
In this section, you will learn about basic scalability techniques such as database sharding. Sharding is widely used in high-end systems and offers a simple and reliable way to scale out a setup. In recent years, sharding has become a standard way to scale up professional systems.
What happens if your setup grows beyond the capacity of a single machine? What if you want to run so many transactions that one server is simply not able to keep up? Let us assume you have millions of users and tens of thousands want to perform a certain task at the very same time.
Clearly, at some point, you cannot buy servers that are big enough to handle infinite load, anymore. It is simply impossible to run a Facebook- or Google-like application on a single box. At some point, you have to come up with a scalability strategy that serves your needs. This is when sharding comes into play.
The idea of sharding is simple: What if you could split data in a way that it can reside on different nodes?
To demonstrate the basic concept of sharding, let us assume the following scenario: We want to store information about millions of users. Each user has a unique user ID. Let us further assume that we have just two servers. In this case we could store even user IDs on server 1 and odd user IDs on server 2.
The following diagram shows how this can be done:
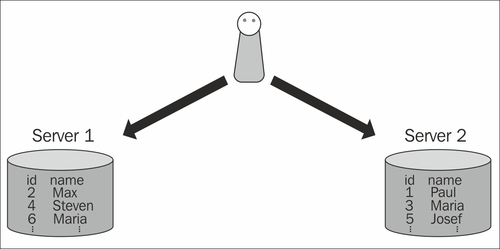
As you can see, in our diagram, we have nicely distributed the data. Once this has been done, we can send a query to the system as follows:
SELECT * FROM t_user WHERE id = 4;
The client can easily figure out where to find the data by inspecting the filter in our query. In our example, the query will be sent to the first node because we are dealing with an even number.
As we have distributed the data based on a key, (in this case, the user ID), we can basically search for any person easily if we know the key. In large systems, referring to users through a key is a common practice, and therefore this approach is suitable. By using this simple approach, we have also easily doubled the number of machines in our setup.
When designing a system, we can easily come up with an arbitrary number of servers; all we have to do is to invent a nice and clever partitioning function to distribute the data inside our server farm. If we want to split the data between ten servers (not a problem), how about using user ID % 10 as a partitioning function?
When you are trying to break up data and store it on different hosts, always make sure that you are using a sane partitioning function; it can be very beneficial to split data in a way that each host has more or less the same amount of data.
Splitting up users alphabetically might not be a good idea. The reason for that is that not all the letters are equally likely. We cannot simply assume that the letters from A to M occur as often as the letters from N to Z. This can be a major issue if you want to distribute a dataset to a thousand servers and not just to a handful of machines. As stated before, it is essential to have a sane partitioning function, which produces evenly distributed results.
In the previous section, you have seen how we can query a person easily using their key. Let us take this a little further and see what happens if the following query is used:
SELECT * FROM t_test WHERE name = 'Max';
Remember, we have distributed data using the ID. In our query, however, we are searching for the name. The application will have no idea which partition to use because there is no rule telling us what is where.
As a logical consequence, the application has to ask every partition for the name. This might be acceptable if looking for the name was a real corner case; however, we cannot rely on this fact. Having to ask many servers instead of one is clearly a serious de-optimization and therefore not acceptable.
We have two options to approach the problem:
- Come up with a cleverer partitioning function
- Store the data redundantly
Coming up with a cleverer partitioning function would surely be the best option, but it is rarely possible if you want to query different fields.
This leaves us with the second option, which is storing data redundantly. Storing a set of data twice or even more often is not too uncommon and actually a good way to approach the problem. The following image shows how this can be done:
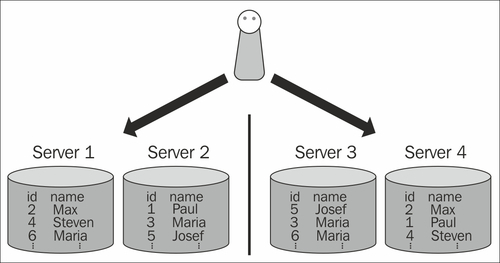
As you can see, we have two clusters in this scenario. When a query comes in, the system has to decide which data can be found on which node. In case the name is queried, we have (for the sake of simplicity) simply split the data in half alphabetically. In the first cluster, our data is still split by user ID.
One important thing to understand is that sharding is not a simple one-way street. If someone decides on using sharding, it is essential to be aware of the upsides as well as of the downsides of the technology. As always, there is no Holy Grail that magically solves all the problems of mankind out of the box without having to think about it.
Each practical use case is different and there is no replacement for common sense and deep thinking.
First, let us take a look at the pros of sharding listed as follows:
- It has the ability to scale a system beyond one server
- It is a straightforward approach
- It is widely supported by various frameworks
- It can be combined with various other replication approaches
- It works nicely with PostgreSQL (for example using PL/Proxy)
Light and shadow tend to go together and therefore sharding also has its downsides listed as follows:
- Adding servers on the fly can be far from trivial (depending on the type of partitioning function)
- Your flexibility might be seriously reduced
- Not all types of queries will be as efficient as on a single server
- There is an increase in overall complexity of the setup (such as failover, and so on)
- Backups need more planning
- You might face redundancy and additional storage requirements
- Application developers should be aware of sharding to make sure that efficient queries are written
In Chapter 13, Scaling with PL/Proxy, we will discuss how you can efficiently use sharding along with PostgreSQL and how to set up PL/Proxy for maximum performance and scalability.
Learning how to shard a table is only the first step to designing a scalable system architecture. In the example we have shown in the previous section, we had just one table, which could be distributed easily using a key. But, what if we have more than just one table? Let us assume we have two tables:
- A table called
t_userto store the users in our system - A table called
t_languageto store the languages supported by our system
We might be able to partition the t_user table nicely and split it in a way that it can reside on a reasonable number of servers. But what about the t_language table? Our system might support as many as ten languages.
