test teams or an audience in a limited location, such as New Zealand. The important thing is to find an audience who are not emotionally involved and who can not only provide honest feedback, but who you make feel special enough that they trust you to respond to that feedback. This way you will be more easily forgiven for versions of the game that fail to satisfy completely, therefore you can get their feedback earlier without causing them to churn.
If for some reason you can’t do this kind of early release, then the demands on quality of the initial release will be much higher. Indeed we have seen that the minimum viable quality bar rising all the time. That means that, although you should continue to keep your initial proposition small, you have to ensure that the level of polish of that initial section is as high as possible to avoid losing your audience at the most critical time (i.e., full launch). That being said, get the game in front of people who aren’t emotionally involved just as soon as it is possible; what matters is that you test realistic user behavior.
Testing Times
Getting information for users about your game ideas is vital, and not just when you release your MVP. Testing should be incorporated throughout the development process including old-school focus-group testing where possible. Have a group of people you trust to give regular feedback on the ideas and the progress of the implementation, but make sure you regularly test these assumptions with new people who are not emotionally engaged with the project. This doesn’t have to be expensive, but should be done as formerly as you can afford. Ideally using a series of open questions that involve interaction with the game and that can be recorded without the players being obviously observed.
This type of testing can only give you opinions. Focus testers notoriously can only tell you what they understand and, like all data research, should only inform your decisions, not determine them.
Having a product in front of an audience with the ability to capture real-user data is much more powerful than focus testing. The game is no longer a theoretical concept; instead it is a living thing providing telemetry that allows you to understand how each twist, turn, and opportunity for play are explored by real players. You can compare their behavior with your findings of how people played the game during your internal usability tests and use all of these sources to inform your own design insight. The military have a saying that no plan survives contact with the enemy. The same could be said of your game design.
Life After Launch
The kind of information we can get from a live product is precisely why it remains vital that we get a MVP to market as soon as practically possible. The faster we can start to get useful, unbiased data, the faster we can adjust our prioritization process. I’m not suggesting that you change what your team is working on in mid-sprint, that would clearly be counterproductive. We should already have to plan for ongoing releases. However, make sure your next sprint is able to take into account information you have learnt from the one you previously released. As far as possible, treat each subsequent release as its own MVP, delivered predictably with each aspect measured in a systematic way, meaning we can learn what works best for our game and build a deeper engagement with the player base. It means our service is not static, but continues to grow organically. However, in order to take advantage of this we have to make sure we build into our development approach the resources and processes that allow us to continue building the service after launch. If you are used to building box-retail games you know that by the time the game hits the shelves the team has usually been all but disbanded and the collective expertise has now been lost to other projects (or worse yet, made redundant). What little remains of the team may not have enough detailed knowledge to make more than minor adjustments to the experience beyond the most essential bug-fix patches.
This way of working is extremely inefficient and expensive. By keeping our requirements focused and limited with many releases over time, we don’t need as many developers to get to launch and we have a longer period of time post-release to continue to invest in that experience while we have an income coming into the organization. Don’t get me wrong, you will find the balance of staff needed for a service changes over the lifecycle of the product, however this will be a much easier transition than we see with large games product releases.
Of course that means that much of the development will happen after the initial release. There are many estimations as to what proportion of development happens after the release of a MVP, but I would suggest that it’s around 80 percent of the total development effort, perhaps more for products with the best life-time value. I appreciate that this sounds like a lot (and it is) but this effort is about building on the original implementation and creating a long-lasting full experience over many years. Most importantly, this has to be sustainable with the revenue from the game. That’s the difference here. We are not taking years before we release a product, we are releasing something fast and using that revenue to sustain our ongoing development in order to build an audience and a revenue stream.
Small Teams, Fewer Specialists?
There are risks of course because it will be much harder to employ rare specialist skills to create the ultimate experience if we can only have smaller teams. We also lose out on the broader experience presented by the larger team structures. However, the gains are huge. The efficiency of running a smaller team more removes layers of bureaucracy overheads and makes it so much easier to collaborate between different disciplines of art, code and design. The more specialized tools and expertise we can buy in through third-party services such as middleware platforms, payment systems, cloud server infrastructure, and game engines such as Unity, Unreal Engine, Cocos, etc.
