
CHAPTER 2
APPLICATION LAYER
THE APPLICATION layer (also called layer 5) is the software that enables the user to perform useful work. The software at the application layer is the reason for having the network because it is this software that provides the business value. This chapter examines the three fundamental types of application architectures used at the application layer (host-based, client-based, client-server). It then looks at the Internet and the primary software application packages it enables: the Web, email, Telnet, and instant messaging.
OBJECTIVES ![]()
- Understand host-based, client-based, and client-server application architectures
- Understand how the Web works
- Understand how email works
- Be aware of how Telnet and instant messaging works
CHAPTER OUTLINE ![]()
2.2.1 Host-Based Architectures
2.2.2 Client-Based Architectures
2.2.3 Client-Server Architectures
2.2.4 Peer-to-Peer Architectures
2.4.3 Attachments in Multipurpose Internet Mail Extension
2.6 IMPLICATIONS FOR MANAGEMENT
2.1 INTRODUCTION
Network applications are the software packages that run in the application layer. You should be quite familiar with many types of network software, because it is these application packages that you use when you use the network. In many respects, the only reason for having a network is to enable these applications.
In this chapter, we first discuss three basic architectures for network applications and how each of those architectures affects the design of networks. Because you probably have a good understanding of applications such as the Web and word processing, we will use those as examples of different application architectures. We then examine several common applications used on the Internet (e.g., Web, email) and use those to explain how application software interacts with the networks. By the end of this chapter, you should have a much better understanding of the application layer in the network model and what exactly we meant when we used the term protocol data unit in Chapter 1.
2.2 APPLICATION ARCHITECTURES
In Chapter 1, we discussed how the three basic components of a network (client computer, server computer, and circuit) worked together. In this section, we will get a bit more specific about how the client computer and the server computer can work together to provide application software to the users. An application architecture is the way in which the functions of the application layer software are spread among the clients and servers in the network.
The work done by any application program can be divided into four general functions. The first is data storage. Most application programs require data to be stored and retrieved, whether it is a small file such as a memo produced by a word processor or a large database such as an organization's accounting records. The second function is data access logic, the processing required to access data, which often means database queries in SQL (structured query language). The third function is the application logic (sometimes called business logic), which also can be simple or complex, depending on the application. The fourth function is the presentation logic, the presentation of information to the user and the acceptance of the user's commands. These four functions—data storage, data access logic, application logic, and presentation logic—are the basic building blocks of any application.
There are many ways in which these four functions can be allocated between the client computers and the servers in a network. There are four fundamental application architectures in use today. In host-based architectures, the server (or host computer) performs virtually all of the work. In client-based architectures, the client computers perform most of the work. In client-server architectures, the work is shared between the servers and clients. In peer-to-peer architectures, computers are both clients and servers and thus share the work. The client-server architecture is the dominant application architecture.
2.1 CLIENTS AND SERVERS
There are many different types of clients and servers that can be part of a network, and the distinctions between them have become a bit more complex over time. Generally speaking, there are four types of computers that are commonly used as servers:
- A mainframe is a very large general-purpose computer (usually costing millions of dollars) that is capable of performing an immense number of simultaneous functions, supporting an enormous number of simultaneous users, and storing huge amounts of data.
- A personal computer is the type of computer you use. Personal computers used as servers can be small, similar to a desktop one you might use, or cost $20,000 or more.
- A cluster is a group of computers linked together so that they act as one computer. Requests arrive at the cluster (e.g., Web requests) and are distributed among the computers so that no one computer is overloaded. Each computer is separate, so that if one fails, the cluster simply bypasses it. Clusters are more complex than single servers because work must be quickly coordinated and shared among the individual computers. Clusters are very scalable because one can always add one more computer to the cluster.
- A virtual server is one computer that acts as several servers. Using special software, several operating systems are installed on the same physical computer so that one physical computer appears as several different servers to the network. These virtual servers can perform the same or separate functions (e.g., a printer server, Web server, file server). This improves efficiency (when each server is not fully used, there is no need to buy separate physical computers) and may improve effectiveness (if one virtual server crashes, it does not crash the other servers on the same computer).
There are five commonly used types of clients:
- A personal computer is the most common type of client today. This includes desktop and laptop computers, as well as Tablet PCs that enable the user to write with a pen-like stylus instead of typing on a keyboard.
- A terminal is a device with a monitor and keyboard but no central processing unit (CPU). Dumb terminals, so named because they do not participate in the processing of the data they display, have the bare minimum required to operate as input and output devices (a TV screen and a keyboard). In most cases when a character is typed on a dumb terminal, it transmits the character through the circuit to the server for processing. Every keystroke is processed by the server, even simple activities such as the up arrow.
- A network computer is designed primarily to communicate using Internet-based standards (e.g., HTTP, Java) but has no hard disk. It has only limited functionality.
- A transaction terminal is designed to support specific business transactions, such as the automated teller machines (ATM) used by banks. Other examples of transaction terminals are point-of-sale terminals in a supermarket.
- A handheld computer, Personal Digital Assistant (PDA), or mobile phone can also be used as a network client.
2.2.1 Host-Based Architectures
The very first data communications networks developed in the 1960s were host-based, with the server (usually a large mainframe computer) performing all four functions. The clients (usually terminals) enabled users to send and receive messages to and from the host computer. The clients merely captured keystrokes, sent them to the server for processing, and accepted instructions from the server on what to display (see Figure 2.1).
This very simple architecture often works very well. Application software is developed and stored on the one server along with all data. If you've ever used a terminal, you've used a host-based application. There is one point of control, because all messages flow through the one central server. In theory, there are economies of scale, because all computer resources are centralized (but more on cost later).
There are two fundamental problems with host-based networks. First, the server must process all messages. As the demands for more and more network applications grow, many servers become overloaded and unable to quickly process all the users’ demands. Prioritizing users’ access becomes difficult. Response time becomes slower, and network managers are required to spend increasingly more money to upgrade the server. Unfortunately, upgrades to the mainframes that usually are the servers in this architecture are “lumpy.” That is, upgrades come in large increments and are expensive (e.g., $500,000); it is difficult to upgrade “a little.”
2.2.2 Client-Based Architectures
In the late 1980s, there was an explosion in the use of personal computers. Today, more than 90 percent of most organizations’ total computer processing power now resides on personal computers, not in centralized mainframe computers. Part of this expansion was fueled by a number of low-cost, highly popular applications such as word processors, spreadsheets, and presentation graphics programs. It was also fueled in part by managers’ frustrations with application software on host mainframe computers. Most mainframe software is not as easy to use as personal computer software, is far more expensive, and can take years to develop. In the late 1980s, many large organizations had application development backlogs of two to three years; that is, getting any new mainframe application program written would take years. New York City, for example, had a six-year backlog. In contrast, managers could buy personal computer packages or develop personal computer-based applications in a few months.
With client-based architectures, the clients are personal computers on a LAN, and the server is usually another personal computer on the same network. The application software on the client computers is responsible for the presentation logic, the application logic, and the data access logic; the server simply stores the data (Figure 2.2).
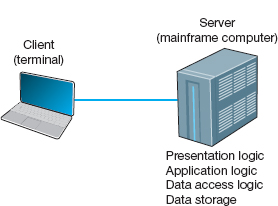
FIGURE 2.1 Host-based architecture
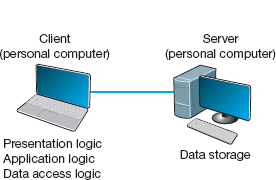
FIGURE 2.2 Client-based architecture
This simple architecture often works very well. If you've ever used a word processor and stored your document file on a server (or written a program in Visual Basic or C that runs on your computer but stores data on a server), you've used a client-based architecture.
The fundamental problem in client-based networks is that all data on the server must travel to the client for processing. For example, suppose the user wishes to display a list of all employees with company life insurance. All the data in the database (or all the indices) must travel from the server where the database is stored over the network circuit to the client, which then examines each record to see if it matches the data requested by the user. This can overload the network circuits because far more data is transmitted from the server to the client than the client actually needs.
2.2.3 Client-Server Architectures
Most applications written today use client-server architectures. Client-server architectures attempt to balance the processing between the client and the server by having both do some of the logic. In these networks, the client is responsible for the presentation logic, whereas the server is responsible for the data access logic and data storage. The application logic may either reside on the client, reside on the server, or be split between both.
Figure 2.3 shows the simplest case, with the presentation logic and application logic on the client and the data access logic and data storage on the server. In this case, the client software accepts user requests and performs the application logic that produces database requests that are transmitted to the server. The server software accepts the database requests, performs the data access logic, and transmits the results to the client. The client software accepts the results and presents them to the user. When you used a Web browser to get pages from a Web server, you used a client-server architecture. Likewise, if you've ever written a program that uses SQL to talk to a database on a server, you've used a client-server architecture.
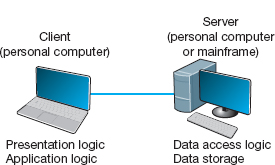
FIGURE 2.3 Two-tier client-server architecture
For example, if the user requests a list of all employees with company life insurance, the client would accept the request, format it so that it could be understood by the server, and transmit it to the server. On receiving the request, the server searches the database for all requested records and then transmits only the matching records to the client, which would then present them to the user. The same would be true for database updates; the client accepts the request and sends it to the server. The server processes the update and responds (either accepting the update or explaining why not) to the client, which displays it to the user.
