
Chapter 7
Modifying Data Stores and Managing Evolution
WHAT’S IN THIS CHAPTER?
- Managing data schema in document databases, column-oriented stores, and key/value databases
- Maintaining data stores as the attributes of a data set evolves
- Importing and exporting data
Over time, data evolves and changes; sometimes drastically and other times at a slower pace and in less radical ways. In addition, data often outlives a single application. Probably designed and structured with a specific use case in mind, data often gets consumed in ways never thought of originally.
The world of relational databases, however, doesn’t normally pay much heed to the evolution of data. It does provide ways to alter schema definitions and data types but presumes that, for the most part, the metadata remains static. It also assumes uniformity of structure is common across most types of data sets and believes in getting the schema right up front. Relational databases focus on effective storage of structured and dense data sets where normalization of data records is important.
Although the debate in this chapter isn’t whether RDBMS can adapt to change, it’s worth noting that modifying schemas and data types and merging data from two versions of a schema in an RDBMS is generally complex and involves many workarounds. For example, something as benign as adding a new column to an existing table (that has some data) could pose serious issues, especially if the new column needs to have unique values. Workarounds exist for such problems but they aren’t elegant or seamless solutions. In contrast, many NoSQL databases promote a schema-less data store where evolution is easy and natural.
As in the previous chapters, the topic of database modification and evolution is explored in the context of the three popular types of NoSQL products, namely:
- Document databases
- Column databases
- Key/value stores
Document databases are schema-less in form, allowing self-contained documents to be stored as a record or item in a collection. Being less rigid about a formal schema or form, document databases by definition accommodate variations and modifications to the average form. In fact, a document database doesn’t prevent you from storing a completely disparate set of documents in a single collection, although such a collection may not be logically very useful.
CouchDB, now part of Couchbase, and MongoDB, the two leading open-source document databases, are extremely flexible about storing documents with different sets of properties in the same collection. For example, you could easily store the following two documents together:
{ name => "John Doe", organization => "Great Co", email => "[email protected]" }
{ name => "Wei Chin", company => "Work Well", phone => "123-456-7890" }
Start up CouchDB and actually store these two documents in a database named contacts.
A MongoDB server can host multiple databases, where each database can have multiple collections. In contrast, a CouchDB server can host multiple databases but has no notion of a collection.
You can use the command-line utility, Futon, or an external program to interface with CouchDB and store the documents.
CouchDB offers a REST API to carry out all the tasks, including creating and managing databases and documents and even triggering replication. Please install CouchDB before you proceed any further. There is no better way to learn than to try out the examples and test the concepts yourself. Read Appendix A if you need help setting it up. Appendix A has installation and setup instructions for all NoSQL products covered in this book.
Look at the screenshot in Figure 7-1 to see a list of the two documents in the contacts database, as viewed in Futon. The list shows only the id, CouchDB-generated UUIDs, and the version number of the documents.

Expanding out the information for Wei Chin shows the complete document with all its fields, as depicted in Figure 7-2.
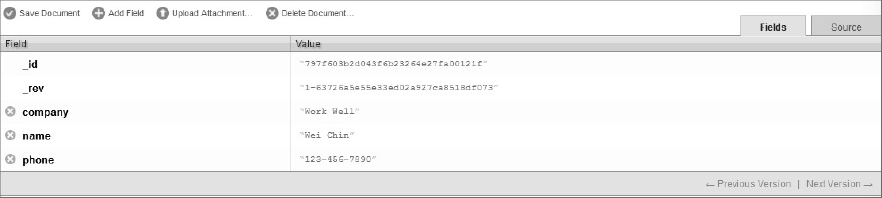
The navigation arrows at the bottom right in Figure 7-2 allow you to navigate through the document versions. This may seem out of place in many databases and remind you of version control software or document management systems, but it is an inherent and important feature in CouchDB. An update to a CouchDB document under the hood translates to the addition of a new version of the document. Therefore, if you update the name from “Wei Chin” to “Wei Lee Chin” the current updated version of the document (in JSON format) would be as follows:
{
"_id": "797f603b2d043f6b23264e27fa00121f",
"_rev": "2-949a21d63459638cbd392e6b3a27989d",
"name": "Wei Lee Chin",
"company": "Work Well",
"phone": "123-456-7890"
}
couchdb_example.txt
Apart from an updated value for the name field, you should see a difference in value of the _rev property. The _rev field holds the revision number for the document. The original revision number of the document was 1-63726a5e55e33ed02a927ca8518df073. After the update the revision number is 2-949a21d63459638cbd392e6b3a27989d. Revision numbers in CouchDB are of the form N-<hash value>, where N depicts the number of times the document has been updated and the hash value is the MD5 hash of the transport representation of the document. N is 1 when the document is created.
