


Miscellaneous enhancements
This chapter describes the following IBM i 7.1 changes or enhancements:
19.1 Licensed product structures and sizes
The IBM i 7.1 operating system and licensed product (LPP) sizes are documented in the IBM i 7.1 Knowledge Center in the section Licensed program releases and sizes:
The DVD installation media is consolidated for IBM i 7.1 into three sets of multiple language version media that support a total of 51 globalizations.
With IBM i 7.1, there is no offline installation version of the IBM i Knowledge Center that is included on physical media. The IBM i 7.1 Knowledge Center is available online:
The following changes to the licensed product (LPP) structure are implemented in IBM i 7.1:
•DHCP moved from the base OS to option 31 “Domain Name System”.
•The Clusters GUI was withdrawn from option 41 “HA Switchable Resources” and is available with PowerHA for i (5770-HAS).
•IBM HTTP Server i (DG1) option 1 “Triggered Cache Manager” was removed.
•IBM Toolbox for Java (JC1) moved to 5770-SS1 option 3 “Extended Base Directory Support”.
•IBM Developer Kit for Java (JV1) options 6 (JDK 1.4) and 7 (JDK 5.0) are no longer supported. J2SE 6.0 32 bit is the default JVM in IBM i 7.1.
•Extended Integrated Server Support for IBM i (5761-LSV) is no longer supported. Option 29 “Integrated Server Support” is available as a replacement.
•IBM System i Access for Wireless (5722-XP1) was withdrawn. The IBM Systems Director family provides similar systems management functionality.
•IBM Secure Perspective for System i (5733-PS1 and 5724-PS1) was withdrawn, although it continues to be available as a custom service offering only.
•The IBM WebSphere Application Server (5733-W61 and 5733-W70) minimum required levels for IBM i 7.1 are 6.1.0.29 and 7.0.0.7.
For more information about LPP changes, see the IBM i Memo to Users at:
Before you plan an IBM i release upgrade, see the IBM i upgrade planning website, which provides planning statements about IBM i product changes or replacements:
19.2 Changed or new CL commands and APIs
For a list with detailed information about changed or new CL commands and APIs in IBM i 7.1, see the CL command finder and API finder section in the IBM i 7.1 Knowledge Center:
19.3 Temporary user-defined file systems
New support for temporary user-defined file systems (UDFSs) is included in the IBM i 7.1 base code and available for IBM i 6.1 through PTF SI34983.
Temporary UDFSs can increase performance by reducing auxiliary storage operations. Applications that create and delete many temporarily used stream files can most benefit from using temporary UDFSs.
For temporary UDFSs, the system allocates only temporary storage. These temporary files and directories are automatically deleted after an IPL, unmount, or reclaim storage operation. Although regular (that is, permanent) UDFSs can be created in any ASP or IASP, the temporary UDFSs are supported in the system ASP only.
Normally, the /tmp IFS directory contains permanent objects that are not cleared when the system is restarted. To have /tmp on IBM i behave more like other platforms, a temporary UDFS can be mounted over /tmp so that it is cleared at system restarts. The files in a temporary UDFS should not contain critical data because it is not persistent.
The CRTUDFS command and IBM Navigator for i are enhanced to support the creation of temporary UDFSs through a new naming convention. Although names for permanent UDFSs must end with .udfs, the names for the new temporary UDFSs adhere to the naming convention of /dev/QASP01/newname.tmpudfs, as shown in Figure 19-1.
|
Create User-Defined FS (CRTUDFS)
Type choices, press Enter.
User-defined file system . . . . > '/dev/QASP01/mytmpfs.tmpudfs'
Public authority for data . . . *INDIR Name, *INDIR, *RWX, *RW...
Public authority for object . . *INDIR *INDIR, *NONE, *ALL...
+ for more values
Auditing value for objects . . . *SYSVAL *SYSVAL, *NONE, *USRPRF...