Staying Alive
However, even with smaller development teams using high quality third-party tools, we can’t be sure of success. If the audience has to wait for months for each update they will think the game had died and will quickly lose interest. We need to be able to update changes to the game regularly, at least weekly but better yet daily. Indeed from my time at 3UK we found that the more regularly you changed what players saw, the better. In our case this was the front page of the games product. We went from changing this from once per week to once every four hours—3Italy went even further and changed theirs every ten minutes. The more regular the change the more frequently players returned to the service.6 Obviously it’s not possible to adjust the underlying game code at this kind of pace, but it is possible to create a pipeline of new content, configurable events, and automated promotions, as well as functional releases over time. By planning a process of releases each week in advance you can make it look to the audience that you are producing material each day even though in reality it might take months to deliver any one feature through code, test, and publishing cycles. You don’t have to make everything available just because the features have been completed. Staggering the release of content and experiences over time really pays dividends.
Falling Down the Waterfall
This takes organizational change and may well be resisted by the development team. There are techniques out there that are well worth investigating but I will focus on “agile” and in particular “scrum.” But first let’s talk about the traditional method of project managing software development is known as “waterfall.” In this model, development is seen as a sequential process, flowing inevitably downward. It comes from the manufacturing tradition where making design changes later in the flow are prohibitively expensive and have knock-on consequences that are unpredictable. It all starts with requirements analysis.7 This would be more systematic than just thinking up whatever features we want. This is about documenting our designs in detail and expressing them from the perspective of what our consumers will need to enjoy the game.
Writing our ideas out and breaking them into specific sprint-sized requirements has the added advantage that it forces us to consider all of the specific necessary steps to play the game, which, usually, in turn means we know all the things our developers need to build. Sometimes the document is called a “project initiation document” or sometimes a “marketing requirements document,” but I prefer to call that the “game design document.” This document shows our requirements in a form we can communicate with the technical team to convert the design into a specification, which should then tested against the requirements before coding starts.
Getting the Team Onboard
The design document also serves as a great tool to help the designer to get the rest of the team on board with the project. Hopefully, they will have spent time talking to all the members of the team in order to ensure that they not only understand the game idea, but are committed to it. There is nothing worse than a development team that is apathetic about your game concept. The development team’s role then is to translate the designs into technical specification documents that outline the planned development approach, then these specifications need to be agreed back with the design team to check they satisfy their requirements. Once the tech specs have been agreed, the development team can proceed and, assuming you got everything in the design right when it comes to testing, we simply test the results against the original specification, which of course should match the original requirements. Finally, once that testing is complete, we release the product and everything works with only occasional maintenance. At least, that’s the theory.
Getting Agile
The trouble with the waterfall approach is that games aren’t easy to pin down into absolute conditions or test cases. We don’t always know whether players will find our game entertaining or not. We can’t know how different mechanics will work in combination, even if we try to time-box things. In short this process fails because it doesn’t support iteration.
The agile system8 is based on the acceptance that project requirements and solutions evolve and proposes that the best way to deal with these changes is through collaboration and time-boxed iteration steps, rather than fixed deliverables. It works well by starting with the underlying vision for the project, agreeing a short and regular release cycle, and focusing on prioritized deliverables that can be completed in that timeframe. This approach has its problems too and is not as efficient for larger projects as well as making it difficult to deliver large and complex features that don’t fit into the agreed release cycle timeframes. However, as a way to direct the development team within the context of a wider strategy it can be hugely beneficial.
The most common version of agile development seems to be scrum, which has a number of “rules” that the development team needs to adopt. These can seem a bit odd to veteran developers, but many have become fanatical converts to this approach.
The Product Owner
There are three core roles in the process. The product owner9 is the person who owns the strategy. They have to be the representative of all the stakeholders, most importantly to champion the customer (in our case the player). It’s their role to translate the vision into a strategy for the project as a whole. Each requirement needs to be defined using self-contained customer focused user journeys, each of which are broken down into functionally simple user cases. These are simple phrases that describe the user (the player) and what they want to be able to do using everyday language such as:
As a player, I want to be able to quickly locate the next available level suitable for my playing ability. In the event that I am an experienced player, I want the option to be able to select my own choice of level, overriding the choice I am presented with automatically.
