
Adding a slave here and there is really a nice scalability strategy, which is basically enough for most modern applications. Many applications will run perfectly fine with just one server; you might want to add a replica to add some security to the setup, but in many cases, this is pretty much what people need.
If your application grows larger, you can in many cases just add slaves and scale out reading; this too is not a big deal and can be done quite easily. If you want to add even more slaves, you might have to cascade your replication infrastructure, but for 98 percent of all applications, this is going to be, by far, enough.
The remaining two percent of applications are when PL/Proxy steps in. The idea of PL/Proxy is to be able to scale out writes. Remember, transaction-log-based replication can only scale out reads, there is no way to scale writes.
As we have mentioned before, the idea behind PL/Proxy is to scale out writes as well as reads. Once the writes are scaled out, reading can be scaled easily with the techniques we have already outlined in this book before.
The question now is: How can you ever scale out writes? To do so, we have to follow an old Roman principle, which has been widely applied in warfare: Divide et impera (in English: Divide and conquer). Once you manage to split a problem into many small problems, you are always on the winning side.
Applying this principle to the database work means that we have to split up writes and spread them to many different servers. The main art here is how to split up data wisely.
As an example, we simply assume that we want to split up user data. Let us assume further that each user has a username to identify himself/herself.
How can we split up data now? At this point, many people would suggest splitting up data alphabetically somehow. Say, everything from A to M goes to server 1 and all the rest to server 2. This is actually a pretty bad idea because we can never assume that data is evenly distributed. Some names are simply more likely than others, so if you split up by letters, you will never end up with roughly the same amount of data in each partition (which is highly desirable). However, we definitely want to make sure that each server has roughly the same amount of data, and we want to find a way to extend the cluster to more boxes easily. But, let us talk about useful partitioning functions later on.
Before we take a look at a real setup and at how to partition data, we have to discuss the bigger picture: Technically, PL/Proxy is a stored procedure language, which consists of just five commands. The only purpose of this language is to dispatch requests to servers inside the cluster.
Let us take a look at the following image:
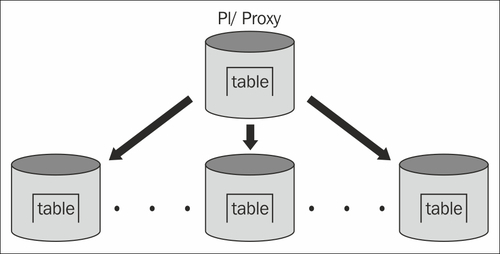
We take PL/Proxy and install it on a server that will act as the proxy for our system. Whenever we do a query, we ask the proxy to provide us with the data. The proxy will consult its rules and figure out to which server the query has to be redirected. Basically, PL/Proxy is a way to shard a database instance.
So, if you issue a query, PL/Proxy will try to hide a lot of complexity from you and just provide you with the data no matter where it comes from.
As we have just seen, PL/Proxy is basically a way to distribute data across various database nodes. The core question now is: How can we split and partition data in a clever and sensible way? In this book, we have already explained that an alphabetic split might not be the very best of all ideas because data won't be distributed evenly.
Of course, there are many ways to split the data. In this section, we will take a look at a simple and yet useful way, which can be applied to many different scenarios. Let us assume for this example that we want to split data and store it on an array of 16 servers. 16 is a good number because 16 is a power of 2. In computer science, powers of 2 are usually good numbers, and the same applies to PL/Proxy.
The key to evenly dividing your data depends on first turning your text value into an integer:
test=# SELECT 'www.postgresql-support.de'; ?column? --------------------------- www.postgresql-support.de (1 row) test=# SELECT hashtext('www.postgresql-support.de'), hashtext ------------- -1865729388 (1 row)
We can use a PostgreSQL built-in function (not related to PL/Proxy) to hash texts. It will give us an evenly distributed integer number. So, if we hash 1 million rows, we will see evenly distributed hash keys. This is important because we can split data into similar chunks.
Now we can take this integer value and keep just the lower 4 bits:
test=# SELECT hashtext('www.postgresql-support.de')::bit(4); hashtext ---------- 0100 (1 row) test=# SELECT hashtext('www.postgresql-support.de')::bit(4)::int4; hashtext ---------- 4 (1 row)
The final 4 bits are 0100, which are converted back to an integer. This means that this row is supposed to reside on the fifth node (if we start counting at 0).
Using hash keys is by far the simplest way to split up data. It has some nice advantages: If you want to increase the size of your cluster, you can easily just add one more bit without having to rebalance data inside the cluster.
Of course you can always come up with more complicated and sophisticated rules to distribute the data.