Scanning option for objects . . *PARENT *PARENT, *YES, *NO, *CHGONLY
Restricted rename and unlink . . *NO *NO, *YES
Default disk storage option . . *NORMAL *NORMAL, *MINIMIZE, *DYNAMIC
Default main storage option . . *NORMAL *NORMAL, *MINIMIZE, *DYNAMIC
Additional Parameters
Case sensitivity . . . . . . . . *MONO *MIXED, *MONO
Default file format . . . . . . *TYPE2 *TYPE1, *TYPE2
More...
F3=Exit F4=Prompt F5=Refresh F12=Cancel F13=How to use this display
F24=More keys
|
Figure 19-1 IBM i CRTUDFS command for creating temporary file systems
The following considerations apply for using temporary file systems:
•Temporary objects cannot be secured by authorization lists.
•User journaling of temporary objects is not allowed.
•Objects cannot be saved from or restored to a temporary file system.
•Extended attributes are not supported for temporary objects.
•Object signing of temporary objects is not allowed.
•Read-only mount of a temporary file system is not supported.
•The storage that is used for temporary objects is not accounted to the owning user profile or to any process.
For more information about temporary user-defined file systems, see the IBM i 7.1 Knowledge Center at the following web address:
19.4 Watch for Event function (message enhancements)
The Watch for Event function allows a user exit program to be started in a server job when certain events occur. The watch exit program does not run in the source job where the event occurs; it runs in a QSCWCHPS job in subsystem QUSRWRK. The following events can be watched:
•Messages sent to a program message queue (job log) of a job
•Messages sent to a nonprogram message queue (for example, a standard message queue such as QSYSOPR or a user profile message queue)
•LIC log entry (VLOG)
•Product Activity Log (PAL) entry
The function can also be used to end a trace when a watched event occurs. Watch parameters exist for the following trace CL commands:
•Start Trace (STRTRC)
•Start Communications Trace (STRCMNTRC)
•Trace Internal (TRCINT)
•Trace TCP/IP Application (TRCTCPAPP)
•Trace Connection (TRCCNN)
The Watch for Event function was initially available for the trace commands in V5R3M0 of IBM i. Watches were generalized in the following release, in V5R4M0, so that the watches were no longer tied only to trace commands. The Start Watch (STRWCH) and Start Watch API (QSCSWCH) commands were created for the generalized support. Additionally, the Work with Watch (WRKWCH) command was created to view watches, and the End Watch (ENDWCH) and End Watch API (QSCEWCH) commands were created to end watches. Support to watch for messages and LIC log entries was added in V5R4M0. Support to watch for PAL entries was added in V6R1M0.
The IBM i Knowledge Center contains exit program information to describe all the parameters that are passed to a watch or trace exit program.
19.4.1 Advantages of using watches
Watches can be used to accomplish the following tasks:
•Capture data for program debugging.
•Automate system management by running a corrective action or start / end functions without human intervention.
•Stop a trace when an event occurs to minimize the amount of data that is collected and minimize the amount of time trace active and slowing performance.
•Real-time notification of events can replace functions that used a periodic polling technique.
19.4.2 New Watch for Event function for IBM i 7.1
The message portion of the Watch for Event function has several enhancements that are described in the following sections. In addition, two new APIs to obtain watch information programmatically were created. The End Watch command and API were expanded to allow generic names, including *ALL.
Watch for Message enhancements
Functions were added to expand the message attributes that are allowed when you start a watch. There are new options for the message ID, message type, and severity in Version 7.1. These new attributes pertain to watching for messages, not LIC log or PAL entries, and allow specific watches to be created:
•Previously, a specific message ID needed to be specified when you watch for a message. Now, immediate or impromptu messages can be watched. The text of an immediate message does not exist in a message file. An example of an immediate message is The order application is down for 5 minutes starting at 11PM to load a fix. or Are you ready to go to lunch?
•Because immediate messages are now supported, this situation enabled support to watch for *ALL messages sent to a nonprogram message queue (such as QSYSOPR) or all messages sent to a program message queue for a job (job log).
