
The pom.xml configuration file will automatically run the test cases using <skipTests>false</skipTests> when doing Clean and Build Project (task-time-tracker) by clicking on the toolbar icon:
It is also possible to only run the testing phase of the project by navigating to Run | Test Project (task-time-tracker):
The results of the testing process can now be examined in the Output – task-time-tracker panel. Note that you may need to dock the output panel to the bottom of the IDE if it is minimized, as shown in the following screenshot (the minimized panel is usually in the bottom-left corner of the NetBeans IDE). The [surefire:test] plugin output is displayed at the start of the testing process. There are many lines of output for configuring Spring, connecting to the database, and loading the persistence context:
We will examine the key testing output in detail soon. Scroll through the output until you reach the end of the test section:
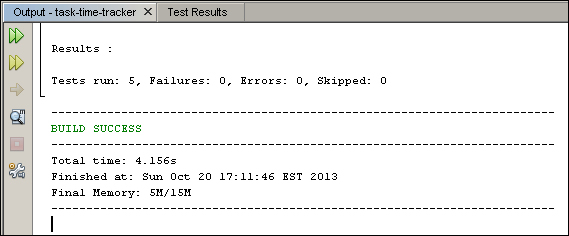
There were five tests executed in total with no errors—a great start!
You can execute a single test case file by right-clicking on the file displayed in the editor and selecting the Test File option:
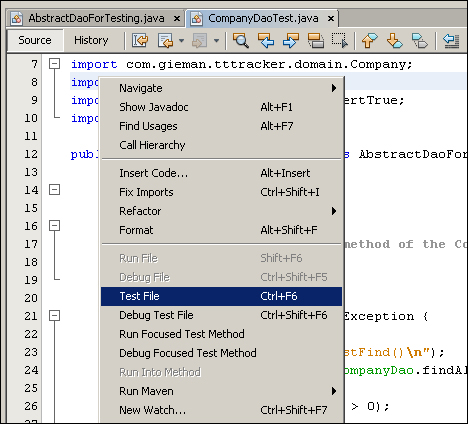
This will execute the file's test cases, producing the same testing output as shown previously, and present you with the results in the Test Results panel. This panel should appear under the file editor but may not be docked (it may be floating at the bottom of the NetBeans IDE; you can change the position and docking as required). The individual file testing results can then be examined:
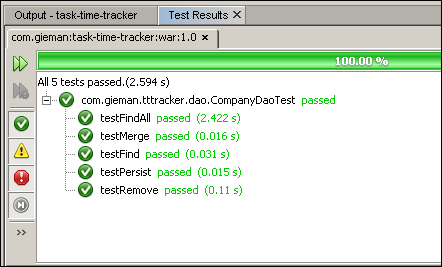
Single test file execution is a practical and quick way of debugging and developing code. We will continue to execute and examine single files during the rest of the chapter.
Let's now examine the results of each test case in detail.
The output for this test case is:
STARTED testMerge() SELECT id_company, company_name FROM ttt_company ORDER BY company_name ASC FINISHED testMerge()
A merge call is used to update a persistent entity. The testMerge method is very simple:
final String NEW_NAME = "Merge Test Company New Name"; Company c = companyDao.findAll().get(0); c.setCompanyName(NEW_NAME); c = companyDao.merge(c); assertTrue(c.getCompanyName().equals(NEW_NAME));
We find the first Company entity (the first item in the list returned by findAll) and then update the name of the company to the NEW_NAME value. The companyDao.merge call then updates the Company entity state in the persistence context. This is tested using the assertTrue() test.
Note that the testing output only has one SQL statement:
SELECT id_company, company_name FROM ttt_company ORDER BY company_name ASC
This output corresponds to the findAll method call. Note that there is no SQL update statement executed! This may seem strange because the entity manager's merge call should result in an update statement being issued against the database. However, the JPA implementation is not required to execute such statements immediately and may cache statements when possible, for performance and optimization purposes. The cached (or queued) statements are then executed only when an explicit commit is called. In our example, Spring executes a rollback immediately after the testMerge method returns (remember, we are running transactional test cases thanks to our AbstractTransactionalJUnit4SpringContextTests extension), and hence the persistence context never needs to execute the update statement.
