
Reading Free-Format Data with Non-Blank Delimiters and Missing Values
Working with Delimiters
Most free-format data fields are clearly
separated by blanks and are easy to imagine as variables and observations.
But fields can also be separated by other delimiters, such as commas,
as shown below.
Figure 18.10 Raw Data File with Comma Delimiters

When characters other than blanks are used to separate
the data values, you can tell SAS which field delimiter to use. Use
the DLM= option in the INFILE statement to specify a delimiter other
than a blank (the default).
|
Syntax, DLM= option:
DLM=delimiter(s)
|
Example: DLM = Option
The following program
creates the output shown below.
data sasuser.creditsurvey;
infile cccomma dlm=',';
input Gender $ Age Bankcard FreqBank
Deptcard FreqDept;
run;
proc print data=sasuser.creditsurvey;
run;Figure 18.11 Output from the DLM= Option

Note: The field delimiter must
not be a character that occurs in a data value. For example, the following
raw data file contains values for LastName and Salary. Notice that
the values for Salary contain commas.
Figure 18.12 Raw Data File with Commas in Values

If the field delimiter
is also a comma, the fields are identified incorrectly, as shown below.
Figure 18.13 Raw Data File with Incorrect Use of Commas

Figure 18.14 Output When Commas Are Used Incorrectly

Reading Values That Contain Delimiters within a Quoted String
You can also use the DSD option in an INFILE statement
to read values that contain delimiters within a quoted string. As
shown in the following PROC PRINT output, the INPUT statement correctly
interprets the commas within the values for Salary, does not interpret
them as delimiters, and removes the quotation marks from the character
strings before the value is stored.
data work.finance2;
filename find 'c:datafindat2';
infile find dsd;
length SSN $ 11 Name $ 9;
input ssn name Salary : comma. Date : date9.;
run;
proc print data=work.finance2;
format date date9.;
run;Figure 18.15 Raw Data File Findat2

Figure 18.16 Output Created with PROC PRINT

Reading Missing Values at the End of a Record
Suppose that the third person
who is represented in the raw data file below did not answer the questions
about how many department store credit cards she has and about how
often she uses them.
Figure 18.17 Raw Data File with Missing Values at the End of a Record

The missing values occur
at the end of the record. Therefore, you can use the MISSOVER option
in the INFILE statement to assign the missing values to variables
with missing data at the end of a record. The MISSOVER option prevents
SAS from reading the next record if, when you are using list input,
it does not find values in the current line for all the INPUT statement
variables. At the end of the current record, values that are expected,
but not found, are set to missing.
For the raw data file
shown above, the MISSOVER option prevents the fields in the fourth
record from being read as values for Deptcard and FreqDept in the
third observation. Note that values for Deptcard and FreqDept are
set to missing.
data sasuser.creditsurvey;
infile creditcr missover;
input Gender $ Age Bankcard FreqBank
Deptcard FreqDept;
run;
proc print data=sasuser.creditsurvey;
run;Figure 18.18 Output Showing Missing Values

Note: The MISSOVER option works
only for missing values that occur at the end of the record.
Reading Missing Values at the Beginning or Middle of a Record
Remember that
the MISSOVER option works only for missing values that occur at the
end of the record. A different method is required when you use list
input to read raw data that contains missing values at the beginning
or middle of a record. In this example, see what happens when a missing
value occurs at the beginning or middle of a record.
Suppose the value for
Age is missing in the first record.
Figure 18.19 Raw Data File with Missing Values at the Beginning or Middle
of a Record

When the program below
executes, each field in the raw data file is read one by one. The
INPUT statement tells SAS to read six data values from each record.
However, the first record contains only five values.
data sasuser.creditsurvey;
infile credit2 dlm=',';
input Gender $ Age Bankcard FreqBank
Deptcard FreqDept;
run;
proc print data=sasuser.creditsurvey;
run;The two commas in the
first record are interpreted as one delimiter. The incorrect value
1 is
read for Age. The program continues to read subsequent incorrect values
for Bankcard 8, FreqBank 0,
and Deptcard 0. The program then attempts
to read the character field FEMALE, at the beginning of the second
record, as the value for the numeric variable FreqDept. This causes
the value of FreqDept in the first observation to be interpreted as
missing. The input pointer then moves down to the third record to
begin reading values for the second observation. Therefore, the first
observation in the data set contains incorrect values, and values
from the second record in the raw data file are not included.
Figure 18.20 Output with Missing Data Records

You can use the Delimiter Sensitive Data (DSD) option
in the INFILE statement to correctly read the raw data. The DSD option
changes how SAS treats delimiters when list input is used. Specifically,
the DSD option does the following:
-
sets the default delimiter to a comma
-
treats two consecutive delimiters as a missing value
-
removes quotation marks from values
When the following program
reads the raw data file, the DSD option sets the default delimiter
to a comma and treats the two consecutive delimiters as a missing
value. Therefore, the data is read correctly.
data sasuser.creditsurvey;
infile credit2 dsd;
input Gender $ Age Bankcard FreqBank
Deptcard FreqDept;
run;
proc print data=sasuser.creditsurvey;
run;Figure 18.21 DSD Raw Data and Output

If the
data uses multiple delimiters or a single delimiter other than a comma,
simply specify the delimiter value or values with the DLM= option.
In the following example, an asterisk (*) is used as a delimiter.
However, the data is still read correctly because of the DSD option.
data sasuser.creditsurvey;
infile credit3 dsd dlm='*';
input Gender $ Age Bankcard FreqBank
Deptcard FreqDept;
run;
proc print data=sasuser.creditsurvey;
run;Figure 18.22 Raw Data with Multiple Delimiters and Output

The DSD option can also
be used to read raw data when there is a missing value at the beginning
of a record, as long as a delimiter precedes the first value in the
record.
data sasuser.creditsurvey;
infile credit4 dsd;
input Gender $ Age Bankcard FreqBank
Deptcard FreqDept;
run;
proc print data=sasuser.creditsurvey;
run;Figure 18.23 Raw Data with Missing Data and Output
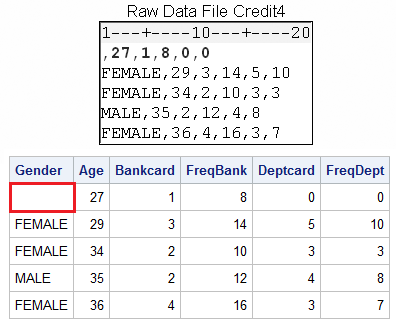
Because DSD uses a comma
as the delimiter, you can use DSD and DLM= to specify a different
delimiter. You can also use the DSD and DLM= options to read fields
that are delimited by blanks.
data sasuser.creditsurvey;
infile credit5.dat dsd dlm=' ';
input Gender $ Age Bankcard FreqBank
Deptcard FreqDept;
run;
proc print data=sasuser.creditsurvey;
run;Last updated: January 10, 2018
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.