
Chapter 17. Linux and Real Time
When Linux began life on an Intel i386 processor, no one expected the success that Linux would enjoy in server applications. That success has led to Linux’s being ported to many different architectures and being used by developers for embedded systems from cellular handsets to telecommunications switches. Not long ago, if your application had real-time requirements, you might not have included Linux among the choices for your operating system. That has all changed with the developments in real-time Linux driven, in large part, by audio and multimedia applications.
This chapter starts with a brief look at the historical development of real-time Linux features. Then we look at the facilities available to the real-time programmer and how these facilities are used.
17.1 What Is Real Time?
Ask five people what “real time” means, and chances are, you will get five different answers. Some might even cite numbers. For the purposes of this discussion, we will cover various scenarios and then propose a definition. Many requirements can be said to be soft real time, and others are called hard real time.
17.1.1 Soft Real Time
Most agree that soft real time means that the operation has a deadline. If the deadline is missed, the quality of the experience could be diminished but not fatal. Your desktop workstation is a perfect example of soft real-time requirements. When you are editing a document, you expect to see the results of your keystrokes on the screen immediately. When playing your favorite mp3 file, you expect to have high-quality audio without any clicks, pops, or gaps in the music.
In general terms, humans cannot see or hear delays of less than a few tens of milliseconds. Of course, musicians will tell you that music can be colored by delays smaller than that. If a deadline is missed by these so-called soft real-time events, the results may be undesirable, leading to a lower level of “quality” for the experience, but not catastrophic.
17.1.2 Hard Real Time
Hard real time is characterized by the results of a missed deadline. In a hard real-time system, if a deadline is missed, the results are often catastrophic. Of course, catastrophic is a relative term. If your embedded device is controlling the fuel flow to a jet aircraft engine, missing a deadline to respond to pilot input or a change in operational characteristics can lead to disastrous results.
Note that the deadline’s duration has no bearing on the real-time characteristic. Servicing the tick on an atomic clock is such an example. As long as the tick is processed within the 1-second window before the next tick, the data remains valid. Missing the processing on a tick might throw off our global positioning systems by feet or even miles!
With this in mind, we draw on a commonly used set of definitions for soft and hard real time. With soft real-time systems, the value of a computation or result is diminished if a deadline is missed. With hard real-time systems, if a single deadline is missed, the system is considered to have failed by definition, and this may have catastrophic consequences.
17.1.3 Linux Scheduling
UNIX and Linux were both designed for fairness in their process scheduling. That is, the scheduler tries its best to allocate available resources across all processes that need the CPU and guarantee each process that it can make progress. This very design objective is counter to the requirement for a real-time process. A real-time process must be given absolute priority to run when it becomes ready to run. Real time means having predictable and repeatable latency.
17.1.4 Latency
Real-time processes are often associated with a physical event, such as an interrupt arriving from a peripheral device. Figure 17-1 illustrates the latency components in a Linux system. Latency measurement begins upon receipt of the interrupt we want to process. This is indicated by time t0 in Figure 17-1. Sometime later, the interrupt occurs, and control is passed to the interrupt service routine (ISR), as indicated by time t1. This interrupt latency is almost entirely dictated by the maximum interrupt off time1—the time spent in a thread of execution that has hardware interrupts disabled.
Figure 17-1. Latency components