One of the strengths of client-server networks is that they enable software and hardware from different vendors to be used together. But this is also one of their disadvantages, because it can be difficult to get software from different vendors to work together. One solution to this problem is middleware, software that sits between the application software on the client and the application software on the server. Middleware does two things. First, it provides a standard way of communicating that can translate between software from different vendors. Many middleware tools began as translation utilities that enabled messages sent from a specific client tool to be translated into a form understood by a specific server tool.
The second function of middleware is to manage the message transfer from clients to servers (and vice versa) so that clients need not know the specific server that contains the application's data. The application software on the client sends all messages to the middleware, which forwards them to the correct server. The application software on the client is therefore protected from any changes in the physical network. If the network layout changes (e.g., a new server is added), only the middleware must be updated.
There are literally dozens of standards for middleware, each of which is supported by different vendors and each of which provides different functions. Two of the most important standards are Distributed Computing Environment (DCE) and Common Object Request Broker Architecture (CORBA). Both of these standards cover virtually all aspects of the client-server architecture but are quite different. Any client or server software that conforms to one of these standards can communicate with any other software that conforms to the same standard. Another important standard is Open Database Connectivity (ODBC), which provides a standard for data access logic.
Two-Tier, Three-Tier, and n-Tier Architectures There are many ways in which the application logic can be partitioned between the client and the server. The example in Figure 2.3 is one of the most common. In this case, the server is responsible for the data and the client, the application and presentation. This is called a two-tier architecture, because it uses only two sets of computers, one set of clients and one set of servers.
A three-tier architecture uses three sets of computers, as shown in Figure 2.4. In this case, the software on the client computer is responsible for presentation logic, an application server is responsible for the application logic, and a separate database server is responsible for the data access logic and data storage.
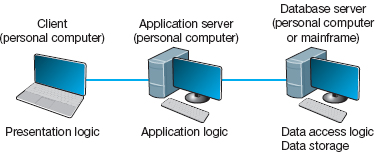
FIGURE 2.4 Three-tier client-server architecture
N -tier architecture uses more than three sets of computers. In this case, the client is responsible for presentation logic, a database server is responsible for the data access logic and data storage, and the application logic is spread across two or more different sets of servers. Figure 2.5 shows an example of an n-tier architecture of a groupware product called TCB-Works developed at the University of Georgia. TCB Works has four major components. The first is the Web browser on the client computer that a user uses to access the system and enter commands (presentation logic). The second component is a Web server that responds to the user's requests, either by providing HTML pages and graphics (application logic) or by sending the request to the third component, a set of 28 C programs that perform various functions such as adding comments or voting (application logic). The fourth component is a database server that stores all the data (data access logic and data storage). Each of these four components is separate, making it easy to spread the different components on different servers and to partition the application logic on two different servers.
The primary advantage of an n-tier client-server architecture compared with a two-tier architecture (or a three-tier compared with a two-tier) is that it separates the processing that occurs to better balance the load on the different servers; it is more scalable. In Figure 2.5, we have three separate servers, which provides more power than if we had used a two-tier architecture with only one server. If we discover that the application server is too heavily loaded, we can simply replace it with a more powerful server, or even put in two application servers. Conversely, if we discover the database server is underused, we could put data from another application on it.
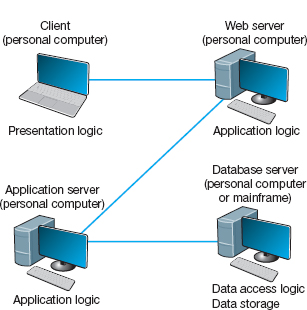
FIGURE 2.5 The n -tier client-server architecture
There are two primary disadvantages to an n-tier architecture compared with a two-tier architecture (or a three-tier with a two-tier). First, it puts a greater load on the network. If you compare Figures 2.3, 2.4, and 2.5, you will see that the n-tier model requires more communication among the servers; it generates more network traffic so you need a higher capacity network. Second, it is much more difficult to program and test software in n-tier architectures than in two-tier architectures because more devices have to communicate to complete a user's transaction.
Thin Clients versus Thick Clients Another way of classifying client-server architectures is by examining how much of the application logic is placed on the client computer. A thin-client approach places little or no application logic on the client (e.g., Figure 2.5), whereas a thick-client (also called fat-client) approach places all or almost all of the application logic on the client (e.g., Figure 2.3). There is no direct relationship between thin and fat client and two-, three- and n-tier architectures. For example, Figure 2.6 shows a typical Web architecture: a two-tier architecture with a thin client. One of the biggest forces favoring thin clients is the Web.
Thin clients are much easier to manage. If an application changes, only the server with the application logic needs to be updated. With a thick client, the software on all of the clients would need to be updated. Conceptually, this is a simple task; one simply copies the new files to the hundreds of affected client computers. In practice, it can be a very difficult task.
Thin-client architectures are the future. More and more application systems are being written to use a Web browser as the client software, with Java Javascriptor AJAX (containing some of the application logic) downloaded as needed. This application architecture is sometimes called the distributed computing model.
2.2.4 Peer-to-Peer Architectures
Peer-to-peer (P2P) architectures are very old, but their modern design became popular in the early 2000s with the rise of P2P file sharing applications (e.g., Napster). With a P2P architecture, all computers act as both a client and a server. Therefore, all computers perform all four functions: presentation logic, application logic, data access logic, and data storage (see Figure 2.7). With a P2P file sharing application, a user uses the presentation, application, and data access logic installed on his or her computer to access the data stored on another computer in the network. With a P2P application sharing network (e.g., grid computing such as seti.org), other users in the network can use others’ computers to access application logic as well.
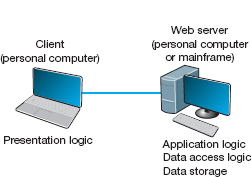
FIGURE 2.6 The typical two-tier thin-client architecture of the Web
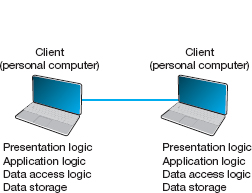
FIGURE 2.7 Peer-to-peer architecture
The advantage of P2P networks is that the data can be installed anywhere on the network. They spread the storage throughout the network, even globally, so they can be very resilient to the failure of any one computer. The challenge is finding the data. There must be some central server that enables you to find the data you need, so P2P architectures often are combined with a client-server architecture. Security is a major concern in most P2P networks, so P2P architectures are not commonly used in organizations, except for specialized computing needs (e.g., grid computing).
2.2.5 Choosing Architectures
Each of the preceding architectures has certain costs and benefits, so how do you choose the “right” architecture? In many cases, the architecture is simply a given; the organization has a certain architecture, and one simply has to use it. In other cases, the organization is acquiring new equipment and writing new software and has the opportunity to develop a new architecture, at least in some part of the organization.
Almost all new applications today are client-server applications. Client-server architectures provide the best scalability, the ability to increase (or decrease) the capacity of the servers to meet changing needs. For example, we can easily add or remove application servers or database servers depending on whether we need more or less capacity for application software or database software and storage.
Client-server architectures are also the most reliable. We can use multiple servers to perform the same tasks, so that if one server fails, the remaining servers continue to operate and users don't notice problems.
Finally, client-server architectures are usually the cheapest because many tools exist to develop them. And lots of client-server software exists for specific parts of applications so we can more quickly buy parts of the application we need. For example, no one writes Shopping Carts anymore; it's cheaper to buy a Shopping Carts software application and put it on an application server than it is to write your own.
Client-server architectures also enable cloud computing. With thin-client client-server architectures, all software resides on a server, whether it is a Web server, application server, or database server. Normally, these servers would be owned and operated by the company itself, but it is not necessary—a server can be anywhere on the Internet and still provide its services to the clients and servers that need them.
2.1 CLOUD COMPUTING WITH SALESFORCE.COM
MANAGEMENT FOCUS
Salesforce.com is the poster child for cloud computing. Companies used to buy and install software for customer relationship management (CRM), the process of identifying potential customers, marketing to them, converting them into customers, and managing the relationship to retain them. The software and needed servers were expensive and took a long time to acquire and install. Typically, only large firms could afford it.
Salesforce.com changed this by offering a cloud computing solution. The CRM software offered by salesforce.com resides on the salesforce.com servers. There is no need to buy and install new hardware or software. Companies just pay a monthly fee to access the software over the Internet. Companies can be up and running in weeks, not months, and it is easy to scale from a small implementation to a very large one. Because salesforce.com can spread its costs over so many users, they can offer deals to small companies that normally wouldn't be able to afford to buy and install their own software.
With cloud computing, a company contracts with another firm to provide software services over the Internet, rather than installing the software on its own servers. The company no longer buys and manages its own servers and software, but instead pays a monthly subscription fee or a fee based on how much they use the application. Because the cloud computing provider provides the same services to many companies, it has considerable economies of scale that drive down costs. Therefore, cloud computing is often cheaper than other options—at least for commonly used applications.
