
8. Getting Started with Calculations
Understanding How and Where Calculations Are Used
Calculations are among the most important and powerful tools at your disposal in the development of FileMaker Pro solutions. Some people find learning calculations to be an easy task, whereas others can find writing complex calculations to be daunting. Whichever camp you fall into, calculations will enable you to unlock much of the advanced power within FileMaker. This chapter and its companion, Chapter 15, “Advanced Calculation Techniques,” will provide you with a solid grounding.
This chapter focuses on basic calculation functions and techniques for using them well. Chapter 15 looks at more advanced calculation formulas and specific techniques. If you’re new to FileMaker, you should start here.
From the outset, it’s important to understand the difference between calculation fields and calculation formulas. The term calculation is often used to denote both concepts. A calculation field is a particular type of field whose value is determined through the evaluation of a calculation formula. Calculation formula is a broader concept that refers to any use of a formula to determine an output, and that output can be a value that is stored in a calculation field or it can be a value that is used in evaluating an if statement, constructing a tooltip, determining whether access to a field is allowed, or dynamically specifying a layout to go to. When you learn “calculations,” you’re really learning calculation formulas. It so happens that you’ll use calculation formulas to construct calculation fields, but the formulas are applied widely throughout FileMaker solutions.
Writing Calculation Formulas
Essentially, the purpose of a calculation formula is to evaluate an expression and return a value. In Figure 8.1, for example, you can see the field definition for a calculation field called Amount (this is from the Time Billing Starter Solution). The value of this field is defined to be the result of the rate multiplied by the time as specified in the Time in Unit Total field. The Time in Unit Total field itself is also a calculation field—one that converts seconds into hours, which is the unit on which Rate is based. Thus, you have a chain of calculations that are all evaluated as necessary so that the Amount field is calculated and ready for you to use as you wish.
You can use calculations in any of the FileMaker products; however, you can create them only in FileMaker Pro and FileMaker Pro Advanced.
Most of the expressions you use in calculation formulas are intended to return a value, and that value might be a number, a text string, a date or time, or even a reference to a file to place in a container field. You select the calculation result type in the lower left of the Specify Calculation dialog.
Another class of formulas, however, is intended to evaluate the truth of an equation or statement. The value returned by these formulas is either a 1, indicating that the equation or statement is true, or 0, indicating that the equation or statement is false. Typically, calculations are used in this manner in If script steps, in calculated validations, and for defining field access restrictions.
The calculation itself is created in the space in the lower center of the Specify Calculation dialog, as you see later in this chapter. Just above that space, you can see the distinction between a calculation that is used to define a calculation field and one that is designed to return a Boolean value. In the first case, as you see in Figure 8.1, the name of the calculation field (Amount, in this case) is shown. In the second case, that area is blank.
![]() To learn more about field validation, see Chapter 3, “Defining and Working with Fields and Tables.”
To learn more about field validation, see Chapter 3, “Defining and Working with Fields and Tables.”
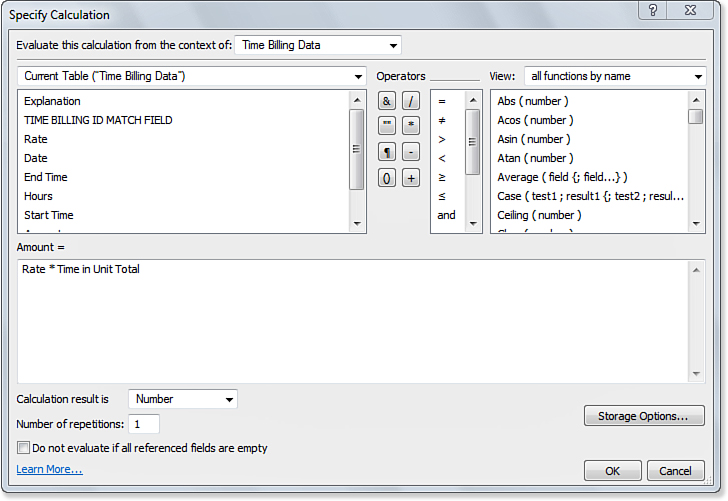
Figure 8.1. When defining calculation fields, you specify an expression to evaluate in the Specify Calculation dialog.
In Figure 8.2, you can see a calculation dialog that specifies the condition for an If script step. This very common calculation checks to see whether the SystemPlatform value is greater than 2 (in other words, it checks to see whether you are running on an iPad). The result of this calculation is used to switch between desktop and iPad layouts. (This is one of those introspective functions.)
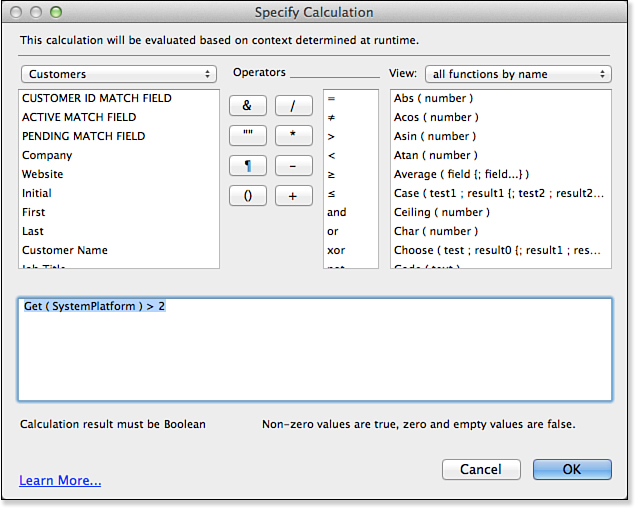
Figure 8.2. Calculation formulas are often used to determine the truthfulness of an equation or a statement.
In situations where FileMaker is expecting a formula that returns a true/false result, you see the words “Calculation result must be Boolean” near the bottom of the Specify Calculation dialog. The If script step shown earlier is a typical example of this situation. Boolean is a software programming term for a value with one of two states: true or false. Any value returned other than 0 or a null value (for example, an empty string) is considered true.
Boolean rules apply for text values, dates, negative numbers, and so on. "Hello" is true (not zero and not null), a single space character (" ") is true, and -1 is true. Note also that the results of a formula evaluate in the same way: (0 * 100) is false. (0 + 100) is true. Last, also note that you can use comparative operators: 1 and 1 is true (where each clause on both sides of the and operator evaluates to true), 1 or 1 is true, 1 xor 1 is false, and so on. You learn about operators later in the chapter.
Uses for Calculation Formulas
This chapter focuses on the use of calculation formulas in field definitions, but it’s important that you understand that calculation formulas are used in other places as well. Briefly, they include the following:
• Script steps—Calculation formulas come into play in many script steps. The If, Set Field, and Set Variable script steps are notable examples. Many other script steps allow you to use a calculation formula to act as a parameter. A sampling includes Go to Layout, Go to Field, Go to Record, Pause/Resume Script, and Omit Multiple. Additionally, calculation formulas can be used to define script parameters and script results.
• Field validation—One of the options available to you for validating data entry is validating by calculation. This, in effect, lets you define your own rules for validation. For example, you might want to test that a due date falls on a weekday, or perhaps that a status field not allow a value of “complete” if data is missing elsewhere in a record.
The equation you provide is evaluated every time a user modifies the field. If it evaluates as true, the user’s entry is committed. If it doesn’t, the user receives an error message. For instance, if a user is supposed to enter a callback date on a contact record, you might want to validate that the entry is a future date. To do this, you might use the formula Call_Back_Date > Get ( CurrentDate ) as the validation for the Call_Back_Date field.
The GetAsBoolean() function treats all data as numeric such that, for example, "hello" evaluates as false and "hello999" evaluates as true. This is inconsistent with the way in which other Boolean logic operates, so be sure to take note of it.
• Record-level security—When you define privilege sets, you have the option of limiting a user’s access to view, edit, and delete records based on a calculation formula you provide. If the equation you provide evaluates as true, the user can perform the action; if not, the action is prohibited. For instance, you might want to prevent users from inadvertently modifying an invoice that has already been posted. So, you set up limited access for editing records based on the formula Invoice_Status ≠ "Posted". Only records for which the formula is a true statement would be editable.
• Auto-entry options—When you’re defining text, number, date, time, and timestamp fields, several auto-entry options are available for specifying default field values. One of these options is to auto-enter the result of a calculation formula. For instance, in a contact management database, you might want a default callback date set for all new contact records. The formula you would use for this might be something like Get ( CurrentDate ) + 14, if you wanted a callback date two weeks in the future.
• Calculated replace—A calculated replace is a way of changing the contents of a field in all the records in the current found set. It’s particularly useful for cleaning up messy data. Say, for example, that your users sometimes enter spaces at the end of a name field as they enter data. You could clean up this data by performing a calculated replace with the formula Trim ( First Name ).
Exploring the Specify Calculation Dialog
Now that you know something about how and where calculation formulas are used, it’s time to turn to the layout of the calculation dialog itself. The various calculation dialogs you find in particular areas in FileMaker Pro have some small differences. We focus our attention on the dialog used for defining calculation fields because it’s the most complex.
