
Before we start to replicate our first database we want to dive into Slony's architecture. It is important to understand how this works because otherwise it will be close to impossible to utilize the software in a useful and reasonable way.
In contrast to transaction log streaming, Slony uses logical replication. This means that it does not use internal binary data (such as the XLOG) but a logical representation of the data (in the case of Slony this is text). Using textual data instead of the built-in transaction log has some advantages but also some downsides, which will be discussed in this chapter in detail.
First of all we have to discuss what logical replication really means: The backbone of every Slony setup is the so called changelog triggers. This means that whenever Slony has to replicate the content of a table it will create a trigger. This trigger will then store all changes made to the table in a log. A process called slon will then inspect this changelog and replicate those changes to the consumers. Let us take a look at the basic algorithm:
INSERT INTO table (name, tstamp) VALUES ('hans', now());
trigger fires
('hans', '2013-05-08 13:26:02') as well as some bookkeeping information will be stored in the log table
COMMITAfter some time:
- The
slondaemon will come along and read all changes since the last commit. - All changes will be replayed on the slaves.
- Once this is done the log can be deleted.
The following diagram shows the overall architecture of Slony:
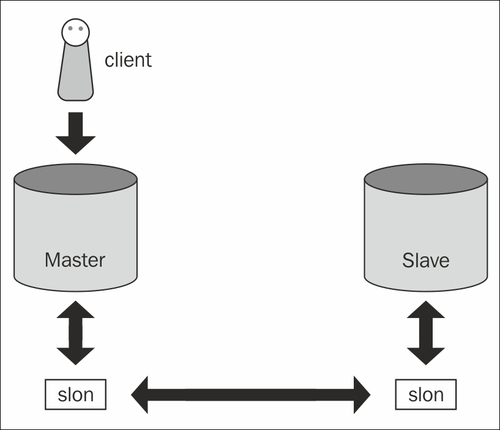
Keep in mind that the transport protocol is pure text. The main advantage here is that there is no need to run the same version of PostgreSQL on every node in the cluster because Slony will abstract the version number. We cannot achieve this with transaction log shipping because in the case of XLOG-based replication all nodes in the cluster must use the very same major version of PostgreSQL.
Because Slony is fairly independent of the PostgreSQL version, it can be used nicely for upgrade purposes.
As we have already stated, the
slon daemon will be in charge of picking up the changes made to a specific table or a set of tables and transporting those changes to the desired destinations.
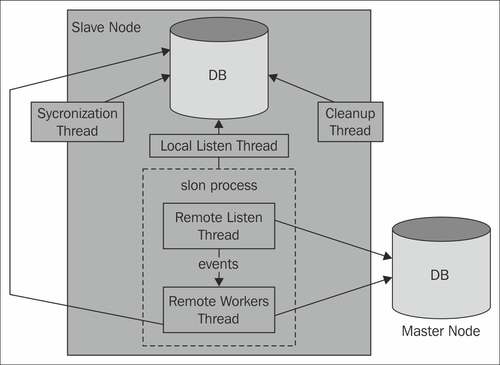
To make this work we have to run exactly one slon daemon per database in our cluster.
As each database will have its own slon daemon, these processes will communicate with each other to exchange and dispatch data. Individual slon daemons can also function as relays and simply pass data on. This is important if you want to replicate data from database A to database C through database B. The idea here is similar to what you can achieve with streaming replication and cascading replicas.
An important thing about Slony is that there is no need to replicate an entire instance or an entire database—replication is always related to a table or to a group of tables. For each table (or for each group of tables) one database will serve as master while as many databases as desired will serve as slaves for this particular set of tables.
It might very well happen that one database is the master of tables A and B and another database will be the master of tables C and D. In other words, Slony allows the replication of data back and forth. Which data has to flow from where to where will be managed by the slon daemon.
The slon daemon itself consists of various threads serving different purposes such as cleanup, listening for events, or applying changes on a server. In addition to that it will perform synchronization-related tasks.
To interface with the slon daemon, you can use a command-line tool called slonik. It will be able to interpret scripts and talk to Slony directly.