
Chapter 3. The View Concept: A Closer Look
Every scientific discipline has its share of unsolved problems. In mathematics, for example, there’s the Riemann Hypothesis, which nobody has managed to prove or disprove in over 150 years; in computer science, there’s the “P = NP?” question, which is still open after some 40 years; in physics and cosmology, there’s the long search for a “theory of everything,” which remains—in many people’s opinion, though possibly not in everyone’s—just that, a search; and in database theory, there’s the problem of view updating. Now, I obviously don’t mean to suggest that the problem of view updating is in the same league as the Riemann Hypothesis or the “P = NP?” question or some hypothetical “theory of everything”;[35] however, I do claim it’s of considerable practical importance and much theoretical interest. In this chapter, therefore, I want to lay some of the groundwork that’s necessary for a systematic attack on that problem.
I begin with the trite observation that a view is a relvar—a virtual relvar, to be precise, or in other words a relvar that “looks and feels” just like a real, or base, relvar but (unlike a real or base relvar) doesn’t exist independently of other relvars; rather, it’s defined in terms of, or derived from, such other relvars. Here’s a definition:
Definition: A view is a derived, virtual relvar. The value of view V at time T is the result of evaluating a certain relational expression (the view defining expression) at that time T. That expression is specified when V is defined and must mention at least one relvar.[36]
Here’s an example (it’s a Tutorial D definition of the “London suppliers” view LS from Chapter 1):
VAR LS VIRTUAL ( S WHERE CITY = 'London' ) ;
Now, it’s well known that a view can be thought of as a kind of “window into” the relvar or relvars in terms of which it’s defined, in the sense that operations on the view are “really” operations on those underlying relvars. In other words, the DBMS is supposed to support user operations on a view, be they retrievals or updates, by mapping them—the operations, that is—into suitable operations on the base relvars in terms of which the view in question is ultimately defined. (I say ultimately defined here because if views really do behave just like base relvars, then one thing we can certainly do is define further views on top of them, and so on to any depth.) Thus, for example, the following expression—
LS WHERE STATUS > 10
(which can be thought of as representing a retrieval operation on view LS)—maps to:
S WHERE CITY = 'London' AND STATUS > 10
And the following update operation on LS (actually a delete)—
DELETE ( LS WHERE STATUS > 10 ) FROM LS ;
—maps to:
DELETE ( S WHERE CITY = 'London' AND STATUS > 10 ) FROM S ;
From all of the above, it’s clear there’s a logical difference between views and base relvars. By The Principle of Interchangeability, however, that difference isn’t one that should affect the user—the aim, to repeat, is to make views “look and feel” just like base relvars as far as the user is concerned, even with respect to updating. (The distinction between base relvars and views is relevant to the DBA and DBMS but not, to repeat, to the user. At least, that’s the intent.) In other words, the user of a given view should ideally be unaware that his or her operations on that view are being mapped to operations on the underlying relvar(s); ideally, in fact, that user shouldn’t even have to be aware that the view is indeed a view, nor indeed that the underlying relvars even exist.
Incidentally, it follows from the foregoing that the terminology of “real” vs. “virtual” relvars is somewhat misleading—views are actually no less (and no more!) “real” than base relvars are—but I’ll stay with it for now, in part because it’s actually reflected in the Tutorial D syntax for defining a view, as we’ve already seen. However, I’ll have a little more to say about this perhaps unfortunate choice of terminology, and syntax, later in the chapter.
The View Update Problem
The View Update Problem
I can now state for the record exactly what the view update problem consists of: Given an arbitrary update operation—perhaps I should say an arbitrary update request—on an arbitrary view, the problem is to determine what operations need to be performed on the relvars in terms of which the view in question is defined. (Note the recursive nature of this problem. I’ll have more to say on this particular point in Chapter 14.) Of course, I’m assuming here, tacitly, that such operations on the underlying relvars (a) do in fact exist and moreover (b) are well defined. I’ll discuss these issues too in the chapters to come.
Note: Perhaps I should say too that of course I’m assuming the system does in fact support views. Personally I do think views should be supported, for reasons I’ll explain in the section Data Independence on page 34; further, it’s my position that since (a) views are relvars, and (b) relvars are variables, and (c) variables are updatable, then (d) views must be updatable. But I suppose you could take the position that there’s no absolute requirement that views be supported in the first place! If that’s your position, you might as well stop reading right now—if you’ve even got this far, I suppose I should add.
Views are Pseudovariables
Now I want to focus on the point that views are indeed relvars; in other words, as I’ve just said, they’re variables,[37] which means by definition that they must be updatable. (To be a variable is to be updatable; equally, to be updatable is to be a variable.) In other words, it must in general be possible to make a view the target in a relational assignment. By way of example, given view LS as defined in the previous section, the following DELETE should be legal:
DELETE ( LS WHERE SNO = 'S1' ) FROM LS ;
Of course, this DELETE is really “shorthand” for the following relational assignment:
LS := LS WHERE NOT ( SNO = 'S1' ) ;
And this assignment is shorthand in turn for the following expanded version (which is, however, not legal syntax in Tutorial D as currently defined):
( S WHERE CITY = 'London' ) :=
( S WHERE CITY = 'London' ) WHERE NOT ( SNO = 'S1' ) ;It follows that from an updating point of view, views act as pseudovariables[38] (recall from the previous chapter that a pseudovariable reference is basically a construct that looks like an operational expression but appears in the target position within an assignment, and that’s exactly the situation we’re dealing with here). But pseudovariables are variables (loosely speaking); please understand, therefore, that the term variable throughout the remainder of this book should be understood to include pseudovariables in particular.
