
Window System and Platform Integration
The OpenGL API is primarily concerned with accepting procedural scene descriptions and generating pixels corresponding to those descriptions. The OpenGL specification per se doesn’t say where the generated pixels will end up. The final step of sending pixels to their target, such as a window on the screen, is left up to the embedding or platform layer. This layer defines how the OpenGL renderer attaches or binds onto the output device or devices. There can be many possible window system targets; defining this interface is the task of the window system, not the OpenGL rendering pipeline. Most window systems have a specification that defines the OpenGL interaction. Some of these specifications, like the OpenGL specification itself, include an extension mechanism; the specification can evolve over time to reflect the evolution of the underlying window system. Here are embeddings of three of the most popular windows systems: the X Window System embedding (Scheifler and Gettys, 1986), called GLX (Womaeck and Leech, 1998); the embedding into the Win32 API (Microsoft, Inc., 2001b) used by Microsoft’s Windows family of operating systems, called WGL (Microsoft, Inc., 2001a) (pronounced wiggle); and the embedding connecting Apple’s Macintosh operating system (MacOS) called AGL (Apple Computer, Inc., 2001). The OpenGL ES project (see Section 8.3) also includes a more portable window system embedding layer called EGL (Leech, 2003).
Of course, OpenGL isn’t limited to, or required to work with a window system. It can just as readily render to a printer, a full screen video game console, or a linear array of memory in an application’s address space. Despite this flexibility, most of our discussions will assume the presence of the most common target, a window system. In particular, terms such as window space (described in Section 2.2.5), imply a window system environment.
This chapter limits itself to describing aspects of window system embedding as useful background for later chapters of the book. For more detailed information regarding using GLX on UNIX systems and WGL on Windows systems, see the texts by Kilgard (1996) and Fosner (1996).
7.1 Renderer and Window State
Since OpenGL is concerned with rendering and not display, we should clarify the roles of the renderer and the window system. An application using OpenGL needs to maintain a bundle of OpenGL state, including the current color, normal, texture coordinate, modelview matrix stack, projection matrix stack, and so forth. This collection of state describes everything needed by an OpenGL renderer to convert a set of input primitives into a set of output pixels. This collection of state is termed renderer state. The precise definition and scope of OpenGL renderer state is described in the OpenGL specification. The contents of the framebuffer (color, depth, stencil, and accumulation buffers), however, are not part of the renderer state. They are part of the window state. While renderer state is governed by the OpenGL renderer, window state is controlled by the window system. Ultimately, window state includes the position and size of the buffers on the display, mapping which bits correspond to the OpenGL front and back buffer, color maps for pseudo-color (color index) windows, gamma lookup tables that correct intensity levels driving output displays, and so on.
The OpenGL renderer state is encapsulated by a context. The data types and methods for creating a context are specific to a particular window system embedding, for example, glxCreateContext for GLX or wglCreateContext for WGL. To render to a window, the context must be bound to that window using a method specific to the window system binding API. This binding notion is not limited to attaching the OpenGL context to a window; it also attaches the context to an application process or thread (Figure 7.1). The exact details of a process or thread are specific to the platform (for example, Windows or Unix). Application calls to OpenGL API methods modify the contents of the current bound context and ultimately the current bound window.
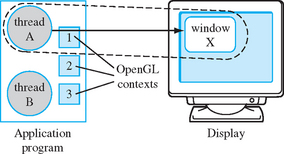
This notion of binding a context to a thread is arguably a little unusual from an API standpoint. One alternative is to pass a handle to the context to be updated as a parameter to the API method. A C++ or Java API might define OpenGL operations as methods of an OpenGL context object, making the context parameter implicit. The downside of this approach is the extra overhead needed to call indirectly through a handle to update the specified context. In the more stateful binding model, resolving information about the target context is done once when the context is bound. There is less overhead involved at the cost of some additional complexity. The OpenGL designers considered the performance savings to be worth the complexity trade-off.
Most applications need only a single OpenGL context to do all of their rendering. The requirements for multiple contexts depend on the window system embedding. As a general rule, a window needs a separate context if it is in a different stacking layer or using a pixel format sufficiently different from the other OpenGL windows. This requirement reduces the complexity of an OpenGL implementation and ensures sensible behavior for the renderer state when it is moved from one window to another. Allowing a context to be moved from an RGB window to a color index window presents numerous problems, since the state representations for each of the context types is quite different. It makes more sense to require each window to have a separate context.