Writing the Formula
The large box in the middle of the Specify Calculation dialog is the place where you define the formula itself. If you know the syntax of the functions you need and the names of the fields, you can simply type in the formula by hand. In most cases, though, you’ll want to use the lists of fields and functions above the text box. Double-clicking an item in those lists inserts that item into your formula at the current insertion point.
Every calculation formula is made up of some combination of fields, constants, operators, and functions. All the following are examples of formulas you might write:
2 + 2
FirstName & " " & LastName
Get ( CurrentDate ) + 14
Left ( FirstName; 1 ) & Left ( LastName; 1 )
"Dear " & FirstName & ":"
$loopCounter = $loopCounter + 1
LastName = "Jones"
FileMaker assumes that any unquoted text in a formula is a number, a function name, or a field name. If it’s none of these, you get an error message when you attempt to exit the dialog.
In these examples, FirstName and LastName are fields. $loopCounter is a variable by virtue of being prefixed with a dollar-sign character. Get ( CurrentDate ) and Left are functions. The only operators used here are the addition operator (+) and the concatenation operator (&). (Concatenation means combining two text strings to form a new text string.) There are also numbers and text strings used as constants (meaning that they don’t change), such as 14, "Dear", and "Jones". Text strings are the only things you have to place within quotation marks.
![]() To learn about variables, see Chapter 16, “Advanced Scripting Techniques.”
To learn about variables, see Chapter 16, “Advanced Scripting Techniques.”
Selecting Fields
In the calculation dialog, above the formula box and to the left is a list of fields. By default, the fields in the current table are listed. You can see the fields in a related (or unrelated) table by making a selection in the pop-up menu above the field list. Double-click a field name to insert it into your formula. You can also type field names directly.
![]() If you’re having difficulty with field name syntax in formulas within ScriptMaker, see “Formulas in Scripts Require Explicit Table Context” in the “Troubleshooting” section at the end of this chapter.
If you’re having difficulty with field name syntax in formulas within ScriptMaker, see “Formulas in Scripts Require Explicit Table Context” in the “Troubleshooting” section at the end of this chapter.
Be aware that the only fields you can use from an unrelated table are those with global storage. There’s no way FileMaker could determine which record(s) to reference for nonglobally stored fields. You get an error message if you attempt to use a nonglobal field from an unrelated table in a formula.
Choosing Operators
In between the field and function areas in the Specify Calculation dialog is a list of operators you can use in your formulas. Operators are symbols that define functions, including the math functions addition, subtraction, raising to a power, and so on.
There is often some confusion about the use of &, +, and the and operator. The ampersand symbol (&) is used to concatenate strings of text together, as in the previous example where we derive the FullName by stringing together the FirstName, a space, and the LastName. The + symbol is a mathematical operator used, as you might expect, to add numbers together. The and operator is a logical operator used when you need to test for multiple Boolean conditions. For instance, you might use the formula Case (Amount Due > 0 and Days Overdue > 30, "Overdue"). Here, the and indicates that both conditions must be satisfied for the test to return true.
The other operators are quite intuitive, with the exception of xor. xor, which stands for exclusive or, tests whether either of two statements is true, but not both of them. That is, (A xor B) is the same thing as (A or B) and not (A and B). The need for such logic doesn’t come up often, but it’s still handy to know.
Strictly speaking, not all the symbols listed here are operators. The ¶ paragraph symbol (or pilcrow), for instance, is used to represent a literal return character in strings. The symbols and concepts available in the Operators section are common to many programming and scripting languages; there are no FileMaker-specific concepts in this part of the dialog.
Selecting Functions
The upper-right portion of the Specify Calculation dialog contains a list of the functions you can use in your formulas. By default, they are listed alphabetically, but you can use the View pop-up menu above the list to view only formulas of a certain type. The Get functions and External functions, in fact, will display only if you change to View by Type.
Double-clicking a function inserts the function into your formula at the current insertion point. Pressing Control and the spacebar (Macintosh) or the Insert key (Windows) while highlighting the function also adds it to your formula. The guts of the function—the portion between the parentheses—is highlighted so that you can begin typing parameters immediately.
![]() To learn more about how to read and use functions, see “Parts of a Function,” p. 229.
To learn more about how to read and use functions, see “Parts of a Function,” p. 229.
Writing Legible Formulas
Whether you’re typing in a formula by hand or are using the selection lists to insert fields and functions, here are a few general comments about how to make your functions easy to read. First, when you’re writing functions, spacing, tabs, and line returns don’t matter at all except within quotation marks. You can put spaces, tabs, and returns just about any place you want without changing how the formula evaluates. For legibility, it’s therefore often helpful to put the parameters of a function on separate lines, especially when you have nested functions. In its own formatting, FileMaker leaves spaces between values and parentheses; this can make for more easily read code.
You can also add comments to calculation formulas. You can prefix a comment with two forward slashes (//) and anything following until the end of that line will not be evaluated. To comment a block of multiple-lined text, begin with /* and close with */.
Figure 8.3 shows a calculation from the Time Billing Starter Solution with a few modifications. As you can see in the lower left of the dialog, the result of the calculation will be a Text value. This function fills the Customer Name field with a value selected by a Case statement.

Figure 8.3. A complex formula written without adequate spacing can be very difficult to understand and troubleshoot.
This is a typical calculation field. It evaluates several statements based on data fields and returns a value for the Customer Name field. Because it is spaced out, it is clear to see the following:
• If both First and Last (name) are empty, set Customer Name to the Company field.
• Otherwise, if First is empty, set Customer Name to Last.
• Otherwise, if Last is empty, set Customer Name to First.
• Otherwise, set Customer Name to First, a space, and then Last.
Lining up sections of code by indenting them helps to make it much easier to see errors and logical flaws.
That is the code you see in Figure 8.3. Some people would argue that it is quite clear, and because the statement appears on a single line, it is easy to see what is happening.
In Figure 8.4, that same formula has been reformatted with extra spacing to make it more legible. Legibility isn’t merely an idle concern; it has real value. If you, or someone else, ever need to debug or alter one of your formulas, it will take much less time and effort if you’ve formatted your formula well in the first place. And that is why the actual calculation field in the Time Billing Starter Solution looks as shown in Figure 8.4.

Figure 8.4. Adding spaces, returns, and comments to a formula can make it much more legible, and hence easier to maintain in the future.
Options
At the bottom of the Specify Calculation dialog, you can see a variety of miscellaneous options. These options pertain only to defining calculation fields; you don’t see them in any of the other calculation dialogs, such as those used to evaluate an If statement.
Data Type
The first of these miscellaneous options is to specify the type of data the calculation will return. Usually, it’s obvious. If you’re concatenating the FirstName and LastName fields to form the FullName field, your calculation result will need to be a text string. If you’re adding the SalesTax to an InvoiceSubTotal to generate the InvoiceTotal, the expected result will obviously be a number. Adding 14 days to the current date to generate a callback date should result in a date. Simply ask yourself what type of data the formula should produce and select the appropriate result.
![]() If you choose the wrong data type for a calculation field, you might experience some unexpected results. See “Errors Due to Improper Data Type Selection” in the “Troubleshooting” section at the end of this chapter.
If you choose the wrong data type for a calculation field, you might experience some unexpected results. See “Errors Due to Improper Data Type Selection” in the “Troubleshooting” section at the end of this chapter.
Number of Repetitions
The only time you’ll ever have to worry about the number of repetitions in a calculation field is when your formula references one or more repeating fields. If it does, you’ll typically define your calculation to have the same number of repetitions as the fields it references. The formula you define is applied to each repetition of the source fields, resulting in different values for each repetition of your calculation field.
If you reference nonrepeating fields in your calculation, they affect only the first repetition of output. You can, however, use the Extend() function to allow a nonrepeating field to be applied to each repetition of output.
Do Not Evaluate
By default, for new calculation fields, the Do Not Evaluate If All Referenced Fields Are Empty box on the Specify Calculation dialog is checked. This means that the calculation returns a null (empty) value as long as all the fields it refers to are empty. If this box is unchecked, the formula will be evaluated using the empty values in the referenced fields. For instance, say that you had a StatusCode field in an invoice database and wanted to use it to generate a status message, the formula of which was If ( StatusCode = "P"; "Paid"; "Not Paid" ). If you left the Do Not Evaluate... box checked, invoices with no status code would have no status message. If it were unchecked, their status message would be Not Paid.
Another example draws from this feature’s most common use: financial calculations. If you have a field that calculates, say, a price total based on quantity and sales tax fields, it’s often helpful to return an explicit zero rather than leaving the calculation field null or blank. Consider a calculation field that calculates a discount based on a transactionAmount field:
If ( transactionAmount >= 1000; 50; 0 )
If the check box is unchecked, this evaluation will return a zero if either transactionAmount is less than 1000 or the field is empty. In this way, the zero is explicit and demonstrates for the user that the calculation was performed. If the check box is left checked and transactionAmount is empty, this discount field will be empty as well, leading to possible uncertainty on the part of users.
