
As we previously described, SVMs can be used to perform linear classification over two distinct classes. An SVM will attempt to find a hyperplane that separates the two classes such that the estimated hyperplane describes the maximum achievable margin of separation between the two classes in our model.
For example, an estimated hyperplane between two classes of data can be visualized using the following plot diagram:
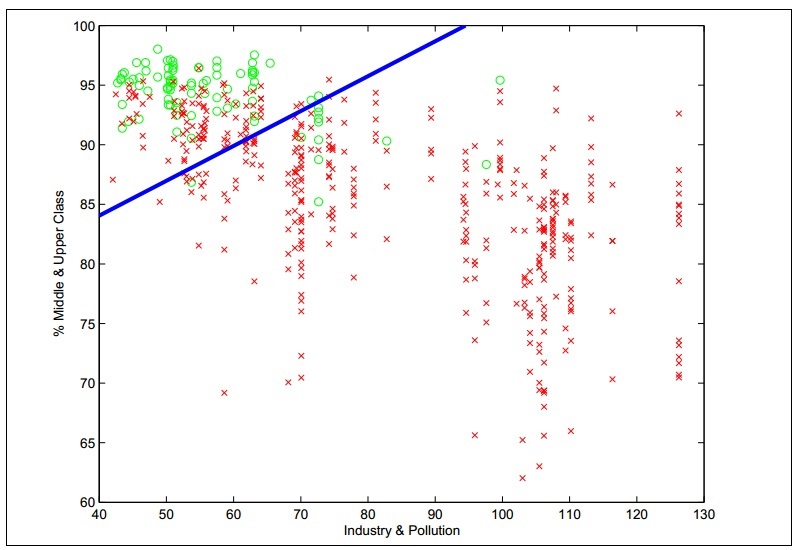
As depicted in the graph shown in the preceding plot diagram, the circles and crosses are used to represent the two classes of input values in the sample data. The line represents the estimated hyperplane of an SVM.
In practice, it's often more efficient to use an implemented SVM rather than implement our own SVM. There are several libraries that implement SVMs that have been ported to multiple programming languages. One such library is LibLinear (http://www.csie.ntu.edu.tw/~cjlin/liblinear/), which implements a linear classifier using an SVM. The Clojure wrapper for LibLinear is clj-liblinear (https://github.com/lynaghk/clj-liblinear) and we will now explore how we can use this library to easily build a linear classifier.
Note
The clj-liblinear library can be added to a Leiningen project by adding the following dependency to the project.clj file:
[clj-liblinear "0.1.0"]
For the example that will follow, the namespace declaration should look similar to the following declaration:
(ns my-namespace (:use [clj-liblinear.core :only [train predict]]))
Firstly, let's generate some training data, such that we have two classes of input values. For this example, we will model two input variables, as follows:
(def training-data
(concat
(repeatedly
500 #(hash-map :class 0
:data {:x (rand)
:y (rand)}))
(repeatedly
500 #(hash-map :class 1
:data {:x (- (rand))
:y (- (rand))}))))Using the repeatedly function as shown in the preceding code, we generate two sequences of maps. Each map in these two sequences contains the keys :class and :data. The value of the :class key represents the class of category of the input values and the value of the :data key is itself another map with the keys :x and :y. The values of the keys :x and :y represent the two input variables in our training data. These values for the input variables are randomly generated using the rand function. The training data is generated such that the class of a set of input values is 0 if both the input values are positive, and the class of a set of input values is 1 if both the input values are negative. As shown in the preceding code, a total of a 1,000 samples are generated for two classes as two sequences using the repeatedly function, and then combined into a single sequence using the concat function. We can inspect some of these input values in the REPL, as follows:
user> (first training-data)
{:class 0,
:data {:x 0.054125811753944264, :y 0.23575052637986382}}
user> (last training-data)
{:class 1,
:data {:x -0.8067872409710037, :y -0.6395480020409928}}We can create and train an SVM using the training data we've generated. To do this, we use the train function. The train function accepts two arguments, which include a sequence of input values and a sequence of output values. Both sequences are assumed to be in the same order. For the purpose of classification, the output variable can be set to the class of a given set of input values as shown in the following code:
(defn train-svm [] (train (map :data training-data) (map :class training-data)))
The train-svm function defined in the preceding code will instantiate and train an SVM with the training-data sequence. Now, we can use the trained SVM to perform classification using the predict function, as shown in the following code:
user> (def svm (train-svm))
#'user/svm
user> (predict svm {:x 0.5 :y 0.5})
0.0
user> (predict svm {:x -0.5 :y 0.5})
0.0
user> (predict svm {:x -0.4 :y 0.4})
0.0
user> (predict svm {:x -0.4 :y -0.4})
1.0
user> (predict svm {:x 0.5 :y -0.5})
1.0The predict function requires two parameters, which are an instance of an SVM and a set of input values.