Gmail is a good example of cloud computing. Gmail is available to individuals for free, but Google has made the same service available to companies for a fee. Companies pay $50 per user per year for private email service using their company name (e.g., [email protected]). Many companies have determined that it is cheaper to pay for gmail than to buy and operate their own email servers. For example, Indiana University has moved to this model for all undergraduate students.
Client server architecture also enables server virtualization, which is essentially the opposite of scaling. With scaling, we add more servers, whether Web servers, application servers, or database servers, depending on which part of the architecture needs more capacity. Server virtualization means to install many virtual or logical servers on the same physical computer.
Many firms have implemented client-server architectures using separate computers for each server, only to discover that the computers are not fully used; they are running at 10% or less of their capacity. Server virtualization combines many separate logical servers onto the same physical computer, but keeps each of the servers separate so that if one has problems, it does not affect the other servers running on the same physical computer. This way the company is not wasting money to buy and operate many separate computers that sit idle much of the time. Server virtualization is also a major part of green computing—that is, environmentally sustainable computing—because it reduces the number of computers needed and therefore reduces amount of electricity and cooling needed in the server room.
Server virtualization requires special software on a physical computer that will host the different logical servers. This software (VMware is one of the leading packages) creates a separate partition on the physical server for each of the logical servers. Each partition has its own operating system (e.g., Windows, Linux) and its own server software and works independently from the other partitions. The number of logical servers hosted on each physical server depends on the amount of traffic and how busy each server is, but a common rule of thumb is three logical servers per physical server.
2.3 WORLD WIDE WEB
The Web was first conceived in 1989 by Sir Tim Berners-Lee at the European Particle Physics Laboratory (CERN) in Geneva. His original idea was to develop a database of information on physics research, but he found it difficult to fit the information into a traditional database. Instead, he decided to use a hypertext network of information. With hypertext, any document can contain a link to any other document.
CERN's first Web browser was created in 1990, but it was 1991 before it was available on the Internet for other organizations to use. By the end of 1992, several browsers had been created for UNIX computers by CERN and several other European and American universities, and there were about 30 Web servers in the entire world. In 1993, Marc Andreessen, a student at the University of Illinois, led a team of students that wrote Mosaic, the first graphical Web browser, as part of a project for the university's National Center for Supercomputing Applications (NCSA). By the end of 1993, the Mosaic browser was available for UNIX, Windows, and Macintosh computers, and there were about 200 Web servers in the world. Today, no one knows for sure how many Web servers there are. There are more than 250 million separate Web sites, but many of these are hosted on the same servers by large hosting companies such as godaddy.com or google sites.
2.3.1 How the Web Works
The Web is a good example of a two-tier client-server architecture (Figure 2.8). Each client computer needs an application layer software package called a Web browser. There are many different browsers, such as Microsoft's Internet Explorer. Each server on the network that will act as a Web server needs an application layer software package called a Web server. There are many different Web servers, such as those produced by Microsoft and Apache.
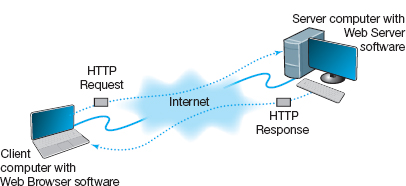
To get a page from the Web, the user must type the Internet uniform resource locator (URL) for the page he or she wants (e.g., www.yahoo.com) or click on a link that provides the URL. The URL specifies the Internet address of the Web server and the directory and name of the specific page wanted. If no directory and page are specified, the Web server will provide whatever page has been defined as the site's home page.
For the requests from the Web browser to be understood by the Web server, they must use the same standard protocol or language. If there were no standard and each Web browser used a different protocol to request pages, then it would be impossible for a Microsoft Web browser to communicate with an Apache Web server, for example.
The standard protocol for communication between a Web browser and a Web server is Hypertext Transfer Protocol (HTTP). 1 To get a page from a Web server, the Web browser issues a special packet called an HTTP request that contains the URL and other information about the Web page requested (see Figure 2.8). Once the server receives the HTTP request, it processes it and sends back an HTTP response, which will be the requested page or an error message (see Figure 2.8).
This request-response dialogue occurs for every file transferred between the client and the server. For example, suppose the client requests a Web page that has two graphic images. Graphics are stored in separate files from the Web page itself using a different file format than the HTML used for the Web page (in JPEG [Joint Photographic Experts Group] format, for example). In this case, there would be three request-response pairs. First, the browser would issue a request for the Web page, and the server would send the response. Then, the browser would begin displaying the Web page and notice the two graphic files. The browser would then send a request for the first graphic and a request for the second graphic, and the server would reply with two separate HTTP responses, one for each request.
2.3.2 Inside an HTTP Request
The HTTP request and HTTP response are examples of the packets we introduced in Chapter 1 that are produced by the application layer and sent down to the transport, network, data link, and physical layers for transmission through the network. The HTTP response and HTTP request are simple text files that take the information provided by the application (e.g., the URL to get) and format it in a structured way so that the receiver of the message can clearly understand it.
An HTTP request from a Web browser to a Web server has three parts. The first two parts are required; the last is optional. The parts are:
- The request line, which starts with a command (e.g., get), provides the Web page and ends with the HTTP version number that the browser understands; the version number ensures that the Web server does not attempt to use a more advanced or newer version of the HTTP standard that the browser does not understand.
- The request header, which contains a variety of optional information such as the Web browser being used (e.g., Internet Explorer) and the date.
- The request body, which contains information sent to the server, such as information that the user has typed into a form.
Figure 2.9 shows an example of an HTTP request for a page on our Web server, formatted using version 1.1 of the HTTP standard. This request has only the request line and the request header, because no request body is needed for this request. This request includes the date and time of the request (expressed in Greenwich Mean Time [GMT], the time zone that runs through London) and name of the browser used (Mozilla is the code name for the browser). The “Referrer” field means that the user obtained the URL for this Web page by clicking on a link on another page, which in this case is a list of faculty at Indiana University (i.e., www.indiana.edu/~isdept/faculty.htm). If the referrer field is blank, then it means the user typed the URL him- or herself. You can see inside HTTP headers yourself at www.rexswain.com/httpview.html.
2.3.3 Inside an HTTP Response
The format of an HTTP response from the server to the browser is very similar to the HTTP request. It, too, has three parts, with the first required and the last two optional:
- The response status, which contains the HTTP version number the server has used, a status code (e.g., 200 means “okay”; 404 means “not found”), and a reason phrase (a text description of the status code).
- The response header, which contains a variety of optional information, such as the Web server being used (e.g., Apache), the date, and the exact URL of the page in the response.
- The response body, which is the Web page itself.

FIGURE 2.9 An example of a request from a Web browser to a Web server using the HTTP (Hypertext Transfer Protocol) standard
Figure 2.10 shows an example of a response from our Web server to the request in Figure 2.9. This example has all three parts. The response status reports “OK,” which means the requested URL was found and is included in the response body. The response header provides the date, the type of Web server software used, the actual URL included in the response body, and the type of file. In most cases, the actual URL and the requested URL are the same, but not always. For example, if you request an URL but do not specify a file name (e.g., www.indiana.edu), you will receive whatever file is defined as the home page for that server, so the actual URL will be different from the requested URL.

FIGURE 2.10 An example of a response from a Web server to a Web browser using the HTTP standard
2.2 FREE SPEECH REIGNS ON THE INTERNET … OR DOES IT?
MANAGEMENT FOCUS
In a landmark decision in 1997, the U.S. Supreme Court ruled that the sections of the 1996 Telecommunications Act restricting the publication of indecent material on the Web and the sending of indecent email were unconstitutional. This means that anyone can do anything on the Internet, right?
Well, not really. The court decision affects only Internet servers located in the United States. Each country in the world has different laws that govern what may and may not be placed on servers in their country. For example, British law restricts the publication of pornography, whether on paper or on Internet servers.
Many countries such as Singapore, Saudi Arabia, and China prohibit the publication of certain political information. Because much of this “subversive” information is published outside of their countries, they actively restrict access to servers in other countries.
Other countries are very concerned about their individual cultures. In 1997, a French court convicted Georgia Institute of Technology of violating French language law. Georgia Tech operates a small campus in France that offers summer programs for American students. The information on the campus Web server was primarily in English because classes are conducted in English. This violated the law requiring French to be the predominant language on all Internet servers in France.
The most likely source of problems for North Americans lies in copyright law. Free speech does not give permission to copy from others. It is against the law to copy and republish on the Web any copyrighted material or any material produced by someone else without explicit permission. So don't copy graphics from someone else's Web site or post your favorite cartoon on your Web site, unless you want to face a lawsuit.
The response body in this example shows a Web page in Hypertext Markup Language (HTML). The response body can be in any format, such as text, Microsoft Word, Adobe PDF, or a host of other formats, but the most commonly used format is HTML. HTML was developed by CERN at the same time as the first Web browser and has evolved rapidly ever since. HTML is covered by standards produced by the IETF, but Microsoft keeps making new additions to HTML with every release of its browser, so the HTML standard keeps changing.
2.4 ELECTRONIC MAIL
Electronic mail (or email) was one of the earliest applications on the Internet and is still among the most heavily used today. With email, users create and send messages to one user, several users, or all users on a distribution list. Most email software enables users to send text messages and attach files from word processors, spreadsheets, graphics programs, and so on. Many email packages also permit you to filter or organize messages by priority.