There’s no simple rule as to when you want to check or uncheck this option. You need to look at your formula and determine whether the inputs to the formula—those fields referenced in the formula—could all ever be blank, and if so, whether you would still want the formula to evaluate. Typically, if your formulas have default results (as in the StatusCode example), rather than using explicit logic for determining results, you probably want to uncheck the box.
Storage Options
The last things in this anatomy lesson are the storage options available when you’re defining calculation fields. Be aware that the output of your calculation formula may differ depending on the storage method selected. The Storage Options dialog is shown in Figure 8.5.
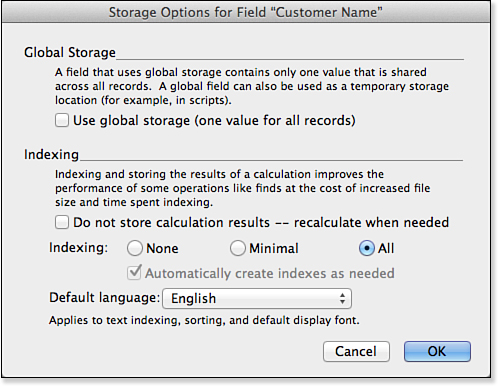
Figure 8.5. The Storage Options dialog enables you to set calculation fields so that they have global results and to specify indexing options.
In the top portion of the dialog, you can specify global storage as an option. This is a concept introduced in FileMaker Pro 7 and one perhaps not immediately intuitive even for longtime FileMaker developers. Global storage for regular fields (that is, text, number, date, time, timestamp, and container) is typically used when you need a temporary storage location for a value or for infrequently changing, solutionwide values such as your company’s name and address. For instance, globally stored text fields are often used in scripts as a place to hold users’ preferences or selections as they navigate through your interface.
![]() For more information on global storage of field data, see “Storage and Indexing,” p. 104.
For more information on global storage of field data, see “Storage and Indexing,” p. 104.
If you set a calculation field to be stored globally, the results of the calculation formula will be available to you from any record and, indeed, any table in your system without having to establish a relationship to a table occurrence tied to its source table. The formula isn’t evaluated for each record in the system; it is evaluated only when one of the inputs of the formula changes or when you modify the formula.
Consider a scenario involving a sales commission calculation. You might create a utility table containing the fields necessary to calculate a daily sales commission (based on market values or whatever variable data affected the business in question) in which a manager could modify the data in the formula on demand. A global calculation then would provide the system with its current sales commission without requiring a series of relationships.
The bottom half of the Storage Options dialog enables you to specify indexing options. Indexing a field speeds up searches based on that field, but it results in larger files. FileMaker also uses field indexes for joining related tables.
![]() For more detailed information on indexing, see “Storage and Indexing,” p. 104.
For more detailed information on indexing, see “Storage and Indexing,” p. 104.
Note that the sales commission example assumes there to be one record in the utility table in question. If there were multiple records, it would be possible to include the concept of an active/inactive status into the calculation or simply rely on the fact that the last edited record will be that from which the calculation will draw its source information.
In most cases, the default indexing option for a calculation field will be set to None, and the Automatically Create Indexes as Needed box will be checked. For most calculations you write, this configuration is perfect. FileMaker determines whether an index is needed and creates one if it is. Performing a find in the field and using the field in a relationship are both actions that trigger the automatic indexing of a field.
For some calculation formulas, the default storage option is to have the Do Not Store Calculation Results option checked and for everything else to be grayed out. This is an indication that the field is unindexable. Calculation fields that return text, number, date, time, or timestamp results can be indexed as long as they are stored. Calculations can be stored as long as they don’t reference any unstored calculations, globally stored fields, related fields, or summary fields. Not saving a calculation means that finds or sorts using the field will be slower than if it is stored. For a field that is frequently used for finds, this is a serious consideration; for other fields, it might be irrelevant.
There are a few circumstances in which you’ll want to explicitly turn off storage. For instance, when you use any of the Get functions in a calculation, you should make sure that the calculation result is unstored. Get functions typically return information relating to the state of a user session. By definition, that information changes on a second-by-second basis, and formulas based on it should not be stored so that they continue to reflect present reality. If you do so, the calculation is forced to evaluate based on the current environment each time it’s evaluated (as opposed to always “remembering” the environment at the time the record was created or modified). Imagine you defined a calculation to return the number of records in the current found set by using the Get ( FoundCount ) formula. If you don’t explicitly set the results to be unstored, for a given record, the formula evaluates once and keeps that value, regardless of changes to the size of the found set. The count of found records the first time the calculation is triggered is the value that will be stored. As their name implies, unstored calculations do not make your files larger, but because they must evaluate each time you view them, they can slow down a system if they’re based on complex formulas.
As a rule of thumb, you should stick with the default storage options unless you know for sure that you need the result to be unstored. You’ll almost never need to explicitly turn indexing on; let FileMaker turn it on as necessary. Very seldom should you uncheck the option to have FileMaker turn on indexing as needed. Be aware that indexing increases the size of your files, sometimes by a great deal. By unchecking the option to have FileMaker turn on indexing as needed, you can ensure that certain fields won’t be indexed accidentally just because a user performs a find on them.
Specifying Context
Across the top of the Specify Calculation dialog, you’re asked to specify the context from which to evaluate this calculation. This choice is necessary only when the source table you are working with appears in your Relationships Graph more than once as several table occurrences. And even in those cases, it really matters only when your calculation formula involves related fields. In such cases, the calculation might return different results, depending on the context from which it’s evaluated. To make this point clear, consider the example of a database that contains transactions for buyers and sellers.
There are two tables in the database: Persons and Transactions. Figure 8.6 shows the Transactions table in Table view.

Figure 8.6. Transactions are stored with the IDs of buyer and seller as well as amount and description.
In this example, a person can act as either a buyer or a seller for a given transaction. This means then that a Persons record will have potentially two sets of related transactions: those for which that person is a seller and those for which she is a buyer.
This database, CalculationDemo, can be downloaded from the author’s website as described in the Introduction.
Figure 8.7 shows the Relationships Graph of the database. Note that there is a single Transactions table and three occurrences of the Persons table: one is named Buyers, one is named Sellers, and one has the default name Persons. Buyers and Sellers are related to Transactions by relationships between sellerID or buyerID in Transactions and the zID in the appropriate table occurrence of Persons (Buyers or Sellers).
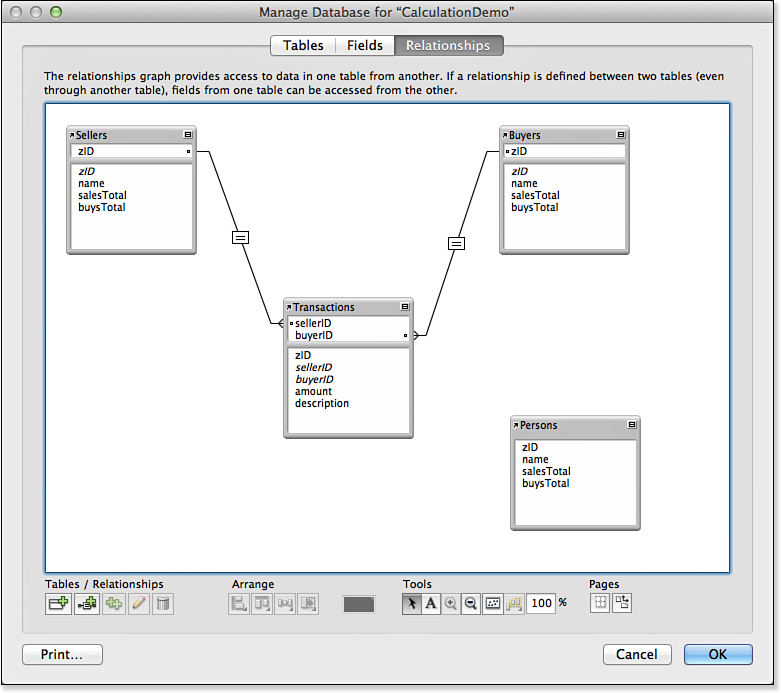
Figure 8.7. The two tables (Persons and Transactions) are the basis for four table occurrences.
Note, too, that in the Persons table (as well as the Sellers and Buyers occurrences based on it) are two additional fields: salesTotal and buysTotal. These calculation fields contain the total amount of sales and purchases for that person.
The relationship between Buyers, Sellers, and Transactions enables you to construct a layout such as the one shown in Figure 8.8. It is based on the Sellers table occurrence, and it has a portal showing the Transactions table to which the seller is related. A copy of this layout, based on the Buyers table occurrence, has a portal for Transactions based on the relationship between Buyers and Transactions.

Figure 8.8. A Sellers layout contains a portal to Transactions.
