
In this chapter, we want to focus our attention on a write-scalable, multimaster, synchronous, symmetric, and transparent replication solution for PostgreSQL called Postgres-XC (PostgreSQL eXtensible Cluster). The goal of the project is to provide the end user with a transparent replication solution, which allows higher levels of loads by horizontally scaling to multiple servers.
In an array of servers running Postgres-XC, you can connect to any node inside the cluster. The system will perfectly make sure that you will exactly get the same view of the data on every single node. This is highly important as it solves a handful of problems on the client side. There is no need to add logic to those applications that write to just one node. You can simply balance your load easily; data is always instantly visible on all nodes after a transaction commits.
The most important thing to keep in mind when considering Postgres-XC is that it is not an add-on to PostgreSQL, it is a code fork. So, it does not use Vanilla PostgreSQL version numbers, and the code base will usually lag behind the official PostgreSQL source tree.
This chapter will provide you with information about Postgres-XC. We will cover the following topics in this chapter:
- The Postgres-XC architecture
- Installing Postgres-XC
- Configuring a cluster
- Optimizing the storage
- Performance management
- Adding and dropping nodes
Before we dive head-on into Postgres-XC installation and ultimately into configuration, we have to take a deep look at the basic system architecture of this marvelous piece of software:
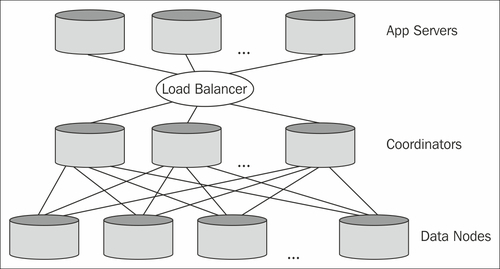
In general, a Postgres-XC system consists of the following essential components:
- Data nodes
- GTM (Global Transaction Manager)
- Coordinator
- GTM Proxy
Let's take a look at the purpose of each of those components.
A data node is the actual storage backbone of the system. It will hold all or a fraction of the data inside the cluster. It is connected to the Postgres-XC infrastructure and will handle the local SQL execution.
The GTM will provide the cluster with a consistent view of the data. A consistent view of the data is necessary because otherwise it would be impossible to load-balance in an environment that is totally transparent to the application.
A consistent view is provided through a cluster-wide snapshot. In addition to that, the GTM will create Global Transaction IDs (GXID). Those GXIDs are essential because transactions must be coordinated cluster-wide.
Beside this core functionality, the GTM will also handle global values for stuff such as sequences, and so on.
The Coordinators are a piece of software serving as an entry point for our applications. An application will connect to one of the Coordinators. It will be in charge of the SQL analysis, global execution plan creation, and global SQL execution.
The GTM Proxy can be used to improve the performance. Given the Postgres-XC architecture, each transaction has to issue a request to the GTM. In many cases, this can lead to latency, and subsequently to performance issues. The GTM Proxy will step in and collect requests to the GTM into blocks of requests and send them together.
One advantage here is that connections can be cached to avoid a great deal of overhead caused by opening and closing of connections all the time.