
Appendix B. JavaScript for object-oriented programmers
There are many routes into becoming a JavaScript programmer, ranging from graphic design to a serious programmer coming up from the business tiers.
This appendix won’t aim to teach you how to program in JavaScript—there are already many good books and articles to help you do that. What I intend to record here are a few core concepts that will help Java and C# programmers make the leap to JavaScript programming in a relatively painless way. (The same is true to a lesser extent of C++ programmers, but C++ inherits a lot of strange flexibility from C, so that JavaScript should prove less of a shock to the system.) If you are a serious enterprise programmer with a grounding in OO design principles, then your first approaches to JavaScript may be overly influenced by your experience with languages such as Java and C#, and you may find yourself fighting against the language rather than working with it. I certainly did, and I’ve based this on my own experience as a programmer and in mentoring others along the same route.
JavaScript can do a lot of clever things that Java and C# can’t. Some of these can help you to write better code, and some can only help you to shoot yourself in the foot more accurately! It’s worth knowing about both, either to make use of the techniques or to avoid doing them unwittingly. If you are coming to Ajax from a structured OO language such as Java or C++, then I hope that reading this appendix will help you as much as I think it would have helped me a few years back!
B.1. JavaScript is not Java
What’s in a name? In the case of Java and JavaScript, a lot of marketing and relatively little substance. JavaScript was renamed from “livescript” at the last minute by Netscape’s marketing department, and now the name has stuck. Contrary to popular perception, JavaScript is not a descendent of the C family of languages. It owes a lot more to functional languages such as Scheme and Self, and it has quite a lot in common with Python, too. Unfortunately, it’s been named after Java and syntactically styled to look like Java. In places, it will behave like Java, but in many places, it just plain won’t.
Table B.1 summarizes the key differences.
Table B.1. Key features of JavaScript and their implications
|
Feature |
Implications |
|---|---|
| Variables are loosely typed. | Variables are just declared as variables, not as integers, strings, or objects of a specific class. In JavaScript, it is legal to assign values of different types to the same variable. |
| Code is dynamically interpreted. | At runtime, code is stored as text and interpreted into machine instructions as the program runs, in contrast to precompiled languages such as Java, C, and C#. Users of your website can generally see the source code of your Ajax application. Furthermore, it allows for the possibility of code being generated dynamically by other code without resorting to special bytecode generators. |
| JavaScript functions are first-class objects. | A Java object’s methods are tied to the object that owns them and can be invoked only via that object. JavaScript functions can be attached to objects so that they behave like methods, but they can also be invoked in other contexts and/or reattached to other objects at runtime. |
| JavaScript objects are prototype-based. | A Java, C++, or C# object has a defined type, with superclasses and virtual superclasses or interfaces. This strictly defines its functionality. Any JavaScript object is just an object, which is just an associative array in disguise. Prototypes can be used to emulate Java-style types in JavaScript, but the similarity is only skin deep. |
These differences allow the language to be used in different ways and open up the possibility of a number of weird tricks worthy of a seasoned Lisp hacker. If you’re a really clever, disciplined coder, you can take advantage of these tricks to do marvelous things, and you might even do so beyond a few hundred lines of code. If, on the other hand, you only think you’re really clever and disciplined, you can quickly end up flat on your face.
I’ve tried it a few times and come to the conclusion that keeping things simple is generally a good thing. If you’re working with a team, coding standards or guidelines should address these issues if the technical manager feels it is appropriate.
However, there is a second reason for knowing about these differences and tricks: the browser will use some of them internally, so understanding what is going on can save you much time and pain in debugging a badly behaved application. In particular, I’ve found it helpful to know where the code is not behaving like a Java object would, given that much of the apparent similarity is only apparent.
So read on, and find out what JavaScript objects really look like when the lights are out, how they are composed of member fields and functions, and what a JavaScript function is really capable of.
B.2. Objects in JavaScript
JavaScript doesn’t require the use of objects or even functions. It is possible to write a JavaScript program as a single stream of text that is executed directly as it is read by the interpreter. As a program gets bigger, though, functions and objects become a tremendously useful way of organizing your code, and we recommend you use both.
The simplest way to create a new JavaScript object is to invoke the built-in constructor for the Object class:
var myObject=new Object();
We’ll look at other approaches, and what the new keyword really does, in section B.2.2. Our object myObject is initially “empty,” that is, it has no properties or methods. Adding them in is quite simple, so let’s see how to do it now.
B.2.1. Building ad hoc objects
As already noted, the JavaScript object is essentially just an associative array, with fields and methods keyed by name. A C-like syntax is slapped on top to make it look familiar to C-family programmers, but the underlying implementation can be exploited in other ways, too. We can build up complex objects line by line, adding new variables and functions as we think of them.
There are two ways of building up objects in this ad hoc fashion. The first of these is to simply use JavaScript to create the object. The second is to use a special notation known as JSON. Let’s start with the plain old JavaScript technique.
Using JavaScript statements
In the middle of a complicated piece of code, we may want to assign a value to some object’s property. JavaScript object properties are read/write and can be assigned by the = operator. Let’s add a property to our simple object:
myObject.shoeSize="12";
In a structured OO language, we would need to define a class that declared a property shoeSize or else suffer a compiler error. Not so with JavaScript. In fact, just to emphasize the array-like nature, we can also reference properties using array syntax:
myObject['shoeSize']="12";
This notation is clumsy for ordinary use but has the advantage that the array index is a JavaScript expression, offering a form of runtime reflection, which we’ll return to in section B.2.4.