To create the salesTotal field in the Persons table, you need to use a function that sums up all sales—that is, all records in the Transactions table that are found via the relationship between Sellers and Transactions. Likewise, to create the buysTotal field, you need a calculation that sums up all records in the Transactions table found via the relationship between Buyers and Transactions.
The problem is that these two calculation fields are in the Persons table. You need a way to specify which relationship from a table occurrence of the Persons table is to be used. You do so by setting the context for the calculation using the pop-up menu at the top of the Specify Calculation dialog, as shown in Figure 8.9.

Figure 8.9. Specify the context for an ambiguous relationship.
Having specified the context, you then add the Sum function and, for the field to be summed, you select the table as shown in Figure 8.10 and then select the field.
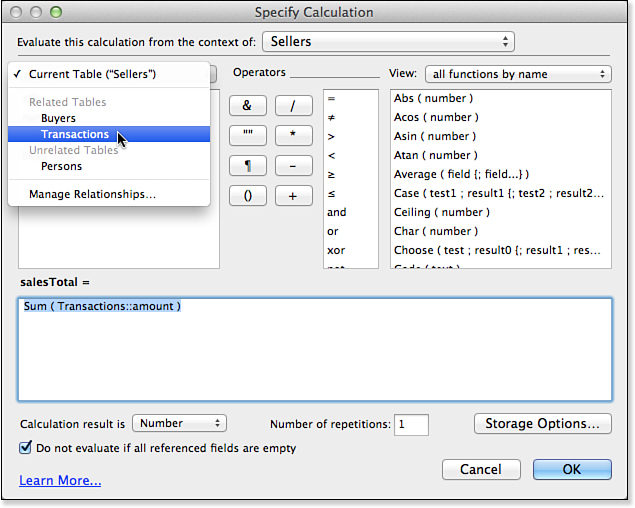
Figure 8.10. Select the table and field to be used.
As you saw from the same layout in Figure 8.8, this calculation correctly computes the totals needed. You only need to specify a context for a calculation when there is ambiguity. The ambiguity arises if the table in which you are creating a calculation has more than one relationship to the table in which a related field resides.
Essential Functions
Now that you know your way around the Specify Calculation dialog itself, it’s time to start learning more about particular calculation functions. Here is an in-depth tutorial on the most essential functions and techniques. These will form a solid base for your own work and for assembling complex formulas. As a reminder, Chapter 15 covers advanced calculation formulas and techniques.
Parts of a Function
Let’s begin with a general discussion about what functions do and how to learn about them. Their sole mission in life is to act on some set of inputs and produce an output. The inputs are usually referred to as parameters; the function’s syntax specifies the number of parameters it expects to be fed and provides a clue about what the nature of each of those parameters is.
An example will help clarify this point. Look at the syntax of the Position function as it’s taken directly from the function list in the calculation dialog:
Position ( text ; searchString ; start ; occurrence )
In English versions prior to FileMaker 7, the parameter separator was a comma. In fact, if you use commas now, they are transformed into semicolons for you.
A function’s parameters are always placed in parentheses directly after the name of the function itself. They are separated from one another by semicolons.
You can see that the Position function has four parameters. The function reference will tell you that the first parameter should be a text string in which you want to search, and the second should be a text string you want to find within it. The third parameter is a number that specifies the character number at which to begin searching. The final parameter is also a number; it specifies which occurrence of the search string to find.
Besides knowing what to feed a function (here, two text strings and two numbers), you also need to know what type of output the function produces. Again, you first learn this by consulting some reference source or the help system. There, you’d learn that the Position function returns a number—not just any number, of course, but the character number where the search string was found within the initial text string. If the string was not found at all, it returns a 0. So, for example, if you had the function
Position ( "Mary had a little lamb"; "a"; 1; 1 )
the function would return 2 because the first occurrence of the letter a is at character 2 of the input string. If you change the function slightly, to
Position ( "Mary had a little lamb"; "a"; 1; 2 )
you’d now expect a value of 7 because that’s the position of the second occurrence of the letter a.
In these examples, all the parameters were hard-coded with constant values. More typically, the parameters that you feed a function will be either fields or the outputs of other functions. For instance, if you have a field called PoemText and another called SearchCharacter, you might end up using the Position function as shown here:
Position ( PoemText; SearchCharacter; 1; 1 )
Now, each record in your database will contain a different result, dependent on the contents of those two fields.
Using functions as parameters of other functions is called nesting. In those cases, the inner functions evaluate first, and their results are used as the inputs for the outer functions. For instance, you might have the following function:
Position ( PoemText; SearchCharacter; Length( PoemText ) - 5; 1 )
Notice that the third parameter of the Position function here is the expression Length( PoemText ) - 5. The Length function (which we discuss in more detail shortly) takes a single parameter, a text string, and returns the number of characters in the string. So, in the preceding function, the length of the PoemText field will be determined, and that value less 5 will be used as the third parameter of the Position function. No practical limit exists on the number of layers you can use to nest functions within one another. Just remember that readability becomes very important as your calculations become more complex.
At this point, you know quite a bit about the Position function. You know about its inputs and outputs; you’ve worked with a few examples. Eventually, you’ll likely want to memorize the inputs and outputs of a core set of functions. For lesser-used functions, you can look up the parameters and usage on an as-needed basis. There’s still a difference between proficiency with a function and a complete understanding of it. For instance, to truly master the Position function, you’d need to know such things as whether it’s case sensitive (it’s not), and what happens if you supply a negative number for the occurrence (it searches backward from the specified start character). Over time and with use, you’ll learn about the subtle and esoteric usage of various functions, thereby moving from mere proficiency to mastery.
Let’s turn now to a close look at those functions and techniques that should form the core of your calculation knowledge.
Text Operations
Text functions enable you to interrogate and manipulate text strings. If you haven’t done much programming before, the concept of a string might require some explanation. Essentially, a string is a series of characters. Think about threading characters on a string like you do popcorn to make holiday decorations, and you’ll have a good mental image of a text string. The characters can be anything from letters and numbers to spaces and punctuation marks.
In versions of FileMaker prior to 7, the size limit for text strings was 64,000 characters. It has now been expanded to a whopping 2GB.
Typically in FileMaker, text strings are found in text fields, but be aware that you can treat any numeric, date, and time data as a text string as well. When you do that, it’s called coercing the data. FileMaker automatically coerces data into the type expected for a given operation. If you ever need to override the automatic coercion for any reason, you can use the GetAs functions. They include GetAsDate(), GetAsNumber(), GetAsTime(), and GetAsText().
The simplest text operation you can perform is concatenation. Concatenation means taking two or more text strings and placing them beside each other to form a new, longer text string. As an example, consider the following formula:
FirstName & " " & LastName
Here, we’re taking three strings, two of which happen to be field data, and we’re concatenating them into a full name format.
Let’s look next at several functions that can be used to interrogate text strings. By interrogate, we mean that we’re interested in answering a specific question about the contents of a text string. For the examples in this section, assume that you have a field called fullName with the string "Fred Flintstone" and the field someString, which contains "The quick brown fox jumped over the lazy dog". The following is a list of some of the core calculation functions with examples that apply to the fullName and someString fields:
• Length ( text )—The Length function takes a single argument and simply returns the number of characters in the string. Remember that spaces and return characters are considered characters. So, Length ( fullName ) would return 15.
• PatternCount ( text; searchString )—The PatternCount function tells you the number of times a search string occurs within some string. As an example, PatternCount ( someString; "the" ) would return 2. Note that this function is not case sensitive. If the search string is not found, the function returns 0. Although the function returns an integer, it’s often used as a true/false test when you just want to know whether something is contained in a string. That is, you don’t care where or how many times the string is found; you just care that it’s there somewhere. Recall that any nonzero value represents “true” when being used as a Boolean value.
• Position ( text; searchString; start; occurrence )—You’ve already looked in depth at the Position function. To recap, it returns an integer that specifies the place where one string is found in another. The start argument specifies where to begin the search; the occurrence argument specifies whether you want the first occurrence, the second, and so on. Much of the time, you’ll simply use 1 for both the start and the occurrence parameters.
• WordCount ( string )—WordCount is similar to the Length function, except that instead of counting every character, it counts every word. So, WordCount ( someString ) would return 9 because there are nine words in the phrase. Be careful if you use WordCount that you have a good understanding of what characters FileMaker considers as being word delimiters.
• Exact ( originalText, comparisonText )—The Exact function takes two strings as its inputs, and it compares them to see whether they are exactly the same string. It returns a 1 if they are, a 0 if not. By “exactly,” we mean exactly; this function is case sensitive. The order of the two input arguments is irrelevant.
The other broad category of text operators consists of those functions that enable you to manipulate a string. Whereas the interrogatory functions returned a number, these functions all return a string. You feed them a string; they do something with it and spit back another string. The text operators that fall into this category are explained in the following sections.
Trim()
The simplest of these functions is the Trim ( text ) function. Trim() takes a string and removes any leading or trailing spaces from it. Spaces between words are not affected; no other leading or trailing characters other than a space (that is, return characters at the end of a field) are removed.
