
After performing your first Point-In-Time-Recovery, we are ready to work on a real replication setup. In this chapter, you will learn how to set up asynchronous replication and streaming. The goal is to make sure that you can achieve higher availability and higher data security.
In this chapter we will cover the following topics:
- Configuring asynchronous replication
- Understanding streaming
- Combining streaming and archives
- Managing timelines
At the end of this chapter, you will be able to easily set up streaming replication within a couple of minutes.
In the previous chapter, we have recovered from simple 16 MB XLOG files. Logically, the replay process can only replay 16 MB at a time. This can lead to latency in your replication setup because you have to wait until 16 MB have been created by the master database instance. In many cases, this kind of delay might not be acceptable.
In this scenario, streaming replication will be the solution to your problem. With streaming replication, the replication delay will be minimal and you can enjoy some extra level of protection for your data.
Let us talk about the general architecture of the PostgreSQL streaming infrastructure. The following image illustrates the basic system design:
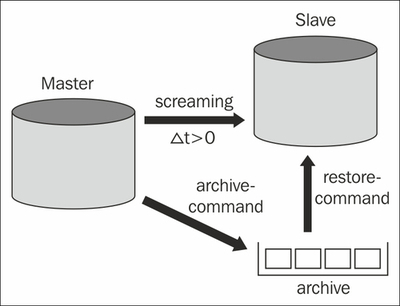
You have already seen this type of architecture. What we have added here is the streaming connection. It is basically a normal database connection as you would use in any other application. The only difference is that, in the case of a streaming connection, the connection will be in a special mode to be able to carry the XLOG.
The question now is: How can you make a streaming connection come into existence? Most of the infrastructure has already been made in the previous example. On the master, the following settings must be set:
wal_levelmust be set tohot_standbymax_wal_sendersmust be at a reasonably high value to support enough slavesTip
How about
archive_modeandarchive_command? Many people use streaming replication to make their systems replicate more data to a slave as soon as possible. In addition to that, file-based replication is often utilized to make sure that there is an extra layer of security. Basically, both mechanisms use the same techniques; just the source of XLOG differs in the cases of streaming- and archive-based recovery.
Now that the master knows that it is supposed to produce enough XLOG, handle XLOG sender, and so on we can move on to the next step.
For security reasons, you must configure the master to enable streaming replication connections. This requires changing pg_hba.conf as shown in the previous section. Again, this is needed to run pg_basebackup and the subsequent streaming connection. If you are using a traditional method to take the base backup, you still have to allow replication connections to stream the XLOG, so, this step is mandatory.
Once your master has been successfully configured, you can restart the database (to make wal_level and max_wal_senders work) and continue working on the slave.
Up to now, you have seen that the process is absolutely identical to performing normal Point-In-Time-Recovery. So far, the only different thing is the wal_level, which has to be configured differently for normal Point-In-Time-Recovery. Otherwise, it is the same technique, there's no difference.
To fetch the base backup, we can use pg_basebackup just as shown in the previous chapter. Here is an example:
iMac:dbhs$ pg_basebackup -D /target_directory -h sample.postgresql-support.de --xlog-method=stream
Now that we have taken a base backup, we can move ahead and configure streaming. To do so, we have to write a file called recovery.conf (just like before). Here is a simple example:
standby_mode = on primary_conninfo= ' host=sample.postgresql-support.de port=5432 '
We have two new settings:
standby_mode: This setting will make sure that PostgreSQL does not stop once it runs out of XLOG. Instead, it will wait for new XLOG to arrive. This setting is essential to make the second server a standby, which replays XLOG constantly.primary_conninfo: This setting will tell our slave where to find the master. You have to put a standard PostgreSQL connect string (just like in libpq) in here.primary_conninfois central and tells PostgreSQL to stream the XLOG.
For a basic setup, those two settings are totally sufficient. All we have to do now is to fire up the slave just like you would start a normal database instance:
iMac:slavehs$ pg_ctl -D . start
server starting
LOG: database system was interrupted; last known up
at 2013-03-17 21:08:39 CET
LOG: creating missing WAL directory
"pg_XLOG/archive_status"
LOG: entering standby mode
LOG: streaming replication successfully connected
to primary
LOG: redo starts at 0/2000020
LOG: consistent recovery state reached at 0/3000000The database instance has successfully started. It detects that normal operations have been interrupted. Then it enters standby mode and starts to stream XLOG from the primary. PostgreSQL then reaches a consistent state and the system is ready for action.
So far we have only set up streaming. The slave is already consuming the transaction log from the master but it is not readable yet. If you try to connect to the instance, you will face the following scenario:
iMac:slavehs$ psql -l
FATAL: the database system is starting up
psql: FATAL: the database system is starting upThis is the default configuration. The slave instance is constantly in backup mode and keeps replaying the XLOG.
If you want to make the slave readable, you have to adapt postgresql.conf on the slave system; hot_standby must be set to on. You can set this straight away but you can also make this change later on and simply restart the slave instance when you want this feature to be enabled:
iMac:slavehs$ pg_ctl -D . restart waiting for server to shut down.... LOG: received smart shutdown request FATAL: terminating walreceiver process due to administrator command LOG: shutting down LOG: database system is shut down done server stopped server starting LOG: database system was shut down in recovery at 2013-03-17 21:56:12 CET LOG: entering standby mode LOG: consistent recovery state reached at 0/3000578 LOG: redo starts at 0/30004E0 LOG: record with zero length at 0/3000578 LOG: database system is ready to accept read only connections LOG: streaming replication successfully connected to primary
The restart will shut down the server and fire it back up again. This is not too much of a surprise; however, it is worth taking a look at the log. You can see that a process called walreceiver is terminated.
Once we are back up and running, we can connect to the server. Logically, we are only allowed to perform read-only operations:
test=# CREATE TABLE x (id int4); ERROR: cannot execute CREATE TABLE in a read-only transaction
The server will not accept writes as expected. Remember, slaves are read-only.
When using streaming replication, you should keep an eye on two processes:
wal_senderwal_receiver
wal_sender instances are processes on the master instance, which serve XLOG to their counterpart on the slave called wal_receiver. Each slave has exactly one wal_receiver and this process is connected to exactly one wal_sender on the data source.
How does this entire thing work internally? As we have stated before, the connection from the slave to the master is basically a normal database connection. The transaction log is using more or less the same method as a COPY command would do. Inside COPY-mode, PostgreSQL uses a little micro language to ship information back and forth. The main advantage is that this little language has its own parser and so it is possible to add functionality fast and in a fairly easy, non-intrusive way. As of PostgreSQL 9.2, the following commands are supported:
IDENTIFY_SYSTEMSTART_REPLICATION <position>BASE_BACKUP[LABEL 'label'][PROGRESS][FAST][WAL][NOWAIT]
What you see is that the protocol level is pretty close to what pg_basebackup offers as command-line flags.