We can force a flush to the database by making a slight change to the GenericDaoImpl class:
@Override
@Transactional(readOnly = false, propagation = Propagation.REQUIRED)
public T merge(T o) {
o = em.merge(o);
em.flush();
return o;
}The em.flush() method results in an immediate update statement being executed; the entity manager is flushed with all pending changes. Changing this code in the GenericDaoImpl class and executing the test case again will result in the following testing output:
SELECT id_company, company_name FROM ttt_company ORDER BY company_name ASC UPDATE ttt_company SET company_name = ? WHERE (id_company = ?) bind => [Merge Test Company New Name, 2]
The update statement now appears as expected. If we now check the database directly after executing the test case, we find:
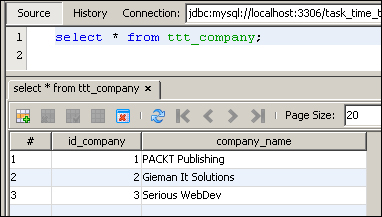
As expected, Spring has rolled back the database at the end of the testMerge method call, and the company name of the first record has not changed.
The output for this test case is:
STARTED testFindAll() SELECT id_company, company_name FROM ttt_company ORDER BY company_name ASC FINISHED testFindAll()
Even though the testMerge method uses the findAll method to retrieve the first item in the list, we should always include a separate findAll test method to compare the size of the result set with the database table. This is easy when using the Spring helper method countRowsInTable:
int rowCount = countRowsInTable("ttt_company");We can then compare the size of the findAll result list with rowCount using the assertTrue statement:
assertTrue("Company.findAll list not equal to row count of table ttt_company", rowCount == allItems.size());Note how the assertTrue statement is used; the message is displayed if the assertion is false. We can test the statement by slightly modifying the assertion so that it fails:
assertTrue("Company.findAll list not equal to row count of table ttt_company", rowCount+1 == allItems.size());It will now fail and result in the following output when the test case is executed:
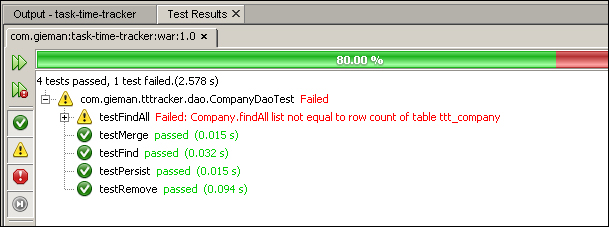
The output for this test case is:
STARTED testFind() SELECT id_company, company_name FROM ttt_company ORDER BY company_name ASC FINISHED testFind()
This may seem a bit surprising for those new to JPA. The SELECT statement is executed from the code:
List<Company> allItems = companyDao.findAll();
But where is the expected SELECT statement when calling the find method using the id attribute?
int id = c1.getId(); // find ID of first item in list Company c2 = companyDao.find(id);
JPA does not need to execute the SELECT statement using the primary key statement on the database as the entity with the required ID has already been loaded in the persistence context. There will be three entities loaded as a result of the findAll method with IDs 1, 2, and 3. When asked to find the entity using the ID of the first item in the list, JPA will return the entity it has already loaded in the persistence context with the matching ID, avoiding the need to execute a database select statement.
This is often a trap in understanding the behavior of JPA-managed applications. When an entity is loaded into the persistence context it will remain there until it expires. The definition of what constitutes "expires" will depend on the implementation and caching properties. It is possible that small sets of data will never expire; in our Company example with only a few records, this will most likely be the case. Performing an update statement directly on the underlying table, for example, changing the company name of the first record, may never be reflected in the JPA persistence context as the persistence context entity will never be refreshed.
Note
If an enterprise application expects data modification from multiple sources (for example, through stored procedures or web service calls via a different entity manager), a caching strategy to expire stale entities will be required. JPA does not automatically refresh the entity state from the database and will assume that the persistence context is the only mechanism for managing persistent data. EclipseLink provides several caching annotations to solve this problem. An excellent guide can be found here: http://wiki.eclipse.org/EclipseLink/Examples/JPA/Caching.
We have added a few minor changes to the GenericDaoImpl.persist method as a result of the exercises from the previous chapter. The modified persist method in the GenericDaoImpl implementation is:
em.persist(o);
em.flush();
if (o instanceof EntityItem) {
EntityItem<ID> item = (EntityItem<ID>) o;
ID id = item.getId();
logger.info("The " + o.getClass().getName() + " record with ID=" + id + " has been inserted");
}You will notice the em.flush() method in GenericDaoImpl after the em.persist() method. Without this flush to the database ,we cannot guarantee that a valid primary key has been set on the new Company entity. The output for this test case is:
STARTED testPersist() INSERT INTO ttt_company (company_name) VALUES (?) bind => [Persist Test Company name] SELECT LAST_INSERT_ID() The com.gieman.tttracker.domain.Company record with ID=4 has been inserted FINISHED testPersist()
Note that the logging outputs the newly generated primary key value of 4. This value is retrieved when JPA queries MySQL using the SELECT LAST_INSERT_ID() statement. In fact, removing the em.flush() method from GenericDaoImpl and executing the test case would result in the following output:
STARTED testPersist() The com.gieman.tttracker.domain.Company record with ID=null has been inserted
The assertion assertTrue(c.getId() != null) will fail and we will not even display the FINISHED testPersist() message. Our test case fails before the debug message is reached.