There are two common uses of Trim(). The first is to identify data-entry problems. Imagine you have a field called FirstName and that some users have been accidentally typing spaces after the first name. You might want to display a message on such records, alerting users to that error. You’d define a new calculation field, called something like SpaceCheck. Its formula could be one of the following:
Case ( FirstName ≠ Trim ( FirstName ), "Extra Space!" )
Case ( not Exact( FirstName, Trim ( FirstName )), "Extra Space!" )
Case ( Length( FirstName ) > Length( Trim( FirstName )), "Extra Space!" )
![]() To review the use and syntax of the
To review the use and syntax of the Case() function, see “Using Conditional Functions,” p. 240.
The other common usage of Trim() is in a calculated replace to clean up fixed-length data that has been imported from another application. Fixed length means that the contents of a field are padded with leading or trailing spaces so that the entries are all the same length. After importing such data, you’d simply replace the contents of each field with a trimmed version of itself.
Substitute()
The next text manipulation function we’ll explore is the Substitute() function. Substitute ( string; searchString; replacementString ) is used to replace every occurrence of some substring with some other substring. So Substitute( fullName; "Fred"; "Wilma") would return the string "Wilma Flintstone". If the initial substring were not found, the Substitute function would simply return the original string. You should be aware that the Substitute() function is case sensitive.
One common use of Substitute() is to remove all occurrences of some character from a string. You just substitute in an empty string for that character. For instance, to remove all occurrences of a carriage return from a field, you could use Substitute ( myString; "¶"; “”). If there are multiple substitutions you want to make to a string, you simply list them all as bracketed pairs in the order in which they should be performed. Let’s say you have a PhoneNumber field from which you want to strip out any parentheses, dashes, or spaces that users might have entered. One way to do this would be to use the following formula:
Substitute (PhoneNumber; ["("; ""] ; [")"; ""] ; ["-"; ""] ; [" ", ""])
Be aware when performing multiple substitutions like this that the substitutions happen in the order in which they are listed, and that each subsequent substitution happens on an altered version of the string rather than on the original string. Say you had the string "xxyz" and you wanted to put z’s where there are x’s, and x’s where there are z’s. The formula Substitute ("xxyz"; ["x"; "z"]; ["z"; "x"]) incorrectly returns "xxyx". First, the two leading x’s are turned to z’s, yielding "zzyz"; then all three z’s are turned into x’s. If you ever want to swap two characters like this, you need to temporarily turn the first character into something you know won’t be found in your string. So to fix this example, we could use the formula Substitute("xxyz"; ["x"; "**TEMP**"]; ["z"; "x"]; ["**TEMP**", "z"]). That would correctly yield "zzyx".
Case-Altering Functions
You can use a few text functions to alter a string’s case. These are Lower ( text ), Upper ( text ), and Proper ( text ). It’s quite intuitive how these act. Lower ("Fred") returns "fred"; Upper ("Fred") returns "FRED". Using Proper() returns a string in which the first letter of each word is capitalized. For instance, Proper ("my NAME is fred") returns "My Name Is Fred".
Text-Parsing Functions
The final category of text operators we’ll look at here is text-parsing functions. Text-parsing functions enable you to extract a substring from a string. The six text-parsing functions are Left(), Middle(), Right(), LeftWords(), MiddleWords(), and RightWords(). The first three operate at the character level; the other three operate at the word level.
The Left() function extracts a substring of length N from the beginning of some string. For example, Left ( "Hello"; 2 ) returns the string "He"; it simply grabs the first two characters of the string. If the number of characters you ask for is greater than the length of the string, the function simply returns the entire string. A negative or zero number of characters results in an empty string being returned.
The Right() function is similar, except that it grabs characters from the end of the specified string. Right ( "Hello"; 2 ) would return "lo". Middle(), as you might expect, is used to extract a substring from the middle of a string. Unlike the Left() and Right() functions, which require only a string and a length as parameters, the Middle function requires a starting position. The syntax is Middle ( text; startCharacter; numberOfCharacters ). For example, Middle ( "Hello"; 2; 3 ) yields "ell".
The LeftWords(), MiddleWords(), and RightWords() functions all operate exactly as Left(), Middle(), and Right() functions, except that they operate at the word level. One typical use of these functions is to extract names or addresses you’ve imported as a lump of data from some other application. Say that your import resulted in contact names coming in as full names. You might want to create a LastName calculation field so that you could sort the records. If you knew that the last name was always the last word of the FullName field, you could use the formula RightWords ( FullName; 1 ).
Nested Functions
The text operators we discussed often appear nested within each other in formulas. Writing nested formulas can be tricky sometimes. One thing that helps is to think of a particular example rather than trying to deal with it abstractly. For instance, let’s say that you have a big text field, and you need a formula that extracts just its first line—that is, everything up until the first carriage return. So, imagine that you had the following text:
The quick
brown fox
jumped over the
lazy dog
Think first: What text-parsing formulas would potentially yield "The quick" from this text? Well, there are several of them:
Left (myText; 9)
LeftWords (myText; 2)
Middle (myText; 1; 9)
Of course, at this point these formulas apply only to this particular example. Think next: Could one of these be extended easily to any multiline text field? If there were a constant number of words per line, the LeftWords() formula would work. And if not? What do the text interrogation formulas tell us about this field? Length ( myText ) is 44. Not particularly helpful. PatternCount ( myText; "¶" ) is 3. This indicates that there are four lines total. Interesting, but not obviously helpful for extracting the first line. WordCount ( myText ) is 9. It’s just coincidence that this is the number of characters in the first line; be careful not to be misled. Position ( myText; "¶"; 1; 1 ) is 10. Finally, something interesting. In this example, the length of the first line is one less than the position of the first carriage return. Is that true in all cases? At this point, if you write out a few more examples, you’ll see that indeed it is. Therefore, a general formula for extracting the first line of text is
Left ( myText; Position( myText, "¶"; 1; 1 ) - 1 )
How about extracting the last line from any multiline text field? You should approach this problem the same way, working from a specific example. Counting characters by hand, assemble a list of options:
Middle ( myText; 36, 8 )
Right ( myText; 8 )
RightWords ( myText; 2 )
What clues do the interrogatory functions yield? If you spend a few minutes thinking about it, you’ll realize that 36 is the position of the last return character. You can derive that by using the number of returns as the occurrence parameter in a Position() function, like this:
Position ( myText; "¶"; 1; PatternCount( myText; "¶" ))
After you have the 36 figured out, recall that the length of the string is 44 characters, and notice that 44 – 36 = 8. Given these discoveries, you’ll soon see that a simple and elegant generalized formula for grabbing the last line of a text field is
Right (myText; Length ( myText ) - Position( myText; "¶"; 1; PatternCount( myText; "¶" )))
Number Functions
In general, most people find working with math functions simpler and more intuitive than working with string functions. Perhaps the reason is that they remind us of various high-school math courses. Or it could be they typically have fewer parameters. Regardless, you’ll find yourself using number functions on a regular basis. This chapter focuses not so much on what these functions do, but rather on some interesting applications for them.
The first set of functions we’ll look at includes Int(), Floor(), Ceiling(), Round(), and Truncate(). Each of these can be thought of as performing some sort of rounding, making it sometimes difficult to know which one you should use. You can look up these functions in the help system for complete syntax and examples, but it’s helpful to consider the similarities and differences of these functions as a set. Here’s a rundown:
• Int ( number )—The Int() function returns the integer portion of the number that it’s fed—that is, anything before the decimal point. Int ( 4.5 ) returns 4. Int ( -2.1 ) returns -2.
• Floor ( number )—Floor() is similar to Int(), except that it returns the next lower integer of the number it’s fed—unless that number is an integer itself, of course, in which case Floor() just returns that integer. For any positive number, Floor ( number ) and Int ( number ) return the same value. For negative numbers, though, Floor ( number ) and Int ( number ) don’t return the same value unless number is an integer. Floor ( -2.1 ) returns -3, whereas Int ( -2.1 ) returns -2.
• Ceiling ( number )—The Ceiling() function is complementary to the Floor() function: It returns the next higher integer from the number it’s fed (unless, again, that number is already an integer). For example, Ceiling ( 5.3 ) returns 6 and Ceiling ( -8.2 ) returns -8.
• Round ( number; precision )—Round() takes a number and rounds it to the number of decimal points specified by the precision parameter. At the significant digit, numbers up to 4 are rounded down; numbers 5 and above are rounded up. So, Round ( 3.6234; 3 ) returns 3.623, whereas Round ( 3.6238; 3 ) returns 3.624. Using a precision of 0 rounds to the nearest whole number. Interestingly, you can use a negative precision. A precision of -1 rounds a number to the nearest 10; -2 rounds to the nearest 100, and so on.
