
Let's look at the previous hypermarket example from a different angle. To handle a lot of customers without long queues and without having to close the shop, the hypermarket employs more than one cashier and installs as many (or even more) cash registers.
This way, if a cash register goes wrong, the cashier can simply close it and sit at another one and the waiting customers can be redirected to the new cash register. The customers don't have to wait too much and the faulty cash register can be repaired while the hypermarket is operational. This is not at all different from software and computer technology, only the events (client programs waiting for data) are done in a much, much shorter time.
This example shows that the most important aspect of designing a cluster is maintaining redundancy at every possible level of the system to avoid single points of failure. One example of this is network connections. Consider two data centers away from each other and a cluster containing computers from both sites. The maintainers of the cluster have subscribed to two Internet Service Providers to provide redundant network connection between them. However, if the cables used by the two providers are buried in the same trench, a caterpillar doing earthworks can damage both at once. This is actually a single point of failure.
Let's see what redundancy means for a small cluster with two machines.
At a minimum, the system has to have two of everything:
- Two servers
- Two connections, one for the public network and one for direct communication between the two servers
- Two Ethernet cables for every connection
- Two switches for every connection
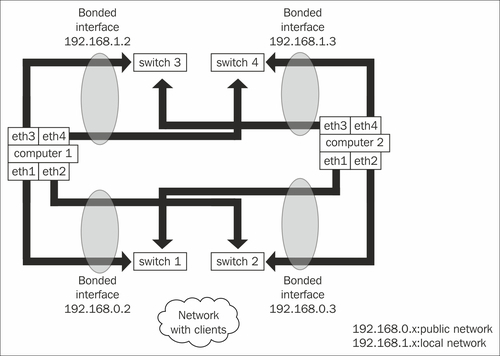
In our example, the nodes have four Ethernet interfaces, each of which is connected to a switch. Two Ethernet interfaces are bonded into one interface at the operating system level, so they have a common IP address. The nodes are connected to the public network using the 192.168.0.x IP address range and also have a private, direct connection between the servers using the 192.168.1.x range. Hardware can go wrong, so one way to avoid the single point of failure is to tie two simple Ethernet interfaces into a higher-level network interface using bonding. This feature can provide higher throughput when everything is working but the point really is to provide higher reliability. The communication still works when one of the switches between the machines or one of the low-level Ethernet interfaces inside one of the servers goes wrong.