Data Independence
Consider the following quote from the abstract to Codd’s famous 1970 paper (“A Relational Model of Data for Large Shared Data Banks,” Communications of the ACM 13, No. 6, June 1970):
Future users of large data banks [sic] must be protected from having to know how the data is organized in the machine (the internal representation) … Activities of users at terminals and … application programs should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed.
The first sentence here says we want physical data independence; the second says we want logical data independence as well. Indeed, data independence was one of Codd’s primary reasons for introducing the relational model in the first place.[39] Physical data independence means we can change the way the data is physically stored and accessed without having to make changes in the way the data is perceived by the user; analogously, logical data independence means we can change the way the data is logically stored and accessed, again without having to make changes in the way the data is perceived by the user. And both kinds of independence translate into protecting customer investment—investment, that is, in existing training, existing applications, and existing databases (even in existing DBMS products, to some extent).
Turning now to views specifically: To the extent that logical data independence can be achieved at all, views provide the means for doing so. Let me elaborate. As mentioned in the preface to this book, we can assume without loss of generality that the database as seen by the user consists entirely of views. So if changes occur to the underlying base relvars, logical data independence is achieved by making appropriate changes to the mapping from the views as seen by the user to those underlying base relvars. Here’s an example (in outline only, for brevity). Suppose the user initially sees a view V that’s identical to the suppliers base relvar S:
VAR V VIRTUAL ( S ) ;
Now suppose for some reason—the precise reason isn’t important for present purposes—we decide to replace base relvar S by base relvars LS (“London suppliers”) and NLS (“non London suppliers”), thus:
VAR LS BASE RELATION/* London suppliers */{ SNO CHAR , SNAME CHAR , STATUS INTEGER , CITY CHAR } KEY { SNO } ; VAR NLS BASE RELATION/* non London suppliers */{ SNO CHAR , SNAME CHAR , STATUS INTEGER , CITY CHAR } KEY { SNO } ;
What we do now is redefine view V as follows:
VAR V VIRTUAL ( LS UNION NLS ) ;
Assuming the system does correctly support operations—update operations in particular—on views (unfortunately a rather large assumption, given the state of today’s products), the user of view V will thus be immune to this particular change to the underlying base data.
So now we see why the ability to update views is so important. In a way, in fact, it’s a little hard to understand why there’s so much skepticism surrounding—not to say downright opposition to—the idea that views should be updatable. The fact is, the problem of (a) updating base relvars appropriately in order to support updates on views is, abstractly, the same problem as (b) the problem of updating stored data appropriately in order to support updates on base relvars. They just show up at different points in the overall system architecture, that’s all. It follows that we must solve this problem, for otherwise we have to give up on the goal of data independence. (Logical data independence, that is—but as this brief discussion should be sufficient to suggest, logical and physical data independence are basically the same problem, too; they too differ only in that they show up at different points in the overall system architecture).
Views Serve a Variety of Purposes
In SQL and Relational Theory, I said views serve two rather different purposes. To be specific, I said the following:
The user who actually defines a given view V is, obviously, aware of the expression exp, say, that defines that view (i.e., the corresponding view defining expression). Thus, that user can use the name V wherever the expression exp is intended. However, such uses are basically just shorthand, and are explicitly understood to be just shorthand by the user in question. What’s more, the user in question is perhaps unlikely to request any updates on V—though if such updates are requested, they must behave as expected, of course.
By contrast, a user who’s merely informed that V exists and is available for use is supposed, at least ideally, not to be aware of that view defining expression; to that user, in fact, V is supposed to look and feel just like a base relvar, as I’ve said (see the foregoing discussion of logical data independence).
Of these two purposes, it’s the second that’s the important one, and the one that’s the primary focus of this book. Note, however, that it subdivides into two further possibilities: The views seen by a given user can effectively be equivalent either (a) to the underlying base data in its entirety—see the discussion of information equivalence later in this chapter—or (b) to some proper subset of that underlying base data. The latter case constitutes one form of information hiding. And as noted in Chapter 1 (see the section There’s No Magic in that chapter), a user from whom information is hidden is seeing only part of the picture, as it were, and it’s only to be expected that there’ll be certain operations that such a user can’t be allowed to perform. We’ll see several examples of such situations in later chapters.
Note: One specific reason for using views to hide information is security. For example, a rule to the effect that some user isn’t allowed to see supplier cities can be enforced by making that user use a view that’s the projection of relvar S on all attributes but CITY. In my opinion, however, there are better ways to manage authorization than using views: better ways, that is, of controlling who is allowed to do what to what data (see, e.g., my book An Introduction to Database Systems, 8th edition, Addison-Wesley, 2004). In other words, I regard this use of views as a red herring, and I don’t propose to say much about it in this book.
A Psychological Mistake?
