
Similar to any other GAN, the generator G and the discriminator D in the Stack-II GAN can also be trained by maximizing the loss for the discriminator and minimizing the loss for the generator network.
The generator loss  can be represented as follows:
can be represented as follows:

The preceding equation is pretty self-explanatory. It represents the loss function for the discriminator network, in which both networks are conditioned on the text embeddings. One major difference is that the generator network has  and
and 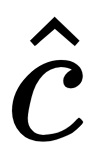 as inputs, where
as inputs, where  is the image generated by the Stage-I and
is the image generated by the Stage-I and 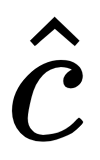 is the CA variable.
is the CA variable.
The discriminator loss 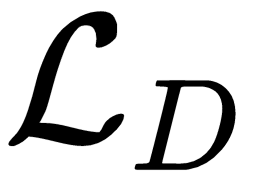 can be represented as follows:
can be represented as follows:

The preceding equation is also pretty self-explanatory. It represents the loss function for the generator network, in which both networks are conditioned on the text embeddings. It also includes a Kullback-Leibler (KL) divergence term to the loss function.