
Digging into the PostgreSQL transaction log without thinking about consistency is impossible. In the first part of this chapter, we have tried hard to explain the basic idea of the transaction log in general. You have learned that it is hard or even impossible to keep data files in good shape without the ability to log changes beforehand.
Up to now we have mostly talked about corruption. It is definitely not nice to lose data files because of corrupted entries in a data file, but corruption is not the only issue you have to be concerned about. Two other important topics are:
- Performance
- Data loss
While this might be an obvious choice for important topics, we have the feeling that those two topics are not evenly well understood, honored, and therefore taken into consideration.
In our daily business as PostgreSQL consultants and trainers, we usually tend to see people who are only focused on performance.
Performance is everything, we want to be fast; tell us how to be fast…
The awareness of potential data loss, or even a concept to handle it, seems to be new to many people. We try to put it this way: What good is higher speed if data is lost even faster? The point of this is not that performance is not important; performance is highly important. However, we simply want to point out that performance is not the only component in the big picture.
To understand issues related to data loss and consistency, we have to see how a chunk of data is sent to the disk. The following image illustrates how this works:
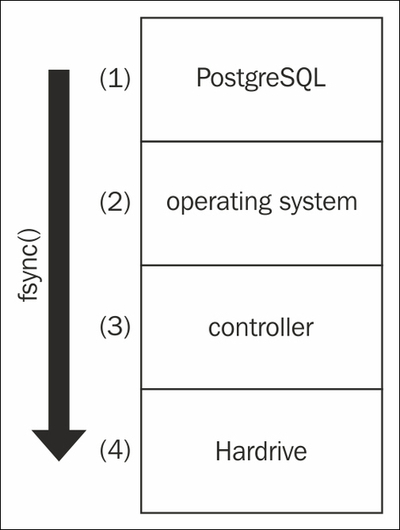
When PostgreSQL wants to read or write a block, it usually has to go through a couple of layers. When a block is written, it will be sent to the operating system. The operating system will cache the data and perform some operation on the data. At some point, the operating system will decide to pass the data on to some lower level. This might be the disk controller. The disk controller will cache, reorder, and massage the write again and finally pass it on to the disk. Inside the disk, there might be one more caching level before the data will finally end up on the real physical storage device.
In our example, we have used four layers. In many enterprise systems, there can even be more layers. Just imagine a virtual machine, storage mounted over the network such as SAN, NAS, NFS, ATA-over_Ethernet, iSCSI, and so on. Many abstraction layers will pass data around, and each of them will try to do its share of optimization.
What happens when PostgreSQL passes an 8k block to the operating system? The only correct answer to this question might be: "Something". When a normal write to a file is performed, there is absolutely no guarantee that the data is actually sent to disk. In reality, writing to a file is nothing more than a copy operation from PostgreSQL memory to some system memory. Both memory areas are in RAM, so in the case of a crash, things can be lost. Practically speaking, it makes no difference who loses the data, if the entire RAM is gone due to a failure.
The following code snippet illustrates the basic problem we are facing:
test=# d t_test Table "public.t_test" Column | Type | Modifiers --------+---------+----------- id | integer | test=# BEGIN; BEGIN test=# INSERT INTO t_test VALUES (1); INSERT 0 1 test=# COMMIT; COMMIT
Just like in the previous chapter, we are using a table with just one column. The goal is to run a transaction inserting a single row.
If a crash happens shortly after commit, no data will be in danger because nothing has happened. If a crash happens shortly after the INSERT statement but before COMMIT, nothing can happen. The user has not issued a COMMIT yet, so the transaction is known to be running and thus unfinished. If a crash happens, the application will notice that things were unsuccessful and (hopefully) react accordingly.
The situation is quite different, however, if the user has issued a COMMIT statement, which has returned successfully. Whatever happens, the user will expect committed data to be available.
Note
Users expect that successful writes will be available after an unexpected reboot. This persistence is also required by the so called ACID criteria. In computer science, ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably.
To make sure that the kernel will pass data from memory on to the disk, PostgreSQL has to take some precautions. On COMMIT, a system call will be issued, which forces data to the transaction log.
The system call necessary to force data to disk is called
fsync(). The following listing has been copied from the BSD manpage. In our opinion, it is one of the best manpages ever written dealing with the topic:
FSYNC(2) BSD System Calls Manual FSYNC(2)
NAME
fsync -- synchronize a file's in-core state with
that on disk
SYNOPSIS
#include <unistd.h>
int
fsync(intfildes);
DESCRIPTION
Fsync() causes all modified data and attributes of
fildes to be moved to a permanent storage device.
This normally results in all in-core modified
copies of buffers for the associated file to be
written to a disk.