We can also add a new function to our object dynamically:
myObject.speakYourShoeSize=function(){
alert("shoe size : "+this.shoeSize);
}
Or borrow a predefined function:
function sayHello(){
alert('hello, my shoeSize is '+this.shoeSize);
}
...
myObject.sayHello=sayHello;
Note that in assigning the predefined function, we omit the parentheses. If we were to write
myObject.sayHello=sayHello();
then we would execute the sayHello function and assign the return value, in this case null, to the sayHello property of myObject.
We can attach objects to other objects in order to build up complex data models and so on:
var myLibrary=new Object(); myLibrary.books=new Array(); myLibrary.books[0]=new Object(); myLibrary.books[0].title="Turnip Cultivation through the Ages"; myLibrary.books[0].authors=new Array(); var jim=new Object(); jim.name="Jim Brown"; jim.age=9; myLibrary.books[0].authors[0]=jim;
This can quickly become tedious (often the case where turnips are involved, I’m afraid), and JavaScript offers a compact notation that we can use to assemble object graphs more quickly, known as JSON. Let’s have a look at it now.
Using JSON
The JavaScript Object Notation (JSON) is a core feature of the language. It provides a concise mechanism for creating arrays and object graphs. In order to understand JSON, we need to know how JavaScript arrays work, so let’s cover the basics of them first.
JavaScript has a built-in Array class that can be instantiated using the new keyword:
myLibrary.books=new Array();
Arrays can have values assigned to them by number, much like a conventional C or Java array:
myLibrary.books[4]=somePredefinedBook;
Or they can be associated with a key value, like a Java Map or Python Dictionary, or, indeed, any JavaScript Object:
myLibrary.books["BestSeller"]=somePredefinedBook;
This syntax is good for fine-tuning, but building a large array or object in the first place can be tedious. The shorthand for creating a numerically indexed array is to use square braces, with the entries being written as a comma-separated list of values, thus:
myLibrary.books=[predefinedBook1,predefinedBook2,predefinedBook3];
And to build a JavaScript Object, we use curly braces, with each value written as a key:value pair:
myLibrary.books={
bestSeller : predefinedBook1,
cookbook : predefinedBook2,
spaceFiller : predefinedBook3
};
In both notations, extra white space is ignored, allowing us to pretty-print for clarity. Keys can also have spaces in them, and can be quoted in the JSON notation, for example:
"Best Seller" : predefinedBook1,
We can nest JSON notations to create one-line definitions of complex object hierarchies (albeit rather a long line):
var myLibrary={
location : "my house",
keywords : [ "root vegetables", "turnip", "tedium" ],
books: [
{
title : "Turnip Cultivation through the Ages",
authors : [
{ name: "Jim Brown", age: 9 },
{ name: "Dick Turnip", age: 312 }
],
publicationDate : "long ago"
},
{
title : "Turnip Cultivation through the Ages, vol. 2",
authors : [
{ name: "Jim Brown", age: 35 }
],
publicationDate : new Date(1605,11,05)
}
]
};
I have assigned three properties to the myLibrary object here: location is a simple string, keywords is a numerical list of strings, and books a numerically indexed list of objects, each with a title (a string), a publication date (a JavaScript Date object in one case and a string in the other), and a list of authors (an array). Each author is represented by a name and age parameter. JSON has provided us with a concise mechanism for creating this information in a single pass, something that would otherwise have taken many lines of code (and greater bandwidth).
Sharp-eyed readers will have noted that we populated the publication date for the second book using a JavaScript Date object. In assigning the value we can use any JavaScript code, in fact, even a function that we defined ourselves:
function gunpowderPlot(){
return new Date(1605,11,05);
}
var volNum=2;
var turnipVol2={
title : "Turnip Cultivation through the Ages, vol. "
+volNum,
authors : [
{ name: "Jim Brown", age: 35 }
],
publicationDate : gunpowderPlot()
}
]
};
Here the title of the book is calculated dynamically by an inline expression, and the publicationDate is set to the return value from a predefined function.
In the previous example, we defined a function gunpowderPlot() that was evaluated at the time the object was created. We can also define member functions for our JSON-invoked objects, which can be invoked later by the object:
var turnipVol2={
title : "Turnip Cultivation through the Ages, vol. "+volNum,
authors : [
{ name: "Jim Brown", age: 35 }
],
publicationDate : gunpowderPlot()
}
],
summarize:function(len){
if (!len){ len=7; }
var summary=this.title+" by "
+this.authors[0].name
+" and his cronies is very boring. Z";
for (var i=0;i<len;i++){
summary+="z";
}
alert(summary);
}
};
...
turnipVol2.summarize(6);
The summarize() function has all the features of a standard JavaScript function, such as parameters and a context object identified by the keyword this. Indeed, once the object is created, it is just another JavaScript object, and we can mix and match the JavaScript and JSON notations as we please. We can use JavaScript to fine-tune an object declared in JSON:
var numbers={ one:1, two:2, three:3 };
numbers.five=5;
We initially define an object using JSON syntax and then add to it using plain JavaScript. Equally, we can extend our JavaScript-created objects using JSON:
var cookbook=new Object();
cookbook.pageCount=321;
cookbook.author={
firstName: "Harry",
secondName: "Christmas",
birthdate: new Date(1900,2,29),
interests: ["cheese","whistling",
"history of lighthouse keeping"]
};
With the built-in JavaScript Object and Array classes and the JSON notation, we can build object hierarchies as complicated as we like, and we could get by with nothing else. JavaScript also offers a means for creating objects that provides a comforting resemblance to class definitions for OO programmers, so let’s look at this next and see what it can offer us.
