
CHAPTER 4
Creating Content Models
You may already be making content models—even if you don’t know it. That’s how it happened to me.
A few years back, not long after I’d convinced my company that there was something to this “content strategy thing,” I found myself inching closer and closer to the people building CMS templates, and asking more and more questions as I did. Why don’t we split this blob into multiple chunks? Why can’t we limit this field to 200 characters? Why isn’t there a place for author attribution?
Pretty soon, I stopped asking why and started making simple bulleted lists of attributes I wanted included. I’d take these lists to the team and ask them to be included in our IA and spec documents.
I didn’t have a name for this back then. Mostly, I referred to it as “making the CMS suck less,” (or, sometimes, “irritating the hell out of my team”). But these bulleted lists were my very first content models. Today my documentation may be slightly more complex (though not much)—and, I hope, my models a bit better—but the approach is basically the same. Take the knowledge you gleaned from knowing your content—and its purpose—inside and out, then:
- Write down all the content types you have and all the elements each one could contain, based on your analysis from Chapter 3, “Breaking Content Down.”
- Decide how granular to get—in other words, which of those elements you actually need to include.
- Discuss it with both those who will technically implement it and those who will rely on it.
- Rinse and repeat until you make it real.
Since you should now have a good draft of your content types and their potential attributes mapped out, we’ll use this chapter to focus on the rest. First, we’ll talk about how you can document your content model. Then we’ll walk through the considerations, compromises, and collaboration opportunities you might experience as you work to get it implemented.
Documenting a Content Model
Type “content modeling” into your favorite search engine, and you may never want to think about modeling content again. Replete with references to XML and RDF and a whole mess of acronyms, information about content modeling tends to include software-specific white papers, jargon-heavy explanations, and engineer-speak galore.
All this makes content modeling seem difficult and often too dry and distant for writers, designers, and strategists. But a content model needn’t be complicated, nor even particularly technical. It just needs to be useful and clearly defined.
After all, in Chapter 3 we got at the art of the content model—the beating heart that lends it life—and looked at how two different models might be constructed for a common content type, a recipe. Sometimes, that level of modeling is enough. Other times, you might need to get more high-level, more nitty-gritty, or both to communicate your model adequately to others.
At the high level, you could create a model that shows a number of content types and how they’re related to one another. For example, let’s say you’re working with content that doesn’t just include recipes, but also additional content about the dishes those recipes make, meal plans according to cuisine types and events or holidays they’re part of, ingredient descriptions, and the like. In this case, you’d show how all those types of content are conceptually connected to one another, as shown in Figure 4.1.
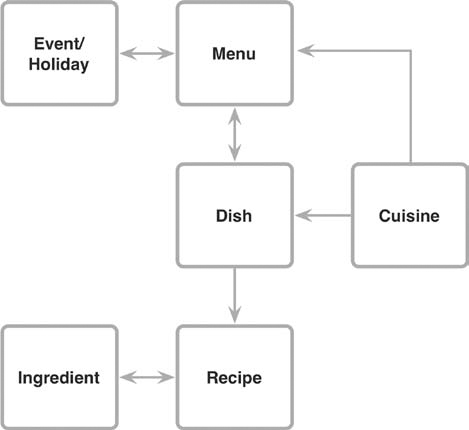
FIGURE 4.1
When you need to show how content concepts fit together at the highest level, a diagram of their relationships can get everyone on the same page.
In this chart, arrows show the relationships between types of content. Lines without an arrow indicate a singular relationship, while those with an arrow indicate multiple potential relationships. (For example, each recipe can only be for a single dish, but you can have multiple recipe options for each dish.) Typically, these relationships are called one-to-one, one-to-many, or many-to-many.
While visuals are helpful for explaining content models at the conceptual level, they aren’t always great for specifics. At some point, you’ll likely need a place to list your actual content elements, and also to document how much content—and which kinds—your model needs to support. This can be done in something as simple as a bulleted list of elements and their requirements for smaller projects, or a detailed spreadsheet with a tab for types of content, as shown in Figure 4.2.