Note that while fsync() will flush all data from
the host to the drive (i.e. the "permanent storage
device"), the drive itself may not physically
write the data to the platters for quite some time
and it may be written in an out-of-order sequence.
Specifically, if the drive loses power or the OS
crashes, the application may find that only some
or none of their data was written. The disk drive
may also re-order the data so that later writes
may be present, while earlier writes are not.
This is not a theoretical edge case. This sce-
nario is easily reproduced with real world work-
loads and drive power failures.It essentially says that the kernel tries to make its image of the file in memory consistent with the image of the file on disk. It does so by forcing all changes out to the storage device. It is also clearly stated that we are not talking about a theoretical scenario here, flushing to disk is a highly important issue.
Without a disk flush on COMMIT, you simply cannot be sure that your data is safe, and this means that you can actually lose data in case of serious trouble.
And, what is essentially important is speed and consistency; they can actually work against each other. Flushing changes to disk is especially expensive because real hardware is involved. The overhead we have is not some 5 percent but a lot more. With the introduction of SSDs, the overhead has gone down dramatically, but it is still substantial.
Most production servers will make use of a RAID controller to manage disks. The important point here is that disk flushes and performance are usually strongly related to RAID controllers. If the RAID controller has no battery, which is usually the case, then it takes insanely long to flush. The RAID controller has to wait for the slowest disk to return. However, if a battery is available, the RAID controller can assume that a power loss will not prevent an acknowledged disk write from completing once power is restored. So, the controller can cache a write and simply pretend to flush. Therefore, a simple battery can increase flush performance tenfold easily.
fsync() is not the only system call flushing data to disk. Depending on the operating system you are using, different flush calls are available. In PostgreSQL, you can decide on your preferred flush call by changing wal_sync_method. Again, this change can be made by tweaking postgresql.conf.
The methods available are open_datasync, fdatasync, fsync, fsync_writethrough, and open_sync.
Ensuring consistency and preventing data loss is costly; every disk flush is expensive and we should think twice before flushing to disk. To give the user the choice, PostgreSQL offers various levels of data protection. Those various choices are represented by two essential parameters, which can be found in postgresql.conf:
fsyncsynchronous_commit
The fsync parameter will control data loss, if fsync is used at all. In the default configuration, PostgreSQL will always flush a commit out to disk. If fsync is off, however, there is no guarantee that a COMMIT will survive a crash at all. Data can be lost and there might even be data corruption. To protect all of your data, it is necessary to keep fsync on. If you can afford to lose some or all of your data, you can relax flushing standards a little.
synchronous_commit is related to XLOG-writes. Normally, PostgreSQL will wait until data has been written to the XLOG completely. Especially short transactions can suffer considerably and therefore various different options are offered:
on: PostgreSQL will wait until XLOG has been fully and successfully written. If you are storing credit card data, you want to make sure that a financial transaction is not lost. In this case, flushing to disk is essential.off: There will be a time difference between reporting success to the client and safely writing to the disk. In a setting like that, there can be corruption. Let us assume a database storing information about who is currently online on a website. Suppose your system crashes and comes back up 20 minutes later. Do you really care about your data? After 20 minutes, everybody has to log in back again anyway. It is not worth sacrificing performance to protect data that will be outdated in a couple of minutes anyway.local: In the case of a replicated database instance, we will only wait for the local instance to flush to disk. The advantage here is that you have a high level of protection because you flush to one disk; however, we can safely assume that not both servers crash at the same time, so we can relax the standards on the slave a little.remote_write: PostgreSQL will wait until a synchronous standby server reports success for a given transaction.
In contract to setting fsync to off, changing synchronous_commit to off will not result in corruption. However, in the case of a crash we might lose a handful of transactions, which have already been committed successfully. The amount of potential data loss is governed by an additional postgresql.conf setting called wal_writer_delay. In the case of setting synchronous_commit to off, we can never lose more data than defined in the wal_writer_delayconfig variable.
Tip
Changing synchronous_commit might look like a small performance tweak; in reality, however, changing the sync behavior is one of the dominant factors when running small writing transactions. The gain might not just be a handful of percentage points, but, if you are lucky, it could be tenfold or even more (depending on hardware, work load, I/O subsystem, and so on).
Keep in mind configuring a database is not just about speed. Consistency is at least as important as speed and therefore you should think carefully whether you want to trade speed for potential data loss.
It is important to fully understand those consistency-related topics outlined in this chapter. When it comes to deciding on your cluster architecture, data security will be an essential part and it is highly desirable to be able to judge if certain architecture makes sense for your data. After all, database work is all about protecting data. Full awareness of your durability requirements is definitely a big plus.