•For predefined messages (that exist in a message file), a generic message ID can be specified, such as CPF18*, which allows messages CPF1806, CPF1808, and CPF1809 to be handled by starting one watch session.
•Message Type is a new attribute that is used for watching for messages. It allows certain message types to be watched with or without regard to other watch attributes.
For example, a message ID can be sent as a diagnostic and escape message, but if you want to act only when the message is sent as an escape, a watch can be tailored to that condition.
Another example is the need to be notified when any message is sent to a nonprogram (standard) message queue that was created with the Create Message Queue (CRTMSGQ) command. A watch can be started to watch for *ALL messages sent to the standard message queue. In the past, a program used the receive message function with a wait time to obtain the next message sent to a standard message queue.
•Messages can be watched based on message severity. Valid message severities values are 0 – 99. Five relational operators can be specified with a severity value:
– Equal to (*EQ)
– Greater than (*GT)
– Less than (*LT)
– Greater than or equal to (*GE)
– Less than or equal to (*LE)
For example, if you care only about messages of severity 99, you can now watch for only those messages.
Figure 19-2 shows the Watch for Message keyword with the STRWCH command for IBM i 7.1, with the new message type, relational operator, and severity code fields near the bottom portion of the window.
|
Start Watch (STRWCH)
Type choices, press Enter.
Session ID . . . . . . . . . . . Name, *GEN
Watch program . . . . . . . . . Name
Library . . . . . . . . . . . *LIBL Name, *LIBL, *CURLIB
Call watch program . . . . . . . *WCHEVT *WCHEVT *STRWCH *ENDWCH
Watch for message:
Message to watch . . . . . . . *NONE Name, generic*, *NONE...
Comparison data . . . . . . .
Compare against . . . . . . . *MSGDTA, *FROMPGM, *TOPGM
Message type . . . . . . . . . *ALL, *COMP, *DIAG...
Relational operator . . . . . *GE, *EQ, *GT, *LT, *LE
Severity code . . . . . . . . 0-99
+ for more values
Bottom
F3=Exit F4=Prompt F5=Refresh F12=Cancel F13=How to use this display
F24=More keys
|
Figure 19-2 Start Watch command
Two new APIs
The new watch APIs are Retrieve Watch List (QSCRWCHL) and Retrieve Watch Information (QSCRWCHI). QSCRWCHL obtains a list of watches on the system. Previously, the list of watches were viewed by using the Work with Watches (WRKWCH) command. QSCRWCHI returns information about a specific watch session. The information that is returned is similar to the data seen by running the WRKWCH command and using option 5 to display the details of a watch session.
End Watch additions
The End Watch function requires a session ID to be specified. The End Watch (ENDWCH) command and End Watch (QSCEWCH) API are enhanced to accept a generic session ID, including a value of *ALL. Previously, the valid values included a specific session ID name and the special value *PRV, which represented the watch session that was started most recently by the same user who is running the End Watch function. In IBM i 7.1, a generic name (such as TSTMSG*, WCH*, or *ALL) can be specified. The new values make it easier to end a group of watches. For example, a generic name of TSTMSG* specifies that all watch sessions with identifiers that begin with the prefix TSTMSG will be ended.
Recursive watches
Recursive watches do not watch for common or high use events. For example, if the job started message (CPF1124) or job ended message (CPF1164) are watched, the system is significantly affected. This watch never ends because when a watch exit program is called in the server job, that job ends and a new job is started to handle subsequent processing for watches. The ending of the job and starting of the new job causes the CPF1164 and CPF1124 to be generated, so a never-ending loop begins. A similar thing happens if *ALL messages in QHST were watched because those job messages for watch processing go to QHST. To prevent this recursive problem, start watches for specific message IDs or specify compare data or additional selection criteria to restrict the occurrence of the event.
19.5 IBM Tivoli Directory Server for IBM i enhancements
This section covers the enhancements to the IBM Tivoli Directory Server for IBM i (LDAP).