Several standards have been developed to ensure compatibility between different email software packages. Any software package that conforms to a certain standard can send messages that are formatted using its rules. Any other package that understands that particular standard can then relay the message to its correct destination; however, if an email package receives a mail message in a different format, it may be unable to process it correctly. Many email packages send using one standard but can understand messages sent in several different standards. The most commonly used standard is SMTP (Simple Mail Transfer Protocol). Other common standards are X. 400 and CMC (Common Messaging Calls). In this book, we will discuss only SMTP, but CMC and X.400 both work essentially the same way. SMTP, X.400, and CMC are different from one another (in the same way that English differs from French or Spanish), but several software packages are available that translate between them, so that companies that use one standard (e.g., CMC) can translate messages they receive that use a different standard (e.g., SMTP) into their usual standard as they first enter the company and then treat them as “normal” email messages after that.
2.4.1 How Email Works
The Simple Mail Transfer Protocol (SMTP) is the most commonly used email standard simply because it is the email standard used on the Internet.2 Email works similarly to how the Web works, but it is a bit more complex. SMTP email is usually implemented as a two-tier thick client-server application, but not always. We first explain how the normal two-tier thick client architecture works and then quickly contrast that with two alternate architectures.
Two-Tier Email Architecture With a two-tier thick client-server architecture, each client computer runs an application layer software package called a mail user agent, which is usually more commonly called an email client (Figure 2.10). There are many common email client software packages such as Eudora and Outlook. The user creates the email message using one of these email clients, which formats the message into an SMTP packet that includes information such as the sender's address and the destination address.
The user agent then sends the SMTP packet to a mail server that runs a special application layer software package called a mail transfer agent, which is more commonly called mail server software (see Figure 2.11).
This email server reads the SMTP packet to find the destination address and then sends the packet on its way through the network—often over the Internet—from mail server to mail server, until it reaches the mail server specified in the destination address (see Figure 2.11). The mail transfer agent on the destination server then stores the message in the receiver's mailbox on that server. The message sits in the mailbox assigned to the user who is to receive the message until he or she checks for new mail.
The SMTP standard covers message transmission between mail servers (i.e., mail server to mail server) and between the originating email client and its mail server. A different standard is used to communicate between the receiver's email client and his or her mail server. Two commonly used standards for communication between email client and mail server are Post Office Protocol (POP) and Internet Message Access Protocol (IMAP). Although there are several important technical differences between POP and IMAP, the most noticeable difference is that before a user can read a mail message with a POP (version 3) email client, the email message must be copied to the client computer's hard disk and deleted from the mail server. With IMAP, email messages can remain stored on the mail server after they are read. IMAP therefore offers considerable benefits to users who read their email from many different computers (e.g., home, office, computer labs) because they no longer need to worry about having old email messages scattered across several client computers; all email is stored on the server until it is deleted.
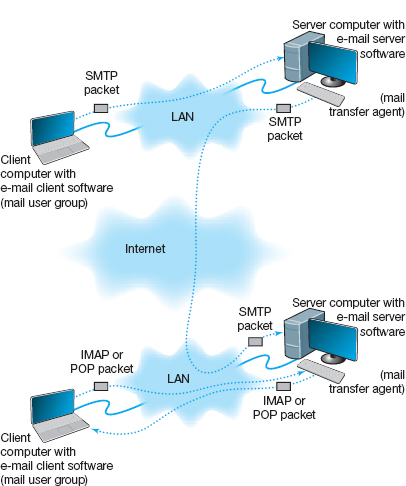
FIGURE 2.11 How SMTP (Simple Mail Transfer Protocol) email works. IMAP = Internet Message Access Protocol; LAN = local area network
In our example in Figure 2.11, when the receiver next accesses his or her email, the email client on his or her computer contacts the mail server by sending an IMAP or POP packet that asks for the contents of the user's mailbox. In Figure 2.11, we show this as an IMAP packet, but it could just as easily be a POP packet. When the mail server receives the IMAP or POP request, it converts the original SMTP packet created by the message sender into a POP or IMAP packet that is sent to the client computer, which the user reads with the email client. Therefore, any email client using POP or IMAP must also understand SMTP to create messages. POP and IMAP provide a host of functions that enable the user to manage his or her email, such as creating mail folders, deleting mail, creating address books, and so on. If the user sends a POP or IMAP request for one of these functions, the mail server will perform the function and send back a POP or IMAP response packet that is much like an HTTP response packet.
Three-Tier Thin Client-Server Architecture The three-tier thin client-server email architecture uses a Web server and Web browser to provide access to your email. With this architecture, you do not need an email client on your client computer. Instead, you use your Web browser. This type of email is sometimes called Web-based email and is provided by a variety of companies such as Hotmail and Yahoo.
You use your browser to connect to a page on a Web server that lets you write the email message by filling in a form. When you click the send button, your Web browser sends the form information to the Web server inside an HTTP request (Figure 2.12). The Web server runs a program (written in C or Perl, for example) that takes the information from the HTTP request and builds an SMTP packet that contains the email message. Although not important to our example, it also sends an HTTP response back to the client. The Web server then sends the SMTP packet to the mail server, which processes the SMTP packet as though it came from a client computer. The SMTP packet flows through the network in the same manner as before. When it arrives at the destination mail server, it is placed in the receiver's mailbox.
When the receiver wants to check his or her mail, he or she uses a Web browser to send an HTTP request to a Web server (see Figure 2.12). A program on the Web server (in C or Perl, for example) processes the request and sends the appropriate POP request to the mail server. The mail server responds with a POP packet, which a program on the Web server converts into an HTTP response and sends to the client. The client then displays the email message in the Web browser Web-based email.
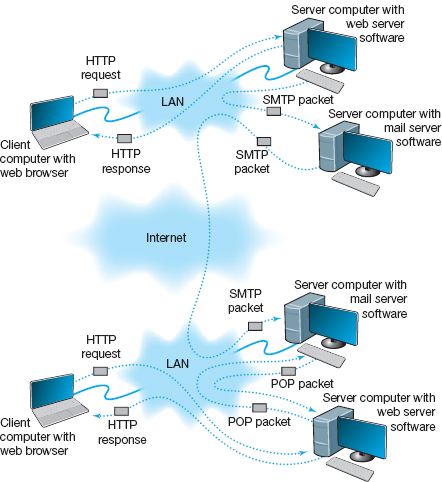
FIGURE 2.12 Inside the Web. HTTP = Hypertext Transfer Protocol; IMAP = Internet Message Access Protocol; LAN = local area network; SMTP = Simple Mail Transfer Protocol
TECHNICAL FOCUS
SMTP (Simple Mail Transfer Protocol) is an older protocol, and transmission using it is rather complicated. If we were going to design it again, we would likely find a simpler transmission method. Conceptually, we think of an SMTP packet as one packet. However, SMTP mail transfer agents transmit each element within the SMTP packet as a separate packet and wait for the receiver to respond with an “OK” before sending the next element.
For example, in Figure 2.13, the sending mail transfer agent would send the from address and wait for an OK from the receiver. Then it would send the to address and wait for an OK. Then it would send the date, and so on, with the last item being the entire message sent as one element.
A simple comparison of Figures 2.11 and 2.12 will quickly show that the three-tier approach using a Web browser is much more complicated than the normal two-tier approach. So why do it? Well, it is simpler to have just a Web browser on the client computer rather than to require the user to install a special email client on his or her computer and then set up the special email client to connect to the correct mail server using either POP or IMAP. It is simpler for the user to just type the URL of the Web server providing the mail services into his or her browser and begin using mail. This also means that users can check their email from a public computer anywhere on the Internet.
It is also important to note that the sender and receiver do not have to use the same architecture for their email. The sender could use a two-tier client-server architecture, and the receiver, a host-based or three-tier client-server architecture. Because all communication is standardized using SMTP between the different mail servers, how the users interact with their mail servers is unimportant. Each organization can use a different approach.
In fact, there is nothing to prevent one organization from using all three architectures simultaneously. At Indiana University, email is usually accessed through an email client (e.g., Microsoft Outlook), but is also accessed over the Web because many users travel internationally and find it easier to borrow a Web browser with Internet access than to borrow an email client and set it up to use the Indiana University mail server.
2.4.2 Inside an SMTP Packet
SMTP defines how message transfer agents operate and how they format messages sent to other message transfer agents. An SMTP packet has two parts:
- The header, which lists source and destination email addresses (possibly in text form [e.g., “Pat Smith”]) as well as the address itself (e.g., [email protected]), date, subject, and so on.
- The body, which is the word DATA, followed by the message itself.
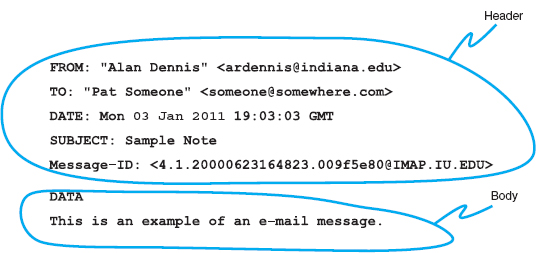
FIGURE 2.13 An example of an email message using the SMTP (Simple Mail Transfer Protocol) standard
Figure 2.13 shows a simple email message formatted using SMTP. The header of an SMTP message has a series of fields that provide specific information, such as the sender's email address, the receiver's address, date, and so on. The information in quotes on the from and to lines is ignored by SMTP; only the information in the angle brackets is used in email addresses. The message ID field is used to provide a unique identification code so that the message can be tracked. The message body contains the actual text of the message itself.