It is considered good design practice to minimize the processing done in the actual ISR. Indeed, this execution context is limited in capability (for example, an ISR cannot call a blocking function, one that might sleep). Therefore, it is desirable to simply service the hardware device and leave the data processing to a Linux bottom half, also called softirqs. There are several types of bottom-half processing; they are best described in Robert Love’s book Linux Kernel Development. See the section at the end of this chapter for the reference.
When the ISR/bottom half has finished its processing, the usual case is to wake up a user space process that is waiting for the data. This is indicated by time t2 in Figure 17-1. Some time later, the scheduler selects the real-time process to run, and the process is given the CPU. This is indicated by time t3 in Figure 17-1. Scheduling latency is affected primarily by the number of processes waiting for the CPU and the priorities among them. Setting the Real Time attribute on a process (SCHED_FIFO or SCHED_RR) gives it higher priority over normal Linux processes and allows it to be the next process selected to run, assuming that it is the highest-priority real-time process waiting for the CPU. The highest-priority real-time process that is ready to run (not blocked on I/O) will always run. You’ll see how to set this attribute shortly.
17.2 Kernel Preemption
In the early Linux days of Linux 1.x, kernel preemption did not exist. This meant that when a user space process requested kernel services, no other task could be scheduled to run until that process blocked (went to sleep) waiting on something (usually I/O) or until the kernel request completed. Making the kernel preemptable2 meant that while one process was running in the kernel, another process could preempt the first and be allowed to run even though the first process had not completed its in-kernel processing. Figure 17-2 illustrates this sequence of events.
Figure 17-2. Kernel preemption

In this figure, Process A has entered the kernel via a system call. Perhaps it was a call to write() to a device such as the console or a file. While executing in the kernel on behalf of Process A, Process B with higher priority is woken up by an interrupt. The kernel preempts Process A and assigns the CPU to Process B, even though Process A had neither blocked nor completed its kernel processing.
17.2.1 Impediments to Preemption
The challenge in making the kernel fully preemptable is to identify all the places in the kernel that must be protected from preemption. These are the critical sections within the kernel where preemption cannot be allowed to occur. For example, assume that Process A in Figure 17-2 is executing in the kernel performing a file system operation. At some point, the code might need to write to an in-kernel data structure representing a file on the file system. To protect that data structure from corruption, the process must lock out all other processes from accessing the shared data structure. Listing 17-1 illustrates this concept using C syntax.
Listing 17-1. Locking Critical Sections