MD5 is a one-way hash algorithm that takes any length of data and produces a 128-bit fingerprint or message digest. Read about MD5 at www.ietf.org/rfc/rfc1321.txt.
CouchDB uses MultiVersion Concurrency Control (MVCC) to facilitate concurrent access to the database. Using MVCC enables CouchDB to avoid locking mechanisms to assure write fidelity. Every document is versioned, and document versions help reconcile conflicts. Before a document is updated, it is verified if the current version (before update) is the same as the version at the time the document was read for update. If the versions don’t match, it suggests a possible conflict, due to an update by another independent process between the read and the subsequent update. When documents are updated, newer versions of entire documents are saved instead of updates on existing documents. A side effect of this process is that you enjoy a performance boost because appending to contiguous memory is faster than updating in place. Because version or revision numbers are central concepts in CouchDB, you see multiple versions.
However, multiple versions of documents, by default, aren’t persisted forever. The purpose of versioning is to avoid conflicts and provide concurrency. Compaction and replication prunes old versions and at any given moment only the presence of the latest version is guaranteed. This means by default you cannot use the _rev field to query or access old versions of a document. In a single node scenario you may be tempted to switch compaction off and retain the versions. However, the strategy fails as soon as you set up a cluster because only the latest version gets replicated.
If you do need to keep versions and query older versions of a document, you would need to do it programmatically. The CouchDB founders have a simple but effective solution to the problem. Read it online at http://blog.couchone.com/post/632718824/simple-document-versioning-with-couchdb. The solution is rather straightforward. It suggests that you do the following:
- Extract a string representation of the current version of the document when it is accessed.
- Before an update, encode the string representation using Base64 encoding and then save the binary representation as an attachment to the document. Use the current version number (before update) as the name of the attachment.
This means if a document itself is accessed as follows:
http://127.0.0.1:5984/contacts/797f603b2d043f6b23264e27fa00121f
Then version 2, which is available with the document as an attachment, can be accessed as follows:
http://127.0.0.1:5984/contacts/797f603b2d043f6b23264e27fa00121f/2-949a21d63459638cbd392e6b3a27989d
This way of managing versions is simple and useful for most cases. More sophisticated version management systems could be built by saving the document versions as per the use case.
Futon manages document versions using the technique illustrated. This technique is implemented in the jQuery JavaScript client library for CouchDB. The jQuery client library is available at http://svn.apache.org/viewvc?revision=948262&view=revision.
So while versioning in CouchDB is an interesting feature, the document store malleability and flexibility is a more generic feature, which is also found in other schema-less NoSQL databases.
Schema-less Flexibility
It’s evident from the previous example that CouchDB is fully capable of storing two documents with different sets of fields in a single database. This has many advantages, especially in situations such as these:
- Sparse data sets can be stored effectively because fields that are null needn’t be stored at all.
- As documents evolve, adding additional fields is trivial.
In the preceding example, "John Doe" has an e-mail address, whereas “Wei Chin" doesn’t have one. It’s not a problem; they can still be in the same database. In the future if "Wei Chin" gets an e-mail address, say [email protected], an additional field can be added to the document without any overhead. Similarly, fields can be deleted and values for fields can be modified.
Apart from fields themselves being added and removed, there aren’t any strong rules about the data types a field can hold either. So a field that stores a string value can also hold an integer. It can even have an array type as a value. This means that you don’t have to worry about strong typing. On the flip side, though, it implies your application needs to make sure that the data is validated and semantically the values are consistent.