2.4.3 Attachments in Multipurpose Internet Mail Extension
As the name suggests, SMTP is a simple standard that permits only the transfer of text messages. It was developed in the early days of computing, when no one had even thought about using email to transfer nontext files such as graphics or word processing documents. Several standards for nontext files have been developed that can operate together with SMTP, such as Multipurpose Internet Mail Extension (MIME), uuencode, and binhex.
Each of the standards is different, but all work in the same general way. The MIME software, which exists as part of the email client, takes the nontext file such as a PowerPoint graphic file, and translates each byte in the file into a special code that looks like regular text. This encoded section of “text” is then labeled with a series of special fields understood by SMTP as identifying a MIME-encoded attachment and specifying information about the attachment (e.g., name of file, type of file). When the receiver's email client receives the SMTP message with the MIME attachment, it recognizes the MIME “text” and uses its MIME software (that is part of the email client) to translate the file from MIME “text” back into its original format.
2.5 OTHER APPLICATIONS
There are literally thousands of applications that run on the Internet and on other networks. Most application software that we develop today, whether for sale or for private internal use, runs on a network. We could spend years talking about different network applications and still cover only a small number.
A Day in the Life: Network Manager
It was a typical day for a network manager. It began with the setup and troubleshooting for a videoconference. Videoconferencing is fairly routine activity but this one was a little different; we were trying to video-conference with a different company who used different standards than we did. We attempted to use our usual web-based videoconferencing but could not connect. We fell back to ISDN-based videoconferencing over telephone lines, which required bringing in our videoconferencing services group. It took two hours but we finally had the technology working.
The next activity was building a Windows database server. This involved installing software, adding a server into our ADS domain, and setting up the user accounts. Once the server was on the network, it was critical to install all the security patches for both the operating system and database server. We receive so many security attacks that it is our policy to install all security patches on the same day that new software or servers are placed on the network or the patches are released.
After lunch, the next two hours was spent in a boring policy meeting. These meetings are a necessary evil to ensure that the network is well-managed. It is critical that users understand what the network can and can't be used for, and our ability to respond to users’ demands. Managing users’ expectations about support and use rules helps ensure high user satisfaction.
The rest of the day was spent refining the tool we use to track network utilization. We have a simple intrusion detection system to detect hackers, but we wanted to provide more detailed information on network errors and network utilization to better assist us in network planning.
With thanks to Jared Beard
Fortunately, most network application software works in much the same way as the Web or email. In this section, we will briefly discuss only three commonly used applications: Telnet, instant messaging (IM), and Video conferencing.
2.5.1 Telnet
Telnet enables users to log in to servers (or other clients). It requires an application layer program on the client computer and an application layer program on the server or host computer. Once Telnet makes the connection from the client to the server, you must use the account name and password of an authorized user to log in.
Although Telnet was developed in the very early days of the Internet (actually, the very first application that tested the connectivity on ARPANET was Telnet), it is still widely used today. Because it was developed so long ago, Telnet assumes a host-based architecture. Any key strokes that you type using Telnet are sent to the server for processing and then the server instructs the client what to display in on the screen.
One of the most frequently used Telnet software packages is PuTTY. PuTTY is open source and can be downloaded for free (and in case you're wondering, the name does not stand for anything, although TTY is a commonly used abbreviation for “terminal” in Unix-based systems).
The very first Telnet applications posed a great security threat because every key stroke was sent over the network as plain text. PuTTY uses secure shell (SSH) encryption when communicating with the server so that no one can read what is typed. An additional advantage of PuTTY is that it can run on multiple platforms, such as Windows, Mac, or Linux. Today, PuTTY is routinely used by network administrators to log in to servers and routers to make configuration changes.
MANAGEMENT FOCUS
Joseph Krull has a chip on his shoulder—well, in his shoulder to be specific. Krull is one of a small but growing number of people who have a Radio Frequency Identification (RFID) chip implanted in their bodies.
RFID technology has been used to identify pets, so that lost pets can be easily reunited with their owners. Now, the technology is being used for humans.
Krull has a blown left pupil from a skiing accident. If he were injured in an accident and unable to communicate, an emergency room doctor might misinterpret his blown pupil as a sign of a major head injury and begin drilling holes to relieve pressure. Now doctors can use the RFID chip to identify Krull and quickly locate his complete medical records on the Internet.
Critics say such RFID chips pose huge privacy risks because they enable any firms using RFID to track users such as Krull. Retailers, for example, can track when he enters and leaves their stores.
Krull doesn't care. He believes the advantages of having his complete medical records available to any doctor greatly outweighs the privacy concerns.
Tagging people is no longer the novelty it once was; in fact, today it is a U.S. Food and Drug Administration approved procedure. More that 10% of all RFID research projects worldwide involve tagging people. There are even do-it-yourself RFID tagging kits available—not that we would recommend them (http://www.youtube.com/watch?v=vsk6dJr4wps).
Besides the application to health records, RFID is also being used for security applications, even something as simple as door locks. Imagine having an RFID-based door lock that opens automatically when you walk up to it because it recognizes the RFID tag in your body.
__________
SOURCE: NetworkWorld, ZDNet, and GizMag.com.
2.5.2 Instant Messaging
One of the fastest growing Internet applications has been instant messaging (IM). With IM, you can exchange real-time typed messages or chat with your friends. Some IM software also enables you to verbally talk with your friends in the same way as you might use the telephone or to use cameras to exchange real-time video in the same way you might use a videoconferencing system. Several types of IM currently exist, including Google Talk and AOL Instant Messenger.
Instant messaging works in much the same way as the Web. The client computer needs an IM client software package, which communicates with an IM server software package that runs on a server. When the user connects to the Internet, the IM client software package sends an IM request packet to the IM server informing it that the user is now online. The IM client software package continues to communicate with the IM server to monitor what other users have connected to the IM server. When one of your friends connects to the IM server, the IM server sends an IM packet to your client computer so that you now know that your friend is connected to the Internet. The server also sends a packet to your friend's client computer so that he or she knows that you are on the Internet.
With the click of a button, you can both begin chatting. When you type text, your IM client creates an IM packet that is sent to the IM server (Figure 2.14). The server then retransmits the packet to your friend. Several people may be part of the same chat session, in which case the server sends a copy of the packet to all of the client computers. IM also provides a way for different servers to communicate with one another, and for the client computers to communicate directly with each other. Additionaly, IM will do Voice and Video.
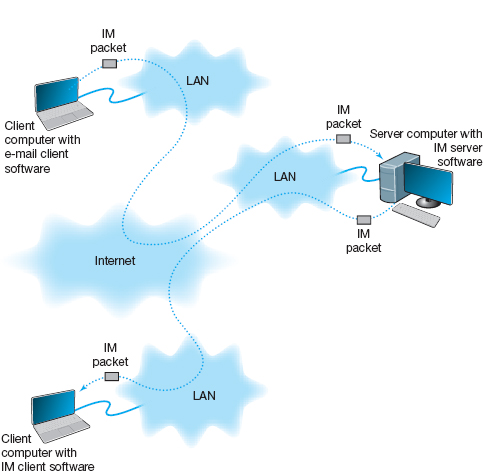
FIGURE 2.14 How instant messaging (IM) works. LAN = local area network
2.5.3 Videoconferencing
Videoconferencing provides real-time transmission of video and audio signals to enable people in two or more locations to have a meeting. In some cases, videoconferences are held in special-purpose meeting rooms with one or more cameras and several video display monitors to capture and display the video signals (Figure 2.15). Special audio microphones and speakers are used to capture and play audio signals. The audio and video signals are combined into one signal that is transmitted though a MAN or WAN to people at the other location. Most of this type of videoconferencing involves two teams in two separate meeting rooms, but some systems can support conferences of up to eight separate meeting rooms. Some advanced systems provide telepresence, which is of such high quality that you feel you are face-to-face with the other participants.
The fastest growing form of videoconferencing is desktop videoconferencing. Small cameras installed on top of each computer permit meetings to take place from individual offices (Figure 2.16). Special application software (e.g., Yahoo IM, Skype, Net Meeting) is installed on the client computer and transmits the images across a network to application software on a videoconferencing server. The server then sends the signals to the other client computers that want to participate in the videoconference. In some cases, the clients can communicate with one another without using the server. The cost of desktop videoconferencing ranges from less than $20 per computer for inexpensive systems to more than $1,000 for high-quality systems. Some systems have integrated conferencing software with desktop videoconferencing, enabling participants to communicate verbally and, by using applications such as white boards, to attend the same meeting while they are sitting at the computers in their offices.

FIGURE 2.15 A Cisco telepresence system
Source: Courtesy Cisco Systems, Inc. Unauthorized use not permitted.
The transmission of video requires a lot of network capacity. Most videoconferencing uses data compression to reduce the amount of data transmitted. Surprisingly, the most common complaint is not the quality of the video image but the quality of the voice transmissions. Special care needs to be taken in the design and placement of microphones and speakers to ensure quality sound and minimal feedback.