• Truncate ( number, precision )—Truncate() is similar to Round(), but Truncate() simply takes the first n digits after the decimal point, leaving the last one unaffected regardless of whether the subsequent number is 5 or higher. Truncate ( 3.6238; 3 ) returns 3.623. For any number, Truncate ( number; 0 ) and Int ( number ) return the same value. Just as Round() can take a negative precision, so can Truncate(). For example, Truncate ( 258; -2 ) returns 200.
Which function you use for any given circumstance depends on your needs. If you’re working with currency and want to add an 8.25% shipping charge to an order, you’d probably end up with a formula such as Round ( OrderTotal * 1.0825 ; 2 ). Using Truncate() might cheat you out of a penny here or there.
Floor(), Ceiling(), and Int() have some interesting uses in situations where you want to group numeric data into sets. For instance, imagine you have a list report that prints ten records per page and that you have a found set of 57 records to print. If you want, for whatever reason, to know how many pages your printed report would be, you could use Ceiling ( Get( FoundCount )/10 ). Similarly, if you want to know what page any given record would print on, you would use the formula Floor ( (Get( RecordNumber )-1 )/10 ) + 1. The Int() function would yield the same result in this case.
Another common use of these functions is to round a number up or down to the multiple of some number. As an example, say you had the number 18, and you want to know the multiples of 7 that bounded it (...14 and 21). To get the lower bound, you can use the formula Floor ( 18/7 )* 7; the upper bound is Ceiling ( 18/7 )* 7. These generalize as the following:
Lower bound: Floor ( myNum / span ) * span
Upper bound: Ceiling ( myNum / span ) * span
The span can be any number, including a decimal number, which comes in handy for rounding currency amounts, say, to the next higher or lower quarter.
You should know a few other number functions as well:
• Abs ( number )—The Abs() function returns the absolute value of the number it’s fed. One interesting use of the function is to determine which platform FileMaker Pro is running on. The three possible return values are –1 for PowerPC-based Macs, 1 for Intel-based Macs, and –2 for Windows. Abs ( Get ( SystemPlatform ) ) returns 1 for both flavors of Macs.
• Mod ( number; divisor )—The Mod() function returns the remainder when a number is divided by a divisor. For instance, Mod ( 13; 5 ) returns 3 because 13 divided by 5 is 2, remainder 3.
• Div ( number; divisor )—The Div() function is complementary to the Mod() function. It returns the whole-number result of dividing a number by a divisor. For instance, Div ( 13; 5 ) would return 2. In all cases, Div ( number; divisor ) and Floor ( number/divisor ) return exactly the same value; it’s a matter of personal preference or context which you should use.
• Random()—The Random() function returns a random decimal number between 0 and 1. Usually, you’ll use the Random() function when you want to return a random number in some other range, so you’ll need to multiply the result of the function by the span of the desired range. For instance, to simulate the roll of a six-sided die, you use the formula Ceiling ( Random * 6 ). To return a random integer between, say, 21 and 50 (inclusive), the method would be similar: First, you generate a random number between 1 and 30, and then you add 20 to the result to translate it into the desired range. The formula would end up as Ceiling ( Random * 30 ) + 20.
Character Functions
In their simplest form, these character functions let you convert a character to its numeric code, and vice versa. This capability is particularly useful in dealing with special characters such as the Return key. Because FileMaker Pro supports Unicode, these functions actually work on Unicode code points, but many people refer to ASCII codes, which are a subset of Unicode code points:
• Char ( number )—This function returns a character for a Unicode code point. It may return more than one character if the number string describes multiple characters.
• Code ( text )—This is the reverse of the preceding function: It provides a text string (often a single character), and the function returns its numeric value. This function is often used with Get ( TriggerKeystroke ), which is described in “Get Function,” later in this chapter.
Working with Dates and Times
Just as there are functions for working with text and numbers, FileMaker Pro provides functions that enable you to manipulate date and time fields. This section introduces you to the most common and discusses some real-world applications you’ll be likely to need in your solutions.
The most important point to understand at the outset is how FileMaker itself stores dates, times, and timestamps. Each is actually stored as an integer number. For dates, this integer represents a serialized number beginning with January 1, 0001. January 1, 0001, is 1; January 2, 0001, is 2; and so on. As an example, October 19, 2013, is stored by FileMaker as 735160. FileMaker understands dates from January 1, 0001, until December 31, 4000.
Times are stored as the number of seconds since midnight. Midnight itself is 0. Therefore, times are typically in the range of 0 to 83999. It’s worth knowing that time fields can contain not only absolute times, but also elapsed times. That is, you can type 46:18:19 into a time field, and it will be stored as 166699 seconds. Negative values can be placed in time fields as well. FileMaker doesn’t have the capability to deal with microseconds; however, it can manage fractional elements:
10:15:45.99 is a valid time within FileMaker and 10:15:45.99 - 10:15:44 = 00:00:01.99. Note that this is not hundredths of a second, but rather simply a case of using a decimal instead of an integer.
Timestamps contain both a date and time. For example, “10/19/2013 8:55:03 AM” is a timestamp. Internally, timestamps are converted to the number of seconds since midnight on January 1, 0001. You could derive this number from date and time fields with the formula (( myDate - 1 ) * 86400 ) + myTime.
The easiest way to begin learning date, time, and timestamp functions is to split them into two categories: those that you feed a date or time and that return a “bit” of information back, and those that are constructors, in which you feed the function bits and you get back a date, time, or timestamp. These aren’t formal terms that you’ll find used elsewhere, but they’re nonetheless useful for learning date and time functions.
The “bit” functions are fed dates and times, and they return numbers or text. For instance, say that you have a field myDate that contains the value 10/19/2013. Here’s a list of the most common “bit” functions and what they’d return:
Month ( myDate ) = 10
MonthName ( myDate ) = October
Day ( myDate ) = 19
DayName ( myDate ) = Saturday
DayOfWeek ( myDate ) = 7
Year ( myDate ) = 2013
Similarly, a field called myTime with a value of 9:23:10 AM could be split into its bits with the following functions:
Hour ( myTime ) = 9
Minute ( myTime ) = 23
Seconds ( myTime ) = 10
You need to know only three constructor functions. Each is fed bits of data and returns, respectively, a date, time, or timestamp:
Date ( month; day; year )
Time ( hours; minutes; seconds )
TimeStamp ( date; time )
For example, Date ( 10; 20; 2013 ) returns 10/20/2013. TimeStamp ( myDate; myTime ) might return 10/19/2013 9:23:10 AM. When using these formulas in calculation fields, be sure to check that you’ve set the calculation result to the proper data type.
One very interesting and useful fact to know about these constructor functions is that you can “overfeed” them. For example, if you ask for Date ( 13; 5; 2013 ), the result will be 1/5/2014. If the bits you provide are out of range, FileMaker automatically adjusts accordingly. Even zero and negative values are interpreted correctly. Date ( 10; 0; 2013 ) returns 9/30/2013 because that’s one day before 10/1/2013.
Using Date and Time Functions
There are many practical uses of the date and time functions. For instance, the “bit” functions are often used to generate a break field that can be used in subsummary reports. Say that you have a table of invoice data, and you want a report that shows totals by month and year. You would define a field called InvoiceMonth with the formula Month ( InvoiceDate ) and another called InvoiceYear with a formula of Year ( InvoiceDate ).
A common use of the constructor functions is to derive a date from the bits of a user-entered date. Say, for example, that a user entered 10/19/2013 into a field called myDate, and you wanted a calculation formula that would return the first of the next month, or 11/1/2013. Your formula would be Date ( Month( myDate ) +1; 1; Year( myDate )).
If you’re importing dates from other systems, you might have to use text-manipulation functions in conjunction with the constructor functions to turn the dates into something FileMaker can understand. Student information systems, for example, often store students’ birth dates in an eight-digit format of MMDDYYYY. To import and clean this data, you first bring the raw data into a text field. Then, using either a calculated replace or a looping script, you would set the contents of a date field to the result of the formula:
Date (
Left ( ImportedDate; 2 );
Middle( ImportedDate; 3; 2 );
Right( ImportedDate; 4 )
)
Using Timestamps
Timestamps are quite useful for logging activities, but sometimes you’ll find that you want to extract either just the date or just the time portion of the timestamp. The easiest way to do this is via the GetAsDate() and GetAsTime() functions. When you feed either of these a timestamp, it returns just the date or time portion of that timestamp. Similarly, if you have a formula that generates a timestamp, you can set the return data type of the calculation result to date or time to return just the date or just the time.
Using Conditional Functions
Conditional functions are used when you want to return a different result based on certain conditions. The most basic and essential conditional function is the If() function. If takes three parameters: a test, a true result, and a false result. The test needs to be a full equation or expression that can evaluate to true or false.
Let’s look at an example. Suppose you have a set of records containing data about invoices. You’d like to display the status of the invoice—“Paid” or “Not Paid”—based on whether the AmountDue field has a value greater than zero. To do this, you’d define a new field, called InvoiceStatus, with the following formula:
If ( AmountDue > 0, "Not Paid", "Paid")
For each record in the database, the contents of the InvoiceStatus field will be derived based on the contents of that record’s AmountDue field.