Let me focus on SQL specifically for a moment. The fact that, in SQL terms, views are supposed to look and feel just like base tables as far as the user is concerned suggests rather strongly that the syntactic distinction between CREATE TABLE and CREATE VIEW was always at least a psychological mistake. First of all, that keyword TABLE in CREATE TABLE refers to a base table specifically, thereby (most unfortunately!) lending weight to the widespread perception in the SQL world that views are somehow different from tables. To elaborate on this point briefly: As is well known, SQL documents—textbooks, product manuals, and indeed the SQL standard itself—all talk quite typically (fairly ubiquitously, in fact) in terms of “tables and views.” But clearly, anyone who talks this way is under the impression that tables and views are different things, and probably that “tables” always means base tables specifically, and probably also that base tables are physically stored and views aren’t. But the whole point about a view is that it is a table (or, as I would prefer to say, a relvar); hence, we should be able to perform the same kinds of operations on views as we can on regular relvars, because views are “regular relvars.” Throughout this book, therefore, I’ll use the term relvar to refer to relvars in general—and if I want to talk about base relvars specifically or views specifically, I’ll use the appropriate more specific term.
The second part of the mistake is this: The syntax of CREATE VIEW in SQL is such that the mapping between the view in question and the table(s) in terms of which it’s defined—in other words, the pertinent view defining expression—is explicitly stated as part of the view definition. That mapping is thus explicitly visible to users who are exposed to that CREATE VIEW statement, despite the fact that those users have no logical need to see it (the mapping, that is). Ideally, in fact, they shouldn’t be aware of it at all. One consequence is that users typically do know among other things that the view in question is indeed a view; more generally, they typically do know which tables are base ones and which ones are views. The problem is compounded by the fact that, ironically enough, the structure of the view, which users do need to be aware of, isn’t explicitly defined in CREATE VIEW but has to be inferred from the mapping! (By structure here, I mean the names of the columns of the view and their corresponding data types—in other words, the heading—but heading isn’t an SQL term. In fact, SQL doesn’t seem to have a term for the concept at all.)
Now, lest I be accused of attacking SQL unfairly here, let me make it clear that the foregoing criticisms all apply, mutatis mutandis, to Tutorial D also (at least in its present incarnation). Let me also make clear what I would regard as an adequate fix for these problems:
First, relvar definitions as perceived by the user should (of course) specify the pertinent heading but should not distinguish between base and virtual relvars in any way.
Second, (a) the mapping between a view and the relvars in terms of which it’s defined should be specified separately and concealed from the user, just as (b)the mapping between a base relvar and physical storage already is specified separately and concealed from the user.
How Not to do it
Before getting into further details of how I believe views ought to work, I think it’s worth taking a quick look at “the state of the art” (such as it is) in this area. In fact, that “state of the art” leaves a lot to be desired; in fact, if truth be told, it’s ad hoc in the extreme. Certainly this is the case in the SQL standard and in current commercial products, and (sadly) it’s also the case in the technical literature, at least to some extent. Indeed, in the case of SQL specifically, it’s quite usual to find that a given SQL DBMS will:[40]
Prohibit updates on logically updatable views, or
Permit updates on “logically nonupdatable” views,[41] or
Implement view updates in a logically incorrect way, or
Do all of the above
(and I’m tempted to say this last is the state of affairs most likely to be encountered in practice).
Let me pursue this point just a moment longer; more specifically, let me say a little more about the SQL standard in particular. I’ve already said the standard is deficient in this area. In fact, not only is it deficient, it’s also extremely hard to understand!—indeed, it’s even more impenetrable in this area than it usually is. The following extract (which is quoted verbatim from SQL:2003, the 2003 version of the standard) gives some idea of the complexities involved:
[The] <query expression> QE1 is updatable if and only if for every <query expression> or <query specification> QE2 that is simply contained in QE1:
QE1 contains QE2 without an intervening <query expression body> that specifies UNION DISTINCT, EXCEPT ALL, or EXCEPT DISTINCT.
If QE1 simply contains a <query expression body> QEB that specifies UNION ALL, then:
QEB immediately contains a <query expression> LO and a <query term> RO such that no leaf generally underlying table of LO is also a leaf generally underlying table of RO.
For every column of QEB, the underlying columns in the tables identified by LO and RO, respectively, are either both updatable or not updatable.
QE1 contains QE2 without an intervening <query term> that specifies INTERSECT.
QE2 is updatable.
Here’s my own gloss on the foregoing extract:
First of all, observe that the extract in question represents just one of the many rules that have to be taken in combination in order to determine whether some given view is updatable in SQL.
The rules in question aren’t all given in one place but are scattered over many different portions of the standard.
All of those rules rely on a variety of additional concepts and constructs—e.g., updatable columns, leaf generally underlying tables, <query term>s—that are defined in turn in still further portions of the standard.
What’s more, the rule as defined by this particular extract doesn’t even seem to make sense. To be specific, the opening sentence says, in effect, that four conditions a), b), c), and d) have to be satisfied “for every … QE2 that is simply contained in QE1”—yet item b) in particular doesn’t even mention any such QE2 (?).
I haven’t finished with my criticisms. The picture is complicated still further by the fact that SQL identifies four distinct cases; to be specific, a view in SQL can be updatable, potentially updatable, simply updatable, or insertable into. Now, the standard defines these terms formally but gives no insight into their intuitive meaning or why they were given those names. However, I can at least say that “updatable” refers to UPDATE and DELETE and “insertable into” refers to INSERT, and a view can’t be insertable into unless it’s updatable. But note the suggestion that some views might permit some updates but not others (e.g., DELETEs but not INSERTs), and the implication that it’s therefore possible that DELETE and INSERT might not be inverses of each other. Both of these facts (if facts they are) I regard at least potentially as further violations of The Principle of Interchangeability.