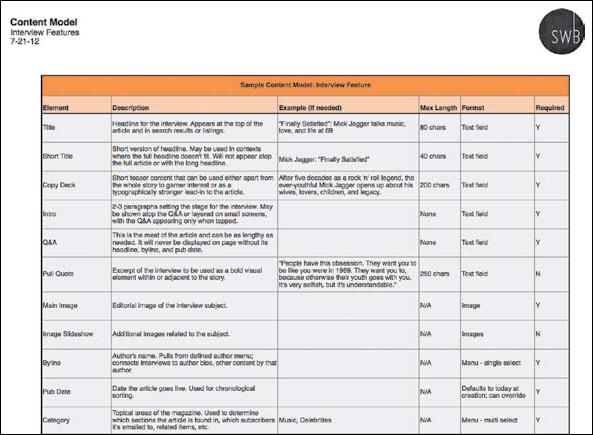
FIGURE 4.2
A detailed spreadsheet describing the components and relationships within each content type—in this case, an “interview”—can supplement a simpler visual model.
Whether you choose a spreadsheet, a list, a wiki, or something else entirely, at some point, you’ll want something that gets specific about a number of things:
- Required/optional rules: For example, a headline may always be required, but a subhead may be optional.
- Length requirements: For example, you may want to limit story summaries to no more than 300 characters so they can display in full easily, or require that all phone numbers have at least 10 digits to ensure data quality.
- Valid character types: For example, you may want to dictate that only numerals may be entered in ZIP code fields.
While this detail may seem minute, these decisions are critical for content people to consider for three reasons. First, the rules you determine now are what will end up in the project’s specifications—and if you’ve already evaluated your content and your users’ needs closely, you’ll be most likely to understand what’s truly needed.
Second, the more care you take now, the better the resulting templates will guide those adding and updating content in the CMS in the long term—resulting in more consistent, less error-prone content entry.
Finally, whether you’re the one responsible for UX documents like wireframes or you’re sharing your insights with the person who is, your content model and associated rules will give crucial guidance not just for which elements should be present, but how much space each one will need.
A Moment for Metadata
So far, we’ve talked a lot about the actual user-facing chunks of content in your model. But there may be a whole other universe of elements that aren’t visible to those on the outside: metadata. Frequently defined as “data about data,” metadata can be mega-confusing at first—mostly because it’s a term people use in a whole range of ways.
I typically use “metadata” to refer to descriptive information. For example, this is a book about content strategy, information architecture, and mobile; those topics describe the contents of the book.
Metadata can also be used to mean structural components. In other words, if you define a content chunk as a “summary,” that can be considered a type of metadata as well. The reason I typically don’t refer to this as metadata is that it’s not describing the contents of the summary—what the summary is about—but rather its container. Makes things less confusing, in my opinion.
What’s most critical here is to remember that you’ll typically need both kinds of information about your content: labels for its chunks, and tags and taxonomies that define what the content is actually about. Some of those tags and taxonomies might be externally visible things users can search and sort by, and some might be internal, visible only to your CMS users.
NOTE WHAT IS TAXONOMY?
Taxonomy might be a common term for IAs, but if you’re from a marketing or editorial background, this word can feel a bit foreign. Don’t fret—it’s not hard to get the basics. A taxonomy is a classification system—a means of organizing information by categorizing it according to a fixed list. A classical case of this is the Linnaean taxonomy of the animal kingdom, in which all animals can be categorized. For example, in the model shown in Figure 4.2, “category” would be a type of descriptive metadata that uses a taxonomy: You can’t make up new tags whenever you want, but instead must select from a defined list—a list that should, in theory, offer an accurate category for anything you’d publish on this site.1
Whether and how much metadata needs to be present in your content model depends on what you intend to do with that content—and to do that, you’ll need to take some considerations into account.
