
Up to now, you have endured a fair amount of theory. As life does not only consist of theory (as important as it may be), it is definitely the time to dig into practical stuff.
The goal of this chapter is to make you understand how you can recover your database to a given point in time. When your system crashes or when somebody just happens to drop a table accidentally, it is highly important to be able to not replay the entire transaction log but just a fraction of it. Point-In-Time-Recovery will be the tool to do this kind of partial replay of transaction log.
In this chapter, you will learn all you need to know about Point-In-Time-Recovery (PITR) and you will be guided through practical examples. Therefore, we will apply all the concepts you have learned in Chapter 2, Understanding the PostgreSQL Transaction Log, to create some sort of incremental backup or to set up a simple, rudimentary standby system.
Here is an overview of the topics we will deal with in this chapter:
- Understanding the concepts behind PITR
- Configuring PostreSQL for PITR
- Running
pg_basebackup - Recovering PostgreSQL to a certain point in time
PostgreSQL offers a tool called
pg_dump to backup a database. Basically, pg_dump will connect to the database, read all the data in transaction isolation level "serializable" and return the data as text. As we are using "serializable", the dump is always consistent. So, if your pg_dump starts at midnight and finishes at 6 A.M, you will have created a backup, which contains all the data as of midnight but no further data. This kind of snapshot creation is highly convenient and perfectly feasible for small to medium amounts of data.
But, what if your data is so valuable and maybe so large in size that you want to backup it incrementally? Taking a snapshot from time to time might be enough for some applications; for highly critical data, it is clearly not. In addition to that, replaying 20 TB of data in textual form is not efficient either. Point-In-Time-Recovery has been designed to address this problem. How does it work? Based on a snapshot of the database, the XLOG will be replayed later on. This can happen indefinitely or up to a point chosen by you. This way, you can reach any point in time.
This method opens the door to many different approaches and features:
- Restoring a database instance up to a given point in time
- Creating a standby database, which holds a copy of the original data
- Creating a history of all changes
In this chapter, we will specifically feature on the incremental backup functionality and describe how you can make your data more secure by incrementally archiving changes to a medium of choice.
The following picture provides an overview of the general architecture in use for Point-In-Time-Recovery:
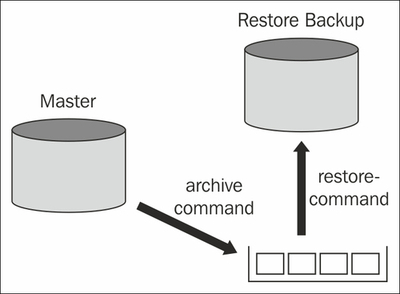
We have seen in the previous chapter that PostgreSQL produces 16 MB segments of transaction log. Every time one of those segments is filled up and ready, PostgreSQL will call the so called
archive_command. The goal of
archive_command is to transport the XLOG file from the database instance to an archive. In our image, the archive is represented as the pot on the bottom-right side of the image.
The beauty of the design is that you can basically use an arbitrary shell script to archive the transaction log. Here are some ideas:
- Use some simple copy to transport data to an NFS share
- Run
rsyncto move a file - Use a custom made script to checksum the XLOG file and move it to an FTP server
- Copy the XLOG file to a tape
The possible options to manage XLOG are only limited by imagination.
The restore_command is the exact counterpart of the archive_command. Its purpose is to fetch data from the archive and provide it to the instance, which is supposed to replay it (in our image, this is labeled as Restored Backup). As you have seen, replay might be used for replication or simply to restore a database to a given point in time as outlined in this chapter. Again, the restore_command is simply a shell script doing whatever you wish, file by file.
Keep in mind, when then
archive_command fails for some reason, PostgreSQL will keep the XLOG file and retry after a couple of seconds. If archiving fails constantly from a certain point on, it might happen that the master fills up. The sequence of XLOG files must not be interrupted; if a single file is missing, you cannot continue to replay XLOG. All XLOG files must be present because PostgreSQL needs an uninterrupted sequence of XLOG files; if a single file is missing, the recovery process will stop there at the very latest.