
Setting up your cluster is not the only task you will face. If things are up and running, you might have to tweak things here and there.
Once a cluster has been up and running, you might figure out that your cluster is too small and that it is not able to handle the load generated by your client applications. In this case, it might be necessary to add hardware to the setup. The question is: How can this be done in the most intelligent way?
The best thing you can do is to create more partitions than needed straight away. So, if you consider getting started with four nodes or so, we create sixteen partitions straight away and run four partitions per server. Extending your cluster will be pretty easy in this case:
- Replicating all the productive nodes
- Reconfiguring PL/Proxy to move the partitions
- Dropping unnecessary partitions from the old nodes
To replicate those existing nodes, you can simply use technologies outlined in this book such as streaming replication, londiste, or Slony.
The main point here is how can you tell PL/Proxy that a partition has moved from one server to some other server?
ALTER SERVER samplecluster
OPTIONS (SET partition_0
'dbname=p4 host=localhost'),In this case, we have moved the first partition from p0 to p4. Of course, the partition can also reside on some other host; PL/Proxy will not care which server it has to go to fetch the data. You just have to make sure that the target database has all the tables in place and you have to ensure that PL/Proxy can reach this database.
Adding partitions is not hard on the PL/Proxy side either. Just as before, you can simply use ALTER SERVER to modify your partition list:
ALTER SERVER samplecluster
OPTIONS (
ADD partition_4 'dbname=p5 host=localhost',
ADD partition_5 'dbname=p6 host=localhost',
ADD partition_6 'dbname=p7 host=localhost',
ADD partition_7 'dbname=p8 host=localhost'),As we have already mentioned, adding those partitions is trivial; however, doing it in practice is really hard. The reason is: How should you handle your old data, which is already in the database? Moving data around inside your cluster is not funny at all, and it can result in a high system usage during system rebalancing, and in addition to that, it can be pretty error prone to move data around during production.
Basically there are just two ways out. You can make your partitioning function cleverer and make it treat the new data differently than the old data; however, this can be error prone and will add a lot of complexity and legacy to your system. A cleverer way is to think ahead and create enough partitions straight away.
Tip
If you increase the size of your cluster, we strongly suggest doubling the size of the cluster straight away. The beauty of this is that you need just one more bit in your hash key; if you move from four to, say, five nodes, there is usually no way to grow the cluster without having to move a large amount of data around. You want to avoid rebalancing data at any cost.
PL/Proxy is a highly scalable infrastructure to handle arrays of servers. But what happens if a server fails? The more boxes you have in your system, the more likely it will be that one of those boxes fails.
To protect yourself against these kinds of issues, you can always turn to streaming replication and Linux HA to make each partition more failsafe. An architecture might look as follows:
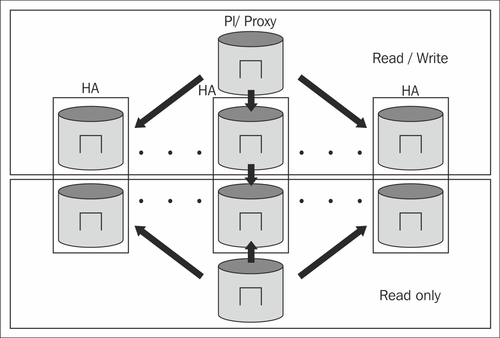
Each node can have its own replica and therefore we can failover each node separately. The good thing about this infrastructure is that you can scale out your reads while you can improve availability at the same time.
The machines in the read-only area of the cluster will provide your system with some extra performance.
If you are dealing with a lot of data (terabytes or more), using integrity constraints might not be the best idea of all. The reason for that is that checking the foreign keys on every write on the database is fairly expensive and might not be worth the overhead. So, it might be better to take precautions within your application to prevent wrong data from reaching the database at all. Keep in mind this is not just about inserting, it is also about updates and deletes.
One important thing about PL/Proxy is that you cannot simply use foreign keys out of the box. Let us assume you have got two tables, which are in a 1:n relationship. If you want to partition the right side of the equation, you will also have to partition the other side. Otherwise, the data you want to reference will simply be in some other database. An alternative would be simply to fully replicate the referenced tables.
In general, it has proven to be fairly beneficial to just avoid foreign key implementations because it needs a fair amount of trickery to get foreign keys right.
From time to time, it might be necessary to update or upgrade PostgreSQL and PL/Proxy. Upgrading PL/Proxy is the simpler part of the problem. The reason for that is that PL/Proxy is usually installed as a PostgreSQL extension. CREATE EXTENSION offers all the functionality to upgrade the infrastructure on the servers running PL/Proxy:
test=# h CREATE EXTENSION
Command: CREATE EXTENSION
Description: install an extension
Syntax:
CREATE EXTENSION [ IF NOT EXISTS ] extension_name
[ WITH ] [ SCHEMAschema_name ]
[ VERSIONversion ]
[ FROMold_version ]What you have to do is to run CREATE EXTENSION with a target version and define the version you want to upgrade from. All the rest will happen behind the scenes automatically.
If you want to upgrade a database partition from one PostgreSQL version to the next major release (minor releases will only need a simple restart of the node), it is a little bit more complicated. When running PL/Proxy, it is safe to assume that the amount of data in your system is so large that doing a simple dump/reload is out of the question because you would simply face far too much downtime.
To get around this problem, it is usually necessary to come up with an upgrade policy based on replication. You can use Slony or londiste to create yourself a logical replica of the old server on some new server and then just tell PL/Proxy to connect to the new version when the replica has fully caught up. The advantage of using Slony or londiste here is that both solutions can replicate between different versions of PostgreSQL nicely.
Just as we have seen before, you can move a partition to a new server by calling ALTER SERVER. This way you can replicate and upgrade one server after the other and gradually move to a more recent PostgreSQL version in a risk and downtime free manner.