These requirements often benefit from discussion with the development team or the scrum master to assess their suitability in terms of size and structure; however, the validity in terms of customer experience should be outside their remit. Personally, as a person who has often been in the product owner role, I like to have a good idea of what their impact will be in the overall experience and especially in terms of acquisition, retention and monetization. We use these factors to determine their priority and we use that to position them in the product backlog. As we have said before, avoid using vague priority settings such as P1 or VeryHigh; use an absolute order for each and every line item from most important down to least with only one item at each priority number, even if that causes you hours, even days of anguish—it’s worth it.
Each sprint is expected to deliver each requirement as “ready to go,” but that doesn’t mean the product owner will want to release the code at the end of every sprint. They need to have an idea of where the MVP line is on their backlog—in other words to know what is the true bottom line as to what you can release—but despite that, they still have to put all the requirements in a single order.
The Development Team
The second role is the development team, whose collective role is to take all the requirements according to their separate specializations and skills and try to turn them into deliverable tasks that can ideally be completed and tested in isolation within the sprint. The duration of a sprint is typically 1–4 weeks within which the development team will concentrate on the deliverables they have committed to focus on, based on the product backlog prioritization. The progress of each sprint is generally displayed publicly with a “burn-down” chart showing the remaining work to be complete for that sprint each day. They need not be particular hierarchies within a team, although in larger groups there will often be a mentoring role for some of the most experienced members. Agile development is more about making better products together and quicker rather than reinforcing artificial labels.
The Scrum Master
The third role is that of the scrum master. These are the people who keep track of the progress and who attempt to maintain the momentum. Interestingly the scrum master need not always be a producer or project manager, sometimes having a lead coder take on this role can also be highly effective, as long as they are able to commit to the process. They host a daily meeting (same time and location each day) where everyone can attend, but only the developers can speak. They are asked what they have done since the previous day, what they are planning to do that day and what blocks they have encountered. These are documented and the scrum master will help work through a resolution of that problem outside of the meeting with only the relevant people. These meeting should always end after 15 minutes—a tricky task at best, but with everyone knowing the time this creates a sense of urgency that avoids wasting time unnecessarily. In the end if something needs further discussion, that should happen outside the daily scrum anyway.
If you are dealing with bigger teams, then rather than expanding the time available it’s better to separate out the different scrums into separate teams. Then after the daily scrum, there will be a scrum of scrums, allowing each team to present its activity and blocks to the wider business. This “cell” structure is particularly powerful for scale, provided that each scrum (cell) can focus on the solution of its own problem, rather than splitting large problems across multiple cells, which usually breaks down.
The objective is to limit the management overhead and productivity impact on the development team while still giving the wider business a clear idea of what the real progress is and what might be causing problems for individual team-members. The scrum master is critical to this progress and their working relationship with the product owner is critical to the success of the project. They are each other’s check and balance and both need to be committed to the team’s vision for the project. In my experience as product owner I am aware that the reality of this is that you and whoever is responsible for production delivery will fall out at times, even on the best of projects. However, you both need to appreciate the other’s perspective and be able to separate the project from the personal. Successful teams can argue passionately and still happily go for a beer or play Call of Duty with each other afterwards.
Time to Review
At the end of each sprint there are two further (also time-boxed) meetings to review the progress. In the first, the “sprint review meeting,” the purpose is to present the results to the product owner and other stakeholders as well. This usually includes demo of the features currently complete and “ready to ship,” as well as an assessment of the progress against the sprint backlog (that section of the product backlog committed to by the development team for the sprint). This meeting should also be time-boxed, typically for between two and four hours depending on the project. At the end of this, the deliverables should be signed off by the product owner who will determine if the current deliverables are sufficient to justify a release (either the MVP or a new update). If that happens then this should be passed off to a team to complete end-to-end QA testing and commence the submission process.
The second meeting is a “sprint retrospective” where the team-members will review the process, progress, and ability to resolve blockages. The purpose is to first understand what worked and what didn’t, then to identify opportunities to improve the process for the next time. This isn’t a witch-hunt, it’s about empowering the team to continually improve their capabilities and should be a chance to people to air their concerns, frustrations, and, importantly, congratulate themselves on their ongoing effort.