Most videoconferencing systems were originally developed by vendors using different formats, so many products were incompatible. The best solution was to ensure that all hardware and software used within an organization was supplied by the same vendor and to hope that any other organizations with whom you wanted to communicate used the same equipment. Today, three standards are in common use: H.320, H.323, and MPEG-2 (also called ISO 13818-2). Each of these standards was developed by different organizations and is supported by different products. They are not compatible, although some application software packages understand more than one standard. H.320 is designed for room-to-room videoconferencing over high-speed telephone lines. H.323 is a family of standards designed for desktop videoconferencing and just simple audio conferencing over the Internet. MPEG-2 is designed for faster connections, such as a LAN or specially designed, privately operated WAN.

FIGURE 2.16 Desktop videoconferencing
Source: Courtesy Cisco Systems, Inc. Unauthorized use not permitted.
Webcasting is a special type of one-directional videoconferencing in which content is sent from the server to the user. The developer creates content that is downloaded as needed by the users and played by a plug-in to a Web browser. At present, there are no standards for Webcast technologies, but the products by RealNetworks.com are the de facto standards.
2.6 IMPLICATIONS FOR MANAGEMENT
The first implication for management from this chapter is that the primary purpose of a network is to provide a worry-free environment in which applications can run. The network itself does not change the way an organization operates; it is the applications that the network enables that have the potential to change organizations. If the network does not easily enable a wide variety of applications, this can severely limit the ability of the organization to compete in its environment.
The second implication is that over the past few years there has been a dramatic increase in the number and type of applications that run across networks. In the early 1990s, networks primarily delivered email and organization-specific application traffic (e.g. accounting transactions, database inquiries, inventory data). Today's traffic contains large amounts of email, Web packets, videoconferencing, telephone calls, instant messaging, music, and organization-specific application traffic. Traffic has been growing much more rapidly than expected and each type of traffic has different implications for the best network design, making the job of the network manager much more complicated. Most organizations have seen their network operating costs grow significantly even though the cost per packet (i.e., the cost divided by the amount of traffic) has dropped significantly over the last 10 years. Experts predict that by 2015, video will be the most common type of traffic on the Web, passing email and web, which are the leading traffic types today.
MANAGEMENT FOCUS
Margaret worked for Cisco Systems, Inc., in San Jose, California, for three years as the executive assistant to Martin de Beer, the vice president of the emerging markets group. With the rising cost of living in San Jose, she decided to move to Dallas, Texas. Margaret didn't want to leave Cisco, and Cisco didn't want to lose her. However, her job as an executive assistant required regular face-to-face interaction with her boss and the other members of the team.
The solution was telepresence. Cisco installed a 65-inch high-definition plasma screen, a camera, microphone, speaker, and lighting array at her desk in San Jose and at her desk in Dallas. When she arrives at work in Dallas, she connects to her desk in San Jose and begins her day. She is immediately available to all who pass her desk—in either location. Cisco installed a second telepresence unit in the conference room in San Jose, so with a push of a button, Margaret can join any meeting in the conference room.
“In the beginning, there were a lot of people stopping by,” she says. “Mouths would drop open when people saw me, as if in disbelief and amazement of what they were seeing. Now, as folks get used to seeing me day in and day out, it is business as usual. One interesting thing that I noted in the beginning was that I felt like I was on camera all the time, and it made me feel a little self-conscious. Now, I don't even remember that I'm on camera. It feels like I'm still in San Jose—for eight hours a day, I'm fully engaged in the business at Cisco's headquarters.”
_________
SOURCE: “Meet Virtual Margaret,” www.Cisco.com, 2008.
SUMMARY
Application Architectures There are four fundamental application architectures. In host-based networks, the server performs virtually all of the work. In client-based networks, the client computer does most of the work; the server is used only for data storage. In client-server networks, the work is shared between the servers and clients. The client performs all presentation logic, the server handles all data storage and data access logic, and one or both perform the application logic. With peer-to-peer networks, client computers also play the role of a server. Client-server networks can be cheaper to install and often better balance the network loads but are more complex to develop and manage.
World Wide Web One of the fastest growing Internet applications is the Web, which was first developed in 1990. The Web enables the display of rich graphical images, pictures, full-motion video, and sound. The Web is the most common way for businesses to establish a presence on the Internet. The Web has two application software packages: a Web browser on the client and a Web server on the server. Web browsers and servers communicate with one another using a standard called HTTP. Most Web pages are written in HTML, but many also use other formats. The Web contains information on just about every topic under the sun, but finding it and making sure the information is reliable are major problems.
Electronic Mail With email, users create and send messages using an application-layer software package on client computers called user agents. The user agent sends the mail to a server running an application-layer software package called a mail transfer agent, which then forwards the message through a series of mail transfer agents to the mail transfer agent on the receiver's server. Email is faster and cheaper than regular mail and can substitute for telephone conversations in some cases. Several standards have been developed to ensure compatibility between different user agents and mail transfer agents such as SMTP, POP, and IMAP.
KEY TERMS
application architecture
application logic
client-based architecture
client-server architecture
cloud computing
cluster
data access logic
data storage
desktop videoconferencing
distributed computing model
dumb terminal
green computing
H.320
H.323
host-based architecture
HTTP request
HTTP response
Hypertext Markup Language (HTML)
Hypertext Transfer Protocol (HTTP)
instant messaging (IM)
Internet Internet Message Access Protocol (IMAP)
mail transfer agent
mail user agent
mainframe
middleware
MPEG-2
Multipurpose Internet Mail Extension (MIME)
network computer
n-tier architecture
peer-to-peer architecture
personal computer
Post Office Protocol (POP)
presentation logic
protocol
request body
request header
request line
response body
response header
response status
scalability
server virtualization
Simple Mail Transfer Protocol (SMTP)
SMTP header
SMTP body
Telnet
terminal
thick client
thin client
three-tier architecture
transaction terminal
two-tier architecture
uniform resource locator (URL)
videoconferencing
virtual server
World Wide Web
Web browser
Webcasting
Web server
QUESTIONS
- What are the different types of application architectures?
- Describe the four basic functions of an application software package.
- What are the advantages and disadvantages of host-based networks versus client-server networks?
- What is middleware, and what does it do?
- Suppose your organization was contemplating switching from a host-based architecture to client-server. What problems would you foresee?
- Which is less expensive: host-based networks or client-server networks? Explain.
- Compare and contrast two-tier, three-tier, and n-tier client-server architectures. What are the technical differences, and what advantages and disadvantages does each offer?
- How does a thin client differ from a thick client?
- What is a network computer?
- For what is HTTP used? What are its major parts?
- For what is HTML used?
- Describe how a Web browser and Web server work together to send a Web page to a user.
- Can a mail sender use a 2-tier architecture to send mail to a receiver using a 3-tier architecture? Explain.
- Describe how mail user agents and mail transfer agents work together to transfer mail messages.
- What roles do SMTP, POP, and IMAP play in sending and receiving email on the Internet?
- What are the major parts of an email message?
- What is a virtual server?
- What is Telnet, and why is it useful?
- What is cloud computing?
- Explain how instant messaging works.
- Compare and contrast the application architecture for videoconferencing and the architecture for email.
- Which of the common application architectures for email (two-tier client server, Web-based) is “best”? Explain.
- Some experts argue that thin-client client-server architectures are really host-based architectures in disguise and suffer from the same old problems. Do you agree? Explain.
EXERCISES
2-1. Investigate the use of the major architectures by a local organization (e.g., your university). Which architecture(s) does it use most often and what does it see itself doing in the future? Why?
2-2. What are the costs of thin client versus thick client architectures? Search the Web for at least two different studies and be sure to report your sources. What are the likely reasons for the differences between the two?
2-3. Investigate the costs of dumb terminals, network computers, minimally equipped personal computers and top-of-the-line personal computers. Many equipment manufacturers and resellers are on the Web, so it's a good place to start looking.
2-4. What application architecture does your university use for email? Explain.
MINI-CASES
I. Deals-R-Us Brokers (Part 1)
Fred Jones, a distant relative of yours and president of Deals-R-Us Brokers (DRUB), has come to you for advice. DRUB is a small brokerage house that enables its clients to buy and sell stocks over the Internet, as well as place traditional orders by phone or fax. DRUB has just decided to offer a set of stock analysis tools that will help its clients more easily pick winning stocks, or so Fred tells you. Fred's information systems department has presented him with two alternatives for developing the new tools. The first alternative will have a special tool developed in C++ that clients will download onto their computers to run. The tool will communicate with the DRUB server to select data to analyze. The second alternative will have the C++ program running on the server, the client will use his or her browser to interact with the server.
- Classify the two alternatives in terms of what type of application architecture they use.
- Outline the pros and cons of the two alternatives and make a recommendation to Fred about which is better.
II. Deals-R-Us Brokers (Part 2)
Fred Jones, a distant relative of yours and president of Deals-R-Us Brokers (DRUB), has come to you for advice. DRUB is a small brokerage house that enables its clients to buy and sell stocks over the Internet, as well as place traditional orders by phone or fax. DRUB has just decided to install a new email package. One vendor is offering an SMTP-based two-tier client-server architecture. The second vendor is offering a Web-based email architecture. Fred doesn't understand either one but thinks the Web-based one should be better because, in his words, “The Web is the future.”