Considerations and Compromises
Now that you have a format for your model, it’s time to finalize it. But before you get too tied to your diagrams, you’ll want to make sure your model is ready for the real world—a world complicated by things like money, people, and technology.
To do this, you’ll need to consider your content against three criteria:
- Gains and losses: What would you gain by making the element its own piece of content, and what might you lose if you don’t? Consider both business and user goals here.
- CMS capabilities and trade-offs: Will the CMS you’re storing this in support this level of complexity—and at what cost? If you’re building or implementing a new CMS, are you early enough in the project to influence it?
- Authors and workflows: Can your content creators and editors—and their workflow—consistently enter and manage content in this way?
As you evaluate elements against each of these questions, you can make a final decision about whether or not to include them in your model.
Let’s start by talking about each of those considerations—gains and losses, CMS capabilities, and authors and workflows—separately. Then, in the last part of this chapter, we’ll talk about how to work with database developers, authors, and content managers to make those attributes a reality—both at launch and as content is authored and updated over time.
Gains and Losses
“Modeling content is a never-ending battle between flexibility and complexity,” says Deane Barker, whom we met in Chapter 3. The more complex a model is—as in, the more separate elements it contains—the more ways you are able to create logic about which content is displayed where and when, as well as how that content can be found, organized, indexed, and archived.
This flexibility comes at a price. The more complex the model, the tougher it is for technical teams to implement, and the less likely it will be that content creators and managers remember to use and maintain all the fields.
In other words, there’s no right amount of detail for your content model. There’s only finding the balance between what that content needs to do now, what you want it to do in the future, and how much you can afford to invest in both.
If you’ve never done it before, it may sound daunting, but don’t worry: more than anything, this is about looking closely, asking questions, and drawing connections between information—skills you’ve likely honed in other interactive work, now reapplied to a more microscopic plane. Plus, it’s work that can be done iteratively, tuned and improved over time. If you don’t get it perfect the first time, it’s OK to come back to it later.
So how you do know how granular you need to be? There are four main things to consider for each content element.
Will this element be used for searching or sorting?
Take an events calendar, for example. To see what’s coming up this weekend, users want to be able to sort events by date—creating an obvious need to treat the date as a separate field. The same need can be seen in many other types of data, such as in online retail, where faceted search allows users to expand or refine results based on criteria like size and style.
These obvious examples of searching and sorting are just the beginning, though. Take a look at your content and consider: would this information be easier to use if you could search or sort it?
Will it be used to relate this content to other content?
Consider our recipe example from Chapter 3. If a recipe has an author or other attribution associated with it, like a cookbook or magazine title, do you need that attribution to be its own content element? That depends: do authors have more than one article in your repository? Do you want to track recipes by author or publication and allow people to find them that way? If so (and the answer is likely yes), that byline will need its own field that relates it to that author’s listing.
Does it need to be extracted and displayed alongside other content?
Let’s say you want to feature upcoming events on a homepage or list them on a results page. What content should be shown in these listings—all event details, or just the name and date with a teaser description and location? If you want relevant parts of a piece of content to appear elsewhere from the main entry, then those parts need their own element in your content model.
Does it need to shift, resize, or be removed altogether for some displays?
As content gets reused and reimagined across more and more displays and devices, this question becomes increasingly difficult and increasingly critical. In fact, the decisions you make now will define what flexibility you have in how content will morph and move across devices and channels. That is, if you ever want to do things like:
- Increase or decrease one element’s prominence relative to other elements.
- Shift its location (such as from a sidebar to the main column) or change its relative size when a responsive design narrows for small screens.
- Exclude it from third parties that are accessing your content through an API (which we’ll dive into in Chapter 7, “Making Sense of Content APIs”), so they can access some of your content, but not all.
- Display a shorter or less complex version of the content for certain circumstances.
- Deliver different versions of the content to different customers.
- Ensure the content’s headers, sections, asides, and other parts stay distinct when displayed on outputs with different displays, from smartphones to read-later apps.
- Remove it from certain devices or displays altogether.