If we did not protect shared data in this fashion, the process updating the shared data structure could be preempted in the middle of the update. If another process attempted to update the same shared data, corruption of the data would be virtually certain. The classic example is when two processes are operating directly on common variables and making decisions on their values. Figure 17-3 illustrates such a case.
Figure 17-3. Shared data concurrency error
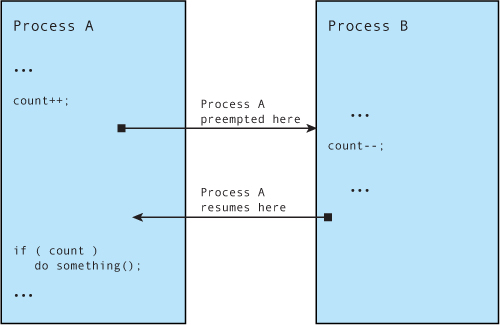
In Figure 17-3, Process A is interrupted after updating the shared data but before it makes a decision based on it. By design, Process A cannot detect that it has been preempted. Process B changes the value of the shared data before Process A gets to run again. As you can see, Process A will be making a decision based on a value determined by Process B. If this is not the behavior you seek, you must disable preemption in Process A around the shared data—in this case, the operation and decision on the variable count.
17.2.2 Preemption Models
The first solution to kernel preemption was to place checks at strategic locations within the kernel code where it was known to be safe to preempt the current thread of execution. These locations included entry and exit to system calls, release of certain kernel locks, and return from interrupt processing. At each of these points, code similar to Listing 17-2 was used to perform preemption.
Listing 17-2. Check for Preemption a la the Linux 2.4+ Preempt Patch
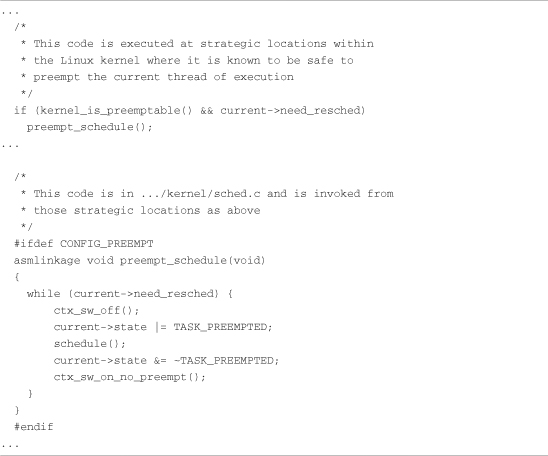
The first snippet of code in Listing 17-2 (simplified from the actual code) is invoked at the strategic locations described earlier, where it is known that the kernel is safe to preempt. The second snippet of code in Listing 17-2 is the actual code from an early Linux 2.4 kernel with the preempt patch applied. This interesting while loop causes a context switch via the call to schedule() until all requests for preemption have been satisfied.
Although this approach led to reduced latencies in the Linux system, it was not ideal. The developers working on low latency soon realized the need to “flip the logic.” With earlier preemption models, we had this:
• The Linux kernel was fundamentally nonpreemptable.
• Preemption checks were sprinkled around the kernel at strategic locations known to be safe for preemption.
• Preemption was enabled only at these known-safe points.
To achieve a further significant reduction in latency, we want the following in a preemptable kernel:
• The Linux kernel is fully preemptable everywhere.
• Preemption is disabled only around critical sections.
This is where the kernel developers have been heading since the original preemptable kernel patch series. However, this is no easy task. It involves poring over the entire kernel source code base, analyzing exactly what data must be protected from concurrency, and disabling preemption at only those locations. The method used for this has been to instrument the kernel for latency measurements, find the longest latency code paths, and fix them. The more recent Linux 2.6 kernels can be configured for very low-latency applications because of the effort that has gone into this “lock-breaking” methodology.
17.2.3 SMP Kernel
It is interesting to note that much of the work involved in creating an efficient multiprocessor architecture also benefits real time. Symmetric multiprocessing (SMP) is a multiprocessing architecture in which multiple CPUs, usually residing on one board, share the same memory and other resources. The SMP challenge is more complex than the uniprocessor challenge because there is an additional element of concurrency to protect against. In the uniprocessor model, only a single task can execute in the kernel at a time. Protection from concurrency involves only protection from interrupt or exception processing. In the SMP model, multiple threads of execution in the kernel are possible in addition to the threat from interrupt and exception processing.
SMP has been supported from as far back as early Linux 2.x kernels. A big kernel lock (BKL) was used to protect against concurrency in the transition from uniprocessor to SMP operation. The BKL is a global spinlock, which prevents any other tasks from executing in the kernel. In his excellent book Linux Kernel Development, Robert Love characterized the BKL as the “redheaded stepchild of the kernel.” In describing the characteristics of the BKL, Robert jokingly added “evil” to its list of attributes!
Early implementations of the SMP kernel based on the BKL led to significant inefficiencies in scheduling. It was found that one of the CPUs could be kept idle for long periods of time. Much of the work that led to an efficient SMP kernel also directly benefited real-time applications—primarily lowered latency. Replacing the BKL with smaller-grained locking surrounding only the actual shared data to be protected led to significantly reduced preemption latency.
17.2.4 Sources of Preemption Latency
A real-time system must be able to service its real-time tasks within a specified upper boundary of time. Achieving consistently low preemption latency is critical to a real-time system. The two single largest contributors to preemption latency are interrupt-context processing and critical section processing where interrupts are disabled. You have already learned that a great deal of effort has been targeted at reducing the size (and thus the duration) of the critical sections. This leaves interrupt-context processing as the next challenge. This was answered with the Linux 2.6 real-time patch.
17.3 Real-Time Kernel Patch
Support for hard real time is still not in the mainline kernel.org source tree. To enable hard real time, a patch must be applied. The real-time kernel patch is the cumulative result of several initiatives to reduce Linux kernel latency. The patch had many contributors, and it is currently maintained by Ingo Molnar; you can find it at www.kernel.org/pub/linux/kernel/projects/rt/. The soft real-time performance of the 2.6 Linux kernel has improved significantly since the early 2.6 kernel releases. When 2.6 was first released, the 2.4 Linux kernel was substantially better in soft real-time performance. Since about Linux 2.6.12, soft real-time performance in the single-digit milliseconds on a reasonably fast x86 processor is readily achieved. Getting repeatable latencies in the microsecond range requires the real-time patch.
The real-time patch adds several important features to the Linux kernel. Figure 17-4 displays the configuration options for Preemption mode when the real-time patch has been applied.
Figure 17-4. Preemption modes with real-time patch