Have a Break
After the sprint it’s useful to give the developers time to recuperate and have a change of pace. This is a great opportunity to have the team spend time experimenting with ideas, to learn new things, or to prototype complex elements for the project. This has to be a time limited period—for example 2–5 days depending on the normal size of your sprints—and should usually be driven by the development team themselves, although that doesn’t mean it can’t involve the product owner. Indeed its often a good idea to switch around the roles and to get some of the team to try something outside their normal skill set, if only to get a perspective of those roles. There is no expectation that any of this work will be used in future projects, but this should be used as an opportunity to identify new creative possibilities and reward team members who exhibit the most innovative contributions. This is not wasted time; at best it can transform a project, perhaps even scope out the seed of a completely new game. At worst your team will have had a chance to stretch their skills in areas that they normally don’t get to. Just as importantly, it’s an opportunity for them to feel appreciated for making their own choices as well as helping to re-energize them for the next sprint.
Publishing is Not Development
The publishing should be treated separately from the development process, although many small developers don’t have the resources to run more than one team. This requires us to first validate the quality of the deliverables from the development team, which is hard to do if you are evaluating your own work or that of your team. There are many agile developers who swear by the test-driven development approach10 alongside scrum, where each technical specification includes a test that confirms the feature has been delivered correctly. This implies that there will be no need to do separate QA testing at all. I’m a little more dubious about this as I feel that you should always do end-to-end testing to ensure all the pieces map together. That being said, the scrum process requires that a developer takes responsibility for the quality of their code before they check it into the project, including taking into account not only the functions of the section they have built but also its compatibility with other systems.
Despite this, as a product owner we also have a responsibility to ensure that the end product is in a suitable state for release on behalf of the consumer. With that in mind, here is a breakdown of the different stages of QA testing.
Unit Testing
We usually start with unit testing, taking the specific class or module relating to a single feature and check this against the test script written by the developer themselves to match the original requirement. The aim is to test that the function performs to the specification within its own context. At this point we are not considering any interactions with other systems and if those are important to the ability to test this specific unit, the interaction would use a “test stub” or simulation of the dependent modules.
Once we know that the feature works according to the specification, we need to test it in context with the other modules of the platform, which means we need to complete and test the integration,11 while along the way demonstrating the performance and reliability of the combinations. We have already demonstrated that both modules work correctly according to their specification, so we can usually narrow down any issues to the way they interact.
End-to-End Testing
Once all the modules have been tested against each of the other modules they are directly integrated with, we should be able to raise our sights higher. Here we need to confirm that the end-to-end experience is performing correctly against the original specification. If it is we can proceed to launch. Doing this, however, requires us to consider a number of different testing approaches. User acceptance testing allows us to confirm that the overall experience is working against the objectives originally set out by the product manager, while stress testing allows us to prove that the platform will be reliable under extreme conditions, and in particular it’s worth considering hacking issues such as packet-sniffing, distributed denial of service (DDOS) attacks, and man-in-the-middle attacks, as well as just simply how the platform would function should you get 10–100 times the volume of users you currently expect all turning up at the same time.
Release Candidates
It will take a number of sprints to get a polished, functional release that you have the confidence can deliver the minimum viable experience, including all the data capture you need to be able to learn for the next release. It will involve compromise and won’t be exactly what you had originally envisioned, but it does have to be a self-contained “complete” experience in its own right. You are now ready to release it through your publishing process. This might be as simple as following the submission guidelines for the platform you are working on, whether that is a publisher, Steam, iOS or Android. This will take some time and may often involve rejection. There may be changes to policy, or even regulation, in specific territories that, as a developer, you won’t necessarily have been aware of. This will require someone to make the fix and to do that in a rapid manner—throwing out your otherwise perfect sprint planning. How do you deal with that if you don’t have multiple teams? I’d recommend that you always allocate time in the sprint to bug-fixing and use that time when necessary. If you don’t need that time in the end there will always be bugs the developer can look at or perhaps we just get started on the next highest priority feature on the backlog that didn’t originally make it into the sprint. The joy of scrum is that we aren’t worrying about how many features make it into the sprint, instead we are focused on how much time to dedicate to that development phase. There should be no need to do crunch again, ever!