Then you’ll need those content elements to be documented in your structure. For example, if your piece of content includes a teaser or copy deck, will that content always be there, and always in the same location? What about for smartphone-sized displays? What about in an Internet-enabled car or refrigerator? If you need content to appear differently on different outputs, it likely needs to be its own chunk.
Some call this process of finalizing elements “atomizing” content, but that description can be misleading. Atoms are tiny building blocks, and creating complete structures out of them would take forever. Instead of atoms, I prefer to think about content as molecules: several atoms that work together. So when modeling content, there’s no need to break content down into the tiniest pieces if it’s not going to help you do anything specific. Instead, cluster them into a larger chunk so as not to overcomplicate your templates (or exasperate your content managers).
At the end of the process, you should have whittled your draft content model down to just the elements you think your CMS should support to meet your user and business goals. Now you just need to turn that ideal model into a realistic one by aligning it with your human and technical realities.
CMS Capabilities and Trade-offs
Content modeling isn’t just up to you; it must be implementable and technically viable in your CMS as well—and that means making a model your technical team can get behind.
What’s the best way to bring your content models and requirements to those responsible for CMS selection, implementation, customization, or enhancement? Instead of making database developers feel like you’re telling them how to do their job (trust me, that one never works), you need to collaborate. After all, they’re the ones likely to let you know whether a model is too complex for your CMS, or whether you can afford to create new templates for all the content types you’ve documented. If you approach them right, they’ll probably even be happy you’re taking an interest and relieved that they won’t be left guessing at what structure the content needs.
Before you go barreling down the hall to make demands, take a moment to understand where this crowd is coming from. Your content model shows how information will be entered into the CMS and displayed to users on the other end, while your developers’ idea of a model likely comes from training in relational database modeling. This means that rather than thinking about how a user will experience the content or even how an editor will enter it, they are often thinking about structures with rigid definitions and roles.
Thankfully, you don’t need to become a database expert to start collaborating with those who are. Instead, we can simply establish some shared vocabulary to help keep the conversation on track. The following is by no means a definitive guide, but it is a starting point—a way to begin to map the content you’re working with back to concepts a database developer is likely comfortable with.
That said, typical terminology used to define elements of a data model, like our illustration in Figure 4.3, includes:
- Entities: Units of data that can be classified into types. In short, each content type you have is an entity—a thing about which data can be stored.
- Relationships: These show how different entities relate to one another, such as a restaurant listing (an entity) that is located at an address (another entity). The relationship between entities in this scenario is “located at.” This is an example of a one-to-one relationship (a restaurant only has one address, and its address only has one restaurant), but they can also be one-to-many or many-to-many, as mentioned earlier in this chapter.
- Attributes: Essentially, the same as those content elements we’ve covered at length—all the chunks that make the content whole.
- Identifiers: Your entities’ unique IDs. These are how your entities are recorded and tracked in the database, rather than the more human-friendly name of your content type.

FIGURE 4.3
Data models show entities, attributes, identifiers, and how they connect to other data—or, in other words, content and how the pieces of that content come together.
In addition to thinking in these more rigid, defined terms about data, your technical team may also be thinking quite literally about what they’ll have to build to make the model a reality. For example, a Drupal developer might hear your description of a model and say, “No, we can’t do that. That goes against the way Drupal nodes work.” That may well be true. But what’s critical to your content isn’t how the back end works; it’s whether the desired effect can be achieved for both your CMS users and your audience. In other words, make sure your developers know you’re less interested in following the letter of your content model than respecting its spirit.
It’s also useful to walk your database developers through your model and talk about why you want your content to include the elements it does, so they understand what you’re trying to accomplish with each. When they understand the thinking behind your decisions, they’ll not only become stronger allies for your work, but will probably also suggest tweaks that make it easier to implement or are more in line with your CMS’s capabilities—without losing your desired results.
Authors and Workflows
A model is an ideal—a perfect example of what you’re attempting to create. In reality, future-friendly content requires not just databases and fields, but also humans: people who will consistently adhere to the model when adding and managing content.