So far, the fundamentals of schema-less flexibility have been explained in the context of CouchDB. To demonstrate a few other aspects of this flexibility, you use MongoDB next. First, create a MongoDB collection named contacts and add the two documents to the collection. You can do this by starting up MongoDB and executing the following commands in order as follows:
use mydb
db.contacts.insert({ name:"John Doe", organization:"Great Co",
email:"[email protected]" });
db.contacts.insert({ name:"Wei Chin", company:"Work Well", phone:"123-456-7890"
});
mongodb_example.txt
Next, confirm that the collection was created and the two documents are in it. You can verify by simply listing the documents as follows:
db.contacts.find();
mongodb_example.txt
The result of this query should be as follows:
{ "_id" : ObjectId("4d2bbad6febd3e2b32bed964"), "name" : "John Doe",
"organization" : "Great Co", "email" : "[email protected]" }
{ "_id" : ObjectId("4d2bbb43febd3e2b32bed965"), "name" : "Wei Chin", "company" :
"Work Well", "phone" : "123-456-7890" }
The _id values may be different because these are the MongoDB-generated values on my system and will certainly vary from one instance to the other. Now, you could add an additional field, email, to the document that relates to "Wei Chin" as follows:
var doc = db.contacts.findOne({ _id:ObjectId("4d2bbb43febd3e2b32bed965") });
doc.email = "[email protected]";
db.contacts.save(doc);
mongodb_example.txt
I use the _id to get hold of the document and then simply assign a value to the email field and save the document. To verify that the new field is now added, simply get the documents from the contacts collection again as follows:
db.contacts.find();
mongodb_example.txt
The response should be as follows:
{ "_id" : ObjectId("4d2bbad6febd3e2b32bed964"), "name" : "John Doe",
"organization" : "Great Co", "email" : "[email protected]" }
{ "_id" : ObjectId("4d2bbb43febd3e2b32bed965"), "name" : "Wei Chin", "company":
"Work Well", "phone" : "123-456-7890", "email" : "[email protected]" }
Unlike CouchDB, MongoDB doesn’t maintain document versions and an update modifies the document in place.
Now, say you had another collection named contacts2, which had some more contact documents and you needed to merge the two collections, contacts and contacts2, into one. How would you do that?
Unfortunately, there is no magic button or command that merges collections at the moment but it’s not terribly difficult to write a quick script in a language of your choice to merge two collections. A few considerations in designing a merge script could be:
- A switch with possible values of overwrite, update, or copy could decide how two documents with the same _id in two different collections need to be merged. Two documents cannot have the same _id value in a single collection. Overwrite would imply the document in the second collection overwrites the corresponding document in the first collection. Update and copy would define alternate merge strategies.
- Merge on the basis of a field other than the _id.
A ruby script to merge two MongoDB collections is available via a project named mongo-tools, available online at https://github.com/tshanky/mongo-tools.
Exporting and Importing Data from and into MongoDB
Exporting data out and importing data into a database is an important and often-used step in backing up, restoring, and merging databases. MongoDB provides a few useful utilities to assist you in this regard.
mongoimport
If you have the data to import in a single file and it is either in JSON format or is text data in comma- or tab-separated format, the mongoimport utility can help you import the data into a MongoDB collection. The utility has a few options that you can learn about by simply executing the command without any options. Running bin/mongoimport with no options produces the following output:
connected to: 127.0.0.1
no collection specified!
options:
--help produce help message
-v [ --verbose ] be more verbose (include multiple times for more
verbosity e.g. -vvvvv)
-h [ --host ] arg mongo host to connect to ("left,right" for pairs)
--port arg server port. Can also use --host hostname:port
-d [ --db ] arg database to use
-c [ --collection ] arg collection to use (some commands)
-u [ --username ] arg username
-p [ --password ] arg password
--ipv6 enable IPv6 support (disabled by default)
--dbpath arg directly access mongod database files in the given
path, instead of connecting to a mongod server -
needs to lock the data directory, so cannot be used
if a mongod is currently accessing the same path
--directoryperdb if dbpath specified, each db is in a separate
directory
-f [ --fields ] arg comma separated list of field names e.g. -f name,age
--fieldFile arg file with fields names - 1 per line
--ignoreBlanks if given, empty fields in csv and tsv will be ignored
--type arg type of file to import. default: json (json,csv,tsv)
--file arg file to import from; if not specified stdin is used
--drop drop collection first
--headerline CSV,TSV only - use first line as headers
--upsert insert or update objects that already exist
--upsertFields arg comma-separated fields for the query part of the
upsert. You should make sure this is indexed
--stopOnError stop importing at first error rather than continuing
--jsonArray load a json array, not one item per line. Currently
limited to 4MB.