As shown in the preceding code, we use the svm variable to represent a trained SVM. We then pass the svm variable to the predict function, along with a new set of input values whose class we intend to predict. It's observed that the output of the predict function agrees with the training data. Interestingly, the classifier predicts the class of any set of input values as 0 as long as the input value :y is positive, and conversely the class of a set of input values whose :y feature is negative is predicted as 1.
In the previous example, we used an SVM to perform classification. However, the output variable of the trained SVM was always a number. Thus, we could also use the clj-liblinear library in the same way as described in the preceding code to train a regression model.
The clj-liblinear library also supports more complex types for the features of an SVM, such as vectors, maps, and sets. We will now demonstrate how we can train a classifier that uses sets as input variables, instead of plain numbers as shown in the previous example. Suppose we have a stream of tweets from a given user's Twitter feed. Assume that the user will manually classify these tweets into a specific category, which is selected from a set of predefined categories. This processed sequence of tweets can be represented as follows:
(def tweets
[{:class 0 :text "new lisp project released"}
{:class 0 :text "try out this emacs package for common lisp"}
{:class 0 :text "a tutorial on guile scheme"}
{:class 1 :text "update in javascript library"}
{:class 1 :text "node.js packages are now supported"}
{:class 1 :text "check out this jquery plugin"}
{:class 2 :text "linux kernel news"}
{:class 2 :text "unix man pages"}
{:class 2 :text "more about linux software"}])The tweets vector defined in the preceding code contains several maps, each of which have the keys :class and :text. The :text key contains the text of a tweet, and we will train an SVM using the value contained by the :text keyword. But we can't use the text in verbatim, since some words might be repeated in a tweet. Also, we need some way of dealing with the case of the letters in this text. Let's define a function to convert this text into a set as follows:
(defn extract-words [text]
(->> #" "
(split text)
(map lower-case)
(into #{})))The extract-words function defined in the preceding code will convert any string, represented by the parameter text, into a set of words that are all in lower case. To create a set, we use the (into #{}) form. By definition, this set will not contain any duplicate values. Note the use of the ->> threading macro in the definition of the extract-words function.
We can inspect the behavior of the extract-words function in the REPL, as follows:
user> (extract-words "Some text to extract some words")
#{"extract" "words" "text" "some" "to"}Using the extract-words function, we can effectively train an SVM with a set of strings as a feature variable. As we mentioned earlier, this can be done using the train function, as follows:
(defn train-svm []
(train (->> tweets
(map :text)
(map extract-words))
(map :class tweets)))The train-svm function defined in the preceding code will create and train an SVM with the processed training data in the tweets variable using the train and extract-words functions. We now need to compose the predict and extract-words functions in the following code so that we can predict the class of a given tweet:
(defn predict-svm [svm text]
(predict
svm (extract-words text)))The predict-svm function defined in the preceding code can be used to classify a given tweet. We can verify the predicted classes of the SVM for some arbitrary tweets in the REPL, as follows:
user> (def svm (train-svm)) #'user/svm user> (predict-svm svm "a common lisp tutorial") 0.0 user> (predict-svm svm "new javascript library") 1.0 user> (predict-svm svm "new linux kernel update") 2.0
In conclusion, the clj-liblinear library allows us to easily build and train an SVM with most Clojure data types. The only restriction that is imposed by this library is that the training data must be linearly separable into the classes of our model. We will study how we can build more complex classifiers in the following sections of this chapter.