Aside: There’s an asymmetry here that seems intuitively odd. An argument might be made—not by me!—that you can do DELETEs but not INSERTs on a union view, because the delete rule is obvious (delete from both operands) but the insert rule isn’t (do we insert into both operands or just one—and if just one, which?). But then an exactly analogous argument would surely say you can do INSERTs but not DELETEs on an intersection view. In other words, if some views are “deletable from but not insertable into,” then surely others must be “insertable into but not deletable from” (?). End of aside.
For what I take to be obvious reasons, I won’t even attempt a precise characterization here of just which views SQL does regard as updatable. Loosely speaking, however, they do at least include the following:
Views defined as a restriction and/or projection (key preserving) of a single base table
Views defined as a one to one or one to many join of two base tables (in the one to many case, only the many side is updatable)
Views defined as a UNION ALL or INTERSECT of two distinct base tables
Certain combinations of Cases 1–3 above
Regarding Case 1, however, I can be a little more precise. To be specific, an SQL view is certainly updatable if all of the following conditions are satisfied:
The defining expression is either (a) a simple SELECT expression (i.e., not a UNION, INTERSECT, or EXCEPT expression) or (b) an “explicit table”—i.e., an expression of the form TABLE <table name>—that’s logically equivalent to such a simple SELECT expression. Note: I’ll assume for simplicity in what follows that Case (b) is automatically converted to Case (a).
The SELECT clause in that SELECT expression specifies ALL, not DISTINCT.
After expansion of any “asterisk style” items, every item in the SELECT item commalist is a simple column reference (i.e., a column name, possibly dot qualified, and possibly accompanied by an AS specification), and no such item appears more than once.
The FROM clause in that SELECT expression takes the form FROM T [AS …], where T is the name of an updatable table (either a base table or an updatable view).
The WHERE clause, if any, in that SELECT expression contains no subquery in which the FROM clause references that table T.
The SELECT expression contains no explicit GROUP BY or HAVING clause.
But even these limited cases are treated incorrectly, thanks to SQL’s lack of understanding of (a) The Golden Rule, (b) The Assignment Principle, and (c) constraint inference (see the section Constraints and Predicates immediately following), and thanks also to (d) the fact that SQL permits nulls and duplicate rows. Surely we can do better than this?
Constraints and Predicates
A view is a relvar and is thus constrained to be of some relation type; in fact, the type of any given view V is, precisely, the type of the defining expression for V.[42] By way of example, here again is the Tutorial D definition of the view LS (“London suppliers”):[43]
VAR LS VIRTUAL ( S WHERE CITY = 'London' ) ;
This view is a “restriction view”—its defining expression calls for invocation of a certain restriction operation on relvar S—and its type is therefore the same as that of relvar S, viz., RELATION {SNO CHAR, SNAME CHAR, STATUS INTEGER, CITY CHAR}.
More generally, however, a view is a relvar and is thus subject to what in Chapter 2 I called a total relvar constraint (for the relvar in question). But the total relvar constraint that applies to a view V is, at least in part, a derived constraint: It’s derived—again, at least in part—from the constraints for the relvars in terms of which V is defined, in accordance with the semantics of the relational operations involved in the view defining expression. In the case of view LS, for example, the total relvar constraint is the logical AND of:
The total relvar constraint for relvar S, and
The restriction condition (CITY = ‘London’) specified in the view defining expression.[44]
In other words, view LS is subject to all constraints that apply to relvar S—e.g., the constraint that {SNO} is a key—and the constraint that the city is London. Note, therefore, that The Golden Rule applies to views just as much as it does to base relvars.
Let’s agree to use the term view constraint to refer to any constraint that applies to some view. Now, even if view constraints can be derived as in the foregoing example, it doesn’t follow that there’s no need to declare them explicitly (for one thing, the system might not be “intelligent” enough to determine those constraints for itself, automatically). Thus, it should certainly be possible to declare explicit constraints for views. In particular, it should be possible (a) to include explicit KEY and FOREIGN KEY specifications in view definitions and (b) to allow the target relvar in a FOREIGN KEY specification to be a view. The following example illustrates both of the possibilities mentioned under (a) here:
VAR LS VIRTUAL ( S WHERE CITY = 'London' )
KEY { SNO }
FOREIGN KEY { SNO } REFERENCES S ;Next, a view is a relvar and therefore has a relvar predicate, in which the parameters correspond one to one to the attributes of the relvar—i.e., the view—in question. But the predicate that applies to a view V is a derived predicate: It’s derived from the predicates for the relvars in terms of which V is defined, in accordance with the semantics of the relational operations involved in the view defining expression. In fact, we already know this, because we know from Chapter 2 that every relational expression has a corresponding predicate, and of course a view has exactly the predicate that corresponds to its defining expression. For example, consider view LS (“London suppliers”) once again. That view is a restriction of relvar S, and its predicate is therefore the logical AND of the predicate for S and the specified restriction condition:
Supplier SNO is under contract, is named SNAME, has status STATUS, and is located in city CITY
AND
city CITY is London.
Or more colloquially:
Supplier SNO is under contract, is named SNAME, has status STATUS, and is located in CITY London.
Note, however, that this latter form obscures the fact that CITY is a parameter. Indeed it is a parameter, but the corresponding argument is always the constant London. (As noted in Chapter 1, a more realistic version of view LS would probably project away the CITY attribute, precisely because of this fact. I choose not to do so here in order to keep the example simple. However, I’ll have more to say about this possibility in Chapter 5.)