Preparing For the Next Sprint
If we are careful and line up the process there should be tasks that run in parallel during the development and publishing processes. We might have a week window to review our backlog, fleshing out the specifications and write our requirement specifications. This could be followed by a week where the development team write their technical specifications and unit test scripts that would be reviewed by the product owner and their peers. We get 2–3 weeks of intense development, with unit and integration testing happening in parallel. Finally 1–2 weeks of end-to-end testing, including user acceptance testing before it’s submitted to the platform holder. Over the next week the development team gets to experiment and learn new things while we await the results of the publishing process, and the product owner works with the team leaders on the details of the next sprint, including time to resolve any bug fixes with the second week before going live being used on the technical specification process. The whole pipeline might take 7–9 weeks to complete. If we have the resources to support multiple teams there is no reason why they can’t push forward a release twice as fast, handing the baton of the “current” version to each other, but you should absolutely remember that your team-members might have a life or family and you will have to accommodate for little things like sickness or holiday.
Releases Without Releases
Features aren’t the only thing we release over time. We also have to look at the goods we offer and consider how we can deliver these more frequently than each software upgrade release. There are two key strategies here. The first is to have some time or procedural unlocking process for “new” items that happen to have been embedded in the application all along (and therefore have to be created prior to the release being submitted). Or alternatively (and my preference) we should have a method that allows the game to user the server-side to deliver updated content.
Server-based distribution of in-game content is a really powerful design strategy that can really unlock your revenue potential as well as your ability to deliver rapid improvements to your games experiences. However, you have to be careful that you comply with the requirements of the platform you are using and you must realize that servers have an associated ongoing cost linked to the level of usage, although cloud-based systems such as EC2 servers from Amazon or Azure from Microsoft can help you mitigate problems with reliability and scaling. There are even complete service providers such as Game Sparks and other specialist server infrastructure providers, such as Exit Games for multiplayer platforms.
You then need to create (or find a provider with) a platform that allows the game to identify what assets are available to each player and make these available to them alongside the unlocking of achievements or specific purchases made in the game, and usually this has to be done working with the platform provider.
Thick and Thin Clients
Thinking about servers means we have to think about whether the client can function when the user is unable to access the internet. We can make the decision that the game can only be played when the player can access the internet, but that comes at the cost of the overall experience. Whatever our decision (and sometimes its unavoidable depending on our game design) we have to ensure that we take care to separately consider the design of the client software and how that operates when there is no connection to the server. Can we cache the activity of the player and upload that in the background when the connection returns? Do we enforce a reconnection within a specific timeframe, or do we simply throw away the data of their behavior while not connected? There is a tension between a “thin client” approach, which treats the server as the main source of functionality and a “thick client” approach, which delivers the minimum reliance on the server infrastructure. Both approaches are a compromise and need careful planning. Regardless of the approach, only the server can be trusted in terms of data integrity, any client can be hacked.
Server Deployment and Roll-Back
Getting back to the server whatever solution we implement needs us to have a mechanism that allows you to test and check content going live can’t accidently bring the game down or other less critical problems such as “missing textures.” Even then you should ensure that there is a method to roll-back any release if you later find there is a problem.
Build for Flexibility
Think carefully about the flexibility and range of goods and assets you want this process to support. That will affect how the client functions and how it needs to function to be able update each element. In particular how will you deal with the fact that you can’t take away or significantly change assets that people have already paid for—even if you update the quality of your graphics engine? Think in particular how you can skin or otherwise customize the playing experience driven by the player and by the platform. I’m not just talking about selling customization goods (although that can have value), I’m talking about how we can manipulate the player experience from the server in order to create events that at least visually (perhaps also adding some specific minigame) update the experience without necessarily updating the app itself—provided you don’t break the rules of the platform holder. Apple in particular has some quite restrictive rules designed to avoid misuse of server process that you should be aware of.
It’s not a trivial process to set this up. It needs careful planning and generally the platform support is something that needs to be managed in parallel. If you have a small team this might even be out of the question without third-party support. But its potential if you want to be able to deliver regularly changing experiences including daily challenges, monthly events, and quarterly “seasons” in your game can be phenomenal for retention and monetization.