7.2 Address Space and Threads
The embedding layer is platform-specific beyond the details of the window system. Data transfers to and from the OpenGL pipeline rely on the (conventional) notion of a process and an address space. When memory addresses are used in OpenGL commands they refer to the address space of the application process. Most OpenGL platform embeddings also support the concept of a thread. A thread is an execution context (a thread of execution) and a process may have multiple threads executing within it. The threads share the process’s address space. The OpenGL embedding layer supports the notion of multiple thread-context-window triplets being current (active) simultaneously. However, a context cannot be used with (current to) multiple threads concurrently. Conversely in the GLX embedding, a window can be current to multiple thread-context pairs concurrently, though this seldom provides real utility unless there are multiple accelerators present in the system. In practice, the most useful multi-thread and multi-context scenarios involve using a single thread for rendering and other threads for non-rendering tasks. Usually, it only makes sense to use multiple rendering threads to render to different accelerators in parallel.
7.3 Anatomy of a Window
In its simplest form a window is a rectangular region on a display,1 described by an origin and a size. From the rendering perspective, the window has additional attributes that describe its framebuffer, color index vs. RGB, number of bits per-pixel, depth buffer size, accumulation buffer size, number of color buffers (single buffered or double buffered), and so forth. When the OpenGL context is bound to the window, these attributes are used by the OpenGL renderer to determine how to render to it correctly.
7.3.1 Overlay and Underlay Windows
Some window systems include the concept of an overlay window. An overlay window always lies on top of non-overlay windows, giving the contents of the overlay window visual priority over the others. In some window systems, notably the X Window System, the overlay window may be opaque or transparent. If the overlay window is opaque, then all pixels in the overlay window have priority over pixels in windows logically underneath the overlay window (below it in the window stacking order). Transparent overlay windows have the property of controlling the visual priority of a pixel using the overlay pixel’s color value. Therefore, pixels assigned a special transparent color have lower priority, so the pixel of the window logically underneath this window can be visible.
Overlay windows are useful for implementing popup menus and other graphical user interface components. They can also be useful for overlaying other types of annotations onto a rendered scene. The principal advantage of using an overlay window rather than drawing directly into the main window is that the two windows can be updated independently—to change window annotations requires redrawing only the overlay window. This assumes that overlay window independence is really implemented by the window system and display hardware, and not simulated.2 Overlays become particularly useful if the contents of the main window are expensive to regenerate. Overlay windows are often used to display data decoded from a multimedia video source on top of other windows with the hardware accelerator decoding the stream directly to a separate overlay framebuffer.
Similar to the concept of overlays, there is the analogous concept of an underlay window with the lowest visual priority. Such a window is only useful when the windows logically above it contain transparent pixels. In general, the need for underlay windows has been minimal; there are few OpenGL implementations that support them.
7.3.2 Multiple Displays
Some operating system/window system combinations can support multiple displays. Some configure multiple displays to share the same accelerator or, in the more general case, multiple accelerators each drive multiple displays. In both cases the details of attaching and using a context with windows on different displays becomes more complicated, and depends on window system embedding details.
Figure 7.2 shows an example of a three-display system in which two of the displays are driven from one graphics accelerator, while a third display is driven from a second accelerator. To use all of the available displays typically involves the use of multiple OpenGL contexts. Since an OpenGL context encapsulates the renderer state, and this state may be contained inside hardware, it follows that each hardware accelerator needs an independent context. If the two accelerators were built by different vendors, they would likely use two different OpenGL implementations. A well-designed operating system/window system embedding layer can allow both accelerators to be used from a single application by creating a context corresponding to each accelerator/display combination. For example, in a GLX-based system, the accelerator is identified by its DISPLAY name; an application can create GLX contexts corresponding to the individual DISPLAY names.
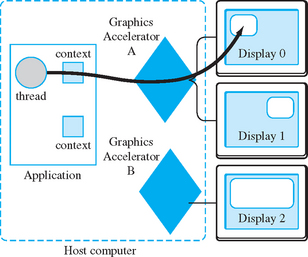
Multiple display systems go by many different names (multimon, dual-head, Twin-View are examples) but all are trying to achieve the same end. They all drive multiple displays, monitors, or video channels from the same accelerator card. The simplest configuration provides a large logical framebuffer from which individual rectangular video or display channels are carved out (as shown in Figure 7.3). This is similar to the way windows are allocated from a framebuffer on a single display. The amount of framebuffer memory used by each channel depends on the resolution of the channel and the pixel formats supported in each channel.