Humans aren’t robots. They can be erratic, inconsistent, and emotional about their beloved content or defensive about their job descriptions. Which means a model doesn’t have a chance of surviving unless those humans—be they writers, editors, marketing managers, communications specialists, or multiple other folks tasked with content updates and additions—understand what the content model is trying to accomplish, and how it will make their content better.
Yet, too often, those folks have no idea what the database developers intended, how certain fields work, or why it matters. To improve both the relationship and the process, your job is to serve as the bridge: the person who can understand the needs and viewpoints of both sides and make a case for all parties to adopt some new practices in the name of better, more flexible content.
Making models that are visual, and that clearly show the interconnectedness and interdependencies of your content, is the first step. But to truly help your content authors succeed, you’ll also need to know a bit about the existing publishing process and how it’s working for them.
If you’re already involved in regular content creation and editing, you may be all too familiar with your current workflow (or lack of flow, as it may be). But for those often outside the day-to-day—like content strategists, information architects, UX designers, or any outside consultant—this analysis is a critical first step to addressing pain points and improving the author experience.
As you’re evaluating the existing process and considering how it could be improved, you should keep several things in mind:
- History: When was the CMS implemented and why? What were the goals, and who was involved in the process? Knowing the history can help you understand underlying reasons for why things are how they are now.
- Reviews and approvals: Who has to approve content before it goes live? How long does it take to get content from draft to publication? How much of the workflow happens inside the CMS, and how much outside of it?
- Complexity: What does it take to publish content now? What will it take if your content models are implemented? Must users go through multiple screens to do it? Can they see what the end result will look like? How much does maintenance cost the organization? Understanding how complicated the system is now can help you streamline it without sacrificing structure.
- Completeness: Are CMS users filling out templates fully or leaving fields blank? If so, why? Are they confused, rushed, or simply unconvinced of the value of those fields? If templates are routinely incomplete, systems and logic will break down. Best to find out why—and how much it’s costing your organization or affecting your users—now.
- Consistency: Are CMS users entering content without regard for consistency? Do multiple authors do things differently? Are they using WYSIWYG editors to override style settings, such as changing font colors and sizes? These issues point to a lack of training, but might also be due to an existing model that doesn’t have what they need—so people just make it up as they go. If you can understand why they’re doing it, you can determine whether you need to address the tool, the people using it, or both.
- Training programs: Who teaches people to use the CMS—technical teams or content-focused professionals? Do training materials talk about the content itself or just the tool? Are they written in jargon or plain language? Do they speak to how publishing content according to the guidelines supports communication and content goals? If training materials focus on features rather than processes and results, they’re likely a problem.
You may always have less-than-perfect tools and people who are less than perfect at using them. But if you can be the bridge between technical teams and content managers—explain to both how the other operates, and help both get what they need—you can go a long way toward easing the CMS pain. You’ll also be able to determine if the content model you’re recommending is unrealistically complex for your team’s workload, skill set, and priorities—and either make the case for getting them more training and resources, simplify your model, or take a staged approach.
After all, ideals are great. But the best content model is the one that actually gets used.
Content Modeling at Work
A model may be an ideal, but we can’t afford to be only idealistic. Things get messy online. Unless you’re working on a brand-new presence for a brand-new company, odds are slim you’re modeling content from scratch. Instead, nearly all of us must, to some extent, work with what we have: legacy content, legacy systems, and legacy workflows.
If you are implementing—or even better, considering options for—a new content management system, you’re in luck. Now’s the right time to make the case for clearly modeled content. But if, like many of us, you’re improving your content’s future one little step at a time, take heart. You can still make improvements to how content is entered and stored. You just may not be able to tackle all your content types at once.
I had that experience with the Arizona Office of Tourism, which I mentioned in Chapter 1, “Framing the New Content Challenge.” While some content had been modeled when the new CMS—a customized, homegrown solution—was launched, much of the content was not (or didn’t have enough structure to make it useful).