The real-time patch adds a fourth preemption mode called PREEMPT_RT, or Preempt Real Time. The four preemption modes are as follows:
• PREEMPT_NONE—No forced preemption. Overall latency is good on average, but some occasional long delays can occur. Best suited for applications for which overall throughput is the top design criterion.
• PREEMPT_VOLUNTARY—First stage of latency reduction. Additional explicit preemption points are placed at strategic locations in the kernel to reduce latency. Some loss of overall throughput is traded for lower latency.
• PREEMPT_DESKTOP—This mode enables preemption everywhere in the kernel except when processing within critical sections. This mode is useful for soft real-time applications such as audio and multimedia. Overall throughput is traded for further reductions in latency.
• PREEMPT_RT—Features from the real-time patch are added, including replacing spinlocks with preemptable mutexes. This enables involuntary preemption everywhere within the kernel except for areas protected by preempt_disable(). This mode significantly smoothes out the variation in latency (jitter) and allows a low and predictable latency for time-critical real-time applications.
If kernel preemption is enabled in your kernel configuration, you can disable it at boot time by adding the following kernel parameter to the kernel command line:
preempt=0
17.3.1 Real-Time Features
Several new Linux kernel features are enabled with CONFIG_PREEMPT_RT. Figure 17-4 shows several new configuration settings. These and other features of the real-time Linux kernel patch are described here.
The real-time patch converts most spinlocks in the system to priority-inheritance mutexes. This reduces overall latency at the cost of additional overhead in spinlock (mutex) processing, resulting in reduced overall system throughput. The benefit of converting spinlocks to mutexes is that they can be preempted. If Process A is holding a lock, and Process B at a higher priority needs the same lock, Process A can preempt Process B in the case where it is holding a mutex.
With CONFIG_PREEMPT_HARDIRQS selected, interrupt service routines (ISRs) are forced to run in process context. This gives the developer control over the priority of ISRs, because they become schedulable entities. As such, they also become preemptable to allow higher-priority hardware interrupts to be handled first. Because they can be scheduled, you can assign them a priority in a similar fashion to other tasks based on your system’s requirements.
This is a powerful feature. Some hardware architectures do not enforce interrupt priorities. Those that do might not enforce the priorities consistent with your specified real-time design goals. Using CONFIG_PREEMPT_HARDIRQS, you are free to define the priorities at which each IRQ will run.
CONFIG_PREEMPT_SOFTIRQS reduces latency by running softirqs within the context of the kernel’s softirq daemon (ksoftirqd). ksoftirqd is a proper Linux task (process). As such, it can be prioritized and scheduled along with other tasks. If your kernel is configured for real time, and CONFIG_PREEMPT_SOFTIRQS is enabled, the ksoftirqd kernel task is elevated to real-time priority to handle the softirq processing.3 Listing 17-3 shows the code responsible for this from a recent Linux kernel, found in .../kernel/softirq.c.
Listing 17-3. Promoting ksoftirqd to Real-Time Status