The test can be a simple equation, as in the preceding example, or it can be a complex test that uses several equations tied together with and and or logic. For the test
If ( A and B; "something"; "something else")
both A and B have to be true to return the true result. However, for the test
If ( A or B; "something"; "something else" )
if either A or B is true, it will return the true result.
The true or false result arguments can themselves be If() statements, resulting in what’s known as a nested If() statement. This allows you to test multiple conditions and return more than two results. For instance, let’s revise the logic of the InvoiceStatus field. Say that we wanted invoices with a negative AmountDue to evaluate as Credit Due. We could then use the following field definition:
If ( Amount Due > 0; "Not Paid"; If (Amount Due < 0; "Credit Due"; "Paid" ))
The other commonly used conditional function is the Case() statement. The Case() statement differs from the If() statement in that you can test for multiple conditions without resorting to nesting. For instance, say that you have a field called GenderCode in a table that contains either M or F for a given record. If you wanted to define a field to display the full gender, you could use the following formula:
Case ( GenderCode = "M"; "Male"; GenderCode="F"; "Female" )
A Case() statement consists of a series of tests and results. The tests are conducted in the order in which they appear. If a test is true, the following result is returned; if not, the next test is evaluated. FileMaker stops evaluating tests after the first true one is discovered. You can include a final optional result that is returned if none of the tests comes back as true. The gender display formula could be altered to include a default response as shown here:
Case ( GenderCode = "M"; "Male"; GenderCode="F"; "Female"; "Gender Unknown" )
Without the default response, if none of the tests is true, then the Case() statement returns a null value.
Aggregate Functions
Another important category of functions includes those known as aggregate functions. They include Sum(), Count(), Min(), Max(), and Avg(). These functions all work in similar, quite intuitive ways. Each operates on a set of inputs (numeric, except for the Count() function) and produce a numeric output. The name of the function implies the operation each performs. Sum() adds a set of numbers, Min() and Max() return (respectively) the smallest and largest items of a set, Avg() returns the arithmetic mean of the numbers, and Count() returns the number of non-null values in the set. List() returns a text field with the inputs concatenated together and separated by carriage returns.
The inputs for an aggregate function can come from any one of three sources:
• A series of delimited values—For example, Sum ( 6; 4; 7; 2 ) yields 19. Average ( 6; 4; 7; 2 ) yields 4.75. An interesting use of the Count() function is to determine the number of fields in a record into which a user has entered values. For instance, Count ( FirstName; LastName; Phone; Address; City; State; Zip ) returns 2 if the user enters values into only those two fields.
• A repeating field—Repeating fields enable you to store multiple values within a single field within the same record. For instance, you might have repeating fields within a music collection database for listing the tracks and times of the contents of a given disc. The functions Count ( Tracks ) and Sum ( Times ) produce the number of tracks and the total playing time for a given disc.
• A related field—By far, this is the most common application for aggregate functions. Imagine that you have a Customer table and an Invoices table and you want to create a field in Customer that totals up all the invoices for a particular customer. That field would be defined as Sum ( Invoices::InvoiceTotal ). Similarly, to tell how many related invoices a customer had, you could use the formula Count ( Invoices:: CustomerID ).
When you are using the Count() function to count related records, it usually doesn’t matter what field you count, as long as it’s not empty. The count will not include records where the specified field is blank. Typically, you should count either the related primary key or the related foreign key because these, by definition, should contain data.
Learning About the Environment: Introspective Functions
FileMaker has two categories of functions whose job it is to tell you information about the environment—the computing and application environment, that is. These are the Get() functions and the Design() functions. There are more than 70 Get() functions and 20 Design() functions. Here, our goal is to give you an overview of the types of things these functions do and some of the most common uses for them.
Get Function
A Get() function provides a broad array of information about a user’s computing environment and the current state of a database. Each takes a single parameter that identifies the type of information you want.
As an example, the Get ( TotalRecordCount ) function returns the total number of records in some table. One typical use for this is as the formula for a calculation field. If you have hidden the Status Area from users, this field could be used as part of constructing your own “Record X of Y” display. If you’re using this function in a script—or any Get() function, for that matter—be sure that you’re aware that the active layout determines the context in which this function is evaluated.
Whenever you use a Get() function as part of a field definition, you need to be acutely aware of the storage options that have been set for that field. For Get() functions to evaluate properly, you must explicitly set the calculation to be unstored. If it is not set this way, the function evaluates only once when the record is created; it reflects the state of the environment at the time of record creation, but not at the current moment. Setting the calculation field to unstored forces it to evaluate every time the field is displayed or used in another calculation, based on the current state of the environment.
Frequently Used Get Functions
Although you don’t need to memorize all the Get() functions, a handful of them are used frequently and should form part of your core knowledge of functions. To remember them, you might find it helpful to group them into subcategories based on their function.
The first subcategory includes functions that reveal information about the current user:
Get ( AccountName )
Get ( ExtendedPrivileges )
Get ( PrivilegeSetName )
Get ( UserName )
Get ( UserCount )
Another subcategory includes functions used frequently in conditional tests within scripts to determine what actions should be taken:
Get ( ActiveModifierKeys )
Get ( LastMessageChoice )
Get ( LastError )
Get ( ScriptParameter )
There are four functions for returning the current date and time:
Get ( CurrentDate )
Get ( CurrentHostTimeStamp )
Get ( CurrentTime )
Get ( CurrentTimeStamp )
Many Get() functions tell you where the user is within the application and what the user is doing:
Get ( FoundCount )
Get ( LayoutNumber )
Get ( LayoutName )
Get ( LayoutTableName )
Get ( PageNumber )
Get ( PortalRowNumber )
Get ( RecordNumber )
Another group of functions reveals information about the position, size, and name of the current window:
Get ( WindowName )
Get ( WindowTop )
Get ( WindowHeight )
Get ( WindowWidth )
The last set of functions lets you find two file paths. You can use them in scripts when you need to create an exported file from FileMaker Pro or a PDF file. The desktop path is just that: the path to the user’s desktop. On both OS X and Windows it is a fully qualified path name, which means that it starts at the drive (a letter like C: in Windows or a name in OS X). You can use the path as a prefix for a file that you will create on the user’s desktop. Alternatively, you can use text functions in FileMaker to drop Desktop/ from the end of the path so that you can save a file in another location inside the user’s home folder.
The new Get ( TemporaryPath ) function in FileMaker Pro 10 and later gives you access to a folder created by FileMaker Pro (or by FileMaker Server) for each session (FileMaker Pro) or schedule (FileMaker Server). This folder is automatically deleted when the program ends. You can place files in this folder confident that they will not clutter up the user’s hard disk once FileMaker Pro has terminated.
Get ( DesktopPath )
Get ( TemporaryPath )
To see the list of Get() functions in the Specify Calculation dialog, you have to toggle the view to either All Functions by Type or to just the Get functions. They don’t show up when the view is All Functions by Name. Be aware that there are a number of functions with Get in their name that aren’t Get() functions. They include functions such as GetRepetition(), GetField(), GetAsText(), and GetSummary(). These are not functionally related in any way to the Get() functions that have just been discussed.
Design Functions
The Design functions are used to get information about the structure of a database file itself. With just two exceptions—specifically, DatabaseNames() and WindowNames()—not one of the Design functions is session dependent. That is, the results returned by these functions won’t differ at all based on who is logged in or what that user is doing. Unlike the Get() functions, Design functions often take parameters.
Fully half of the Design functions simply return lists of names or IDs of the major structural components of a file. These include the following:
FieldIDs ( fileName; layoutName )
FieldNames ( fileName; layout/tableName )
LayoutIDs ( fileName )
LayoutNames ( fileName )
ScriptIDs ( fileName )
ScriptNames ( fileName )
TableIDs ( fileName )
TableNames ( fileName )
ValueListIDs ( fileName )
ValueListNames ( fileName )
Six other Design functions return information about a specified field:
FieldBounds ( fileName ; layoutName ; fieldName )
FieldComment ( fileName ; fieldName )
FieldRepetitions ( fileName ; layoutName ; fieldName )
FieldStyle ( fileName ; layoutName ; fieldName )
FieldType ( fileName ; fieldName )
GetNextSerialValue ( fileName ; fieldName )
The DatabaseNames() function returns a list of the databases that the current user has open. The list doesn’t include file extensions, and it doesn’t distinguish between files that are open as a host versus those that are open as a guest.
Similarly, the WindowNames() function returns a list of the window names that the current user has open. The list is ordered by the stacking order of the windows; it includes both visible and hidden windows across all the open database files.
Typically, the DatabaseNames() and WindowsNames() functions are used to check whether a user has a certain database file or window open already. For instance, if you have a navigation window that you always want to be open, you can have a subscript check for its presence and open it if the user closed it. To do this, you use the formula PatternCount ( WindowNames; "Nav Window" ). This formula returns a 0 if there was no open window whose name included the string "Nav Window".