B.2.2. Constructor functions, classes, and prototypes
In OO programming, we generally create objects by stating the class from which we want them to be instantiated. Both Java and JavaScript support the new keyword, allowing us to create instances of a predefined kind of object. Here the similarity between the two ends.
In Java, everything (bar a few primitives) is an object, ultimately descended from the java.lang.Object class. The Java virtual machine has a built-in understanding of classes, fields, and methods, and when we declare in Java
MyObject myObj=new MyObject(arg1,arg2);
we first declare the type of the variable and then instantiate it using the relevant constructor. The prerequisite for success is that the class MyObject has been declared and offers a suitable constructor.
JavaScript, too, has a concept of objects and classes but no built-in concept of inheritance. In fact, every JavaScript object is really an instance of the same base class, a class that is capable of binding member fields and functions to itself at runtime. So, it is possible to assign arbitrary properties to an object on the fly:
MyJavaScriptObject.completelyNewProperty="something";
This free-for-all can be organized into something more familiar to the poor OO developer by using a prototype, which defines properties and functions that will automatically be bound to an object when it is constructed using a particular function. It is possible to write object-based JavaScript without the use of prototypes, but they offer a degree of regularity and familiarity to OO developers that is highly desirable when coding complex rich-client applications.
In JavaScript, then, we can write something that looks similar to the Java declaration
var myObj=new MyObject();
but we do not define a class MyObject, but rather a function with the same name. Here is a simple constructor:
function MyObject(name,size){
this.name=name;
this.size=size;
}
We can subsequently invoke it as follows:
var myObj=new MyObject("tiddles","7.5 meters");
alert("size of "+myObj.name+" is "+myObj.size);
Anything set as a property of this in the constructor is subsequently available as a member of the object. We might want to internalize the call to alert() as well, so that tiddles can take responsibility for telling us how big it is. One common idiom is to declare the function inside the constructor:
function MyObject(name,size){
this.name=name;
this.size=size;
this.tellSize=function(){
alert("size of "+this.name+" is "+this.size);
}
}
var myObj=new Object("tiddles","7.5 meters");
myObj.tellSize();
This works, but is less than ideal in two respects. First, for every instance of MyObject that we create, we create a new function. As responsible Ajax programmers, memory leaks are never far from our minds (see chapter 7), and if we plan on creating many such objects, we should certainly avoid this idiom. Second, we have accidentally created a closure here—in this case a fairly harmless one—but as soon as we involve DOM nodes in our constructor, we can expect more serious problems. We’ll look at closures in more detail later in this appendix. For now, let’s look at the safer alternative, which is something known as a prototype.
A prototype is a property of JavaScript objects, for which no real equivalent exists in OO languages. Functions and properties can be associated with a constructor’s prototype. The prototype and new keyword will then work together, and, when a function is invoked by new, all properties and methods of the prototype for the function are attached to the resulting object. That sounds a bit strange, but it’s simple enough in action:
function MyObject(name,size){
this.name=name;
this.size=size;
}
MyObject.prototype.tellSize=function(){
alert("size of "+this.name+" is "+this.size);
}
var myObj=new MyObject("tiddles","7.5 meters");
myObj.tellSize();
First, we declare the constructor as before, and then we add functions to the prototype. When we create an instance of the object, the function is attached. The keyword this resolves to the object instance at runtime, and all is well.
Note the ordering of events here. We can refer to the prototype only after the constructor function is declared, and objects will inherit from the prototype only what has already been added to it before the constructor is invoked. The prototype can be altered between invocations to the constructor, and we can attach anything to the prototype, not just a function:
MyObject.prototype.color="red"; var obj1=new MyObject(); MyObject.prototype.color="blue"; MyObject.prototype.soundEffect="boOOOoing!!"; var obj2=new MyObject();
obj1 will be red, with no sound effect, and obj2 will be blue with an annoyingly cheerful sound effect! There is generally little value in altering prototypes on the fly in this way. It’s useful to know that such things can happen, but using the prototype to define class-like behavior for JavaScript objects is the safe and sure route.
Interestingly, the prototype of certain built-in classes (that is, those implemented by the browser and exposed through JavaScript, also known as host objects) can be extended, too. Let’s have a look at how that works now.
B.2.3. Extending built-in classes
JavaScript is designed to be embedded in programs that can expose their own native objects, typically written in C++ or Java, to the scripting environment. These objects are usually described as built-in or host objects, and they differ in some regards to the user-defined objects that we have discussed so far. Nonetheless, the prototype mechanism can work with built-in classes, too. Within the web browser, DOM nodes cannot be extended in the Internet Explorer browser, but other core classes work across all major browsers. Let’s take the Array class as an example and define a few useful helper functions:
Array.prototype.indexOf=function(obj){
var result=-1;
for (var i=0;i<this.length;i++){
if (this[i]==obj){
result=i;
break;
}
}
return result;
}
This provides an extra function to the Array object that returns the numerical index of an object in a given array, or -1 if the array doesn’t contain the object. We can build on this further, writing a convenience method to check whether an array contains an object:
Array.prototype.contains=function(obj){
return (this.indexOf(obj)>=0);
}
and then add another function for appending new members after optionally checking for duplicates:
Array.prototype.append=function(obj,nodup){
if (!(nodup && this.contains(obj))){
this[this.length]=obj;
}
}
Any Array objects created after the declaration of these functions, whether by the new operator or as part of a JSON expression, will be able to use these functions:
var numbers=[1,2,3,4,5];
var got8=numbers.contains(8);
numbers.append("cheese",true);
As with the prototypes of user-defined objects, these can be manipulated in the midst of object creation, but I generally recommend that the prototype be modified once only at the outset of a program, to avoid unnecessary confusion, particularly if you’re working with a team of programmers.