Here we see that the ksoftirqd kernel task is promoted to a real-time task (SCHED_FIFO) using the sys_sched_setscheduler() kernel function.
17.3.2 O(1) Scheduler
The O(1) scheduler has been around since the days of Linux 2.5. It is mentioned here because it is a critical component of a real-time solution. The O(1) scheduler is a significant improvement over the previous Linux scheduler. It scales better for systems with many processes and helps produce lower overall latency.
In case you are wondering, O(1) is a mathematical designation for a system of the first order. In this context, it means that the time it takes to make a scheduling decision is not dependent on the number of processes on a given runqueue. The old Linux scheduler did not have this characteristic, and its performance degraded with the number of processes.4
17.3.3 Creating a Real-Time Process
You can designate a process as real time by setting a process attribute that the scheduler uses as part of its scheduling algorithm. Listing 17-4 shows the general method.
Listing 17-4. Creating a Real-Time Process
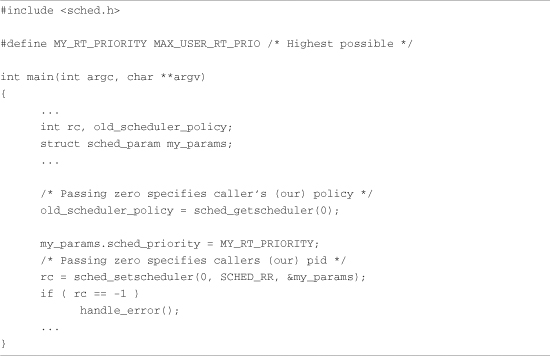
This code snippet does two things in the call to sched_setscheduler(). It changes the scheduling policy to SCHED_RR and raises its priority to the maximum possible on the system. Linux supports three scheduling policies:
• SCHED_OTHER—Normal Linux process, fairness scheduling.
• SCHED_RR—Real-time process with a time slice. In other words, if it does not block, it is allowed to run for a given period of time determined by the scheduler.
• SCHED_FIFO—Real-time process that runs until it either blocks or explicitly yields the processor, or until another higher-priority SCHED_FIFO process becomes runnable.
The man page for sched_setscheduler() provides more detail on the three different scheduling policies.
17.4 Real-Time Kernel Performance Analysis
The instrumentation for examining real-time kernel performance was once somewhat ad hoc. Those days are over. Ftrace has replaced the older tracing mechanisms that existed when the first edition of this book was published. Ftrace is a powerful set of tracing tools that can give the developer a detailed look at what is going on inside the kernel. Complete documentation on the Ftrace system can be found in the kernel source tree at .../Documentation/trace/ftrace.txt.
17.4.1 Using Ftrace for Tracing
Ftrace must be enabled in your kernel configuration before it can be used. Figure 17-5 shows the relevant kernel configuration parameters from a recent kernel release.
Figure 17-5. Kernel configuration for Ftrace

Ftrace has many available modules. It is prudent to select only those you might need for a particular test session, because each one adds some level of overhead to the kernel.
The general framework for enabling tracing is through its interface exported to the debugfs file system. Assuming that you have properly enabled Ftrace in your kernel configuration, you must then mount the debugfs. This is done as follows:
# mount -t debugfs debug /sys/kernel/debug
When this is complete, you should find a directory under /sys/kernel/debug called tracing. This tracing directory contains all the controls and output sources for Ftrace data. This will become more clear as we interact with this system in the following sections. As suggested in the kernel documentation, we will use a symlink called /tracing to simplify reporting and interacting with the Ftrace subsystems:
# ln -s /sys/kernel/debug/tracing /tracing
From here on, we will reference /tracing instead of the longer /sys/kernel/debug/ tracing.
17.4.2 Preemption Off Latency Measurement
The kernel uses calls to disable preemption during processing in critical shared data structures. When preemption is disabled, interrupts can still occur, but a higher- priority process cannot run. You can profile the preempt off times using the preemptoff functionality of Ftrace.
To enable measurement of preemption off latency, enable PREEMPT_TRACER and PREEMPT_OFF_HIST in the Kernel hacking submenu of your kernel configuration. This trace mode enables the detection of the longest latency paths with preemption disabled.
The general method for arming Ftrace for a preemptoff measurement is as follows:

Listing 17-5 shows the trace output resulting from this sequence of commands. Notice that the maximum latency of 221 microseconds is displayed in the header.
Listing 17-5. Preemptoff Trace