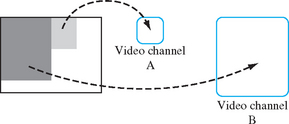
7.4 Off-Screen Rendering
As mentioned previously, an OpenGL renderer isn’t limited to rendering to a window or a video output display device; it can render to any device that implements some sort of framebuffer storage. One technique that has gained popularity is rendering to accelerated framebuffer memory that isn’t visible as part of the display. For example, in Figure 7.3 a third of the framebuffer memory isn’t allocated as part of a visible video channel, but could be useful for generating intermediate images used to construct a more complicated final image. The back buffer in a double-buffered window can also be used for intermediate storage, but the application is limited to a single back buffer, and the buffer contents cannot persist across multiple frames. The OpenGL specification includes the notion of auxiliary buffers (or auxbufs) that serve as additional persistent color buffers, but they suffer from a number of limitations. Auxilliary buffers are the same dimensions as the main color buffer, and they don’t provide a way to save the depth buffer. The concept of more general off-screen windows overcomes many of these limitations.
Off-screen windows introduce their own problems, however. The first is how to move data from an off-screen window to some place useful. Assuming that the off-screen image is intended for use as a rendering step in an on-screen window, a mechanism is needed to allow an OpenGL context to use the off-screen window in conjunction with an on-screen window. The mechanism chosen to do this is to separate a window into two components: a read window and a write window. In most situations the read and write window are one and the same, but when it’s necessary to retrieve data from another window, the source window is bound to the OpenGL context as a read window—all OpenGL read-related operations (glReadPixels, glCopyPixels, and glCopyTexture) use the read window as the read source. Note that the read window does not change the window used for pixel-level framebuffer read operations, such as blending, depth test, stencil, or accumulation buffer returns. Figure 7.4 illustrates a thread-context pair with a separate off-screen read source and a visible write window. The accelerator memory is divided between framebuffers for two displays and a third partition for off-screen surfaces.
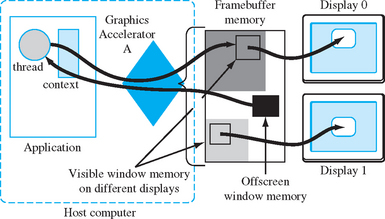
To use an off-screen window as part of a complex rendering algorithm, the application renders the relevant parts of the scene to the off-screen window, then binds the context to both the visible window and the off-screen window. The off-screen window is bound as a read source, while the visible window is bound as a write source. Then the application performs a pixel copy operation to merge the off-screen buffer contents with the on-screen contents.
The second problem with using off-screen memory is managing the memory itself. In the case of visible windows, the windows are allowed to overlap. The end user can see where windows are being allocated and directly manage the “screen real-estate.” For off-screen memory, the end user has no idea how much memory is available, the “shape” of the memory, and whether there are implementation-specific constraints on how the memory can be allocated. If the framebuffer memory can’t be treated as a one dimensional array of bytes—this restriction is often true with sophisticated hardware accelerators—the memory allocation and management problem becomes substantially more complicated. In Figure 7.3 the off-screen part of framebuffer memory has an irregular shape that may affect the maximum allowed dimensions of an off-screen window. If multiple off-screen memory allocation requests are made, the outcome of the requests may depend on their order. The window system embedding layer attempts to provide a 90% solution to this problem as simply as possible, but doesn’t provide guarantees.
7.4.1 GLX Pbuffers
GLX provides support for rendering to off-screen memory as X Window System pixmaps. However, X pixmaps are a little too general and don’t provide all of the necessary functionality needed for efficient rendering. In fact, no known GLX+OpenGL implementation supports accelerated rendering to pixmaps. To address the need for efficient off-screen rendering, a form of off-screen drawable specifically for OpenGL rendering was added to GLX 1.3. GLX calls these off-screen drawables pbuffers—short for pixel buffers.
