
In this chapter, we will explore a few methodologies for handling large volumes of data to train machine learning models. In the latter section of this chapter, we will also demonstrate how to use cloud-based services for machine learning.
A data-processing methodology that is often encountered in the context of data parallelism is MapReduce. This technique is inspired by the map and reduce functions from functional programming. Although these functions serve as a basis to understand the algorithm, actual implementations of MapReduce focus more on scaling and distributing the processing of data. There are currently several active implementations of MapReduce, such as Apache Hadoop and Google Bigtable.
A MapReduce engine or program is composed of a function that performs some processing over a given record in a potentially large dataset (for more information, refer to "Map-Reduce for Machine Learning on Multicore"). This function represents the Map() step of the algorithm. This function is applied to all the records in the dataset and the results are then combined. The latter step of extracting the results is termed as the Reduce() step of the algorithm. In order to scale this process over huge datasets, the input data provided to the Map() step is first partitioned and then processed on different computing nodes. These nodes may or may not be on separate machines, but the processing performed by a given node is independent from that of the other nodes in the system.
Some systems follow a different design in which the code or query is sent to nodes that contain the data, instead of the other way around. This step of partitioning the input data and then forwarding the query or data to different nodes is called the Partition() step of the algorithm. To summarize, this method of handling a large dataset is quite different from traditional methods of iterating over the entire data as fast as possible.
MapReduce scales better than other methods because the partitions of the input data can be processed independently on physically different machines and then combined later. This gain in scalability is not only because the input is divided among several nodes, but because of an intrinsic reduction in complexity. An NP-hard problem cannot be solved for a large problem space, but can be solved if the problem space is smaller.
For problems with an algorithmic complexity of ![]() or
or ![]() , partitioning the problem space will actually increase the time needed to solve the given problem. However, if the algorithmic complexity is
, partitioning the problem space will actually increase the time needed to solve the given problem. However, if the algorithmic complexity is ![]() , where
, where ![]() , partitioning the problem space will reduce the time needed to solve the problem. In case of NP-hard problems,
, partitioning the problem space will reduce the time needed to solve the problem. In case of NP-hard problems, ![]() . Thus, MapReduce decreases the time needed to solve NP-hard problems by partitioning the problem space (for more information, refer to Evaluating MapReduce for Multi-core and Multiprocessor Systems).
. Thus, MapReduce decreases the time needed to solve NP-hard problems by partitioning the problem space (for more information, refer to Evaluating MapReduce for Multi-core and Multiprocessor Systems).
The MapReduce algorithm can be illustrated using the following diagram:
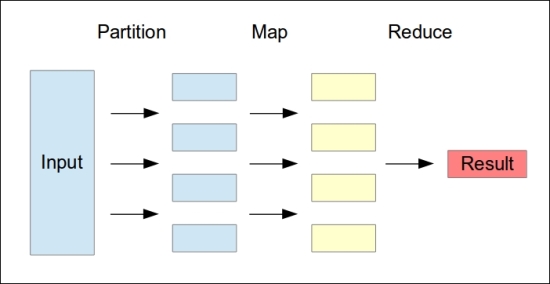
In the previous diagram, the input data is first partitioned, and each partition is independently processed in the Map() step. Finally, the results are combined in the Reduce() step.
We can concisely define the MapReduce algorithm in Clojure pseudo-code, as shown in the following code:
(defn map-reduce [f partition-size coll]
(->> coll
(partition-all partition-size) ; Partition
(pmap f) ; Parallel Map
(reduce concat))) ; ReduceThe map-reduce function defined in the previous code distributes the application of the function f among several processors (or threads) using the standard pmap (abbreviation for parallel map) function. The input data, represented by the collection coll, is first partitioned using the partition-all function, and the function f is then applied to each partition in parallel using the pmap function. The results of this Map() step are then combined using a composition of the standard reduce and concat functions. Note that this is possible in Clojure due to the fact the each partition of data is a sequence, and the pmap function will thus return a sequence of partitions that can be joined or concatenated into a single sequence to produce the result of the computation.
Of course, this is only a theoretical explanation of the core of the MapReduce algorithm. Actual implementations tend to focus more on distributing the processing among several machines, rather than among several processors or threads as shown in the map-reduce function defined in the previous code.