Although useful, this utility hits the limits as soon as you start importing data that is a little more complicated than comma-separated or tab-separated values (or the JSON format). You may recall the Ruby script that was used in Chapter 6 to load the MovieLens data into MongoDB collections. You couldn’t use mongoimport for that task.
mongoexport
The exact opposite of loading data into a MongoDB collection is to export data out of a collection. If JSON or CSV format is what you need, you can use this tool to export the data out of a collection. To explore the options, again simply run the mongoexport command without any collections specified. You will be prompted with a message stating all the options as follows:
connected to: 127.0.0.1
no collection specified!
options:
--help produce help message
-v [ --verbose ] be more verbose (include multiple times for more
verbosity e.g. -vvvvv)
-h [ --host ] arg mongo host to connect to ("left,right" for pairs)
--port arg server port. Can also use --host hostname:port
-d [ --db ] arg database to use
-c [ --collection ] arg collection to use (some commands)
-u [ --username ] arg username
-p [ --password ] arg password
--ipv6 enable IPv6 support (disabled by default)
--dbpath arg directly access mongod database files in the given
path, instead of connecting to a mongod server -
needs to lock the data directory, so cannot be used
if a mongod is currently accessing the same path
--directoryperdb if dbpath specified, each db is in a separate
directory
-f [ --fields ] arg comma separated list of field names e.g. -f name,age
--fieldFile arg file with fields names - 1 per line
-q [ --query ] arg query filter, as a JSON string
--csv export to csv instead of json
-o [ --out ] arg output file; if not specified, stdout is used
--jsonArray output to a json array rather than one object per
line
mongodump
The mongoimport and mongoexport utilities help import into and export from a single collection and deal with human-readable data formats. If the purpose is simply to take a hot backup, you could rely on mongodump to dump a complete database copy in a binary format. To explore the mongodump options, run the mongodump commands with –help as the argument. The output would be as follows:
Running mongodump with no options dumps the relevant MongoDB database so don’t run it the way you have run mongoimport and mongoexport to explore the options.
options:
--help produce help message
-v [ --verbose ] be more verbose (include multiple times for more
verbosity e.g. -vvvvv)
-h [ --host ] arg mongo host to connect to ("left,right" for pairs)
--port arg server port. Can also use --host hostname:port
-d [ --db ] arg database to use
-c [ --collection ] arg collection to use (some commands)
-u [ --username ] arg username
-p [ --password ] arg password
--ipv6 enable IPv6 support (disabled by default)
--dbpath arg directly access mongod database files in the given
path, instead of connecting to a mongod server -
needs to lock the data directory, so cannot be used
if a mongod is currently accessing the same path
--directoryperdb if dbpath specified, each db is in a separate
directory
-o [ --out ] arg (=dump) output directory
-q [ --query ] arg json query
With good coverage about document database flexibility and a survey of some of the maintenance tools, you may now be ready to move on to column databases.
SCHEMA EVOLUTION IN COLUMN-ORIENTED DATABASES
HBase is not completely schema-less. There is a loosely defined schema, especially in terms of the column-family definitions. A column-family is a fairly static definition that partitions the more dynamic and flexible column definitions into logical bundles. For the purpose of explanation, I reuse and extend an example that you saw when you first started out with HBase in Chapter 3. It’s about a set of blogposts. If you would like to get the details, review the section on HBase in Chapter 3.
The elements of that collection are like so:
{
"post" : {
"title": "an interesting blog post",
"author": "a blogger",
"body": "interesting content",
},
"multimedia": {
"header": header.png,
"body": body.mpeg,
},
}
or
{
"post" : {
"title": "yet an interesting blog post",
"author": "another blogger",
"body": "interesting content",
},
"multimedia": {
"body-image": body_image.png,
"body-video": body_video.mpeg,
},
}
blogposts.txt
You can start HBase using bin/start-hbase.sh and connect via the shell using bin/hbase shell. Then, you can run the following commands in sequence to create the tables and populate some sample data:
create 'blogposts', 'post', 'multimedia' put 'blogposts', 'post1', 'post:title', 'an interesting blog post' put 'blogposts', 'post1', 'post:author', 'a blogger' put 'blogposts', 'post1', 'post:body', 'interesting content' put 'blogposts', 'post1', 'multimedia:header', 'header.png' put 'blogposts', 'post1', 'multimedia:body', 'body.mpeg' put 'blogposts', 'post2', 'post:title', 'yet an interesting blog post' put 'blogposts', 'post2', 'post:title', 'yet another interesting blog post' put 'blogposts', 'post2', 'post:author', 'another blogger' put 'blogposts', 'post2', 'post:body', 'interesting content' put 'blogposts', 'post2', 'multimedia:body-image', 'body_image.png' put 'blogposts', 'post2', 'multimedia:body-video', 'body_video.mpeg'
blogposts.txt
Once the database is ready you could run a simple get query like so:
get 'blogposts', 'post1'
blogposts.txt
The output would be something like this:
COLUMN CELL multimedia:body timestamp=1294717543345, value=body.mpeg multimedia:header timestamp=1294717521136, value=header.png post:author timestamp=1294717483381, value=a blogger post:body timestamp=1294717502262, value=interesting content post:title timestamp=1294717467992, value=an interesting blog post 5 row(s) in 0.0140 seconds
Now that the data set is ready, I recap a few more fundamental aspects of HBase and show you how HBase evolves as the data schema changes.