19.5.1 Creating suffix entries automatically when they are needed
The directory administrator can configure a new suffix dynamically and start adding entries beneath it. If the suffix entry does not exist, it is created when the first child entry is added.
19.5.2 Administrative roles
IBM Tivoli Directory Server for IBM i now implements a scheme where the root administrator can delegate tasks at a more granular level. This scheme is based on the administrative roles of the users that are defined in the configuration file. These roles are applicable only to the admin group members. Six roles are supported by IBM i:
•Audit Administrator (AuditAdmin)
•Directory Data Administrator (DirDataAdmin)
•No Administrator (NoAdmin)
•Replication Administrator (ReplicationAdmin)
•Schema Administrator (SchemaAdmin)
•Password Administrator (PasswordAdmin)
19.5.3 User interface enhancements
Tivoli includes the Web Administration Tool interface with Version 6.2. The Web-enablement for LDAP interface on IBM i Navigator enhancement enables the usage of an LDAP management tool on IBM Navigator for i and IBM i Navigator Tasks for the web.
19.5.4 Security enhancements
Attribute encryption can encrypt arbitrary attributes when they are stored in the underlying directory database.
19.5.5 New password encryption options
Two new password encryption options are supported:
•Salted SHA
•MD5
19.5.6 Pass-through authentication
If an LDAP client tries to bind to the Tivoli Directory Server and the credential is not available locally, the server attempts to verify the credential from an external directory server on behalf of the client.
19.5.7 Enhanced password policy to use global date and time for initialization
The proposed design change for the initialization of password policy attributes when the Password Policy function is first turned on is to introduce a new password policy entry attribute, ibm-pwdPolicyStartTime, that is added to the cn=pwdPolicy entry. This attribute is generated by the server when the administrator sends a request to turn on the Password Policy function. The current time is put into this attribute. This attribute is an optional attribute that cannot be deleted by a client request. It cannot be modified by a client request, except by administrators with administrative control. It can be replaced by a master server-generated request. The value of this attribute is changed when the Password Policy function is turned off and on by an administrator.
19.5.8 Multiple password policies
In this release, more options are available. In addition to the global password policy, each user in the directory can have their own individual password policy. Furthermore, to assist administrators, a group password policy is supported to enable effective password management.
19.5.9 Policy that is enforced for Digest-MD5 binds
The implementation of this feature ensures password policy rules such as account lockout, usage of grace logins, and a password expiration warning message is sent to a user when it uses DIGEST-MD5 bind as authentication mechanism.
In addition, the ibm-slapdDigestEnabled configuration option is added to enable and disable the DIGEST-MD5 bind mechanism.
19.5.10 Persistent search
Persistent search provides a function for clients to receive notification of changes that occur in the directory server by altering the standard LDAP search operation so that it does not end after the initial set of entries that match the search criteria are returned. Instead, LDAP clients can keep an active channel through which information about entries that change is communicated.
19.5.11 Replication configuration enhancements
The server configuration attributes master DN and password in the consumer server's configuration is now dynamic. For the extended operation readconfig, addition, deletion, or modification of entries that have an objectclass of ibm-slapdReplication/ibm-slapdSupplier is supported for the scopeValues of entire/entry/subtree.
19.5.12 Filtered replication
This enhancement allows the directory administrator to control what data is replicated to consumer servers by specifying which entries and attributes are to be replicated, based on the filters that are defined by the directory administrator.
19.5.13 Limiting the number of values that are returned by a search
The LDAP server provides a control that can be used on a search operation to limit the total number of attribute values that are returned for an entry and to limit the number of attribute values that are returned for each attribute in the entry.
19.5.14 Enhanced syntaxes and matching rules
Additional matching rule and syntax support (24 syntaxes and 17 matching rules) were added for new syntaxes and matching rules from RFC 2252, RFC 2256, and RFC 3698. Matching rules are not defined in any RFC, but are referenced in RFC 2798.