Prototypes can offer us a lot, then, when developing client-side object models for our Ajax applications. A meticulous object modeler used to C++, Java, or C# may not only want to define various object types but to implement inheritance between types. JavaScript doesn’t offer this out of the box, but the prototype can come in useful here, too. Let’s find out how.
B.2.4. Inheritance of prototypes
Object orientation provides not only support for distinct object classes but also a structured hierarchy of inheritance between them. The classic example is the Shape object, which defines methods for computing perimeter and area, on top of which we build concrete implementations for rectangles, squares, triangles, and circles.
With inheritance comes the concept of scope. The scope of an object’s methods or properties determines who can use it—that is, whether it is public, private, or protected.
Scope and inheritance can be useful features when defining a domain model. Unfortunately, JavaScript doesn’t support either natively. That hasn’t stopped people from trying, however, and some fairly elegant solutions have developed.
Doug Crockford (see the Resources section at the end of this appendix) has developed some ingenious workarounds that enable both inheritance and scope in JavaScript objects. What he has accomplished is undoubtedly impressive and, unfortunately, too involved to merit a detailed treatment here. The syntax that his techniques require can be somewhat impenetrable to the casual reader, and in a team-based project, adopting such techniques should be considered similar to adopting a Java framework of the size and complexity of Struts or Tapestry—that is, either everybody uses it or nobody does. I urge anyone with an interest in this area to read the essays on Crockford’s website.
Within the world of object orientation, there has been a gradual move away from complex use of inheritance and toward composition. With composition, common functionality is moved out into a helper class, which can be attached as a member of any class that needs it. In many scenarios, composition can provide similar benefits to inheritance, and JavaScript supports composition perfectly adequately.
The next stop in our brief tour of JavaScript objects is to look at reflection.
B.2.5. Reflecting on JavaScript objects
In the normal course of writing code, the programmer has a clear understanding of how the objects he is dealing with are composed, that is, what their properties and methods do. In some cases, though, we need to be able to deal with completely unknown objects and discover the nature of their properties and methods before dealing with them. For example, if we are writing a logging or debugging system, we may be required to handle arbitrary objects dumped on us from the outside world. This discovery process is known as reflection, and it should be familiar to most Java and .NET programmers.
If we want to find out whether a JavaScript object supports a certain property or method, we can simply test for it:
if (MyObject.someProperty){
...
}
This will fail, however, if MyObject.someProperty has been assigned the boolean value false, or a numerical 0, or the special value null. A more rigorous test would be to write
if (typeof(MyObject.someProperty) != "undefined"){
If we are concerned about the type of the property, we can also use the instanceof operator. This recognizes a few basic built-in types:
if (myObj instanceof Array){
...
}else if (myObj instanceof Object){
...
}
as well as any class definitions that we define ourselves through constructors:
if (myObj instanceof MyObject){
...
}
If you do like using instanceof to test for custom classes, be aware of a couple of “gotchas.” First, JSON doesn’t support it—anything created with JSON is either a JavaScript Object or an Array. Second, built-in objects do support inheritance among themselves. Function and Array, for example, both inherit from Object, so the order of testing matters. If we write
function testType(myObj){
if (myObj instanceof Array){
alert("it's an array");
}else if (myObj instanceof Object){
alert("it's an object");
}
}
testType([1,2,3,4]);
and pass an Array through the code, we will be told—correctly—that we have an Array. If, on the other hand, we write
function testType(myObj){
if (myObj instanceof Object){
alert("it's an object");
}else if (myObj instanceof Array){
alert("it's an array");
}
}
testType([1,2,3,4]);
then we will be told that we have an Object, which is also technically correct but probably not what we intended.
Finally, there are times when we may want to exhaustively discover all of an object’s properties and functions. We can do this using the simple for loop:
function MyObject(){
this.color='red';
this.flavor='strawberry';
this.azimuth='45 degrees';
this.favoriteDog='collie';
}
var myObj=new MyObject();
var debug="discovering...
";
for (var i in myObj){
debug+=i+" -> "+myObj[i]+"
";
}
alert(debug);
This loop will execute four times, returning all the values set in the constructor. The for loop syntax works on built-in objects, too—the simple debug loop above produces very big alert boxes when pointed at DOM nodes! A more developed version of this technique is used in the examples in chapters 5 and 6 to develop the recursive ObjectViewer user interface.
There is one more feature of the conventional object-oriented language that we need to address—the virtual class or interface. Let’s look at that now.
B.2.6. Interfaces and duck typing
There are many times in software development when we will want to specify how something behaves without providing a concrete implementation. In the case of our Shape object being subclassed by squares, circles, and so on, for example, we know that we will never hold a shape in our hands that is not a specific type of shape. The base concept of the Shape object is a convenient abstraction of common properties, without a real-world equivalent.
A C++ virtual class or a Java interface provides us with the necessary mechanism to define these concepts in code. We often speak of the interface defining a contract between the various components of the software. With the contract in place, the author of a Shape-processing library doesn’t need to consider the specific implementations, and the author of a new implementation of Shape doesn’t need to consider the internals of any library code or any other existing implementations of the interface.
Interfaces provide good separation of concerns and underpin many design patterns. If we’re using design patterns in Ajax, we want to use interfaces. JavaScript has no formal concept of an interface, so how do we do it?