Delivering Ongoing Service
Service doesn’t end there. Service also means having the tools to support moderation, community interaction and, of course, to engage with players as directly as possible whether that’s through Facebook, Twitter, YouTube, or other more specialist platforms like Everyplay. Focus on how you will deliver that experience and how you can maintain its support (and costs) over time. Choosing the right service tools is vital but we don’t have space in this book to be able to discuss that in any detail and, as with every area of this book, I strongly recommend you research the key areas for yourself.
Summing Up Service
The point of this chapter is that delivering a service requires a fundamental change in the way we approach development. It’s about smaller focused teams delivering ongoing sections of our game offering over time so we can test each section in isolation as well as demonstrate to the users that the experience has life and ongoing investment that they can choose to reciprocate. We are not trying to create everything in advance of their engagement and instead will respond to their needs from a functional point of view, just as we will respond to their community, moderation, and social needs. I didn’t go into detail about how these latter essential components of service can be delivered, as that probably deserves its own book. The key in my mind is that we approach each step in the delivery chain one at a time, break down each problem into its components, and work out the priority. If you can understand that approach you will be able to resolve every problem as you will have understood the fundamental point of creating a service … we only have to do each step at a time, but there will always be more steps to take.
Notes
1 Eric Ries’ book The Lean Startup has quickly become the bible of many small indie studios. Personally I wasn’t all that interested in the book as I rarely see much value in business strategy gurus, until I read that one of the quotes in the book came from Geoffrey Moore, author of Crossing the Chasm, http://theleanstartup.com.
2 One of the key differences between UK-based investment and that of the USA (particularly in San Francisco) is that the UK investors seem to find failure in previous ventures as an entirely bad thing, whereas US investors see failure as an opportunity to learn—provided you demonstrate that you have! I suspect this is partially because the larger funds in the US mean that they can afford to be less risk-averse, but this attitude also clearly pays dividends.
3 Avoiding making the same mistakes as other people have already made is what makes it difficult for me to decide how I feel about Peter Molyneux’s Curiosity from 22 Cans. Molyneux has often said that this project was an experiment, but I find it hard to identify what lessons they may have learnt from the project that weren’t already obvious from researching other projects. Don’t get me wrong, they certainly will have learnt a lot as a team, but was that project the best way to learn them? The game presented a significant networking challenge, and they unsurprisingly had a significant server outage in the early days—a problem that was both predictable and avoidable. It might have been expensive, but cloud server infrastructure was created specifically for managing unpredictable scaling problems and there were plenty of precedents out there on how to avoid such problems. There were other obvious things, such as the behavior of some users creating crude imagery and offensive comments, while others tried their best to “clean up” those messages—so far so obvious. Of course the real answer is that Curiosity wasn’t a minimum viable product at all. It was a marketing tool where the team had to learn the hard way how to pull all these techniques together, allowing their mistakes to be public, showing their commitment to learn, and building trust with 3 million players. In the end the reveal we had all been waiting for was about their next title Godus. Now that’s brilliant marketing. www.telegraph.co.uk/technology/10084700/The-end-of-Curiosity-teenager-crowned-God-after-winning-game.html.
4 To extend William Faulkner’s quote in games, like “in writing, you must kill all your darlings,” http://en.wikipedia.org/wiki/William_Faulkner. This remains true even with �service-based delivery; however, prioritizing features to a later release is much less painful to do that the actual slaying of your favorite ideas.
5 Traditional software development defines the alpha as the first release and usually to friendly or internal audiences. A closed beta is a release to a select invited audience where as an open beta is open to all comers who pass specific criteria (e.g., signing an non-�disclosure agreement). Some services spend years in open beta, while others, like PlayStation Home, never leave the beta stage, largely to communicate to the public users that the platform will constantly be in development.
6 There is a level of diminishing returns to the frequency of change, but the average return rate of the active user generally matched the rate of change.
7 There are some formal processes that help developers use waterfall development approaches for software development, most notably PRINCE2.0. Apparently this is an acronym for PRojects IN Controlled Environments and derived from a UK government standard for IT system project management, http://en.wikipedia.org/wiki/PRINCE2.
8 Agile has many forms but essentially focuses on the collaboration of cross-functional teams, which fits neatly with the games as a service model, http://en.wikipedia.org/wiki/Agile_software_development.