19.5.15 IASP enablement for Directory Server on IBM i
From IBM i 7.1 onward, the Directory Server on IBM i supports private IASPs, where:
•The support database library is in the IASP.
•The support change log library is in the IASP.
19.5.16 The ldapcompare utility
The ldapcompare utility compares the attribute value of an entry with a user provided value.
19.5.17 Providing a re-entrant LDAP C client library
The LDAP C client library is now re-entrant.
19.6 Automating multiple IPLs for PTF installation
A new function in IBM i 6.1 and IBM i 7.1 automates any additional IPLs that are required for a technology refresh PTF or special handling of pre-apply PTFs during the PTF installation process. If an additional IPL is required for a technology refresh PTF, your PTF installation parameters are saved and used during the next IPL. Instead of seeing the “Confirm IPL for Technology Refresh or Special Handling PTFs” panel, you see a new English message CPF362E: “IPL required to complete PTF install processing”. If you select Automatic IPL=Y on the “Install Options for PTFs” panel, you do not see any messages or panels; the server shuts down. On the next normal IPL, your second “GO PTF” occurs during the “PTF Processing” IPL step in the SCPF job, and then a second IPL of the partition occurs automatically. So when the system undergoes an IPL the second time, all the way up to sign on, your PTFs are all activated and ready to go.
Your total PTF installation time is shorter because none of the system jobs start during the first IPL when the partition restarts. However, you have a longer IPL time because the system is doing the work you previously did interactively, that is, the second GO PTF to set all PTFs for delayed applies.
If you wonder why the IPL is taking so long and what it is doing, you can always open the console. When you open the console, you can open the “Operating System IPL in Progress” panel, which shows the “PTF Processing” IPL step as active. Previously, the “Applying PTFs” for the Activity were shown in this step, but now you also see “Loading PTFs” or “Setting IPL Action for PTFs” if the previous PTF installation was incomplete.
When all PTFs are set for delayed apply, you see the IPL requested by PTF processing status message at the bottom of the panel and then the partition restarts to apply the delayed LIC PTFs. The next time that you reach the “PTF Processing” IPL step, you see the usual “Applying PTFs” step and the IPL continues.
To take advantage of this new function, you must have the following PTF (PTF management code) temporarily applied before you run your PTF installation:
•Version 7.1: SI43585 in HIPER PTF group SF99709 level 30 or higher
•Version 6.1: SI43939 in HIPER PTF group SF99609 level 94 or higher
For Version 7.1, if an IPL is required for a technology refresh PTF, the new function supports installing only from a virtual optical device or *SERVICE (PTFs downloaded electronically to save files). If you are installing from a physical optical device, you still must run the additional IPL and second GO PTF manually. So, if you received your PTFs on physical DVDs, create an image catalog from the DVDs and use the new support.
19.7 IBM i workload groups
IBM i 7.1 now provides workload groups, which were formerly called workload capping. Workload groups can restrict a workload to a specified maximum number of processor cores within the partition it is running in.
A workload is defined as a job, subsystem, or product that is running on the IBM i system. The user or system administrator can define a workload group, assigning a specified number of processing cores to that group. The workload group is then assigned to a job or subsystem. After the assignment is done, the workload is limited to the defined number of processing cores. The system enforces this processing core assignment, ensuring that a job or all the jobs that are running (and threads) under the subsystem are not allowed to run on more processing cores than are designated.
An example is shown in Figure 19-3. The number of processing cores of the subsystem for Application #1 is set to three and for Application #2 is set to six. No matter how much Application #1 needs processing capabilities that exceed three, it is not allowed to run on more processing cores than three cores, even though IBM i has eight cores. The general concept is if a workload is designated to use a single core, the workload behaves as through it is actually running on a single processor core system.