The final Design function is ValueListItems ( fileName ; valueList ). This function returns a list of the items in the specified value list. As with most of the Design functions, the primary purpose of this function is to help you catalog or investigate the structure of a file. There’s another common usage of ValueListItems() that is handy to know. Imagine that you have a one-to-many relationship between a table called Salespeople and a table called Contacts, which contains demographic information about all of a salesperson’s contacts. For whatever reason, you might want to assemble a list of all the cities where a salesperson has contacts. You can do this by defining a value list based on the relationship that shows the City field and then creating an unstored calculation field in Contacts with the formula ValueListItems ("Contacts"; "CityList"). For any given salesperson record, this field will contain the “sum” of all the cities where the salesperson has contacts.
Device Identification Functions
FileMaker’s built-in security mechanism lets you determine and control who is using your database. The device identification functions let you determine what device they are using. These functions return either
• UUID—This is the Universally Unique Identifier of the device. It is a text string containing letters and numbers separated by hyphens.
• PersistentID—This is an MD5 hash value of the UUID.
The UUID is the actual identifier value. If you display it or store it in a database, you have identified the user’s device, and that may be an invasion of privacy. The MD5 has the value of the PersistentID and is a one-way encryption of the UUID.
This means that you can store the hash value in your database safely. At another time, you can check to see whether the PersistentID of the current device matches that of the previous device. If so, the same device is being used. However, because these values are hashed, you do not directly check whether the device is the same, which could reveal the UUID. You only check to see if the current and former PersistentID values are the same.
Mobile Functions
Scripts that can be run on mobile devices can interrogate the location of the device.
Location returns the latitude and longitude of the device. It takes a single required parameter, accuracy. This is the accuracy of the distance in meters of the returned result. You can optionally provide timeout, which is the number of seconds after which to stop the query. The latitude and longitude are returned as two comma-separated values. If the timeout or accuracy prevent the location from being returned, you get and empty string.
This function is only available on mobile devices; on FileMaker Pro, it is a no-op (that is, not an error, just no operation).
For more precise location information, you can use LocationValues, which takes the same parameters. It returns six values you can parse using GetValue:
• Latitude in decimal
• Longitude in decimal
• Altitude in decimal
• Horizontal accuracy in integer meters
• Vertical accuracy in integer meters
• Age of value in decimal minutes
Again, you might get an empty string returned if the accuracy or timeout prevent completion of the request.
Troubleshooting
Formulas in Scripts Require Explicit Table Context
I’m used to being able to type field names into calculation formulas rather than selecting them from the field list. Sometimes, even if I’ve typed the field name correctly, I get a Field not found message when trying to leave the calculation dialog. It seems that sometimes calculations need the table occurrence name before the field name, and sometimes they don’t. What are the rules for this?
When you define calculation fields, any fields within the current table can be entered into the formula without the table context being defined. For instance, you might have a FullName field defined to be FirstName & " " & LastName.
All formulas you write anywhere within ScriptMaker require that the table context be explicitly defined for every field, even when there’s only a single table in the file. For instance, if you wanted to use a Set Field script step to place a contact’s full name into a field, you wouldn’t be able to use the preceding formula as written. Instead, it would need to be something like Contact::FirstName & " " & Contact::LastName.
If you’re used to being able to manually type field names into formulas, be aware that the table context must be included for every field referenced in the formula. The reason for this is that the table context for a script is determined by the active layout when the script is executed. Contact::FirstName might have a very different meaning when evaluated on a layout tied to the Contact table than it would, say, on one tied to an Invoice table.
Errors Due to Improper Data Type Selection
I’ve heard that the data type selection for calculation fields is important. What kind of problems will I have if I select the wrong data type, and how do I know what type to choose?
Every time you define a calculation field, no matter how simple, be sure to check the data type that the formula is defined to return. The default data type is Number unless you’re defining multiple calculations in a row, in which case the default for subsequent fields will be the data type defined for the previous calculation.
A number of errors can result from selecting the improper data type. For instance, if your formula returns a text string but you leave the return data type as Number, any finds or sorts you perform using that field will not return the expected results.
Be especially aware that formulas that return dates, times, and timestamps are defined to have date, time, and timestamp results. If you leave the data type as Number, your field displays the internal serial number that represents that date and/or time. For instance, the formula Date ( 4 ; 26 ; 2013 ) returns 734984 if the date type is set to number.
FileMaker Extra: Tips for Becoming a Calculation Master
As mentioned at the outset of this chapter, mastering the use of calculation formulas takes time. We thought it would be helpful to compile a list of tips to help you get started on the path:
• Begin with a core—Don’t try to memorize everything at once; chances are you’ll end up frustrated. Instead, concentrate on building a small core of functions that you know inside and out and can use without having to look up the syntax or copy from examples. Then gradually expand the core over time. As you have a need to use a new function, spend a few minutes reading about it or testing how it behaves in various conditions.
• Work it out on paper first—Before writing a complex formula, work through the logic with pencil and paper. This way, you can separate the logic from the syntax. You’ll also know what to test against and what to expect as output.
• Search for alternative methods of doing the same thing—It’s uncommon to have only one way to approach a problem or only one formula that will suit a given need. As you write a formula, ask yourself how else you might be able to approach the problem, and what the pros and cons of each method would be. Try to avoid the “if your only tool is a hammer, all your problems look like nails” situation. For instance, if you always use If() statements for conditional tests, be adventurous and see whether you could use a Case() statement instead.
• Strive for simplicity, elegance, and extensibility—As you expand your skills, you’ll find that it becomes easy to come up with multiple approaches to a given problem. So how do you choose which to use? We suggest that simplicity, elegance, and extensibility are the criteria to judge by. All other things being equal, choose the formula that uses the fewest functions, has tightly reasoned logic, or can be extended to handle other scenarios or future needs most easily. This doesn’t mean that the shortest formula is the best. The opposite of simplicity and elegance is what’s often referred to as the brute-force approach. There are certainly situations in which that’s the best approach, and you shouldn’t hesitate to use such an approach when necessary. But if you want to become a calculation master, you’ll need to have the ability to go beyond brute-force approaches as well.
• Use comments and spacing—Part of what makes a formula elegant is that it’s written in a way that’s logical and transparent to other developers. There might come a time when someone else needs to take over development of one of your projects, or when you’ll need to review a complex formula that you wrote years before. By commenting your formulas and adding whitespace within your formulas, you make it easier to expand on and troubleshoot problems in the future.
• Be inquisitive and know where to get the answer—As you write formulas, take time to digress and test hunches and learn new things. Whip up little sample files to see how something behaves in various conditions. Also, know what resources are available to you to get more information when you get stuck or need help. The Help system and online discussion groups are all examples of resources you should take advantage of.
• Use your keyboard—Entering a less-than character followed by a greater-than character (<>) equates to the “not equal to” operator (≠) within an expression. The following expressions are functionally identical:
1 <> 2
1 ≠ 2
This is true for >= and <= for > and <, respectively.
• Use tabs to improve clarity—To enter a tab character into an expression (either as literal text or simply to help with formatting), use (Option-Tab) [Ctrl+Tab].
• Learn the exceptions—FileMaker allows for a shorthand approach to entering conditional Boolean tests for non-null, nonzero field contents. The following two expressions are functionally identical:
Case ( fieldOne; "true"; "false" )
Case ( (IsEmpty (text) or text = 0); "false"; "true" )
Note that the authors do not recommend this shortcut as a best practice. We tend to believe you should write explicit (and, yes, more verbose) code, leaving no room for ambiguity, but if you ever inherit a system from another developer who has used this approach, you’ll need to be able to grasp it.
• Use defaults with conditionals—FileMaker allows for optional negative or default values in both the Case() and If() conditional functions. The following expressions are both syntactically valid:
Case (
fieldOne = 1; "one";
fieldOne = 2; "two"
)
Case (
fieldOne = 1; "one";
fieldOne = 2; "two";
"default"
)
We strongly recommend you always provide a default condition at the end of your Case statements, even if that condition should “never” occur. The next time your field shows a value of “never happens,” you’ll be glad you did.
• Remember that Case short-circuiting can simplify logic—The Case() function features a “short-circuiting” functionality whereby it evaluates conditional tests only until it reaches the first true test. In the following example, the third test will never be evaluated, thus improving system performance:
Case (
1 = 2; "one is false";
1 = 1; "one is true";
2 = 2; "two is true"
)
• Repeating value syntax—Note that fields with repeating values can be accessed either using the GetRepetition() function or via a shorthand of placing an integer value between two brackets. The following are functionally identical:
Quantity[2]
GetRepetition ( Quantity; 2 )
• Common calculations—Create custom functions for common calculations, particularly those that are specific to your solution or to a set of solutions. For example, you can create a custom function that takes a date and returns the fiscal year or the quarter in which it occurs. Depending on the chances of your company changing its accounting year, you might choose to incorporate the start date of the fiscal year into the custom function itself or to place it in a more changeable location such as a custom-built table for such settings.