- Briefly explain to Fred, in layperson's terms, the differences between the two.
- Outline the pros and cons of the two alternatives and make a recommendation to Fred about which is better.
III. Accurate Accounting
Diego Lopez is the managing partner of Accurate Accounting, a small accounting firm that operates a dozen offices in California. Accurate Accounting provides audit and consulting services to a growing number of small-and medium-sized firms, many of which are high technology firms. Accurate Accounting staff typically spend many days on-site with clients during their consulting and audit projects, but has increasingly been using email and Instant Messenger (IM) to work with clients. Now, many firms are pushing Accurate Accounting to adopt videoconferencing. Diego is concerned about what videoconferencing software and hardware to install. While Accurate Accounting's email system enables it to exchange email with any client, using IM has proved difficult because Accurate Accounting has had to use one IM software package with some companies and different IM software with others. Diego is concerned that videoconferencing may prove to be as difficult to manage as IM. “Why can't IM work as simply as email?” he asks. “Will my new videoconferencing software and hardware work as simply as email, or will it be IM all over again?” Prepare a response to his questions.
IV. Ling Galleries
Howard Ling is a famous artist with two galleries in Hawaii. Many of his paintings and prints are sold to tourists who visit Hawaii from Hong Kong and Japan. He paints 6–10 new paintings a year, which sell for $50,000 each. The real money comes from the sales of prints; a popular painting will sell 1,000 prints at a retail price of $1,500 each. Some prints sell very quickly, while others do not. As an artist, Howard paints what he wants to paint. As a businessman, Howard also wants to create art that sells well. Howard visits each gallery once a month to talk with clients, but enjoys talking with the gallery staff on a weekly basis to learn what visitors say about his work and to get ideas for future work. Howard has decided to open two new galleries, one in Hong Kong and one in Tokyo. How can the Internet help Howard with the two new galleries?
CASE STUDY
NEXT-DAY AIR SERVICE
See the Web site.
HANDS-ON ACTIVITY 2A
Looking Inside Your HTTP Packets
Figures 2.9 and 2.10 show you inside one HTTP request and one HTTP response that we captured. The objective of this Activity is for you to see inside HTTP packets that you create.
- Use your browser to connect to www.rexswain.com/httpview.html. You will see the screen in Figure 2.17.
- In box labeled URL, type any URL you like and click Submit. You will then see something like the screen in Figure 2.18. In the middle of the screen, under the label “Sending Request:” you will see the exact HTTP packet that your browser generated.
- If you scroll this screen down, you'll see the exact HTTP response packet that the server sent back to you. In Figure 2.19, you'll see the response from the Indiana University Web server. You'll notice that at the time we did this, Indiana University was using the Apache Web server.
- Try this on several sites around the Web to see what Web server they use. For example, Microsoft uses the Microsoft IIS Web server, while Cisco uses Apache. Some companies set their Web servers not to release this information.
Deliverables
Do a print screen from two separate Web sites that shows your HTTP requests and the servers’ HTTP responses.
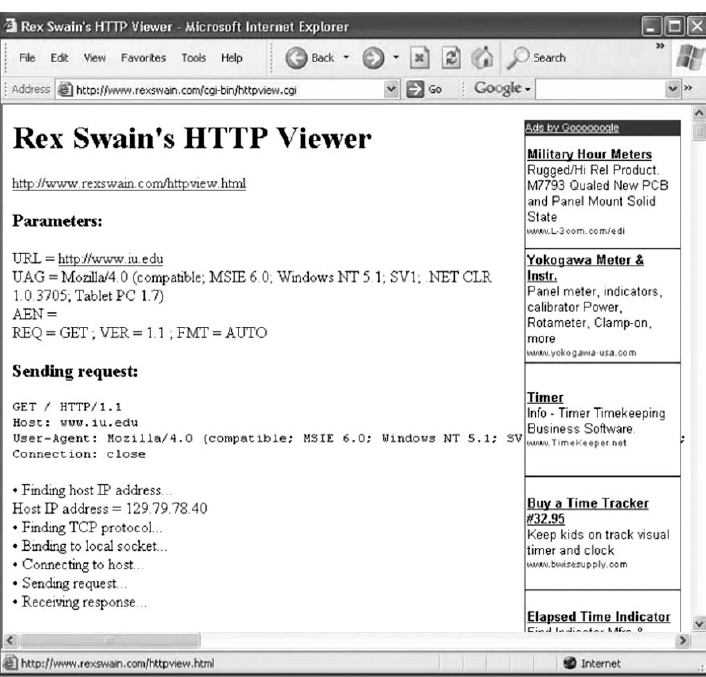
FIGURE 2.18 Looking inside an HTTP request
HANDS-ON ACTIVITY 2B
Tracing Your Email
Most email today is spam, unwanted commercial email, or phishing, fake email designed to separate you from your money. Criminals routinely send fake emails that try to get you to tell them your log-in information for your bank or your PayPal account, so they can steal the information, log-in as you, and steal your money.
It is very easy to fake a return address on an email, so simply looking to make sure that an email has a valid sender is not sufficient to ensure that the email was actually sent by the person or company that claims to have sent it. However, every SMTP email packet contains information in its header about who actually sent the email. You can read this information yourself, or you can use a tool designed to simplify the process for you. The objective of this Activity is for you to trace an email you have received to see if the sending address on the email is actually the organization that sent it.
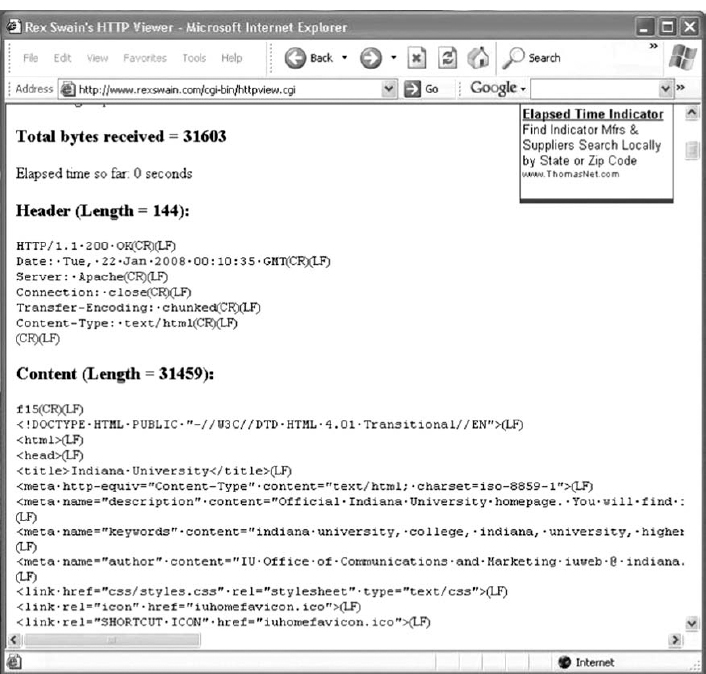
FIGURE 2.19 Looking inside an HTTP response
There are many tools you can use to trace your email. We like a tool called eMail Tracker Pro, which has a free version that lasts 15 days.
- Go to www.emailtrackerpro.com and download and install eMail Tracker Pro.
- Login to your email and find an email message you want to trace. I recently received an email supposedly from Wachovia Bank; the sender's email address was [email protected].
- After you open the email, find the option that enables you to view the Internet header or source of the message (in Microsoft Outlook, click the Options tab and look at the bottom of the box that pops up). Figure 2.20 shows the email I received and how to find the SMTP header (which Outlook calls the Internet header). Copy the entire SMTP header to the clipboard.
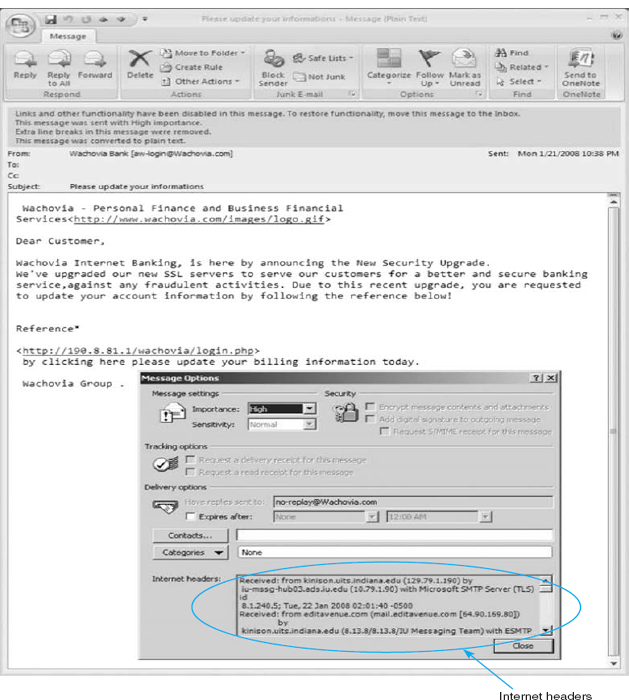
- Start eMail Tracker Pro. Select Trace an email, and paste the SMTP header into the box provided. Click Trace to start the trace.