Once again we see the JPA optimization in action. Without the em.flush() method, JPA will wait until a transaction is committed in order to execute any changes in the database. As a result, the primary key may not be set as expected for any subsequent code using the newly created entity object within the same transaction. This is another trap for the unwary developer, and the persist method identifies the only situation where an entity manager flush() to the database may be required.
This is probably the most interesting test case so far. The output is:
STARTED testRemove() SELECT id_company, company_name FROM ttt_company ORDER BY company_name ASC SELECT id_project, project_name, id_company FROM ttt_project WHERE (id_company = ?) bind => [2] SELECT id_task, task_name, id_project FROM ttt_task WHERE (id_project = ?) bind => [4] SELECT id_task, task_name, id_project FROM ttt_task WHERE (id_project = ?) bind => [5] SELECT id_task, task_name, id_project FROM ttt_task WHERE (id_project = ?) bind => [6] The com.gieman.tttracker.domain.Company record with ID=2 has been deleted DELETE FROM ttt_task WHERE (id_task = ?) bind => [10] DELETE FROM ttt_task WHERE (id_task = ?) bind => [12] DELETE FROM ttt_task WHERE (id_task = ?) bind => [11] DELETE FROM ttt_task WHERE (id_task = ?) bind => [13] DELETE FROM ttt_project WHERE (id_project = ?) bind => [4] DELETE FROM ttt_project WHERE (id_project = ?) bind => [6] DELETE FROM ttt_project WHERE (id_project = ?) bind => [5] DELETE FROM ttt_company WHERE (id_company = ?) bind => [2] SELECT id_company, company_name FROM ttt_company ORDER BY company_name ASC FINISHED testRemove()
The first SELECT statement is executed as a result of finding the first company in the list:
Company c = companyDao.findAll().get(0);
The second SELECT statement may not be as obvious:
SELECT id_project, project_name, id_company FROM ttt_project WHERE (id_company = ?) bind => [2]
Why does deleting a company result in a SELECT statement on the ttt_project table? The reason is that each Company entity may have one or more related Projects entities as defined in the Company class definition:
@OneToMany(cascade = CascadeType.ALL, mappedBy = "company")
private List<Project> projects;JPA understands that deleting a Company requires a check against the ttt_project table to see if there are any dependent Projects. In the @OneToMany annotation, the cascade = CascadeType.ALL property defines the behavior if a Company is deleted; the change should be cascaded to any dependent entities. In this example, deleting a company record will require the deletion of all related project records. Each Project entity in turn owns a collection of Task entities as defined in the Project class definition:
@OneToMany(cascade = CascadeType.ALL, mappedBy = "project")
private List<Task> tasks;The result of removing a Company entity has far-reaching consequences as all related Projects and their related Tasks are deleted from the underlying tables. A cascade of DELETE statements in the testing output is the result of the final deletion being that of the company itself. This may not be suitable behavior for enterprise applications; in fact, such a cascading of deletions is usually never implemented without extensive checks to ensure data integrity. A simple change in the cascade annotation in the Company class will ensure that the deletion is not propagated:
@OneToMany(cascade = {CascadeType.MERGE, CascadeType.PERSIST}, mappedBy ="company")
private List<Project> projects;Now only the MERGE and PERSIST operations on the Company entity will be cascaded to the related Project entities. Running the test case again after making this change will result in:
Internal Exception: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Cannot delete or update a parent row: a foreign key constraint fails (`task_time_tracker`.`ttt_project`, CONSTRAINT `ttt_project_ibfk_1` FOREIGN KEY (`id_company`) REFERENCES `ttt_company` (`id_company`))
As the cascade type for REMOVE was not included, JPA does not check for related rows in the ttt_project table and simply attempts to execute the DELETE statement on the ttt_company table. This will fail, as there are related records on the ttt_project table. It will now only be possible to remove a Company entity if there are no related Project entities (the projects field is an empty list).
Note
Changing the CascadeType as outlined in this section adds business logic to the DAO layer. You will no longer be able to perform certain actions through the persistence context. There may, however, be a legitimate situation where you do want a cascading delete of a Company entity and this will no longer be possible. CascadeType.ALL is the most flexible option, allowing all possible scenarios. Business logic such as deletion strategies should be implemented in the service layer, which is the subject of the next chapter.
We will continue to use the cascade = CascadeType.ALL property and allow JPA-managed deletions to propagate. The business logic to restrict these actions will be implemented in the service layer.