To support the addition of pbuffers, substantial additions were made to the GLX 1.3 API. These changes separate the description of the framebuffer (bits per color component, depth buffer size, etc.) from the X Window System’s visual concept; instead, identifying a framebuffer configuration description as an FBConfig rather than a visual. The end result is that the original API using visuals can be layered on the new API using FBConfigs by internally associating an FBConfig with each visual. This new API operates on the three types of drawables: windows, pixmaps, and pbuffers. Windows and pixmaps are created using X Window System commands, while pbuffers are created with a GLX-specific API.
The pbuffer creation command, glxCreatePbuffer, includes some additional attributes that help with off-screen memory management. In addition to requesting a pbuffer of specific dimension be created, the application can also specify that if that request fails, a pbuffer of the largest available size should be allocated. This provides a means of discovering the largest available pbuffer. The discovery routine also allocates the pbuffer to avoid race conditions with other applications. The created pbuffer also includes an attribute specifying whether the pbuffer is volatile; that is, whether the pbuffer contents should be preserved. If the contents need not be preserved, then they may be damaged by rendering operations on other drawables, in much the same way that the contents of one window may be damaged by rendering to another overlapping window. When this happens, the application can be notified by registering for GLX-specific buffer clobber events. The idea is to provide a choice to application writers; if the contents of a pbuffer can be regenerated easily or are transient, then volatile pbuffers are the best solution. If the pbuffer contents cannot be easily regenerated, then the application can use a non-volatile pbuffer and the system will save and restore the pbuffer contents when the resources are needed by another drawable. Of course, the save and restore operations may slow the application, so non-volatile pbuffers should only be used when absolutely necessary.
7.5 Rendering to Texture Maps
In many OpenGL implementations the storage for texture maps and the framebuffer comes from the same physical pool of memory. Since they are in the same memory, it suggests the opportunity to improve the efficiency of using the framebuffer contents as a texture map (see Section 5.3) without copying the data from the framebuffer to the texture map. The ARB_render_texture WGL extension provides a means to do this using pbuffers.
An application using the extension creates a pbuffer, binds it to the context using wglMakeCurrent, renders to it, then unbinds from it. Next, the application binds to a new drawable and uses the extension command wglBindTexImageARB to bind the pbuffer to the current texture. In an optimized implementation, subsequent texture-mapped geometry will retrieve texel data directly from the pbuffer. The extension can still be implemented on pipeline implementations that don’t share texture and framebuffer storage by simply copying the data from the pbuffer to the texture map. The latter implementation is no worse than the application calling glCopyTexture directly, and on implementations that share storage it is considerably more efficient. After using the pbuffer as a texture, it is unbound from the texture (using wglReleaseTexImageARB) and can again be used for rendering. The extension does not allow a pbuffer to be used simultaneously for rendering and texturing since this can have unpredictable implementation-specific behavior.
7.6 Direct and Indirect Rendering
Another factor that arises in a discussion of both the window system embedding and the host operating system is the notion of direct and indirect rendering. For X Window System embedding, these notions have a very precise meaning. Indirect rendering means that each OpenGL command issued by a client application is encoded in the X11 protocol, as defined by the GLX extension. The encoded stream is then decoded by the server and sent to an OpenGL renderer. The advantage of indirect rendering is that it allows OpenGL rendering to be used by any client that implements the client side of the GLX protocol encoder. It can send rendering commands over a network to a remote server and execute the rendering operations and display the results on the remote server. The disadvantage is that the protocol encoding and decoding consumes extra processing and memory resources that can limit the achievable performance. If both the client and server are both on the same computer, then a more efficient mechanism to issue commands to the hardware can be used—direct rendering.
GLX doesn’t specify a protocol for direct rendering; instead, it specifies a set of ground rules that allow vendors some flexibility in doing their implementations, while retaining indirect rendering compatibility. In a high-performance direct rendering implementation, once a context/window pair has been made current, the application issues commands directly to the hardware mapped into the address space of the application. There is no need to buffer commands or interact with device drivers or the operating system kernel layer. The details for one such implementation are available in Graphics Interface ’95 by Kilgard et al. (1995).
In other embeddings the notion of direct and indirect rendering is more vague. The Windows platform does not provide native support for remote rendering, so it can be said to only support direct rendering. However, mechanisms used to achieve direct rendering may be radically different from those used on UNIX platforms.