Aside: If you prefer the somewhat more formal style for predicates described in Chapter 2, you might alternatively say the predicate for view LS looks something like this:
is_entity ( SNO ) AND has_SNAME ( SNO , SNAME ) AND has_STATUS ( SNO , STATUS ) AND has_CITY ( SNO , CITY ) AND CITY = 'London'End of aside.
Multivariable Constraints
There’s another matter I need to discuss briefly in connection with constraints as opposed to predicates (though the matter in question really has to do with constraints in general, not just view constraints in particular). First of all, recall this simple example from Chapter 2:
CONSTRAINT CX1 IS_EMPTY ( S WHERE STATUS < 1 ) ;
This example is expressed in Tutorial D, of course, but for reasons that will quickly become clear I want to show the same constraint (or at least the boolean expression portion of the constraint, which is to say the portion between the constraint name CX1 and the terminating semicolon) in relational calculus instead:[45]
NOT EXISTSx∈ S (x.STATUS < 1 )
Or equivalently:
FORALLx∈ S (x.STATUS ≥ 1 )
In these formulations, the subexpression “x ∈ S” (which can be read as “x such that x is a tuple in the current value of S”) defines the variable x to be a range variable, “ranging over” the current value of relvar S. In other words, the permitted values of x at any given time are exactly the tuples appearing in the relation that’s the value of relvar S at the time in question.
As a basis for further examples, consider view LS once again (“London suppliers”), together with its companion view NLS (“non London suppliers”). Here are relational calculus formulations of a couple of obvious constraints that apply to these two views:
FORALLx∈ LS (x.CITY = 'London' ) FORALLx∈ NLS (x.CITY ≠ 'London' )
Now, all of the constraints we’ve seen in this section so far have been single-variable constraints, because each of them involves just one range variable. Here by contrast is an example of a multivariable constraint (it’s basically constraint CX3 from Chapter 2):
FORALLx∈ S ( FORALLy∈ SP ( IFx.STATUS < 20 ANDx.SNO =y.SNO THENy.PNO ≠ 'P6' ) )
Aside: By the way, note that there’s a logical difference between multivariable constraints and what SQL and Relational Theory calls multirelvar constraints. A multivariable constraint is one that involves involves two or more range variables; a multirelvar constraint is one that involves two or more relvars. Now, it’s certainly true that every multirelvar constraint is also a multivariable constraint, but the converse is false—the range variables in a multivariable constraint might all range over the same relvar (e.g., see the next example but one). End of aside.
Here are some more examples of multivariable constraints (all of them based on relvars S and/or LS and/or NLS):
No supplier number appears in both LS and NLS:
FORALL
x∈ LS ( FORALLy∈ NLS (x.SNO ≠y.SNO ) ){SNO} is a key for each of S, LS, and NLS (for simplicity, I show the constraint for relvar S only):
FORALL
x∈ S ( UNIQUEy∈ S (x.SNO =y.SNO ) )Note: In case you’re unfamiliar with the UNIQUE quantifier, it can be read as “there exists exactly one … such that.”
{SNO} in LS is a foreign key, referencing the key {SNO} in S:
FORALL
x∈ LS ( UNIQUEy∈ S (x.SNO =y.SNO ) )S is equal to the (disjoint) union of LS and NLS:
FORALL
x∈ S ( UNIQUEy∈ LS (x=y) OR UNIQUEy∈ NLS (x=y) ) AND FORALLy∈ LS ( UNIQUEx∈ S (x=y) AND FORALLy∈ NLS ( UNIQUEx∈ S (x=y)At any given time, LS is equal to that restriction of S where the CITY value is London:
FORALLx∈ LS ( UNIQUEy∈ S (x=y) AND FORALLy∈ S ( IF y.CITY = 'London' THEN UNIQUEx∈ LS (x=y) )
Now (at last) we come to the point of this perhaps rather lengthy digression. In Chapter 1, I introduced the idea of compensatory actions, which are additional updates that are performed automatically by the DBMS, over and above updates explicitly requested by the user, in order to prevent some integrity constraint violation from occurring. Well, it’s precisely if the constraint in question is a multivariable constraint specifically that some compensatory action might be needed—as we’ll see in subsequent chapters.
Information Equivalence
When I first mentioned information equivalence in Chapter 1, I said by way of example (paraphrasing slightly) that a database design involving just the suppliers relvar S was information equivalent to one involving relvars LS and NLS—“London suppliers” and “non London suppliers,” respectively—taken in combination. I also said a design involving just relvar LS wasn’t information equivalent to either of the ones just mentioned (nor is one involving just relvar NLS, of course). Now I can explain these ideas in more detail.