Notice the last two lines of Listing 17-5. Here we have displayed the maximum latency value captured by Ftrace by displaying the contents of tracing_max_latency. This value will always be updated with the maximum latency recorded and the output of the trace file (the entire contents of Listing 17-5) that corresponds to the path through the system associated with this longest latency.
17.4.3 Wakeup Latency Measurement
One of the most critical measurements of interest to real-time developers is how long it takes to get the high-priority task running after it has been signaled to do so. When a real-time process (one with the SCHED_FIFO or SCHED_RR scheduling attribute) is running in your system, it is by definition sharing the processor with other tasks. When an event needs servicing, the real-time task is woken up. In other words, the scheduler is informed that it needs to run. Wakeup timing is the time from the wakeup event until the task actually gets the CPU and begins to run.
Ftrace has a wakeup and wakeup_rt trace facility. This facility records and traces the longest latency from wakeup to running while the tracer is enabled.
Listing 17-6 was generated from a simple C test program that creates and writes to a file. Prior to the file I/O, the test program elevates itself to SCHED_RR with priority 99 and sets up the tracing system using writes to stdio, similar to issuing the following commands from the shell:

After our test program issues these commands, tracing has completed. Listing 17-6 shows the results. Notice in this case that the maximum wakeup latency is reported as 7 microseconds.
Listing 17-6. Wakeup Timing Trace


When the test program runs, it performs the file I/O and then sleeps. This guarantees that it will yield the processor even if it did not block on I/O. The trace shown in Listing 17-6 is quite interesting. From the header, you see that the test program ran as PID 6006 with priority 99. You also see that the maximum latency reported was 7 microseconds—certainly a very acceptable value.
The first line of the trace output is the wakeup event. A process with PID 1789 was running (ssh daemon) at the time. The last trace is the actual context switch from sshd to the test program running as PID 6006 with RT priority. The lines between the wakeup and context switch are the kernel path taken, along with the relative times.
Refer to the a .../Documentation subdirectory of the Linux kernel source tree for trace/ftrace.txt for additional details.
The maximum latency is provided separately in another trace file. To display the maximum wakeup latency during a particular tracing run, simply issue this command:
root@speedy:~# cat /tracing/tracing_max_latency
7
17.4.4 Interrupt Off Timing
To enable measurement of maximum interrupt off timing, make sure your kernel has IRQSOFF_TRACER enabled in your kernel configuration. This option measures time spent in critical sections with IRQs disabled. This feature works the same as wakeup latency timing. To enable the measurement, do the following as root:

To read the current maximum, simply display the contents of /tracing/tracing_max_latency:
# cat /tracing/tracing_max_latency
97
You will notice that the latency measurements for both wakeup latency and interrupt off latency are enabled and displayed using the same file. This means, of course, that only one measurement can be configured at a time, or the results might be invalid. Because these measurements add significant runtime overhead, it would be unwise to enable them all at once anyway.
17.4.5 Soft Lockup Detection
To enable soft lockup detection, enable DETECT_SOFTLOCKUP in the kernel configuration. This feature enables the detection of long periods of running in kernel mode without a context switch. This feature exists in non-real-time kernels but is useful for detecting very-high-latency paths or soft deadlock conditions. To use soft lockup detection, simply enable the feature and watch for any reports on the console or system log. Reports similar to this will be emitted:
BUG: soft lockup detected on CPU0
When the kernel emits this message, it is usually accompanied by a backtrace and other information such as the process name and PID. It will look similar to a kernel oops message, complete with processor registers. See .../kernel/softlockup.c for details. This information can be used to help track down the source of the lockup condition.
17.5 Summary
Linux is increasingly being used in systems where real-time performance is required. Examples include multimedia applications and robot, industrial, and automotive controllers. This chapter presented fundamental concepts and analysis techniques to help you develop and debug real-time applications.
• Real-time systems are characterized by deadlines. When a missed deadline results in inconvenience or a diminished customer experience, this is called soft real time. In contrast, hard real-time systems are considered failed when a deadline is missed.
• Kernel preemption was the first significant feature in the Linux kernel that addressed system-wide latency.
• Recent Linux kernels support several preemption modes, ranging from no preemption to full real-time preemption.
• The real-time patch adds several key features to the Linux kernel, resulting in reliable low latencies.
• The real-time patch includes several important measurement tools to aid in debugging and characterizing a real-time Linux implementation.
17.5.1 Suggestion for Additional Reading
Linux Kernel Development, 3rd Edition
Robert Love
Addison-Wesley, 2010