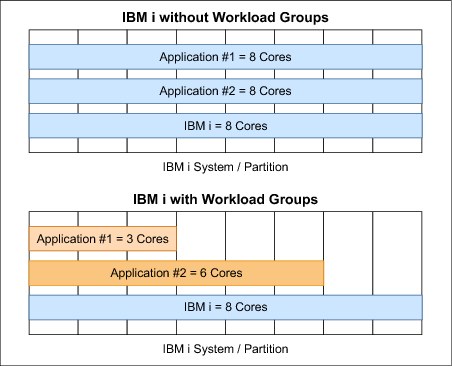
Figure 19-3 Concept of Workload Groups
19.7.1 Example of how Workload Group works
A user has a batch job that is processor intensive. This user must run this job during the day but cannot afford to impact the performance of the production system. By assigning this batch job to a workload group, this job can be put into a “processing container” to help ensure that this job is kept to a limited amount of system capacity. If the workload group has a processor core limit of one, then the batch job and any threads that are running under that job are allowed to run only on a single processor core. If this job is running on a multiple threaded core, multiple threads can be running for that designated batch job, but only a single core is used at a time. This same concept also applies to jobs that are running under a subsystem that is assigned to a workload group. All jobs and their associated threads are limited to the number of processor cores that are specified in the workload group.
This new capability can help users get better control of the workloads on their systems along with ensuring products are using only a designated number of processor cores. Software vendors can take advantage of the workload group support as a new virtualization technology. A workload can be virtualized and licensed within a virtualized system. Product entitlements can be specified based on the usage of the product instead of the total processor cores of the LPAR.
Customers who want to take advantage of the enhanced licensing controls must register the specified products with the native IBM i License Management tool that facilitates both the registering and management of the enforcement of the workload groups. To help users manage and understand the performance of jobs that are running in a workload group, the performance metrics are updated to include metrics on workload groups.
To learn more about the workload groups support, see the IBM i 7.1 Knowledge Center:
19.7.2 IBM Passport Advantage Sub-capacity Licensing support
IBM i Workload Groups is now an Eligible Virtualization Technology for IBM Passport Advantage® Sub-capacity Licensing. You can use Passport Advantage Sub-capacity Licensing to license an eligible software product for less than the full capacity of a server. It provides the licensing granularity that is needed to use various multi-core chip and virtualization technologies. As more customers take advantage of virtualization technologies in their server environments, IBM continues to introduce enhancements to the Sub-capacity Licensing offering.
For details and current information about Sub-capacity Licensing terms, go to these websites:
Configuring WebSphere MQ to use workload groups
You can learn how to configure your systems to use workload groups for the WebSphere MQ product. You can limit the amount of processing capacity available to this product to better fit your licensing needs based on the capacity that is being used for this product.
To see the details, see WebSphere MQ and Workload Groups Final, found at the following web address:
19.8 IBM i on a Flex Compute Node
IBM i can run on a Flex Compute Node since April 2012.
The following two models of the POWER processor-based Flex Compute Node support IBM i.
•IBM Flex System® p260 Compute Node Model 7895-22X
•IBM Flex System p460 Compute Node Model 7895-42X
For the hardware details, see the following website:
The following releases of IBM i are supported on the POWER processor-based Flex
Compute Node.
Compute Node.
•IBM i 6.1 Resave RS610-10 with License Internal Code 6.1.1 Resave RS-611-H or later
•IBM i 7.1 with Technology Refresh 4 or later
To configure an IBM i environment on those Compute Nodes, VIOS is required. Any physical adapters that are installed on the node are owned by VIOS, which is also the case with POWER processor-based blade servers. To see the details of IBM i on a Flex Compute Node, including configuring IBM i, go to the developerWorks website at the following web address:
You can also run IBM i on the POWER processor-based Compute Node in the IBM PureFlex® System. When you order IBM PureFlex System, a dedicated management appliance, which is called Flex System Manager (FSM), is bundled with the IBM PureFlex System. FSM is used for managing and operating an IBM PureFlex System, including hardware, firmware, virtualization environment, and operating systems environment on a POWER processor-based Compute Node.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.