Now, when I said the design involving just relvar S was information equivalent to the one involving relvars LS and NLS taken together, what I meant from an intuitive point of view—and I’m sure you understood me to mean exactly this—was that any proposition that could be represented by either one could also be represented by the other. Intuitively speaking, in other words, two designs are information equivalent if and only if they’re capable of representing the same set of propositions.[46] And that’s essentially what the following definition says:
By way of example, consider relvars S, LS, and NLS once again. Let DB1 and DB2 be, respectively, the set of relvars consisting of relvar S in isolation and the set of relvars consisting of relvars LS and NLS taken together. Now, it’s clear that we can define the relvars in DB2 in terms of the sole relvar in DB1, thus:
LSS WHERE CITY = 'London' NLS
(the symbol “![]() ” means “is defined as”). It’s also clear that we can define the sole relvar in DB1 in terms of the relvars in DB2, thus:
” means “is defined as”). It’s also clear that we can define the sole relvar in DB1 in terms of the relvars in DB2, thus:
S
Moreover, I think it’s clear without going into too much detail that for every constraint that applies to DB1 there’s an analogous constraint that applies to DB2 and vice versa. I’ll give just one loose example: For DB1, no two distinct tuples in relvar S have the same supplier number; for DB2, (a) the union of relvars LS and NLS is disjoint and (b) no two distinct tuples in that union have the same supplier number. Thus, I hope you agree it’s at least intuitively reasonable to say that every proposition that can be represented by DB1 can be represented by DB2 and vice versa; in other words, DB1 and DB2 are indeed information equivalent.
Several points arise from the foregoing, the following among them. Let DB1 and DB2 be information equivalent sets of relvars, and let their current values be db1 and db2, respectively. Assume also that the specific set of propositions represented by DB1 at any given time is supposed to be identical to the set of propositions represented by DB2 at that same time. Then:
Those values db1 and db2 can be said to be information equivalent in turn (certainly it’s true that every proposition represented by db1 is represented by db2 and vice versa). In other words, the notion of information equivalence can usefully be applied to sets of relations as such as well as to sets of relvars.
If db1 and db2 are information equivalent, there must exist mappings M12 and M21 that transform db1 into db2 and db2 into db1, respectively, where the mappings in question are, or can be, formulated in terms of operations of the relational algebra (and are inverses of each other, of course). Conversely, if such mappings exist, then db1 and db2 are information equivalent. And if such mappings exist for all possible pairs of current values db1 and db2 of DB1 and DB2, respectively, then DB1 and DB2 per se are information equivalent. (Of course, these observations, taken together, are little more than a paraphrase of the original definition.)
For every query Q1 on db1, there must exist a query Q2 on db2 that yields the same result (and vice versa, obviously). Note: It follows from this observation that IS_EMPTY (Q1) and IS_EMPTY (Q2) are either both true or both false, and hence that, as claimed previously, for every constraint C1 on DB1 there must exist a corresponding constraint C2 on DB2 and vice versa.
Let U1 be an update on DB1 that yields a “new” value db1’ of DB1; then there must exist an update U2 on DB2 that yields a “new” value db2’ of DB2, such that db1’ and db2’ are information equivalent in turn (and vice versa once again). Figure 3-1 illustrates this point.
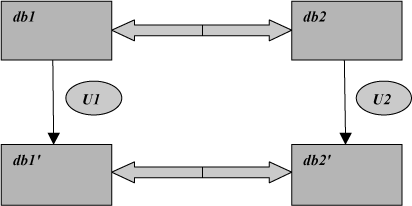
In contrast to the foregoing, suppose DB1 and DB2 aren’t information equivalent. Then there’ll be operations—queries and updates—on DB1 that have no counterpart on DB2 or vice versa. (Note, incidentally, that if DB1 and DB2 are indeed not information equivalent, then their current values db1 and db2 might or might not themselves be information equivalent in turn; in general, however, they won’t be.)
Observe now that all of the above applies in the particular case in which DB2 consists exclusively of views of the relvars in DB1. In other words, if DB2 is “views only” and that set of views is information equivalent to DB1, then every update on DB2 has a counterpart update on DB1 and vice versa. In the chapters to come, I’ll consider this situation in detail; that is, I’ll show in detail how updates on the views in DB2 can be implemented in terms of updates on the relvars in DB1.
What about the case in which DB2 consists only of views of the relvars in DB1 but DB2 and DB1 are not information equivalent?[49] Well, notice first that, precisely because the relvars in DB2 are derived from those in DB1, there can’t be any propositions that can be represented by DB2 and not by DB1—or, turning this statement around, everything that can be represented by DB2 can certainly be represented by DB1, but the converse is false. In general, therefore, there might still be some updates on DB2 that can be implemented in terms of updates on DB1. At the same time, there’ll certainly be updates on DB2 that can’t be implemented in this way (because there’s not enough information available), and those updates must therefore fail. The structure of the argument in the next several chapters is thus as follows:
When we do have information equivalence, it should always be possible to update DB2 (the views) in a logically correct fashion, and I’ll explain the rules for doing so as carefully as I can.
Even when we don’t have information equivalence, sometimes it’ll be possible to apply the view updating rules anyway (albeit only partially, perhaps), and I’ll discuss such cases in detail too. But I must stress that updating in such cases can lead to results that, while of course always formally predictable and well defined, might sometimes be undesirable—possibly even unacceptable for some reason. Because of this state of affairs, I leave to others (perhaps the individual user, perhaps the DBA, perhaps even the DBMS) the choice as to whether updates should in fact be allowed in such situations.
When the rules don’t apply at all—and I’ll explain when they don’t—then as I’ve said updates will necessarily fail. Note: I do have a few further remarks to make in connection with this case, however, but I’ll defer those remarks to the very end of Chapter 5.