While tackling every piece of content in AOT’s massive ecosystem wasn’t feasible at once, we were able to quickly implement a new content model for an expensive-to-produce, yet formerly underutilized, content type: their collection of feature articles.
TIP WHAT SHOULD YOU FIX FIRST?
If you can’t afford to restructure all your content, all at once, don’t worry: content strategy is here to help. Like we talked about in Chapter 3, content strategy defines the role content should play for your organization and your users. Once you’ve defined your content goals and figured out the resources you have to work with, it’s a lot easier to look at all your unstructured content types and decide which ones will make the most impact—and be the most feasible for your team to implement—and tackle those first.
Each month, AOT publishes a couple of these long-form features, which are written by serious writers—the kind of thing you might see in Sunset or Food & Wine. Detailing adventures across Arizona, like a tour of Frank Lloyd Wright homes in Scottsdale and Phoenix or a road trip through the Americana of old Route 66, the articles are designed to engage Arizona enthusiasts and add color and inspiration to the more practical content about attractions and accommodations.
Published monthly and promoted in AOT’s email newsletter, which reaches around 150,000 subscribers, these feature articles take substantial editorial effort to produce: a trade publisher develops a content calendar, hires the writers, works with them on story development and editing, fact-checks and copyedits each piece, and delivers the final versions to AOT.
With so much going into these stories, AOT wanted to get more out of them—much more than a one-time email blast. But because all those articles had originally been created as basic pages in the CMS, AOT’s digital marketing manager had to paste the new articles into a new page each month and WYSIWYG them into the format she wanted: bolding the author’s byline, manually linking city names to pages for those cities, and bulleting out businesses featured in the article at the end. The result (shown in Figure 4.4) was time-consuming, but it worked fine—if you never left that page.
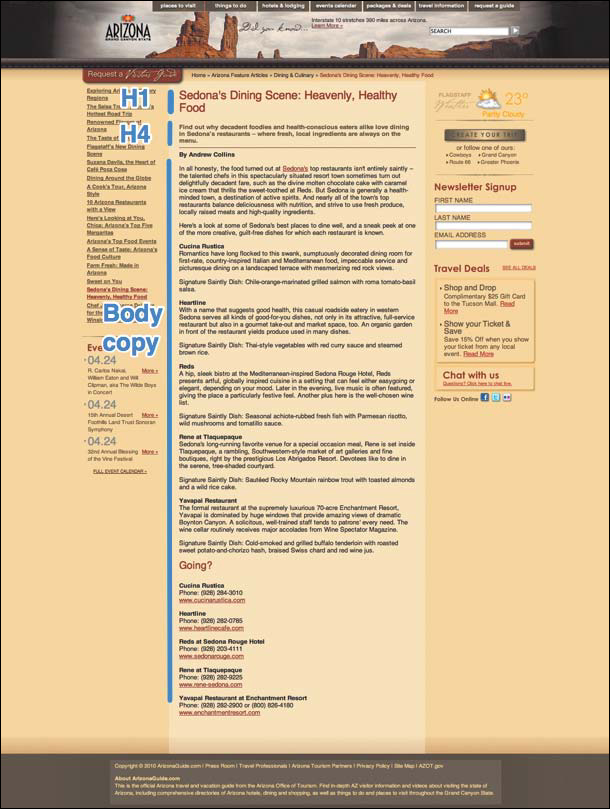
FIGURE 4.4
An example of the original feature articles, stored in unstructured, WYSIWYG-formatted pages.
But that’s where the content stopped.
Relating these features to other site content—like making articles about a city accessible from that city’s page—was challenging, manual, and rarely done. Those entering content didn’t know why they needed to tag items, and the process was finicky and prone to error. The result was that you could be reading up on Williams, Arizona—a charming town along old Route 66—and have no idea that someone had written a carefully crafted, richly detailed account of a road trip through this very place. And if you happened to like one writer’s work, forget about getting an archive of all his contributions to the site.