First, all data updates in HBase are overwrites with newer versions of the record and not in-place updates of existing records. You have seen analogous behavior in CouchDB. By default, HBase is configured to keep the last three versions but you could configure to store more than three versions for each. The number of versions is set at a per column-family level. You can specify the number of versions when you define a column-family. In the HBase shell you could create a table named 'mytable' and define a column-family named 'afamily' with the configuration to keep 15 past versions as follows:
create 'mytable', { NAME => 'afamily', VERSIONS => 15 }
The VERSIONS property takes an integer value and so the maximum value it can take is Integer.MAX_VALUE. Although you can define a large value for the number of versions to keep, using this data it is not easy to retrieve and query the value because there is no built-in index based on versions. Also, versions have a timestamp but querying across this time series for the data set is not a feature that is easy or efficient to implement.
Although the configuration was done using a command-line utility, you could also achieve the same programmatically. The maximum versions property needs to be passed as an argument to the HColumnDescriptor constructor.
Columns in HBase don’t need to be defined up front so they provide a flexible way of managing evolving schemas. Column-families, on the other hand, are more static. However, columns can’t be renamed or assigned easily from one column-family to the other. Making such changes requires creation of the new columns, migration of data from the existing columns to the new column, and then potentially deletion of the old columns.
Though HBase allows creation of column-families from the shell or through programmatic options, Cassandra has traditionally been far more rigid. The definition of column-families in older versions of Cassandra needed a database restart. The current version of Cassandra is more flexible and allows for configuration changes at runtime.
The data in a table, say 'blogposts', can be exported out to the local filesystem or exported to HDFS.
You can export the data to the local filesystem as follows:
bin/hbase org.apache.hadoop.hbase.mapreduce.Driver export blogposts path/to/local/filesystem
You can export the same data to HDFS as follows:
bin/hbase org.apache.hadoop.hbase.mapreduce.Driver export blogposts hdfs://namenode/path/to/hdfs
Like export, you can also import the data into an HBase table. You could import the data from the local filesystem or from HDFS. Analogous to export, import from the local filesystem is as follows:
bin/hbase org.apache.hadoop.hbase.mapreduce.Driver import blogposts path/to/local/filesystem
Importing from HDFS is similar. You could import the data like so:
bin/hbase org.apache.hadoop.hbase.mapreduce.Driver import blogposts hdfs://namenode/path/to/hdfs
DATA EVOLUTION IN KEY/VALUE STORES
Key/value stores usually support fairly limited data sets and either hold string or object values. Some, like Redis, allow a few sophisticated data structures. Some key/value stores, like Memcached and Membase, store time-sensitive data, purging everything that is old as per the configuration.
Redis has collection structures like hashes, sets, lists, and such but it has little if any metadata facility. To Redis, everything is a hash or a collection of hashes. It is totally agnostic to what the key is and what it means.
Key/value databases don’t hold documents, data structures or objects and so have little sense of a schema beyond the key/value pair itself. Therefore, the notion of schema evolution isn’t that relevant to key/value databases.
Somewhat similar to renaming a field name would be renaming a key. If a key exists you can easily rename it as follows:
RENAME old_key_name new_key_name
Redis persists all the data it holds by flushing it out to disks. In order to back up a Redis database, you could simply copy the Redis DB file and configure another instance to use it. Alternatively, you could issue a BGSAVE to run and save the database job asynchronously.
NoSQL databases support schema-less structures and thus accommodate flexible and continuing evolution. Though not explicitly observed, this is one of the key NoSQL features. The notion of no strict schema allows document databases to focus on storing real-world-centric data as such and not force fitting them into the normalized relational model.
In column databases, the lack of strict schema allows for easy maintenance and growth of sparse data. In key/value-based stores, the notion of a schema is limited.