Concluding Remarks
To close this chapter, I have a few miscellaneous observations. First of all, I want to say something about terminology. This book is, of course, all about views, and I hope it goes without saying that when I use the term view, I do so in the original sense—the sense, that is, in which that term was originally defined. Unfortunately, however, some terminological confusion has arisen in recent years, certainly in the academic world, and to some extent in the commercial world also. As we know, a view in the original sense is a derived relvar—it’s derived in the obvious way from the relvars (base relvars and/or other views) in terms of which it’s defined. Well, there’s another kind of derived relvar too, called a snapshot.[50] As that name might tend to suggest, a snapshot, although it’s derived, is real, not virtual, meaning it’s represented not just by its definition in terms of other relvars but also, at least conceptually, by its own separate copy of the data. For example (to invent some syntax on the fly):
VAR LSS SNAPSHOT ( S WHERE CITY = 'London' )
KEY { SNO }
REFRESH EVERY DAY ;Defining a snapshot is just like executing a query, except that:
The result of the query is saved in the database under the specified name (LSS in the example) as a read-only relvar. Note: By read-only here, I mean no updates on the relvar are allowed, apart from the periodic “refresh”—see the bullet point immediately following.
Periodically (EVERY DAY in the example) the snapshot is “refreshed,” meaning its current value is discarded, the query is executed again, and the result of that new execution becomes the new snapshot value. Of course, other REFRESH options are possible too—for example, EVERY MONDAY, EVERY 5 MINUTES, EVERY MONTH, and so on. In particular, REFRESH ON EVERY UPDATE would mean the snapshot is at all times in synch with the relvar(s) from which it’s derived.
In the example, therefore, snapshot LSS represents the data as it was at most 24 hours ago.
Snapshots are important in data warehouses, distributed systems, and many other contexts. In all such cases, the rationale is that applications can often tolerate—in some cases even require—data as of some particular point in time. Reporting and accounting applications are a case in point; such applications typically require the data to be frozen at an appropriate moment (typically the end of an accounting period), and snapshots allow such freezing to occur without locking out other applications.
So far, so good. The problem is, snapshots have come to be known (at least in some circles) not as snapshots at all but as materialized views. But they’re not views! Views aren’t supposed to be materialized at all; rather, operations on views are supposed to be implemented (as explained in the introduction to this chapter) by mapping them into suitable operations on the relvars in terms of which they’re defined.[51] Thus, “materialized view” is simply a contradiction in terms. Worse yet, the unqualified term view is now often taken to mean a “materialized view” specifically—again, at least in some circles—and so we’re in danger of no longer having a good term to mean a view in the original sense. In this book, as I’ve said, I do use the term view in its original sense, but be warned that it doesn’t always have that meaning elsewhere.
My second point is this. As some readers might know, I’ve been thinking about the problem of view updating for some time; indeed, I’ve been trying to get view updating “right” for many years, and this book, which represents my most recent thinking on the subject, is far from being my first publication in this area. Thus, where there are discrepancies between this book and something I’ve said in an earlier publication, this book should be taken as superseding. Here for the record is a summary list of those earlier publications:
“File Definition and Logical Data Independence” (coauthored with Paul Hopewell), Proc. 1971 ACM SIGFIDET Workshop on Data Definition, Access, and Control, San Diego, California (November 1971)
“Updating Views,” in Relational Database: Selected Writings (Addison-Wesley, 1986)
“Updating Union, Intersection, and Difference Views” and “Updating Joins and Other Views” (both coauthored with David McGoveran), Database Programming & Design 7, Nos. 6 (June 1994) and 8 (August 1994); republished in Relational Database Writings 1991-1994 (Addison-Wesley, 1995)
“View Updates,” Section 10.4 of An Introduction to Database Systems (8th edition, Addison-Wesley, 2004)
“View Updating,” Appendix E of Databases, Types, and the Relational Model: The Third Manifesto, by Hugh Darwen and myself (3rd edition, Addison-Wesley, 2006)
“The Logic of View Updating,” in Logic and Databases: The Roots of Relational Theory (Trafford, 2007)
“How to Update Views,” in Database Explorations: Essays on The Third Manifesto and Related Topics, by Hugh Darwen and myself (Trafford, 2010)
The first two items in this list are rather embarrassingly bad, but the rest are (I believe) generally on the right lines, though they’re all somewhat confused (and the farther back they go, chronologically speaking, the more confused they are; I guess that indicates progress, of a kind).
I should also mention David McGoveran’s patents in this area:
“Accessing and Updating Views and Relations in a Relational Database,” U.S. Patent No. 7,263,512 (August 28th, 2007)
“Computer-Implemented Method for Translating among Multiple Representations and Storage Structures,” U.S. Patent No. 7,620,664 (November 17th, 2009)
The ideas to be described in the present book are somewhat similar to (and heavily influenced by) the ones discussed in these patents, though I must also make it clear that they differ considerably at the detail level.
Note: As should be obvious from the foregoing, I freely admit that I’ve changed my mind in this area quite a few times. In my defense here, I’d like to quote Bertrand Russell:
I have been accused of a habit of changing my opinions … I am not myself in any degree ashamed of [that habit]. What physicist who was already active in 1900 would dream of boasting that his opinions had not changed during the last half century? … [The] kind of philosophy that I value and have endeavoured to pursue is scientific, in the sense that there is some definite knowledge to be obtained and that new discoveries can make the admission of former error inevitable to any candid mind. For what I have said, whether early or late, I do not claim the kind of truth which theologians claim for their creeds. I claim only, at best, that the opinion expressed was a sensible one to hold at the time … I should be much surprised if subsequent research did not show that it needed to be modified. [Such opinions were not] intended as pontifical pronouncements, but only as the best I could do at the time towards the promotion of clear and accurate thinking. Clarity, above all, has been my aim.
