
Databases are part of our daily digital life and they are expected to work fast.
Are you browsing an online forum? The posts are in a database. Are you visiting a doctor? Your medical records are in a database. Are you shopping online? The items, your data and previous purchases are all in a database.
All these data are expected to appear in a few seconds. And it's not only you who expect it. A small web shop may have hundreds of visitors at the same time and every one of them expects the website to be displayed very quickly. The larger sites can handle tens or hundreds of thousands simultaneously.
This means that the database behind the service must be available at all times. The scope of the problem becomes apparent when we consider that such sites serve users from all around the globe. There is always daylight somewhere so there is no night time which could hide the downtime. And downtime is definitely needed for individual machines, since there is regular maintenance, like software upgrades and cleaning, not to mention when some hardware actually goes wrong.
Client programs of the database, such as a web server or accounting software, expect the database not on a specific computer (with a given serial number) but at a certain address on the network. Computers can grab and release network addresses on demand. (Within limits, of course, TCP networking is another huge topic.) This makes it possible that a particular machine can be down and another machine can grab the same address. The client programs will notice that the original database doesn't respond and attempt to reconnect, now to another machine. This address that "floats" between nodes in the cluster is called a floating IP address or virtual IP address.
The administrators of the cluster can issue commands that make one of the machines go offline, in other words, stop servicing the database clients, and another one automatically take over the service.
Now that the concepts of a high-availability cluster have been discussed, it's time to see two different, detailed examples of a small database cluster.
In this section, we look at a small cluster where fencing is done voluntarily by nodes inside the cluster. Quorum means majority and it can be ensured by an odd number of nodes in the cluster.
If the network communication is cut between nodes, separate "islands" of nodes are formed. There will be at least two such islands and neither one can be the same size as the other because of the odd total number of the nodes. All such islands "know" whether they have the majority or the minority by counting the live nodes inside the island and comparing it with the total number of nodes in the whole cluster.
With the proper constraints, services provided by an island in minority will be given up voluntarily and will be picked up by another island in majority.
If the network breaks down so badly that no island is larger than the half of the total number of nodes then every island will give up services. This is actually a good thing, because it prevents the split-brain situation and providing the same service for different clients from different islands. It means trouble when a replicated database gets into this situation: two (or more) master databases start serving different clients. Primary key clashes can occur by assigning the same numeric identifier to different data in the different databases. This can also lead to foreign key conflicts when trying to merge the databases. Cleaning it up may require a lot of manual labor.
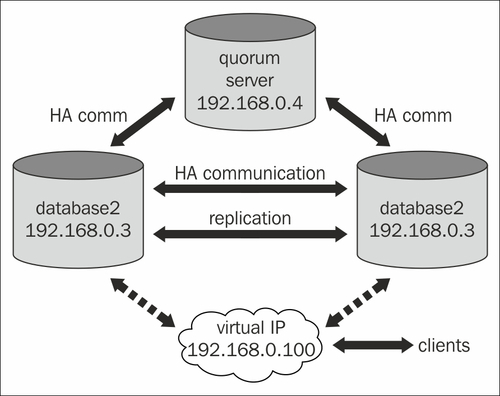
In this high-level view, we have a three-node cluster. Remember that all connections are redundant, as previously described.
Only two of the nodes carry the database, the third is the so called quorum server.
The nodes are connected to two networks: the public network on the 192.168.0.x range (clients also connect to the database from this one) and a private network on the 192.168.1.x range.
This is because the two servers are connected as a replication cluster and for a high-traffic database, the replication stream can also cause a high traffic itself. In order to allow the highest traffic to the database from the clients, the replication goes through the private network.
The high-availability software (the previously mentioned Pacemaker with either Heartbeat or Corosync transport) also needs communication. Usually it's enough to go through only on the private network. But since it only needs very little bandwidth, to provide even more redundancy, the transport level can be set up to use both the private and the public networks.
The quorum-server provides the tie-breaker vote, in case the communication between the two database servers goes down. This can be caused by networking problems. In this case, both database servers are alive and each tries to do what it needs to do: the master node serves the clients and the slave replicates the master. There can be three cases of the split-brain situation:
- The master server goes wrong or becomes standalone
- The slave server goes wrong or becomes standalone
- The quorum-server goes wrong or becomes standalone
Remember, all nodes are running the cluster manager layer of the high-availability cluster software.
In the first case, the other two nodes cannot communicate with the master node. As a consequence, two things may happen. The slave node and the quorum-server are representing the majority, so the slave node takes over the service, it promotes the replica database to be the master instance and pulls up the virtual IP. The previous master node may have crashed so it doesn't work at all, or only the network may have gone wrong between it and the other two nodes. If the node itself doesn't work, it will need to be repaired or at least restarted. If it still works, it knows about itself that it's in the minority, so it relinquishes the services voluntarily. It stops the database and drops the virtual IP.
When the previous master node or the network connection is fixed, it starts up its instance of the high-availability software and since the master copy of the database is already running elsewhere, it will not start it up. However, the resource may be started up as a slave since this is how the master-slave resources work in Pacemaker. But a properly implemented resource agent prevents this from happening, since the current master node (our previous slave database) diverged from the original master and replication cannot be established automatically at this point. It requires taking a new base backup from the current master and after restoring it on the failed node, the replication and the slave instance of the database can be started under the high-availability manager layer.
In the second case, when the slave server goes wrong or becomes standalone, the situation is better. The master instance of the database is still working and serving clients but the replication is stopped. Depending on the length of the downtime of the slave node and the configuration of the master database, either the slave can catch up with replication automatically, or a new base backup is needed before replication can be established again.
In the third case, nothing needs to be taken care of. Only the quorum-server goes wrong or becomes standalone. But the master and the slave nodes still work and can communicate with each other and they represent the majority of the cluster. This means that the services are not affected and the replication is continuous.
We look at a cluster where fencing is forced by remote administration facilities. As opposed to voluntary fencing in a cluster where the number of nodes must be an odd number, it's not required with forced fencing.
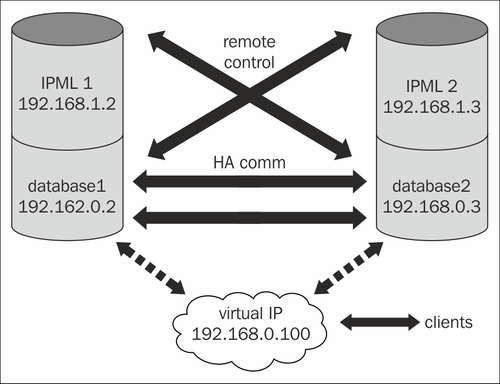
In this setup, there is no third node to provide the tie-breaker vote. If any of the nodes fails or cut off the network, it can be forcibly and externally fenced. This is what the so called STONITH devices are for: IPMI, iLO, DRAC, and so on. The STONITH action performed by the cluster can be turning off a node or restarting it.
When one of the nodes goes wrong or offline, the other one can ensure that it stays offline by actually turning it off and requiring it to be manually turned on. The other solution is to restart it so it comes online with no services and it's in a known good state of a node. It can then adapt to the new state of the other nodes in the cluster from this state.
The redundancy of the network and the high-availability communication are especially important in this case. Consider the case when there is a single cable and a single switch on the private network between the nodes and the high-availability communication only goes through the private network. When, for example, the switch between them goes wrong, each node rightfully acts on the knowledge that it's the only good node in the cluster and performs the STONITH action on the other node. This results in both nodes being either turned off or restarted, which (depending on the hardware) can take a while and can ruin the intended availability figures.