
As you have already seen in this chapter, setting up streaming replication is really easy. All it takes is to set a handful of parameters, take a base backup, and enjoy your replication setup.
In many cases, however, the situation is a little bit more delicate. Let us assume for this example that we want to use a master to spread data to dozens of servers. The overhead of replication is actually very small (common wisdom says that the overhead of a slave is around 3 percent), but if you do something small often enough, it can still be an issue. It is definitely not too beneficial to the master to have, say, 100 slaves.
An additional use case is having a master in one location and a couple of slaves in some other location. It does not make sense to send a lot of data over a long distance, over and over again. It is a lot better to send it once and dispatch it on the other side.
To make sure that not all servers have to consume the transaction log from a single master, you can make use of a cascaded replication. Cascading means that a master can stream its transaction log to a slave, which will then serve as dispatcher and stream the transaction log to further slaves.
The following image illustrates the basic architecture:
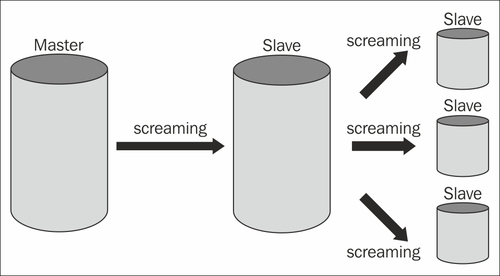
The slaves at the far edge of the image could serve as dispatchers again. With this very simple method, you can basically create a system of infinite size.
The procedure to set things up is basically the same as setting up a single slave. You can easily take base backups from an operational slave (postgresql.conf and pg_hba.conf have to be configured just like in the case of a single master).