- It may take up to 30 seconds to trace the email, so be patient. Figure 2.21 shows the results from the email I received. The email supposedly from Wachovia Bank was actually from a company named Musser and Kouri Law whose primary contact is Musser Ratliff, CPA, which uses SBC in Plano, Texas, as its Internet service provider. We suspect that someone broke into this company's network and used their email server without permission, or fraudulently used this company's name and contact information on its domain registration.
Deliverables
Trace one email. Print the original email message and the trace results.
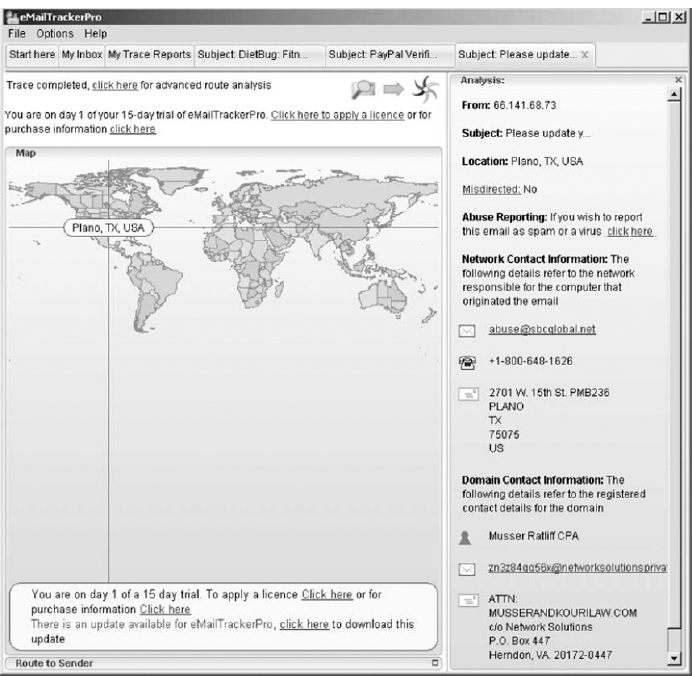
FIGURE 2.21 Viewing the source of the SMTP packet
HANDS-ON ACTIVITY 2C
Seeing SMTP and POP PDUs
We've discussed about how messages are transferred using layers and the different protocol data units (PDUs) used at each layer. The objective of this Activity is for you to see the different PDUs in the messages that you send. To do this, we'll use Wireshark, which is one of the world's foremost network protocol analyzers, and is the de facto standard that most professional and education institutions use today. It is used for network troubleshooting, network analysis, software and communications protocol development, and general education about how networks work. Wireshark enables you to see all messages sent by your computer and may also let you see the messages sent by other users on your LAN (depending on how your LAN is configured).
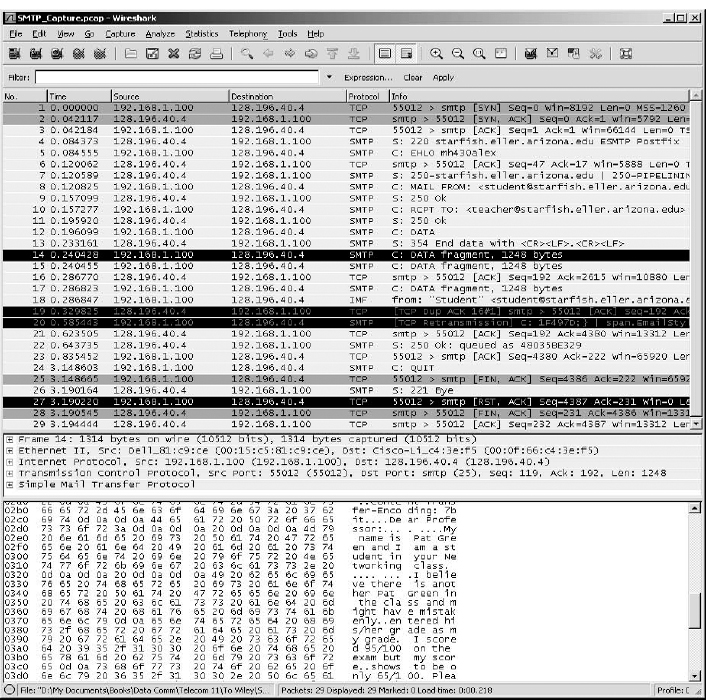
FIGURE 2.22 SMTP packets in Wireshark
For this activity you can capture your own SMTP and POP packets using Wireshark, or use two files that we've created by capturing SMTP and POP packets. We'll assume you're going to use our files. If you'd like to capture your own packets, read Hands-On Activity 1B in Chapter 1 and use your two-tier email client to create and send an email message instead of your Web browser. If you'd like to use our files, go to the Web site for this book and download the two files: SMTP Capture.pkt and POP3 Capture.pkt.
Part 1: SMTP
- Start Wireshark and either capture your SMTP packets or open the file called SMTP Capture.pkt.
- We used the email software on our client computer to send an email message to our email server. Figure 2.22 shows the packets we captured that were sent to and from the client computer (called 192.168.1.100) and the server (128.196.40.4) to send this message from the client to the server. The first few packets are called the handshake, as the client connects to the server and the server acknowledges it is ready to receive a new email message.
- Packet 8 is the start of the email message that identifies the sender. The next packet from the client (packet 10) provides the recipient address and then the email message starts with the DATA command (packet 12) and is spread over several packets (14, 15, and 17) because it is too large to fit in one Ethernet frame. (Remember that the sender's transport layer breaks up large messages into several smaller TCP segments for transmission and the receiver's transport layer reassembles the segments back into the one SMTP message.)
- Packet 14 contains the first part of the message that the user wrote. It's not that easy to read, but by looking in the bottom window, you can see what the sender wrote.
Deliverables
- List the information in the SMTP header (to, from, date, subject, message ID#).
- Look through the packets to read the user's message. List the user's actual name (not her email address), her birth date, and her SSN.
- Some experts believe that sending an email message is like sending a postcard. Why? How secure is SMTP email? How could security be improved?
Part 2: POP
- Start Wireshark and either capture your SMTP packets or open the file called POP3 Capture.pkt.
- We used the email software on our client computer to read an email message that was our email server. Figure 2.23 shows the packets we captured that were sent to and from the client computer (called 128.196.239.91) and the server (128.192.40.4) to send an email message from the server to the client. The first few packets are called the handshake, as the client logs in to the server and the server accepts the log in.
- Packet 12 is the POP STAT command (status) that asks the server to show the number of email messages in the user's mailbox. The server responds in packet 13 and tells the client there is one message.
- Packet 16 is the POP LIST command that asks the server to send the client a summary of email messages, which it does in packet 17.
- Packet 18 is the POP RETR command (retrieve) that asks the server to send message 1 to the client. Packets 20, 22, and 23 contain the email message. It's not that easy to read, but by looking in the bottom window for packet 20, you can see what the sender wrote. You can also expand the POP packet in the middle packet detail window (by clicking on the + box in front of it), which is easier to read.
Deliverables
- Packets 5 through 11 are the log-in process. Can you read the user id and passwords? Why or why not?
- Look through the packets to read the user's message. List the user's actual name (not her email address), her birth date, and her SSN.
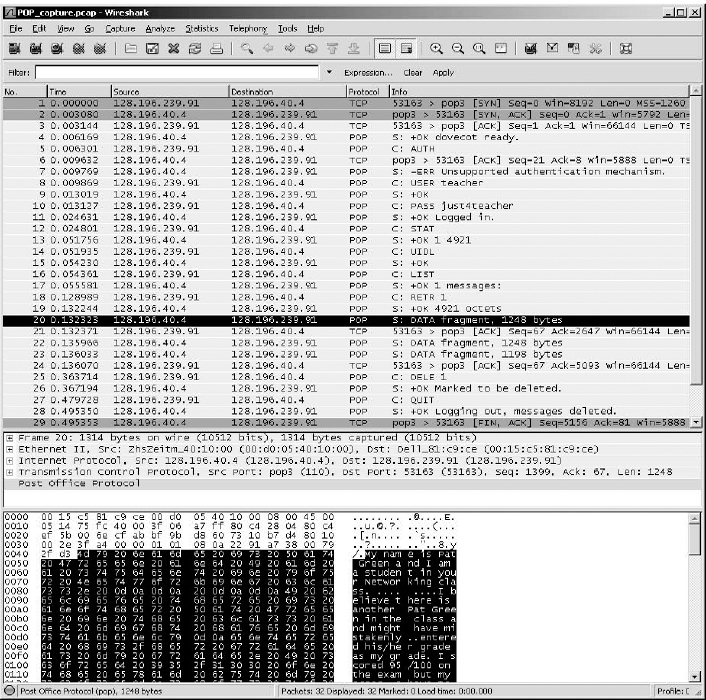
FIGURE 2.23 POP packets in Wireshark
1 The formal specification for HTTP version 1.1 is provided in RFC 2616 on the IETF's Web site. The URL is www.ietf.org/rfc/rfc2616.txt.
2 The formal specification for SMTP is provided in RFC 822 at: www.ietf.org/rfc/rfc0821.txt