The problem was twofold. The content may have been engaging newsletter subscribers, but it wasn’t connecting them with other information and driving them deeper. Worse, these articles were only reaching subscribers who had already demonstrated a commitment to the state—not the site’s top (and much larger) audience: people just considering a trip to Arizona.
Moreover, AOT had bigger plans for this content. They had started sharing fresh articles on Facebook and running sidebars of older “related stories” in their newsletter, and those efforts required even more time to organize and manually publish.
To wrangle this content type into a shape fit for AOT’s future, I took on the task of breaking these articles down to their elements. At first glance, they appeared minimal: a title, an author, and a big block of text, with images inserted in-line in the WYSIWYG. But looking more closely at what the articles communicated, as we talked about in Chapter 3, I found each one really needed several more elements:
- Headline, which set the stage for the story, caught readers’ attention, and was critical to its overall meaning.
- Copy deck, which was a short intro blurb that played off the headline and provided an entry point to the story, employing engaging overviews and calls to action to drive readers onward.
- Author bylines, which lent credibility to the stories and demonstrated that they were more than marketing materials. This also, quite critically, served the state agency’s requirement of not favoring one business over another by using respected third-party journalists to make editorial statements. To allow users to easily find authors’ bios and see other stories by the same author, this element pulled from a separate database of author entries.
- Images, which provided visuals of distinctive landscapes, cultural attractions, and other only-in-Arizona elements—important for engaging prospective visitors from faraway places with the beauty of the American Southwest and adding depth to these detailed accounts.
- Cities, which provided geographic context for readers unfamiliar with all of Arizona’s attractions and served as a point of reference for trip planners. By relating the places featured in each story to their respective cities—which already had their own content type—we could make an at-a-glance list of city links, rather than manual text links.
- Businesses, like hotels and restaurants. These provided entry points into tangible places to go in Arizona, allowing prospective visitors to take steps toward booking their trips and contributing to the state’s tourism economy. Like cities, businesses already existed in their own database—and by tying them to articles within the content model, writers stopped adding their own listing information to the ends of articles, where it was unlikely to be maintained.
- Themes, like dining, the arts, or outdoors, which provided readers with a sense of the topic, and also correlated to the taxonomy already used in other content areas on the site.
Because visitors don’t come to arizonaguide.com specifically to read articles, it wasn’t enough for these features to live in a repository waiting for readers; they needed to come to users as they explored the more practical parts of the site, adding depth and texture to content about cities, regions, parks, and events.
Knowing this, I designed a content model using the elements outlined previously to migrate those articles out of a generic page and into a specific CMS template, as shown in Figure 4.5. From there, they can now be tagged to relevant cities, business listings, and categories of “things to do”—a taxonomical system used sitewide.
Today, the site uses these articles’ content elements to build business rules, which we’ll discuss in Chapter 5, “Designing Content Systems,” that dictate how and when they should appear as related content throughout the site. And the articles themselves (shown in Figure 4.6) are easier to skim, understand, and use as an entry point to other content—like local cities, landmarks, and businesses that all benefit from tourist interest.
But this content isn’t yet as useful as I’d like. State budgets being stagnant at best, arizonaguide.com is, as of this writing, primarily a desktop-oriented site. Its mobile site is limited to just a few features, and was built for free by a vendor that sells sponsored listings and other advertising.
Compromises and trade-offs like these are inevitable. Every organization has limitations, be they budget, resources, legislation, digital savvy, or just plain old fear. That’s OK. Today, AOT’s content is smarter than it was before—and when the time and budget for a flexible, device-agnostic site are available, all those feature articles and other types of content will be ready for the party.