The simplest approach is to define the contract informally and simply rely on the developers at each side of the interface to know what they are doing. Dave Thomas has given this approach the engaging name of “duck typing”—if it walks like a duck and it quacks like a duck, then it is a duck. Similarly with our Shape interface, if it can compute an area and a perimeter, then it is a shape.
Let’s suppose that we want to add the area of two shapes together. In Java, we could write
public double addAreas(Shape s1, Shape s2){
return s1.getArea()+s2.getArea();
}
The method signature specifically forbids us from passing in anything other than a shape, so inside the method body, we know we’re following the contract. In JavaScript, our method arguments aren’t typed, so we have no such guarantees:
function addAreas(s1,s2){
return s1.getArea()+s2.getArea();
}
If either object doesn’t have a function getArea() attached to it, then we will get a JavaScript error. We can check for the presence of the function before we call it:
function hasArea(obj){
return obj && obj.getArea && obj.getArea instanceof Function;
}
and modify our function to make use of the check:
function addAreas(s1,s2){
var total=null;
if (hasArea(s1) && hasArea(s2)){
total=s1.getArea()+s2.getArea();
}
return total;
}
Using JavaScript reflection, in fact, we can write a generic function to check that an object has a function of a specific name:
function implements(obj,funcName){
return obj && obj[funcName] && obj[funcName] instanceof Function;
}
Or, we can attach it to the prototype for the Object class:
Object.prototype.implements=function(funcName){
return this && this[funcName] && this[funcName] instanceof Function;
}
That allows us to check specific functions by name:
function hasArea(obj){
return obj.implements("getArea");
}
or even to test for compliance with an entire interface:
function isShape(obj){
return obj.implements("getArea") && obj.implements("getPerimeter");
}
This gives us some degree of safety, although still not as much as we would get under Java. A rogue object might implement getArea() to return a string rather than a numerical value, for example. We have no way of knowing the return type of a JavaScript function unless we call it, because JavaScript functions have no predefined type. (Indeed, we could write a function that returns a number during the week and a string on weekends.) Writing a set of simple test functions to check return types is easy enough; for example:
function isNum(arg){
return parseFloat(arg)!=NaN;
}
NaN is short for “not a number,” a special JavaScript variable for handling number format errors. This function will actually return true for strings if they begin with a numeric portion, in fact. parseFloat() and its cousin parseInt() will try their best to extract a recognizable number where they can. parseFloat("64 hectares") will evaluate to 64, not NaN.
We could firm up our addAreas() function a little further:
function addAreas(s1,s2){
var total=null;
if (hasArea(s1) && hasArea(s2)){
var a1=s1.getArea();
var a2=s2.getArea();
if (isNum(a1) && isNum(a2)){
total=parseFloat(a1)+parseFloat(a2);
}
}
return total;
}
I call parseFloat() on both arguments to correctly handle strings that slip through the net. If s1 returns a value of 32 and s2 a value of 64 hectares, then addAreas() will return 96. If I didn’t use parseFloat, I’d get a misleading value of 3264 hectares!
In summary, duck typing keeps things simple but requires you to trust your development team to keep track of all the details. Duck typing is popular among the Ruby community, who are generally a very smart bunch. As one moves from a single author or small tightly bound team to larger projects involving separate subgroups, this trust inevitably weakens. If you want to add a few checks and balances to your code on top of duck typing, then perhaps this section will have shown you where to start.
We’ve looked at the language from the point of view of objects. Now let’s drill down a little to look at these functions that we’ve been throwing around and see what they really are.
B.3. Methods and functions
We’ve been defining functions and calling them in the previous section and in the rest of this book. A Java or C# programmer might have assumed that they were something like a method, defined with a slightly funny-looking syntax. In this section, we’ll take functions apart a bit more and see what we can do with them.
B.3.1. Functions as first-class citizens
Functions are a bit like Java methods in that they have arguments and return values when invoked, but there is a key difference. A Java method is inherently bound to the class that defined it and cannot exist apart from that class. A JavaScript function is a free-floating entity, a first-class object in its own right. (Static Java methods lie somewhere in between these two—they are not bound to any instance of an object but are still attached to a class definition.)
Programmers who have worked their way through the C family may think “Ah, so it’s like a function pointer in C++, then.” It is indeed, but that’s not the end of it.
In JavaScript, Function is a type of built-in object. As expected, it contains executable code, and can be invoked, but it is also a descendant of Object, and can do everything that a JavaScript object can, such as storing properties by name. It is quite possible (and quite common) for a Function object to have other Function objects attached to it as methods.
We’ve already seen how to get a reference to a Function object. More usually, we would want to reference a function and invoke it in a single line, such as
var result=MyObject.doSomething(x,y,z)
However, the Function is a first-class object, and it can also be executed via the call() method (and its close cousin apply()):
var result=MyObject.doSomething.call(MyOtherObject,x,y,z)
or even
var result=MyObject['doSomething'].call(MyOtherObject,x,y,z)
The first argument of Function.call() is the object that will serve as the function context during the invocation, and subsequent arguments are treated as arguments to the function call. apply() works slightly differently in that the second argument is an array of arguments to pass to the function call, allowing greater flexibility in programmatically calling functions whose argument list length is undetermined.