These wonderful remarks, which need no elaboration by me, are taken from Russell’s own preface to The Bertrand Russell Dictionary of Mind, Matter and Morals, ed., Lester E. Denonn (Citadel Press, 1993).
To repeat, this book represents my most recent thinking. But I make no claim that what it has to say represents the last word on the subject. There are still some loose ends—indeed, there are one or two points on which the ideas could quite reasonably be challenged (and in the interest of full disclosure, I’ll call out such points explicitly, when we get to them). But I’m an optimist; I believe those loose ends can and will be tied up in good time, and I don’t believe there are any showstoppers lurking among them. Indeed, part of my reason for wanting to publish this book at this time and in its present form is to solicit constructive suggestions. Certainly I’m open to discussion in those areas where such suggestions might make sense. Though perhaps I should stress that qualifier constructive … Perhaps I’m being a little defensive here, but the fact is that I’ve seen quite enough negative criticism in this area in the past, and I would prefer to keep the dialog positive.
One final point to close this chapter: The topic of view updating can unfortunately be quite confusing, even when it’s not particularly controversial. Part of the difficulty lies in the fact that there’s unavoidably a lot of detail to wade through, and it’s easy to lose one’s way in debates and discussions. In particular, it’s all too easy to forget, especially in examples, which relvars are base ones and which ones are views. It’s important to keep a clear head! Again I have to say: Caveat lector.
[35] One of my reviewers claimed it most certainly is in the same league. Maybe it is. I don’t want to argue the point.
[36] It must mention at least one relvar because otherwise the view wouldn’’t be a relvar at all but merely a relation constant (see further discussion in Chapter 13).
[37] At least inasmuch as the underlying base relvars are! See the remarks on this point in the final section of Chapter 2.
[38] So do base relvars, of course. Again, see the remarks on this point in the final section of Chapter 2.
[39] I note in passing that today’s mainstream DBMS products still don’t do a very good job on it.
[40] The approach to updating views found in today’s SQL DBMSs has its origins in the paper “Views, Authorization, and Locking in a Relational Data Base System,” by Donald D. Chamberlin, James N. Gray, and Irving L. Traiger, in the proceedings of the 1975 National Computer Conference, Anaheim, Calif. (AFIPS Press, May 1975). With hindsight, it’s tempting to suggest—perhaps a little unfairly—that some of the confusions commonly found in practice in connection with the view concept are reflected in the very title of this paper.
[41] You might raise an eyebrow at this point, given my claim in Chapter 1 to the effect that all views are logically updatable. But what I meant, and still do mean, by that claim is more specifically that all relational views are updatable. I neither know nor care whether nonrelational views—by which I mean ones involving nonrelational concepts such as duplicate rows and nulls—are updatable (though I’m pretty sure there’s no way to update such views that can be defended as logically correct).
[42] See Appendix B for an explanation of the type of an arbitrary relational expression.
[43] I’ll continue to use conventional Tutorial D syntax for view definitions, despite my misgivings regarding that syntax as articulated in the section before last.
[44] In general, it should be clear that the relation denoted at any given time by the restriction expression rx WHERE bx must satisfy all constraints that apply to the relation denoted by the relational expression rx and the constraint denoted by the boolean expression bx (in other words, WHERE is AND, loosely speaking). Note: The constraint represented by bx here is a restriction condition. See Appendix B for a precise definition of this concept.
[45] Refer to SQL and Relational Theory if you need further explanation of relational calculus expressions like those discussed in this section.
[46] It follows that another term that might be used for the concept is expressive equivalence.
[47] Please note that this definition is slightly simplified, in a sense. I’ll have more to say about it in Chapter 14. Until then, however, the definition as given here will serve.
[48] I use the symbols DB1 and DB2 here to suggest that we might intuitively think of each of those sets of relvars, together with the pertinent constraints, as constituting a database—or a dbvar, rather, to be a little more precise about the matter. In subsequent chapters, in fact, when I’m talking about examples of information equivalence, for brevity I’ll sometimes refer to the sets of relvars under discussion as databases, or sometimes as dbvars. Note: With regard to the symbol DB2 in particular, please understand that no reference is intended to the commercial product that goes, somewhat inappropriately, by that name.
[49] In Database Design and Relational Theory, I argue that such a DB2 is logically incorrect (or at least incomplete), in the sense that it’s incapable of representing certain facts about the real world that we want to be able to represent. David McGoveran would say it’s not expressively complete. Moreover, note that what we have here is exactly a case of what earlier in the chapter I referred to as information hiding: Users of DB2 are seeing only part of the picture, as it were, and it’s only to be expected that there’ll be operations they can’t be allowed to perform.
[50] The term snapshot first appeared, so far as I’m aware, in the paper “Database Snapshots,” by Michel E. Adiba and Bruce G. Lindsay (IBM Research Report RJ2772, March 7th, 1980). See also the extended version “Derived Relations: A Unified Mechanism for Views, Snapshots, and Distributed Data,” by Michel Adiba (Proc. 1981 International Conference on Very Large Data Bases, Cannes, France, September 1981).
[51] It’s true that certain products do use materialization instead of operation mapping as an implementation technique—specifically, as a technique for implementing certain “complex” retrievals on certain “complex” views—but the fact that this is so isn’t germane to the present discussion (in fact, it’s a complete red herring).