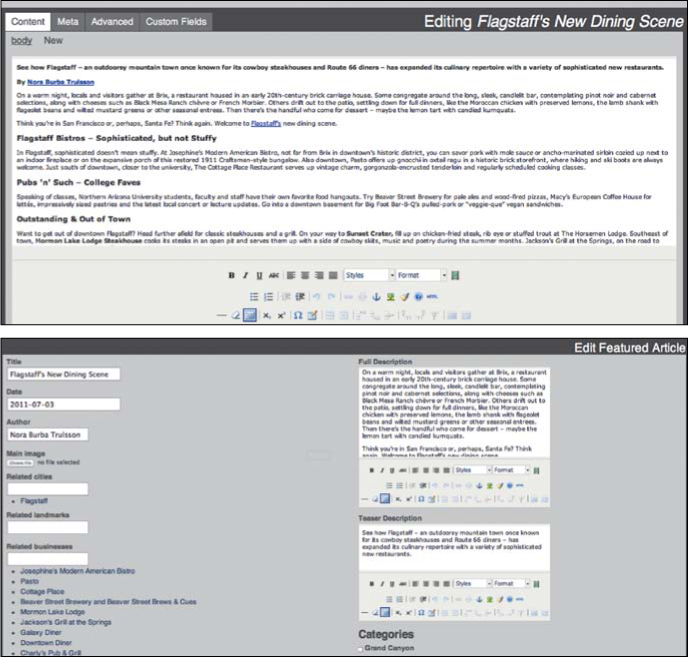
FIGURE 4.5
The articles’ CMS template, before and after. Note how that vast, wide-open text box from the old design is now broken into multiple parts.
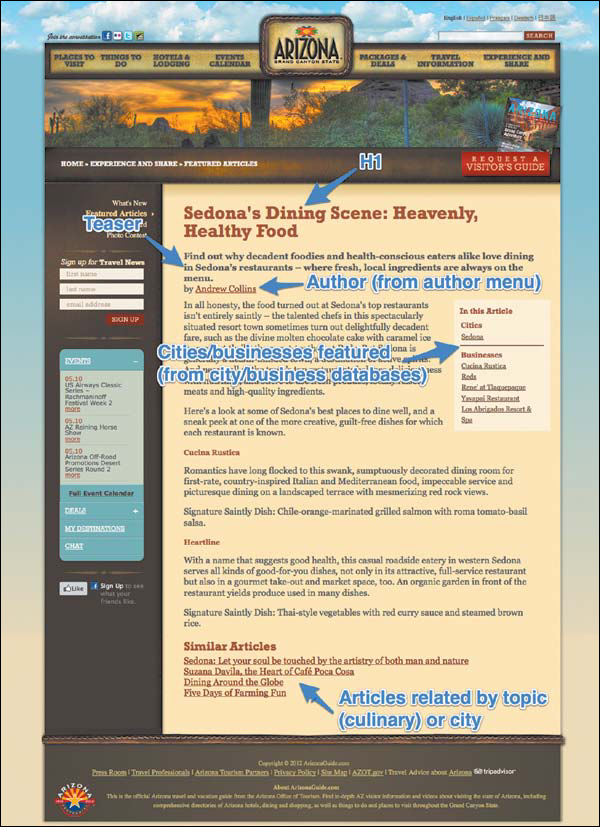
FIGURE 4.6
Detailed, informative, and written by expert travel writers, these editorially driven articles complement the Arizona Office of Tourism’s more practical content perfectly—now that users can find them and use them to access other important information, like city pages and business listings.
Turning Models into Ecosystems
Content modeling is complex work, but you already have enough expertise to get started. In this chapter, we’ve covered the basics for evaluating the elements you need to include, aligning them with your team, and documenting them for the world. These are things you can start doing now—even just with one critical content type. After all, some structure is often better than none.
Lending shape and structure to your information are great, but the real benefit will be when you can create a content ecosystem where all your content types work together—and your content models won’t truly be finished until you do. In Chapter 5, “Designing Content Systems,” we’ll talk about doing this by building business rules for content—rules that dictate how your content shifts, reshapes, relates, and appears (or doesn’t) as it is presented across displays and devices. With this, you can move on from how your content is entered and, in Chapters 6, “Understanding Markup,” and 7, “Making Sense of Content APIs,” understand how it will be stored and transported wherever and whenever you need it.