It’s worth pointing out here that the argument list to a JavaScript function is not of a fixed length. Calling a Java or C# method with more or fewer arguments than it declares would generate a compile-time error. JavaScript just ignores any extra args and assigns undefined to missing ones. A particularly clever function might query its own argument list through the arguments property and assign sensible defaults to missing values, throw an exception, or take any other remedial action. This can be exploited to combine a getter and setter method into a single function, for example:
function area(value){
if (value){
this.area=value;
}
return this.area;
}
If we simply call area(), then value is undefined, so no assignment takes place, and our function acts as a getter. If a value is passed in, our function acts as a setter. This technique is used extensively by Mike Foster’s x library (see the Resources section at the end of this chapter, and also chapter 3), so if you plan on working with that, you’ll soon be familiar with the idiom.
Functions become really interesting, though, when we take advantage of their independence as first-class objects.
B.3.2. Attaching functions to objects
As a functional language, JavaScript allows us to define functions in the absence of any object, for example:
function doSomething(x,y,z){ ... }
Functions can also be defined inline:
var doSomething=function(x,y,z){ ... }
As a concession to object-orientation, functions may be attached to objects, giving the semblance of a Java or C# method. There is more than one way of doing this.
We can attach a predefined function to a predefined object (in which case only that object can call the function, not any other object derived from the same prototype):
myObj.doSomethingNew=doSomething; myObj.doSomethingNew(x,y,z);
We can also attach functions such that every instance of a class can access them, by adding the function (either predefined or declared inline) to the new object in the constructor, as we saw in section B.2.2, or by attaching it to the prototype.
Once we’ve done this, though, they aren’t very strongly attached, as we will see.
B.3.3. Borrowing functions from other objects
Giving functions first-class object status alters the capabilities of a language significantly. Furthermore, an understanding of these alterations is important when coding GUI event handling, so most Ajax programmers would do well to understand it.
So what are these new capabilities? Well, first off, one object can borrow another’s function and call it on itself. Let’s define a class to represent species of tree in a taxonomic system:
function Tree(name, leaf, bark){
this.name=name;
this.leaf=leaf;
this.bark=bark;
}
Next, we’ll add a function to it that provides a quick description of the tree:
Tree.prototype.describe=function(){
return this.name+": leaf="+this.leaf+", bark="+this.bark;
}
If we now instantiate a Tree object and ask it to describe itself, we get a fairly predictable response:
var Beech=new Tree("green, serrated edge","smooth");
alert(Beech.describe());
The alert box will display the text Beech: leaf=green, serrated edge, bark=smooth. So far, so good. Now let us define a class to represent a dog:
function Dog(name,bark){
this.name=name;
this.bark=bark;
}
and create an instance of our Dog class:
var Snowy=new Dog("snowy","wau! wau!");
Snowy wants to show us his bark, but, although we’ve defined it for him, he has no function through which to express it. He can, however, hijack the Tree class’s function:
var tmpFunc=Beech.describe; tmpFunc.call(Snowy);
Remember, the first argument to function.call() is the context object, that is, the object that the special variable this will resolve to. The previous code will generate an alert box displaying the text Snowy: leaf=undefined, bark=wau! wau!. Well, it’s better than nothing for the poor dog.
So what’s going on here? How can a dog call a function that really belongs to a tree? The answer is that the function doesn’t belong to the tree. Despite being peppered with references to this, assigning the function to the Tree prototype binds it only inasmuch as it enables us to use the shorter MyTree.describe() notation. Internally, the function is stored as a piece of text that gets evaluated every time it is called, and that allows the meaning of this to differ from one invocation to the next.
Borrowing functions is a neat trick that we can use in our own code, but in production-quality code, we’d prefer to see someone implement a bark() method for Snowy of his very own. The real reason for discussing this behavior is that when you are writing event-handling code, the web browser will do it for you behind the scenes.
B.3.4. Ajax event handling and function contexts
Ajax event handlers are pretty much the same as most GUI toolkit languages, with specialized categories for mouse and keyboard events, as we saw in chapter 4. Our example uses the onclick handler, fired when a mouse is clicked on a visible element. A full discussion of DHTML event handling is beyond the scope of this book, but let’s take the time here to highlight a particular issue that can often trip up the unwary.
Event handlers can be declared either as part of the HTML markup; for example
<div id='myDiv' onclick='alert:alert(this.id)'></div>
or programmatically; for example:
function clickHandler(){ alert(this.id); }
myDiv.onclick=clickHandler;
Note that in the programmatic case, we pass a reference to the Function object (that is no () after the clickHandler). When declaring the function in the HTML, we are effectively declaring an anonymous function inline, equivalent to
myDiv.onclick=function(){ alert(this.id); }
Note that in both cases, the function has no arguments assigned to it, nor is there any way for us to pass in arguments with the mouse click. However, when we click on the DOM element, the function is called with an Event object as the argument and the element itself as the context object. Knowing this can save a lot of grief and puzzlement, particularly when you’re writing object-based code. The key source of confusion is that the DOM node is always passed as context, even if the function is attached to the prototype of a different object.
In the following example, we define a simple object with an event handler for a visible GUI element that it knows about. We can think of the object as the Model in MVC terms, with the event handler taking the role of Controller, and the DOM element being the View.
function myObj(id,div){
this.id=id;
this.div=div;
this.div.onclick=this.clickHandler;
}
The constructor takes an internal ID and a DOM element, to which it assigns an onclick handler. We define the event handler as follows:
myObj.prototype.clickHandler=function(event){
alert(this.id);
}
So, when we click on the GUI element, it will alert us to the ID of that object, right? In fact, it won’t, because the myObj.clickHandler function will get borrowed by the browser (just as our wayward dog borrowed a method from the tree object in the previous section) and invoked in the context of the element, not the Model object. Since the element happens to have a built-in id property, it will show a value, and, depending on your naming conventions, it may even be the same as the Model object’s ID, allowing the misunderstanding to continue for some time.