9 I know some people don’t like the term “product owner” as it denies the shared nature of the creative process. You could use terms like “champion,” “requirements manager,” or “producer,” but in the end someone has to represent the consumer and “own” the product in some way. It doesn’t have to diminish the role of the rest of the team.
10 It’s often a good idea that the developer writes a technical specification and test script for each section of code they are to develop and then have that signed off by the product owner. This ensures that both sides have a clear understanding of what is needed and how to demonstrate that it functions correctly. It is also worthwhile having a senior developer—often the scrum master or a person responsible for other modules with which this code has to integrate—to review to tests and consider potential integration problems.
11 There are several approaches to integration testing, including smoke-testing, big-bang, top-down, layer integration, etc. However, this is more detail than we need to go into in this book, http://en.wikipedia.org/wiki/Integration_test.
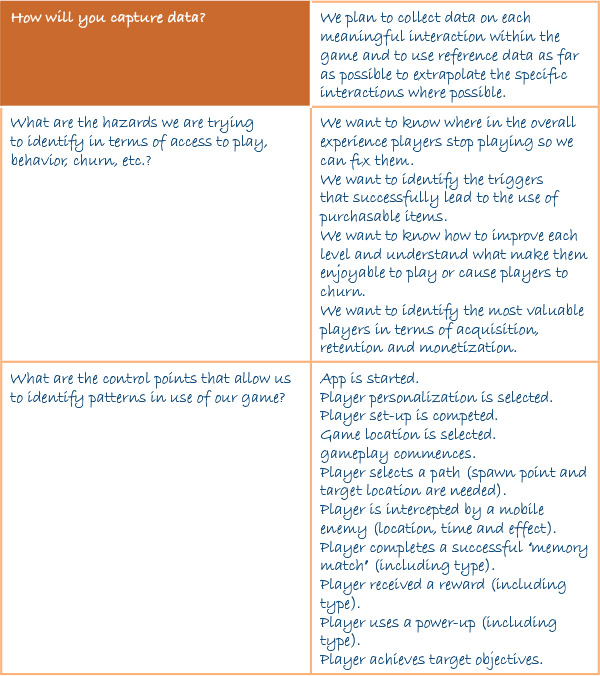
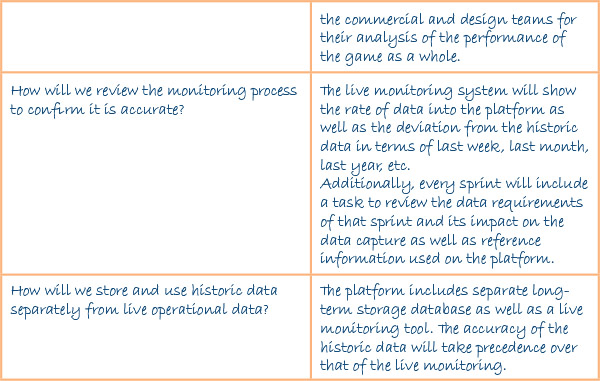
Exercise 12: How Will You Capture Data?
One of the most powerful tools that comes from using a connection with a server is the wide-scale capture of data. However, while there is a temptation to capture everything, we should take time to work out what data points will allow us to understand what things, as it can be as bad to have too much information to sort through as having too little. Worse still is to have the right information but to have collected it out of context, making that information irrelevant. This is a tricky balance to reach as its often only after launching your game that you can identify the oddments of data that prove to be the most insightful. However, that doesn’t mean we should collect meaningless confusing data.
In this exercise we will consider how you can collect as much meaningful information as possible by understanding the data that actually matters to the commercial and design performance of the game. We will use the HACCP model described in Chapter 11 as a way to help us understand the flow of the game and use this to identify data points in the game that are most likely to help us understand the performance in our game.
This starts by looking at what kinds of hazards we are trying to measure as well as where in the game we can find the control points that are most meaningful in terms of their value in interpretation. We should also try to have an idea of the expected range of the data points for each of these tests so we have some kind of benchmark to know what success looks like. Finally we need to consider how we monitor and review the whole process, including the separate storage (and comparison) of historic and operation data.

Worked Example: