
In the previous chapter, we have dealt with various replication concepts. It was meant to be more of a theoretical overview to sharpen your senses for what is to come and it was supposed to introduce you to the topic in general.
In this chapter, we will move closer to practical solutions and learn about how PostgreSQL works internally and what it means for replication. We will see what the so called transaction log (XLOG) does and how it operates. The XLOG is the very backbone of the PostgreSQL-onboard replication machinery. It is essential to understand how this part works.
PostgreSQL replication is all about writing data. Therefore, the way PostgreSQL writes a chunk of data internally is highly relevant and directly connected to replication and replication concepts. In this section, we will dig into writes. You will learn the following things in this chapter:
- How PostgreSQL writes data
- Which memory and storage parameters are involved
- How writes can be optimized
- How writes are replicated
- How data consistency can be ensured
Once you have completed reading this chapter, you will be ready to understand the next chapter, which will teach you how to safely replicate your first database.
One of the first things we want to take a look at in this chapter is the PostgreSQL disk layout. Knowing about the disk layout can be very helpful when inspecting an existing setup and it can be helpful when designing an efficient, high-performance installation.
In contrast to other database systems such as Oracle, PostgreSQL will always rely on a filesystem to store data. PostgreSQL does not use raw devices. The philosophy behind that is that if a filesystem developer has done his or her job well, there is no need to re-implement filesystem functionality over and over again.
To understand the filesystem layout used by PostgreSQL, we can have a look at what we can find inside the data directory (created by initdb at the time of installation):
[hs@paulapgdata]$ ls -l total 92 -rw------- 1 hs staff 4 Feb 11 18:14 PG_VERSION drwx------ 6 hs staff 4096 Feb 11 18:14 base drwx------ 2 hs staff 4096 Feb 11 18:14 global drwx------ 2 hs staff 4096 Feb 11 18:14 pg_clog -rw------- 1 hs staff 4458 Feb 11 18:14 pg_hba.conf -rw------- 1 hs staff 1636 Feb 11 18:14 pg_ident.conf drwx------ 4 hs staff 4096 Feb 11 18:14 pg_multixact drwx------ 2 hs staff 4096 Feb 11 18:14 pg_notify drwx------ 2 hs staff 4096 Feb 11 18:14 pg_serial drwx------ 2 hs staff 4096 Feb 11 18:14 pg_snapshots drwx------ 2 hs staff 4096 Feb 11 18:19 pg_stat_tmp drwx------ 2 hs staff 4096 Feb 11 18:14 pg_subtrans drwx------ 2 hs staff 4096 Feb 11 18:14 pg_tblspc drwx------ 2 hs staff 4096 Feb 11 18:14 pg_twophase drwx------ 3 hs staff 4096 Feb 11 18:14 pg_XLOG -rw------- 1 hs staff 19630 Feb 11 18:14 postgresql.conf -rw------- 1 hs staff 47 Feb 11 18:14 postmaster.opts -rw------- 1 hs staff 69 Feb 11 18:14 postmaster.pid
You will see a range of files and directories, which are needed to run a database instance. Let us take a look at those in detail.
This file will tell the system at startup if the data directory contains the right version number. Please note that only the major release version is in this file. It is easily possible to replicate between different minor versions of the same major version.
[hs@paulapgdata]$ cat PG_VERSION 9.2
The file is plain text readable.
The base directory is one of the most important things in our data directory. It actually contains the real data (meaning tables, indexes, and so on). Inside the base directory, each database will have its own subdirectory:
[hs@paula base]$ ls -l total 24 drwx------ 2 hs staff 12288 Feb 11 18:14 1 drwx------ 2 hs staff 4096 Feb 11 18:14 12865 drwx------ 2 hs staff 4096 Feb 11 18:14 12870 drwx------ 2 hs staff 4096 Feb 11 18:14 16384
We can easily link these directories to the databases in our system. It is worth noticing that PostgreSQL uses the object ID of the database here. This has many advantages over using the name because the object ID never changes and offers a good way to abstract all sorts of problems, such as issues with different character sets on the server and so on:
test=# SELECT oid, datname FROM pg_database;
oid |datname
-------+-----------
1 | template1
12865 | template0
12870 | postgres
16384 | test
(4 rows)Now we can see how data is stored inside those database-specific directories. In PostgreSQL, each table is related to (at least) one data file. Let us create a table and see what happens:
test=# CREATE TABLE t_test (id int4); CREATE TABLE
We can check the system table now to retrieve the so called relfilenode, which represents the name of the storage file on disk:
test=# SELECT relfilenode, relname
FROM pg_class
WHERE relname = 't_test';
relfilenode | relname
-------------+---------
16385 | t_test
(1 row)As soon as the table is created, PostgreSQL will create an empty file on disk:
[hs@paula base]$ ls -l 16384/16385* -rw------- 1 hs staff 0 Feb 12 12:06 16384/16385
Tables can sometimes be quite large and therefore it is more or less impossible to put all the data related to a table into a single data file. To solve the problem, PostgreSQL will add additional files every time 1 GB of data has been added.
So, if the file called 16385 grows beyond 1 GB, there will be a file called 16385.1. Once this has been filled up, you will see a file named 16385.2, and so on. This way, a table in PostgreSQL can be scaled up reliably and safely without having to worry about underlying filesystem limitations on some rare operating systems or embedded devices.
To improve I/O performance, PostgreSQL will always perform I/O in 8k chunks. Thus, you will see that your data files will always grow in 8k steps. When talking about physical replication, you have to make sure that both sides (master and slave) were compiled with the same block size.
In addition to those data files discussed in the previous paragraph, PostgreSQL will create additional files using the same number. As of now, those files are used to store information about free space inside a table (Free Space Map), the so called Visibility Map, and so on. In the future, more types of relation forks might be added.
global will contain the global system tables. This directory is small, so you should not expect excessive storage consumption.
There is one thing that is often forgotten by users: A single PostgreSQL data file is basically more or less worthless. It is hardly possible to restore data reliably if you just have a data file; trying to extract data from single data files can easily end up as hopeless guesswork. So, in order to read data, you need an instance that is more or less complete.
The commit log is an essential component of a working database instance. It stores the status of the transactions on this system. A transaction can be in four states (TRANSACTION_STATUS_IN_PROGRESS, TRANSACTION_STATUS_COMMITTED, TRANSACTION_STATUS_ABORTED, and TRANSACTION_STATUS_SUB_COMMITTED), and if the commit log status for a transaction is not available, PostgreSQL will have no idea whether a row should be seen or not.
If the commit log of a database instance is broken for some reason (maybe because of filesystem corruption), you can expect some funny hours ahead.
The pg_hba.conf file configures the PostgreSQL-internal firewall and represents one of the two most important configuration files in a PostgreSQL cluster. It allows the users to define various types of authentication based on the source of a request. To a database administrator, understanding the pg_hba.conf file is of vital importance because this file decides whether a slave is allowed to connect to the master or not. If you happen to miss something here, you might see error messages in the slave's logs (for instance: no pg_hba.conf entry for ...).
The pg_ident.conf file can be used in conjunction with the pg_hba.conf file to configure
ident authentication.
The multi-transaction-log manager is here to handle shared row locks efficiently. There are no replication-related practical implications of this directory.
In this directory, the system stores information about LISTEN/NOTIFY (the async backend interface). There are no practical implications related to replication.
Information about serializable transactions is stored here. We have to store information about commits of serializable transactions on disk to ensure that long-running transactions will not bloat memory. A simple SLRU structure is used internally to keep track of those transactions.
This is a file consisting of information needed by the PostgreSQL snapshot manager. In some cases, snapshots have to be exported to disk to avoid going to memory. After a crash, those exported snapshots will be cleaned out automatically.
Temporary statistical data is stored in this file. This information is needed for most pg_stat_* system views (and therefore also for the underlying function providing the raw data).
In this directory, we store information about subtransactions. pg_subtrans(and pg_clog) directories are permanent (on-disk) storage of transaction-related information. There is a limited number of pages of each kept in the memory, so in many cases there is no need to actually read from disk. However, if there's a long-running transaction or a backend sitting idle with an open transaction, it may be necessary to be able to read and write this information from disk. They also allow the information to be permanent across server restarts.
The pg_tblspc directory is a highly important one. In PostgreSQL, a tablespace is simply an alternative storage location, which is represented by a directory holding the data.
The important thing here is: If a database instance is fully replicated, we simply cannot rely on the fact that all servers in the cluster use the very same disk layout and the very same storage hardware. There can easily be scenarios in which a master needs a lot more I/O power than a slave, which might just be around to function as backup or standby. To allow users to handle different disk layouts, PostgreSQL will place symlinks into the pg_tblspc directory. The database will blindly follow those symlinks to find those tablespaces, regardless of where they are.
This gives end users enormous power and flexibility. Controlling storage is both essential to replication as well as to performance in general. Keep in mind that those symlinks can only be changed ex post. It should be carefully thought over.
PostgreSQL has to store information about two-phase commit. While two-phase commit can be an important feature, the directory itself will be of little importance to the average system administrator.
The PostgreSQL transaction log is the essential directory we have to discuss in this chapter. pg_XLOG contains all files related to the so called XLOG. If you have used PostgreSQL already in the past, you might be familiar with the term WAL (Write Ahead Log). XLOG and WAL are two names for the very same thing. The same applies to the term transaction log. All these three terms are widely in use and it is important to know that they actually mean the same thing.
The pg_XLOG directory will typically look like this:
[hs@paulapg_XLOG]$ ls -l total 81924 -rw------- 1 hs staff 16777216 Feb 12 16:29 000000010000000000000001 -rw------- 1 hs staff 16777216 Feb 12 16:29 000000010000000000000002 -rw------- 1 hs staff 16777216 Feb 12 16:29 000000010000000000000003 -rw------- 1 hs staff 16777216 Feb 12 16:29 000000010000000000000004 -rw------- 1 hs staff 16777216 Feb 12 16:29 000000010000000000000005 drwx------ 2 hs staff 4096 Feb 11 18:14 archive_status
What you see is a bunch of files, which are always exactly 16 MB in size (default setting). The filename of an XLOG file is generally 24 bytes long. The numbering is always hexadecimal. So, the system will count "… 9, A, B, C, D, E, F, 10" and so on.
One important thing to mention is that the size of the pg_XLOG directory will not vary wildly over time and it is totally independent of the type of transactions you are running on your system. The size of the XLOG is determined by postgresql.conf parameters, which will be discussed later in this chapter. In short: No matter if you are running small or large transactions, the size of the XLOG will be the same. You can easily run a transaction as big as 1 TB with just a handful of XLOG files. This might not be too efficient, performance wise, but it is technically and perfectly feasible.
Finally, there is the main PostgreSQL configuration file. All configuration parameters can be changed in postgresql.conf and we will use this file extensively to set up replication and to tune our database instances to make sure that our replicated setups provide us with superior performance.
Tip
If you happen to use prebuilt binaries, you might not find postgresql.conf directly inside your data directory. It is more likely to be located in some subdirectory of /etc/ (on Linux/Unix) or in your place of choice in Windows. The precise location is highly dependent on the type of operating system you are using. The typical location for data directories is /var/lib/pgsql/data. But postgresql.conf is often located under /etc/postgresql/9.X/main/postgresql.conf (as in Ubuntu and similar systems) or under /etc directly.
Now that we have gone through the disk layout, we will dive further into PostgreSQL and see what happens when PostgreSQL is supposed to write one line of data. Once you have mastered this chapter, you will have fully understood the concept behind the XLOG.
Note that, in this section about writing a row of data, we have simplified the process a little to make sure that we can stress the main point and the ideas behind the PostgreSQL XLOG.
Let us assume that we are doing a simple INSERT statement like the following one:
INSERT INTO foo VALUES ('abcd'):As one might imagine, the goal of an INSERT operation is to somehow add a row to an existing table. We have seen in the previous section about the disk layout of PostgreSQL that each table will be associated with a file on disk.
Let us perform a mental experiment and assume that the table we are dealing with here is 10 TB large. PostgreSQL will see the INSERT operation and look for some spare place inside this table (either using an existing block or adding a new one). For the purpose of this example, we simply just put the data into the second block of the table.
Everything will be fine as long as the server actually survives the transaction. What happens if somebody pulls the plug after just writing abc instead of the entire data? When the server comes back up after the reboot, we will find ourselves in a situation where we have a block with an incomplete record, and to make it even funnier, we might not even have the slightest idea where this block containing the broken record might be.
In general, tables containing incomplete rows in unknown places can be considered to be corrupted tables. Of course, systematic table corruption is nothing the PostgreSQL community would ever tolerate, especially not if problems like that are caused by clear design failures.
To fix the problem that we have just discussed, PostgreSQL uses the so called WAL (Write Ahead Log) or simply XLOG. Using WAL means that a log is written ahead of data. So, before we actually write data to the table, we make log entries in sequential order indicating what we are planning to do to our underlying table. The following image shows how things work:
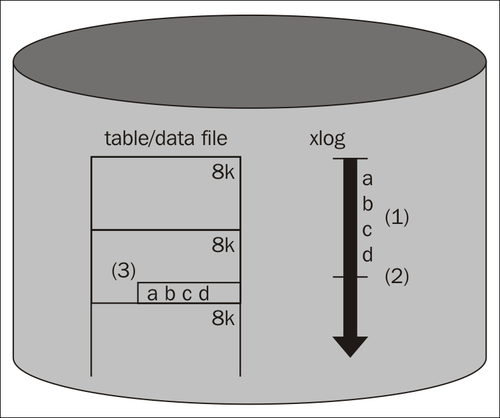
As we can see from the figure, once we have written data to the log (1), we can go ahead and mark the transaction as done (2). After that, data can be written to the table (3).
Let us demonstrate the advantages of this approach with two examples:
To make sure that the concept described in this chapter is rock solid and working, we have to make sure that we can crash at any point in time without risking our data. Let us assume that we crash while writing the XLOG. What will happen in this case? Well, in this case, the end user will know that the transaction was not successful, so he or she will not rely on the success of the transaction anyway.
As soon as PostgreSQL starts up, it can go through the XLOG and replay everything necessary to make sure that PostgreSQL is in consistent state. So, if we don't make it through WAL-writing, something nasty has happened and we cannot expect a write to be successful.
A WAL entry will always know if it is complete or not. Every WAL entry has a checksum inside, and therefore PostgreSQL can instantly detect problems in case somebody tries to replay broken WAL. This is especially important during a crash when we might not be able to rely on the very latest data written to disk anymore. The WAL will automatically sort out those problems during crash recovery.
Let us now assume we have made it through WAL-writing and we crashed shortly after that, maybe while writing to the underlying table. What if we only manage to write ab instead of the entire data?
Well, in this case, we will know during replay what is missing. Again, we go to WAL and replay what is needed to make sure that all data is safely in our data table.
While it might be hard to find data in a table after a crash, we can always rely on the fact that we can find data in the WAL. The WAL is sequential and if we simply keep track of how far data has been written, we can always continue from there; the XLOG will lead us directly to the data in the table and it always knows where a change has been or should have been made. PostgreSQL does not have to search for data in the WAL; it just replays it from the proper point on.
Now that we have seen how a simple write is performed, we have to take a look at what impact writes have on reads. The next image shows the basic architecture of the PostgreSQL database system:
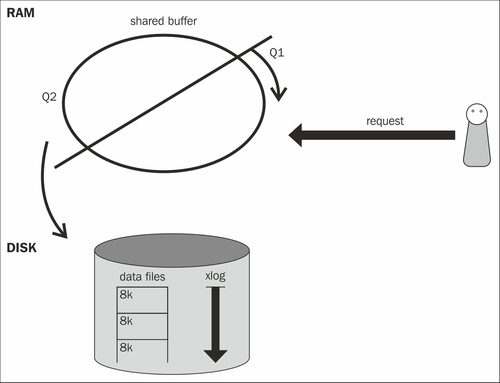
For the sake of simplicity, we can see a database instance as a thing consisting of three major components:
- PostgreSQL data files
- The transaction log
- Shared buffer
In the previous sections, we have already discussed data files. You have also seen some basic information about the transaction log itself. Now we have to extend our model and bring another component on to the scenery: The memory component of the game, the so called shared buffer.
The shared buffer is the I/O cache of PostgreSQL. It helps to cache 8k blocks, which are read from the operating system and it helps to hold back writes to the disk to optimize efficiency (how this works will be discussed later in this chapter).
But, performance is not the only issue we should be focused on when it comes to the shared buffer. Let us assume that we want to issue a query. For the sake of simplicity, we also assume that we need just one block to process this read request.
What happens if we do a simple read? Maybe we are looking up something simple like a phone number or a username given a certain key. The following list shows, in a heavily simplified way, what PostgreSQL will do under the assumption the instance has been restarted freshly:
- PostgreSQL will look up the desired block in the cache (as stated before, this is the shared buffer). It will not find the block in the cache of a freshly started instance.
- PostgreSQL will ask the operating system for the block.
- Once the block has been loaded from the OS, PostgreSQL will put it into the first queue of the cache.
- The query has been served successfully.
Let us assume the same block will be used again by a second query. In this case, things will work as follows:
- PostgreSQL will look up the desired block and land a cache hit.
- PostgreSQL will figure out that a cached block has been reused and move it from a lower level of cache (Q1) to a higher level of the cache (Q2). Blocks that are in the second queue will stay in cache longer because they have proven to be more important than those that are just on the Q1 level.
Tip
How large should the shared buffer be? Under Linux, a value of up to 8 GB is usually recommended. On Windows, values below 1 GB have proven to be useful (as of PostgreSQL9.2). From PostgreSQL 9.3 onwards, higher values might be useful and feasible under Windows. Insanely large shared buffers on Linux can actually be a deoptimization. Of course, this is only a rule of thumb; special setups might need different settings.
Remember, in this section, it is all about understanding writes to make sure that our ultimate goal, full and deep understanding of replication, can be achieved. Therefore we have to see how reads and writes go together. Let's see how a write and a read go together:
- A write comes in.
- PostgreSQL will write to the transaction log to make sure that consistency can be reached.
- PostgreSQL will grab a block inside the PostgreSQL shared buffer and make the change in the memory.
- A read comes in.
- PostgreSQL will consult the cache and look for the desired data.
- A cache hit will be landed and the query will be served.
What is the point of this example? Well, as you might have noticed, we have never talked about actually writing to the underlying table. We talked about writing to the cache, to the XLOG and so on, but never about the real data file.
It is important to understand that data is usually not sent to a data file directly after or during a write operation. It makes perfect sense to write data a lot later to increase efficiency. The reason why this is important is that it has subtle implications for replication. A data file itself is worthless because it is neither necessarily complete nor correct. To run a PostgreSQL instance, you will always need data files along with the transaction log. Otherwise, there is no way to survive a crash.
From a consistency point of view, the shared buffer is here to complete the view a user has of the data. If something is not in the table, it logically has to be in memory.
In case of a crash, memory will be lost, and so the XLOG is consulted and replayed to turn data files into a consistent data store again. Under any circumstances, data files are only half of the story.
Note
In PostgreSQL 9.2 and before, the shared buffer was exclusively in SysV/POSIX shared memory or simulated SysV on Windows. PostgreSQL9.3 (unreleased at the time of writing) started using memory-mapped files, which is a lot faster under Windows, and makes no difference in performance under Linux, but is slower under BSDs. BSD developers have already started fixing this. Moving to mmap was done to make configuration easier because mmap is not limited by the operating system, it is unlimited as long as enough RAM is around. SysVshmem is limited and a high amount of SysVshmen can usually only be allocated if the operating system is tweaked accordingly. The default configuration of shared memory varies from Linux distribution to Linux distribution. Suse tends to be a bit more relaced while RedHat, Ubuntu and some others tend to be more conservative.