If we want the event handler to refer to the Model object that we’ve attached it to, we need another way of passing the reference to that object across. There are two idioms for doing this that I’ve commonly come across. One is clearly superior to the other, in my opinion, but I coded for years using the other one, and it works. One of the aims of this book is to give names to the patterns (and anti-patterns) that we have adopted by habit, so I will present both here.
Referencing the Model by name
In this solution, we assign a globally unique ID to each instance of our Model object and keep a global array of these objects referenced by the ID. Given a reference to a DOM element, we can then reference its Model object by using part of the ID as a key to the lookup array. Figure B.1 illustrates this strategy.
Figure B.1. Referencing the Model from an event handler function by name. The DOM element ID is parsed, and the parsed value used as a key to a global lookup array.

Generating a unique ID for every element is an overhead in this approach, but ID generation can be accomplished fairly automatically. We can use the array length as part of the key, for example, or a database key, if we’re generating code on the web server.
As a simple example, we’re creating an object of type myObj, which has a clickable title bar that invokes a function myObj.foo().
Here is the global array:
var MyObjects=new Array();
And here is the constructor function, which registers the Model object with that array:
function myObj(id){
this.uid=id;
MyObjects[this.uid]=this;
...
this.render();
}
Here is a method of the myObj object, which does something exciting. We want to invoke this when the title bar is clicked:
myObj.prototype.foo=function(){
alert('foooo!!! '+this.uid);
}
Here is the object’s render() method, which creates various DOM nodes:
myObj.prototype.render=function(){
...
this.body=document.createElement("div");
this.body.id=this.uid+"_body";
...
this.titleBar=document.createElement("div");
this.titleBar.id=this.uid+"_titleBar";
this.titleBar.onclick=fooEventHandler;
...
}
When we construct any DOM nodes in the view for this Model object, we assign an ID value to them that contains the Model object ID.
Note that we refer to a function fooEventHandler() and set it as the onclick property of our title bar DOM element:
function fooEventHandler(event){
var modelObj=getMyObj(this.id);
if (modelObj){ modelObj.foo(); }
}
}
The event handler function will need to find the instance of myObj in order to invoke its foo() method. We provide a finder method:
function getMyObj(id){
var key=id.split("_")[0];
return MyObjects[key];
}
It has a reference to the DOM node and can use its id property to extract a key from which to retrieve the Model object from the global array.
And there it is. The Reference Model By Name method served me well for a few years, and it works, but there is a simpler, cleaner way that doesn’t pepper your DOM tree with lengthy IDs. (Actually, I never reached a decision as to whether that was good or bad. It was a waste of memory, for sure, but it also made debugging in the Mozilla DOM Inspector very easy.)
Attaching a Model to the DOM node
In this second approach to DOM event handling, everything is done with object references, not strings, and no global lookup array is needed. This is the approach that has been used throughout this book. Figure B.2 illustrates this approach.
Figure B.2. Attaching a reference to the Model directly to a DOM node makes it easier for the event handler function to find the Model at runtime.
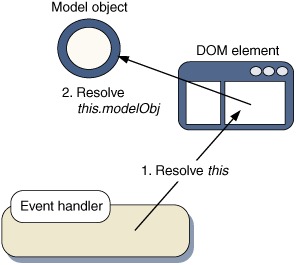
This approach simplifies the event handler’s job considerably. The constructor function for the Model object needs no specialized ID manipulation, and the foo() method is defined as before. When we construct DOM nodes, we exploit JavaScript’s dynamic ability to attach arbitrary attributes to any object and clip the Model object directly onto the DOM node receiving the event:
myObj.prototype.createView=function(){
...
this.body=document.createElement("div");
this.body.modelObj=this;
...
this.titleBar=document.createElement("div");
this.titleBar.modelObj=this;
this.titleBar.onclick=fooEventHandler;
...
}
When we write the event handler, we can then get a direct reference back to the Model:
function fooEventHandler(event){
var modelObj=this.modelObj;
if (modelObj){ modelObj.foo(); }
}
}
No finders, no global lookups—it’s as simple as that.
One word of warning, however. When using this pattern, we create a cyclic reference between a DOM and a non-DOM variable, and web browser folklore has it that this is bad for garbage collection under certain popular browsers of the day. If this pattern is used correctly, memory overheads can be avoided, but I’d recommend you study chapter 7 before implementing the Attach Model To DOM Node pattern.
Understanding how a JavaScript function has defined its context has helped us to develop an elegant reusable solution for the browser event model, then. The ability of a function to switch between contexts can be confusing at first, but understanding the model behind us helps to work with it.
The final thing that we need to understand about JavaScript functions is the language’s ability to create closures. Again, Java and C# lack the concept of closures, although some Java and .NET scripting languages, such as Groovy and Boo, support them, and C# 2.0 will support them, too. Let’s look at what they are and how to work with them.
B.3.5. Closures in JavaScript
On its own, a Function object is incomplete—to invoke it, we need to pass in a context object and a set of arguments (possibly an empty set). At its simplest, a closure can be thought of as a Function bundled with all the resources that it needs to execute.
Closures are created in JavaScript implicitly, rather than explicitly. There is no constructor function new Closure() and no way to get a handle on a closure object. Creating a closure is as simple as declaring a function within a code block (such as another function) and making that function available outside the block.