It can make perfect sense to shard and distribute hundreds of millions of users but splitting up ten languages? This is clearly useless. In addition to that, we might need our language table on all nodes so that we can perform joins.
The solution to the problem is simple: You need a full copy of the language table on all nodes. This will not cause a storage consumption related problem because the table is just so small.
Again, every case has to be thought over thoroughly.
So far, we have always considered the size of a sharded setup to be constant. We have designed sharding in a way that allowed us to utilize a fixed number of partitions inside our cluster. This limitation might not reflect everyday requirements. How can you really tell for certain how many nodes will be needed at the time a setup is designed? People might have a rough idea of the hardware requirements, but actually knowing how much load to expect is more art than science.
A commonly made mistake is that people tend to increase the size of their setup in unnecessarily small steps. Somebody might want to move from five to maybe six or seven machines. This can be tricky. Let us assume for a second we have split out data using the user id % 5 as the partitioning function. What if we wanted to move to user id % 6? This is not too easy; the problem is that we have to rebalance the data inside our cluster to reflect the new rules.
Remember, we have introduced sharding (that is, partitioning) because we have so much data and so much load that one server cannot handle those requests anymore. If we came up with a strategy now that requires rebalancing of data, we are already on the wrong track. You definitely don't want to rebalance 20 TBs of data just to add two or three servers to your existing system.
Practically, it is a lot easier to simply double the number of partitions. Doubling your partitions does not require rebalancing data because you can simply follow the strategy outlined later:
- Create a replica of each partition
- Delete half of the data on each partition
If your partitioning function was user id % 5 before, it should be user id % 10 afterwards. The advantage of doubling is that data cannot move between partitions. When it comes to doubling, users might argue that the size of your cluster might increase too rapidly. This is true, but if you are running out of capacity, adding 10 percent to your resources won't fix the problem of scalability anyway.
Instead of just doubling your cluster (which is fine for most cases), you can also put more thought into writing a more sophisticated partitioning function that leaves the old data in place but handles the more recent data more intelligently. Having time-dependent partitioning functions might cause issues of its own but it might be worth investigating this path.
Tip
Some NoSQL systems use range partitioning to spread out data. Range partitioning would mean that each server has a fixed slice of data for a given time frame. This can be beneficial if you want to do time series analysis or similar. However, it can be counterproductive if you want to make sure that data is split up evenly.
If you expect your cluster to grow, we recommend starting with more partitions than those initially necessary and packing more than just one partition on a single server. Later on, it will be easy to move single partitions to additional hardware joining the cluster setup. Some cloud services are able to do that but those aspects are not covered in this book.
To shrink your cluster again you can simply apply the reverse strategy and move more than just one partition to a single server. This leaves the door for a future increase of servers wide open and can be done fairly easily.
Once data has been broken up into useful chunks, which can be handled by one server or partition, we have to think about how to make the entire setup more reliable and failsafe.
The more servers you have in your setup, the more likely it will be that one of those servers will be down or not available for some other reason.
In order to ensure maximum throughput and maximum availability, we can again turn to redundancy. The design approach can be summed up in a simple formula, which should always be in the back of a system architect's mind:
"One is none and two is one".
One server is never enough to provide us with high availability. Every system needs a backup system, which can take over in case of a serious emergency. By just splitting up a set of data, we have definitely not improved availability because we have more servers, which can fail at this point. To fix the problem, we can add replicas to each of our partitions (shards) just as is shown in the following diagram:
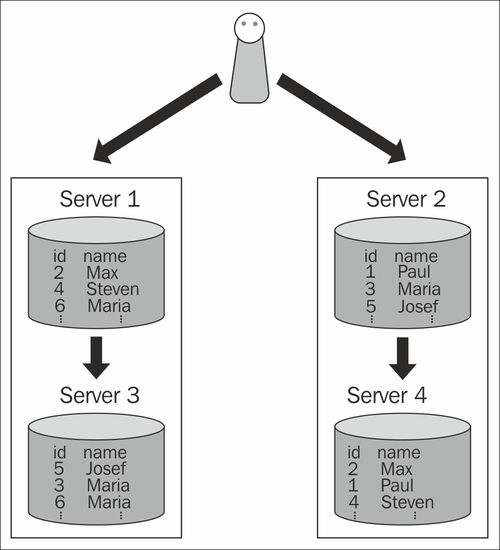
Each partition is a separate PostgreSQL database instance and each of those instances can have its own replica(s).
Keep in mind that you can choose from the full arsenal of features and options discussed in this book (for example, synchronous and asynchronous replication). All strategies outlined in this book can be combined flexibly; a single technique is usually not enough, so feel free to combine various technologies in different ways to achieve your goals.
In recent years, sharding has emerged as an industry standard solution to many scalability-related problems. Thus, many programming languages, frameworks, and products already provide out-of-the-box support for sharding.
When implementing sharding, you can basically choose between two strategies:
- Rely on some framework/middleware
- Rely on PostgreSQL-means to solve the problem
In the next two sections, we will discuss both options briefly. This little overview is not meant to be a comprehensive guide but rather an overview to get you started with sharding.
PostgreSQL cannot shard data out of the box, but it has all of the interfaces and means to allow sharding through add-ons. One of those add-ons, which is widely used, is called PL/Proxy. It has been around for many years and offers superior transparency as well as good scalability.
The idea behind PL/Proxy is basically to use a local virtual table to hide an array of servers making up the table.
PL/Proxy will be discussed in depth in Chapter 13, Scaling with PL/Proxy.