Again, this sounds a bit weird conceptually but is simple enough when we look at an example. Let’s define a simple object to represent a robot and record the system clock time at which each robot is created. We can write a constructor like this:
function Robot(){
var createTime=new Date();
this.getAge=function(){
var now=new Date();
var age=now-createTime;
return age;
}
}
(All the robots are identical, so we haven’t bothered to assign names or anything else through constructor arguments.) Normally, we would record createTime as a member property, that is, write
this.createTime=new Date();
but here we’ve deliberately created it as a local variable, whose scope is limited to the block in which it is called, that is, the constructor. On the second line of the constructor, we define a function getAge(). Note here that we’re defining a function inside another function and that the inner function uses the local variable createTime, belonging to the scope of the outer function. By doing this, and nothing else, we have in fact created a closure. If we define a robot and ask it how old it is once the page has loaded,
var robbie=new Robot();
window.onload=function(){
alert(robbie.getAge());
}
then it works and gives us a value of around 10–50 milliseconds, the difference between the script first executing and the page loading up. Although we have declared createTime as being local to the constructor function scope, it cannot be garbage-collected so long as Robbie the robot is still referenced, because it has been bound up in a closure.
The closure works only if the inner function is created inside the outer one. If we refactor my code to predefine the getAge function and share it between all robot instances, like so
function Robot(){
var createTime=new Date();
this.getAge=roboAge;
}
function roboAge(){
var now=new Date();
var age=now-createTime;
return age;
};
then the closure isn’t created, and we get an error message telling me that createTime is not defined.
Closures are very easy to create and far too easy to create accidentally, because closures bind otherwise local variables and keep them from the garbage collector. If DOM nodes, for example, get caught up in this way, then inadvertently created closures can lead to significant memory leaks over time.
The most common situation in which to create closures is when binding an event-handler callback function to the source of the event. As we discussed in section B.3.4, the callback is invoked with a context and set of arguments that is sometimes not as useful as it might be. We presented a pattern for attaching additional references (the Model object) to the DOM element that generates the event, allowing us to retrieve the Model via the DOM element. Closures provide an alternative way of doing this, as illustrated here:
myObj.prototype.createView=function(){
...
this.titleBar=document.createElement("div");
var modelObj=this;
this.titleBar.onclick=function(){
fooEventHandler.call(modelObj);
}
}
The anonymous onclick handler function that we define makes a reference to the locally declared variable modelObj, and so a closure is created around it, allowing modelObj to be resolved when the function is invoked. Note that closures will resolve only local variables, not those referenced through this.
We use this approach in the ContentLoader object that we introduced in chapter 2, because the onreadystatechange callback provided in Internet Explorer returns the window object as the function context. Since window is defined globally, we have no way of knowing which ContentLoader’s readyState has changed, unless we pass a reference to the relevant loader object through a closure.
My recommendation to the average Ajax programmer is to avoid closures if there is an alternative. If you use the prototype to assign functions to your custom object types, then you don’t duplicate the functions and you don’t create closures. Let’s rewrite our Robot class to follow this advice:
function Robot(){
this.createTime=new Date();
}
Robot.prototype.getAge=function(){
var now=new Date();
var age=now-this.createTime;
return age;
};
The function getAge() is defined only once, and, because it is attached to the prototype, it is accessible to every Robot that we create.
Closures have their uses, but we’d consider them an advanced topic. If you do want to explore closures in greater depth, then Jim Ley’s article, listed in the Resources section, is a good place to start.
B.4. Conclusions
We’ve taken you through some of the stranger and more interesting features of the JavaScript language in this appendix, with two purposes in mind. The first was to show the expressive power of the language. The second was to point out several traps for the unwary, in which thinking in an OO style may result in suboptimal or even dangerous code.
We’ve looked at JavaScript’s support for objects and at the similarities between the Object and Array classes. We’ve seen several ways of instantiating JavaScript objects, using JSON, constructor functions, and the prototype concept. Along the way, we’ve discussed how to tackle OO concepts such as inheritance and interfaces in JavaScript, in ways that work with rather than against the language.
In our exploration of JavaScript Function objects, we saw how functions can exist independently of any object to which they are assigned and even be borrowed or swapped between objects. We used this knowledge to get a better understanding of the JavaScript event model. Finally, we looked at closures and saw how some common programming idioms can create closures unintentionally, potentially resulting in memory leaks.
Compared to Java or C#, JavaScript offers a great deal of flexibility and scope for developing personal styles and approaches to the language. This can be liberating for the individual programmer, provided that you know what you are doing. It can also present problems when working in teams, but these problems can be alleviated by shared coding conventions or house styles.
JavaScript can be a very enjoyable language to work with, once you understand what makes it tick. If you’re coming to Ajax from a structured OO background, we hope that this chapter has helped you to cross the gap.
B.5. Resources
There are very few books on JavaScript the language, as opposed to web browser programming. David Flanagan’s JavaScript: The Definitive Guide (O’Reilly, 2001) is the definitive work. It’s a bit old, but a new version is due out next year. A more recent book, Nicholas Zakas’s Professional JavaScript for Web Developers(Wrox, 2004) offers a good language overview, too, and covers some more recent developments in the language.
On the Web, Doug Crockford discusses object-oriented approaches to JavaScript, such as creating private members for classes (www.crockford.com/javascript/private.html) and inheritance (www.crockford.com/javascript/private.html). Peter-Paul Koch’s Quirksmode site (http://quirksmode.org) also discusses many of the finer points of the language. Jim Ley’s discussion of closures in JavaScript can be found at http://jibbering.com/faq/faq_notes/closures.html.
Mike Foster’s x library can be found at www.cross-browser.com.